
Comparaison de la génération de contenu IA
Publié: 2020-05-29Bien que le contenu de l'IA ne prendra pas le dessus sur Internet de si tôt, je voulais faire l'expérience de première main de ce que c'était que de créer du contenu à l'aide de l'IA. Plus précisément, je voulais voir le type de qualité que je pouvais attendre de la sortie de ces quatre modèles de génération de langage naturel :
- GPT-2
- GROVER
- Première ébauche de MarketMuse
- XLNet
J'ai donc entrepris de créer du contenu, en utilisant ces modèles NLG, sur les sujets suivants :
- Le glucagon comme traitement non invasif du diabète
- dépendance au téléphone
- comment faire pousser des poivrons
- le pouvoir de la narration
- comment devenir travailleur social en toxicomanie
Ensuite, j'ai évalué chaque résultat par rapport à ces critères :
- MarketMuse Content Score (pour déterminer l'exhaustivité du contenu)
- MarketMuse Word Count (MarketMuse analyse tout le contenu concurrentiel pour déterminer comment les experts abordent un sujet donné)
- Score global de grammaire (pour comprendre la quantité d'édition nécessaire pour rendre le contenu publiable)
- Mots uniques (pour mesurer la diversité du vocabulaire)
- Mots rares (pour mesurer la profondeur du vocabulaire)
- Longueur des mots et des phrases (pour évaluer le niveau de complexité)
- Flesch Reading-Ease (pour déterminer si la lisibilité correspondait au public visé)
Notez qu'il ne s'agit pas de références de modélisation du langage sur lesquelles s'appuient les data scientists. Ce sont plutôt des mesures du monde réel qu'un spécialiste du marketing de contenu prendrait en compte lors de l'évaluation d'une soumission, qu'elle soit humaine ou non.
Résumé des résultats
Voici les résultats de l'exécution des cinq sujets à travers quatre modèles de génération de langage naturel, ainsi que quelques commentaires.

Score de contenu MarketMuse
MarketMuse First Draft était le seul modèle capable d'atteindre ou de battre systématiquement le score de contenu cible. Notre modèle est conçu pour générer une sortie thématiquement riche, complète et pertinente.
Les autres modèles ? Apparemment non. Dans un cas, GPT-2 est passé complètement à un autre sujet, après quoi j'ai mis fin à la sortie.
Avez-vous déjà rencontré quelqu'un qui aime beaucoup parler mais qui dit très peu de choses ? Le score de contenu est un moyen de mesurer cela. GROVER, GPT-2 et XLNet sont l'équivalent IA de cette personne !
Nombre de mots
MarketMuse First Draft était le seul modèle NLG capable de générer de manière cohérente un contenu de plus de 1 000 mots. Les autres modèles ont eu du mal à produire quoi que ce soit au-delà de quelques centaines de mots.
Alors que GROVER générerait toujours une sortie complète d'au moins 500+ mots, GPT-2 et XLNet étaient différents. Parfois, XLNet était incapable de générer ne serait-ce que 100 mots. La sortie de GPT-2 et XLNet a été interrompue à des occasions où il y avait un changement radical de sujet ou une répétition excessive. En cas de répétition, j'ai appliqué la règle du « trois prises et vous êtes éliminé ».
Score global grammatical
Le score global de Grammarly est un moyen rapide de déterminer le niveau d'édition requis pour transformer un brouillon en un article soigné prêt à être publié. MarketMuse First Draft et GROVER ont tous deux bien réussi à obtenir une note globale élevée, ce qui signifie que le niveau d'écriture était assez bon avec quelques modifications de base requises. GPT-2 et XLNet ne se sont pas aussi bien comportés, surtout compte tenu de leur faible nombre de mots. La sortie de ces modèles nécessiterait un effort éditorial important pour être présentable.
Mots uniques
GROVER a constamment obtenu les meilleurs résultats dans l'utilisation d'un vocabulaire varié. Malheureusement, cela ne s'est pas traduit par des discussions détaillées sur aucun des sujets, comme le montrent ses faibles scores de contenu.
Mots rares
MarketMuse First Draft a un vocabulaire relativement profond, comme le montre son pourcentage élevé de mots rares dans tous les sujets. Notez que tous les modèles de sujets fonctionnaient en dessous de la moyenne pour tous les utilisateurs de Grammarly en examinant le pourcentage de mots uniques et rares.
Longueur des mots et des phrases
MarketMuse First Draft et GROVER ont tendance à utiliser un vocabulaire avec des mots plus longs que GPT-2 ou XLNet. Dans tous les sujets, MarketMuse First Draft a systématiquement utilisé les phrases les plus courtes. GPT-2, à une seule exception, utilisait des phrases beaucoup plus longues, créant ainsi le besoin potentiel d'un effort éditorial supplémentaire.
Flesch Lecture-Facilité
Flesch Reading-Ease est calculé de manière à ce que le contenu avec des scores plus élevés soit jugé plus facile à lire. Il faut être prudent lors de l'incorporation de cette métrique car plus facile n'est pas nécessairement meilleur. L'application de Flesch Reading-Ease présente de nombreux défis, mais dans ce cas, je cherchais à savoir si la lisibilité était appropriée pour le public visé.
Prenons par exemple le sujet Glucagon en tant que traitement non invasif du diabète. Je m'attendrais à ce que le public de ce sujet ait une formation universitaire et crée du contenu pour ce niveau de lecture. D'autre part, comment faire pousser des poivrons est un sujet approprié pour un public plus large. En tant que tel, le contenu devrait être plus facile à lire. À part quelques rares exceptions, c'est généralement ce qui s'est passé.
Contexte des modèles de génération de langage naturel
Voici quelques informations générales sur les quatre modèles NLG utilisés dans cette étude et pourquoi ils ont été choisis.
Première ébauche de MarketMuse
MarketMuse First Draft (à venir) est un modèle NLG qui produit un contenu long (plus de 1 000 mots) selon un ensemble de spécifications. Il maintient un récit sans modèles ni plagiat tout en se conformant et en validant avec d'autres mesures dans un dossier de contenu associé.
Le résumé du contenu (cliquez pour voir l'exemple) contient tout ce dont un rédacteur a besoin pour créer un article complet, y compris les sous-titres (pour la structure), les questions à poser et les sujets à aborder. Le même brief de contenu est fourni à notre modèle de génération de langage naturel pour créer une première ébauche.
Cette direction explicite donne à MarketMuse First Draft un avantage inhérent par rapport aux autres modèles NLG qui offrent très peu de contrôle, voire aucun. Pense-y de cette façon. Les écrivains humains produisent rarement un travail stellaire sans aucune direction. Pourquoi vous attendez-vous à quelque chose de différent de l'IA ?
Pour cette étude, j'ai réussi à récupérer des échantillons auprès de notre équipe de science des données, à leur insu !
GROVER
GROVER est un modèle NLG populaire publié en 2019 par Allen Institute for AI. Il n'est plus accessible au public, même si c'était le cas lorsque ce message a été initialement écrit en mai 2020.
Ayant reçu pas mal de presse depuis son introduction au public, j'ai pensé que ce serait un bon modèle de comparaison. Ce fut aussi le premier modèle à introduire le conditionnement (contrôle sur les générations). Dans ce cas, vous pouvez donner à votre article des critères sur lesquels écrire (domaine, auteur et titre), donnant ainsi un certain contrôle sur le résultat final.
GPT-2
GPT-2 est sorti par étapes tout au long de 2019 en commençant par leur plus petit modèle. Les principaux organes de presse ont diffusé cette histoire et se sont amusés avec elle. Les articles donnaient l'impression que la sortie GPT-2 était indiscernable de l'écriture humaine.
HuggingFace propose une implémentation publique du modèle que j'ai utilisé pour cette étude. Selon le site, GPT-2 "se présente actuellement comme le modèle le plus cohérent sur le plan syntaxique". Mais honnêtement, je n'ai pas été impressionné par sa sortie.
J'ai opté pour les paramètres par défaut (grande taille de modèle, Top-p 0,9, Température 1, Temps max 1) car je pensais que c'était le pari le plus sûr. Je lui ai fourni un texte de départ sous la forme d'un paragraphe de l'article n°1 sur le Web, selon Google.
La façon dont cela fonctionne est que vous fournissez un extrait de texte (une phrase ou un paragraphe) et il offre jusqu'à trois choix pour l'ensemble de mots suivant (maximum de trois mots). Pour mon test, j'ai toujours sélectionné le premier choix, en supposant que le premier est le meilleur et pour être cohérent.
J'ai trouvé que cette forme de microgestion est très fastidieuse et que le contrôle disponible pour un utilisateur n'est pas très utile. C'est comme essayer de diriger une voiture qui fonce sur l'autoroute en ne regardant que les premiers mètres devant soi.
Un résultat troublant est que le manque de structure d'ordre supérieur peut entraîner un changement de sujet en cours d'article. Une minute, vous parlez de cultiver des poivrons et la suivante, il s'agit de pêches !
XLNet
XLNet est une amélioration du modèle autorégressif de pointe connu sous le nom de TransformerXL et surpasse BERT sur 20 tâches différentes. Comme GPT-2, il est disponible pour un usage public sur HuggingFace. Il adopte également la même approche que GPT-2 sur la question du contrôle et souffre des mêmes problèmes.
Utilisation de ces modèles de génération de langage naturel
À quoi ressemble l'utilisation des modèles NLG ? Voici ce que j'ai trouvé au cours de cette étude. Ils sont organisés par sujet et modèle NLG.
Thème – Le glucagon comme traitement non invasif du diabète
Première ébauche de MarketMuse
Tout d'abord, vous devez créer un résumé de contenu, comme vous le feriez si vous utilisiez un écrivain humain. Une fois que vous êtes satisfait de la synthèse de contenu, vous pouvez demander une première ébauche. Le processus de génération n'est pas automatique. Actuellement, une intervention humaine est nécessaire, ce qui n'est pas surprenant étant donné que le service n'est pas encore accessible au public.

Remarquez les brèves données apparaissant dans la barre latérale de cet exemple ? Telles sont les questions et les sujets pertinents que cette section doit aborder. Ces informations guident le processus NLG pour assurer un résultat favorable. Il a atteint le score de contenu cible de 38.
GROVER
GROVER devait écrire sur l'un des meilleurs domaines dans les résultats pour ce sujet et l'auteur de cet article. L'espoir ici est que la sortie imitera ce style.

J'ai essayé trois fois et j'ai pris la meilleure génération qui avait un score de contenu de 17. Bien que bien meilleur que GPT-2 et XLNet, avec des scores de contenu de 0 et 4, il n'avait rien à voir avec la substance de MarketMuse First Draft. Il manque plusieurs sujets clés dans sa discussion sur le sujet.
GPT-2
J'ai rencontré quelques problèmes en utilisant GPT-2 pour ce sujet.

Seulement quelques centaines de mots dans la génération et il est resté "coincé" faute d'un meilleur terme. Il a continué à me donner un seul choix pour le mot suivant dans l'article.

Il a également mal étiqueté le DT1 (un registre des personnes souffrant de diabète de type 1) comme une maladie. De plus, les quelques centaines de mots qu'il a générés ont donné un score de contenu MarketMuse de zéro.
Il y a peut-être un problème avec le modèle GPT-2 ou la façon dont il est codé. Mais remarquez dans la sortie la phrase "hyp" "oglyce" "mia" ? Cette implémentation du modèle considère l'hypoglycémie comme trois mots différents !

XLNet
Comme GPT-2, XLNet est également resté bloqué après seulement quelques centaines de mots. Il a également subi la colère de la règle des trois coups (répétez quelque chose trois fois et c'est terminé). Il s'en est un peu mieux sorti en termes de score de contenu (4), mais cela ne veut pas dire grand-chose.

XLNet, comme GPT-2, semble avoir un problème similaire. Dans ce cas, hypoglycémique est séparé en trois mots différents.
Sujet – Dépendance au téléphone
Première ébauche de MarketMuse
Voici la section de début de la sortie générée par MarketMuse First Draft.
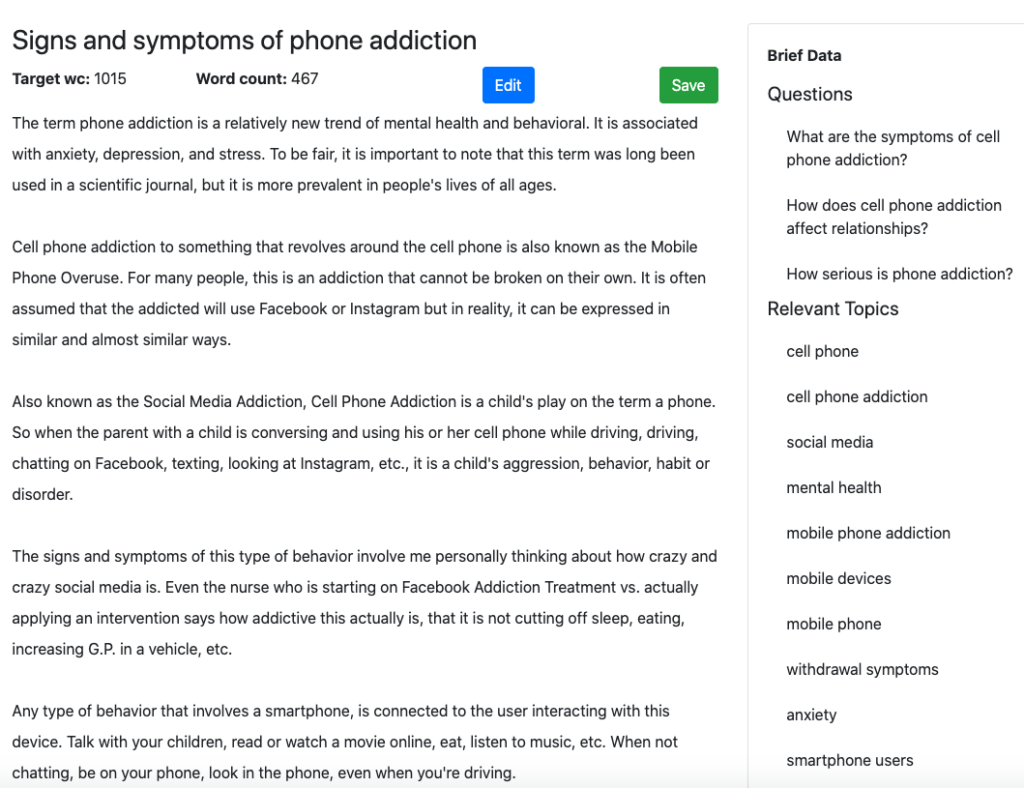
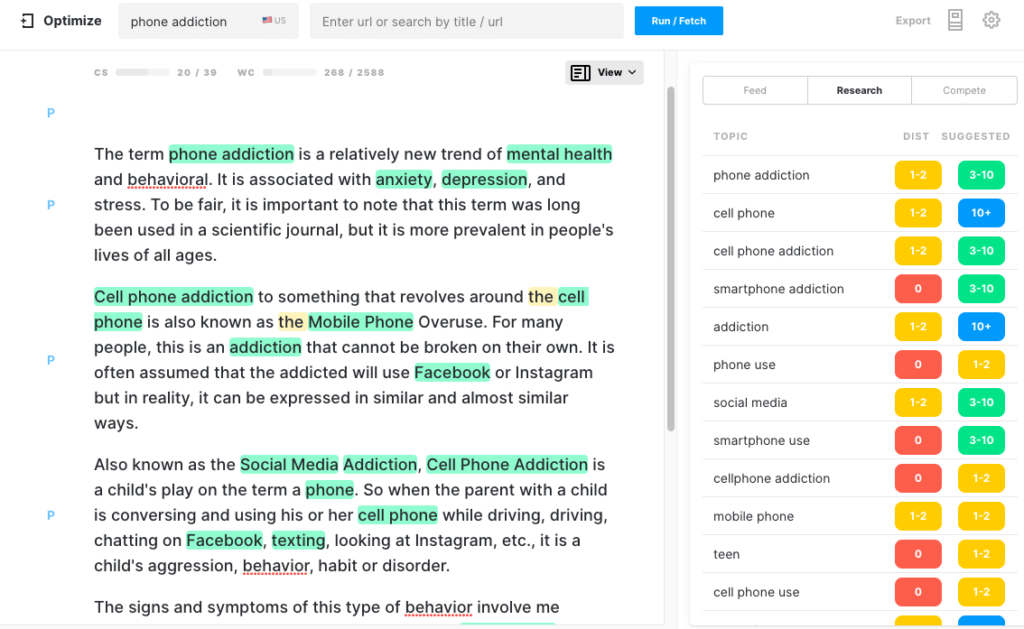
Voici à quoi cela ressemble dans Optimize. Notez qu'il a déjà un score de contenu sain. Chaque sujet mis en surbrillance est celui qui se trouve dans le modèle pour ce sujet.
GROVER
J'ai choisi NYTimes et Nellie Bowels, un auteur qui a déjà écrit sur ce sujet, en espérant que le texte généré serait impressionnant.

Bien qu'il ait atteint cet objectif, il est plutôt vide de sens lorsqu'il s'agit d'exhaustivité. J'ai essayé plusieurs générations, la meilleure étant de 431 mots avec un score de contenu de 7.
GPT-2
J'ai commencé à parler de "dépendance au téléphone" et 500 mots plus tard, le sujet s'est transformé en un examen d'une application capable de contrôler les appareils domestiques intelligents !

À ce stade, l'article avait un score de contenu de 14 avec un score de contenu cible de 39. Comme il était loin de la cible, j'ai laissé la génération continuer. À 1 048 mots, le nombre de mots avait doublé mais le score de contenu avait légèrement augmenté à 18. À 1 474 mots, le score de contenu n'avait toujours pas changé. Pas de surprise là-bas puisque la génération était allée loin du sujet.
XLNet
XLNet a fourni une expérience similaire à GPT-2. Après environ 300 mots, il est resté coincé dans une boucle et s'est répété. Trois coups et vous êtes éliminé !

Sujet - Comment faire pousser des poivrons
Certes, Glucagon est un sujet assez lourd. Après quelque chose comme ça, cultiver des poivrons devrait être une promenade dans le parc. Découvrons-le.
Première ébauche de MarketMuse
Bien que MarketMuse First Draft atteigne toutes les mesures, son style d'écriture, dans ce cas, les feuilles pourrait être meilleur. Curieusement, son score Flesch Reading-Ease élevé indique que cet article est facile à lire.
GROVER
Cette génération a été conçue pour imiter le style d'un auteur populaire de TheSpruce qui a écrit un article similaire qui fonctionne bien dans la recherche. Avec un peu plus de 600 mots, ce n'est certainement pas un traité sur le sujet. Son faible score de contenu le confirme.

GPT-2
Encore une fois, ce modèle de génération de langage naturel a du mal à rester dans le sujet. Environ 400 mots dans la génération et l'article est passé de parler de poivrons à des pêches ! C'est à ce moment-là que j'ai arrêté la génération, car il était peu probable qu'elle fasse marche arrière. Il n'est pas surprenant qu'il ait un score de contenu aussi bas.

XLNet
Il y a très peu de choses que je puisse dire sur la génération de texte fournie par XLNet pour ce sujet. Il s'est bloqué après avoir généré une seule phrase ! Voir par vous-même. Je lui ai donné plus qu'assez de chances de se corriger, après quoi j'ai mis fin à la génération.

Sujet - Le pouvoir de la narration
Première ébauche de MarketMuse
S'il y avait un sujet où l'histoire pouvait aller dans n'importe quel sens, ce serait celui-là. Mais rappelez-vous, MarketMuse First Draft est basé sur un Content Brief très structuré qui est lui-même basé sur l'analyse de tout le contenu concurrentiel sur ce sujet.
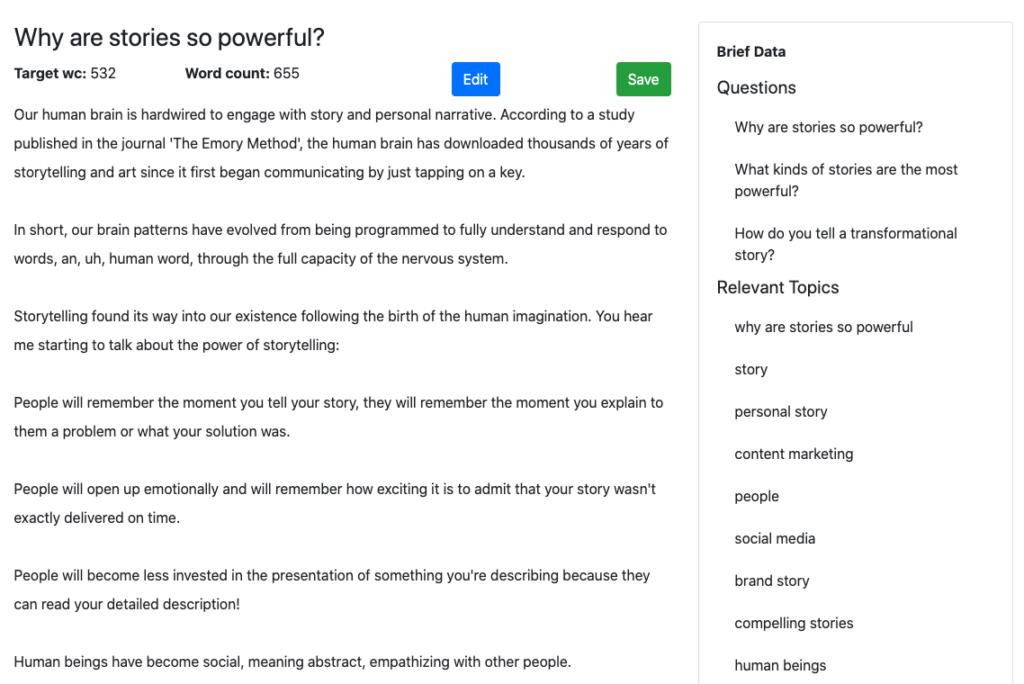
Pour bien vous classer pour ce sujet, il y a des sujets spécifiques que vous devrez couvrir. MarketMuse détermine de quoi il s'agit.
GROVER
GROVER était sur le point d'écrire contre l'un des 10 meilleurs sites Web sur ce sujet, health.org.uk. Une fois de plus, le raisonnement était que l'émulation de cette publication prestigieuse générerait un article crédible.
Le résultat? Pas vraiment.
Ce n'est pas surprenant quand on y pense. Avec si peu de direction, à quoi pouvez-vous vous attendre ?

À 612 mots, c'était une histoire courte et légèrement intéressante. Mais ce n'était pas un article sur le pouvoir des histoires.
GPT-2
Une fois de plus, GPT-2 est resté bloqué en se répétant, j'ai donc mis fin à la génération. La majeure partie de l'article est répétitive, ce qui entraîne des scores faibles pour toutes les mesures.

XLNet
Comme, GPT-2, j'ai fourni à XLNet le premier paragraphe de l'article de haut niveau de health.org.uk sur le même sujet. Le texte en gras est le matériel généré par le modèle de langage. Puisqu'il n'arrêtait pas de répéter la première phrase qu'il avait créée, j'ai mis fin à la génération.

Sujet - Comment devenir un travailleur social en toxicomanie
Première ébauche de MarketMuse
Je pensais que le sujet était suffisamment simple pour que tous les modèles puissent exceller dans la génération de texte approprié. MarketMuse First Draft a l'avantage de la synthèse de contenu pour fournir une structure, des sujets et des questions à aborder. Et les autres ?
GROVER
Alors que GROVER peut inventer une histoire, ce n'est pas toujours aussi informatif. Certes, son score de contenu de 16 dépasse de loin ses rivaux, GPT-2 et XLNet. Cependant, il est loin de celui de MarketMuse First Draft à 36. Son score global grammatical relativement faible de 65 indique qu'il y a une bonne quantité d'édition nécessaire pour le rendre publiable.
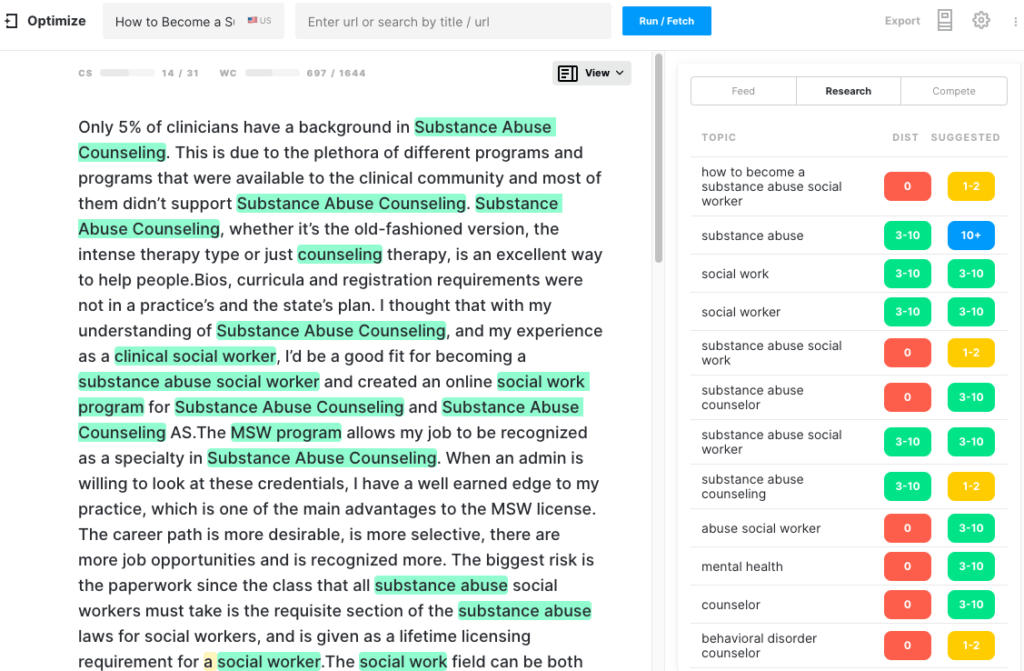
GPT-2
Ce modèle de langage a eu du mal à générer un contenu significatif sur ce sujet. Après les 300 premiers mots, le texte n'a pas affecté le score de contenu, atteignant un maximum de 7 contre un objectif de 31. La qualité du texte a diminué au point où la sortie n'était plus cohérente et la génération a donc été interrompue.
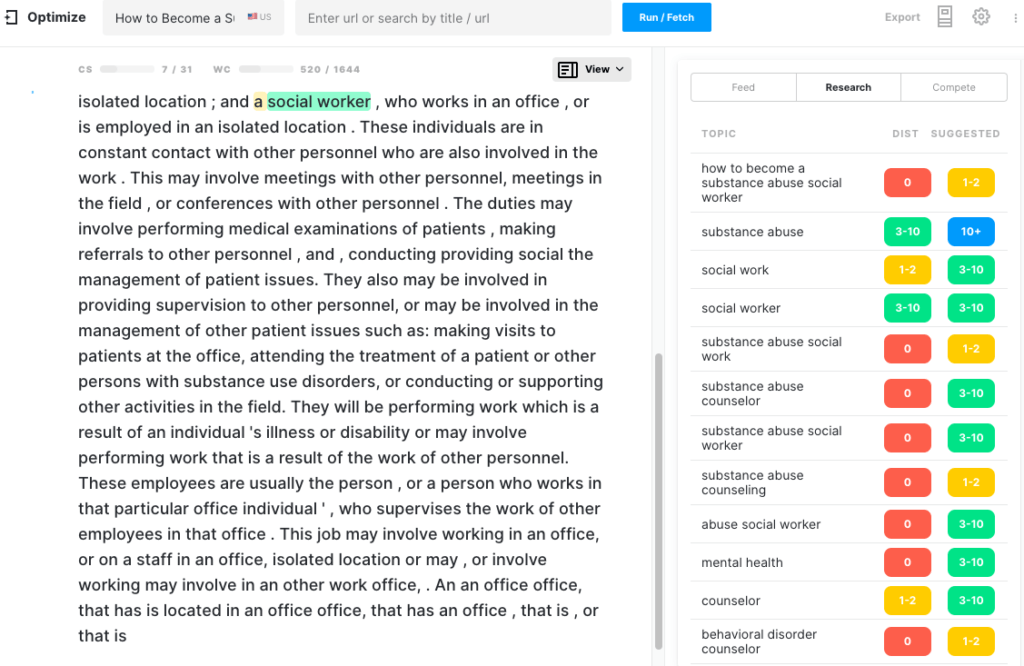
XLNet
XLNet avait le score de contenu le plus bas (5) pour ce sujet par rapport aux quatre modèles de génération de langage. Une fois de plus, son texte de sortie avait le plus petit nombre de mots. Non seulement cela, mais le texte qu'il a créé a rapidement dégénéré en répétition sur laquelle la génération s'est une fois de plus terminée.

Résumé
En 2019, les modèles de génération de langage naturel, GROVER et GPT-2 en particulier, ont reçu beaucoup d'attention. On craignait qu'ils ne soient utilisés à des fins néfastes. La vérité est que ces modèles, contrairement à MarketMuse First Draft, ont du mal à générer un contenu long qui reste sur le sujet et qui est complet. Il est donc difficile pour les spécialistes du marketing de contenu de les utiliser dans n'importe quelle capacité productive.
Il existe une différence fondamentale dans l'approche de la génération du langage naturel entre MarketMuse First Draft et ces modèles. Dans le cas de MarketMuse First Draft, les humains sont étroitement liés au flux de travail et définissent l'ordre du jour de la manière dont l'article est structuré, les sujets à discuter et les questions auxquelles répondre. MarketMuse aide à déterminer ce que ces éléments devraient être, mais s'appuie sur la validation humaine de ces facteurs, avant de générer du contenu. Notre conviction est que, dans la situation actuelle, l'IA fonctionne mieux pour augmenter les écrivains humains.
Ce que tu dois faire maintenant
Lorsque vous êtes prêt… voici 3 façons dont nous pouvons vous aider à publier un meilleur contenu, plus rapidement :
- Réservez du temps avec MarketMuse Planifiez une démonstration en direct avec l'un de nos stratèges pour voir comment MarketMuse peut aider votre équipe à atteindre ses objectifs de contenu.
- Si vous souhaitez apprendre à créer un meilleur contenu plus rapidement, visitez notre blog. Il regorge de ressources pour vous aider à faire évoluer le contenu.
- Si vous connaissez un autre spécialiste du marketing qui aimerait lire cette page, partagez-la avec lui par e-mail, LinkedIn, Twitter ou Facebook.