
Сравнение генерации контента ИИ
Опубликовано: 2020-05-29Хотя ИИ-контент в ближайшее время не захватит Интернет, я хотел на собственном опыте узнать, каково это — создавать контент с помощью ИИ. В частности, я хотел увидеть тип качества, который я мог бы ожидать от вывода этих четырех моделей генерации естественного языка:
- ГПТ-2
- ГРУВЕР
- Первый проект MarketMuse
- XLNet
Итак, я решил создать контент, используя эти модели NLG, по следующим темам:
- Глюкагон как неинвазивный метод лечения диабета
- телефонная зависимость
- как вырастить перец
- сила рассказывания историй
- как стать социальным работником по борьбе с наркозависимостью
Затем я оценил каждый результат по следующим критериям:
- MarketMuse Content Score (для определения полноты содержания)
- MarketMuse Word Count (MarketMuse анализирует весь конкурентный контент, чтобы определить, как эксперты подходят к данной теме)
- Общий балл по грамматике (чтобы понять, какой объем редактирования требуется для публикации контента)
- Уникальные слова (для измерения разнообразия словарного запаса)
- Редкие слова (для измерения глубины словарного запаса)
- Длина слова и предложения (для оценки уровня сложности)
- Flesch Reading-Ease (чтобы определить, соответствует ли читабельность предполагаемой аудитории)
Обратите внимание, что это не тест языкового моделирования, на который полагаются специалисты по данным. Скорее, это реальные метрики, которые контент-маркетолог будет учитывать при оценке заявки, будь то человек или нет.
Сводка результатов
Вот результаты прохождения пяти тем по четырем моделям генерации естественного языка, а также некоторые комментарии.

Оценка содержания MarketMuse
MarketMuse First Draft была единственной моделью, которая могла постоянно соответствовать или превосходить Target Content Score. Наша модель предназначена для создания результатов, которые являются тематически богатыми, всеобъемлющими и актуальными.
Другие модели? Видимо не так. В одном случае ГПТ-2 вообще переключился на другую тему, после чего я прекратил выпуск.
Вы когда-нибудь встречали человека, который любит много говорить, но говорит очень мало по существу? Content Score — это способ измерить это. GROVER, GPT-2 и XLNet — это искусственный эквивалент этого человека!
Количество слов
MarketMuse First Draft была единственной моделью NLG, способной последовательно генерировать контент длиной более 1000 слов. Другие модели изо всех сил пытались создать что-то большее, чем несколько сотен слов.
В то время как GROVER всегда генерировал полный вывод не менее 500+ слов, GPT-2 и XLNet отличались друг от друга. Иногда XLNet не мог сгенерировать даже 100 слов. Вывод GPT-2 и XLNet прекращался в тех случаях, когда происходил резкий сдвиг темы или чрезмерное повторение. В случае повторения я применил правило «три удара и ты выбыл».
Общий балл по грамматике
Общий балл Grammarly — это быстрый способ определить уровень редактирования, необходимый для превращения черновика в отполированную статью, пригодную для публикации. И MarketMuse First Draft, и GROVER неплохо справились с получением высокого общего балла, что означает, что уровень написания был достаточно хорошим, и требовалось некоторое базовое редактирование. GPT-2 и XLNet также не преуспели, особенно с учетом небольшого количества слов. Выход из этих моделей потребует значительных редакторских усилий, чтобы быть презентабельным.
Уникальные слова
ГРОВЕР всегда лучше всех справился с использованием разнообразного словарного запаса. К сожалению, это не привело к подробному обсуждению ни одной из тем, о чем свидетельствуют его низкие оценки содержания.
Редкие слова
MarketMuse First Draft имеет сравнительно большой словарный запас, о чем свидетельствует высокий процент редких слов по всем темам. Обратите внимание, что все тематические модели работали ниже среднего для всех пользователей Grammarly, если смотреть на процент уникальных и редких слов.
Длина слова и предложения
MarketMuse First Draft и GROVER, как правило, используют словарь с более длинными словами, чем GPT-2 или XLNet. По всем темам в MarketMuse First Draft постоянно использовались самые короткие предложения. В GPT-2, за одним исключением, использовались значительно более длинные предложения, что создавало потенциальную потребность в дополнительных редакторских усилиях.
Флеш Чтение-Легкость
Flesch Reading-Ease рассчитывается таким образом, что контент с более высокими баллами считается более легким для чтения. Нужно быть осторожным при включении этой метрики, так как проще не обязательно лучше. Есть много проблем с применением Flesch Reading-Ease, но в этом случае я хотел посмотреть, подходит ли читабельность для целевой аудитории.
Возьмем, к примеру, тему глюкагона как неинвазивного лечения диабета. Я ожидаю, что аудитория этой темы будет иметь высшее образование и создавать контент для этого уровня чтения. С другой стороны, как выращивать перец — тема, подходящая для более широкой аудитории. Таким образом, контент должен быть легко читаемым. За исключением нескольких странных исключений, обычно так и происходило.
Общие сведения о моделях генерации естественного языка
Вот некоторая справочная информация о четырех моделях NLG, использованных в этом исследовании, и почему они были выбраны.
Первый проект MarketMuse
MarketMuse First Draft (скоро появится) — это модель NLG, которая создает объемный контент (более 1000 слов) в соответствии с набором спецификаций. Он поддерживает повествование без шаблонов или плагиата, соблюдая и проверяя другие показатели в соответствующем кратком описании содержания.
Краткое содержание (нажмите, чтобы увидеть пример) содержит все, что нужно автору для создания всеобъемлющей статьи, включая подзаголовки (для структуры), вопросы, которые необходимо задать, и темы для обсуждения. Тот же краткий обзор содержания предоставляется нашей модели генерации естественного языка для создания первого черновика.
Это четкое указание дает MarketMuse First Draft неотъемлемое преимущество перед другими моделями NLG, которые предлагают очень мало контроля, если вообще дают его. Подумайте об этом так. Писатели-люди редко создают блестящие произведения без какого-либо направления. Почему вы ожидаете чего-то другого от ИИ?
Для этого исследования мне удалось получить несколько образцов от нашей команды по обработке данных, без их ведома!
ГРУВЕР
GROVER — популярная модель NLG, выпущенная в 2019 году Институтом искусственного интеллекта Аллена. Он больше не является общедоступным, хотя это сообщение было написано в мае 2020 года.
Получив довольно много прессы с момента его представления публике, я почувствовал, что это будет хорошая модель для сравнения. Это также была первая модель, в которой была введена обусловленность (контроль над поколениями). В этом случае вы можете указать для своей статьи критерии, по которым следует писать (домен, автор и заголовок), тем самым предоставив некоторый контроль над конечным результатом.
ГПТ-2
GPT-2 выпускался поэтапно в течение 2019 года, начиная с самой маленькой модели. Крупнейшие новостные агентства опубликовали эту историю и устроили ей настоящий полевой день. В статьях создавалось впечатление, что вывод GPT-2 неотличим от человеческого письма.
HuggingFace предлагает общедоступную реализацию модели, которую я использовал для этого исследования. Согласно сайту, GPT-2 «в настоящее время является наиболее синтаксически последовательной моделью». Но, честно говоря, я не был впечатлен его выходом.
Я выбрал настройки по умолчанию (большой размер модели, Top-p 0,9, температура 1, максимальное время 1), потому что решил, что это самая безопасная ставка. Я предоставил ему начальный текст в виде абзаца из статьи № 1 в Интернете по версии Google.
Это работает так: вы предоставляете фрагмент текста (предложение или абзац), и он предлагает до трех вариантов следующего набора слов (максимум три слова). Для своего теста я всегда выбирал первый вариант, предполагая, что первый вариант является лучшим и последовательным.
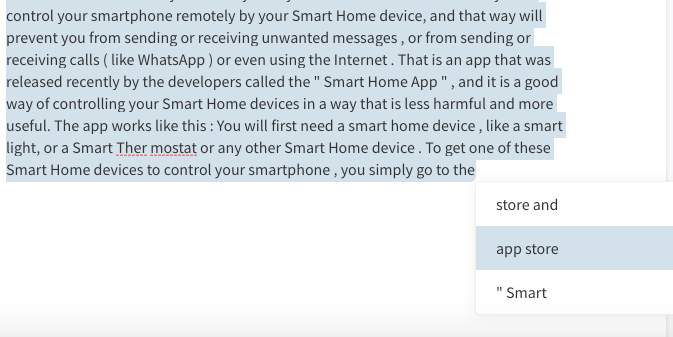
Я обнаружил, что эта форма микроуправления очень утомительна, а контроль, доступный пользователю, не очень полезен. Это все равно, что пытаться управлять автомобилем, мчащимся по шоссе, глядя только на первые несколько футов вперед.
Один тревожный результат заключается в том, что отсутствие структуры более высокого порядка может привести к изменению темы в середине статьи. В одну минуту вы говорите о выращивании перца, а в следующую — о персиках!
XLNet
XLNet является усовершенствованием современной авторегрессионной модели, известной как TransformerXL, и превосходит BERT в 20 различных задачах. Как и GPT-2, он доступен для публичного использования на HuggingFace. Он также использует тот же подход, что и GPT-2, к вопросу управления и страдает от тех же проблем.
Использование этих моделей генерации естественного языка
Каково это использовать модели NLG? Вот что я обнаружил, работая над этим исследованием. Они организованы по темам и модели NLG.
Тема – Глюкагон как неинвазивный метод лечения диабета
Первый проект MarketMuse
Во-первых, вам нужно создать краткое содержание, как если бы вы использовали писателя-человека. Когда вы будете удовлетворены кратким описанием содержания, вы можете запросить первый черновик. Процесс генерации не является автоматическим. В настоящее время требуется некоторое вмешательство человека, что неудивительно, учитывая, что сервис еще не общедоступен.

Обратите внимание на краткие данные, появляющиеся на боковой панели этого примера? Это вопросы и соответствующие темы, которые необходимо рассмотреть в этом разделе. Эта информация направляет процесс NLG для обеспечения благоприятного результата. Он соответствует целевому баллу содержания 38.
ГРУВЕР
GROVER должен был написать против одного из лучших доменов в результатах по этой теме и автора этой статьи. Здесь есть надежда, что результат будет подражать этому стилю.

Я пробовал три раза и выбрал лучшее поколение с оценкой содержания 17. Хотя оно намного лучше, чем GPT-2 и XLNet, с оценкой содержания 0 и 4, оно и близко не соответствовало сути первого черновика MarketMuse. В его обсуждении этой темы упущено несколько ключевых тем.
ГПТ-2
Я столкнулся с несколькими проблемами, используя GPT-2 для этой темы.

Всего несколько сотен слов в поколении, и оно «застряло» из-за отсутствия лучшего термина. Это продолжало давать мне только один выбор для следующего слова в статье.

Он также ошибочно назвал T1D (регистр людей, страдающих диабетом 1 типа) заболеванием. Кроме того, несколько сотен слов, которые он сгенерировал, привели к нулевой оценке содержания MarketMuse.
Возможно, проблема с моделью GPT-2 или с кодировкой. Но заметили в выводе фразу «hyp», «oglyce», «mia»? Эта реализация модели рассматривает гипогликемию как три разных слова!

XLNet
Как и GPT-2, XLNet тоже застрял уже после пары сотен слов. Он тоже подвергся гневу правила трех ударов (повтори что-то три раза, и оно прекращается). Он показал себя немного лучше с точки зрения Content Score (4), но это мало о чем говорит.

У XLNet, как и у GPT-2, похожая проблема. В этом случае гипогликемический разделен на три разных слова.
Тема – Телефонная зависимость
Первый проект MarketMuse
Вот начальный раздел выходных данных, созданных MarketMuse First Draft.
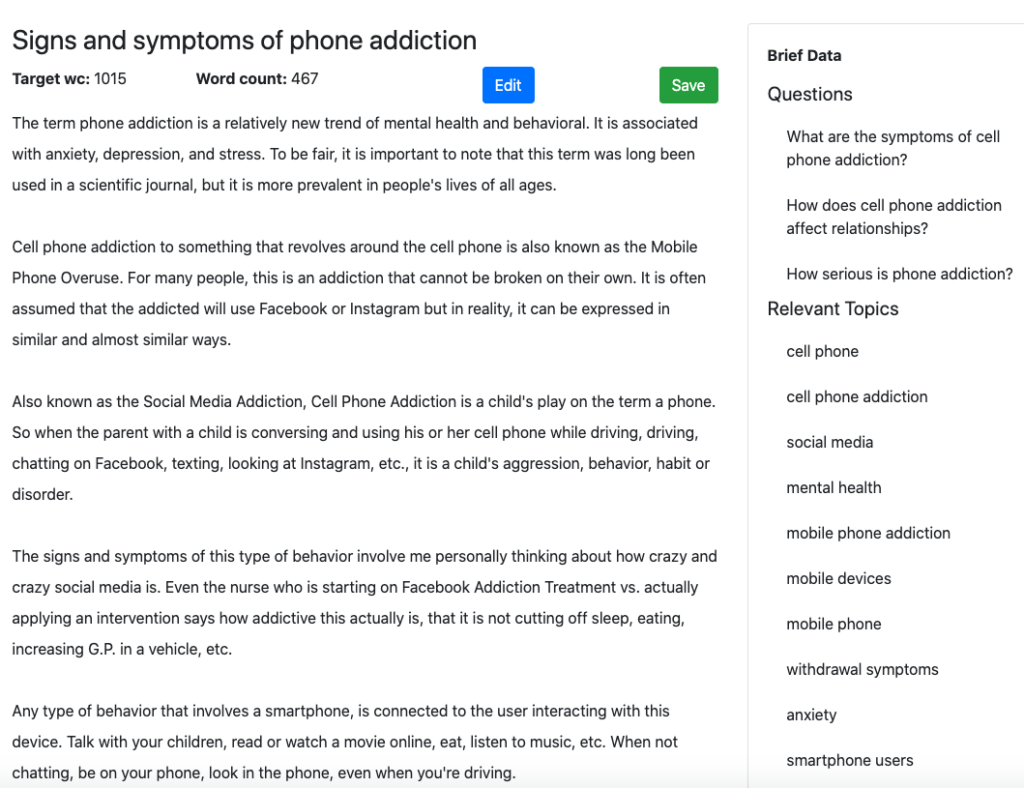
Вот как это выглядит в Оптимизации. Обратите внимание, что у него уже есть хороший показатель содержания. Каждая выделенная тема — это тема, найденная в модели для этой темы.
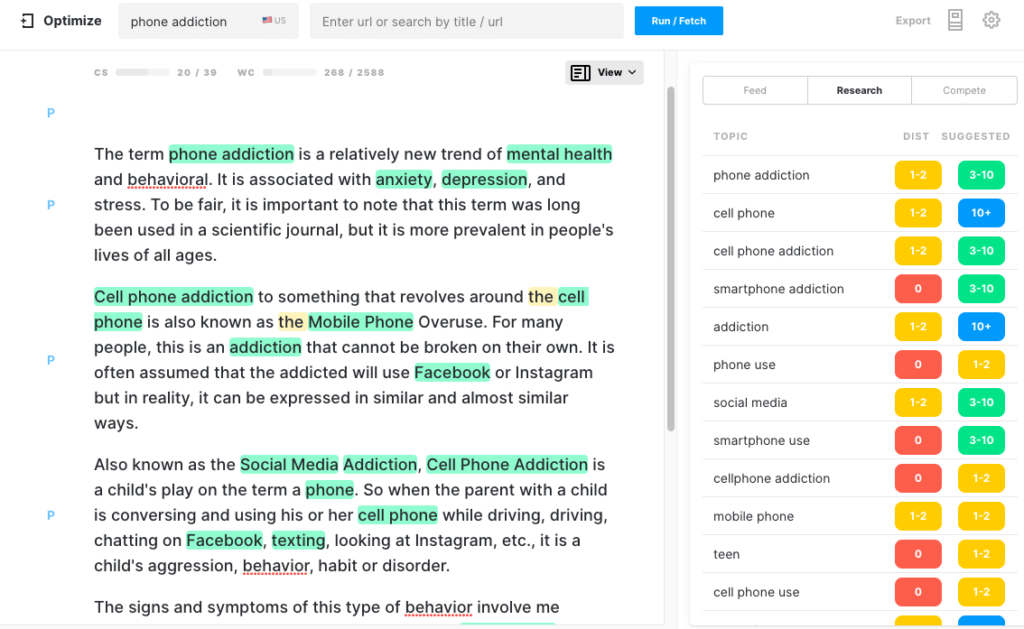
ГРУВЕР
Я выбрал NYTimes и Нелли Боуэлс, автора, который писал на эту тему раньше, надеясь, что сгенерированный текст будет выглядеть впечатляюще.

Хотя он достиг этой цели, он довольно бесполезен, когда дело доходит до полноты. Я пробовал несколько поколений, лучший из которых состоял из 431 слова с оценкой содержания 7.
ГПТ-2
Начал с «телефонной зависимости», а через 500 слов тема сменилась на обзор приложения, которое может управлять устройствами умного дома!

На данный момент статья имела оценку содержания 14 с оценкой целевого содержания 39. Поскольку она была далека от цели, я позволил продолжить генерацию. При 1048 словах количество слов удвоилось, но оценка содержания немного увеличилась до 18. При 1474 словах оценка содержания по-прежнему не изменилась. Неудивительно, поскольку поколение ушло далеко от темы.
XLNet
XLNet предоставил опыт, аналогичный GPT-2. Примерно через 300 слов он зациклился и повторился. Три удара и ты вылетаешь!

Тема – Как вырастить перец
По общему признанию, глюкагон — довольно тяжелая тема. После чего-то подобного выращивание перца должно стать прогулкой в парке. Давай выясним.
Первый проект MarketMuse
Хотя MarketMuse First Draft соответствует всем показателям, его стиль написания в данном случае может быть лучше. Как ни странно, высокий балл Flesch Reading-Ease указывает на то, что эту статью легко читать.
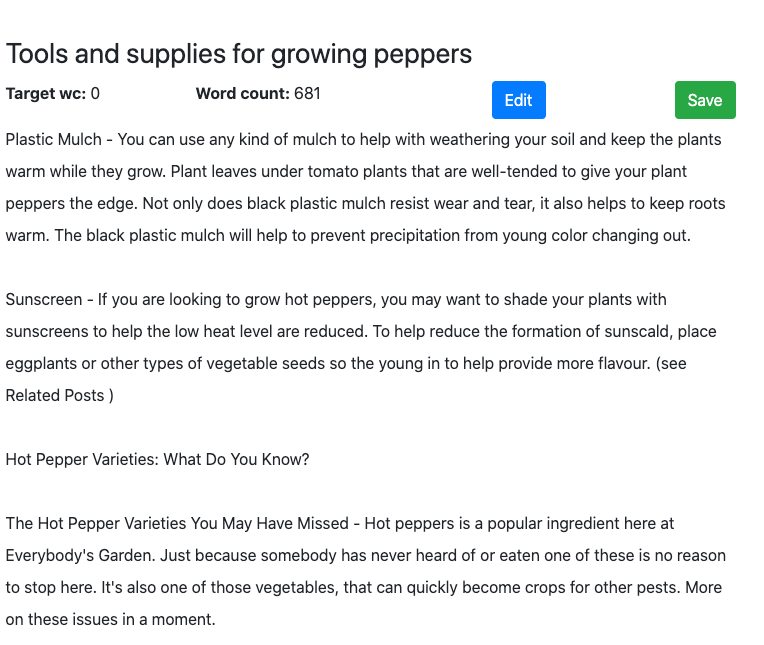
ГРУВЕР
Это поколение должно было подражать стилю популярного автора из TheSpruce, написавшего аналогичную статью, которая хорошо работает в поиске. В чуть более 600 слов его, конечно, нельзя квалифицировать как трактат на эту тему. Низкий показатель содержания подтверждает это.

ГПТ-2
Опять же, эта модель генерации естественного языка не может оставаться в теме. Примерно 400 слов в поколении, и статья перешла от разговоров о перцах к персикам! Именно в этот момент я остановил генерацию, так как она вряд ли поменяет курс. Неудивительно, что у него такой низкий показатель содержания.

XLNet
Я мало что могу сказать о генерации текста, которую XLNet предоставил для этой темы. Он застрял после генерации только одного предложения! Посмотреть на себя. Я дал ему более чем достаточно шансов исправиться, после чего прекратил генерацию.

Тема – Сила сторителлинга
Первый проект MarketMuse
Если бы существовала тема, в которой история могла бы развиваться как угодно, то это была бы она. Но помните, что MarketMuse First Draft основан на четко структурированном обзоре контента, который сам основан на анализе всего конкурентного контента по этой теме.
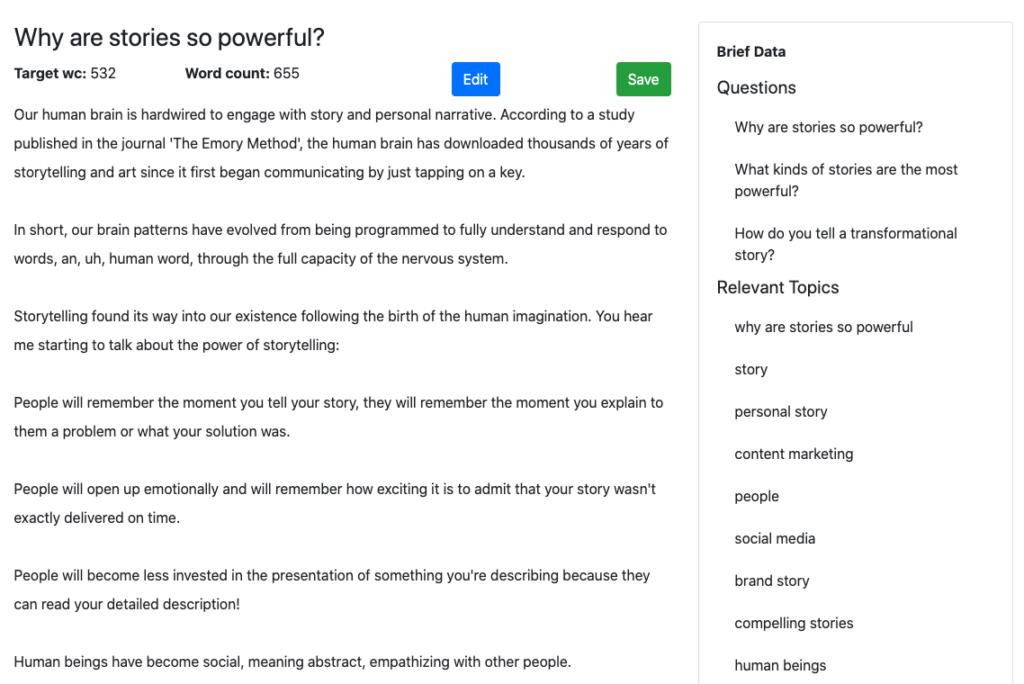
Чтобы получить хороший рейтинг по этому предмету, вам необходимо осветить определенные темы. MarketMuse определяет, что это такое.
ГРУВЕР
ГРОВЕР должен был написать статью против одного из 10 лучших веб-сайтов по этой теме, health.org.uk. Еще раз аргументация заключалась в том, что подражание этому престижному изданию приведет к созданию заслуживающей доверия статьи.
Результат? Не совсем.
Это не удивительно, если подумать. С таким небольшим направлением, что вы можете ожидать?

В 612 словах это был короткий и довольно интересный рассказ. Но это была не статья о силе историй.
ГПТ-2
В очередной раз GPT-2 застрял, повторяясь, поэтому я закончил генерацию. Большая часть статьи повторяется, что приводит к низким баллам по всем показателям.

XLNet
Мол, GPT-2, я предоставил XLNet первый абзац из высокорейтинговой статьи на health.org.uk на ту же тему. Жирный текст — это материал, созданный языковой моделью. Поскольку он продолжал повторять первое созданное им предложение, я завершил генерацию.

Тема – Как стать социальным работником по борьбе со злоупотреблением психоактивными веществами
Первый проект MarketMuse
Я думал, что тема была достаточно простой, чтобы все модели могли преуспеть в создании соответствующего текста. Преимущество MarketMuse First Draft по сравнению с кратким описанием содержания состоит в том, что в нем представлена структура, темы и вопросы для ответа. А остальные?
ГРУВЕР
Хотя ГРУВЕР может сочинить историю, она не всегда настолько информативна. Конечно, его Content Score, равный 16, намного превосходит своих конкурентов, GPT-2 и XLNet. Тем не менее, это далеко не так, как у MarketMuse First Draft с 36 баллами. Его относительно низкий общий балл по грамматике 65 указывает на то, что для того, чтобы его можно было опубликовать, требуется изрядное количество редактирования.
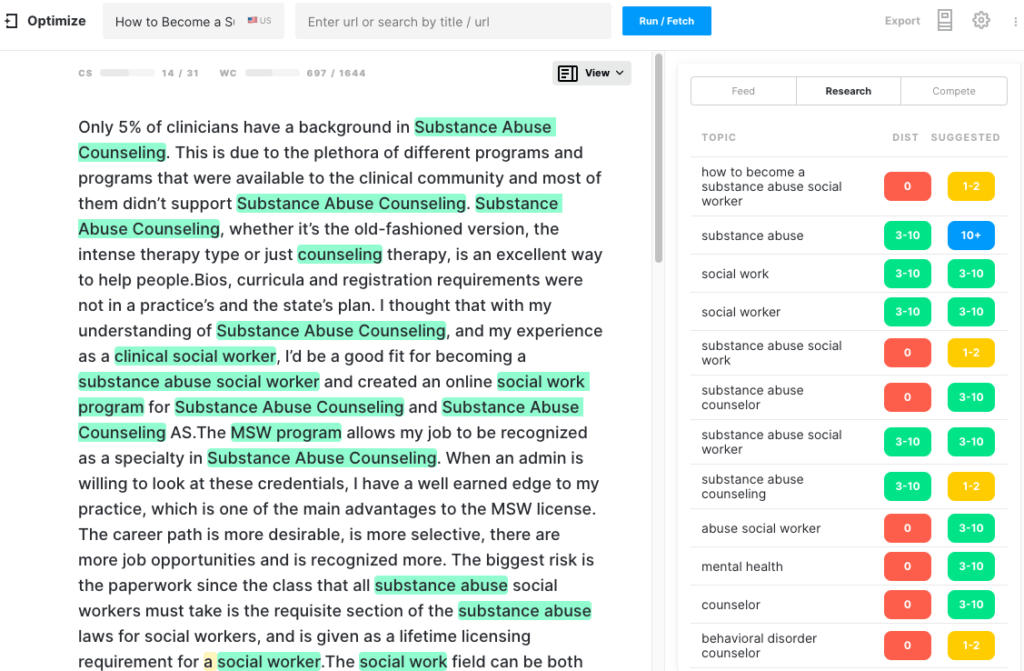
ГПТ-2
Эта языковая модель изо всех сил пыталась создать осмысленный контент по этой теме. После первых 300 слов текст не влиял на оценку содержания, достигнув максимума 7 по сравнению с целевым значением в 31. Качество текста ухудшилось до такой степени, что вывод перестал быть последовательным, поэтому генерация была прекращена.
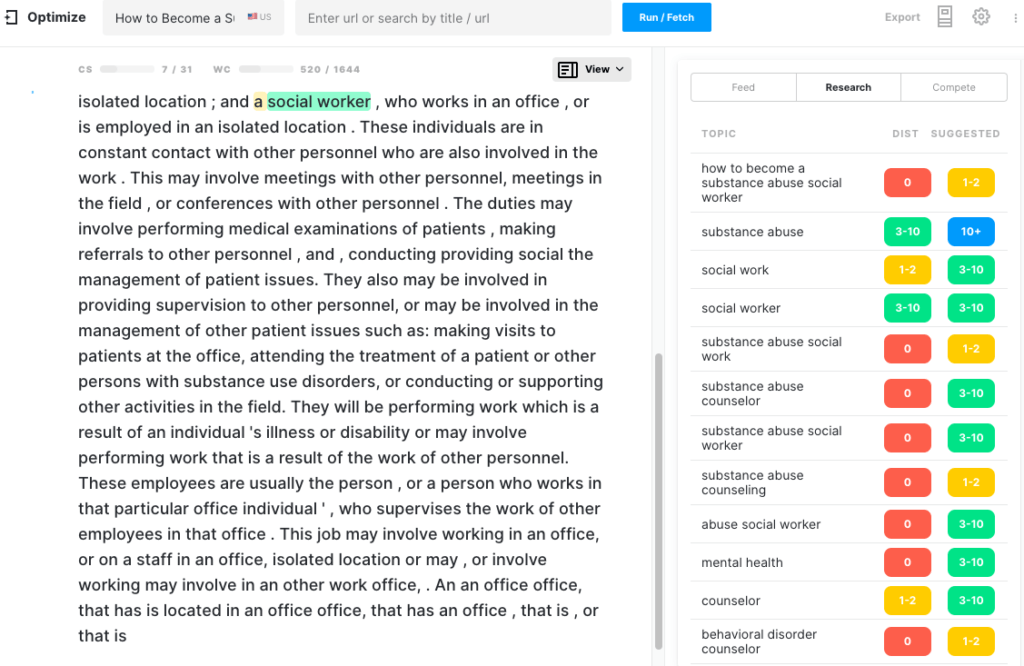
XLNet
У XLNet была самая низкая оценка контента (5) по этой теме по сравнению со всеми четырьмя моделями генерации языков. И снова его выходной текст имел наименьшее количество слов. Мало того, созданный им текст быстро вырождался в повторение, на котором генерация снова прекращалась.

Резюме
В 2019 году большое внимание уделялось моделям генерации естественного языка, в частности GROVER и GPT-2. Были опасения, что их могут использовать в гнусных целях. Правда в том, что эти модели, в отличие от MarketMuse First Draft, с трудом генерируют объемный контент, который остается по теме и является всеобъемлющим. Это затрудняет маркетологам контента использовать их в любых продуктивных целях.
Существует фундаментальная разница в подходе к генерации естественного языка между MarketMuse First Draft и этими моделями. В случае с MarketMuse First Draft люди тесно вовлечены в рабочий процесс и определяют структуру статьи, темы для обсуждения и вопросы, на которые нужно ответить. MarketMuse помогает определить, какими должны быть эти элементы, но полагается на проверку этих факторов человеком до создания контента. Мы верим, что в текущей ситуации ИИ лучше всего подходит для дополнения человеческих писателей.
Что вы должны сделать сейчас
Когда вы будете готовы... вот 3 способа, которыми мы можем помочь вам публиковать более качественный контент и быстрее:
- Забронируйте время с MarketMuse Запланируйте живую демонстрацию с одним из наших специалистов по стратегии, чтобы увидеть, как MarketMuse может помочь вашей команде достичь своих целей в отношении контента.
- Если вы хотите узнать, как быстрее создавать качественный контент, посетите наш блог. Он полон ресурсов, помогающих масштабировать контент.
- Если вы знаете другого маркетолога, которому было бы интересно прочитать эту страницу, поделитесь ею с ним по электронной почте, LinkedIn, Twitter или Facebook.