
Nieszczelne wiadro indyjskich startupów dostarczających jedzenie
Opublikowany: 2016-06-10[Ten post opisuje matematyczną analizę dynamiki i ekonomiki jednostkowej samodzielnych firm dostarczających żywność w Indiach . Na przykład, aby uzyskać miesięczne obliczenia „współczynnika spalania” (tj. ile pieniędzy tracą samodzielne firmy dostarczające żywność), użyliśmy między innymi liczb charakterystycznych dla Indii dla opłat za dostawę i kosztów pracy. Jednak modele matematyczne dotyczące wskaźników przybycia zamówień, czasu oczekiwania i ich wpływu na poziom usług mają zastosowanie globalnie].
„Jedzenie poza domem” jest poza domem, „zamawianie w” jest już dostępne. W tej nowej ekonomii wygody, branża restauracyjna uczy się radzić sobie z tą zmianą dzięki wielu startupom oferującym nowe sposoby dostarczania żywności klientom na żądanie. Jak można było przewidzieć, nastąpiły inwestycje: firma Tracxn zajmująca się analizą startupów wykazała, że 31 startupów branży spożywczej w Indiach zebrało ponad 160 milionów dolarów w 2015 roku, w porównaniu do ~67 milionów dolarów w 2014 roku. Co więcej, tylko w ciągu pierwszych 15 dni 2016 roku jedna firma zebrała 35 milionów dolarów finansowanie. Pieniądze zdecydowanie napływają do sektora pomimo szeptów o nierentowności i kilku ostatnich przestojów i być może spowolnienia inwestycji, które może nastąpić.
Firmy dostarczające żywność są ograniczone przez szereg rzeczywistych czynników:
* Ograniczony czas dostawy, ponieważ ludzie chcą jedzenia zwykle w ciągu 30–45 minut, pozostawiając 20–30 minut na dostawę (przy założeniu, że czas przygotowania wynosi 10–15 minut)
* Nieprzewidywalne wzorce popytu , np. osoba może zamawiać w różnych restauracjach w tym samym tygodniu
* Wysoce skoncentrowane szczyty zamówień w porze posiłków, np. w południe — 15:00 w porze lunchu i 20–23:00 w porze kolacji, co utrudnia oszacowanie wydajności i zarządzanie flotą dostawczą
* Niemożność codziennego wpływania na okoliczności zewnętrzne, takie jak ruch uliczny, pogoda i zmieniające się wymagania
* Operacje kuchenne
Czynniki te utrudniają samodzielnym dostawcom żywności (FD) osiągnięcie rentowności. Startupy te potrzebują ogromnej wydajności, aby sprostać wyzwaniom realnego świata, sprostać oczekiwaniom klientów i osiągać zyski, jednocześnie konkurując z kosztami dostaw w restauracjach, które nie są zbyt duże (i są to wydatki dyskrecjonalne).
W celu zaspokojenia rosnącego popytu na takie zamówienia, wiele firm zajmujących się dostawą uciekło się do zatrudniania dużej liczby motocyklistów (zwanych również „kierownikami terenowymi” lub FE w Indiach), tj. nadmiernie inwestuje w liczbę osób, aby rozwiązać problem problem. Zakłada się, że chociaż obecnie jest nieopłacalny, branża dostaw żywności byłaby podobna do innych firm kurierskich (np. dostawy e-commerce) i ostatecznie z czasem przyniesie zyski dzięki większej agregacji zamówień i większej skali operacyjnej. W tej notatce badamy te założenia matematycznie.
Typowy dzień z życia firmy FD:
Rozważ następujący scenariusz.
Popularny start-up dostarczający jedzenie w południowym Delhi otrzymuje wiele zamówień dzięki niedawnym relacjom w krajowych gazetach i telewizji. Obecnie otrzymuje ponad 2000 zamówień na dostawę żywności tygodniowo, czyli około 40 zamówień na godzinę. Jak tylko zamówienie zostanie umieszczone w systemie, przypisuje najbliższe dostępne FE, aby dotrzeć do restauracji, odebrać zamówienie i dostarczyć je do klienta. Zakłada się, że system został zoptymalizowany tak, że jak tylko FE dotrze do restauracji, zamówienie jest gotowe do odbioru. Natychmiast po dostarczeniu zamówienia FE staje się ponownie dostępny do przypisania do innego zamówienia. Prezes start-upu ocenił, co następuje:
- Od momentu przypisania zamówienia do FE średni czas realizacji zamówienia przez FE wynosi 30 minut, tj. FE może podjechać do przydzielonej restauracji, odebrać jedzenie i dostarczyć je do klienta w ciągu 30 minut . Dlatego zdrowy rozsądek sugeruje, że FE może dostarczać dwa zamówienia na godzinę przy 100% wykorzystaniu.
- Aby zaspokoić potrzeby klientów, firma zatrudniła 25 FE. Przy 100% wykorzystaniu powinny być w stanie dostarczyć 50 zamówień na godzinę, znacznie powyżej zapotrzebowania 40 zamówień na godzinę.
Jednak sprawy nie są tak proste, jak początkowo wyobrażała sobie firma. W minionym tygodniu byli zmuszeni opóźniać dostawę, zatrudniać dodatkowe osoby w ostatniej chwili po bardzo wysokich kosztach i od czasu do czasu odbierać telefony od wściekłych klientów.
Co tu się stało?
Parametry rentowności w branży Food Delivery:
Aby przeanalizować omówioną powyżej sytuację, zamodelujmy matematycznie cały proces. Następujące czynniki są ważne dla każdej firmy FD, ponieważ tworzą parametry modelu matematycznego, w ramach którego firma może działać:
* Wskaźnik realizacji zamówień , czyli ilość zamówień klientów na godzinę,

Rysunek 1: Zróżnicowany współczynnik przybycia dla zamówień klientów
* Czas realizacji dostawy , czyli średni czas potrzebny na dostarczenie zamówienia, oraz
* Liczba FE dostępnych w danym momencie.
Analiza danych:
Przeanalizowaliśmy dane historyczne związane ze stawkami przybycia i czasem obsługi dla firm FD i poczyniliśmy następujące obserwacje:
- Szybkość realizacji zamówienia: Zamówienia nie są dostarczane po jednolitej stawce. W rzeczywistości wskaźnik przyjazdów klientów do restauracji może wyglądać tak (rys.1):
Rysunek 1: Zróżnicowany współczynnik przybycia dla zamówień klientów
Do modelowania napływających zamówień zakładamy proces Markowa. Zgodnie z procesem Markowa, liczba potencjalnych nowych klientów jest niezależna od liczby klientów oczekujących już w kolejce. Dobrze znanym procesem Markowa, który jest często używany do modelowania wskaźnika przybycia zamówień w firmie takiej jak dostarczanie żywności, jest proces Poissona. Zgodnie z tym procesem, liczba nowych klientów, którzy przychodzą co godzinę, jest podawana w rozkładzie Poissona (szczegóły w Załączniku 1). Głównym parametrem wejściowym wymaganym do zdefiniowania rozkładu Poissona jest średni wskaźnik przybycia na godzinę (λ), który dla przykładu omówionego powyżej jest równy 40 zamówień na godzinę.
- Stawka za usługę dostawy: Zdefiniowana jako średnia liczba klientów obsługiwanych w ciągu godziny. Zależy to od czasu obsługi pojedynczego zamówienia, które jest zmienną losową, ze względu na nieprzewidywalne czynniki, takie jak warunki na drodze, czas oczekiwania w restauracji/klienta itp. Jak piszemy, wstępne dane zbieramy z FD usług i wydaje się, że czasy obsługi są zgodne z rozkładem Gamma ze średnią około 30 minut (tj. średnio 2 zamówienia na godzinę) i odchyleniem standardowym wynoszącym 16,2 minuty (patrz Rysunek 2). Te czasy obsługi obejmują czas, jaki zajmuje FE dojazd do wyznaczonej restauracji, odebranie jedzenia i dostarczenie go do klienta.
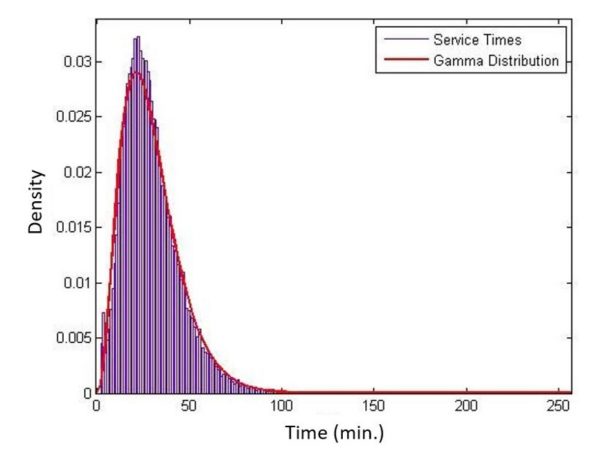
Rys 2: Czasy obsługi są zgodne z rozkładem Gamma ze średnią ~30 minut i odchyleniem standardowym 16,2 minut
Opierając się na powyższych obserwacjach, łatwo zrozumieć, dlaczego kolejki i czas oczekiwania narastają w branży dostaw żywności. Jeżeli założono, że stawki i czasy obsługi są jednolite, tj. zamówienie przychodzi co 1,5 minuty i obsłużenie zamówienia zajmuje dokładnie 30 minut, to jeśli mamy więcej niż 30/1,5 ~ 20 FE, wszystkie zamówienia będą przetwarzane natychmiast, bez tworzenia kolejek. Jednak ze względu na zmienność stawek za przyjazd/usługę, usługa dostawy bez oczekiwania nie jest możliwa.
System kolejkowy:
Teraz, aby przeanalizować zachowanie formujących się kolejek, na podstawie obserwowanych danych opracowujemy model kolejkowania, który pomoże nam oszacować średni czas oczekiwania klienta na dostawę zamówienia. Zwróć uwagę, że czas oczekiwania na klienta jest definiowany jako suma (i) czasu oczekiwania zamówienia w kolejce, tj. czasu potrzebnego na przypisanie zamówienia do FE (ma to miejsce, gdy wszystkie FE są zajęte istniejącymi dostawy zamówienia) oraz (ii) czas obsługi zamówienia (który następuje po dystrybucji Gamma).
Matematycznie problem przypisywania serwerów do klientów należy do klasy problemów znanych jako „problem z kolejką” — dosłownie, w jaki sposób klienci przychodzą i dołączają do kolejki w nieregularnych odstępach czasu oraz jak są obsługiwani. Teoria kolejek nie jest hipotetyczną sytuacją: kolejki w supermarketach lub na dworcach autobusowych lub czas oczekiwania na odpowiedź, gdy dzwonisz do linii lotniczej, są zgodne z teorią kolejek.
Model kolejkowania dla naszego scenariusza będzie miał następującą strukturę (rys. 3):
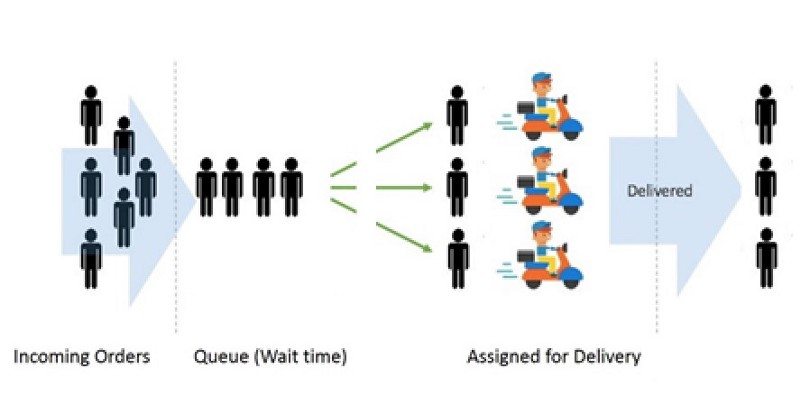
Rysunek 3: Typowy proces dostarczania żywności
Polecany dla Ciebie:

Co oznacza przepis anty-profitowy dla indyjskich startupów?

W jaki sposób start-upy Edtech pomagają indyjskim pracownikom podnosić umiejętności i być gotowym na przyszłość...

Akcje New Age Tech w tym tygodniu: Kłopoty Zomato nadal, EaseMyTrip publikuje Stro...

Indyjskie startupy idą na skróty w pogoni za finansowaniem

Digital Marketing Platform Logicserve Bags Finansowanie INR 80 Cr, zmienia nazwę na LS Dig...

Raport ostrzega przed odnowioną kontrolą regulacyjną dotyczącą przestrzeni Lendingtech
- Zamówienia przychodzące: Zamówienia przychodzą losowo, a liczba zamówień na godzinę jest zgodna z rozkładem Poissona ze średnią λ . System kolejkowy będzie badany pod kątem różnych dla różnych wartości λ.
- Kolejka: Kolejka podlega regule pierwszeństwa pierwsze przyszło, pierwsze wyszło (FIFO) i zakłada się, że ma nieograniczoną pojemność, tj. firma dostarczająca żywność nie odrzuci zamówienia.
- Usługa: Obsługa systemu kolejkowego jest uzależniona od Liczby FE, Stawki za Usługę oraz Stawki Agregacji Zleceń:
- Liczba FE: Zakładamy, że wszystkie są równie dobre i zajmują tyle samo czasu na realizację zamówienia.
- Stawki za usługi: Wiemy, że czasy obsługi są zmienne i są zgodne z rozkładem Gamma ze średnią 30 minut i odchyleniem standardowym 16,2 minut. Zatem średnia stawka za usługę może być obliczona jako µ = 2.
- Wskaźnik agregacji zamówień: Zdefiniowany jako ułamek wszystkich zamówień, które są agregowane w dwie przesyłki, np. gdy dwa zamówienia są agregowane, FE jest w stanie dostarczyć je oba w ramach jednej podróży. Jeśli wskaźnik agregacji zamówień jest wysoki, poprawi to również stawki za usługi. Można łatwo wywnioskować, że jeśli ułamek x wszystkich zamówień zostanie zagregowany w pary, to stawka usług µ zostanie pomnożona przez współczynnik
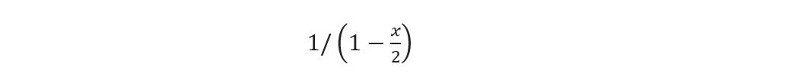

- Aktualne dane sugerują, że mniej niż 5% zamówień jest zagregowanych, co oznacza, że zaktualizowaną stawkę za usługę można znaleźć jako µ = 2,05.
Matematyczny opis proponowanego modelu kolejkowania:
Powyższy model kolejkowania może być reprezentowany jako model M/G/m w standardowej nomenklaturze kolejkowania. „M” w pierwszym polu oznacza, że istnieje proces Markowa dla wskaźników przybycia; „G” w drugim polu oznacza, że rozkład ogólny (w naszym przypadku Gamma) jest używany do modelowania czasów obsługi; „m” w trzecim polu oznacza, że w modelu kolejkowania używanych jest wiele serwerów (w naszym przypadku FE).
Model ten jest nieco egzotycznym modelem kolejkowania z bardzo małą liczbą wyników analitycznych dostępnych w literaturze dotyczącej kolejek. Zgodnie z artykułem badawczym Lee i Longton (1959), średni czas oczekiwania na model M/G/m można przybliżyć za pomocą współczynnika do dostosowania średniego czasu oczekiwania w kolejce M/M/m. Drugi model zakłada, że czasy obsługi są zgodne z rozkładem wykładniczym i jest jednym z najlepiej zbadanych modeli kolejkowania w literaturze. Przedstawione poniżej wzory reprezentują kluczowe metryki systemu kolejkowego M/M/m i można je łatwo wyprowadzić:

Wreszcie średni czas oczekiwania na model M/G/m można obliczyć jako:
![]()
gdzie C to współczynnik zmienności (stosunek odchylenia standardowego do średniej równy 0,54 dla naszych danych), a W to średni czas oczekiwania określony wzorem (5).
Wyniki obliczeń: czasy oczekiwania nie rosną liniowo
Korzystając ze wzoru (6) na średni czas spędzony w systemie, możemy obliczyć średni czas realizacji zamówienia (czas obsługi + czas oczekiwania) dla różnych wskaźników przyjazdów i średniego wykorzystania systemu (użyj wzoru ( 1)). Wydaje się, że czas oczekiwania klientów wydłuża się nieliniowo wraz ze wzrostem liczby przyjazdów. Tabela 1 przedstawia wyniki dla stałej liczby FE i kilku wskaźników przyjazdów.

Tabela 1: Szybkość realizacji zamówienia, wykorzystanie i czas oczekiwania klienta różnią się nieliniowo
Jest to sprzeczne z intuicją : można by pomyśleć, że jeśli parametr zmieni się o około 25% (w tym przypadku szybkość przybycia wzrośnie z 40 do 50), inne powiązane parametry, takie jak czas oczekiwania, zmienią się w podobny sposób, tj. prawdopodobnie około 25% lub więcej. Zamiast tego, nieregularność w liczbie przyjazdów powoduje, że system jest bardzo niestabilny i wydłuża czas oczekiwania nieproporcjonalnie, w tym przypadku o 134%.
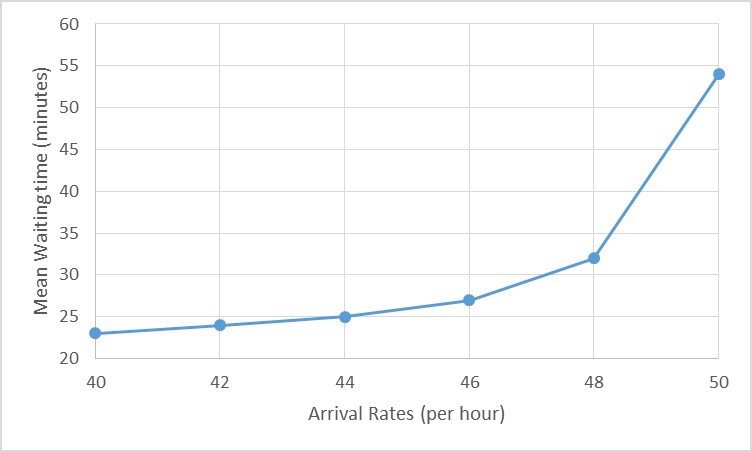
Rysunek 4: W tym scenariuszu, zwiększając liczbę klientów z 40-50, czyli tylko o 25%, średni czas oczekiwania wydłuża się z 23 minut do 54 minut
Wpływ na rachunek zysków i strat:
Tabela 2 pokazuje przedziały wynagrodzeń FE dla dwóch rodzajów scenariuszy, z którymi się spotykamy. W większości miast „koszt dla firmy (CTC)” dla FE wynosi Rs. 15 000 miesięcznie. W niektórych częściach droższych stacji metra, takich jak Bangalore i Delhi, pensje rosną teraz w kierunku Rs. 18 000 miesięcznie. Należy pamiętać, że firma FD ma znaczne inne wydatki, takie jak paliwo, wynajem rowerów, koszty ogólne firmy itp.

Tabela 2. Koszt/FE dla różnych przedziałów wynagrodzeń
Łatwo zrozumieć, że jeśli na ziemi będziemy mieć więcej FE, średni czas oczekiwania na zamówienie ulegnie skróceniu. Obecnie obiecujemy czas zwrotu (TAT) wynoszący około 45 minut. Aby konsekwentnie osiągnąć ten cel, średnia TAT powinna wynosić około 30–35 minut, ponieważ odchylenie standardowe czasów obsługi wynosi około 16 minut.
Zobaczmy, ile FE jest potrzebnych do utrzymania średniego czasu oczekiwania około 30–35 minut, dla różnych szybkości przybycia (patrz Tabela 3). Dla każdego wskaźnika przyjazdu pokazujemy również, co się dzieje, gdy mamy tylko jedno FE mniej niż zalecany poziom. Okazuje się, że średni czas oczekiwania wzrasta do około 55-60 minut. Jeśli usuniemy z systemu kolejne FE, system dostarczania staje się niewykonalny, tj. stawka przybycia staje się wyższa niż stawka usług netto. Obliczenia te wykonuje się za pomocą wzoru (6). Tabela 3 podaje również minimalną kwotę, jaką należy naliczyć za zamówienie, aby w każdym przypadku osiągnąć rentowność.
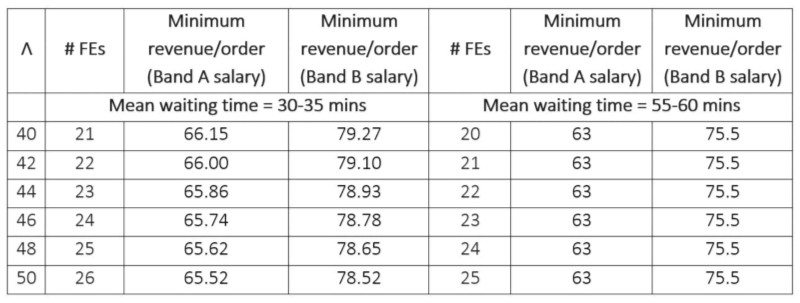
Tabela 3: Minimalna liczba FE wymagana dla danej stopy przybycia i odpowiednie wymagania dotyczące przychodów na zamówienie (w Rs.); Λ oznacza średnią liczbę przyjazdów na godzinę
Pamiętaj, że jeśli średni czas oczekiwania wynosi około 30 minut (55 minut), minimalny wymagany przychód na zamówienie oscyluje wokół Rs. 66 (Rs. 63)/zamówienie z pracownikami zespołu A i około Rs. 79 (Rs. 76)/za zamówienie dla pracowników Grupy B. W rzeczywistości rynek nie pozwala nam pobierać więcej niż Rs. 50 na zamówienie, ponosząc tym samym straty na każdym zamówieniu, nawet jeśli dopuszczamy średni czas oczekiwania 55–60 minut, co może nie być akceptowalnym czasem realizacji zamówień z dostawą żywności.
Przeskalujmy teraz nasze obliczenia i obliczmy „współczynnik spalania”, zakładając, że naszym celem jest średni czas oczekiwania około 30–35 minut, a przychód na zamówienie wynosi Rs. 50. Tabela 4 przedstawia „szybkość spalania” w dwóch scenariuszach:
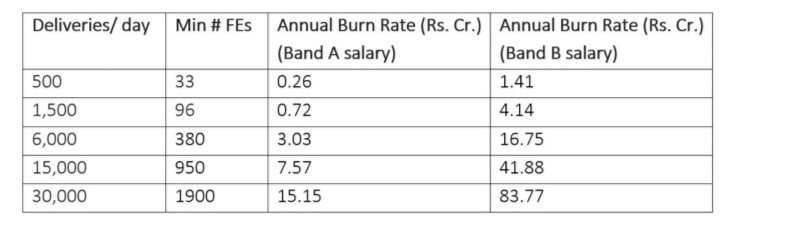
Tabela 4: Wskaźnik spalania dla samodzielnej firmy FD
Kluczowe założenia:
Zwróć uwagę, że w celu wykonania obliczeń przedstawionych w tym artykule przyjęto szereg kluczowych założeń. Wszystkie te założenia sprzyjają biznesowi FD, więc wyniki obliczeń należy postrzegać jako optymistyczne oszacowanie rzeczywistej sytuacji. Główne założenia to:
- Średnia liczba przyjazdów pozostaje stała przez cały dzień — jest to bardzo mało prawdopodobne, ponieważ w rzeczywistości liczba zamówień osiąga szczyt tylko w porze posiłków. Zauważ, że średni wskaźnik przybycia λ = 40, wspomniany w przykładzie omówionym powyżej, dotyczył tylko pory posiłków.
- System został zoptymalizowany tak, że gdy tylko FE dotrze do restauracji, zamówienie jest gotowe do odbioru. W rzeczywistości jest to niezwykle trudne do osiągnięcia i często obserwuje się, że FE traci dużo czasu (średnio 8 minut) w restauracji, czekając, aż jedzenie będzie gotowe. Na potrzeby naszych obliczeń przyjęliśmy, że ten czas oczekiwania wynosi nominalnie 2 minuty, ponieważ uważa się, że przy lepszym rozplanowaniu zasobów można tego czasu oczekiwania uniknąć.
- Jeśli dwa lub więcej zamówień jest zagregowanych, FE zajmuje taką samą ilość czasu, aby dostarczyć zagregowane zamówienie, jak dostarczenie pojedynczego zamówienia.
Wniosek:
Z naszej analizy jasno wynika, że branża dostaw żywności jest bardzo niestabilna, głównie dlatego, że wskaźniki przybycia/obsługi zamówień nie są jednolite. Skutkuje to dużymi wahaniami czasu dostawy, a także wykorzystaniem FE, z wysokimi szansami na nieopłacalność.
W obecnej skali zagęszczenie zamówień nie jest zbyt gęste, co utrudnia agregację zamówień i powoduje, że większość zamówień to „Single pick, Single drop”. Z naszych własnych danych wewnętrznych wynika, że agregowanych jest tylko około 4–5% zamówień, co ma niewielki wpływ na rentowność modelu FD. Jeśli jednak liczba ta wzrośnie do około 55%, obliczenia sugerują, że rentowność można osiągnąć, pod warunkiem, że wszystkie inne założenia nadal się utrzymają.
Istnieją inne potencjalne sposoby osiągania zysków, na przykład poprzez krzyżowe wykorzystanie zasobów lub inny model biznesowy. Firma, która ma wiele linii biznesowych, takich jak żywność czy dostawa paczek, mogłaby wykorzystać zasoby w celu zbudowania rentownego modelu biznesowego. Na przykład firma dostarczająca paczki może użyć FE do dostarczania paczek 9-12, niektórych do dostarczania żywności 12-3, dostarczania paczek 3-6, a niektórych do dostarczania jedzenia w nocy.
Drugą alternatywą jest model „klubu żywnościowego” z ograniczonym menu i ograniczonym czasem dostawy. Eliminuje to niepewność dotyczącą szybkości przybycia z równania, co skutkuje wysokim wykorzystaniem FE.
Trzecią alternatywą jest model „dostawcy na miejscu”, w którym FE jest również wykorzystywany do obowiązków restauracyjnych (takich jak podawanie jedzenia), aby obniżyć całkowity koszt dostawy i poprawić wykorzystanie. W rzeczywistości większość indyjskich restauracji pracuje wewnętrznie na tym modelu, więc warto zrozumieć jego ekonomię.
Czwartym możliwym modelem jest wysoka gęstość użytkowników (np. Koramangala w Bangalore Metro Area), a jedzenie z wcześniej wybranego menu dostarczane jest w bardzo krótkim czasie, co przypomina eksperymenty UberEATS.
Ekonomia samodzielnego dostarczania żywności leży w nauce o zachętach. Jeśli obecne stawki za dostawę naliczane przez istniejące FD cos są znacznie niższe od kosztów ponoszonych wewnętrznie, przedsiębiorca ostatecznie zamknie się. Z drugiej strony, jeśli cena wystarczająco wzrośnie, restauracja prawdopodobnie przejdzie na model wewnętrzny.
Załącznik 1:
Zrozum rozkład Poissona:
Proces Poissona reprezentuje dyskretne zdarzenia, takie jak przybycie klientów lub rozmowy telefoniczne z centralą lub centrum obsługi telefonicznej. Jak pokazano na rys. 5 poniżej, N(t) = liczba przyjazdów w przedziale czasu (0,t) jest zmienną losową, która jest zgodna z rozkładem Poissona.
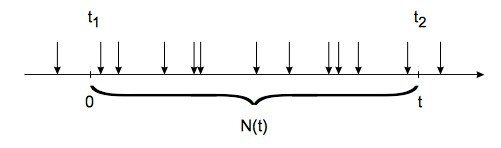
Rysunek 5: Liczba przylotów w przedziale czasowym (0, t)
Matematycznie, prawdopodobieństwo otrzymania N(t) = x przylotów w oknie czasowym (0,t) można wyznaczyć wzorem,
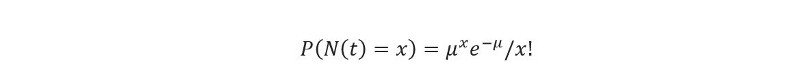
gdzie µ jest średnią liczbą przyjazdów w oknie czasowym (0,t).
Czasy między przybyciem są niezależne i podlegają rozkładowi wykładniczemu, ze średnim czasem przybycia między miejscami (1/ µ), gdzie µ jest szybkością przybycia na jednostkę czasu. Na przykład dla wskaźnika przybycia 40 klientów na godzinę µ =40. Rysunek 6 przedstawia to graficznie.
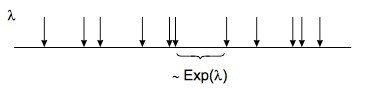
Rysunek 6: Czasy między przybyciem są niezależne i podlegają rozkładowi wykładniczemu
Epilog:
Zespół, który pracował nad tym stanowiskiem, to dr Santanu Bhattacharya, dr Kabir Rustogi, Suvayu Ali (doktorant) i Snigdha Gupta, przy aktywnym wsparciu naszego dyrektora generalnego Sahila Barua i CTO Kapila Bharatiego. Aby uzyskać pełną informację, Delhivery jest wiodącym indyjskim zewnętrznym dostawcą usług logistycznych. Współpracujemy z wieloma firmami FD, aby pomóc im osiągnąć wydajność.
Autorzy chcieliby podziękować licznym przyjaciołom, którzy zrecenzowali artykuł i przekazali cenne uwagi, w tym Nick Berry, Data Scientist na Facebooku, Abhi Dhall z Multiples Equity, Ashok Tilotia z Kotak Security i Haresh Chawla z India Value Fund.
Bibliografia:
- AM Lee i PA Longton, „Procesy kolejkowania związane z odprawą pasażerów linii lotniczych”, Oper. Res. Kwarta. 10: 56-71 ( 1959 )
[Pierwsze opublikowanie na Medium.]