
Die Verwirrung durchbrechen: Data Warehouse vs. Data Lake vs. Data Lakehouse
Veröffentlicht: 2022-03-11CIOs in allen Branchen stehen vor großen Herausforderungen, wenn sie darum kämpfen, die Datenflut zu nutzen. Einer davon ist, wo alle Unternehmensdaten gespeichert werden, um robuste Datenanalysen zu liefern.
Traditionell gab es zwei Speicherlösungen für Daten: Data Warehouses und Data Lakes.
Data Warehouses speichern hauptsächlich transformierte, strukturierte Daten aus Betriebs- und Transaktionssystemen und werden für schnelle komplexe Abfragen über diese historischen Daten verwendet.
Data Lakes fungieren als Dump und speichern alle Arten von Daten, einschließlich halbstrukturierter und unstrukturierter Daten. Sie ermöglichen fortschrittliche Analysen wie Streaming-Analysen für die Live-Datenverarbeitung oder maschinelles Lernen.
In der Vergangenheit war die Einführung von Data Warehouses teuer, da Sie neben den Fähigkeiten für deren Wartung sowohl den Speicherplatz als auch die Rechenressourcen bezahlen mussten. Da die Speicherkosten gesunken sind, sind Data Warehouses billiger geworden. Einige glauben, dass Data Lakes (traditionell eine kosteneffizientere Alternative) jetzt tot sind. Einige argumentieren, dass Data Lakes immer noch im Trend liegen. Währenddessen sprechen andere über eine neue, hybride Datenspeicherlösung – Data Lakehouses.
Was hat es mit jedem von ihnen auf sich? Schauen wir genau hin.
Dieser Blog untersucht die wichtigsten Unterschiede zwischen Data Warehouses, Data Lakes und Data Lakehouses, beliebte Tech-Stacks und Anwendungsfälle. Es enthält auch Tipps zur Auswahl der richtigen Lösung für Ihr Unternehmen, obwohl diese schwierig ist.
Was ist ein Data Warehouse?
Data Warehouses sind darauf ausgelegt, strukturierte, kuratierte Daten zu speichern und Datensätze in Tabellen und Spalten zu organisieren. Diese Daten stehen Benutzern für traditionelle Business Intelligence, Dashboards und Berichte leicht zur Verfügung.
Data-Warehouse-Architektur
Eine dreistufige Architektur ist der am häufigsten verwendete Ansatz zum Entwerfen von Data Warehouses. Es umfaßt:
- Unterste Ebene: Ein Staging-Bereich und der Datenbankserver des Data Warehouse, der zum Laden von Daten aus verschiedenen Quellen verwendet wird. Ein Extraktions-, Transformations- und Ladeprozess (ETL) ist ein traditioneller Ansatz, um Daten in das Data Warehouse zu übertragen
- Mittlere Ebene: Ein Server für die Online-Analyseverarbeitung (OLAP), der Daten für schnelle Berechnungen in ein mehrdimensionales Format reorganisiert
- Höchste Stufe: APIs und Frontend-Tools für die Arbeit mit Daten
Abbildung 1: Data Warehouse-Referenzarchitektur
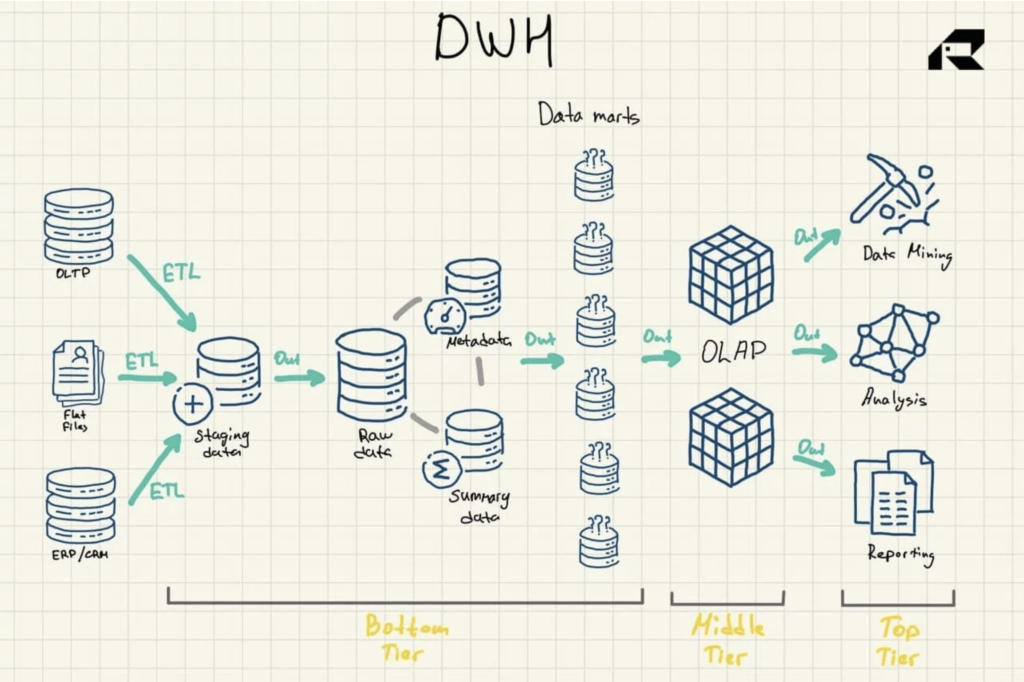
Es gibt drei weitere wichtige Komponenten eines Data Warehouse, die erwähnt werden sollten: der Data Mart, die Speicherung von Betriebsdaten und Metadaten. Data Marts gehören zur untersten Stufe. Sie speichern Teilmengen der Data-Warehouse-Daten und bedienen einzelne Geschäftsbereiche.
Betriebsdatenspeicher fungieren als Repository, das eine Momentaufnahme der aktuellsten Daten der Organisation für die Betriebsberichterstattung basierend auf einfachen Abfragen bereitstellt. Sie können als Zwischenschicht zwischen den Datenquellen und dem Data Warehouse verwendet werden.
Es gibt auch Metadaten – Daten, die die Data Warehouse-Daten beschreiben – die in speziellen Repositories gespeichert sind, ebenfalls auf der untersten Schicht.
Entwicklung und Technologien von Data Warehouses
Data Warehouses gibt es schon seit einigen Jahrzehnten.
Traditionell wurden Data Warehouses vor Ort gehostet, was bedeutete, dass Unternehmen die gesamte Hardware kaufen und Software lokal bereitstellen mussten, entweder kostenpflichtige oder Open-Source-Systeme. Sie brauchten auch ein ganzes IT-Team, um das Data Warehouse zu pflegen. Auf der positiven Seite brachten traditionelle Data Warehouses (und tun dies noch heute) eine schnelle Zeit bis zur Einsicht ohne Latenzprobleme, die vollständige Kontrolle über die Daten zusammen mit hundertprozentiger Privatsphäre und minimiertem Sicherheitsrisiko.
Angesichts der allgegenwärtigen Cloud entscheiden sich viele Unternehmen jetzt für eine Migration zu Cloud-Data-Warehouse-Lösungen, bei denen alle Daten in einer Cloud gespeichert werden. Es wird auch in einer Cloud analysiert, indem eine Art integrierte Abfrage-Engine verwendet wird.
Es gibt eine Vielzahl etablierter Cloud-Data-Warehouse-Lösungen auf dem Markt. Jeder Anbieter bietet seine einzigartigen Lagerfunktionen und unterschiedliche Preismodelle an. Beispielsweise ist Amazon Redshift als traditionelles Data Warehouse organisiert. Snowflake ist ähnlich. Microsoft Azure ist ein SQL Data Warehouse, während Google BigQuery auf einer serverlosen Architektur basiert, die im Wesentlichen Software-as-a-Service (SaaS) anbietet, und nicht Infrastruktur oder Plattform-as-a-Service wie beispielsweise Amazon Redshift.
Zu den bekannten lokalen Data-Warehouse-Lösungen gehören IBM Db2, Oracle Autonomous Database, IBM Netezza, Teradata Vantage, SAP HANA und Exasol. Sie sind auch in der Cloud verfügbar.
Cloud-basierte Data Warehouses sind offensichtlich billiger, da keine physischen Server gekauft oder bereitgestellt werden müssen. Nutzer bezahlen nur den Speicherplatz und die Rechenleistung nach Bedarf. Cloud-Lösungen sind auch viel einfacher zu skalieren oder mit anderen Diensten zu integrieren.
Data Warehouses erfüllen hochspezifische Geschäftsanforderungen mit höchster Datenqualität und schnellen Erkenntnissen und sind für lange Zeit da.
Anwendungsfälle für Data Warehouses
Data Warehouses liefern Hochgeschwindigkeits- und Hochleistungsanalysen für Petabytes und Petabytes an historischen Daten.
Sie sind grundsätzlich für BI-artige Abfragen ausgelegt. Ein Data Warehouse kann beispielsweise eine Antwort auf die Verkäufe in einem bestimmten Zeitraum, gruppiert nach Region oder Abteilung, und die jährlichen Verkaufsbewegungen geben. Wichtige Anwendungsfälle für Data Warehouses sind:
- Transaktionsberichte, um ein Bild der Geschäftsleistung zu liefern
- Ad-hoc-Analyse/Berichterstellung, um Antworten auf eigenständige und „einmalige“ geschäftliche Herausforderungen zu geben
- Data Mining, um nützliches Wissen und verborgene Muster aus Daten zu extrahieren, um komplexe reale Probleme zu lösen
- Dynamische Darstellung durch Datenvisualisierung
- Drilldown, um hierarchische Datendimensionen für Details zu durchlaufen
Strukturierte Geschäftsdaten an einem leicht zugänglichen Ort außerhalb der Betriebsdatenbanken zu haben, ist für jedes Unternehmen mit ausgereiften Daten ziemlich wichtig.
Herkömmliche Data Warehouses unterstützen jedoch keine Big-Data-Technologie.
Sie werden auch stapelweise aktualisiert, wobei Datensätze aus allen Quellen regelmäßig auf einmal verarbeitet werden, was bedeutet, dass die Daten veraltet sein können, wenn sie für die Analyse zusammengefasst werden. Der Data Lake scheint diese Einschränkungen zu lösen. Mit einem Kompromiss. Lass uns erforschen.
Was ist ein Data Lake?
Data Lakes sammeln meist unverarbeitete Rohdaten in ihrer ursprünglichen Form. Ein weiterer wesentlicher Unterschied zwischen dem Data Lake und dem Data Warehouse besteht darin, dass Data Lakes diese Daten speichern, ohne sie in logischen Beziehungen anzuordnen, die Schemas genannt werden. Auf diese Weise ermöglichen sie jedoch anspruchsvollere Analysen.
Data Lakes beziehen (i) Transaktionsdaten aus Geschäftsanwendungen wie ERP, CRM oder SCM, (ii) Dokumente im .csv- und .txt-Format, (iii) halbstrukturierte Daten wie XML-, JSON- und AVRO-Formate, (iv) Geräteprotokolle und IoT-Sensoren und (v) Bilder, Audio-, Binär- und PDF-Dateien.
Data-Lake-Architektur
Data Lakes verwenden eine flache Architektur für die Datenspeicherung. Seine Schlüsselkomponenten sind:
- Bronze-Zone für alle in den See aufgenommenen Daten. Daten werden entweder unverändert für Stapelmuster oder als aggregierte Datasets für Streaming-Workloads gespeichert
- Silberne Zone, in der Daten gefiltert und für die Exploration entsprechend den Geschäftsanforderungen angereichert werden
- Goldzone, in der kuratierte, gut strukturierte Daten für die Anwendung von BI-Tools und ML-Algorithmen gespeichert werden. Diese Zone verfügt häufig über einen Betriebsdatenspeicher, der herkömmliche Data Warehouses und Data Marts speist
- Sandbox , in der mit Daten für Hypothesenvalidierung und Tests experimentiert werden kann. Sie wird entweder als komplett separate Datenbank für Hadoop oder andere NoSQL-Technologien oder als Teil der Goldzone implementiert.
Abbildung 2: Data Lake-Referenzarchitektur
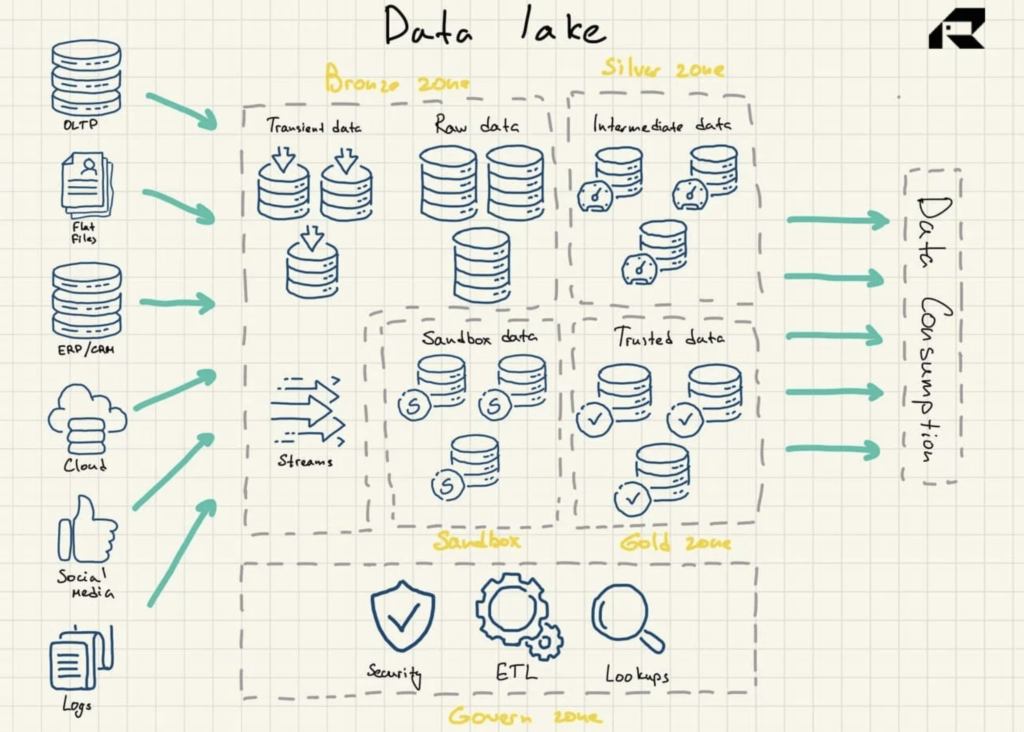
Data Lakes enthalten von Natur aus keine Analysefunktionen. Ohne sie speichern sie nur Rohdaten, die an sich nicht nützlich sind. Unternehmen bauen also Data Warehouses auf oder nutzen andere Tools zusätzlich zu Data Lakes, um Daten nutzbar zu machen.
Um sicherzustellen, dass ein Data Lake nicht zu einem Datensumpf wird, ist es wichtig, über eine effiziente Datenverwaltungsstrategie zu verfügen, die integrierte Data Governance und Metadatenverwaltung in das Data Lake-Design einbezieht. In einer idealen Welt sollten Daten, die sich in einem Data Lake befinden, katalogisiert, indiziert, validiert und für Datennutzer leicht verfügbar sein. Dies ist jedoch selten der Fall und viele Data-Lake-Projekte scheitern. Dies kann vermieden werden: Unabhängig von der Reife eines Datenteams ist es entscheidend, zumindest grundlegende Kontrollen zu installieren, um die Datenvalidierung und -qualität durchzusetzen.
Entwicklung und Technologien von Data Lakes
Der Aufstieg von Big Data in den frühen 2000er Jahren hat Unternehmen sowohl große Chancen als auch große Herausforderungen gebracht. Unternehmen brauchten neue Technologien, um diese riesigen, chaotischen und lächerlich schnell wachsenden Datensätze zu analysieren und die geschäftlichen Auswirkungen der Big Data zu erfassen.
Im Jahr 2008 entwickelte Apache Hadoop eine innovative Open-Source-Technologie zum Sammeln und Verarbeiten unstrukturierter Daten in großem Umfang und ebnete damit den Weg für Big-Data-Analysen und Data Lakes. Kurz darauf tauchte Apache Spark auf. Es war einfacher zu bedienen. Darüber hinaus bot es Funktionen zum Erstellen und Trainieren von ML-Modellen, zum Abfragen strukturierter Daten mithilfe von SQL und zum Verarbeiten von Echtzeitdaten.
Heutzutage sind Data Lakes überwiegend in der Cloud gehostete Repositories. Alle führenden Cloud-Anbieter wie AWS, Azure und Google bieten Cloud-basierte Data Lakes mit kostengünstigen Objektspeicherdiensten an. Ihre Plattformen verfügen über verschiedene Datenverwaltungsdienste, um die Bereitstellung zu automatisieren. In einem Szenario könnte ein Data Lake beispielsweise aus einem Datenspeichersystem wie dem Hadoop Distributed File System (HDFS) oder Amazon S3 bestehen, das in eine Cloud-Data-Warehouse-Lösung wie Amazon Redshift integriert ist. Diese Komponenten würden von Diensten im Ökosystem entkoppelt, zu denen Amazon EMR für die Datenverarbeitung, Amazon Glue, das den Datenkatalog und die Transformationsfunktionalität bereitstellt, der Amazon Athena-Abfragedienst oder Amazon Elasticsearch Service, der zum Erstellen eines Metadaten-Repositorys und -Index verwendet wird, gehören könnte Daten. Lokale Data Lakes sind aufgrund der üblichen Cloud-Bedenken wie Sicherheit, Datenschutz oder Latenz immer noch üblich.

Es gibt auch On-Premise-Storage-Anbieter, die einige Produkte für Data Lakes anbieten, aber ihre Data Lake-Angebote sind nicht genau definiert. Im Gegensatz zu Data Warehouses haben Data Lakes nicht viele Jahre realer Bereitstellungen hinter sich. Es gibt immer noch viel Kritik, die das Data-Lake-Konzept als verschwommen und schlecht definiert bezeichnet. Kritiker argumentieren auch, dass nur wenige Personen in einer Organisation über die Fähigkeiten (oder den Enthusiasmus für diese Angelegenheit) verfügen, um explorative Workloads gegen Rohdaten auszuführen.
Die Idee, dass Data Lakes als zentrales Repository für alle Unternehmensdaten verwendet werden sollten, muss mit Vorsicht angegangen werden, sagen sie. Es wurde auch provokativ darüber gesprochen, dass die Data Lake-Tage gezählt sind. Folgende Gründe werden genannt:
- Data Lakes können Rechenressourcen nicht effizient nach Bedarf skalieren (naja, das liegt daran, dass sie von vornherein nicht beabsichtigt sind).
- Data Lakes tragen eine große technologische Schuld, da ihre Entstehung hauptsächlich durch Marketing-Hype und nicht aus technischen Gründen getrieben wird (das gleiche ist auch mit vielen Data Warehouses passiert).
- Mit dem Aufkommen von Cloud-Data-Warehouse-Lösungen bieten Data Lakes keine signifikanten Kostenvorteile mehr (das Kostenproblem ist nicht so einfach, da es schwierig ist, die Rechenkosten vorherzusagen).
Solche Kritik ist ein fester Bestandteil jeder jüngeren Technologie. Data Lakes haben jedoch klare Anwendungsfälle wie Streaming Analytics. Und noch nicht bedrohen sie Data Warehouses. Irgendwann triumphierten Data Lakes sogar über Data Warehouses und boten breitere Analysemöglichkeiten, Kosteneffizienz und Flexibilität in Bezug auf die gespeicherten Daten. Da die Data-Warehouse-Technologien jedoch ausgereift sind, sind sich viele einig, dass es jetzt keinen offensichtlichen Gewinner gibt. Generell ist es ratsam, beide zu pflegen oder … sich für eine hybride Architektur zu entscheiden. Weiter lesen.
Data Lake-Anwendungsfälle
Die Hauptidee von Data Lakes besteht darin, Unternehmen so schnell wie möglich Zugriff auf alle verfügbaren Daten aus allen Quellen zu geben. Data Lakes geben nicht nur ein Bild von dem, was gestern passiert ist. Data Lakes speichern riesige Datenmengen und sollen es Unternehmen ermöglichen, mehr über die Gegenwart (unter Verwendung von Streaming-Analysen) und die Zukunft (unter Verwendung von Big-Data-Lösungen, einschließlich prädiktiver Analysen und maschinellem Lernen) zu erfahren. Wichtige Anwendungsfälle für Data Lakes sind:
- Ein Enterprise Data Warehouse mit Datensätzen füttern
- Durchführen von Stream-Analysen
- Umsetzung von ML-Projekten
- Erstellen Sie erweiterte Analysediagramme mit bewährten BI-Tools für Unternehmen wie Tableau oder MS Power BI
- Erstellen benutzerdefinierter Datenanalyselösungen
- Durchführung einer Ursachenanalyse, die es Datenteams ermöglicht, Probleme bis zu ihren Wurzeln zurückzuverfolgen
Mit starken Data-Engineering-Fähigkeiten, um Rohdaten in eine Analyseumgebung zu verschieben, können Data Lakes äußerst relevant sein. Sie ermöglichen es Teams, mit Daten zu experimentieren, um zu verstehen, wie sie nützlich sein können. Dies kann das Erstellen von Modellen zum Durchsuchen von Daten und das Ausprobieren verschiedener Schemas umfassen, um die Daten auf neue Weise anzuzeigen. Data Lakes ermöglichen auch das Hantieren mit Stream-Daten, die von Weblogs und IoT-Sensoren einfließen, und eignen sich nicht für einen traditionellen Data-Warehouse-Ansatz.
Kurz gesagt, Data Lakes ermöglichen es Unternehmen, Muster aufzudecken, Änderungen zu antizipieren oder potenzielle Geschäftsmöglichkeiten rund um neue Produkte oder aktuelle Prozesse zu finden. Data Lakes und Data Warehouses werden für unterschiedliche Geschäftsanforderungen verwendet und oft zusammen implementiert. Bevor wir zum nächsten Datenspeicherkonzept übergehen, lassen Sie uns kurz die wichtigsten Unterschiede zwischen dem Data Warehouse und dem Data Lake zusammenfassen.
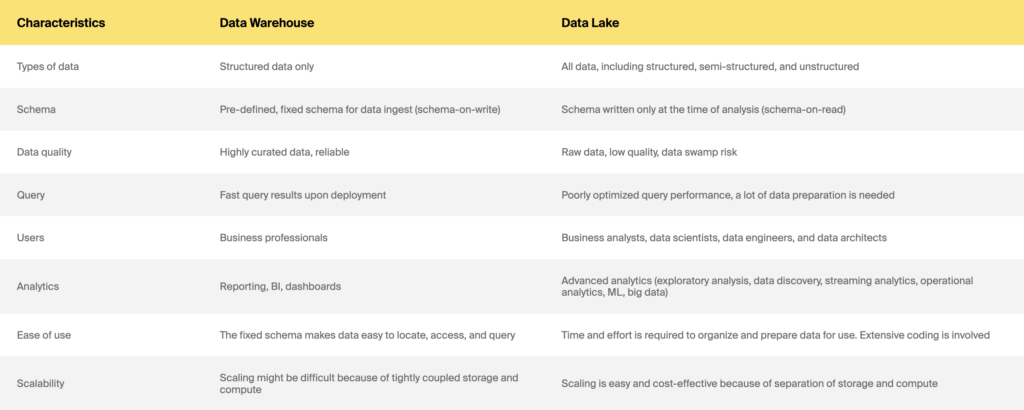
Data Warehouse vs. Data Lake
Was ist mit einer neuen hybriden Architektur, Data Lakehouses?
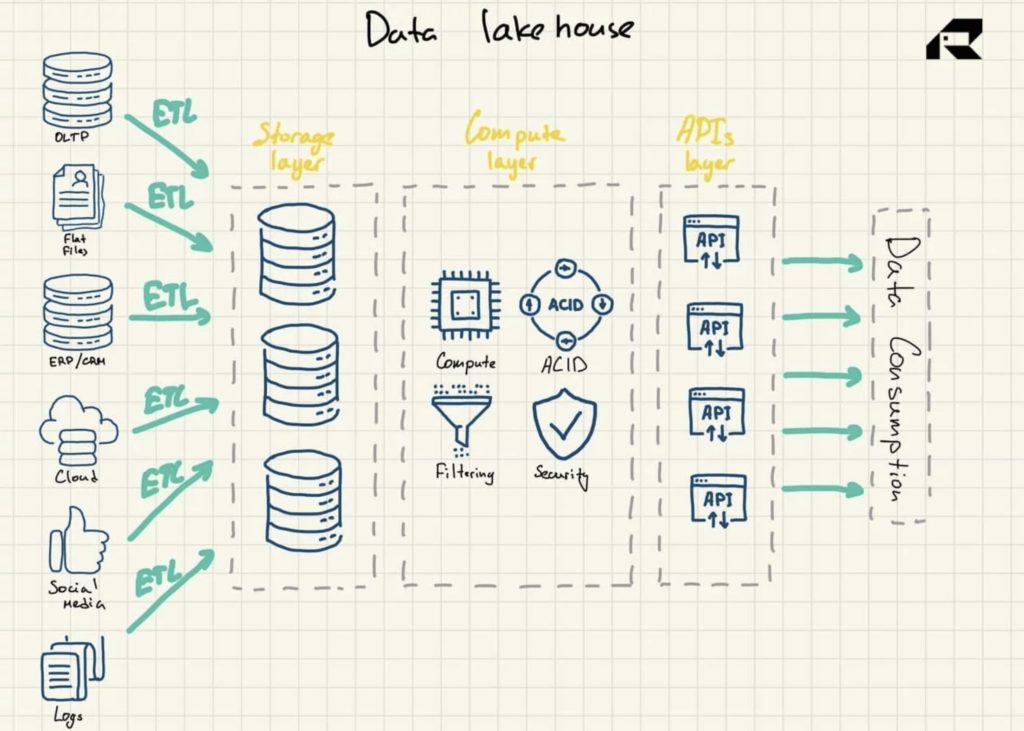
Abgesehen vom Marketing besteht die Schlüsselidee eines Data Lakehouse darin, Rechenleistung in einen Data Lake zu bringen. Architektonisch besteht das Data Lakehouse in der Regel aus:
- Speicherschicht zum Speichern von Daten in offenen Formaten (z. B. Parquet). Diese Schicht kann als Data Lake bezeichnet werden und ist von der Rechenschicht getrennt
- Datenverarbeitungsschicht, die der Organisation Warehouse-Funktionen zur Verfügung stellt und Metadatenverwaltung, Indexierung, Schemadurchsetzung und ACID-Transaktionen (Atomicity, Consistency, Reliability, and Durability) unterstützt
- APIs-Schicht für den Zugriff auf Datenbestände
- Serving-Schicht zur Unterstützung verschiedener Workloads, von der Berichterstellung bis hin zu BI, Data Science oder maschinellem Lernen.
Abbildung 3: Data Lakehouse-Referenzarchitektur
Angepriesen als eine Lösung, die das Beste aus beiden Welten vereint, spricht das Data Lakehouse beide an:
- Data Warehouse-Einschränkungen, einschließlich fehlender Unterstützung für erweiterte Datenanalysen, die sowohl auf strukturierten als auch unstrukturierten Daten beruhen, und erhebliche Skalierungskosten bei herkömmlichen Data Warehouses, die Speicher nicht von Rechenressourcen trennen
- Data Lake-Herausforderungen, einschließlich Datenduplizierung, Datenqualität und die Notwendigkeit, für verschiedene Aufgaben auf mehrere Systeme zuzugreifen oder komplexe Integrationen mit Analysetools zu implementieren
Das Data Lakehouse ist ein neuer Fortschritt in der Data-Analytics-Szene. Das Konzept wurde erstmals 2017 in Bezug auf die Snowflake-Plattform verwendet. Im Jahr 2019 verwendete AWS den Begriff Data Lakehouse, um seinen Amazon Redshift Spectrum-Dienst zu beschreiben, der es Benutzern seines Data Warehouse-Dienstes Amazon Redshift ermöglicht, in Amazon S3 gespeicherte Daten zu durchsuchen. Im Jahr 2020 wurde der Begriff Data Lakehouse weit verbreitet, und Databricks übernahm ihn für seine Delta Lake-Plattform.
Das Data Lakehouse könnte eine glänzende Zukunft vor sich haben, da Unternehmen aus allen Branchen KI einsetzen, um den Servicebetrieb zu verbessern, innovative Produkte und Dienstleistungen anzubieten oder den Marketingerfolg zu steigern. Strukturierte Daten aus Betriebssystemen, die von Data Warehouses bereitgestellt werden, sind für intelligente Analysen ungeeignet, während Data Lakes einfach nicht für robuste Governance-Praktiken, Sicherheit oder ACID-Compliance ausgelegt sind.
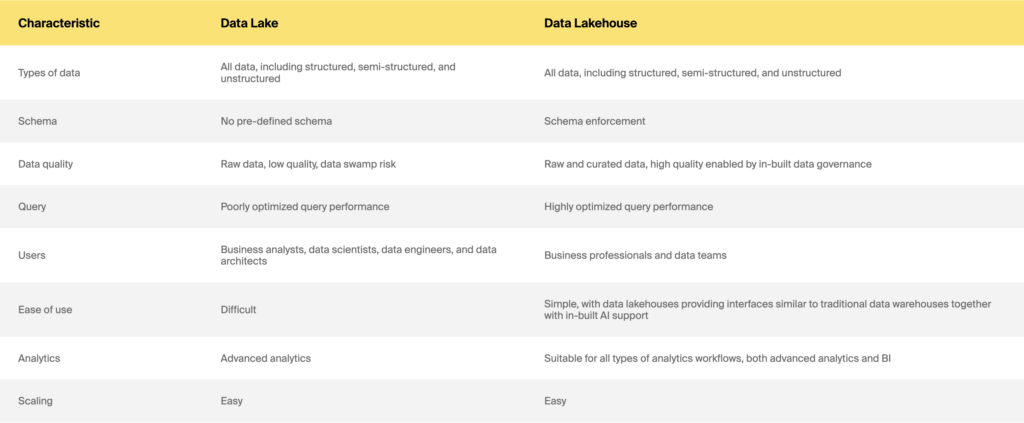
Data Lake vs. Data Lakehouse
Also Data Warehouse vs. Data Lake vs. Data Lakehouse: Was soll man wählen?
Ganz gleich, ob Sie eine Datenspeicherlösung von Grund auf neu erstellen oder Ihr Altsystem modernisieren möchten, um ML zu unterstützen oder die Leistung zu verbessern, die richtige Antwort wird nicht einfach sein. Es gibt immer noch viel Durcheinander über die wichtigsten Unterschiede, Vorteile und Kosten, da sich die Angebote und Preismodelle der Anbieter schnell weiterentwickeln. Außerdem ist es immer ein schwieriges Projekt, selbst wenn Sie die Zustimmung der Interessengruppen haben. Es gibt jedoch einige wichtige Überlegungen bei der Wahl des Data Warehouse vs. Data Lake vs. Data Lakehouse.
Die primäre Frage, die Sie beantworten sollten, lautet: WARUM. Ein guter Punkt, an den Sie sich erinnern sollten, ist, dass die Hauptunterschiede zwischen Data Warehouse, Lakes und Lakehouses nicht in der Technologie liegen. Sie dienen dazu, unterschiedliche Geschäftsanforderungen zu erfüllen. Warum brauchen Sie überhaupt eine Datenspeicherlösung? Geht es um regelmäßiges Reporting, Business Intelligence, Echtzeitanalysen, Data Science oder andere anspruchsvolle Analysen? Ist Datenkonsistenz oder Aktualität für Ihre Geschäftsanforderungen wichtiger? Verbringen Sie etwas Zeit mit der Entwicklung von Anwendungsfällen. Ihre Analyseanforderungen sollten gut definiert sein. Sie sollten auch Ihre Benutzer und Fähigkeiten genau verstehen. Ein paar Faustregeln sind:
- Ein Data Warehouse ist eine gute Wahl, wenn Sie genaue Fragen haben und wissen, welche Analyseergebnisse Sie regelmäßig erhalten möchten.
- Wenn Sie in einer stark regulierten Branche wie dem Gesundheitswesen oder dem Versicherungswesen tätig sind, müssen Sie möglicherweise vor allem umfangreiche Meldevorschriften einhalten. Daher ist ein Data Warehouse die bessere Wahl.
- Wenn Ihre KPIs und Berichtsanforderungen mit einer einfachen historischen Analyse adressiert werden können, ist ein Data Lake oder eine Hybridlösung ein Overkill. Entscheiden Sie sich stattdessen für ein Data Warehouse.
- Wenn Ihr Datenteam auf experimentelle und explorative Analysen aus ist, wählen Sie einen Data Lake oder eine Hybridlösung. Sie benötigen jedoch starke Datenanalysefähigkeiten, um mit unstrukturierten Daten zu arbeiten.
- Wenn Sie eine datenreife Organisation sind, die maschinelle Lerntechnologie nutzen möchte, ist eine Hybridlösung oder ein Data Lake die natürliche Lösung.
Berücksichtigen Sie auch Ihre Budget- und Zeitbeschränkungen. Data Lakes sind sicherlich schneller zu erstellen als Data Warehouses und wahrscheinlich billiger. Möglicherweise möchten Sie Ihre Initiative schrittweise implementieren und bei der Skalierung Funktionen hinzufügen. Wenn Sie Ihr altes Datenspeichersystem modernisieren möchten, sollten Sie sich erneut fragen, WARUM Sie dies benötigen. Ist es zu langsam? Oder können Sie keine Abfragen für größere Datensätze ausführen? Fehlen einige Daten? Möchten Sie eine andere Art von Analyse herausholen? Ihre Organisation hat viel Geld für das Altsystem ausgegeben, also brauchen Sie definitiv einen starken Business Case, um es aufzugeben. Binden Sie es auch an einen ROI. Datenspeicherarchitekturen sind noch in der Reifephase. Wie sie sich entwickeln, lässt sich nicht mit Sicherheit sagen. Unabhängig davon, welchen Weg Sie einschlagen, ist es jedoch hilfreich, häufige Fallstricke zu erkennen und das Beste aus der bereits vorhandenen Technologie zu machen.
Wir hoffen, dass dieser Artikel einige Verwirrung über Data Warehouses vs. Data Lakes vs. Data Lakehouses beseitigt hat. Wenn Sie noch Fragen haben oder erstklassige technische Fähigkeiten oder Ratschläge zum Aufbau Ihrer Datenspeicherlösung benötigen, schreiben Sie ITrex eine Nachricht. Sie werden dir helfen.
Ursprünglich am 23. Februar 2022 unter https://itrexgroup.com veröffentlicht.