
Perbandingan Pembuatan Konten AI
Diterbitkan: 2020-05-29Meskipun konten AI tidak akan mengambil alih internet dalam waktu dekat, saya ingin merasakan langsung bagaimana rasanya membuat konten menggunakan AI. Secara khusus, saya ingin melihat jenis kualitas yang dapat saya harapkan dari keluaran empat model generasi bahasa alami ini:
- GPT-2
- GROVER
- Konsep Pertama MarketMuse
- XLNet
Jadi, saya mulai membuat konten, menggunakan model NLG itu, dengan topik berikut:
- Glukagon sebagai pengobatan diabetes non-invasif
- kecanduan telepon
- cara menanam paprika
- kekuatan bercerita
- bagaimana menjadi pekerja sosial penyalahgunaan zat
Kemudian saya mengevaluasi setiap hasil berdasarkan kriteria ini:
- Skor Konten MarketMuse (untuk menentukan seberapa komprehensif kontennya)
- MarketMuse Word Count (MarketMuse menganalisis semua konten kompetitif untuk menentukan bagaimana para ahli membahas topik tertentu)
- Skor Keseluruhan Grammarly (untuk memahami jumlah pengeditan yang diperlukan agar konten dapat diterbitkan)
- Kata-kata unik (untuk mengukur keragaman kosakata)
- Kata-kata langka (untuk mengukur kedalaman kosakata)
- Panjang kata dan kalimat (untuk mengevaluasi tingkat kerumitan)
- Flesch Reading-Ease (untuk menentukan apakah keterbacaan cocok dengan audiens yang dituju)
Perhatikan bahwa ini bukan tolok ukur pemodelan bahasa yang diandalkan oleh para ilmuwan data. Sebaliknya, itu adalah metrik dunia nyata yang akan dipertimbangkan pemasar konten saat mengevaluasi kiriman, baik manusia atau bukan.
Ringkasan Hasil
Berikut adalah hasil menjalankan lima topik melalui empat model generasi bahasa alami, ditambah beberapa komentar.

Skor Konten MarketMuse
MarketMuse First Draft adalah satu-satunya model yang mampu secara konsisten memenuhi atau mengalahkan Skor Konten Target. Model kami dirancang untuk menghasilkan keluaran yang kaya topik, komprehensif, dan sesuai topik.
Model lainnya? Rupanya tidak begitu. Dalam satu kasus GPT-2 beralih ke topik lain sama sekali, setelah itu saya menghentikan output.
Pernahkah Anda bertemu seseorang yang suka banyak bicara tetapi tidak banyak bicara? Skor Konten adalah cara untuk mengukurnya. GROVER, GPT-2, dan XLNet adalah AI yang setara dengan orang itu!
Jumlah kata
MarketMuse First Draft adalah satu-satunya model NLG yang mampu secara konsisten menghasilkan konten sepanjang 1.000+ kata. Model-model lain berjuang untuk menghasilkan sesuatu di luar beberapa ratus kata.
Sementara GROVER akan selalu menghasilkan output lengkap setidaknya 500+ kata, GPT-2 dan XLNet berbeda. Kadang-kadang XLNet tidak mampu menghasilkan bahkan 100 kata. Keluaran GPT-2 dan XLNet dihentikan pada saat terjadi perubahan topik yang dramatis atau pengulangan yang berlebihan. Dalam hal pengulangan, saya menerapkan aturan 'tiga pukulan dan Anda keluar'.
Skor Keseluruhan Tata Bahasa
Skor Keseluruhan Grammarly adalah cara cepat untuk menentukan tingkat pengeditan yang diperlukan untuk mengubah draf menjadi artikel yang dipoles agar sesuai untuk dipublikasikan. Baik MarketMuse First Draft dan GROVER cukup baik dalam mencapai Skor Keseluruhan yang tinggi, yang berarti standar penulisan cukup baik dengan beberapa pengeditan dasar yang diperlukan. GPT-2 dan XLNet tidak berjalan dengan baik, terutama mengingat jumlah kata yang rendah. Keluaran dari model-model ini akan membutuhkan upaya editorial yang signifikan agar dapat ditampilkan.
Kata-kata Unik
GROVER secara konsisten melakukan yang terbaik dalam menggunakan kosakata yang bervariasi. Sayangnya, itu tidak diterjemahkan ke dalam diskusi terperinci tentang topik apa pun, seperti yang ditunjukkan oleh Skor Kontennya yang rendah.
Kata-kata Langka
MarketMuse First Draft memiliki kosakata yang relatif dalam, seperti yang ditunjukkan oleh persentase kata langka yang tinggi di semua topik. Perhatikan bahwa semua model topik beroperasi di bawah rata-rata untuk semua pengguna Grammarly saat melihat persentase kata unik dan langka.
Panjang Kata dan Kalimat
MarketMuse First Draft dan GROVER cenderung menggunakan kosakata dengan kata yang lebih panjang daripada GPT-2 atau XLNet. Di semua topik, MarketMuse First Draft secara konsisten menggunakan kalimat terpendek. GPT-2, dengan hanya satu pengecualian, menggunakan kalimat yang jauh lebih panjang sehingga menciptakan potensi kebutuhan untuk upaya editorial tambahan.
Flesch Membaca-Kemudahan
Flesch Reading-Ease dihitung sedemikian rupa sehingga konten dengan skor lebih tinggi dianggap lebih mudah dibaca. Seseorang perlu berhati-hati saat memasukkan metrik ini karena lebih mudah belum tentu lebih baik. Ada banyak tantangan dengan menerapkan Flesch Reading-Ease tetapi dalam kasus ini, saya mencari untuk melihat apakah keterbacaan sesuai untuk audiens yang dituju.
Ambil contoh topik Glukagon sebagai pengobatan diabetes non-invasif. Saya berharap audiens untuk topik ini memiliki pendidikan tinggi dan membuat konten untuk tingkat membaca itu. Di sisi lain, cara menanam paprika adalah topik yang cocok untuk khalayak yang lebih luas. Dengan demikian, konten harus lebih mudah dibaca. Selain beberapa pengecualian aneh, ini umumnya yang terjadi.
Latar Belakang Model Generasi Bahasa Alami
Berikut adalah beberapa informasi latar belakang tentang empat model NLG yang digunakan dalam penelitian ini dan mengapa mereka dipilih.
Konsep Pertama MarketMuse
MarketMuse First Draft (segera hadir) adalah model NLG yang menghasilkan konten bentuk panjang (1.000+ kata) ke serangkaian spesifikasi. Ini mempertahankan narasi tanpa template atau plagiarisme sambil mematuhi dan memvalidasi metrik lain dalam ringkasan konten terkait.
Isi singkat (klik untuk melihat contoh) berisi semua yang dibutuhkan penulis untuk membuat artikel yang komprehensif termasuk subjudul (untuk struktur), pertanyaan untuk diajukan, dan topik untuk ditangani. Ringkasan konten yang sama disediakan untuk model generasi bahasa alami kami untuk membuat draf pertama.
Arahan eksplisit ini memberi MarketMuse First Draft keunggulan inheren dibandingkan model NLG lain yang menawarkan kontrol yang sangat sedikit jika ada. Pikirkan seperti ini. Penulis manusia jarang menghasilkan karya bintang tanpa arah. Mengapa Anda mengharapkan sesuatu yang berbeda dari AI?
Untuk penelitian ini, saya berhasil mengambil beberapa sampel dari tim ilmu data kami, tanpa sepengetahuan mereka!
GROVER
GROVER adalah model NLG populer yang dirilis pada tahun 2019 oleh Allen Institute for AI. Itu tidak lagi dapat diakses publik, meskipun saat posting ini awalnya ditulis pada Mei 2020.
Setelah menerima cukup banyak pers sejak diperkenalkan ke publik, saya merasa ini akan menjadi model yang baik untuk dibandingkan. Itu juga merupakan model pertama yang memperkenalkan pengkondisian (kontrol atas generasi). Dalam hal ini, Anda dapat memberikan kriteria artikel Anda untuk menulis (domain, penulis, dan judul) sehingga memberikan beberapa kontrol atas hasil akhir.
GPT-2
GPT-2 dirilis secara bertahap sepanjang tahun 2019 dimulai dari model terkecilnya. Outlet berita utama menjalankan dengan cerita ini dan memiliki hari lapangan dengan itu. Artikel-artikel tersebut membuatnya seolah-olah keluaran GPT-2 tidak dapat dibedakan dari tulisan manusia.
HuggingFace menawarkan implementasi model yang saya gunakan untuk penelitian ini. Menurut situs tersebut, GPT-2 “saat ini berdiri sebagai model yang paling koheren secara sintaksis.” Tapi jujur, saya tidak terkesan dengan outputnya.
Saya menggunakan pengaturan default (ukuran model besar, Top-p 0.9, Suhu 1, Waktu maksimum 1) karena saya pikir itu adalah taruhan teraman. Saya menyediakannya dengan teks awal dalam bentuk paragraf dari artikel #1 di web, menurut Google.
Cara kerjanya adalah Anda memberikan potongan teks (kalimat atau paragraf) dan menawarkan hingga tiga pilihan untuk rangkaian kata berikutnya (maksimal tiga kata). Untuk tes saya, saya selalu memilih pilihan pertama, dengan asumsi bahwa yang pertama adalah yang terbaik dan konsisten.
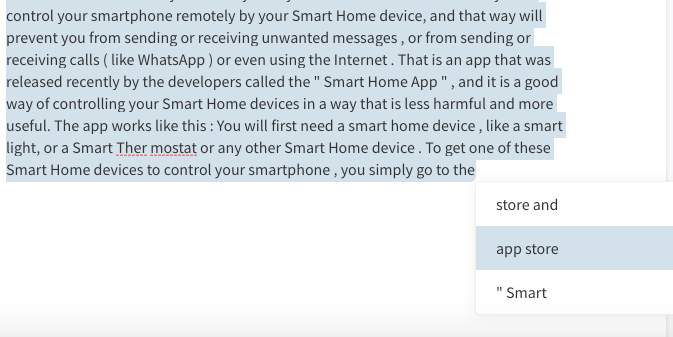
Saya menemukan bentuk pengelolaan mikro ini sangat membosankan dan kontrol yang tersedia untuk pengguna tidak terlalu membantu. Ini seperti mencoba mengarahkan mobil yang melaju kencang di jalan raya dengan hanya melihat beberapa kaki pertama di depan.
Salah satu hasil yang mengganggu adalah bahwa kurangnya struktur tingkat tinggi dapat mengakibatkan perubahan materi pelajaran di tengah artikel. Satu menit Anda berbicara tentang menanam paprika dan menit berikutnya tentang buah persik!
XLNet
XLNet adalah peningkatan dari model autoregresif canggih yang dikenal sebagai TransformerXL dan mengungguli BERT pada 20 tugas berbeda. Seperti GPT-2, ini tersedia untuk penggunaan umum di HuggingFace. Ini juga mengambil pendekatan yang sama seperti GPT-2 pada masalah kontrol dan menderita masalah yang sama.
Menggunakan Model Generasi Bahasa Alami Ini
Bagaimana rasanya menggunakan model NLG? Inilah yang saya temukan saat saya mengerjakan penelitian ini. Mereka diatur berdasarkan topik dan model NLG.
Topik – Glukagon sebagai pengobatan diabetes non-invasif
Konsep Pertama MarketMuse
Pertama, Anda perlu membuat Ringkasan Konten, seperti yang Anda lakukan jika Anda menggunakan penulis manusia. Setelah Anda puas dengan Ringkasan Konten, Anda dapat meminta Draf Pertama. Proses pembuatannya tidak otomatis. Saat ini, beberapa intervensi manusia diperlukan, yang tidak mengherankan mengingat layanan tersebut belum tersedia untuk umum.

Perhatikan data singkat yang muncul di sidebar contoh ini? Ini adalah pertanyaan dan topik relevan yang perlu ditangani bagian ini. Informasi ini memandu proses NLG untuk memastikan hasil yang menguntungkan. Itu memenuhi Target Skor Konten 38.
GROVER
GROVER diatur untuk menulis terhadap salah satu domain teratas dalam hasil untuk topik ini dan penulis artikel itu. Harapannya di sini adalah output akan meniru gaya itu.

Saya mencoba tiga kali dan mengambil generasi terbaik yang memiliki Skor Konten 17. Meskipun jauh lebih baik daripada GPT-2 dan XLNet, dengan Skor Konten 0 dan 4, itu sama sekali tidak mendekati substansi MarketMuse First Draft. Ada beberapa topik kunci yang hilang dalam pembahasannya tentang subjek tersebut.
GPT-2
Saya mengalami beberapa masalah menggunakan GPT-2 untuk topik ini.

Hanya beberapa ratus kata ke dalam generasi dan itu menjadi "macet" karena tidak ada istilah yang lebih baik. Itu terus memberi saya hanya satu pilihan untuk kata berikutnya dalam artikel.

Itu juga salah memberi label T1D (daftar orang yang menderita diabetes tipe 1) sebagai penyakit. Plus, beberapa ratus kata yang dihasilkannya menghasilkan Skor Konten MarketMuse nol.
Mungkin ada masalah dengan model GPT-2 atau cara pengkodeannya. Tapi perhatikan di output frasa "hyp" "oglyce" "mia"? Implementasi model ini menganggap hipoglikemia sebagai tiga kata yang berbeda!

XLNet
Seperti GPT-2, XLNet juga macet hanya setelah beberapa ratus kata. Itu juga menderita murka aturan tiga pukulan (ulangi sesuatu tiga kali dan itu dihentikan). Ini bernasib sedikit lebih baik dalam hal Skor Konten (4), tetapi itu tidak banyak berarti.

XLNet, seperti GPT-2, tampaknya memiliki masalah serupa. Dalam hal ini, hipoglikemik dipisahkan menjadi tiga kata yang berbeda.
Topik – Kecanduan telepon
Konsep Pertama MarketMuse
Inilah bagian awal dari output yang dihasilkan oleh MarketMuse First Draft.
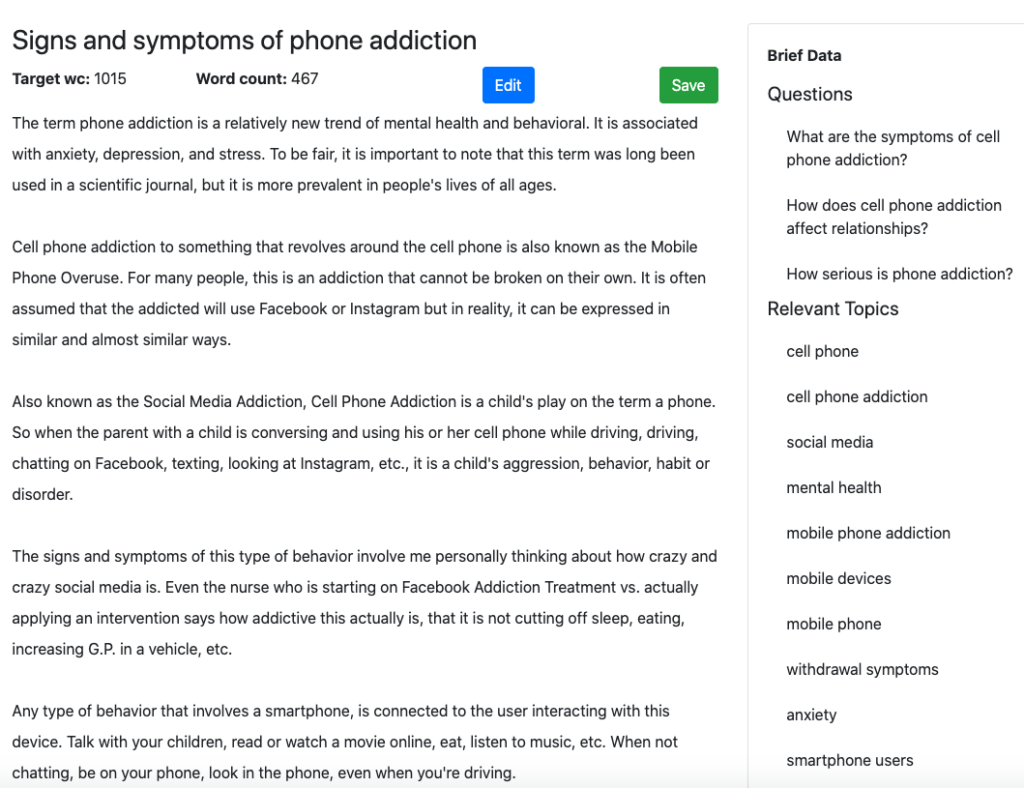
Berikut tampilannya saat di Optimize. Perhatikan bahwa itu sudah memiliki skor konten yang sehat. Setiap topik yang disorot adalah topik yang ditemukan dalam model untuk topik tersebut.
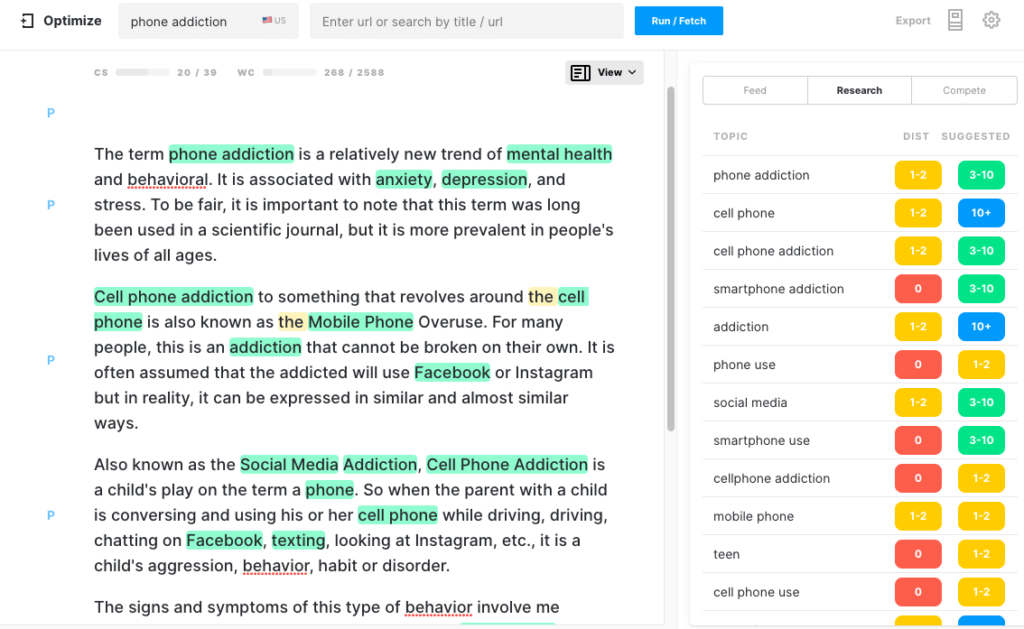
GROVER
Saya memilih NYTimes dan Nellie Bowels, seorang penulis yang telah menulis tentang topik ini sebelumnya, berharap teks yang dihasilkan akan terlihat mengesankan.

Sementara itu mencapai tujuan itu, itu agak hampa dalam hal kelengkapan. Saya mencoba beberapa generasi dengan yang terbaik adalah 431 kata dengan Skor Konten 7.
GPT-2
Mulai berbicara tentang "kecanduan telepon" dan 500 kata kemudian topik telah berubah menjadi ulasan aplikasi yang dapat mengontrol perangkat rumah pintar!

Pada titik ini, artikel memiliki Skor Konten 14 dengan Skor Konten Target 39. Karena jauh dari target, saya membiarkan generasi melanjutkan. Pada 1.048 kata, jumlah kata meningkat dua kali lipat tetapi Skor Konten sedikit meningkat menjadi 18. Pada 1.474 kata, skor konten masih belum berubah. Tidak mengherankan di sana karena generasi telah keluar dari topik.
XLNet
XLNet memberikan pengalaman yang mirip dengan GPT-2. Setelah sekitar 300 kata, itu macet dalam satu lingkaran dan berulang. Tiga pemogokan dan Anda keluar!

Topik – Cara Menanam Paprika
Harus diakui, Glukagon adalah topik yang cukup berat. Setelah sesuatu seperti itu, menanam paprika seharusnya berjalan-jalan di taman. Mari kita cari tahu.
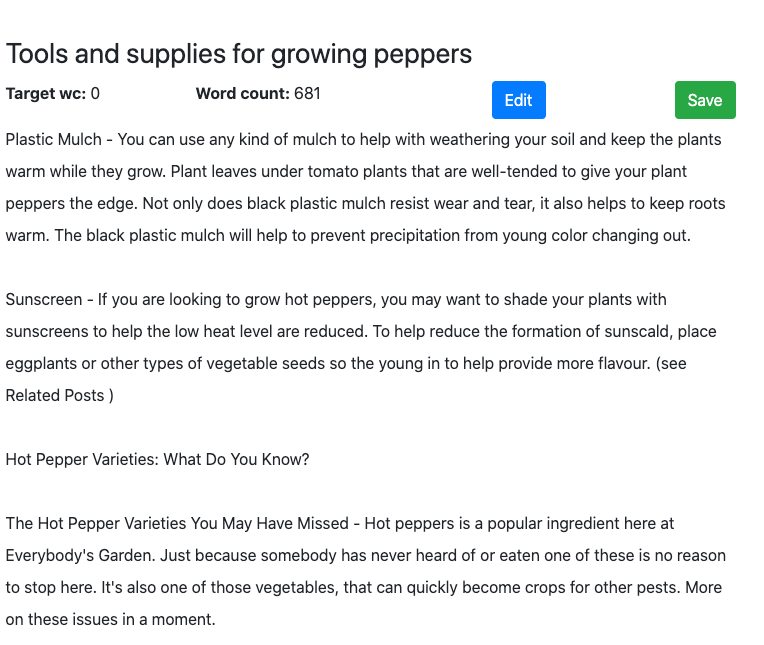
Konsep Pertama MarketMuse
Meskipun MarketMuse First Draft mencapai semua metrik, gaya penulisannya, dalam hal ini, daun bisa lebih baik. Anehnya, skor Flesch Reading-Ease yang tinggi menunjukkan bahwa artikel ini mudah dibaca.
GROVER
Generasi ini dibuat untuk meniru gaya penulis populer dari TheSpruce yang menulis artikel serupa yang berkinerja baik di Penelusuran. Dengan sedikit lebih dari 600 kata, itu tentu saja tidak memenuhi syarat sebagai risalah tentang masalah ini. Skor Konten yang rendah menegaskan hal ini.

GPT-2
Sekali lagi, model generasi bahasa alami ini mengalami kesulitan untuk tetap pada topik. Kira-kira 400 kata ke dalam generasi dan artikel telah bergeser dari berbicara tentang paprika ke buah persik! Pada titik inilah saya menghentikan generasi, karena tidak mungkin untuk membalikkan arah. Tidak mengherankan bahwa ia memiliki Skor Konten yang rendah.

XLNet
Sangat sedikit yang bisa saya katakan tentang pembuatan teks yang disediakan XLNet untuk topik ini. Itu macet setelah hanya menghasilkan satu kalimat! Lihat diri mu sendiri. Saya memberikannya lebih dari cukup kesempatan untuk memperbaiki dirinya sendiri setelah itu saya menghentikan generasi.

Topik – Kekuatan Mendongeng
Konsep Pertama MarketMuse
Jika ada topik di mana cerita bisa mengarah ke mana saja, ini dia. Tapi ingat, Konsep Pertama MarketMuse didasarkan pada Ringkasan Konten yang sangat terstruktur yang didasarkan pada analisis semua konten kompetitif tentang subjek itu.
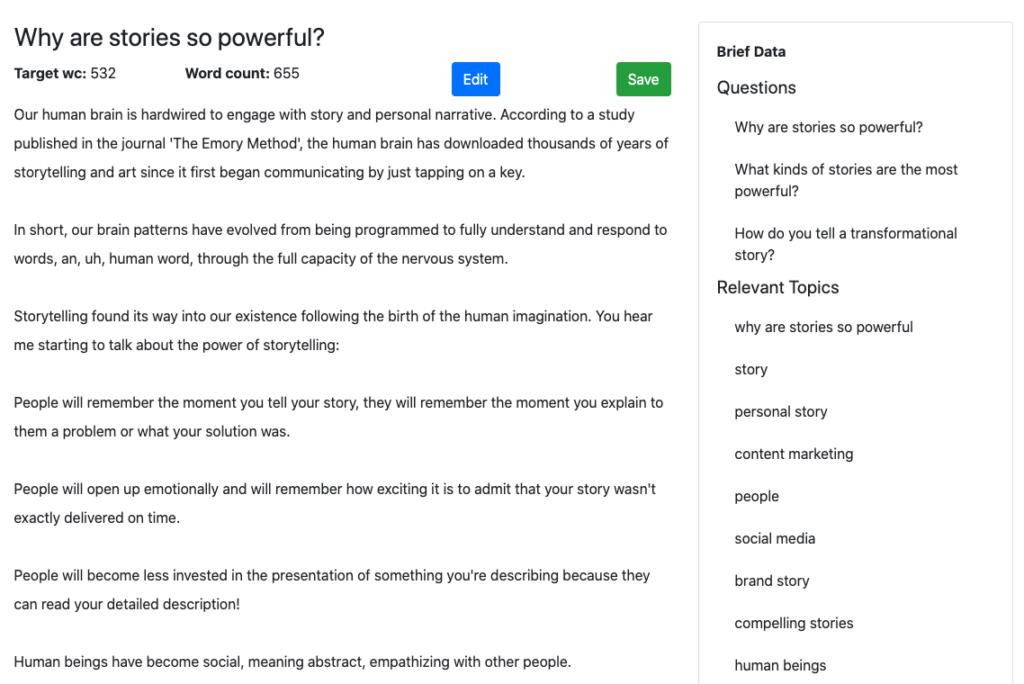
Untuk mendapatkan peringkat yang baik untuk subjek ini, ada topik khusus yang harus Anda bahas. MarketMuse menentukan apa itu.
GROVER
GROVER diatur untuk menulis melawan salah satu dari 10 situs web teratas tentang topik ini, health.org.uk. Sekali lagi alasannya adalah meniru publikasi bergengsi ini akan menghasilkan artikel yang kredibel.
Hasil? Tidak juga.
Itu tidak mengejutkan ketika Anda memikirkannya. Dengan sedikit arahan, apa yang bisa Anda harapkan?

Dengan 612 kata, itu adalah cerita yang pendek dan agak menarik. Tapi itu bukan artikel tentang kekuatan cerita.
GPT-2
Sekali lagi, GPT-2 macet berulang, jadi saya mengakhiri generasi. Sebagian besar artikel berulang, menghasilkan skor rendah di semua metrik.

XLNet
Seperti, GPT-2, saya memberi XLNet paragraf pertama dari artikel health.org.uk tingkat tinggi tentang subjek yang sama. Teks tebal adalah materi yang dihasilkan oleh model bahasa. Karena terus mengulangi kalimat pertama yang dibuatnya, saya mengakhiri generasi.

Topik – Bagaimana Menjadi Pekerja Sosial Penyalahgunaan Narkoba
Konsep Pertama MarketMuse
Saya pikir topiknya cukup lugas sehingga semua model dapat unggul dalam menghasilkan teks yang sesuai. Draf Pertama MarketMuse memiliki keunggulan Ringkasan Konten untuk menyediakan struktur, topik, dan pertanyaan untuk ditangani. Bagaimana dengan yang lainnya?
GROVER
Meskipun GROVER bisa mengarang cerita, itu tidak selalu informatif. Memang, Skor Kontennya 16 jauh melebihi para pesaingnya, GPT-2 dan XLNet. Namun, itu tidak jauh dari MarketMuse First Draft di 36. Grammarly Overall Score 65 yang relatif rendah menunjukkan ada cukup banyak pengeditan yang diperlukan untuk membuatnya dapat diterbitkan.
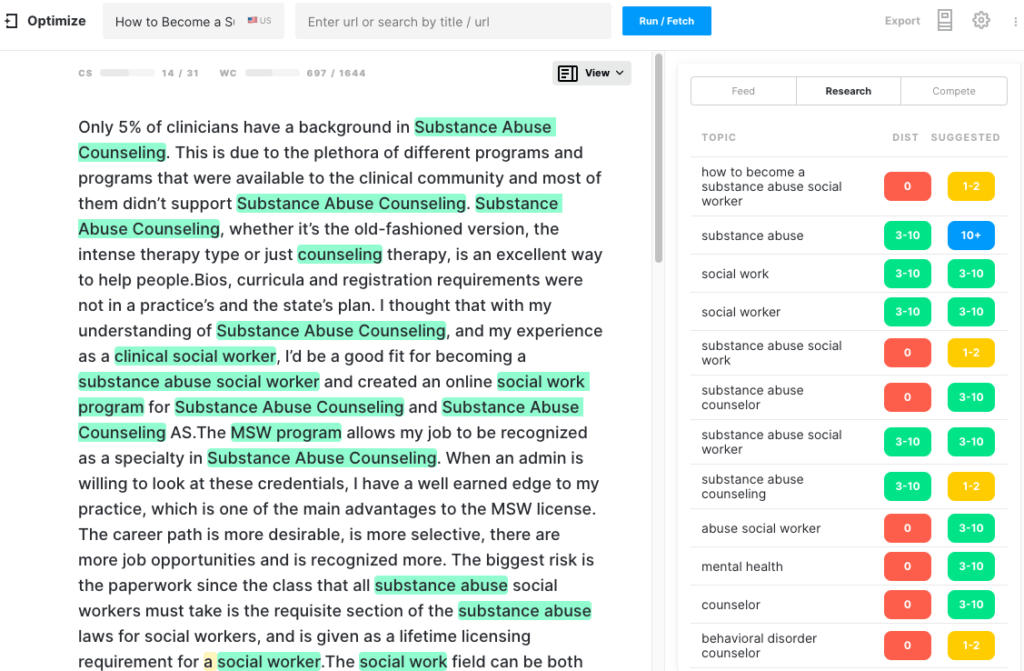
GPT-2
Model bahasa ini berjuang untuk menghasilkan konten yang bermakna tentang topik ini. Setelah 300 kata pertama, teks tidak memengaruhi Skor Konten, mencapai maksimum 7 dibandingkan target 31. Kualitas teks menurun ke titik di mana output tidak lagi koheren sehingga pembuatan dihentikan.
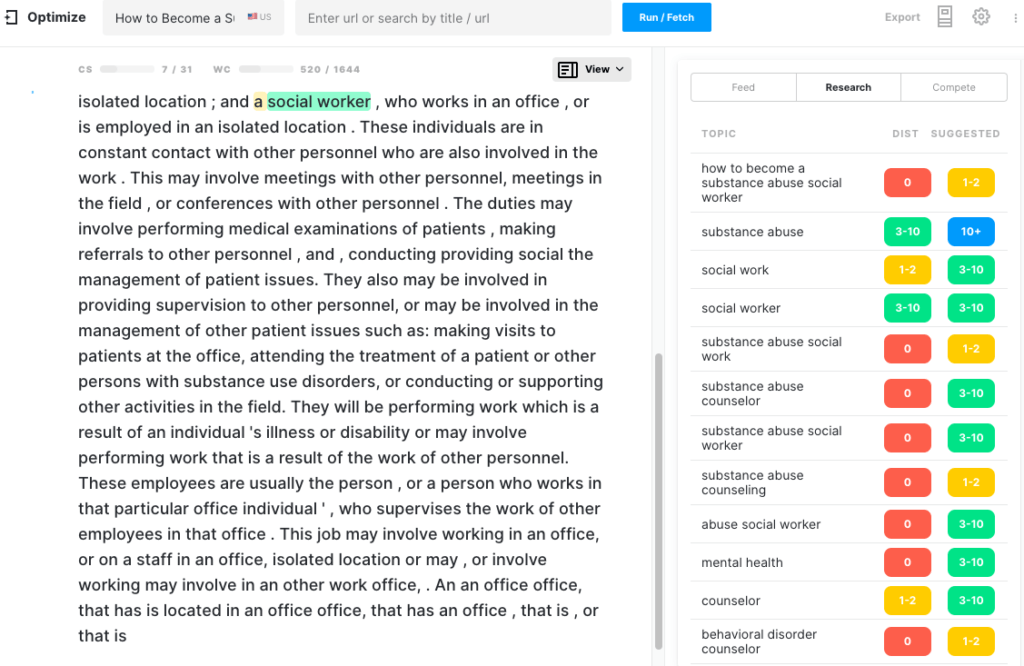
XLNet
XLNet memiliki Skor Konten terendah (5) untuk topik ini jika dibandingkan dengan keempat model generasi bahasa. Sekali lagi teks keluarannya memiliki jumlah kata terkecil. Bukan hanya itu, tetapi teks yang dibuatnya dengan cepat berubah menjadi pengulangan di mana generasi itu sekali lagi dihentikan.

Ringkasan
Pada tahun 2019, model generasi bahasa alami, khususnya GROVER dan GPT-2, mendapat banyak perhatian. Ada ketakutan bahwa mereka dapat digunakan untuk tujuan jahat. Yang benar adalah bahwa model ini, tidak seperti MarketMuse First Draft, berjuang untuk menghasilkan konten bentuk panjang yang tetap pada topik dan komprehensif. Ini menyulitkan pemasar konten untuk menggunakannya dalam kapasitas produktif apa pun.
Ada perbedaan mendasar dalam pendekatan generasi bahasa alami antara MarketMuse First Draft dan model ini. Dalam kasus MarketMuse First Draft, manusia terjalin erat ke dalam alur kerja dan mengatur agenda tentang bagaimana artikel disusun, topik untuk didiskusikan, dan pertanyaan untuk dijawab. MarketMuse membantu dalam menentukan item apa yang seharusnya, tetapi bergantung pada validasi manusia dari faktor-faktor ini, sebelum menghasilkan konten. Keyakinan kami adalah bahwa, dalam situasi saat ini, AI bekerja paling baik untuk menambah penulis manusia.
Apa yang harus kamu lakukan sekarang?
Saat Anda siap… berikut adalah 3 cara kami dapat membantu Anda memublikasikan konten yang lebih baik, lebih cepat:
- Pesan waktu dengan MarketMuse Jadwalkan demo langsung dengan salah satu ahli strategi kami untuk melihat bagaimana MarketMuse dapat membantu tim Anda mencapai sasaran konten mereka.
- Jika Anda ingin mempelajari cara membuat konten yang lebih baik dengan lebih cepat, kunjungi blog kami. Ini penuh dengan sumber daya untuk membantu menskalakan konten.
- Jika Anda mengenal pemasar lain yang senang membaca halaman ini, bagikan dengan mereka melalui email, LinkedIn, Twitter, atau Facebook.