
Modelarea subiectului cu Word2Vec
Publicat: 2020-03-13Un cuvânt este definit de compania pe care o păstrează. Aceasta este premisa din spatele Word2Vec, o metodă de conversie a cuvintelor în numere și de reprezentare a acestora într-un spațiu multidimensional. Cuvintele frecvent întâlnite apropiate într-o colecție de documente (corpus) vor apărea și ele apropiate în acest spațiu. Se spune că ele sunt legate contextual.
Word2Vec este o metodă de învățare automată care necesită un corpus și o pregătire adecvată. Calitatea ambelor afectează capacitatea sa de a modela cu acuratețe un subiect. Orice deficiențe devin ușor evidente atunci când se examinează rezultatele pentru subiecte foarte specifice și complicate, deoarece acestea sunt cele mai dificil de modelat cu precizie. Word2Vec poate fi folosit singur, deși este frecvent combinat cu alte tehnici de modelare pentru a-și rezolva limitele.
Restul acestui articol oferă informații suplimentare despre Word2Vec, cum funcționează, cum este utilizat în modelarea subiectelor și unele dintre provocările pe care le prezintă.
Ce este Word2Vec?
În septembrie 2013, cercetătorii Google, Tomas Mikolov, Kai Chen, Greg Corrado și Jeffrey Dean, au publicat lucrarea „Efficient Estimation of Word Representations in Vector Space” (pdf). La asta ne referim acum ca Word2Vec. Scopul lucrării a fost de a „introduce tehnici care pot fi folosite pentru a învăța vectori de cuvinte de înaltă calitate din seturi uriașe de date cu miliarde de cuvinte și cu milioane de cuvinte în vocabular”.
Înainte de acest punct, orice tehnici de procesare a limbajului natural tratau cuvintele ca unități singulare. Nu au luat în considerare nicio asemănare între cuvinte. Deși au existat motive întemeiate pentru această abordare, ea avea și limitări. Au existat situații în care scalarea acestor tehnici de bază nu putea oferi îmbunătățiri semnificative. De aici, necesitatea de a dezvolta tehnologii avansate.
Lucrarea a arătat că modelele simple, cu cerințele lor de calcul mai mici, ar putea antrena vectori de cuvinte de înaltă calitate. După cum conchide lucrarea, este „posibil să se calculeze vectori de cuvinte cu dimensiuni mari foarte precise dintr-un set de date mult mai mare”. Ei vorbesc despre colecții de documente (corpora) cu un trilion de cuvinte care oferă o dimensiune practic nelimitată a vocabularului.
Word2Vec este o modalitate de a converti cuvintele în numere, în acest caz vectori, astfel încât asemănările să poată fi descoperite matematic. Ideea este că vectorii cuvintelor similare sunt grupați în spațiul vectorial.
Gândiți-vă la coordonatele latitudinale și longitudinale de pe o hartă. Folosind acest vector bidimensional, puteți determina rapid dacă două locații sunt relativ apropiate. Pentru ca cuvintele să fie reprezentate corespunzător într-un spațiu vectorial, două dimensiuni nu sunt suficiente. Deci, vectorii trebuie să încorporeze mai multe dimensiuni.
Cum funcționează Word2Vec?
Word2Vec ia ca intrare un corpus de text mare și îl vectorizează folosind o rețea neuronală superficială. Rezultatul este o listă de cuvinte (vocabular), fiecare cu un vector corespunzător. Cuvintele cu sens similar apar spațial în imediata apropiere. Matematic, aceasta este măsurată prin asemănarea cosinusului, unde asemănarea totală este exprimată ca un unghi de 0 grade, în timp ce nicio asemănare nu este exprimată ca un unghi de 90 de grade.
Cuvintele pot fi codificate ca vectori folosind diferite tipuri de modele. În lucrarea lor, Mikolov et al. a analizat două modele existente, modelul de limbaj de rețea neuronală feedforward (NNLM) și modelul de limbaj de rețea neuronală recurentă (RNNLM). În plus, ei propun două noi modele log-lineare, continuous bag of words (CBOW) și continuu Skip-gram.
În comparațiile lor, CBOW și Skip-gram au avut rezultate mai bune, așa că haideți să examinăm aceste două modele.
CBOW este similar cu NNLM și se bazează pe context pentru a determina un cuvânt țintă. Determină cuvântul țintă pe baza cuvintelor care vin înainte și după el. Mikolov a constatat că cea mai bună performanță a avut loc cu patru cuvinte de viitor și patru cuvinte istorice. Se numește „pungă de cuvinte”, deoarece ordinea cuvintelor în istorie nu influențează rezultatul. „Continuu” în termenul CBOW se referă la utilizarea sa de „reprezentare continuă distribuită a contextului”.
Skip-gram este reversul CBOW. Dat un cuvânt, acesta prezice cuvintele din jur într-un anumit interval. O gamă mai mare asigură vectori de cuvinte de calitate mai bună, dar crește complexitatea de calcul. Se acordă mai puțină pondere termenilor îndepărtați, deoarece de obicei sunt mai puțin legați de cuvântul curent.
Comparând CBOW cu Skip-gram, s-a constatat că acesta din urmă oferă rezultate de mai bună calitate pe seturi mari de date. Deși CBOW este mai rapid, Skip-gram gestionează mai bine cuvintele utilizate rar.
În timpul antrenamentului, fiecărui cuvânt i se atribuie un vector. Componentele acelui vector sunt ajustate astfel încât cuvintele similare (pe baza contextului lor) să fie mai apropiate. Gândiți-vă la asta ca la un remorcher, în care cuvintele sunt împinse și trase în acest vector multidimensional de fiecare dată când un alt termen este adăugat în spațiu.
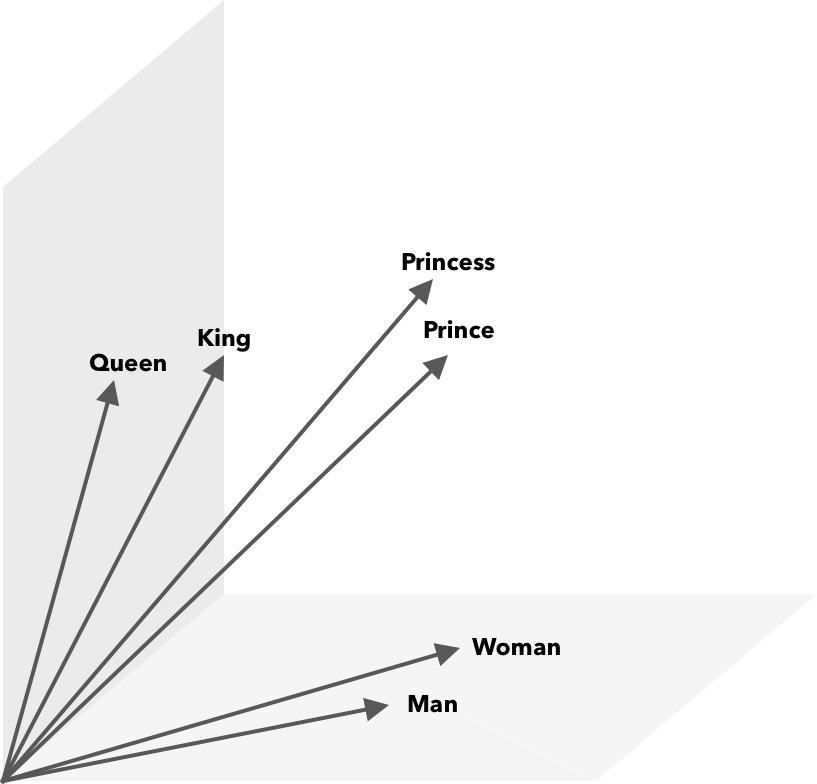
Operațiile matematice, pe lângă asemănarea cosinusului, pot fi efectuate pe vectori de cuvinte. De exemplu, vectorul(”Rege”) – vector(”Bărbat”) + vector(”Femeie”) are ca rezultat un vector cel mai apropiat de cel care reprezintă cuvântul Regina.
Word2Vec pentru modelarea subiectelor
Vocabularul creat de Word2Vec poate fi interogat direct pentru a detecta relațiile dintre cuvinte sau poate fi introdus într-o rețea neuronală de învățare profundă. O problemă cu algoritmii Word2Vec precum CBOW și Skip-gram este că aceștia cântăresc fiecare cuvânt în mod egal. Problema care apare atunci când lucrați cu documente este că cuvintele nu reprezintă în mod egal sensul unei propoziții.

Unele cuvinte sunt mai importante decât altele. Astfel, diferite strategii de ponderare, cum ar fi TF-IDF, sunt adesea folosite pentru a face față situației. Acest lucru ajută și la rezolvarea problemei hubness menționată în secțiunea următoare. Searchmetrics ContentExperience utilizează o combinație de TF-IDF și Word2Vec, despre care puteți citi aici în comparația noastră cu MarketMuse.
În timp ce înglobările de cuvinte precum Word2Vec captează informații morfologice, semantice și sintactice, modelarea subiectelor își propune să descopere subiecte structurate sau semantice latente într-un corpus.
Potrivit lui Budhkar și Rudzicz (PDF), combinarea alocării latente Dirichlet (LDA) cu Word2Vec poate produce caracteristici discriminatorii pentru „a aborda problema cauzată de absența informațiilor contextuale încorporate în aceste modele”. Citirea mai ușoară a LDA2vec poate fi găsită în acest tutorial DataCamp.
Provocările Word2Vec
Există mai multe probleme cu încorporarea de cuvinte în general, inclusiv Word2Vec. Vom atinge unele dintre acestea, pentru o analiză mai detaliată, consultați „Un studiu despre metodele de evaluare a încorporarii cuvintelor” (pdf) de Amir Bakarov. Corpusul și dimensiunea acestuia, precum și formarea în sine, vor avea un impact semnificativ asupra calității rezultatelor.
Cum evaluezi rezultatul?
După cum explică Bakarov în lucrarea sa, un inginer NLP va evalua în mod obișnuit performanța înglobărilor în mod diferit decât un lingvist computațional sau un marketer de conținut. Iată câteva probleme suplimentare citate în lucrare.
- Semantica este o idee vagă. Încorporarea unui cuvânt „bună” reflectă noțiunea noastră de semantică. Cu toate acestea, este posibil să nu fim conștienți dacă înțelegerea noastră este corectă. De asemenea, cuvintele au diferite tipuri de relații, cum ar fi relația semantică și similitudinea semantică. Ce fel de relație ar trebui să reflecte cuvântul încorporare?
- Lipsa datelor de antrenament adecvate. Când antrenează încorporarea cuvintelor, cercetătorii își măresc frecvent calitatea ajustându-le la date. Aceasta este ceea ce ne referim drept potrivire curbă. În loc să facă ca rezultatul să se potrivească cu datele, cercetătorii ar trebui să încerce să surprindă relațiile dintre cuvinte.
- Absența corelației dintre metodele intrinseci și extrinseci înseamnă că nu este clar ce clasă de metodă este preferată. Evaluarea extrinsecă determină calitatea ieșirii pentru utilizare mai departe în aval în alte sarcini de procesare a limbajului natural. Evaluarea intrinsecă se bazează pe judecata umană a relațiilor dintre cuvinte.
- Problema hubness. Hub-urile, vectori de cuvinte care reprezintă cuvinte comune, sunt aproape de un număr excesiv de alți vectori de cuvinte. Acest zgomot poate influența evaluarea.
În plus, există două provocări semnificative cu Word2Vec în special.
- Nu poate face față foarte bine ambiguităților. Ca urmare, vectorul unui cuvânt cu sensuri multiple reflectă media, care este departe de a fi ideală.
- Word2Vec nu poate gestiona cuvinte în afara vocabularului (OOV) și cuvinte similare din punct de vedere morfologic. Atunci când modelul întâlnește un nou concept, recurge la utilizarea unui vector aleatoriu, care nu este o reprezentare exactă.
rezumat
Folosirea Word2Vec sau a oricărui alt cuvânt încorporat nu este o garanție a succesului. Rezultatele de calitate se bazează pe o pregătire adecvată folosind un corpus adecvat și suficient de mare.
Deși evaluarea calității rezultatelor poate fi greoaie, iată o soluție simplă pentru marketerii de conținut. Data viitoare când evaluați un optimizator de conținut, încercați să utilizați un subiect foarte specific. Modelele de subiecte de proastă calitate eșuează atunci când vine vorba de testarea în acest mod. Sunt în regulă pentru termenii generali, dar se descompun atunci când cererea devine prea specifică.
Deci, dacă folosiți subiectul „cum să creșteți avocado”, asigurați-vă că sugestiile au legătură cu cultivarea plantei și nu cu avocado în general.
Generarea limbajului natural MarketMuse First Draft a ajutat la crearea acestui articol.
Ce ar trebui să faci acum
Când sunteți gata... iată 3 moduri prin care vă putem ajuta să publicați conținut mai bun, mai rapid:
- Rezervați timp cu MarketMuse Programați o demonstrație live cu unul dintre strategii noștri pentru a vedea cum MarketMuse vă poate ajuta echipa să-și atingă obiectivele de conținut.
- Dacă doriți să aflați cum să creați mai rapid conținut mai bun, vizitați blogul nostru. Este plin de resurse pentru a ajuta la scalarea conținutului.
- Dacă cunoașteți un alt agent de marketing căruia i-ar plăcea să citească această pagină, distribuiți-o prin e-mail, LinkedIn, Twitter sau Facebook.