
Taglio attraverso la confusione: Data Warehouse vs Data Lake vs Data Lakehouse
Pubblicato: 2022-03-11Lottando per sfruttare la proliferazione dei dati, i CIO di tutti i settori devono affrontare sfide difficili. Uno di questi è dove archiviare tutti i dati della propria azienda per fornire una solida analisi dei dati.
Tradizionalmente esistono due soluzioni di archiviazione per i dati: data warehouse e data lake.
I data warehouse archiviano principalmente dati strutturati trasformati provenienti da sistemi operativi e transazionali e vengono utilizzati per query rapide e complesse su questi dati storici.
I data lake fungono da dump, memorizzando tutti i tipi di dati, inclusi i dati semistrutturati e non strutturati. Consentono l'analisi avanzata come l'analisi in streaming per l'elaborazione dei dati in tempo reale o l'apprendimento automatico.
Storicamente, i data warehouse erano costosi da implementare perché era necessario pagare sia lo spazio di archiviazione che le risorse di elaborazione, oltre alle competenze per mantenerli. Poiché il costo dello storage è diminuito, i data warehouse sono diventati più economici. Alcuni credono che i data lake (tradizionalmente un'alternativa più efficiente in termini di costi) siano ormai morti. Alcuni sostengono che i data lake siano ancora alla moda. Nel frattempo, altri stanno parlando di una nuova soluzione di archiviazione ibrida dei dati: i data lakehouses.
Qual è il problema con ciascuno di loro? Diamo un'occhiata da vicino.
Questo blog esplora le differenze chiave tra data warehouse, data lake e data lakehouse, stack tecnologici popolari e casi d'uso. Fornisce anche suggerimenti per scegliere la soluzione giusta per la tua azienda, anche se questa è complicata.
Che cos'è un data warehouse?
I data warehouse sono progettati per archiviare dati strutturati e curati, organizzando set di dati in tabelle e colonne. Questi dati sono facilmente disponibili per gli utenti per la business intelligence, i dashboard e i report tradizionali.
Architettura del data warehouse
Un'architettura a tre livelli è l'approccio più comunemente utilizzato per la progettazione di data warehouse. Comprende:
- Livello inferiore: un'area di gestione temporanea e il server di database del data warehouse utilizzato per caricare i dati da varie origini. Un processo di estrazione, trasformazione e caricamento (ETL) è un approccio tradizionale al push dei dati nel data warehouse
- Livello intermedio: un server per l'elaborazione analitica online (OLAP) che riorganizza i dati in un formato multidimensionale per calcoli veloci
- Livello superiore: API e strumenti front-end per lavorare con i dati
Figura 1: Architettura di riferimento del data warehouse
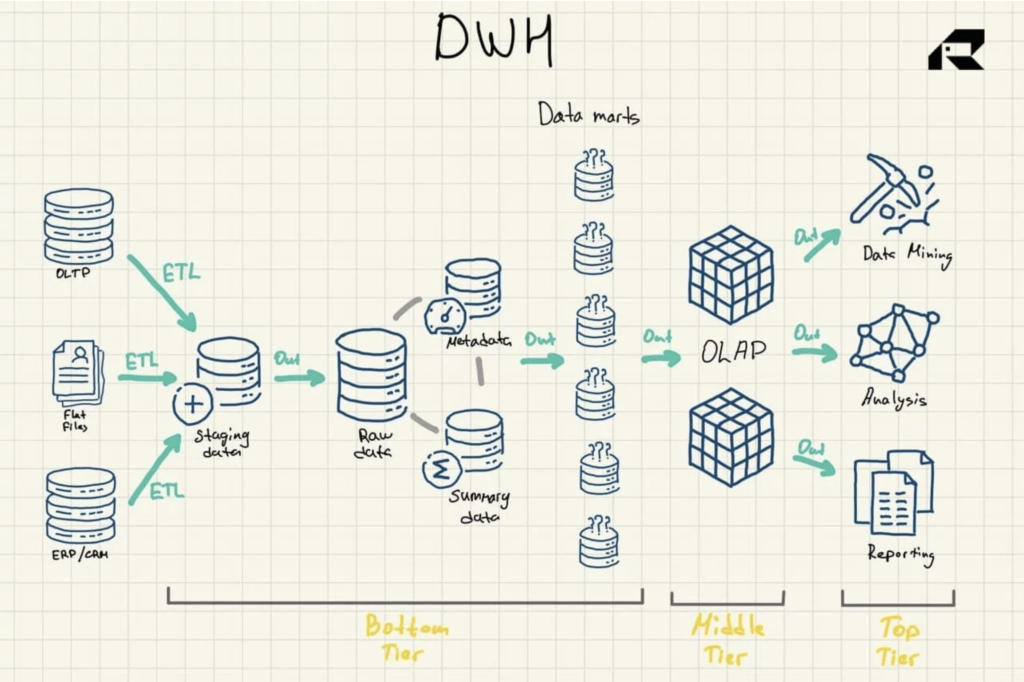
Ci sono altri tre componenti vitali di un data warehouse che dovrebbero essere menzionati: il data mart, l'archiviazione dei dati operativi e i metadati. I data mart appartengono al livello inferiore. Memorizzano sottoinsiemi di dati del data warehouse, servendo singole linee di business.
Gli archivi dati operativi fungono da repository che fornisce un'istantanea dei dati più aggiornati dell'organizzazione per il reporting operativo basato su semplici query. Possono essere utilizzati come livello intermedio tra le origini dati e il data warehouse.
Esistono anche metadati, dati che descrivono i dati del data warehouse, che vengono archiviati in repository per scopi speciali, anche nel livello inferiore.
Evoluzione e tecnologie del data warehouse
I data warehouse esistono da alcuni decenni.
Tradizionalmente, i data warehouse erano ospitati in loco, il che significa che le aziende dovevano acquistare tutto l'hardware e distribuire il software localmente, sia sistemi a pagamento che open source. Avevano anche bisogno di un intero team IT per la manutenzione del data warehouse. Il lato positivo è che i data warehouse tradizionali stavano introducendo (e lo fanno ancora oggi) un time-to-insight rapido senza problemi di latenza, controllo totale dei dati insieme a privacy al cento per cento e rischi per la sicurezza ridotti al minimo.
Con l'ubiquità del cloud, molte organizzazioni ora scelgono di migrare a soluzioni di data warehouse nel cloud in cui tutti i dati sono archiviati in un cloud. Viene anche analizzato in un cloud, utilizzando un qualche tipo di motore di query integrato.
Sul mercato sono disponibili una varietà di soluzioni di data warehouse su cloud consolidate. Ogni fornitore offre il suo set unico di capacità di magazzino e diversi modelli di prezzo. Ad esempio, Amazon Redshift è organizzato come un data warehouse tradizionale. Fiocco di neve è simile. Microsoft Azure è un data warehouse SQL, mentre Google BigQuery si basa su un'architettura serverless che offre essenzialmente software-as-a-service (SaaS), piuttosto che infrastruttura o piattaforma-as-a-service come, ad esempio, Amazon Redshift.
Tra le ben note soluzioni di data warehouse in locale ci sono IBM Db2, Oracle Autonomous Database, IBM Netezza, Teradata Vantage, SAP HANA ed Exasol. Sono disponibili anche sul cloud.
I data warehouse basati su cloud sono ovviamente più economici perché non è necessario acquistare o implementare server fisici. Gli utenti pagano solo per lo spazio di archiviazione e la potenza di calcolo secondo necessità. Le soluzioni cloud sono anche molto più facili da scalare o integrare con altri servizi.
Soddisfacendo esigenze aziendali altamente specifiche con la massima qualità dei dati e informazioni rapide, i data warehouse sono qui per durare a lungo.
Casi d'uso del data warehouse
I data warehouse forniscono analisi ad alta velocità e prestazioni elevate su petabyte e petabyte di dati storici.
Sono fondamentalmente progettati per query di tipo BI. Un data warehouse potrebbe fornire una risposta, ad esempio, sulle vendite in un determinato periodo di tempo, raggruppate per regione o divisione, e sui movimenti di anno in anno delle vendite. I casi d'uso chiave per i data warehouse sono:
- Reportistica transazionale per fornire un quadro delle prestazioni aziendali
- Analisi/reporting ad hoc per fornire risposte a sfide aziendali autonome e "una tantum".
- Data mining per estrarre conoscenze utili e modelli nascosti dai dati per risolvere complessi problemi del mondo reale
- Presentazione dinamica attraverso la visualizzazione dei dati
- Drill-down per esaminare le dimensioni gerarchiche dei dati per i dettagli
Avere dati aziendali strutturati in una posizione facilmente accessibile al di fuori dei database operativi è praticamente importante per qualsiasi azienda matura di dati.
Tuttavia, i data warehouse tradizionali non supportano la tecnologia dei big data.
Vengono inoltre aggiornati in batch, con i record di tutte le origini elaborati periodicamente in una volta sola, il che significa che i dati possono diventare obsoleti quando vengono raccolti per l'analisi. Il data lake sembra risolvere questi vincoli. Con un compromesso. Esploriamo.
Che cos'è un data lake?
I data lake raccolgono principalmente dati grezzi non raffinati nella loro forma originale. Un'altra differenza fondamentale tra il data lake e il data warehouse è che i data lake archiviano questi dati senza organizzarli in relazioni logiche chiamate schemi. Tuttavia, questo è il modo in cui consentono analisi più sofisticate.
I data lake estraggono (i) dati transazionali da applicazioni aziendali come ERP, CRM o SCM, (ii) documenti nei formati .csv e .txt, (iii) dati semistrutturati come XML, JSON e formati AVRO, (iv) registri del dispositivo e sensori IoT e (v) immagini, file audio, binari e PDF.
Architettura del lago di dati
I data lake utilizzano un'architettura piatta per l'archiviazione dei dati. I suoi componenti chiave sono:
- Zona bronzo per tutti i dati ingeriti nel lago. I dati vengono archiviati così come sono per i modelli batch o come set di dati aggregati per i carichi di lavoro in streaming
- Silver zone dove i dati vengono filtrati e arricchiti per essere esplorati in base alle esigenze aziendali
- Gold zone in cui vengono archiviati dati curati e ben strutturati per l'applicazione di strumenti BI e algoritmi ML. Questa zona presenta spesso un archivio dati operativo che alimenta i tradizionali data warehouse e data mart
- Sandbox in cui i dati possono essere sperimentati per la convalida e i test di ipotesi. È implementato come database completamente separato per Hadoop o altre tecnologie NoSQL o come parte della zona d'oro.
Figura 2: architettura di riferimento di Data Lake
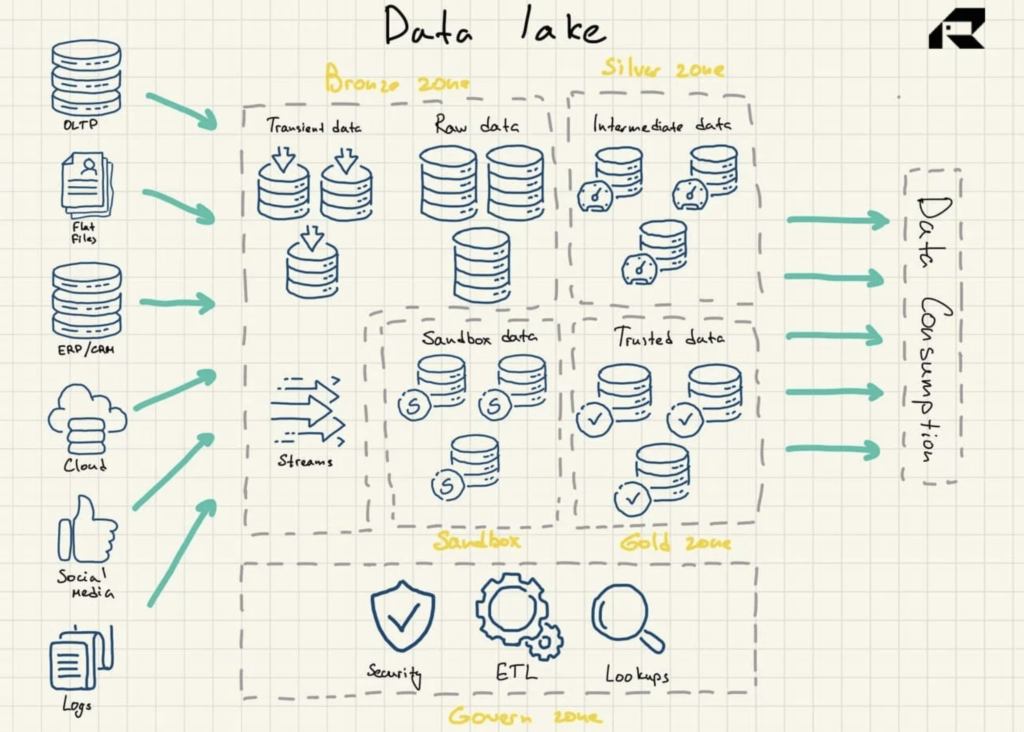
I data lake non contengono intrinsecamente capacità di analisi. Senza di loro, memorizzano solo dati grezzi che non sono utili di per sé. Pertanto, le organizzazioni creano data warehouse o sfruttano altri strumenti in aggiunta ai data lake per utilizzare i dati.
Per assicurarsi che un data lake non si trasformi in una palude di dati, è importante disporre di una strategia di gestione dei dati efficiente che includa la governance dei dati e la gestione dei metadati integrate nella progettazione di data lake. In un mondo ideale, i dati che si trovano in un data lake dovrebbero essere catalogati, indicizzati, convalidati e facilmente disponibili per gli utenti dei dati. Questo è un caso raro e molti progetti di data lake falliscono. Questo può essere evitato: indipendentemente dalla maturità di un team di dati, è fondamentale installare almeno i controlli essenziali per imporre la convalida e la qualità dei dati.
Evoluzione e tecnologie del data lake
L'ascesa dei big data all'inizio degli anni 2000 ha portato grandi opportunità e grandi sfide per le organizzazioni. Il business aveva bisogno di una nuova tecnologia per analizzare questi set di dati enormi, disordinati e in rapida crescita per catturare un impatto aziendale dai big data.
Nel 2008, Apache Hadoop ha ideato un'innovativa tecnologia open source per la raccolta e l'elaborazione di dati non strutturati su vasta scala, aprendo la strada all'analisi dei big data e ai data lake. Poco dopo emerse Apache Spark. Era più facile da usare. Inoltre, ha fornito funzionalità per creare e addestrare modelli ML, eseguire query sui dati strutturati utilizzando SQL ed elaborare dati in tempo reale.
Oggi i data lake sono prevalentemente repository ospitati nel cloud. Tutti i principali fornitori di servizi cloud come AWS, Azure e Google offrono data lake basati su cloud con servizi di storage di oggetti convenienti. Le loro piattaforme sono dotate di vari servizi di gestione dei dati per automatizzare la distribuzione. In uno scenario, ad esempio, un data lake potrebbe essere costituito da un sistema di archiviazione dati come Hadoop Distributed File System (HDFS) o Amazon S3 integrato con una soluzione di data warehouse su cloud come Amazon Redshift. Questi componenti sarebbero disaccoppiati dai servizi nell'ecosistema che potrebbero includere Amazon EMR per l'elaborazione dei dati, Amazon Glue che fornisce il catalogo dei dati e la funzionalità di trasformazione, il servizio di query Amazon Athena o Amazon Elasticsearch Service che viene utilizzato per creare un repository di metadati e un indice dati. I data lake locali sono ancora comuni a causa dei soliti problemi del cloud come sicurezza, privacy o latenza.

Esistono anche fornitori di storage in sede che offrono alcuni prodotti per i data lake, ma le loro offerte di data lake, tuttavia, non sono ben definite. A differenza dei data warehouse, i data lake non hanno molti anni di implementazioni nel mondo reale alle spalle. Ci sono ancora molte critiche che descrivono il concetto di data lake come sfocato e mal definito. I critici sostengono inoltre che poche persone in qualsiasi organizzazione hanno le capacità (o l'entusiasmo per quella materia) per eseguire carichi di lavoro esplorativi rispetto a dati grezzi.
L'idea che i data lake debbano essere utilizzati come repository centrale per i dati di tutte le imprese deve essere affrontata con cautela, affermano. C'è stato anche un discorso provocatorio sul fatto che i giorni di data lake sono contati. Si citano i seguenti motivi:
- I data lake non possono ridimensionare le risorse di calcolo in modo efficiente su richiesta (beh, questo è perché non sono previste dalla progettazione in primo luogo)
- I data lake portano un grosso debito tecnologico, con la loro creazione principalmente guidata da clamore di marketing, piuttosto che da ragioni tecniche (lo stesso è successo anche con molti data warehouse)
- Con l'avvento delle soluzioni di data warehouse nel cloud, i data lake non offrono più vantaggi in termini di costi significativi (il problema dei costi non è così semplice poiché è difficile prevedere i costi di elaborazione)
Tali critiche sono una parte intrinseca di qualsiasi tecnologia più giovane. Tuttavia, i data lake hanno casi d'uso chiari come l'analisi in streaming. Eppure, non minacciano i data warehouse. Ad un certo punto, i data lake hanno persino trionfato sui data warehouse, offrendo capacità di analisi più ampie, convenienza e flessibilità in termini di dati archiviati. Tuttavia, poiché le tecnologie di data warehouse sono maturate, molti concordano sul fatto che non ci sia un vincitore ovvio ora. In genere è consigliabile mantenerli entrambi o... optare per un'architettura ibrida. Continuare a leggere.
Casi d'uso di Data Lake
L'idea principale dei data lake è di fornire l'accesso aziendale a tutti i dati disponibili da tutte le origini il più rapidamente possibile. I data lake non si limitano a fornire un quadro di ciò che è accaduto ieri. Archiviando enormi quantità di dati, i data lake sono progettati per consentire alle organizzazioni di saperne di più sul presente (usando l'analisi in streaming) e sul futuro (usando soluzioni di big data, inclusi l'analisi predittiva e l'apprendimento automatico). I casi d'uso chiave per i data lake sono:
- Alimentare un data warehouse aziendale con set di dati
- Esecuzione dell'analisi del flusso
- Implementazione di progetti ML
- Creazione di grafici analitici avanzati utilizzando strumenti BI aziendali consolidati come Tableau o MS Power BI
- Creazione di soluzioni di analisi dei dati personalizzate
- Esecuzione dell'analisi delle cause principali che consente ai team di dati di risalire alle origini dei problemi
Con forti capacità di ingegneria dei dati per spostare i dati grezzi in un ambiente di analisi, i data lake possono essere estremamente rilevanti. Consentono ai team di sperimentare i dati per capire come possono essere utili. Ciò potrebbe comportare la creazione di modelli per scavare nei dati e provare schemi diversi per visualizzare i dati in modi nuovi. I data lake consentono anche di litigare con i dati di flusso che fluiscono dai log Web e dai sensori IoT e non sono adatti per un approccio di data warehouse tradizionale.
In breve, i data lake consentono alle organizzazioni di portare alla luce modelli, anticipare i cambiamenti o trovare potenziali opportunità di business intorno a nuovi prodotti o processi attuali. Utilizzati per diverse esigenze aziendali, i data lake e i data warehouse vengono spesso implementati in tandem. Prima di passare al prossimo concetto di archiviazione dei dati, ricapitoliamo rapidamente le differenze principali tra il data warehouse e il data lake.
Data warehouse e data lake
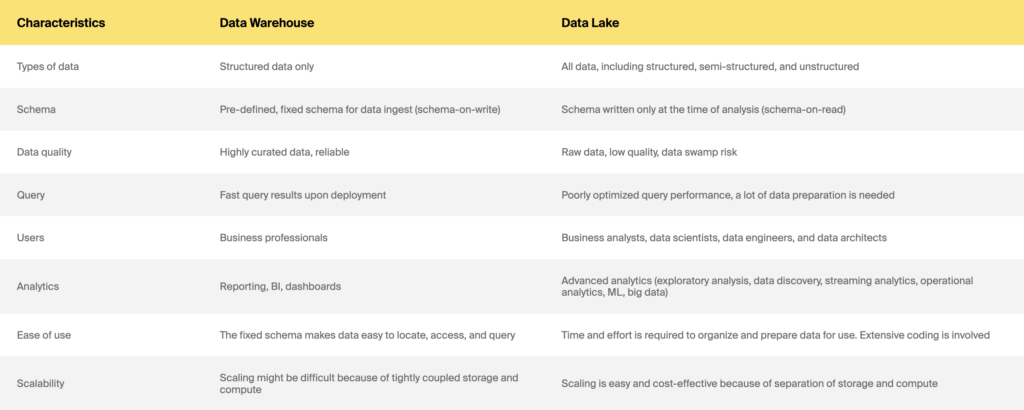
Che ne dici di una nuova architettura ibrida, data lakehouses?
Marketing a parte, l'idea chiave di un data lakehouse è portare la potenza di calcolo in un data lake. Architettonicamente, la Data Lakehouse è solitamente composta da:
- Livello di archiviazione per archiviare i dati in formati aperti (ad es. Parquet). Questo livello può essere chiamato data lake ed è separato dal livello di elaborazione
- Livello di elaborazione che offre all'organizzazione capacità di magazzino, supportando la gestione dei metadati, l'indicizzazione, l'applicazione dello schema e le transazioni ACID (Atomicity, Consistency, Reliability, and Durability)
- Livello API per accedere alle risorse di dati
- Livello di servizio per supportare vari carichi di lavoro, dal reporting alla BI, alla scienza dei dati o all'apprendimento automatico.
Figura 3: Architettura di riferimento di Data Lakehouse
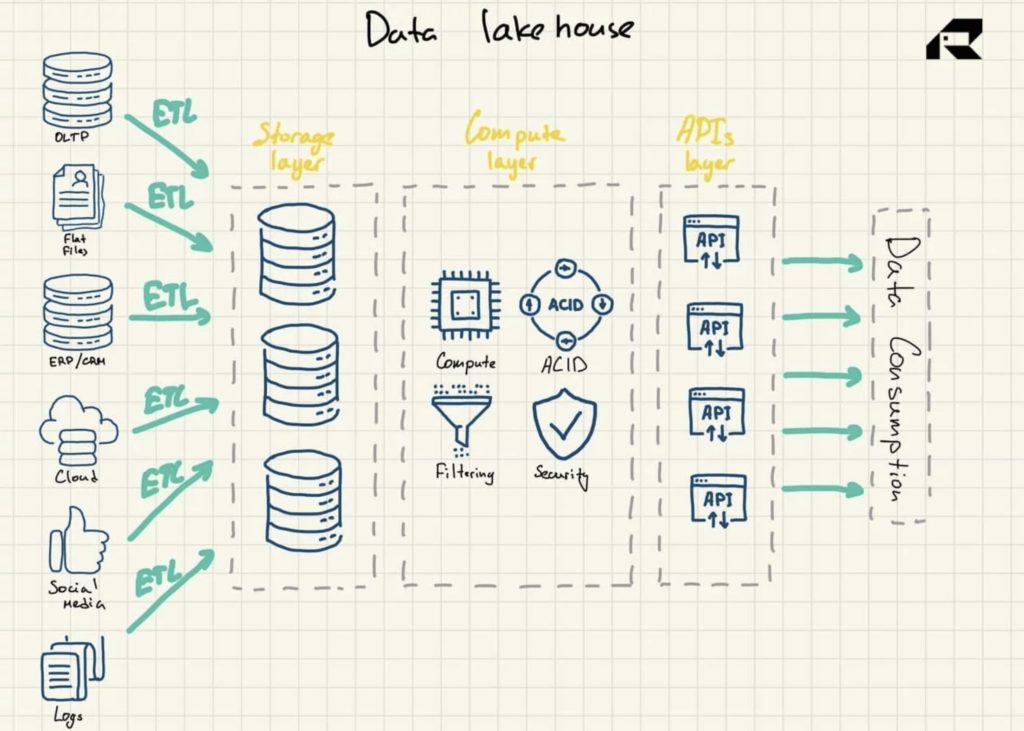
Pubblicizzato come una soluzione che unisce il meglio di entrambi i mondi, il data lakehouse si rivolge a entrambi:
- Vincoli del data warehouse, inclusa la mancanza di supporto per l'analisi dei dati avanzata che si basa su dati strutturati e non strutturati e costi di scalabilità significativi con i data warehouse tradizionali che non separano lo storage dalle risorse informatiche
- Le sfide del data lake, tra cui la duplicazione dei dati, la qualità dei dati e la necessità di accedere a più sistemi per varie attività o implementare integrazioni complesse con strumenti di analisi
Il data lakehouse è un nuovo progresso nella scena dell'analisi dei dati. Il concetto è stato utilizzato per la prima volta nel 2017 in relazione alla piattaforma Snowflake. Nel 2019, AWS ha utilizzato il termine data lakehouse per descrivere il suo servizio Amazon Redshift Spectrum che consente agli utenti del suo servizio di data warehouse Amazon Redshift di cercare tra i dati archiviati in Amazon S3. Nel 2020, il termine data lakehouse è diventato ampiamente utilizzato, con Databricks che lo ha adottato per la sua piattaforma Delta Lake.
Il data lakehouse potrebbe avere un futuro brillante in quanto le aziende di tutti i settori stanno adottando l'intelligenza artificiale per migliorare le operazioni di servizio, offrire prodotti e servizi innovativi o guidare il successo del marketing. I dati strutturati dei sistemi operativi forniti dai data warehouse non sono adatti per l'analisi intelligente, mentre i data lake non sono progettati per solide pratiche di governance, sicurezza o conformità ACID.
Data Lake vs Data Lakehouse
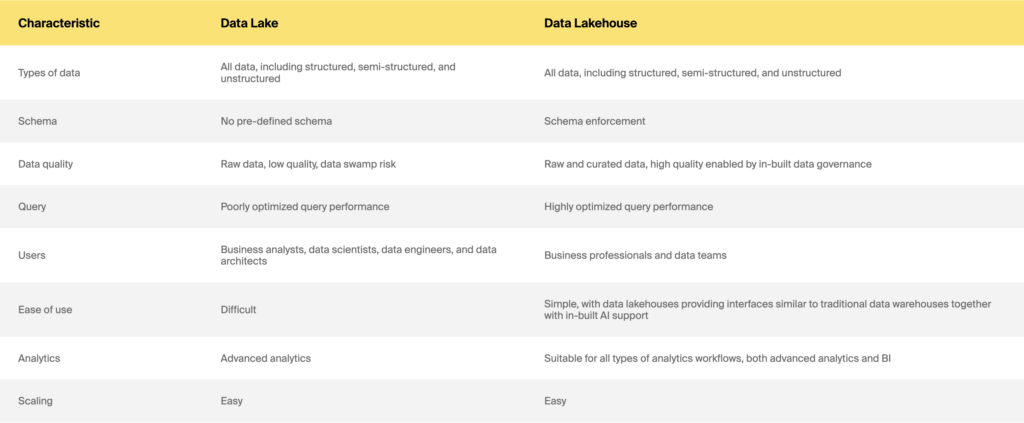
Quindi data warehouse vs data lake vs data lakehouse: quale scegliere
Sia che tu voglia creare una soluzione di archiviazione dati da zero o modernizzare il tuo sistema legacy per supportare ML o migliorare le prestazioni, la risposta giusta non sarà facile. C'è ancora un sacco di confusione su differenze chiave, vantaggi e costi, con offerte e modelli di prezzo dei fornitori in rapida evoluzione. Inoltre, è sempre un progetto difficile anche se hai il consenso degli stakeholder. Tuttavia, ci sono alcune considerazioni chiave nella scelta del data warehouse rispetto a data lake e data lakehouse.
La domanda principale a cui dovresti rispondere è: PERCHÉ. Un buon punto da ricordare qui è che le differenze chiave tra data warehouse, laghi e case sul lago non risiedono nella tecnologia. Si tratta di soddisfare diverse esigenze aziendali. Allora perché hai bisogno di una soluzione di archiviazione dati in primo luogo? È per rapporti regolari, business intelligence, analisi in tempo reale, scienza dei dati o altre analisi sofisticate? La coerenza o la tempestività dei dati è più importante per le tue esigenze aziendali? Dedica un po' di tempo allo sviluppo di casi d'uso. Le tue esigenze di analisi dovrebbero essere ben definite. Dovresti anche comprendere a fondo i tuoi utenti e le tue competenze. Alcune regole pratiche sono:
- Un data warehouse è una buona scommessa se hai domande esatte e sai quali risultati di analisi vuoi ottenere regolarmente.
- Se operi in un settore altamente regolamentato come quello sanitario o assicurativo, potresti dover rispettare soprattutto le normative di segnalazione estese. Quindi, un data warehouse sarà una scelta migliore.
- Se i tuoi KPI e i requisiti di reporting possono essere risolti con una semplice analisi storica, un data lake o una soluzione ibrida saranno eccessivi. Scegli invece un data warehouse.
- Se il tuo data team è alla ricerca di analisi sperimentali ed esplorative, scegli un data lake o una soluzione ibrida. Tuttavia, avrai bisogno di solide capacità di analisi dei dati per lavorare con dati non strutturati.
- Se sei un'organizzazione basata sui dati che desidera sfruttare la tecnologia di machine learning, una soluzione ibrida o un data lake sarà una scelta naturale.
Considera anche il tuo budget e i tuoi limiti di tempo. I data lake sono sicuramente più veloci da costruire rispetto ai data warehouse e probabilmente più economici. Potresti voler implementare la tua iniziativa in modo incrementale e aggiungere funzionalità man mano che aumenti. Se vuoi modernizzare il tuo sistema di archiviazione dati legacy, allora di nuovo, dovresti chiedere PERCHÉ ne hai bisogno. È troppo lento? O non ti consente di eseguire query su set di dati più grandi? Mancano dei dati? Vuoi estrarre un diverso tipo di analisi? La tua organizzazione ha speso molti soldi per il sistema legacy, quindi hai sicuramente bisogno di un solido business case per abbandonarlo. Legalo anche a un ROI. Le architetture di archiviazione dei dati sono ancora in fase di maturazione. È impossibile dire con certezza come si evolveranno. Tuttavia, indipendentemente dal percorso che prenderai, è utile riconoscere le insidie comuni e sfruttare al meglio la tecnologia che è già disponibile.
Ci auguriamo che questo articolo abbia chiarito un po' di confusione tra data warehouse e data lake e data lakehouse. Se hai ancora domande o hai bisogno di competenze tecniche o consigli di alto livello per costruire la tua soluzione di archiviazione dati, scrivi a ITRex. Ti aiuteranno.
Pubblicato originariamente su https://itrexgroup.com il 23 febbraio 2022.