
Automatyczne śledzenie jest [nadal] złe!
Opublikowany: 2022-01-11Wiele lat temu byłem na konferencji poświęconej analitykom cyfrowym i odwiedziłem stoisko nowego dostawcy marketingu, który proponował opcję „braku tagowania” dla analityki marketingu cyfrowego. Byłem zaintrygowany, ponieważ większość mojej kariery zawodowej spędziłem pisząc o architekturze rozwiązań do analityki cyfrowej i tagowaniu. Po usłyszeniu ich głosu mogłem zobaczyć urok tego, co oferowali. Wyobraź sobie, że możesz „automatycznie śledzić” wszystkie dane, których możesz potrzebować od swoich klientów, bez konieczności poświęcania czasu na architekturę rozwiązania, projektowanie lub błaganie programistów o zbudowanie warstwy danych i ustawienie zdarzeń i właściwości analitycznych. Kto by tego nie chciał?
Ale kiedy o tym pomyślałem, zacząłem zdawać sobie sprawę, jaki to byłby okropny pomysł! W początkach analityki cyfrowej powszechne było zbieranie danych przez strony internetowe „DOM scraping”. Skrobanie DOM umożliwiło zbieranie danych ze znaczników HTML i umieszczanie ich w zmiennych analitycznych. Ta metoda była szybka, ale też niezwykle delikatna. Skrobanie DOM zostało wkrótce zastąpione warstwami danych i systemami zarządzania tagami. Ta ostatnia zajęła więcej czasu, ale była znacznie mniej krucha (aby zapoznać się z dobrą historią tego przejścia, przeczytaj to). Używanie podejść do automatycznego śledzenia do tagowania to krok wstecz do dni scrapingu DOM i przywraca wiele jego kruchości.
Jednak co kilka lat pojawia się ponowny nacisk, aby skłonić organizacje do ponownego rozważenia rozwiązań automatycznego śledzenia lub „bez tagowania”, a wielu, którzy nie byli w pobliżu, aby doświadczyć ich wad, nabiera się na nie i powtarza błędy z przeszłości. O ile nie budujesz cyfrowej usługi, która będzie używana tylko przez kilka tygodni lub miesięcy, nie wyobrażam sobie żadnej sytuacji, w której doradzałbym organizacji stosowanie podejścia automatycznego śledzenia do analityki cyfrowej. Oto krótkie podsumowanie powodów, dla których warto unikać tych rozwiązań:
- Za dużo danych — produkty z funkcją automatycznego śledzenia z natury gromadzą zbyt dużo danych i utrudniają znalezienie istotnych danych, których potrzebujesz, aby odnieść sukces.
- Złe dane — produkty z funkcją automatycznego śledzenia ułatwiają zbieranie danych, ale wiele z tych danych staje się złych lub bezużytecznych bez potrzeby czyszczenia definicji zdarzeń i reguł dopasowania CSS za każdym razem, gdy programiści wprowadzają zmiany w witrynach lub aplikacjach. Prosta zmiana nazwy przez programistę może odrzucić niektóre kluczowe metryki, dopóki nowa nazwa nie zostanie naprawiona/zracjonalizowana. Dowiedziałem się, że uzyskanie adopcji w zakresie analityki cyfrowej jest trudne, nawet jeśli wykonujesz świetną robotę, zapewniając, że zbierane dane są dokładne. Wyobraź sobie, że próbujesz odnieść sukces, jeśli krytyczne punkty danych są nieprawidłowe przez pewien czas, dopóki nie zostaną naprawione. W wielu organizacjach ludzie szukają wymówek, aby „ufać swojemu przeczuciu” zamiast korzystać z danych, a niska jakość danych może dać im pretekst do ignorowania danych z analityki cyfrowej.
- Nie oszczędza czasu — jak mówi jeden z naszych współzałożycieli, Jeffrey Wang: „Automatyczne śledzenie nie eliminuje pracy. Przenosi pracę do mniej skalowalnego procesu”. Automatyczne śledzenie oszczędza czas tym, którzy w innym przypadku musieliby przemyśleć to, co chcą śledzić w witrynach/aplikacjach, ale daje więcej pracy analitykom, zasobom jakości danych lub menedżerom produktów, którzy mają obsesję na punkcie tagowania. Więc jeśli osoby w Twojej organizacji naciskają na rozwiązanie z automatycznym śledzeniem, istnieje możliwość, że motywacją jest to, że zaoszczędzi to im czasu. Lub może być tak, że uważają, że organizacja i tak nie wykorzystuje danych do osiągania lepszych wyników, więc po prostu chcą ścieżki najmniejszego oporu.
- Problemy z bezpieczeństwem/prywatnością – produkty z funkcją automatycznego śledzenia mogą przypadkowo przechwytywać poufne lub prywatne dane, które nie są przeznaczone do gromadzenia (więcej informacji można uzyskać w „hasłach automatycznego śledzenia” Google). Jest to coraz bardziej niebezpieczne, ponieważ nowe dyrektywy, takie jak RODO i CCPA, nakładają kary na organizacje za niewłaściwe przetwarzanie danych osobowych.
Wiele z tych obaw zostało przedstawionych lata temu przez Jeffreya Wanga, jednego z naszych współzałożycieli Amplitude, kiedy wyjaśnił, dlaczego Amplitude celowo nie dodała automatycznego śledzenia do naszego produktu. Nawet organizacje, z którymi konkuruje Amplitude, zgodziły się, że automatyczne śledzenie to zła strategia.
Poziomy danych
Niedawno miałem przyjemność przysłuchiwać się rozmowie mojego kolegi Johna Cutlera na temat automatycznego śledzenia. Podczas rozmowy pojawił się potencjalny klient, który porównywał Amplitudę z konkurentem, a jedną z dużych różnic było automatyczne śledzenie, które zdaniem potencjalnego klienta może im pomóc. John wyjaśnił, że w przypadku analityki cyfrowej istnieją zasadniczo trzy poziomy danych:
- Poziom 0 — są to najważniejsze punkty danych dla Twojej organizacji. Nigdy się nie zmienią, chyba że Twoja organizacja dokona ogromnego zwrotu w nowym obszarze lub modelu biznesowym. Na przykład produkt do zarządzania kampanią B2B prawie na pewno miałby zdarzenie Campaign Created z zestawem dość stabilnych właściwości.
- Poziom 1 — Są to punkty danych, które będą przydatne w średnim okresie. Prawdopodobnie przydadzą się przez następny rok lub dwa, ale istnieje szansa, że mogą się zmienić wraz ze zmianą witryny/aplikacji. Kontynuując przykład B2B, może to obejmować śledzenie rozpoczęcia i zakończenia wideo wprowadzającego. Obecnie podczas tworzenia kampanii filmy są wyświetlane nowym klientom, ale za rok filmy mogą zostać usunięte, jeśli nie zostanie udowodnione, że zwiększają współczynniki tworzenia kampanii.
- Poziom 2 – Są to punkty danych, które są bardziej przejściowe i często bardzo szczegółowe. Mogą istnieć tylko przez kilka tygodni lub kilka miesięcy. Przykładem może być śledzenie kliknięć określonego linku, przełącznika lub przycisku w formularzu. W tej chwili jest to dla kogoś interesujące, ale nie wnosi tak dużej wartości i prawdopodobnie zniknie za kilka tygodni, lub oznaczanie go może zakończyć się, gdy dostarczone informacje zostaną zrozumiane i prawdopodobnie nie zmienią się dramatycznie.
W przypadku większości organizacji będzie stosunkowo niewiele zdarzeń i właściwości poziomu 0, znacznie więcej elementów poziomu 1 i mogą istnieć setki elementów poziomu 2. Większość czasu należy poświęcić na przedmioty poziomu 0 i 1. Pozycje poziomu 2 powinny pojawiać się naturalnie, dzięki zintegrowaniu tagowania z procesem tworzenia. Powodem, dla którego ta koncepcja jest tak interesująca, jest to, że większość przypadków rozwiązań z automatycznym śledzeniem opiera się na tym, ile pracy jest potrzebne do proaktywnego wdrażania tagowania analitycznego. Kiedy jednak zdasz sobie sprawę, że możesz odpowiedzieć na 80% swoich potrzeb analitycznych, oznaczając stosunkowo niewielką liczbę punktów danych, argument oszczędności czasu (który i tak jest fałszywy) po prostu wyparowuje.

W dyskusji John narysował ten wspaniały diagram porównujący wysiłek i wartość automatycznego śledzenia z bardziej tradycyjnej implementacji proaktywnego tagowania. Jak widać, rozwiązanie ze śledzeniem automatycznym zaczyna się od większej wartości przy mniejszym wysiłku, ale wkrótce staje się stopniowo coraz mniej wartości na ilość wysiłku. Podczas gdy tradycyjne podejście wymaga początkowo nieco więcej wysiłku i większej wartości na wysiłek w miarę upływu czasu.
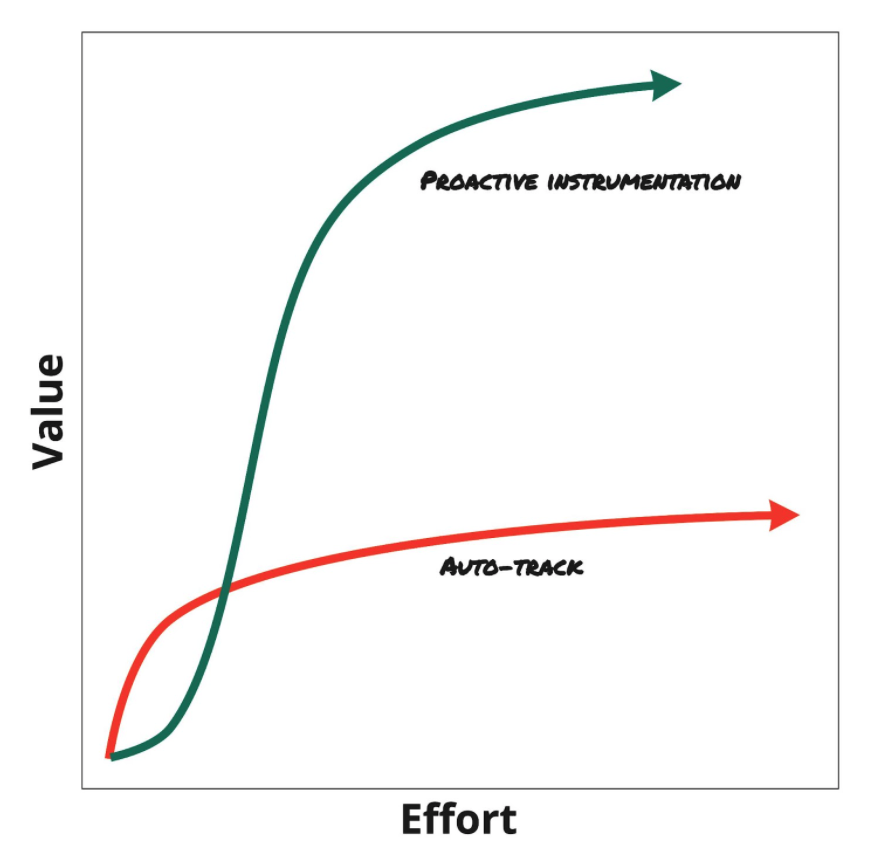
Od dawna opowiadam się za organizacjami, które identyfikują pytania biznesowe, na które chcą odpowiedzieć, i mapują te pytania biznesowe do architektury rozwiązania, zanim nastąpi tagowanie. Uważam, że warto poświęcić czas z góry, aby określić, jakie dane planujesz zbierać i dlaczego, zamiast śledzić dane, a następnie próbować dowiedzieć się, jak można je wykorzystać. Jak większość rzeczy w życiu, dostajesz z tego tyle, ile w to wkładasz. Nie wpadnij więc w pułapkę rozwiązań automatycznego śledzenia i uznaj, że sukces w analityce cyfrowej to maraton, a nie sprint.
A jeśli czegoś zapomniałem?
Oprócz rzekomej oszczędności czasu, kolejnym argumentem, jaki słyszę przemawiający za automatycznym śledzeniem, jest pominięcie lub zapomnienie wymaganych danych. Zwykle wygląda to mniej więcej tak: „Nie ma możliwości przewidzenia wszystkich danych, których będę potrzebować, poprzez zbieranie wymagań, więc potrzebuję rozwiązania do automatycznego śledzenia, aby zebrać wszystkie moje dane na wypadek, gdyby pojawiła się jakaś kwestia biznesowa, która wynika, że nie przewidziałem z góry…”
Oczywiście będą przypadki, w których coś się stanie i brakuje Ci danych, które chciałbyś podjąć w celu podjęcia decyzji biznesowej. Bez względu na to, jak dobry jesteś w zbieraniu wymagań biznesowych, nie możesz przewidzieć każdego zdarzenia i nieruchomości, które będą potrzebne. Ale jeśli cofniesz się myślami do omówionych powyżej elementów Poziomu 0, Poziomu 1 i Poziomu 2, bardzo rzadko zdarza się, że coś, co zostało pominięte, będzie elementem Poziomu 0, który reprezentuje najbardziej krytyczne punkty danych dla Twojej organizacji. Pozycje poziomu 0 powinny być dość oczywiste dla Twojej organizacji. Być może pojawiły się niektóre elementy poziomu 1, które przeoczyłeś, ale jest mało prawdopodobne, że nie będziesz mógł dodać nowych elementów poziomu 1 i poczekać kilka tygodni, aby uzyskać wystarczającą ilość danych, aby odpowiedzieć na Twoje pytanie biznesowe. Jeśli pytanie było tak ważne, że trzeba było na nie odpowiedzieć w ciągu 24 godzin, powinno było pojawić się podczas zbierania wymagań. Pozycje poziomu 2 powinny być jeszcze mniej ważne w ogólnym schemacie rzeczy. Jest prawdopodobne, że wiele z brakujących przedmiotów to przedmioty poziomu 2, ponieważ albo nie są krytyczne, albo reprezentują nowe rzeczy, które nie były obecne podczas zbierania wymagań. W większości przypadków wystarczy dodać kilka nowych tagów i poczekać kilka dni lub tygodni, aby uzyskać brakujące dane.
Kultura
Ostatnią rzeczą, o której chciałbym wspomnieć w temacie auto-tracku, jest obszar kultury korporacyjnej. Jak to często bywa, decyzje dotyczące technologii mówią wiele o kulturze organizacji i zespołach w organizacji. Kiedy widzę zespoły analityków, które przyglądają się rozwiązaniom automatycznego śledzenia, oto kilka myśli, które krążą mi po głowie:
- Dlaczego tak trudno jest im zaplanować wdrożenie z wyprzedzeniem? Czasami pragnienie rozwiązania z automatycznym śledzeniem maskuje fakt, że zespół analityczny tak naprawdę nie wie, czego potrzebuje firma. Być może muszą spędzać więcej czasu ze swoimi wewnętrznymi interesariuszami, zamiast szukać produktu, który pozwoli im na wszelki wypadek śledzić wszystko.
- Dlaczego tak trudno jest im zdobyć zasoby wdrożeniowe? Jeśli zespół analityków wykonuje dobrą robotę, powinien być postrzegany jako krytyczny i strategiczny dla organizacji. Właściwie wykonane analizy pomagają organizacjom zarabiać lub oszczędzać pieniądze, więc dlaczego organizacja nie miałaby poświęcać zasobów na działania wdrożeniowe? Być może rozwiązanie z automatycznym śledzeniem ułatwia zespołowi analityków uniknięcie faktu, że organizacja nie docenia ich pracy.
- Czy nowy produkt analityczny rozwiąże ich problemy? Czasami przejście z jednego rozwiązania analitycznego na inne wydaje się świetnym sposobem, aby wyczyścić plan i zacząć od nowa, ale jeśli Twoja organizacja ma nieodłączne problemy kulturowe, które spowodowały niepowodzenie obecnego rozwiązania, wskazane może być naprawienie tych problemów przed próbą nowy sprzedawca. Niezastosowanie się do tego może spowodować powtórzenie tych samych problemów z nowym narzędziem.
Końcowe przemyślenia
Chociaż mam nadzieję, że ten post jest ostatecznie niepotrzebny, ponieważ organizacje wyciągnęły swoją lekcję na temat produktów z automatycznym śledzeniem, czasami ważne jest, aby przypomnieć sobie rzeczy, których nauczyliśmy się w przeszłości, aby historia się nie powtórzyła. Jeśli Twoja organizacja jest pod presją, aby przyjrzeć się rozwiązaniu z automatycznym śledzeniem, zachęcam do rozważenia potencjalnych problemów poruszonych powyżej, różnych poziomów danych, korzyści z planowania z góry i podstawowych aspektów kulturowych, które mogą decydować o podjęciu decyzji .
