
カノニカルタグとは何ですか、いつ使用するか
公開: 2022-04-28正規タグは、しばしばrel =“ canonical”と呼ばれ、検索エンジンにコンテンツのプライマリバージョンまたは「マスターコピー」であるURLを通知するHTMLタグです。 これらのわかりやすいタグにより、サイト所有者は、検索に表示する優先ページとしてGoogleが指定する1つのURLを提案することができます。 正規タグは、重複コンテンツから発生するSEOの問題も防ぎます。
これらの単純なHTMLリンク要素は、サイトのSEOで主要な役割を果たします。 それらも使いやすいですが、正しく使用された場合にのみ機能します。 正規タグに慣れていない場合、この記事は、正規タグを使用する方法、時期、理由、および正規タグの問題を回避する方法を学ぶのに役立ちます。
カノニカルタグとは何ですか?
正規タグは、ページのヘッダーまたは<head>に挿入されるHTMLリンク要素です。 これらのタグは検索エンジンによって開発され、2009年に公開されました。これらのタグは、検索結果の品質を向上させるためにサイト所有者と協力している検索エンジンの優れた例の1つです。
正規タグは、検索エンジンに次のいずれかを伝えます。
- ページ上のそのコンテンツは、どのページをプライマリバージョンと見なす必要があるかに加えて、別のページの複製です。
- 複数のURLを持つ単一のページの場合、タグはGooglebotまたはBingボットにどの正確なURLがインデックスに登録するのが正しいかを通知します。
このタグは、重複ではなくプライマリページにインデックスを付けるようにクローラーに指示します。 正規URLは、検索エンジンが検索エンジンの結果に表示するページをGoogleに示します。このタグは、プライマリバージョンがオーガニック検索の可視性を受け取る必要があるバージョンであることを検索エンジンに通知します。
インデックスに登録するURLをGoogleに指示することはできますが、 Googleが推奨に従わない場合があることに注意してください。
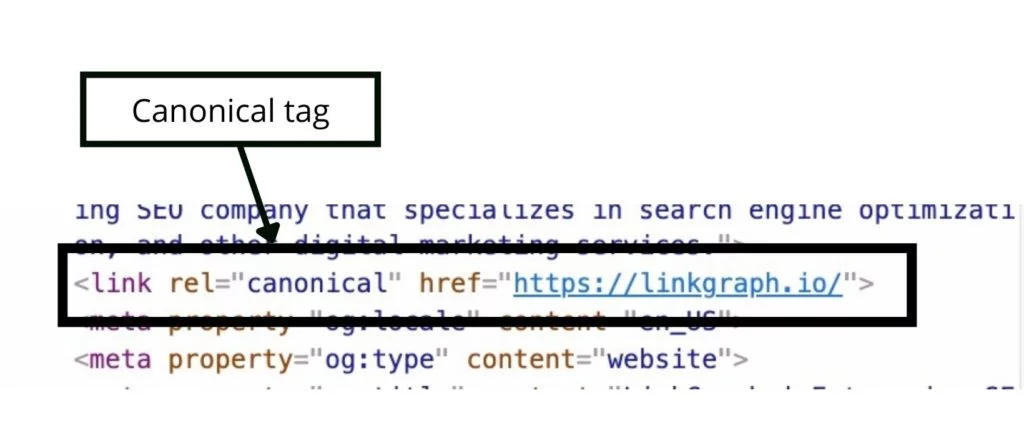
正規タグは次のようになります。
または
<link rel = “ canonical” href = “ https://example.com “ />
カノニカルタグのパーツは何ですか?
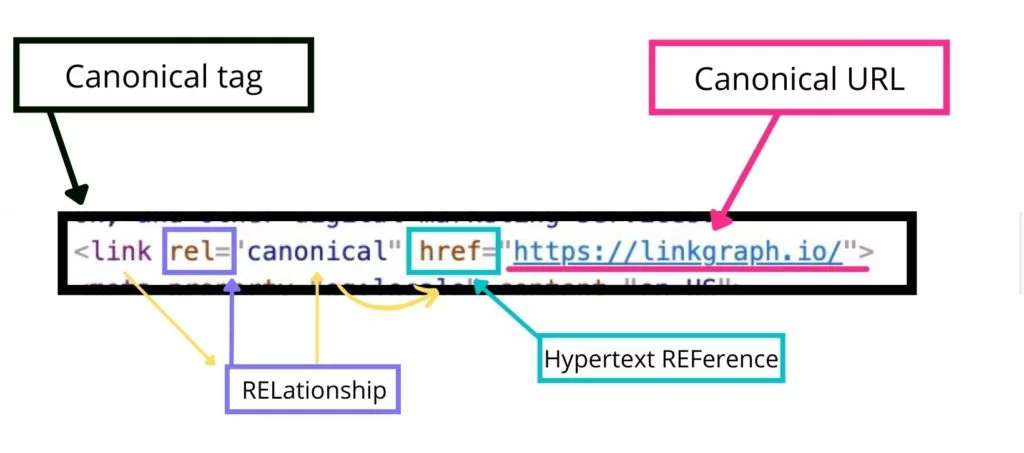
正規タグは、正規リンク要素とも呼ばれます。これは、この一意のHTMLコードのもう少し直感的なラベルです。 なんで? 正規タグは正規リンクを提供し、ページとリンクの間の関係を定義するためです。
HTMLでは、 relはページとリンクされたリソースの間に関係があることをGooglebotに伝えます。 この場合、関係は、 href属性の後に表示される正規ページを識別します(hrefはハイパーテキストREFerenceです)。
標準URLとは
正規URLは、サイト所有者が検索エンジンにコンテンツの主要なソースとして認識させたいWebページの主要なバージョンです。 正規URLは、Webクローラーがコンテンツの正しいソースとしてインデックスを作成するWebページです。 リンク要素のこの部分は、href =” canonicalURL”の後に表示されます。
正規タグは正規URLと同じですか?

正規URLは正規タグ内に表示されます。 正規URLは、正規タグ内のハイパーリンク参照要素です。 これは、ソースコンテンツの正規バージョンと見なされる正確なURLを示します。
なぜ正規化が重要なのですか?
eコマースサイトや広告収入を生み出すサイトに関しては、あらゆる機会を利用して、検索エンジンの結果ページ(SERP)に最適なURLを表示するようにしてください。 そして、正規化は、どのサイトをインデックスに登録するかをGoogleに指示することでこれを実行します。 サイトをより細かく制御できるだけでなく、ユーザーを最も価値の高いページに誘導することもできます。
自己参照の正規タグを使用する必要がありますか?
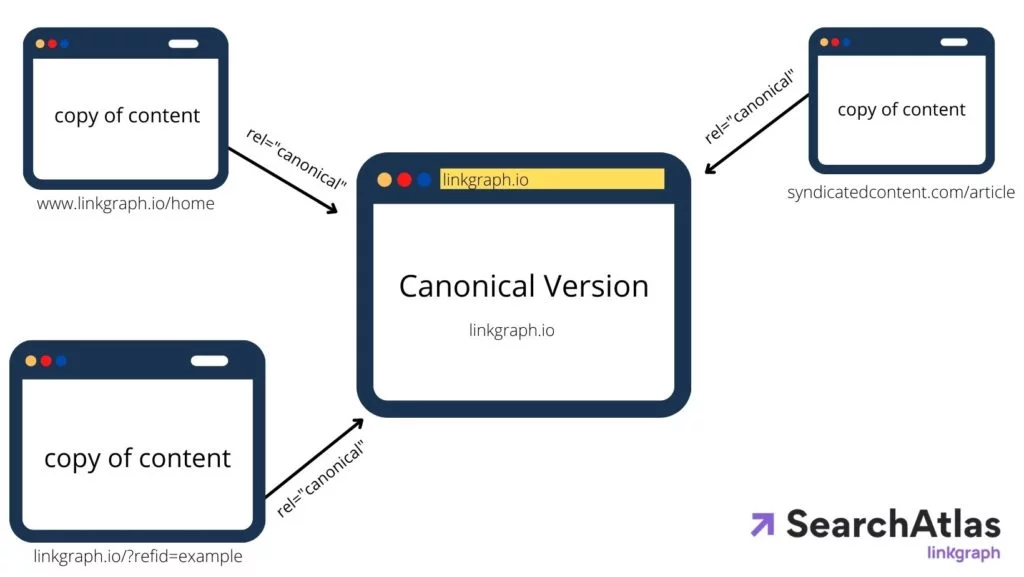
ユニークに見えるかもしれないウェブページでさえ、さまざまなURLの下で見つけることができます。 例えば:

これらの各URLは同じホームページを表示しますが、技術的にはそれぞれ独自のURLでもあります。 これにより、サードパーティのWebサイトにコンテンツが重複しているのと同じ問題が発生する可能性があります。 linkgraph.ioに正規タグがないと、検索エンジンのアルゴリズムは検索者に表示する優先URLではありません。
検索エンジンをさらに混乱させるため、動的ページには多くの場合、さまざまなタグがあり、それぞれに独自のURLがあります。 WordPressのようなコンテンツ管理システム(CMS)は、多くの場合、タグをWebページに自動的に埋め込みます。 したがって、基本的なページでさえ、検索エンジンによって完全に索引付け可能な多数のURLで終わることになります。
したがって、最善の策は、正規URLのヘッダー内にも正規タグを配置することです。
Canonicalタグはデータ収集と分析を合理化します
さらに、検索指標を追跡しているときに、同じURLで1つのページのすべてのオーガニック検索をコンパイルする必要があります。 正規タグは、指定されたページのみが検索結果の指標を受け取ることを保証します。
シンジケートコンテンツとのSEOの競合を防ぐ
多くのウェブサイトは、コンテンツシンジケーションを通じてバックリンクを構築します。 ただし、コンテンツの作成は、タイムリーでコストのかかる投資になる可能性があります。 シンジケート化された関係を通じて、サードパーティのサイトにある既存の高品質のコンテンツをユーザーに提供できます。 または、ブランドの認知度を高めながら、サイトにコンテンツのライブラリを構築し続けます。
ただし、正規のタグがないと、検索エンジンはサイトのインデックスを記事のインデックスにするかサードパーティのインデックスにするかを判断できません。 標準タグを使用すると、シンジケーションパートナーはこの問題を単純化できます。 注:重複を防ぐために、ページの1つでnoindexタグを使用することもできます。
重複コンテンツの問題は何ですか?

コンテンツが重複していると、SEOに関連するさまざまな問題が発生する可能性があります。 Googlebotsが同一または非常に類似したコンテンツのウェブページをインデックスに登録すると、次のことが可能になります。
- インデックス作成プロセスを遅くすると、インデックスに登録されるサイトが少なくなります。
- 負のランキングシグナルとしてGoogleに登録し、ページをSERPのさらに下にランク付けします。
- 検索エンジンが検索者に表示するページについて混乱させます。
カノニカルタグがSEOにどのように役立つか
何よりもまず、正規タグは、Googleが検索者にサイトを表示する方法に影響を与えることができる数少ない方法の1つです。 また、正規化により、重複コンテンツがあるためにPageRankに「ドッキング」されるのを防ぎます。Googleは重複コンテンツに直接ペナルティを課しませんが、適切に編成された元のコンテンツを優先します。
最後に、バックリンクやブランド構築のための優れたコンテンツをWebサイト以外のユーザーに提供することもできます。
重複コンテンツとは何ですか?

重複するコンテンツは、テキストをコピーして貼り付けるだけではありません。 まったく同じ、類似した、または並べ替えられたテキスト、画像、およびその他のメディアを書き込むことができます。 また、Googleは、CMSの重複コンテンツからのプレースフィラーテキストと画像がウェブに公開されている場合、それを考慮します。
サイトのすべてのページにある著作権テキストなどの基本情報には、重複のフラグを付けることもできます。
カノニカルタグの使用方法
最終的に、最高のSEO結果を得るには、Webサイト全体で正規のタグを使用することをお勧めします。 既存のページを更新したら、正規化のベストプラクティスを引き続き実装する必要があります。
最初のステップは、サイトページのどのURLバージョンを正規URLにするかを特定することです。 Googleは、正規リンクのフォーマットに一貫性があるかどうかを優先します。 したがって、「www」を使用する場合。 ホームページの正規リンクで、他の正規URLに含めます。
たとえば、LinkGraphでは、正規タグ全体で「https」プロトコルを使用していますが、「www」は含まれていません。

これにより、同じページを指す複数のURLに関する問題が解決されます。
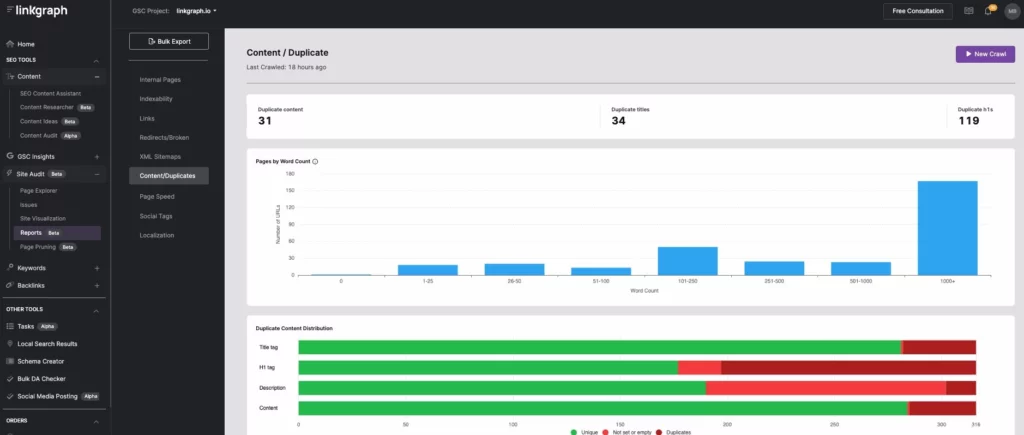
次に、サイト内の重複コンテンツにタグを付けるか、削除する必要があります。 これは、SearchAtlasのサイト監査ツールを使用して行うことができます。 コンテンツ/複製レポートを表示するのと同じくらい簡単です。
最後に、サードパーティのサイトに残っている重複コンテンツを見つけたいと思うでしょう。 Copyscapeなどのツールを使用してこれを行うことができます。 Web上の他の場所でコンテンツを特定したら、次のことを決定する必要があります。
- あなたのコンテンツは許可なく盗まれ、再公開されました
- 既存のコンテンツまたは他のページと類似しすぎているコンテンツを誤って盗用した
- シンジケートされたページが重複として登録されています
- 同じコンテンツのページがありますが、2つの異なるカテゴリページに商品が表示されるなど、適切です。
次に、対応するソリューションで応答する必要があります。
- 重複をGoogleに報告する
- コンテンツをすぐに削除して、オリジナルの高品質なコンテンツを作成します
- どのページを正規URLにするかについてシンジケーションパートナーと話し合い、正しい正規を反映する正規タグを実装します
- 指定された正規URLで正規タグを使用する
カノニカルタグを使用する場合
正規タグに関しては、常に正規タグを使用することで、重複コンテンツの問題を減らすことができます。 ただし、サイトを更新する場合は、次のことを優先する必要があります。

- バリエーションフィルタリングを備えた製品カテゴリページ:これには、さまざまなサイズ、ブランド、色、および数量が含まれます。 これらのバリエーションにはそれぞれ異なるURLが必要です。
- ページネーションを使用する記事とページ:多くの場合、これらは複数のページに分割された長いブログです。
- 複数のカテゴリページに表示される商品ページ。
- ビジネスに関する情報など、類似したコンテンツを含むページ。
Webサイトに正規タグを実装する
正規のタグを実装するには、ウェブマスターである必要がありますか? 必ずしも。 サイトのHTMLコードでの作業に慣れている場合は、正規のタグを独自に実装できます。
正規タグを設定する方法は次のとおりです。
HTTPヘッダーの正規タグ
正規タグを使用する最も簡単な方法は、HTTPヘッダーにタグテキストを挿入して更新することです。 ページのこのHTTPヘッダーセクションは次のようになります![]()
1.希望する正規URLを特定します。
2. rel = canonicalリンクタグを非正規ページの<head>セクションに追加し、正しい正規URLリンクをHTMLリンクタグに挿入します。
次のようになります。

コピーアンドペーストバージョン:
<link rel = “ canonical” href = “ https:// yoursite / canonicalpage” />
これですべてです。 正規バージョンのページにリンクするためにウェブマスターである必要はありません。
カノニカルタグの確認
正規タグが正しいURLで正しく実装されているかどうかを確認するには、Webページのソースコードを表示する必要があります。 このプロセスは簡単です。
- まず、ブラウザを使用して確認するWebページまたはコンテンツのバージョンに移動します。
- 次に、ページ内の任意の場所を右クリックして、[検査]を選択します。 これにより、自分のサイトまたは他のサイトのページ(またはURL検査ツール)のソースコードが開き、他のサイトの正規リンク要素が表示されます。
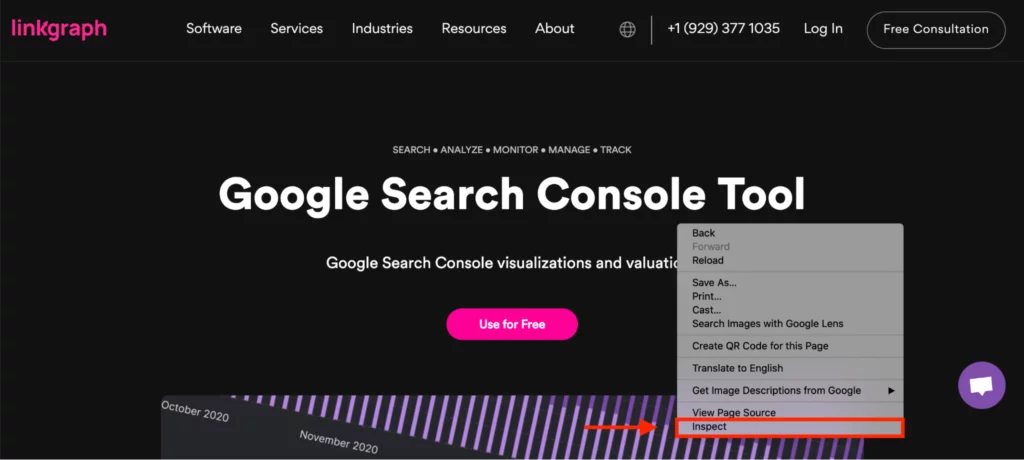
- HTMLソースコードメニューが開いたら、Windowsの場合はCtrl + f、Macの場合はf+コマンドを押します。 次に、検索文字列、セレクター、またはXPathに「canonical」と入力します。
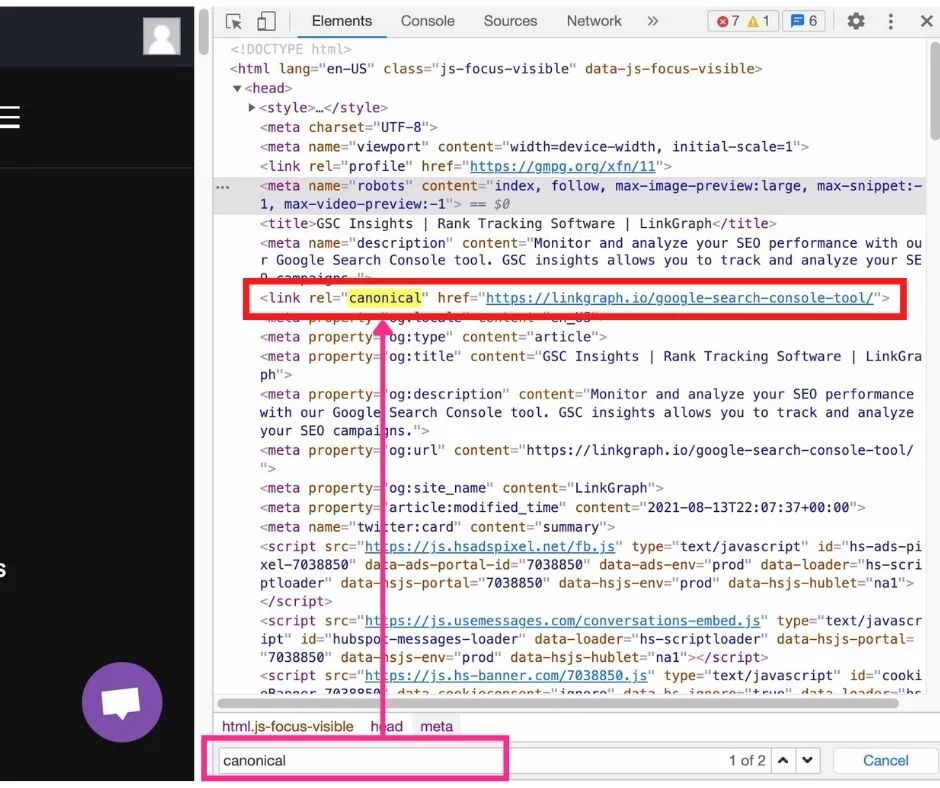
- 「canonical」という単語が表示され、黄色が強調表示されるため、確認のためにヘッダーが見やすくなります。 正規化されたURLが正しいことを確認してください。 結果が表示されない場合、ページには正規のHTMLタグがありません。
正規タグを検証する他の方法
Google SearchConsoleとGSCInsightsは、誤ってタグ付けされたページを見つけるための優れたツールです。 オーガニックトラフィックの統計を調べて、非正規ページに到達する検索トラフィックに気付いた場合、正規タグが正しくない可能性があります。
これらのページを修正するには、特定のURLに移動してから、ページを調べます。
サイトマップの正規URL
サイトマップを作成または更新するときは、重複するURLを含めないでください。 正規のURLを含めるだけで済みます。 サイトマップに正規バージョンのページが含まれていると、Googleのボットが重複バージョンのコンテンツをクロールしないように示唆されます。
Robots.txtファイルの重複ページを除外する必要がありますか?
robots.txtファイルの重複ページを禁止しないでください。 これにより、Googleはこれらのページのランキングシグナルを使用できなくなります。 正規タグを正しく実装すると、エンゲージメント(クリック、スクロール、テキスト入力)やコンテンツ信号などのランキング信号が正規ページの指標にカウントされます。
CMSで正規タグを使用する方法
WordPress、Shopify、Wix、BigCommerceなどのCMSプラットフォームを介してサイトを編集する場合。 これらのCMSのほとんどには、HTMLドキュメントを直接編集せずに、正規リンクタグを追加するための特定の手順があります。 最も一般的なCMSプラットフォームについて説明します。
Wix、Shopify、またはWordPressサイトの正規タグにYoastを使用する
WordPress、Shopify、またはWix用のYoast SEOプラグインを使用すると、優先URLを簡単に編集して正規タグとして追加できます。
- Yoast SEOプラグインを追加すると、Yoast編集の下部に[詳細設定]メニューが表示されます。 このメニューを開きます。
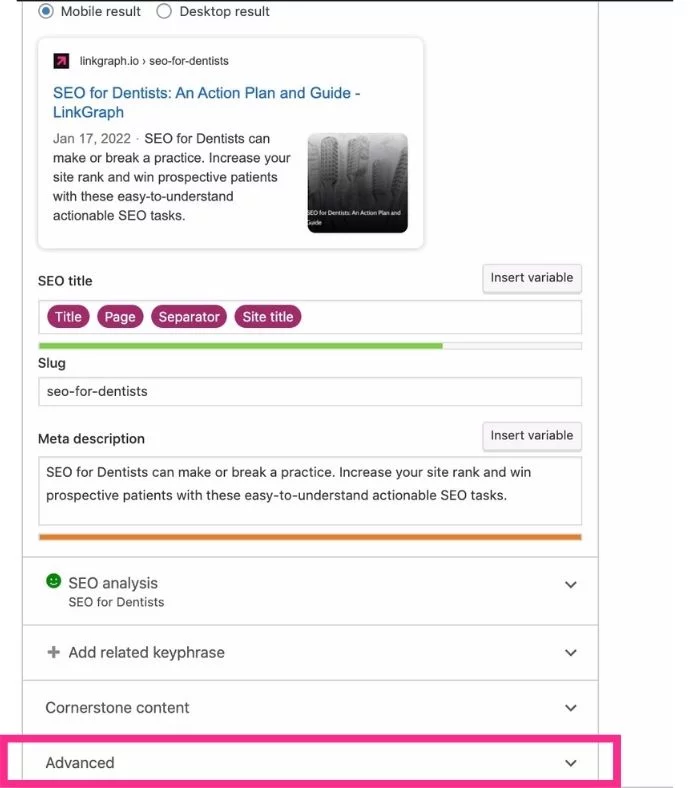
- 正規URLとして指定するURLのバージョンを入力します。
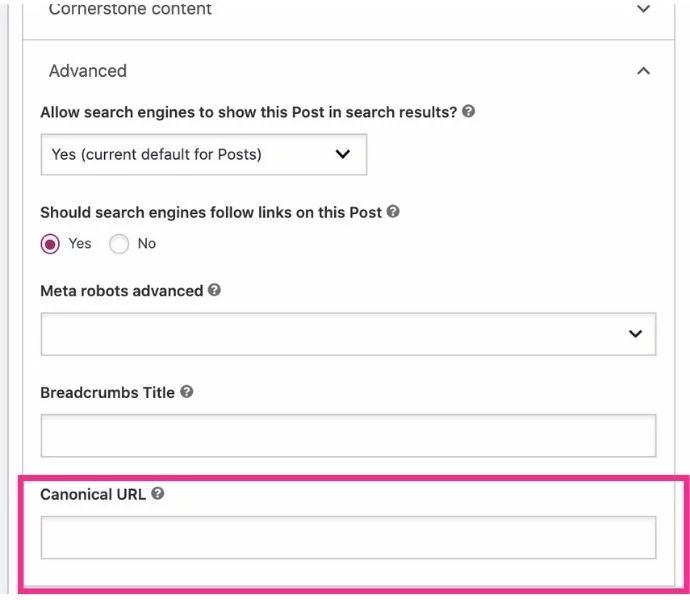
これらの8つの正規タグの間違いをしないでください

正規タグは、正しく実装されている場合にのみ適切に機能します。誤った実装は災害になる可能性があります。 幸いなことに、eコマースサイトや広告収入サイトが次のGoogleクロールを最大限に活用できるようにするために回避できる一般的な間違いがあります。
優先されないバージョンのページへのオーガニックトラフィックを受信していることに気付いた場合は、次の問題を確認する必要があります。
1.正規リンクの代わりに301リダイレクトを使用しないでください

Googleやその他の検索エンジンは、ウェブサイトの構成を改善し、ユーザーエクスペリエンスを改善するために、正規の属性を作成しました。 301リダイレクトを使用すると、ページの読み込み時間が長くなります。 これは、サーバーが他のバージョンのページを取得する前に、リダイレクトされたURLを取得する必要があるためです。
さらに、正規属性の代わりにリダイレクトを選択すると、Googlebotに間違ったシグナルが送信されます。
2.内部リンクと正規タグ
正規バージョンとしてそのページを指す内部リンクのないページを選択しないでください。 正規タグはクローラーへの単なるヒントであり、正規URLがサイトマップに表示されない場合は、インデックスに登録されない可能性が高くなります。
3.重複ページのいずれかで「noindex」を使用する

Googlebotが重複ページのインデックスを作成するのを防ぐ必要はありません。 実際、複製ページでリンクの公平性やその他の品質信号を正規のページに渡す必要があります。
Noindexは、ゲートされたコンテンツや検索結果から非表示にするその他のコンテンツ用に予約する必要があります。
4.正規化されたURLの4XXステータスコードを防止します
正規リンクのURLを正しく入力してください。 使用するバージョンがわからない場合は、絶対URLをデフォルトにすることを検討してください。
絶対URLには、プロトコル(HTTPS)、ドメイン名( www.yourhomepage.com )、およびサブフォルダー(/ subfolder)を含める必要があります。 HTTPSプロトコルを使用して、サイトがユーザーに対してSSLセキュリティを備えていることを示す必要があることを忘れないでください。
また、優先URLのスペルが正しいことを常に確認してください。 これが404エラーの最も一般的な理由です。
5.すべてのページ化されたページをルートページに正規化する
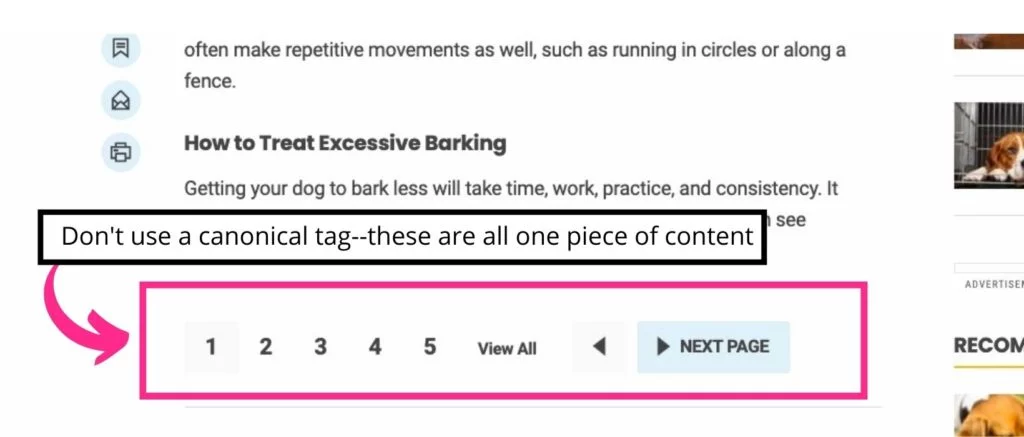
複数のWebページを含むブログ投稿またはガイドを作成する場合は、後続のページからシリーズの最初のページに正規にリンクしないでください。 これにより、Googlebotがシリーズ全体のインデックスを作成できなくなります。 代わりに、rel =” canonical”をrel =” prev”およびrel =” next”に置き換えます。
6.HreflangタグでCanonicalsを使用しない
Hreflanfタグは、多様でマルチリージョンのオーディエンスにより良いサービスを提供するために、ページが複数の言語で表示されることをGoogleに通知します。 異なる言語バージョンは、コンテンツの重複として表示できます。 したがって、Googleは、ウェブマスターが常に正規タグと組み合わせてHreflangタグを使用することを求めています。
7.1つのページで複数の正規タグを使用する
見落とされがちな問題は、誤って複数のrel=canonicalタグを使用していることです。 この問題は、複数の人がページを編集するときに発生する可能性があります。 幸いなことに、それを知っていれば、修正するのは簡単で、回避するのも簡単です。
8.正規URLの基本的なタイプミス
正規タグを挿入したが、非優先ページに到着するオーガニックトラフィックに気付いた場合は、すべての要素が正しく配置されていることを再確認してください。 最も一般的にスキップされる文字の1つは、終了スラッシュであることに注意してください。
カノニカルタグを採用し、より良いSEO結果をお楽しみください
正規のタグを使用していない場合は、見逃している可能性があります。 標準タグは、URLバリアントから発生する多数の重複コンテンツの問題を防ぐことができ、その結果、SEOパフォーマンスが向上し、Googleがクロールするためのサイトがより整理されます。 さらに、正規タグを実装すると、すべての検索メトリックが無数のバリアントではなく、1つの整頓されたページにコンパイルされます。
検索指標を先取りし、利用可能な最高のキーワード追跡ツールを使用して、統合されたデータを最大限に活用します。