
¿Qué es un archivo txt de robots? Permitir todo y más
Publicado: 2020-11-19¿Qué es un archivo txt de robots?
El archivo robots.text es un método clave para indicar a los motores de búsqueda las áreas que no pueden visitar en su sitio. La funcionalidad básica proporcionada por este archivo de texto es compatible con todos los principales motores de búsqueda. Las reglas adicionales a las que responderán algunos de los motores de búsqueda pueden ser extremadamente útiles. Existe una amplia gama de formas en las que puede usar los archivos robots.txt en su sitio. Aunque el proceso parece bastante simple, debe tener cuidado. Si comete un error, puede causar un daño significativo a su sitio web.
Las arañas de los motores de búsqueda leen el archivo robots.txt y se adhieren a una sintaxis muy estricta. Muchas personas se refieren a estas arañas como robots, que es de donde se originó el nombre. El archivo utilizado para la sintaxis debe ser simple porque debe ser legible por computadoras. Esto significa que no hay absolutamente ningún lugar para errores. Todo es uno o cero sin espacio para nada intermedio. El archivo robots.txt también se conoce como el protocolo de exclusión de robots.
Este nombre se originó a través de un grupo de primeros desarrolladores de arañas para los motores de búsqueda. En este momento, ninguna organización estándar ha establecido el archivo de texto robots como un estándar oficial. A pesar de esto, todos los principales motores de búsqueda se adhieren a este archivo.
¿Qué hace un archivo de texto de Robots?
Los motores de búsqueda indexan la web rastreando páginas. Se siguen los enlaces para guiar a los motores de búsqueda del sitio A al B y así sucesivamente. Antes de que las arañas enviadas por los motores de búsqueda rastreen cualquier página de un dominio que no se haya encontrado en el pasado, se abre el archivo robots.txt para el dominio. Esto es lo que informa al motor de búsqueda qué URL del sitio web no se pueden indexar.
En la mayoría de los casos, los motores de búsqueda almacenan en caché el contenido de robot.txt. La memoria caché generalmente se actualiza varias veces al día. Esto significa que cualquier cambio que realice se muestra con bastante rapidez.
Armando su archivo Robots.txt
Armar un archivo robots.txt muy básico es bastante simple. No deberías tener ninguna dificultad con el proceso. Todo lo que necesitará es un editor de texto simple como el Bloc de notas. Comience abriendo una página. Ahora guarde su página vacía como robots.txt. Ve a tu cPanel e inicia sesión. Busque la carpeta market public_html para acceder al directorio raíz de su sitio web. Abra esta carpeta, luego arrastre su archivo. Debe asegurarse de haber establecido los permisos correctos para su archivo.
Dado que usted es el propietario del sitio web, debe escribir, leer y editar su archivo. No debe permitir que nadie más realice estas acciones en su nombre. El código de permiso que se muestra en su archivo debe ser 0644. Si no se muestra, deberá cambiarlo. Puede lograr esto haciendo clic en el archivo y eligiendo el permiso de archivo.
Sintaxis de robots.txt
Hay numerosas secciones de directivas contenidas en su archivo robots.txt. Cada uno comienza con el agente de usuario especificado. Este es el nombre del bot de rastreo con el que está hablando su código. Tienes dos opciones diferentes disponibles. El primero es dirigirse a todos los motores de búsqueda al mismo tiempo usando un comodín. También puede dirigirse individualmente a un motor de búsqueda específico. Una vez que se ha implementado un bot para rastrear un sitio web, los bloques lo atraen de inmediato.
Su directiva de agente de usuario son las primeras líneas de cada bloque. Esto se conoce simplemente como el agente de usuario y señala el bot específico. Su agente de usuario hace coincidir los nombres de bot específicos. Si necesita decirle a Googlebot qué quiere que haga, comience con el agente de usuario: Googlebot. Los motores de búsqueda siempre intentarán identificar ciertas directivas con la relación más cercana a ellas. Aquí hay un par de ejemplos de directivas de agente de usuario:
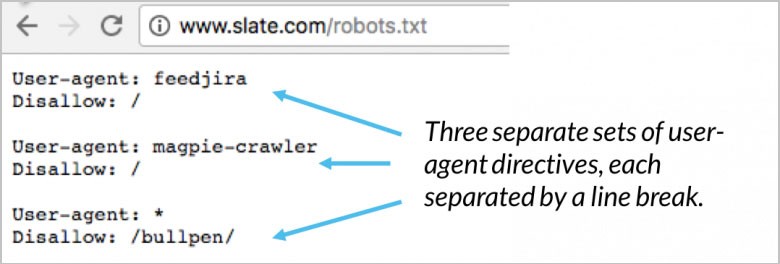
(Crédito de la imagen: Moz)
Un buen ejemplo es cuando está utilizando dos directivas diferentes. Si su primera directiva es para Googlebot-video y la segunda para Bingbot, el proceso es el siguiente. El primer bot con Bingbot como agente de usuario seguirá sus instrucciones. Su directiva Googlebot-video se pasará por alto y el bot comenzará a buscar una directiva más específica.
¡Prueba el SEO y el rendimiento de tu sitio en 60 segundos!
Un buen diseño del sitio web es fundamental para la participación de los visitantes y las conversiones, pero un sitio web lento o errores de rendimiento pueden hacer que incluso el sitio web mejor diseñado tenga un rendimiento inferior. Diib es una de las mejores herramientas de monitoreo de SEO y rendimiento de sitios web del mundo. Diib utiliza el poder de los grandes datos para ayudarlo a aumentar rápida y fácilmente su tráfico y clasificaciones. Como se ve en Emprendedor!
- Herramienta SEO automatizada fácil de usar
- Monitoreo de palabras clave y backlinks + ideas
- Garantiza la velocidad, la seguridad y el seguimiento de Core Vitals
- Sugiere inteligentemente ideas para mejorar el SEO
- Más de 250,000k miembros globales
- Comparación integrada y análisis de la competencia
Utilizado por más de 250 000 empresas y organizaciones:




sincroniza con 

Directiva de host
Actualmente, solo Yandex admite la directiva de host. Hay algunas especulaciones de que esta directiva también es compatible con Google. Esto es lo que permite al usuario decidir si la www. debe mostrarse antes de la URL. Dado que el único partidario confirmado es Yandex, no se recomienda confiar en la directiva de host. Si no está interesado en usar sus nombres de host actuales, se pueden redirigir mediante la redirección 301.
La segunda línea es robots.txt disallow. Este es un bloque de directivas. Esto se puede usar para especificar a qué áreas de su sitio web no deben acceder los bots. Si selecciona un desautorizado vacío, se convierte en un todos contra todos. Esto significa que los bots pueden determinar dónde quieren y dónde no quieren visitar sin directivas de su sitio.
Directiva de mapa del sitio
La directiva de su mapa del sitio utiliza el mapa del sitio robots.txt para indicar a los motores de búsqueda dónde se encuentra su mapa del sitio XML. Su mejor y más útil opción es enviar cada uno individualmente a los motores de búsqueda mediante el uso de herramientas específicas para webmasters. Esto le permitirá aprender una gran cantidad de información valiosa sobre su sitio web de todos ellos. Si no tienes mucho tiempo, usar la directiva del mapa del sitio es una buena alternativa. Por ejemplo:

usted estará interesado
Cómo escalar con éxito su negocio
Velocidad de carga del sitio web: herramientas para la optimización
Comprobación del estado del sitio web: herramientas y consejos
¿Qué significa UX?
(Crédito de la imagen: WooRank)
Validador de robots.txt
Un validador es una herramienta para mostrar si su archivo robots.txt está bloqueando los rastreadores web de Google para URL específicas ubicadas en su sitio web. Un buen ejemplo es usar esta herramienta para probar si el rastreador Googlebot-Image tiene acceso para rastrear una URL de imagen que desea bloquear de todas las búsquedas de imágenes de Google.
Robots.txt Permitir todo
Una directiva disallow puede contrarrestarse usando la directiva Allow. Tanto Google como Bing admiten la directiva Permitir. Puede usar las directivas Disallow y Allow juntas para que los motores de búsqueda sepan que pueden acceder a ciertas páginas o archivos con un directorio Disallow. Por ejemplo:

(Crédito de la imagen: DeepCrawl)
Robots.txt Google
A partir del 1 de septiembre, Google dejó de admitir reglas no publicadas y no admitidas para el protocolo exclusivo del robot. Este anuncio se hizo en el blog para webmasters de Google. Esto significa que Google ya no admite archivos robots.txt dentro de un archivo con un directorio sin índice.
Directiva de retraso de rastreo
En lo que respecta al rastreo, Yahoo, Yandex y Bing pueden ser un poco felices. Dicho esto, responden a la directiva de retraso de rastreo. Esto significa que puede mantenerlos alejados por un tiempo.
Generador de robots.txt
Un generador de robots.txt es una herramienta creada para ayudar a los webmasters, especialistas en marketing y SEO con la generación de un archivo robots.txt sin necesidad de muchos conocimientos técnicos. Aún debe tener cuidado porque cuando crea un archivo robots.txt, puede tener un gran impacto en la capacidad de Google para acceder a su sitio web, independientemente de si lo creó con WordPress o con uno de los otros CMS.

Aunque el uso de esta herramienta es bastante sencillo, la recomendación es familiarizarse primero con las instrucciones proporcionadas por Google. Si su implementación es incorrecta, los motores de búsqueda, incluido Google, no podrán rastrear todo su dominio, incluidas las páginas críticas de su sitio web. El resultado puede afectar significativamente sus esfuerzos de SEO.
Robots.txt WordPress
En la mayoría de los casos, puede encontrar su archivo robots.txt en la carpeta raíz de su sitio web de WordPress. Deberá usar su administrador de archivos cPanel para ver su carpeta raíz o conectarse a su sitio web a través de un cliente FTP. Este es solo un archivo de texto simple que podrá abrir con el Bloc de notas. La siguiente imagen le muestra cómo llegar a su administrador de archivos en WordPress:
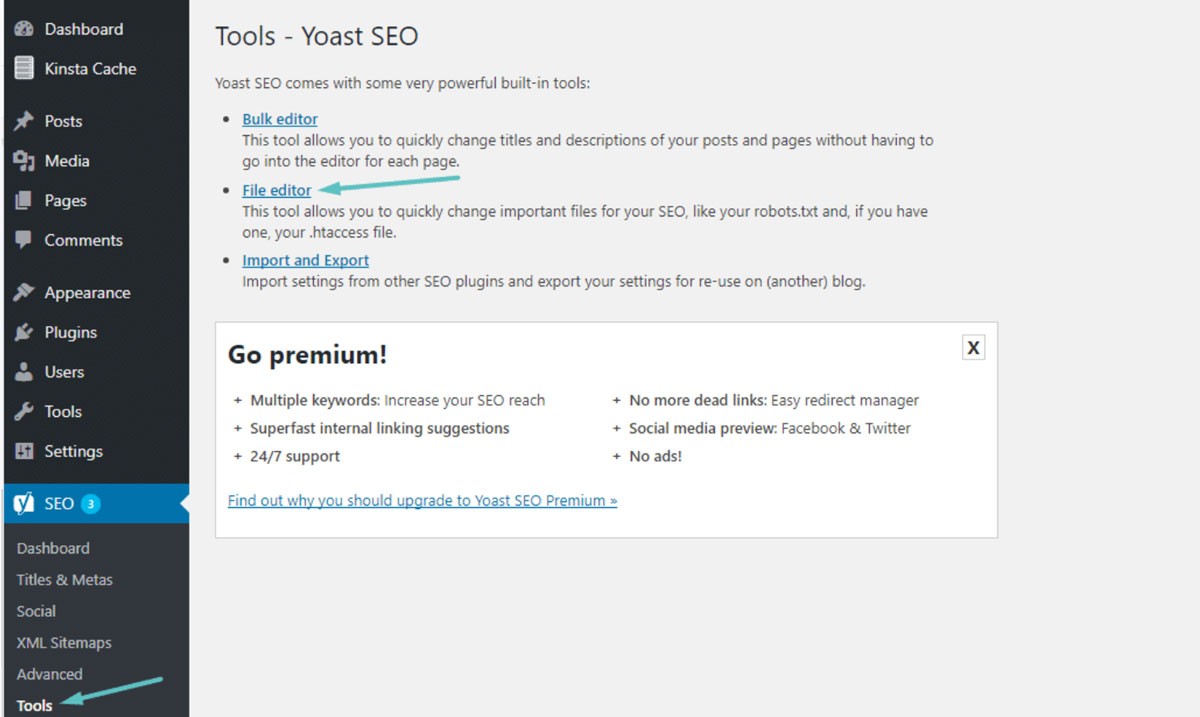
(Crédito de la imagen: Kinsta)
Retardo de rastreo: 10
Esto le permite asegurarse de que los motores de búsqueda esperarán 10 segundos antes de rastrear su sitio web o después de volver a acceder a su sitio web para rastrearlo. El concepto es casi el mismo, pero hay una ligera diferencia según el motor de búsqueda específico.
¿Por qué usar Robots.txt?
Robots.txt no es necesario para tener un sitio web exitoso. Incluso si no tiene uno, puede lograr una buena clasificación con un sitio web que funcione correctamente. Antes de que decida no usar un archivo robots.txt, tenga en cuenta que hay algunos beneficios clave que incluyen:
- Mantenga seguros los archivos privados: puede mantener los bots alejados de sus carpetas privadas para asegurarse de que sean mucho más difíciles de localizar e indexar.
- Especificar mapa del sitio: puede especificar la ubicación de su mapa del sitio. Proporcionar a los rastreadores la ubicación es importante porque desea que puedan escanear a través de ella.
- Control de recursos: puede asegurarse de que sus recursos permanezcan bajo control. Cada vez que un bot rastrea su sitio web, se utilizan los recursos de su servidor y el ancho de banda. Si tiene un sitio web con muchas páginas y contenido masivo, como un sitio de comercio electrónico, sus recursos pueden agotarse extremadamente rápido debido a una gran cantidad de páginas. El uso de un archivo robots.txt garantiza que sea más difícil para los bots acceder a sus imágenes y secuencias de comandos individuales. Esto significa que sus valiosos recursos se conservan para sus visitantes reales.
- Control de navegación: desea que los motores de búsqueda encuentren las páginas más importantes de su sitio. Puede desviar el acceso a ciertas páginas para controlar qué páginas ven los buscadores. No se recomienda bloquear completamente los motores de búsqueda para que no vean páginas específicas.
- Sin contenido duplicado: no desea que los SERP vean ningún contenido duplicado. Puede usar sus robots para agregar una regla para evitar que los rastreadores indexen cualquier página que contenga contenido duplicado.
Robots.txt Sin índice vs. No permitido
Ya sabe que robots.txt no es compatible con la regla noindex. Todavía puede asegurarse de que los motores de búsqueda no indexen una página específica mediante el uso de una metaetiqueta noindex. Los bots aún podrán acceder a su página, pero los robots sabrán por su etiqueta que su página no debe indexarse ni mostrarse en los SERP. Como etiqueta general de noindex, la regla de rechazo suele ser efectiva. Una vez que haya agregado esta etiqueta a su archivo robots.txt, los bots no podrán rastrear su página. Por ejemplo:

Si su página ya está vinculada a otras páginas mediante enlaces externos e internos, los bots aún pueden indexar su página utilizando la información recibida de otros sitios web o páginas. Si su página no está permitida con la etiqueta noindex, los robots nunca verán la etiqueta. Esto puede hacer que tu página aparezca en las SERP de todos modos.
Uso de comodines y expresiones regulares
Ahora debería comprender bastante bien el archivo robots.txt y cómo se utiliza. También necesita saber acerca de los comodines porque puede implementarlos dentro de su archivo robots.txt. Puede elegir entre dos tipos diferentes de comodines. Puede utilizar caracteres comodín para hacer coincidir cualquier secuencia de caracteres que desee. Este tipo de comodín es una excelente solución si tiene alguna URL que siga el mismo patrón. Un buen ejemplo es usar un comodín para impedir el rastreo desde cualquier página de filtro con un signo de interrogación en la URL.
El comodín $ coincide con el final de la URL. Un buen ejemplo es si desea asegurarse de que su archivo robots.txt no permitirá que los bots accedan a sus archivos PDF. Todo lo que tienes que hacer es agregar una regla. Su archivo robots.txt permitirá que todos los bots de agentes de usuario rastreen su sitio. Al mismo tiempo, se rechazará cualquier página que contenga el final .pdf.
Errores que debes evitar
Puede usar su archivo robots.txt para realizar una amplia gama de acciones de muchas maneras diferentes. Comprender el uso correcto de su archivo es imprescindible. No usar su archivo robots.txt correctamente puede convertirse fácilmente en un desastre de SEO. Los errores más comunes que debe evitar incluyen:
El buen contenido nunca debe ser bloqueado
Si tiene la intención de utilizar una etiqueta noindex o un archivo robots.txt para la presentación pública, es fundamental que ninguno de sus buenos contenidos esté bloqueado. Este tipo de error es extremadamente común y dañará tus resultados de SEO. Asegúrese de revisar sus páginas minuciosamente tanto para las reglas de rechazo como para las etiquetas sin índice para proteger sus esfuerzos de SEO.
Sensibilidad de mayúsculas y minúsculas
Recuerde que su archivo robots.txt distingue entre mayúsculas y minúsculas. Esto significa que su archivo de robots debe crearse correctamente. Siempre debe nombrar su archivo de robots robots.txt en minúsculas o no funcionará. Por ejemplo:

(Crédito de la imagen: Search Engine Land)
Uso excesivo de Crawl-Delay
El uso excesivo de su directiva para el retraso del rastreo es una idea excepcionalmente mala. Esto limitará la cantidad de páginas que los bots pueden rastrear. Si tiene un sitio web muy pequeño, esto podría funcionar. Si su sitio web es bastante grande, se está perjudicando al evitar un flujo sólido de tráfico y buenas clasificaciones. Tenga cuidado con la frecuencia con la que utiliza el retardo de rastreo.
Esperamos que este artículo le haya resultado útil.
Si desea obtener más información interesante sobre el estado de su sitio, obtener recomendaciones y alertas personales, escanee su sitio web por Diib. Solo toma 60 segundos.
Prevención de la indexación de contenido con Robots.txt
La mejor manera de ayudar a evitar que los bots rastreen directamente una de sus páginas es prohibir la página. Bajo ciertas circunstancias, esto no va a funcionar. Esto incluye cualquier página con un enlace a una fuente externa. Los bots podrán usar su enlace para acceder e indexar su página. Si el bot es ilegítimo, no podrá evitar que rastree e indexe su contenido.
Proteger el contenido privado con su archivo Robots.txt
Incluso si aleja a los bots del contenido privado, incluidas las páginas de agradecimiento o los archivos PDF, aún se pueden indexar. Una de sus mejores opciones es poner todo su contenido privado detrás del inicio de sesión y junto con la directiva de rechazo. Tenga en cuenta que los visitantes de su sitio tendrán que realizar un paso adicional. La ventaja es que todo su contenido permanecerá seguro.
¡Diib se asegura de que los archivos txt de su robot funcionen!
Diib Digital le brinda la información más reciente sobre la salud y la efectividad de sus archivos robot.txt. No permita que Google desvíe su tráfico, lo que generará altas tasas de rebote. Estas son algunas de las características de nuestro panel de usuario que pueden ayudar:
- Proporcione alertas personalizadas , que lo mantienen informado sobre el estado de su sitio web y cualquier cambio en los algoritmos de Google que pueda afectar sus archivos robot.txt.
- Objetivos con sugerencias personalizadas sobre formas de mejorar la compatibilidad con dispositivos móviles, el estado del sitio web y el tráfico orgánico.
- Información no solo sobre el estado de su propio sitio web, sino también sobre el de sus principales competidores.
- Le permite sincronizar su perfil de Facebook , brindándole información sobre los detalles de su campaña en las redes sociales. Cosas como el rendimiento de publicaciones específicas, la demografía de los usuarios, la mejor hora del día para publicar y las conversiones.
- Una sesión colaborativa mensual con un experto en crecimiento de Diib que puede ayudarlo a ajustar sus esfuerzos de SEO móvil y guiarlo hacia el crecimiento y el éxito.
Llame hoy al 800-303-3510 o haga clic aquí para obtener su escaneo gratuito de 60 sitios web y obtener más información sobre sus fortalezas y debilidades de SEO.