
使用 Word2Vec 进行主题建模
已发表: 2020-03-13一个词是由它所拥有的公司定义的。 这就是 Word2Vec 背后的前提,这是一种将单词转换为数字并在多维空间中表示它们的方法。 在文档集合(语料库)中频繁出现的单词也将在此空间中出现。 据说它们在上下文中是相关的。
Word2Vec 是一种机器学习方法,需要语料库和适当的训练。 两者的质量都会影响其准确建模主题的能力。 在检查非常具体和复杂的主题的输出时,任何缺点都变得很明显,因为这些是最难精确建模的。 Word2Vec 可以单独使用,尽管它经常与其他建模技术结合使用以解决其局限性。
本文的其余部分提供有关 Word2Vec 的其他背景、它的工作原理、它在主题建模中的使用方式以及它所面临的一些挑战。
什么是 Word2Vec?
2013 年 9 月,Google 研究人员 Tomas Mikolov、Kai Chen、Greg Corrado 和 Jeffrey Dean 发表了论文“向量空间中单词表示的有效估计”(pdf)。 这就是我们现在所说的 Word2Vec。 该论文的目标是“引入可用于从包含数十亿单词和词汇表中的数百万单词的庞大数据集中学习高质量单词向量的技术。”
在此之前,任何自然语言处理技术都将单词视为单数单位。 他们没有考虑单词之间的任何相似性。 虽然这种方法有正当的理由,但它确实有其局限性。 在某些情况下,缩放这些基本技术无法提供显着改进。 因此,需要开发先进的技术。
该论文表明,计算要求较低的简单模型可以训练高质量的词向量。 正如论文总结的那样,“有可能从更大的数据集中计算出非常准确的高维词向量”。 他们谈论的是包含一万亿个单词的文档集合(语料库),提供了几乎无限大小的词汇表。
Word2Vec 是一种将单词转换为数字的方法,在这种情况下为向量,以便可以在数学上发现相似之处。 这个想法是相似词的向量在向量空间内分组。
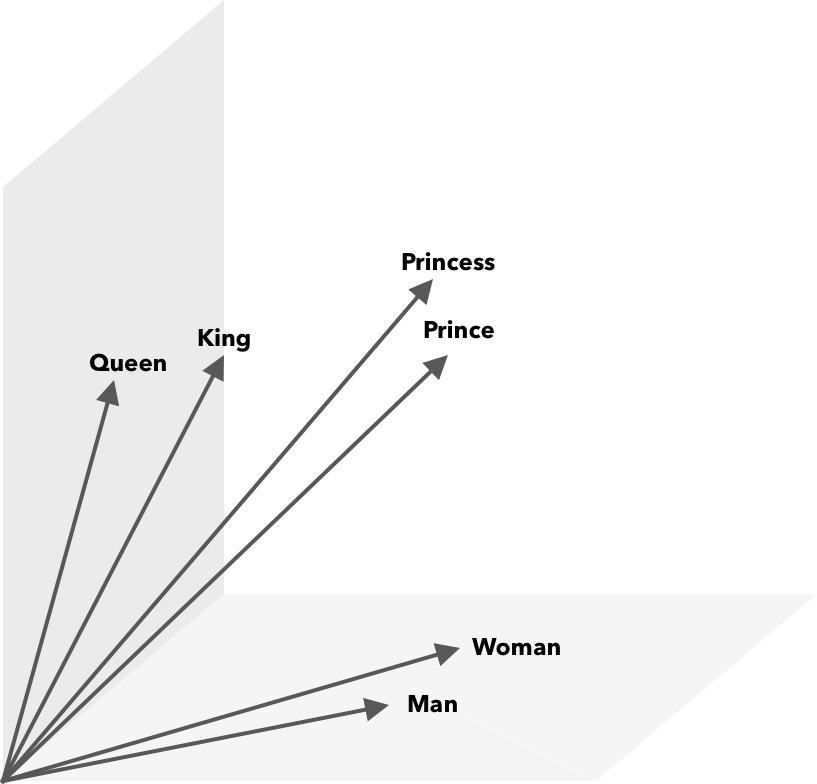
想想地图上的纬度和经度坐标。 使用这个二维向量,您可以快速确定两个位置是否相对靠近。 对于要在向量空间中适当表示的单词,二维是不够的。 因此,向量需要包含许多维度。
Word2Vec 如何工作?
Word2Vec 将大型文本语料库作为其输入,并使用浅层神经网络对其进行矢量化。 输出是一个单词列表(词汇表),每个单词都有一个对应的向量。 具有相似含义的单词在空间上非常接近。 在数学上,这是通过余弦相似度来衡量的,其中总相似度表示为 0 度角,而没有相似度表示为 90 度角。
可以使用不同类型的模型将单词编码为向量。 在他们的论文中,Mikolov 等人。 研究了两个现有模型,前馈神经网络语言模型(NNLM)和递归神经网络语言模型(RNNLM)。 此外,他们提出了两个新的对数线性模型,连续词袋(CBOW)和连续 Skip-gram。
在他们的比较中,CBOW 和 Skip-gram 表现更好,所以让我们来看看这两个模型。
CBOW 与 NNLM 类似,依赖于上下文来确定目标词。 它根据它之前和之后的单词来确定目标单词。 米科洛夫发现最好的表现出现在四个未来和四个历史词上。 之所以称为“词袋”,是因为历史中单词的顺序不会影响输出。 术语 CBOW 中的“连续”是指其使用“上下文的连续分布式表示”。
Skip-gram 是 CBOW 的反面。 给定一个单词,它会预测特定范围内的周围单词。 更大的范围提供了更好质量的词向量,但增加了计算复杂度。 较远的术语被赋予较少的权重,因为它们通常与当前单词的相关性较小。
在比较 CBOW 和 Skip-gram 时,发现后者在大型数据集上提供了更好的质量结果。 尽管 CBOW 更快,但 Skip-gram 可以更好地处理不常用的单词。
在训练期间,为每个单词分配一个向量。 调整该向量的分量,使相似的词(基于它们的上下文)更接近。 将其视为一场拔河比赛,每次在空间中添加另一个术语时,单词都会在这个多维向量中被推拉。
除了余弦相似度之外,还可以对词向量执行数学运算。 例如,vector(”King”) – vector(”Man”) + vector(”Woman”) 得到的向量最接近表示单词 Queen 的向量。
用于主题建模的 Word2Vec
可以直接查询 Word2Vec 创建的词汇表以检测单词之间的关系或输入深度学习神经网络。 CBOW 和 Skip-gram 等 Word2Vec 算法的一个问题是它们对每个单词的权重相等。 处理文档时出现的问题是单词不能平等地代表句子的含义。

有些词比其他词更重要。 因此,通常采用不同的加权策略,例如 TF-IDF 来处理这种情况。 这也有助于解决下一节中提到的 hubness 问题。 Searchmetrics ContentExperience 使用 TF-IDF 和 Word2Vec 的组合,您可以在此处阅读我们与 MarketMuse 的比较。
虽然 Word2Vec 等词嵌入捕获形态、语义和句法信息,但主题建模旨在发现语料库中的潜在语义结构或主题。
根据 Budhkar 和 Rudzicz (PDF) 的说法,将潜在 Dirichlet 分配 (LDA) 与 Word2Vec 相结合可以产生区分特征,以“解决由于这些模型中缺少上下文信息而导致的问题”。 可以在这个 DataCamp 教程中找到更容易阅读 LDA2vec。
Word2Vec 的挑战
一般来说,词嵌入存在几个问题,包括 Word2Vec。 我们将涉及其中的一些,更详细的分析,请参阅 Amir Bakarov 的“词嵌入评估方法调查”(pdf)。 语料库及其大小以及训练本身将显着影响输出质量。
你如何评价输出?
正如 Bakarov 在他的论文中解释的那样,NLP 工程师通常会以不同于计算语言学家或内容营销人员的方式评估嵌入的性能。 以下是论文中引用的一些其他问题。
- 语义是一个模糊的概念。 “好的”词嵌入反映了我们的语义概念。 但是,我们可能不知道我们的理解是否正确。 此外,单词具有不同类型的关系,例如语义相关性和语义相似性。 词嵌入应该反映哪种关系?
- 缺乏适当的训练数据。 在训练词嵌入时,研究人员经常通过根据数据调整它们来提高它们的质量。 这就是我们所说的曲线拟合。 研究人员不应使结果适合数据,而应尝试捕捉单词之间的关系。
- 内在方法和外在方法之间缺乏相关性意味着不清楚哪种方法是首选。 外部评估决定了在其他自然语言处理任务中进一步下游使用的输出质量。 内在评价依赖于人类对词语关系的判断。
- 中心问题。 Hubs,表示常用词的词向量,接近于过多的其他词向量。 这种噪音可能会使评估产生偏差。
此外,特别是 Word2Vec 存在两个重大挑战。
- 它不能很好地处理歧义。 结果,一个多义词的向量反映的是平均值,这很不理想。
- Word2Vec 无法处理词汇表外 (OOV) 单词和形态相似的单词。 当模型遇到一个新概念时,它会求助于使用随机向量,这不是一个准确的表示。
概括
使用 Word2Vec 或任何其他词嵌入并不能保证成功。 质量输出取决于使用适当且足够大的语料库进行适当培训。
虽然评估输出质量可能很麻烦,但这里有一个针对内容营销人员的简单解决方案。 下次您评估内容优化器时,请尝试使用非常具体的主题。 以这种方式进行测试时,质量差的主题模型会失败。 它们适用于一般条款,但当请求过于具体时就会崩溃。
因此,如果您使用“如何种植鳄梨”这一主题,请确保这些建议与种植植物有关,而不是一般的鳄梨。
MarketMuse First Draft 自然语言生成帮助创建了这篇文章。
你现在应该做什么
当您准备就绪时……我们可以通过以下 3 种方式帮助您更快地发布更好的内容:
- 与 MarketMuse 预约时间 与我们的一位策略师安排现场演示,了解 MarketMuse 如何帮助您的团队实现其内容目标。
- 如果您想了解如何更快地创建更好的内容,请访问我们的博客。 它充满了帮助扩展内容的资源。
- 如果您认识其他喜欢阅读此页面的营销人员,请通过电子邮件、LinkedIn、Twitter 或 Facebook 与他们分享。