
Was ist eine Robots-TXT-Datei? Alles und mehr zulassen
Veröffentlicht: 2020-11-19Was ist eine Robots Txt-Datei?
Die robots.text-Datei ist eine Schlüsselmethode, um Suchmaschinen die Bereiche mitzuteilen, die sie auf Ihrer Website nicht besuchen können. Die grundlegende Funktionalität dieser Textdatei wird von allen großen Suchmaschinen unterstützt. Die zusätzlichen Regeln, auf die einige Suchmaschinen reagieren, können äußerst nützlich sein. Es gibt eine Vielzahl von Möglichkeiten, wie Sie robots.txt-Dateien auf Ihrer Website verwenden können. Obwohl der Prozess ziemlich einfach erscheint, müssen Sie vorsichtig sein. Wenn Sie einen Fehler machen, können Sie Ihrer Website erheblichen Schaden zufügen.
Suchmaschinen-Spider lesen die robots.txt-Datei und halten sich an eine sehr strenge Syntax. Viele Menschen bezeichnen diese Spinnen als Roboter, woher der Name stammt. Die für die Syntax verwendete Datei muss einfach sein, da sie von Computern lesbar sein muss. Das heißt, es gibt absolut keinen Raum für Fehler. Alles ist entweder eins oder null, ohne Platz für irgendetwas dazwischen. Die robots.txt-Datei wird auch als Robots Exclusion Protocol bezeichnet.
Dieser Name entstand durch eine Gruppe früher Spider-Entwickler für die Suchmaschinen. Zu diesem Zeitpunkt hat keine Standardorganisation die Robots-Textdatei als offiziellen Standard festgelegt. Trotzdem halten sich alle großen Suchmaschinen an diese Datei.
Was macht eine Robots-Textdatei?
Das Web wird von Suchmaschinen durch das Spidern von Seiten indiziert. Links werden befolgt, um die Suchmaschinen von Seite A zu Seite B zu leiten und so weiter. Bevor die von den Suchmaschinen gesendeten Spider eine Seite für eine Domain durchsuchen, die in der Vergangenheit nicht gefunden wurde, wird die robots.txt-Datei für die Domain geöffnet. Dadurch wird der Suchmaschine mitgeteilt, welche URLs auf der Website nicht indexiert werden dürfen.
In den meisten Fällen werden die robot.txt-Inhalte von den Suchmaschinen zwischengespeichert. Der Cache wird im Allgemeinen mehrmals täglich aktualisiert. Das bedeutet, dass alle Änderungen, die Sie vornehmen, ziemlich schnell angezeigt werden.
Zusammenstellen Ihrer Robots.txt-Datei
Das Zusammenstellen einer sehr einfachen robots.txt-Datei ist ziemlich einfach. Sie sollten keine Schwierigkeiten mit dem Prozess haben. Sie benötigen lediglich einen einfachen Texteditor wie Notepad. Öffnen Sie zunächst eine Seite. Speichern Sie nun Ihre leere Seite als robots.txt. Gehen Sie zu Ihrem cPanel und melden Sie sich an. Suchen Sie den Ordner market public_html, um auf das Stammverzeichnis Ihrer Website zuzugreifen. Öffnen Sie diesen Ordner und ziehen Sie Ihre Datei hinein. Sie müssen sicherstellen, dass Sie die richtigen Berechtigungen für Ihre Datei festgelegt haben.
Da Sie der Eigentümer der Website sind, müssen Sie Ihre Datei schreiben, lesen und bearbeiten. Sie sollten niemandem erlauben, diese Aktionen in Ihrem Namen auszuführen. Der in Ihrer Datei angezeigte Berechtigungscode sollte 0644 lauten. Wenn dieser nicht angezeigt wird, muss er geändert werden. Sie können dies erreichen, indem Sie auf die Datei klicken und die Dateiberechtigung auswählen.
Robots.txt-Syntax
In Ihrer robots.txt-Datei sind zahlreiche Abschnitte mit Anweisungen enthalten. Jeder beginnt mit dem angegebenen Benutzeragenten. Dies ist der Name des Crawl-Bots, mit dem Ihr Code kommuniziert. Sie haben zwei verschiedene verfügbare Optionen. Die erste besteht darin, alle Suchmaschinen gleichzeitig anzusprechen, indem ein Platzhalter verwendet wird. Sie können auch eine bestimmte Suchmaschine individuell ansprechen. Sobald ein Bot zum Crawlen einer Website eingesetzt wurde, wird er sofort von den Blöcken angezogen.
Ihre User-Agent-Anweisung sind die ersten paar Zeilen für jeden Block. Dies wird einfach als User-Agent bezeichnet und lokalisiert den spezifischen Bot. Bestimmte Bot-Namen werden von Ihrem User-Agent abgeglichen. Wenn Sie dem Googlebot mitteilen müssen, was er tun soll, beginnen Sie mit dem User-Agent: Googlebot. Suchmaschinen werden immer versuchen, bestimmte Richtlinien mit der engsten Beziehung zu ihnen zu lokalisieren. Hier sind ein paar Beispiele für User-Agent-Anweisungen:
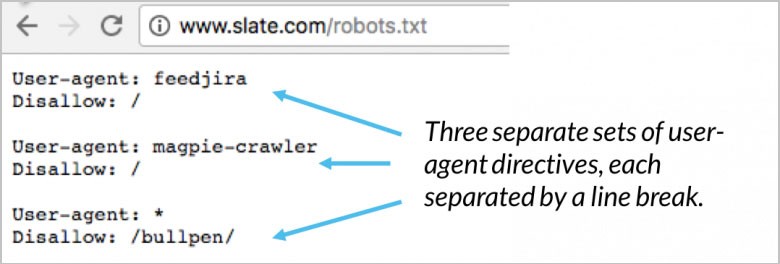
(Bildnachweis: Moz)
Ein gutes Beispiel ist, wenn Sie zwei verschiedene Direktiven verwenden. Wenn Ihre erste Anweisung für Googlebot-Video und Ihre zweite für Bingbot ist, ist der Prozess wie folgt. Der erste Bot mit Bingbot als User-Agent folgt Ihren Anweisungen. Ihre Googlebot-Video-Anweisung wird übergangen und der Bot beginnt mit der Suche nach einer spezifischeren Anweisung.
Testen Sie die SEO und Leistung Ihrer Website in 60 Sekunden!
Gutes Website-Design ist entscheidend für das Besucherengagement und die Conversions, aber eine langsame Website oder Leistungsfehler können dazu führen, dass selbst die am besten gestaltete Website unterdurchschnittlich abschneidet. Diib ist eines der besten Website-Performance- und SEO-Monitoring-Tools der Welt. Diib nutzt die Kraft von Big Data, um Ihnen dabei zu helfen, Ihren Traffic und Ihre Rankings schnell und einfach zu steigern. Wie in Entrepreneur!
- Einfach zu bedienendes automatisiertes SEO-Tool
- Keyword- und Backlink-Überwachung + Ideen
- Gewährleistet Geschwindigkeit, Sicherheit, + Core Vitals-Tracking
- Schlägt intelligent Ideen zur Verbesserung der SEO vor
- Über 250.000.000 globale Mitglieder
- Eingebautes Benchmarking und Konkurrenzanalyse
Wird von über 250.000 Unternehmen und Organisationen verwendet:




Synchronisiert mit 

Host-Richtlinie
Nur Yandex unterstützt derzeit die Host-Richtlinie. Es gibt einige Spekulationen, dass diese Richtlinie auch von Google unterstützt wird. Dadurch kann der Benutzer entscheiden, ob das www. sollte vor der URL angezeigt werden. Da der einzige bestätigte Unterstützer Yandex ist, wird es nicht empfohlen, sich auf die Host-Direktive zu verlassen. Wenn Sie nicht daran interessiert sind, Ihre aktuellen Hostnamen zu verwenden, können diese mithilfe der 301-Umleitung umgeleitet werden.
Die zweite Zeile ist robots.txt disallow. Dies ist ein Block von Anweisungen. Damit kann festgelegt werden, welche Bereiche Ihrer Website von Bots nicht aufgerufen werden sollen. Wenn Sie ein leeres Disallow auswählen, wird es zu einem Free-for-all. Dies bedeutet, dass die Bots ohne Anweisungen von Ihrer Website bestimmen können, wo sie sie besuchen möchten und wo nicht.
Sitemap-Richtlinie
Ihre Sitemap-Direktive verwendet die robots.txt-Sitemap, um Suchmaschinen mitzuteilen, wo sich Ihre XML-Sitemap befindet. Ihre nützlichste und beste Option besteht darin, jeden einzeln an die Suchmaschinen zu übermitteln, indem Sie bestimmte Webmaster-Tools verwenden. Auf diese Weise können Sie von allen eine Menge wertvoller Informationen über Ihre Website erfahren. Wenn Sie nicht viel Zeit haben, ist die Verwendung der Sitemap-Direktive eine gute Alternative. Zum Beispiel:

Sie werden interessiert sein
Wie Sie Ihr Unternehmen erfolgreich skalieren
Website-Ladegeschwindigkeit: Tools zur Optimierung
Website Health Check: Tools und Tipps
Was bedeutet UX?
(Bildnachweis: WooRank)
Robots.txt-Validator
Ein Validator ist ein Tool, das anzeigt, ob Ihre robots.txt-Datei die Web-Crawler von Google für bestimmte URLs blockiert, die sich auf Ihrer Website befinden. Ein gutes Beispiel ist die Verwendung dieses Tools zum Testen, ob der Googlebot-Image-Crawler Zugriff zum Crawlen einer Bild-URL hat, die Sie für alle Google-Bildsuchen blockieren möchten.
Robots.txt Alle zulassen
Einer Disallow-Direktive kann mit der Allow-Direktive entgegengewirkt werden. Sowohl Google als auch Bing unterstützen die Allow-Direktive. Sie können die Direktiven Disallow und Allow zusammen verwenden, um Suchmaschinen mitzuteilen, dass sie auf bestimmte Seiten oder Dateien mit einem Disallow-Verzeichnis zugreifen können. Zum Beispiel:

(Bildnachweis: DeepCrawl)
Robots.txt Google
Ab dem 1. September hat Google die Unterstützung von unveröffentlichten und nicht unterstützten Regeln für das exklusive Protokoll des Roboters eingestellt. Diese Ankündigung erfolgte im Google Webmaster-Blog. Das bedeutet, dass Google robots.txt-Dateien innerhalb einer Datei mit einem noindex-Verzeichnis nicht mehr unterstützt.
Crawl-Delay-Richtlinie
In Bezug auf das Crawlen können Yahoo, Yandex und Bing alle ein wenig triggerglücklich sein. Davon abgesehen reagieren sie auf die Crawl-Delay-Direktive. Das bedeutet, dass Sie sie für eine Weile fernhalten können.
Robots.txt-Generator
Ein robots.txt-Generator ist ein Tool, das entwickelt wurde, um Webmaster, Vermarkter und SEOs bei der Generierung einer robots.txt-Datei zu unterstützen, ohne dass viel technisches Wissen erforderlich ist. Sie müssen dennoch vorsichtig sein, denn wenn Sie eine robots.txt-Datei erstellen, kann dies einen großen Einfluss auf die Fähigkeit von Google haben, auf Ihre Website zuzugreifen, unabhängig davon, ob Sie sie mit WordPress oder einem der anderen CMS erstellt haben.

Auch wenn die Verwendung dieses Tools ziemlich einfach ist, empfiehlt es sich, sich zuerst mit den Anweisungen von Google vertraut zu machen. Wenn Ihre Implementierung nicht korrekt ist, können Suchmaschinen, einschließlich Google, Ihre gesamte Domain einschließlich der kritischen Seiten Ihrer Website nicht crawlen. Das Ergebnis kann Ihre SEO-Bemühungen erheblich beeinflussen.
Robots.txt WordPress
In den meisten Fällen finden Sie Ihre robots.txt im Stammordner Ihrer WordPress-Website. Sie müssen Ihren cPanel-Dateimanager verwenden, um Ihren Stammordner anzuzeigen, oder sich über einen FTP-Client mit Ihrer Website verbinden. Dies ist nur eine einfache Textdatei, die Sie mit Notepad öffnen können. Das folgende Bild zeigt Ihnen, wie Sie zu Ihrem Dateimanager in WordPress gelangen:
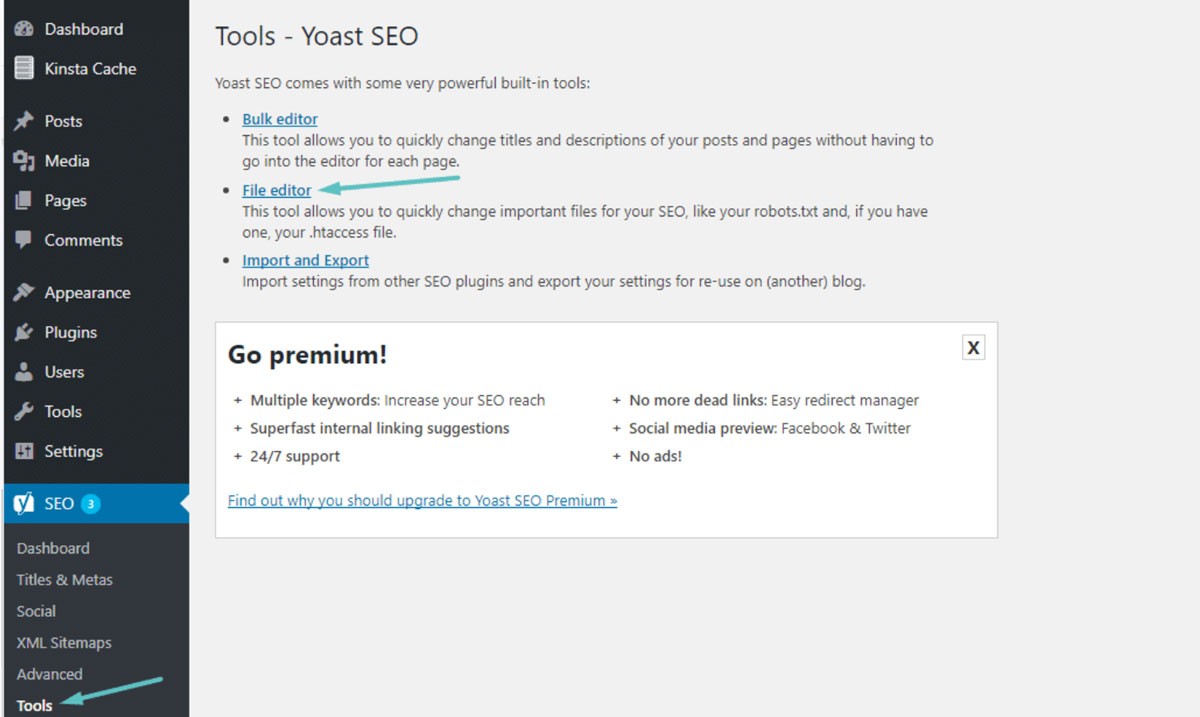
(Bildnachweis: Kinsta)
Kriechverzögerung: 10
Auf diese Weise können Sie sicherstellen, dass Suchmaschinen 10 Sekunden warten, bevor sie Ihre Website crawlen oder nachdem sie zum Crawlen erneut auf Ihre Website zugegriffen haben. Das Konzept ist fast das gleiche, aber je nach Suchmaschine gibt es einen kleinen Unterschied.
Warum Robots.txt verwenden?
Robots.txt ist nicht erforderlich, um eine erfolgreiche Website zu haben. Auch wenn Sie keine haben, können Sie mit einer korrekt funktionierenden Website ein gutes Ranking erzielen. Bevor Sie sich entscheiden, keine robots.txt-Datei zu verwenden, bedenken Sie einige wichtige Vorteile, darunter:
- Schützen Sie private Dateien: Sie können Bots von Ihren privaten Ordnern fernhalten, um sicherzustellen, dass sie viel schwieriger zu finden und zu indizieren sind.
- Sitemap angeben: Sie können den Speicherort Ihrer Sitemap angeben. Die Angabe des Standorts für Crawler ist wichtig, da Sie möchten, dass sie ihn durchsuchen können.
- Ressourcenkontrolle: Sie können sicherstellen, dass Ihre Ressourcen unter Kontrolle bleiben. Jedes Mal, wenn Ihre Website von einem Bot gecrawlt wird, werden Ihre Serverressourcen und Bandbreite verwendet. Wenn Sie eine Website mit vielen Seiten und massivem Inhalt haben, wie z. B. eine E-Commerce-Website, können Ihre Ressourcen aufgrund einer großen Anzahl von Seiten extrem schnell erschöpft sein. Die Verwendung einer robots.txt-Datei stellt sicher, dass es für Bots schwieriger ist, auf Ihre individuellen Bilder und Skripte zuzugreifen. So bleiben Ihre wertvollen Ressourcen für Ihre echten Besucher erhalten.
- Navigationssteuerung: Sie möchten, dass Suchmaschinen die wichtigsten Seiten Ihrer Website finden. Sie können den Zugriff auf bestimmte Seiten umleiten, um zu steuern, welche Seiten die Suchenden sehen. Es wird nicht empfohlen, die Suchmaschinen vollständig daran zu hindern, bestimmte Seiten anzuzeigen.
- Kein doppelter Inhalt: Sie möchten nicht, dass SERPs doppelten Inhalt sehen. Sie können Ihre Roboter verwenden, um eine Regel hinzuzufügen, um Crawler daran zu hindern, Seiten mit doppeltem Inhalt zu indizieren.
Robots.txt Kein Index vs. Nicht zulassen
Sie wissen bereits, dass robots.txt für die noindex-Regel nicht unterstützt wird. Sie können immer noch sicherstellen, dass die Suchmaschinen eine bestimmte Seite nicht durch die Verwendung eines noindex-Meta-Tags indizieren. Die Bots können weiterhin auf Ihre Seite zugreifen, aber die Roboter wissen anhand Ihres Tags, dass Ihre Seite nicht indiziert oder in den SERPs angezeigt werden soll. Als allgemeines Noindex-Tag ist die Disallow-Regel oft wirksam. Sobald Sie dieses Tag zu Ihrer robots.txt hinzugefügt haben, werden Bots daran gehindert, Ihre Seite zu crawlen. Zum Beispiel:

Wenn Ihre Seite bereits über externe und interne Links mit anderen Seiten verknüpft ist, kann Ihre Seite dennoch von den Bots mithilfe von Informationen indexiert werden, die sie von anderen Websites oder Seiten erhalten. Wenn Ihre Seite mit dem noindex-Tag nicht zugelassen wird, wird das Tag niemals von den Robotern gesehen. Dies kann dazu führen, dass Ihre Seite trotzdem in den SERPs erscheint.
Verwendung von Platzhaltern und regulären Ausdrücken
Sie sollten jetzt ein ziemlich gutes Verständnis der robots.txt-Datei und ihrer Verwendung haben. Sie müssen sich auch mit Wildcards auskennen, da Sie diese in Ihrer robots.txt implementieren können. Sie können zwischen zwei verschiedenen Arten von Platzhaltern wählen. Sie können Platzhalterzeichen verwenden, um jede gewünschte Zeichenfolge abzugleichen. Diese Art von Platzhaltern ist eine ausgezeichnete Lösung, wenn Sie URLs haben, die demselben Muster folgen. Ein gutes Beispiel ist die Verwendung eines Platzhalters, um das Crawlen von Filterseiten mit einem Fragezeichen in der URL zu verhindern.
Der Platzhalter $ entspricht dem Ende der URL. Ein gutes Beispiel ist, wenn Sie sicherstellen möchten, dass Ihre robots.txt-Datei Bots den Zugriff auf Ihre PDF-Dateien verbietet. Sie müssen lediglich eine Regel hinzufügen. Ihre robots.txt-Datei erlaubt dann allen User-Agent-Bots, Ihre Website zu crawlen. Gleichzeitig werden alle Seiten, die .pdf-Endungen enthalten, nicht zugelassen.
Fehler, die Sie vermeiden sollten
Sie können Ihre robots.txt-Datei verwenden, um eine Vielzahl von Aktionen auf viele verschiedene Arten auszuführen. Es ist unerlässlich, dass Sie verstehen, wie Sie Ihre Datei richtig verwenden. Wenn Sie Ihre robots.txt-Datei nicht korrekt verwenden, kann dies leicht zu einem SEO-Desaster werden. Zu den häufigsten Fehlern, die Sie vermeiden müssen, gehören:
Gute Inhalte sollten niemals blockiert werden
Wenn Sie beabsichtigen, ein noindex-Tag oder eine robots.txt-Datei für die öffentliche Präsentation zu verwenden, ist es wichtig, dass keiner Ihrer guten Inhalte blockiert wird. Diese Art von Fehler ist sehr häufig und schadet Ihren SEO-Ergebnissen. Stellen Sie sicher, dass Sie Ihre Seiten gründlich auf Sperrregeln und Noindex-Tags überprüfen, um Ihre SEO-Bemühungen zu schützen.
Groß-/Kleinschreibung
Denken Sie daran, dass Ihre robots.txt zwischen Groß- und Kleinschreibung unterscheidet. Das bedeutet, dass Ihre Robots-Datei korrekt erstellt werden muss. Benennen Sie Ihre Robots-Datei immer in Kleinbuchstaben robots.txt, sonst funktioniert es nicht. Zum Beispiel:

(Bildnachweis: Search Engine Land)
Überbeanspruchung der Crawl-Verzögerung
Eine übermäßige Verwendung Ihrer Direktive für die Crawl-Verzögerung ist eine äußerst schlechte Idee. Dadurch wird die Anzahl der Seiten begrenzt, die die Bots crawlen können. Wenn Sie eine sehr kleine Website haben, könnte dies funktionieren. Wenn Ihre Website ziemlich groß ist, schaden Sie sich selbst, indem Sie einen soliden Verkehrsfluss und gute Platzierungen verhindern. Achten Sie darauf, wie oft Sie die Crawl-Verzögerung verwenden.
Wir hoffen, dass Sie diesen Artikel nützlich fanden.
Wenn Sie mehr Interessantes über den Zustand Ihrer Website erfahren möchten, persönliche Empfehlungen und Benachrichtigungen erhalten möchten, scannen Sie Ihre Website von Diib. Es dauert nur 60 Sekunden.
Verhindern der Inhaltsindizierung mit Robots.txt
Der beste Weg, um zu verhindern, dass Bots direkt eine Ihrer Seiten crawlen, besteht darin, die Seite zu verbieten. Unter bestimmten Umständen wird dies nicht funktionieren. Dazu gehören alle Seiten mit einem Link zu einer externen Quelle. Die Bots können Ihren Link verwenden, um auf Ihre Seite zuzugreifen und sie zu indizieren. Wenn der Bot illegitim ist, können Sie ihn nicht daran hindern, Ihre Inhalte zu crawlen und zu indizieren.
Schützen Sie private Inhalte mit Ihrer Robots.txt
Selbst wenn Sie Bots von privaten Inhalten wegleiten, einschließlich Dankesseiten oder PDFs, können sie dennoch indiziert werden. Eine Ihrer besten Optionen besteht darin, alle Ihre privaten Inhalte hinter dem Login und neben der Disallow-Anweisung zu platzieren. Denken Sie daran, dass Ihre Website-Besucher einen zusätzlichen Schritt ausführen müssen. Der Vorteil ist, dass alle Ihre Inhalte sicher bleiben.
Diib stellt sicher, dass Ihre Robot-txt-Dateien funktionieren!
Diib Digital gibt Ihnen die neuesten Informationen über den Zustand und die Wirksamkeit Ihrer robot.txt-Dateien. Lassen Sie Google Ihren Traffic nicht fehlleiten, was zu hohen Absprungraten führt. Hier sind einige der Funktionen unseres Benutzer-Dashboards, die Ihnen helfen können:
- Bieten Sie benutzerdefinierte Benachrichtigungen an, die Sie über den Zustand Ihrer Website und alle Änderungen an den Google-Algorithmen informieren, die sich auf Ihre robot.txt-Dateien auswirken können.
- Ziele mit maßgeschneiderten Vorschlägen, wie Sie Ihre mobile Benutzerfreundlichkeit, Website-Gesundheit und organischen Traffic verbessern können.
- Einblicke nicht nur in den Zustand Ihrer eigenen Website, sondern auch in den Ihrer wichtigsten Konkurrenten.
- Ermöglicht es Ihnen, Ihr Facebook-Profil zu synchronisieren und Ihnen Einblicke in die Besonderheiten Ihrer Social-Media-Kampagne zu geben. Dinge wie spezifische Post-Performance, Demografie der Benutzer, beste Tageszeit zum Posten und Conversions.
- Eine monatliche gemeinsame Sitzung mit einem Diib-Wachstumsexperten, die Ihnen helfen kann, Ihre mobilen SEO-Bemühungen zu optimieren und Sie zu Wachstum und Erfolg zu führen.
Rufen Sie noch heute unter 800-303-3510 an oder klicken Sie hier, um Ihren kostenlosen 60-Website-Scan zu erhalten und mehr über Ihre SEO-Stärken und -Schwächen zu erfahren.