
Che cos'è un file txt di robot? Consenti tutto e di più
Pubblicato: 2020-11-19Che cos'è un file txt di Robots?
Il file robots.text è un metodo chiave per indicare ai motori di ricerca le aree in cui non possono accedere al tuo sito. La funzionalità di base fornita da questo file di testo è supportata da tutti i principali motori di ricerca. Le regole extra a cui risponderanno alcuni motori di ricerca possono essere estremamente utili. Esiste un'ampia gamma di modi in cui puoi utilizzare i file robots.txt sul tuo sito. Sebbene il processo appaia abbastanza semplice, devi stare attento. Se commetti un errore, puoi causare danni significativi al tuo sito web.
Gli spider dei motori di ricerca leggono il file robots.txt e aderiscono a una sintassi molto rigida. Molte persone si riferiscono a questi ragni come robot, da cui ha avuto origine il nome. Il file utilizzato per la sintassi deve essere semplice perché deve essere leggibile dai computer. Ciò significa che non c'è assolutamente spazio per gli errori. Tutto è uno o zero senza spazio per nulla nel mezzo. Il file robots.txt viene anche chiamato protocollo di esclusione dei robot.
Questo nome ha avuto origine da un gruppo di primi sviluppatori di spider per i motori di ricerca. Al momento, nessuna organizzazione standard ha impostato il file di testo robots come standard ufficiale. Nonostante ciò, tutti i principali motori di ricerca aderiscono a questo file.
Cosa fa un file di testo di un robot?
Il web è indicizzato dai motori di ricerca tramite spidering pages. I collegamenti sono seguiti per guidare i motori di ricerca dal sito A al B e così via. Prima che gli spider inviati dai motori di ricerca eseguano la scansione di qualsiasi pagina di un dominio non incontrata in passato, viene aperto il file robots.txt per il dominio. Questo è ciò che informa il motore di ricerca quali URL sul sito Web non possono essere indicizzati.
Nella maggior parte dei casi, il contenuto del robot.txt viene memorizzato nella cache dai motori di ricerca. La cache viene generalmente aggiornata più volte al giorno. Ciò significa che tutte le modifiche apportate vengono visualizzate abbastanza rapidamente.
Mettere insieme il tuo file Robots.txt
Mettere insieme un file robots.txt molto semplice è abbastanza semplice. Non dovresti avere difficoltà con il processo. Tutto ciò di cui avrai bisogno è un semplice editor di testo come Blocco note. Inizia aprendo una pagina. Ora salva la tua pagina vuota come robots.txt. Vai al tuo cPanel e accedi. Trova la cartella market public_html per accedere alla directory principale del tuo sito web. Apri questa cartella, quindi trascina il file. Devi assicurarti di aver impostato le autorizzazioni corrette per il tuo file.
Poiché sei il proprietario del sito web, devi scrivere, leggere e modificare il tuo file. Non dovresti consentire a nessun altro di eseguire queste azioni per tuo conto. Il codice di autorizzazione visualizzato nel file dovrebbe essere 0644. Se non viene visualizzato, sarà necessario modificarlo. Puoi farlo facendo clic sul file e scegliendo il permesso del file.
Sintassi Robots.txt
Ci sono numerose sezioni di direttive contenute nel tuo file robots.txt. Ognuno inizia con lo user-agent specificato. Questo è il nome del bot di scansione con cui sta parlando il tuo codice. Hai due diverse opzioni disponibili. Il primo è indirizzare tutti i motori di ricerca contemporaneamente utilizzando un carattere jolly. Puoi anche indirizzare individualmente un motore di ricerca specifico. Una volta che un bot è stato distribuito per la scansione di un sito Web, viene immediatamente attratto dai blocchi.
La tua direttiva user-agent è le prime righe per ogni blocco. Questo viene chiamato semplicemente user-agent e individua il bot specifico. I nomi di bot specifici sono abbinati dal tuo agente utente. Se devi dire a Googlebot cosa vuoi che faccia, inizia con lo user-agent: Googlebot. I motori di ricerca cercheranno sempre di individuare determinate direttive con la relazione più stretta con esse. Ecco un paio di esempi di direttive user-agent:
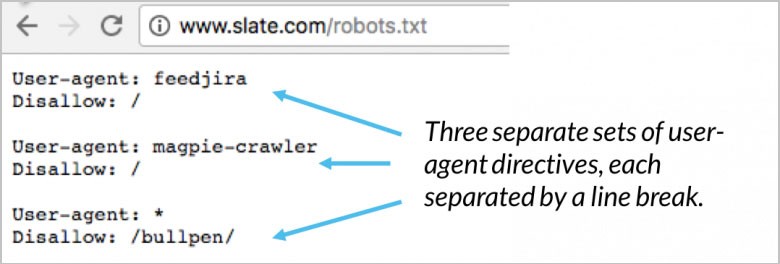
(Credito immagine: Moz)
Un buon esempio è quando si utilizzano due diverse direttive. Se la tua prima direttiva è per Googlebot-video e la seconda per Bingbot, il processo è il seguente. Il primo bot con Bingbot come user-agent seguirà le tue istruzioni. La tua direttiva Googlebot-video verrà ignorata e il bot inizierà a cercare una direttiva più specifica.
Metti alla prova la SEO e le prestazioni del tuo sito in 60 secondi!
Un buon design del sito Web è fondamentale per il coinvolgimento e le conversioni dei visitatori, ma un sito Web lento o errori di prestazioni possono compromettere le prestazioni anche del sito Web meglio progettato. Diib è uno dei migliori strumenti di monitoraggio delle prestazioni del sito Web e SEO al mondo. Diib utilizza la potenza dei big data per aiutarti ad aumentare rapidamente e facilmente il traffico e le classifiche. Come si vede in Imprenditore!
- Strumento SEO automatizzato facile da usare
- Monitoraggio parole chiave e backlink + idee
- Garantisce velocità, sicurezza, + monitoraggio di Core Vitals
- Suggerisce in modo intelligente idee per migliorare la SEO
- Oltre 250.000.000 membri globali
- Benchmarking integrato e analisi della concorrenza
Utilizzato da oltre 250.000 aziende e organizzazioni:




Sincronizza con 

Direttiva ospite
Solo Yandex sta attualmente supportando la direttiva host. Ci sono alcune speculazioni sul fatto che questa direttiva sia supportata anche da Google. Questo è ciò che consente all'utente di decidere se il www. dovrebbe essere mostrato prima dell'URL. Poiché l'unico sostenitore confermato è Yandex, non è consigliabile fare affidamento sulla direttiva host. Se non sei interessato a utilizzare i tuoi nomi host attuali, possono essere reindirizzati utilizzando il reindirizzamento 301.
La seconda riga è robots.txt non consentito. Questo è un blocco di direttive. Questo può essere utilizzato per specificare a quali aree del tuo sito Web non devono accedere i bot. Se selezioni un disallow vuoto, diventa gratuito per tutti. Ciò significa che i bot possono determinare dove fanno e non vogliono visitare senza direttive dal tuo sito.
Direttiva sulla mappa del sito
La tua direttiva sulla mappa del sito utilizza la mappa del sito robots.txt per indicare ai motori di ricerca dove si trova la tua mappa del sito XML. La tua opzione più utile e migliore è inviarli individualmente ai motori di ricerca utilizzando strumenti specifici per i webmaster. Ciò ti consentirà di apprendere una grande quantità di informazioni preziose sul tuo sito Web da tutti loro. Se non hai molto tempo, l'utilizzo della direttiva sitemap è una buona alternativa. Per esempio:

Sarai interessato
Come scalare con successo il tuo business
Velocità di caricamento del sito Web: strumenti per l'ottimizzazione
Controllo dello stato del sito Web: strumenti e suggerimenti
Cosa significa UX?
(Credito immagine: WooRank)
Validatore Robots.txt
Un validatore è uno strumento per mostrare se il tuo file robots.txt sta bloccando i web crawler di Google per URL specifici che si trovano sul tuo sito web. Un buon esempio è l'utilizzo di questo strumento per verificare se il crawler Googlebot-Image ha accesso per eseguire la scansione dell'URL di un'immagine che desideri venga bloccato da tutte le ricerche di immagini di Google.
Robots.txt Consenti tutto
Una direttiva disallow può essere contrastata utilizzando la direttiva Allow. Sia Google che Bing supportano la direttiva Consenti. Puoi utilizzare le direttive Disallow e Allow insieme per far sapere ai motori di ricerca che possono accedere a determinate pagine o file con una directory Disallow. Per esempio:

(Credito immagine: DeepCrawl)
Robots.txt Google
A partire dal 1 settembre, Google ha smesso di supportare le regole non pubblicate e non supportate per il protocollo esclusivo del robot. Questo annuncio è stato fatto sul blog di Google Webmaster. Ciò significa che Google non supporta più i file robots.txt all'interno di un file con una directory noindex.
Direttiva Crawl-Delay
Per quanto riguarda la scansione, Yahoo, Yandex e Bing possono essere tutti un po' felici. Detto questo, rispondono alla direttiva crawl-delay. Ciò significa che puoi tenerli lontani per un po'.
Generatore Robots.txt
Un generatore robots.txt è uno strumento creato per assistere webmaster, marketer e SEO nella generazione di un file robots.txt senza che siano necessarie molte conoscenze tecniche. Devi comunque stare attento perché quando crei un file robots.txt può avere un impatto importante sulla capacità di Google di accedere al tuo sito Web indipendentemente dal fatto che tu lo abbia creato utilizzando WordPress o uno degli altri CMS.

Anche se l'utilizzo di questo strumento è abbastanza semplice, il consiglio è di familiarizzare prima con le istruzioni fornite da Google. Se la tua implementazione non è corretta, i motori di ricerca, incluso Google, non saranno in grado di eseguire la scansione dell'intero dominio, comprese le pagine critiche del tuo sito web. Il risultato può avere un impatto significativo sui tuoi sforzi SEO.
Robots.txt WordPress
Nella maggior parte dei casi, puoi trovare il tuo robots.txt nella cartella principale del tuo sito Web WordPress. Dovrai utilizzare il tuo file manager cPanel per visualizzare la tua cartella principale o connetterti al tuo sito Web tramite un client FTP. Questo è solo un semplice file di testo che potrai aprire usando Blocco note. L'immagine seguente mostra come accedere al tuo file manager su WordPress:
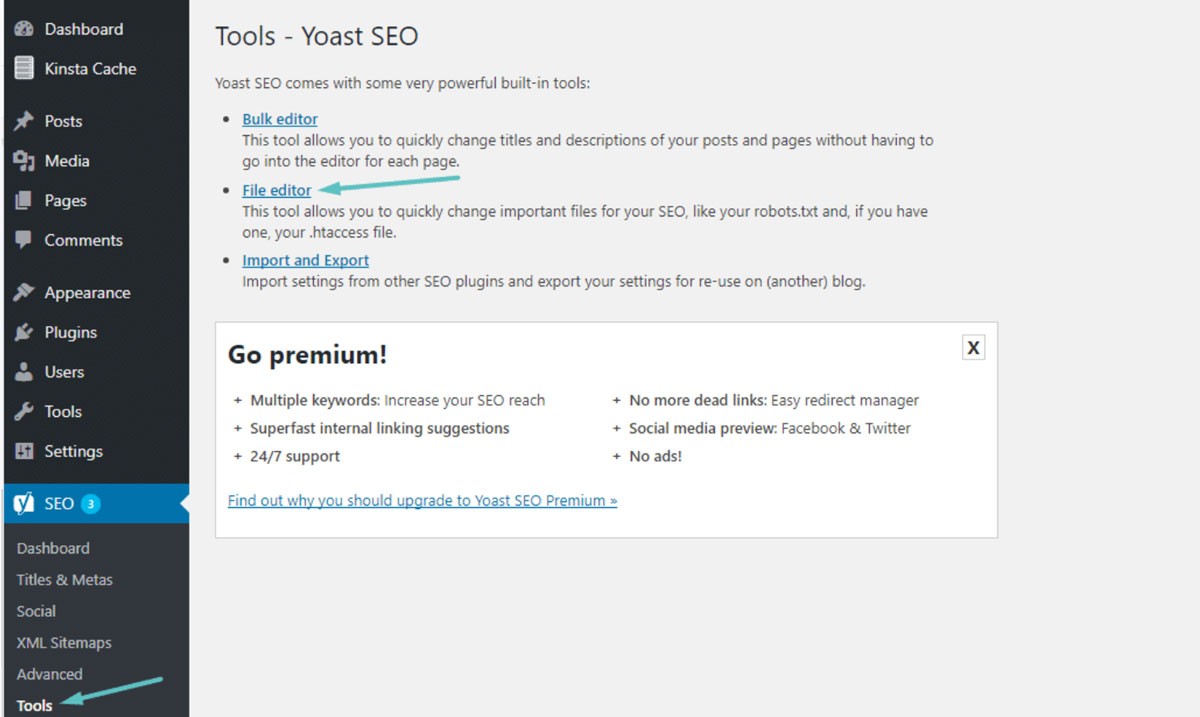
(Credito immagine: Kinsta)
Ritardo di scansione: 10
Ciò ti consente di assicurarti che i motori di ricerca attendano 10 secondi prima di eseguire la scansione del tuo sito Web o dopo aver effettuato nuovamente l'accesso al tuo sito Web per la scansione. Il concetto è quasi lo stesso ma c'è una leggera differenza a seconda del motore di ricerca specifico.
Perché usare Robots.txt?
Robots.txt non è necessario per avere un sito web di successo. Anche se non ne possiedi uno, puoi ottenere un buon posizionamento con un sito web correttamente funzionante. Prima di decidere di non utilizzare un robots.txt, tieni presente che ci sono alcuni vantaggi chiave tra cui:
- Mantieni i file privati al sicuro: puoi tenere i bot lontani dalle tue cartelle private per assicurarti che siano molto più difficili da individuare e indicizzare.
- Specifica la mappa del sito: puoi specificare la posizione della mappa del sito. Fornire ai crawler la posizione è importante perché vuoi che possano scansionarla.
- Controllo delle risorse: puoi assicurarti che le tue risorse rimangano sotto controllo. Ogni volta che un bot esegue la scansione del tuo sito Web, le risorse del tuo server e la larghezza di banda vengono utilizzate. Se hai un sito Web con molte pagine e contenuti enormi come un sito di e-commerce, le tue risorse possono essere esaurite in modo estremamente rapido a causa di un gran numero di pagine. L'utilizzo di un file robots.txt garantisce che sia più difficile per i bot accedere alle tue singole immagini e script. Ciò significa che le tue preziose risorse vengono conservate per i tuoi visitatori reali.
- Controllo della navigazione: vuoi che i motori di ricerca trovino le pagine più importanti del tuo sito. Puoi deviare l'accesso a determinate pagine per controllare quali pagine vedono gli utenti. Non è consigliabile bloccare completamente i motori di ricerca dalla visualizzazione di pagine specifiche.
- Nessun contenuto duplicato: non vuoi che le SERP vedano alcun contenuto duplicato. Puoi utilizzare i tuoi robot per aggiungere una regola per impedire ai crawler di indicizzare le pagine che contengono contenuti duplicati.
Robots.txt Nessun indice e Disallow
Sai già che robots.txt non è supportato per la regola noindex. Puoi comunque assicurarti che i motori di ricerca non indicizzino una pagina specifica attraverso l'uso di un meta tag noindex. I bot potranno comunque accedere alla tua pagina ma i robot sapranno dal tuo tag che la tua pagina non deve essere indicizzata o mostrata nelle SERP. Come tag noindex generale, la regola di non consentire è spesso efficace. Dopo aver aggiunto questo tag al tuo robots.txt, ai bot viene impedito di eseguire la scansione della tua pagina. Per esempio:

Se la tua pagina è già collegata ad altre pagine tramite link esterni e interni, la tua pagina può comunque essere indicizzata dai bot utilizzando le informazioni ricevute da altri siti web o pagine. Se la tua pagina non è consentita utilizzando il tag noindex, il tag non verrà mai visto dai robot. Ciò può comunque comportare la visualizzazione della tua pagina nelle SERP.
Utilizzo di caratteri jolly ed espressioni regolari
Ora dovresti avere una comprensione abbastanza buona del file robots.txt e di come viene utilizzato. Devi anche conoscere i caratteri jolly perché puoi implementarli nel tuo robots.txt. Puoi scegliere tra due diversi tipi di caratteri jolly. Puoi utilizzare i caratteri jolly per abbinare qualsiasi sequenza di caratteri che desideri. Questo tipo di carattere jolly è un'ottima soluzione se hai URL che seguono lo stesso schema. Un buon esempio è l'utilizzo di un carattere jolly per impedire la scansione da qualsiasi pagina di filtro con un punto interrogativo nell'URL.
Il carattere jolly $ corrisponde alla fine dell'URL. Un buon esempio è se vuoi assicurarti che il tuo file robots.txt impedisca ai bot di accedere ai tuoi file PDF. Tutto quello che devi fare è aggiungere una regola. Il tuo file robots.txt consentirà quindi a tutti i bot user-agent di eseguire la scansione del tuo sito. Allo stesso tempo, tutte le pagine contenenti la fine del .pdf non saranno consentite.
Errori da evitare
Puoi utilizzare il tuo file robots.txt per eseguire un'ampia gamma di azioni in molti modi diversi. Comprendere l'utilizzo corretto del file è fondamentale. Il mancato utilizzo corretto del file robots.txt può facilmente diventare un disastro SEO. Gli errori più comuni che devi evitare includono:
I buoni contenuti non dovrebbero mai essere bloccati
Se intendi utilizzare un tag noindex o un file robots.txt per la presentazione pubblica, è fondamentale che nessuno dei tuoi buoni contenuti venga bloccato. Questo tipo di errore è estremamente comune e danneggerà i tuoi risultati SEO. Assicurati di controllare accuratamente le tue pagine sia per le regole di non autorizzazione che per i tag noindex per proteggere i tuoi sforzi SEO.
Sensibilità alle maiuscole
Ricorda che il tuo robots.txt fa distinzione tra maiuscole e minuscole. Ciò significa che il tuo file robots deve essere creato correttamente. Dovresti sempre nominare il tuo file robots robots.txt in tutte le lettere minuscole o non funzionerà. Per esempio:

(Credito immagine: motore di ricerca Land)
Utilizzo eccessivo del Crawl-Delay
L'uso eccessivo della direttiva per il crawl-delay è una pessima idea. Ciò limiterà il numero di pagine che i bot possono scansionare. Se hai un sito web molto piccolo, questo potrebbe funzionare. Se il tuo sito web è abbastanza grande, ti stai danneggiando impedendo un solido flusso di traffico e un buon posizionamento. Fai attenzione alla frequenza con cui usi il crawl-delay.
Ci auguriamo che tu abbia trovato utile questo articolo.
Se vuoi saperne di più sulla salute del tuo sito, ricevere consigli e avvisi personali, scansiona il tuo sito web da Diib. Ci vogliono solo 60 secondi.
Impedire l'indicizzazione dei contenuti con Robots.txt
Il modo migliore per impedire ai bot di eseguire direttamente la scansione di una delle tue pagine è impedire la pagina. In determinate circostanze, questo non funzionerà. Ciò include qualsiasi pagina con un collegamento a una fonte esterna. I bot potranno utilizzare il tuo link per accedere e indicizzare la tua pagina. Se il bot è illegittimo, non sarai in grado di impedirgli di eseguire la scansione e l'indicizzazione dei tuoi contenuti.
Protezione dei contenuti privati con il tuo Robots.txt
Anche se indirizzi i bot lontano dai contenuti privati, comprese le pagine di ringraziamento o i PDF, possono comunque essere indicizzati. Una delle tue migliori opzioni è mettere tutti i tuoi contenuti privati dietro l'accesso e insieme alla direttiva disallow. Tieni presente che i visitatori del tuo sito dovranno eseguire un passaggio aggiuntivo. Il vantaggio è che tutti i tuoi contenuti rimarranno al sicuro.
Diib assicura che i file txt del tuo robot funzionino!
Diib Digital ti fornisce le informazioni più recenti sulla salute e l'efficacia dei tuoi file robot.txt. Non lasciare che Google indirizzi in modo errato il tuo traffico, portando a frequenze di rimbalzo elevate. Ecco alcune delle funzionalità della nostra dashboard utente che possono aiutare:
- Fornisci avvisi personalizzati , che ti tengono informato sulla salute del tuo sito Web e su eventuali modifiche agli algoritmi di Google che possono influire sui file robot.txt.
- Obiettivi con suggerimenti personalizzati su come migliorare la compatibilità con i dispositivi mobili, la salute del sito Web e il traffico organico.
- Approfondimenti non solo sulla salute del tuo sito Web, ma su quella dei tuoi principali concorrenti.
- Ti consente di sincronizzare il tuo profilo Facebook , fornendoti informazioni dettagliate sulle specifiche della tua campagna sui social media. Cose come prestazioni post specifiche, dati demografici degli utenti, momento migliore della giornata per pubblicare post e conversioni.
- Una sessione collaborativa mensile con un esperto di crescita Diib che può aiutarti a mettere a punto i tuoi sforzi SEO per dispositivi mobili e guidarti verso la crescita e il successo.
Chiama oggi al numero 800-303-3510 o fai clic qui per ottenere la scansione gratuita di 60 siti Web e saperne di più sui tuoi punti di forza e di debolezza SEO.