
為您的法學碩士服務排名鋪路
已發表: 2024-01-06隨著人工智慧和 LLM(大型語言模型)的最新發展,我們無法抑制這對人們如何使用搜尋引擎和理解 SEO 的影響。
如果Google最初開發的用於對反向連結和網站價值進行分類的傳統頁面排名模型在1996 年是一個重大突破,那麼除了其他不太重要但仍然影響網站和網站價值的相關因素外,我們對網站進行排名的基礎並沒有太大變化。他們在搜尋引擎上相應的查詢排名。
法學碩士,尤其是一線的 GPT,已經開始挑戰這些傳統模式,為使用者提供搜尋資訊的新方式。 使用 ChatGPT 獲取某些事實或資訊所需的時間和點擊次數顯著減少,而且通常這些資訊更能代表客觀事實,因為 LLM 的本質就是「消耗」大量資訊。
這使得法學碩士非常實用,不僅可以寫詩、編碼和準備旅行行程,而且可以實際提供大量有用的信息「查找」。
讓我們來看一些例子,了解人們如何學習使用 LLM 和 GPT 快速有效地獲得目標問題的答案,以及這對 SEO 的未來意味著什麼。
法學碩士的實踐
我們詢問 ChatGPT“在價格、準確性和客戶服務方面搜尋和比較航班的最可靠的網站是什麼?”

GPT 很好地列出了所有選項,以及每項服務的簡短摘要。 認識到這種方法的效率不僅可以節省時間,而且重要的是還可以繞過評論網站的偏見意見,用戶越來越多地轉向 GPT 來訪問資訊。
由此,我們發現了一個新的資訊優化領域,其中包括(類似於搜尋引擎優化)技術和方法,以了解我們的潛在客戶和用戶正在使用的問題來查找我們的產品或服務正在解決的問題的解決方案。
這個新興學科 - 我們可以稱之為 LLMO(大型語言模型優化) - 專注於優化我們的位置,使這些查詢變得更加相關、可見和排名更高。
在以下部分中,我們將更深入地研究這些GPT 問題與用戶在搜尋引擎中輸入的搜尋查詢有何不同,為什麼我們應該關心它們,以及我們應該如何準備優化,以便利用這項創新來促進我們的業務成長或我們客戶的服務和產品。
為什麼用戶寧願轉向 ChatGPT
這種從使用傳統搜尋引擎到在 ChatGPT 上直接提問的轉變並不是一個新趨勢,而是對其優勢的直接回應。 使用者發現 GPT 回傳的答案更符合他們的要求的一些關鍵原因如下:
- 全面且資訊豐富。 雖然搜尋引擎返回網站鏈接列表,用戶必須手動篩選這些鏈接,但 GPT 能夠生成直接回答其查詢的文本。 這對於那些正在尋找快速而徹底的答案但不一定有時間或能力打開並閱讀首頁結果中的一堆連結的用戶來說特別有幫助。
- 客觀公正。 傳統的搜尋引擎結果可能會受到某些因素的影響,而這些因素可能並非所有人都能獲得,例如他們可以花在購買連結或其他可疑策略上的網站預算來幫助他們排名更高。 另一方面,法學碩士接受海量資料集的培訓,並使用先進的分類和關聯演算法來產生基於事實和證據的答案,而不是基於公司的預算。
- 個性化。 提及對於用戶尋求的答案至關重要的更複雜的個人背景信息,對於傳統搜尋引擎來說並不是一個好兆頭,因為傳統搜尋引擎通常採用一刀切的方法並針對給定的查詢呈現相同的搜尋結果。 GPT 在這方面具有開創性,因為它能夠透過明確的、內容豐富的輸入來理解和適應用戶的偏好和要求,同時又不會侵犯用戶的隱私。
- 動態的。 法學碩士有能力參與多輪對話,鼓勵用戶完善他們的查詢並透過後續問題提供更多背景資訊。 這使他們能夠提出逐步完善的回應,感覺就像是專門為每個用戶量身定制的。
法學碩士如何改變我們的搜尋方式
使用傳統搜尋引擎,使用者已經學會輸入與他們正在尋找的資訊相符的精確關鍵字——這種方法通常需要將查詢分割成多個關鍵字,這通常效率低下,並且可能不會產生期望的結果。
即使將法學碩士整合到搜尋引擎中,特別是為了獲得更大的結果相關性,搜尋引擎仍然在掙扎,而且往往會呈現不相關和不完整的結果。
隨著 GPT 等模型的出現,搜尋過程的新視角正在開放,我們看到從分散的基於關鍵字的方法到更自然和直觀的提問方法的明確轉變。 這項演進與語音搜尋技術的興起同時發生,語音搜尋技術目前佔 Google 行動搜尋查詢的 20%。
與 LLM 的互動(例如 Chat GPT)使用戶能夠積極塑造和指導資訊尋求過程; 更深入地了解他們所需的資訊以及如何有效地闡明他們的問題以獲得所需的結果。
他們不再依賴一串簡單的互不相關的關鍵字,而是學習:
- 以清晰、簡潔的方式表達他們的問題,避免歧義和含糊的語言;
- 提供背景和具體細節,包括相關背景資訊、偏好和情境因素。
人們會問什麼樣的問題?
回顧 GPT 查詢過程,不僅要了解人們為何以及何時向人工智慧尋求答案,還要了解他們如何表達查詢以及從中推斷出哪些其他上下文信息,這一點至關重要。
這種理解構成了新興學科 AEO(答案引擎優化)的核心,該學科專注於這些用戶查詢的模式,並強調直接滿足特定用戶需求的內容的必要性。
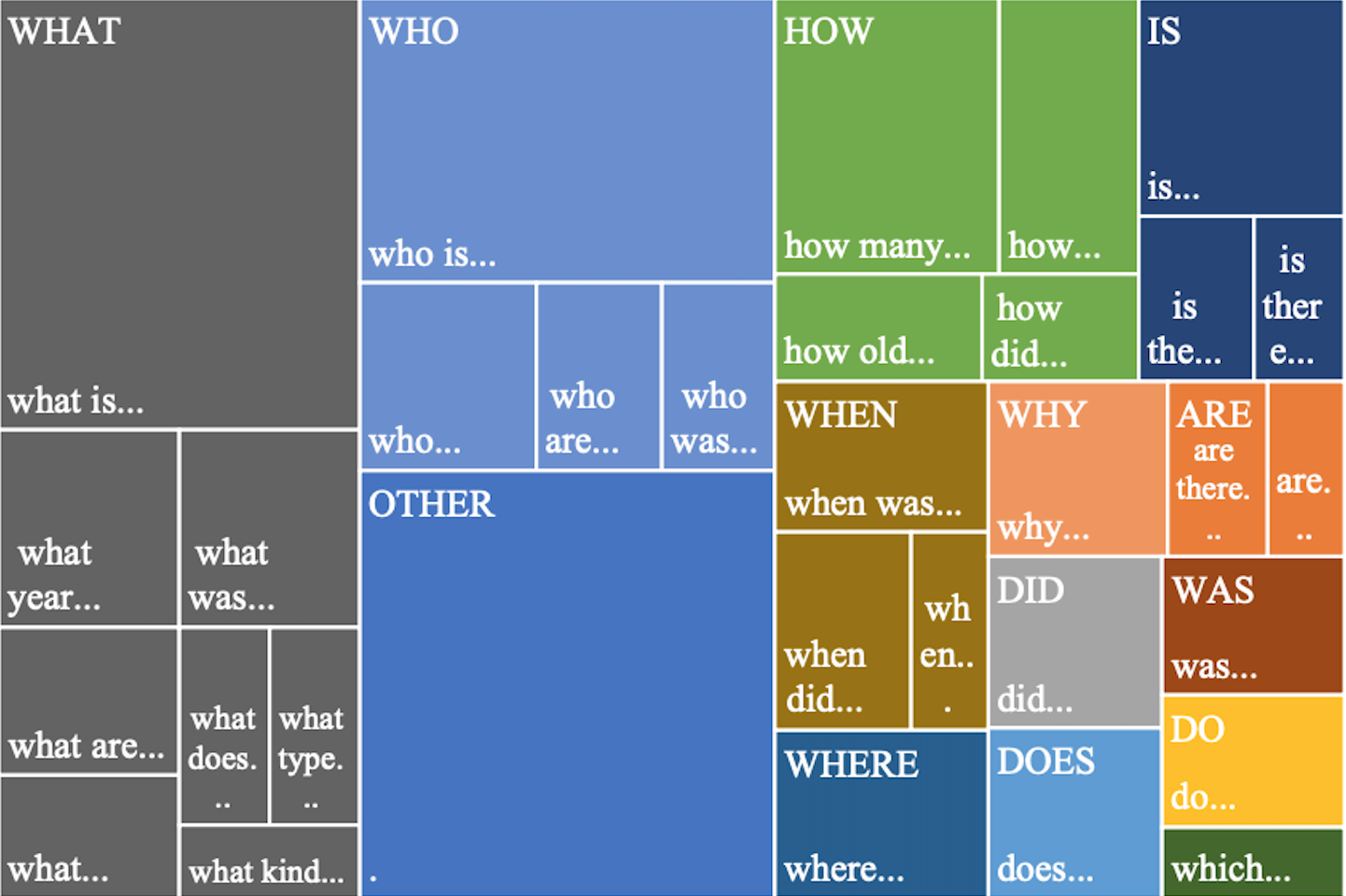
這些問題遵循特定的模式和結構,這對於理解 GPT 優化的嘗試至關重要。 以下是用戶在尋找特定產品或服務時在 ChatGPT 上進行的一些常見查詢措辭:
尋求個人化推薦
使用者經常向 GPT 尋求建議/個人化推薦或專家建議,並提出諸如「什麼是最好的... 」或「你能推荐一些...... 」之類的問題。
價格敏感的查詢
當您想找到最物有所值的方案時,法學碩士是一個很好的諮詢工具。 他們可以提供有關各種場景的定價、折扣和成本效益選項的即時資訊。
問題的措辭大致為「什麼是最便宜的… 」、「什麼是最具成本效益的…」或「我在哪裡可以找到負擔得起的… 」。
特定功能的請求
通常,使用者會詢問服務和產品的特定功能或品質。
例如,他們可能會問“哪種[產品/服務]具有最好的[特定功能]? ”或“您能說出提供[特定功能]的[產品/服務]嗎? ”
比較問題
此類查詢特別適合法學碩士,因為它們可以根據使用者指出的需求和偏好提供不同產品的詳細分析。

他們將問題表述為“ X 比 Y 更好嗎?”、“在[特定功能]方面 X 與 Y 相比如何? ”或“ X 和 Y 之間有什麼區別? ”
基於位置的搜索
法學碩士非常適合包含地理元素的查詢,提供有關附近選項、服務或活動的即時資訊。
問題的措辭類似於“我在哪裡可以購買我附近的 X? ”或“ [位置] 提供的最佳 [服務]是什麼? ”
解決問題的查詢
許多用戶帶著特定的問題來到LLM,詢問“我如何解決X? ”或“處理Y的最佳方法是什麼? ”
這些問題表明他們正在尋找產品或服務作為解決方案。
針對這些見解,建議企業採取主動的內容策略,並專注於創建精確滿足用戶查詢突出的特定需求的材料。 這樣做可以確保產品和服務不僅在搜尋結果中可見,而且可以直接與目標受眾在各種場景中的需求產生共鳴。
聊天GPT排名機制
現在我們已經探討了了解使用者向 GPT 提出的問題的類型和結構的重要性,讓我們看看流程的另一端,看看哪些因素決定了基於解決方案的查詢的排名。 這個基本機制涉及一個全面的非線性過程,其中包括:
語意分析
語義分析過程將單字和短語連接成更大的語義關係,以了解單字在不同上下文中如何組合在一起。
為此,GPT 分析大量文本來映射模式和關聯,這些模式和關聯雖然不是立即顯而易見,但對於掌握查詢的完整含義至關重要。 過程包括:
查詢分析
GPT 進行深入的語義分析,涉及將查詢分解為其元素——單字、短語及其句法關係——然後在它們的集體上下文中進行評估,即。 他們之間的關係如何。
確定使用者意圖
GPT 使用機率方法來確定使用者意圖,分析訓練資料中單字模式的頻率以及它們在特定上下文中的關聯方式。
例如,在有關「預算友善家庭汽車」的查詢中,GPT 認識到「預算友善型」與車輛成本考量之間的相關性,就像「家庭友善」汽車與空間和安全性等屬性相關聯一樣。
結合上下文進行評估
法學碩士考慮到查詢雖然可能包含相似的單詞,但可能具有完全不同的含義和要求,並且它們確定問題的措辭是否表明用戶尋求建議、進行比較或詢問特定功能。 答案是根據潛在的用戶需求量身定制的,無論是預算限制、性能特徵還是品牌偏好。
資料檢索與綜合
除了語義分析的結果之外,ChatGPT 還根據其廣泛的訓練資料集以及即時網路搜尋來評估查詢。
訓練資料集
GPT的資料庫涵蓋廣泛的來源,從學術文章到流行媒體,確保對各個領域的全面了解。 然而,目前尚不清楚訓練集中的具體特徵,也不知道其中包含的來源是根據什麼準則進行的。
網路搜尋
GPT 訓練資料的一個重要面向是其時間限制 - 在撰寫本文時,其時間限制為 2023 年 4 月。為了補充這一點,ChatGPT 的 Pro 版本現在也透過 Bing 提供網路搜尋功能。 這種整合對於經常推出新產品或服務的領域尤其重要。

排名因素
當 GPT 針對查詢對產品或服務進行排名時,它依賴一組排名因素。 這些旨在確保回應不僅相關,而且可信、多樣化和及時。 以下是一些最重要的內容的詳細介紹:
查詢和上下文匹配
GPT 優先考慮直接滿足使用者需求的解決方案。 這種相關性不僅取決於關鍵字頻率,還取決於查詢意圖和與產品或服務相關的資訊之間的匹配深度。
信譽度和知名度
當提及產品或服務時,GPT 會評估來源的可靠性。 這涉及評估各種來源中提及的頻率和上下文,對那些在信譽良好的上下文中經常被引用的內容給予更高的權重。 該模型還考慮了產品的受歡迎程度,如訓練資料中產品的流行程度所示。
使用者回饋分析
GPT對其訓練資料和最近的網路搜尋結果中的回饋和評論進行情緒分析。 具有正面情緒的產品或服務在其排名中受到青睞。
多樣性和覆蓋範圍
在確保多樣性的同時,GPT 保持了平衡,以便為使用者提供與查詢高度相關的廣泛選擇。
新鮮資訊
雖然歷史資料構成了 GPT 知識的支柱,但由於某些查詢可能受益於經過時間考驗的資訊或長期聲譽,它也會考慮新訊息,特別是對於發展迅速的市場。
除此之外,GPT 還會考慮其他因素,儘管程度較小,例如:
個性化和回饋
GPT的反應不是靜態的,每次使用者互動都是模型學習和調整的機會。 當使用者提供更具體的要求或回饋時,GPT 會動態變更其回應。 這個迭代過程使 GPT 能夠動態調整其排名,確保最終的推薦盡可能相關且個人化。
道德和公正的排名
GPT努力在回應中保持客觀立場。 它的設計目的是為了避免付費促銷、廣告或任何不當的外部影響可能產生的偏見。 重點是對數據進行客觀分析,並根據優點和相關性提出建議。
最後的話
毫無疑問:GPT的引入及其後續迭代正在重新定義搜尋引擎優化的參數。 與主要基於反向連結和關鍵字密度的傳統排名模型不同,GPT 提出了一個新的領域,其中預測和理解用戶的上下文和意圖,並主動優化複雜查詢的內容將處於最前沿。
為了有效地做到這一點,不僅要了解使用者輸入和 GPT 排名機制,還要了解產品和服務在各種 LLM 模型中的排名。 那些展望未來的人應該考慮利用專門為追蹤 GPT 排名而定制的高級工具的幫助,以深入了解不同用戶問題的排名位置。

當我們擁抱法學碩士的創新能力並為他們的進步正在進入 SEO 世界做好準備時,重要的是要記住,人工智慧時代仍處於起步階段,並且可能會發生快速變化。
我們希望本指南有助於闡明 GPT 排名機制的一些最重要的方面,這些方面對於理解這些機制至關重要,以便有效地利用這項新興技術。 像往常一樣,請記住隨時了解最新動態並關注更多創新。