
Przebijanie się przez zamieszanie: hurtownia danych a Data Lake a Data Lakehouse
Opublikowany: 2022-03-11Starając się wykorzystać rozrost danych, dyrektorzy ds. informatyki w różnych branżach stoją przed trudnymi wyzwaniami. Jednym z nich jest miejsce przechowywania wszystkich danych przedsiębiorstwa w celu zapewnienia solidnej analizy danych.
Tradycyjnie istniały dwa rozwiązania do przechowywania danych: hurtownie danych i jeziora danych.
Hurtownie danych przechowują głównie przekształcone, ustrukturyzowane dane z systemów operacyjnych i transakcyjnych i są używane do szybkich złożonych zapytań dotyczących tych danych historycznych.
Jeziora danych działają jak zrzut, przechowując wszystkie rodzaje danych, w tym dane częściowo ustrukturyzowane i nieustrukturyzowane. Umożliwiają zaawansowane analizy, takie jak analizy strumieniowe do przetwarzania danych na żywo lub uczenia maszynowego.
Historycznie rzecz biorąc, wdrażanie hurtowni danych było drogie, ponieważ oprócz umiejętności ich utrzymania trzeba było płacić zarówno za przestrzeń dyskową, jak i zasoby obliczeniowe. Ponieważ koszt przechowywania spadł, hurtownie danych stały się tańsze. Niektórzy uważają, że jeziora danych (tradycyjnie bardziej opłacalna alternatywa) są już martwe. Niektórzy twierdzą, że jeziora danych wciąż są modne. Tymczasem inni mówią o nowym, hybrydowym rozwiązaniu do przechowywania danych — data lakehouses.
O co chodzi z każdym z nich? Przyjrzyjmy się bliżej.
Ten blog omawia kluczowe różnice między hurtowniami danych, jeziorami danych i jeziorami danych, popularnymi stosami technologicznymi i przypadkami użycia. Zawiera również wskazówki dotyczące wyboru odpowiedniego rozwiązania dla Twojej firmy, choć ta jest podchwytliwa.
Co to jest hurtownia danych?
Hurtownie danych są przeznaczone do przechowywania uporządkowanych, wyselekcjonowanych danych, organizowania zestawów danych w tabelach i kolumnach. Dane te są łatwo dostępne dla użytkowników na potrzeby tradycyjnej analizy biznesowej, pulpitów nawigacyjnych i raportowania.
Architektura hurtowni danych
Architektura trójwarstwowa to najczęściej stosowane podejście do projektowania hurtowni danych. Zawiera:
- Warstwa dolna: obszar pomostowy i serwer bazy danych hurtowni danych, który jest używany do ładowania danych z różnych źródeł. Proces ekstrakcji, transformacji i ładowania (ETL) to tradycyjne podejście do wypychania danych do hurtowni danych
- Warstwa środkowa: serwer do przetwarzania analitycznego online (OLAP), który reorganizuje dane w wielowymiarowy format w celu szybkich obliczeń
- Najwyższy poziom: API i narzędzia frontendowe do pracy z danymi
Rysunek 1: Architektura referencyjna hurtowni danych
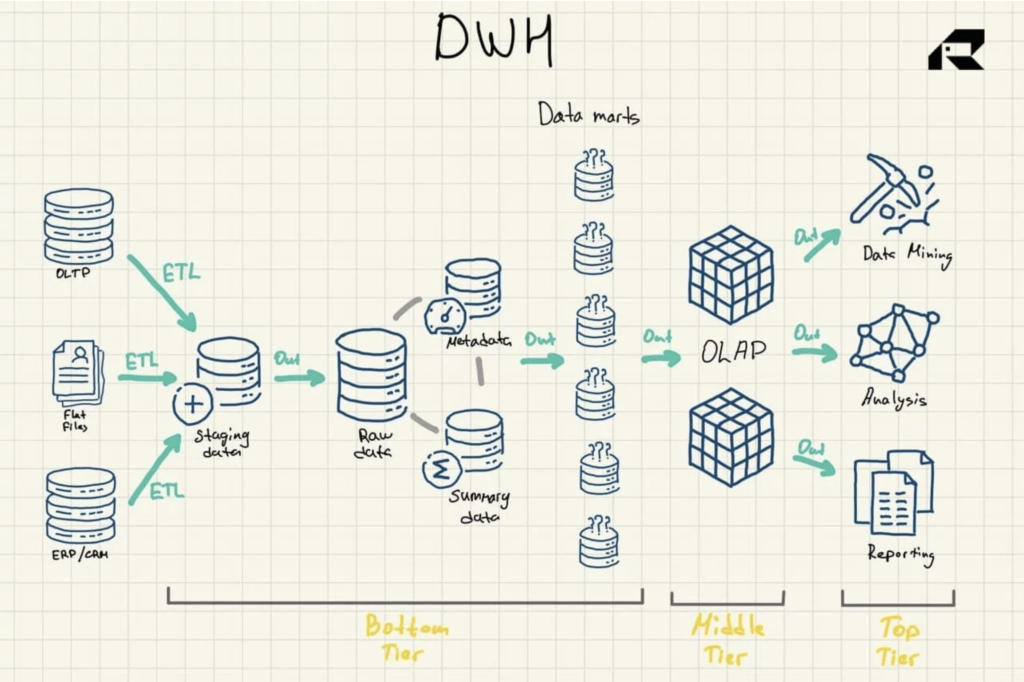
Istnieją trzy inne ważne elementy hurtowni danych, o których należy wspomnieć: data mart, operacyjne przechowywanie danych i metadane. Marty danych należą do najniższego poziomu. Przechowują podzbiory danych hurtowni danych, obsługując poszczególne linie biznesowe.
Operacyjne magazyny danych działają jak repozytorium, zapewniając migawkę najbardziej aktualnych danych organizacji na potrzeby raportowania operacyjnego opartego na prostych zapytaniach. Mogą być używane jako warstwa pośrednia między źródłami danych a hurtownią danych.
Istnieją również metadane — dane opisujące dane hurtowni danych — które są przechowywane w specjalnych repozytoriach, również w dolnej warstwie.
Ewolucja i technologie hurtowni danych
Hurtownie danych istnieją od kilkudziesięciu lat.
Tradycyjnie hurtownie danych były hostowane lokalnie, co oznaczało, że firmy musiały kupować cały sprzęt i wdrażać oprogramowanie lokalnie, w systemach płatnych lub open source. Potrzebowali również całego zespołu IT do utrzymania hurtowni danych. Z drugiej strony tradycyjne hurtownie danych zapewniały (i nadal to robią) szybki czas do uzyskania wglądu bez problemów z opóźnieniami, całkowitą kontrolę danych wraz ze stuprocentową prywatnością i zminimalizowanym ryzykiem bezpieczeństwa.
Dzięki wszechobecności w chmurze wiele organizacji decyduje się teraz na migrację do rozwiązań hurtowni danych w chmurze, w których wszystkie dane są przechowywane w chmurze. Jest również analizowany w chmurze za pomocą pewnego rodzaju zintegrowanego silnika zapytań.
Na rynku istnieje wiele uznanych rozwiązań hurtowni danych w chmurze. Każdy dostawca oferuje swój unikalny zestaw możliwości magazynowych i różne modele cenowe. Na przykład Amazon Redshift jest zorganizowany jako tradycyjna hurtownia danych. Podobnie jest z płatkiem śniegu. Microsoft Azure to hurtownia danych SQL, podczas gdy Google BigQuery opiera się na architekturze bezserwerowej oferującej zasadniczo oprogramowanie jako usługa (SaaS), a nie infrastrukturę lub platformę jako usługę, jak na przykład Amazon Redshift.
Wśród znanych lokalnych rozwiązań hurtowni danych są IBM Db2, Oracle Autonomous Database, IBM Netezza, Teradata Vantage, SAP HANA i Exasol. Są również dostępne w chmurze.
Hurtownie danych w chmurze są oczywiście tańsze, ponieważ nie ma potrzeby kupowania ani rozwijania serwerów fizycznych. Użytkownicy płacą tylko za przestrzeń dyskową i moc obliczeniową w razie potrzeby. Rozwiązania chmurowe są również znacznie łatwiejsze do skalowania lub integracji z innymi usługami.
Spełniając bardzo specyficzne potrzeby biznesowe z najwyższą jakością danych i szybkim wglądem, hurtownie danych mogą pozostać na długo.
Przypadki użycia hurtowni danych
Hurtownie danych zapewniają szybką i wydajną analizę petabajtów i petabajtów danych historycznych.
Są one zasadniczo zaprojektowane dla zapytań typu BI. Hurtownia danych może udzielić odpowiedzi na przykład na temat sprzedaży w określonym okresie czasu, pogrupowanej według regionu lub działu, oraz zmian sprzedaży rok do roku. Kluczowe przypadki użycia hurtowni danych to:
- Raportowanie transakcyjne w celu dostarczenia obrazu wyników biznesowych
- Analiza/raportowanie ad hoc w celu uzyskania odpowiedzi na samodzielne i „jednorazowe” wyzwania biznesowe
- Eksploracja danych w celu wydobycia przydatnej wiedzy i ukrytych wzorców z danych w celu rozwiązania złożonych problemów w świecie rzeczywistym
- Dynamiczna prezentacja poprzez wizualizację danych
- Drążenie w dół, aby przejść przez hierarchiczne wymiary danych w celu uzyskania szczegółów
Posiadanie uporządkowanych danych biznesowych w jednym łatwo dostępnym miejscu poza bazami operacyjnymi jest bardzo ważne dla każdej firmy dojrzałej do przetwarzania danych.
Jednak tradycyjne hurtownie danych nie obsługują technologii Big Data.
Są one również aktualizowane wsadowo, a rekordy ze wszystkich źródeł są przetwarzane okresowo za jednym razem, co oznacza, że dane mogą stać się nieaktualne do czasu ich zestawienia do celów analitycznych. Jezioro danych wydaje się rozwiązywać te ograniczenia. Z kompromisem. Odkryjmy.
Co to jest jezioro danych?
Jeziora danych gromadzą w większości nieprzetworzone, surowe dane w ich oryginalnej formie. Inną kluczową różnicą między jeziorem danych a hurtownią danych jest to, że jeziora danych przechowują te dane bez organizowania ich w żadne logiczne relacje zwane schematami. Jednak w ten sposób umożliwiają bardziej wyrafinowaną analitykę.
Jeziora danych pobierają (i) dane transakcyjne z aplikacji biznesowych, takich jak ERP, CRM lub SCM, (ii) dokumenty w formatach .csv i .txt, (iii) dane częściowo ustrukturyzowane, takie jak formaty XML, JSON i AVRO, (iv) dzienniki urządzeń i czujniki IoT oraz (v) obrazy, pliki dźwiękowe, binarne, PDF.
Architektura jeziora danych
Jeziora danych wykorzystują płaską architekturę do przechowywania danych. Jego kluczowe elementy to:
- Brązowa strefa dla wszystkich danych pozyskiwanych do jeziora. Dane są przechowywane bez zmian w przypadku wzorców wsadowych lub jako zagregowane zestawy danych do przesyłania strumieniowego
- Strefa srebrna, w której dane są filtrowane i wzbogacane do eksploracji zgodnie z potrzebami biznesowymi
- Strefa złota, w której przechowywane są wyselekcjonowane, dobrze ustrukturyzowane dane do stosowania narzędzi BI i algorytmów ML. W tej strefie często znajduje się operacyjny magazyn danych, który zasila tradycyjne hurtownie danych i hurtownie danych
- Piaskownica , w której można eksperymentować z danymi w celu weryfikacji hipotez i testów. Jest wdrażany albo jako całkowicie oddzielna baza danych dla Hadoop lub innych technologii NoSQL, albo jako część złotej strefy.
Rysunek 2: Architektura referencyjna Data Lake
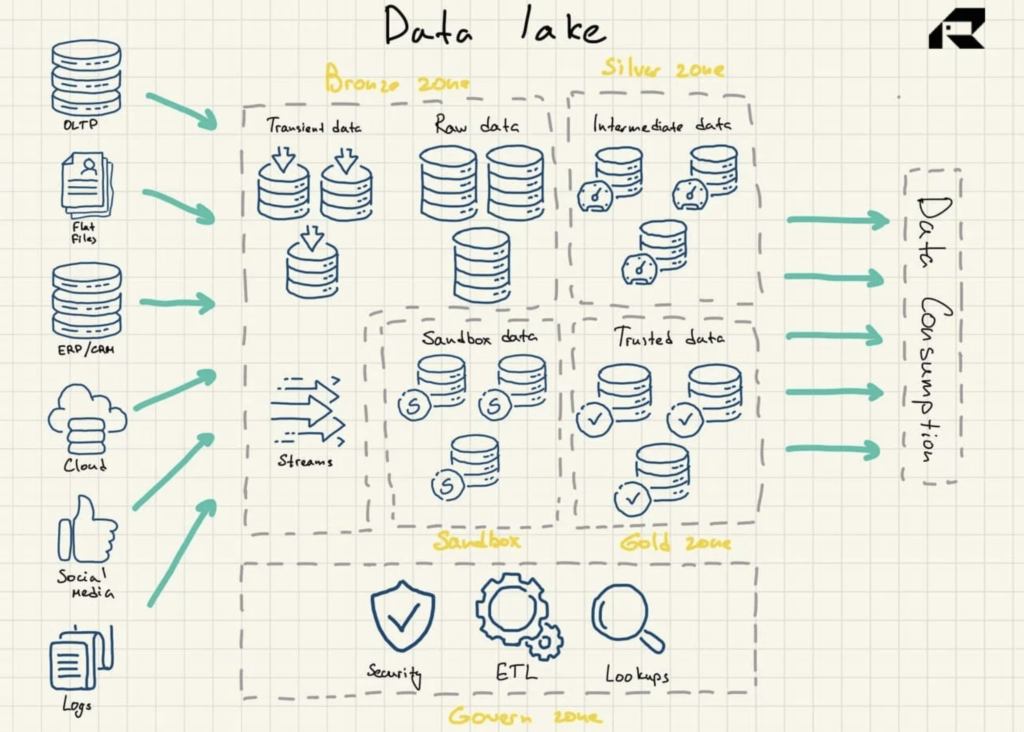
Jeziora danych z natury nie zawierają funkcji analitycznych. Bez nich przechowują tylko surowe dane, które same w sobie nie są przydatne. Dlatego organizacje budują hurtownie danych lub wykorzystują inne narzędzia na jeziorach danych, aby wykorzystać dane.
Aby mieć pewność, że jezioro danych nie zamieni się w bagno danych, ważne jest, aby mieć wydajną strategię zarządzania danymi, obejmującą wbudowane zarządzanie danymi i zarządzanie metadanymi w projektowaniu jeziora danych. W idealnym świecie dane znajdujące się w jeziorze danych powinny być katalogowane, indeksowane, sprawdzane i łatwo dostępne dla użytkowników danych. Rzadko się to zdarza i wiele projektów Data Lake kończy się niepowodzeniem. Można tego uniknąć: niezależnie od dojrzałości zespołu zajmującego się danymi, kluczowe znaczenie ma zainstalowanie przynajmniej niezbędnych mechanizmów kontrolnych w celu wymuszenia walidacji i jakości danych.
Ewolucja i technologie jeziora danych
Rozwój big data na początku XXI wieku przyniósł organizacjom zarówno ogromne możliwości, jak i wielkie wyzwania. Biznes potrzebował nowej technologii do analizowania tych ogromnych, niechlujnych i absurdalnie szybko rosnących zbiorów danych, aby uchwycić wpływ na biznes z dużych zbiorów danych.
W 2008 r. Apache Hadoop opracował innowacyjną technologię open source do gromadzenia i przetwarzania nieustrukturyzowanych danych na masową skalę, torując drogę do analizy big data i jezior danych. Niedługo potem pojawił się Apache Spark. To było łatwiejsze w użyciu. Ponadto zapewnił możliwości budowania i trenowania modeli ML, wysyłania zapytań do danych strukturalnych przy użyciu języka SQL oraz przetwarzania danych w czasie rzeczywistym.
Obecnie jeziora danych to głównie repozytoria hostowane w chmurze. Wszyscy najlepsi dostawcy usług w chmurze, tacy jak AWS, Azure i Google, oferują oparte na chmurze jeziora danych z opłacalnymi usługami obiektowej pamięci masowej. Ich platformy są dostarczane z różnymi usługami zarządzania danymi w celu zautomatyzowania wdrażania. Na przykład w jednym scenariuszu jezioro danych może składać się z systemu przechowywania danych, takiego jak Hadoop Distributed File System (HDFS) lub Amazon S3, zintegrowanego z rozwiązaniem hurtowni danych w chmurze, takim jak Amazon Redshift. Te komponenty byłyby oddzielone od usług w ekosystemie, które mogą obejmować Amazon EMR do przetwarzania danych, Amazon Glue, który zapewnia katalog danych i funkcjonalność transformacji, usługę zapytań Amazon Athena lub Amazon Elasticsearch Service, która służy do tworzenia repozytorium i indeksu metadanych dane. Lokalne jeziora danych są nadal powszechne ze względu na typowe problemy związane z chmurą, takie jak bezpieczeństwo, prywatność lub opóźnienia.

Istnieją również lokalni dostawcy pamięci masowych, którzy oferują niektóre produkty dla jezior danych, ale ich oferta jezior danych nie jest jednak dobrze zdefiniowana. W przeciwieństwie do hurtowni danych, jeziora danych nie mają za sobą wielu lat rzeczywistych wdrożeń. Wciąż spotyka się wiele krytyki opisującej koncepcję jeziora danych jako niewyraźną i źle zdefiniowaną. Krytycy twierdzą również, że niewiele osób w jakiejkolwiek organizacji ma umiejętności (lub entuzjazm w tym zakresie) do uruchamiania obciążeń eksploracyjnych na surowych danych.
Twierdzą, że do pomysłu, że jeziora danych powinny być wykorzystywane jako centralne repozytorium wszystkich danych przedsiębiorstw, należy podchodzić z ostrożnością. Odbyło się również prowokacyjne przemówienie, że dni jeziora danych są policzone. Przytoczono następujące powody:
- Jeziora danych nie mogą wydajnie skalować zasobów obliczeniowych na żądanie (cóż, to dlatego, że nie są one pierwotnie zamierzone)
- Jeziora danych niosą za sobą duży dług technologiczny, a ich tworzenie wynika głównie z szumu marketingowego, a nie z przyczyn technicznych (to samo stało się z wieloma hurtowniami danych)
- Wraz z rozwojem rozwiązań hurtowni danych w chmurze, jeziora danych nie oferują już znaczących korzyści kosztowych (kwestia kosztów nie jest tak prosta, ponieważ trudno jest przewidzieć koszty obliczeń)
Taka krytyka jest nieodłączną częścią każdej młodszej technologii. Jednak jeziora danych mają wyraźne przypadki użycia, takie jak analiza strumieniowa. A jednak nie zagrażają hurtowniom danych. W pewnym momencie jeziora danych zatriumfowały nawet nad hurtowniami danych, oferując szersze możliwości analityczne, opłacalność i elastyczność w zakresie przechowywanych danych. Jednak w miarę dojrzewania technologii hurtowni danych wielu zgadza się, że nie ma teraz oczywistego zwycięzcy. Generalnie wskazane jest, aby zachować je obie lub… wybrać architekturę hybrydową. Czytaj.
Przypadki użycia jeziora danych
Główną ideą jezior danych jest zapewnienie firmom dostępu do wszystkich dostępnych danych ze wszystkich źródeł tak szybko, jak to możliwe. Jeziora danych dają nie tylko obraz tego, co wydarzyło się wczoraj. Przechowując ogromne ilości danych, Data Lakes są zaprojektowane tak, aby umożliwić organizacjom uzyskanie więcej informacji zarówno o teraźniejszości (przy użyciu analizy strumieniowej), jak i przyszłości (przy użyciu rozwiązań big data, w tym analizy predykcyjnej i uczenia maszynowego). Kluczowe przypadki użycia jezior danych to:
- Zasilanie hurtowni danych przedsiębiorstwa zbiorami danych
- Wykonywanie analizy strumienia
- Wdrażanie projektów ML
- Tworzenie zaawansowanych wykresów analitycznych przy użyciu sprawdzonych narzędzi BI dla przedsiębiorstw, takich jak Tableau lub MS Power BI
- Budowanie niestandardowych rozwiązań do analizy danych
- Przeprowadzanie analizy przyczyn źródłowych, która pozwala zespołom zajmującym się danymi prześledzić problemy do ich źródeł
Dzięki silnym umiejętnościom inżynierii danych, które pozwalają przenieść surowe dane do środowiska analitycznego, jeziora danych mogą być niezwykle istotne. Pozwalają zespołom eksperymentować z danymi, aby zrozumieć, w jaki sposób mogą być przydatne. Może to obejmować budowanie modeli do przeszukiwania danych i wypróbowywania różnych schematów w celu przeglądania danych w nowy sposób. Jeziora danych umożliwiają również walkę z danymi strumieniowymi napływającymi z dzienników internetowych i czujników IoT i nie nadają się do tradycyjnego podejścia do hurtowni danych.
Krótko mówiąc, jeziora danych umożliwiają organizacjom odkrywanie wzorców, przewidywanie zmian lub znajdowanie potencjalnych możliwości biznesowych związanych z nowymi produktami lub bieżącymi procesami. Wykorzystywane do różnych potrzeb biznesowych, jeziora danych i hurtownie danych są często wdrażane w tandemie. Zanim przejdziemy do następnej koncepcji przechowywania danych, szybko przypomnijmy kluczowe różnice między hurtownią danych a jeziorem danych.
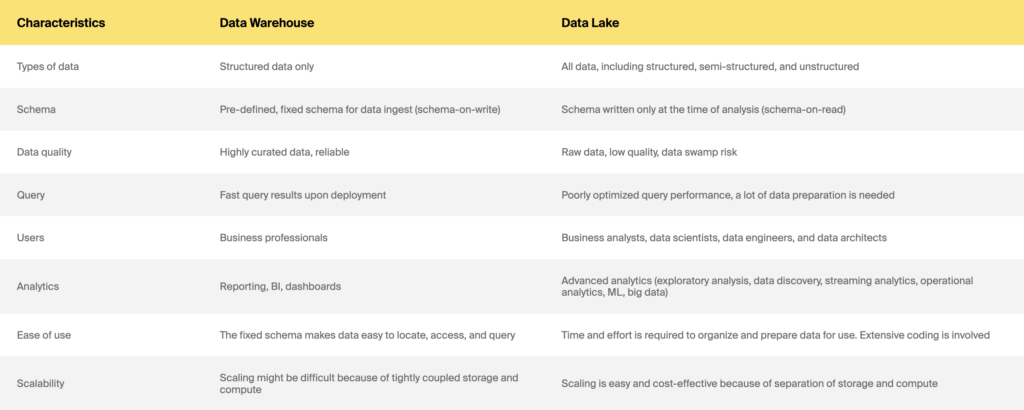
Hurtownia danych a jezioro danych
A co z nową architekturą hybrydową, Data Lakehouses?
Pomijając marketing, kluczową ideą dotyczącą Data Lakehouse jest dostarczenie mocy obliczeniowej do Data Lake. Architektonicznie Data Lakehouse składa się zazwyczaj z:
- Warstwa przechowywania do przechowywania danych w otwartych formatach (np. Parkiet). Tę warstwę można nazwać jeziorem danych i jest ona oddzielona od warstwy obliczeniowej
- Warstwa obliczeniowa zapewniająca możliwości hurtowni organizacji, obsługująca zarządzanie metadanymi, indeksowanie, egzekwowanie schematów i transakcje ACID (atomowość, spójność, niezawodność i trwałość)
- Warstwa API umożliwiająca dostęp do zasobów danych
- Warstwa obsługująca do obsługi różnych obciążeń, od raportowania po BI, analitykę danych lub uczenie maszynowe.
Rysunek 3: Architektura referencyjna Data Lakehouse
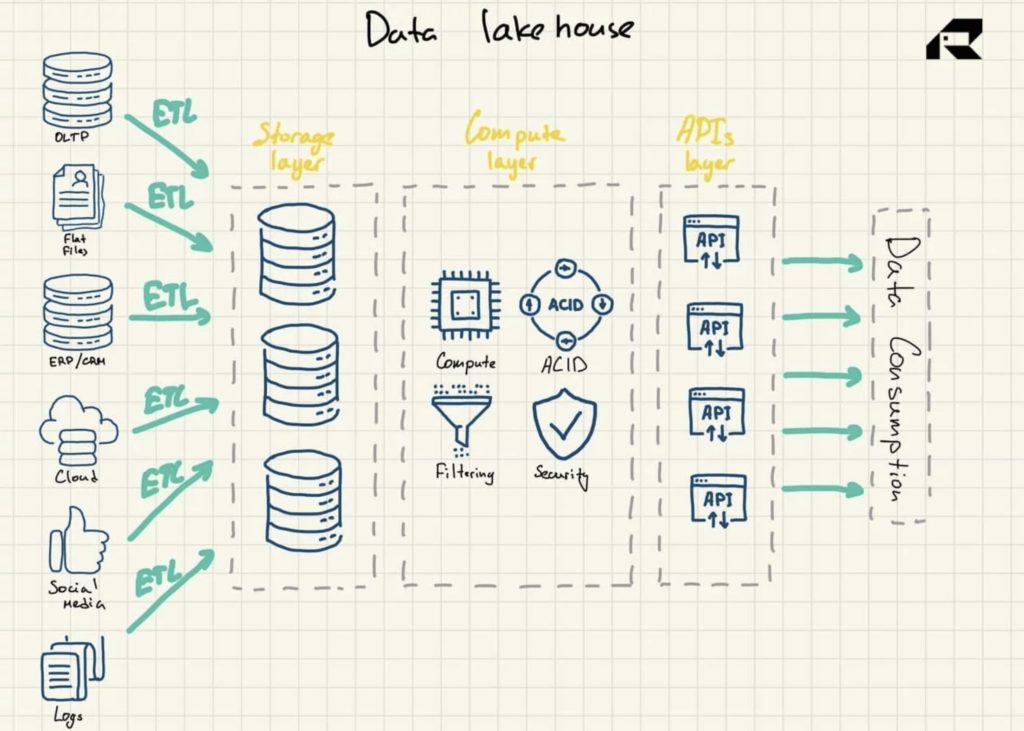
Reklamowany jako rozwiązanie łączące to, co najlepsze z obu światów, Data Lakehouse obejmuje oba:
- Ograniczenia hurtowni danych, w tym brak obsługi zaawansowanej analityki danych, która opiera się zarówno na danych ustrukturyzowanych, jak i nieustrukturyzowanych, oraz znaczne koszty skalowania w przypadku tradycyjnych hurtowni danych, które nie oddzielają pamięci masowej od zasobów obliczeniowych
- Wyzwania związane z jeziorem danych, w tym duplikacja danych, jakość danych i konieczność dostępu do wielu systemów dla różnych zadań lub wdrożenie złożonych integracji z narzędziami analitycznymi
Data Lakehouse to nowy postęp na scenie analizy danych. Koncepcja została po raz pierwszy zastosowana w 2017 roku w odniesieniu do platformy Snowflake. W 2019 r. firma AWS użyła terminu Data Lakehouse do opisania swojej usługi Amazon Redshift Spectrum, która umożliwia użytkownikom usługi hurtowni danych Amazon Redshift przeszukiwanie danych przechowywanych w Amazon S3. W 2020 roku termin Data Lakehouse wszedł do powszechnego użycia, a Databricks zaadoptował go na swojej platformie Delta Lake.
Data Lakehouse może mieć przed sobą świetlaną przyszłość, ponieważ firmy z różnych branż przyjmą sztuczną inteligencję, aby usprawnić operacje serwisowe, oferować innowacyjne produkty i usługi lub napędzać sukces marketingowy. Ustrukturyzowane dane z systemów operacyjnych dostarczane przez hurtownie danych nie nadają się do inteligentnej analizy, podczas gdy jeziora danych po prostu nie są zaprojektowane z myślą o solidnych praktykach zarządzania, zabezpieczeniach ani zgodności z ACID.
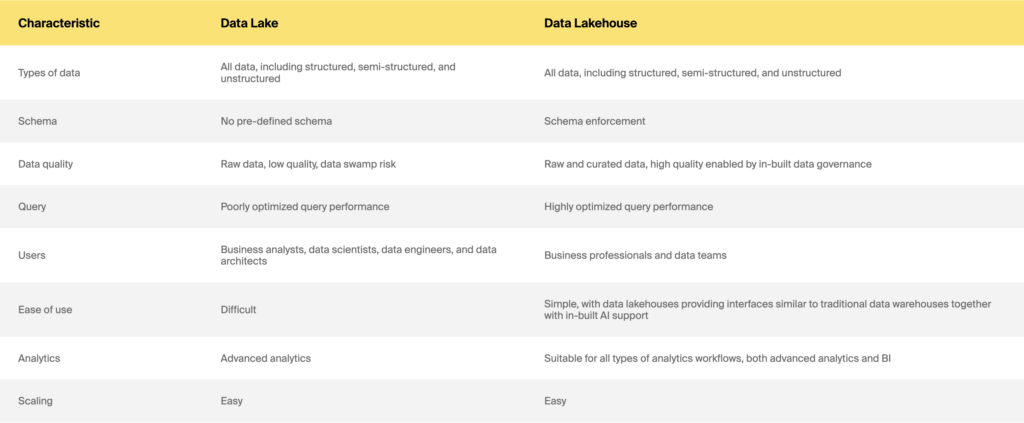
Data lake a data lakehouse
Hurtownia danych vs. Data Lake vs. Data Lakehouse: co wybrać
Niezależnie od tego, czy chcesz zbudować rozwiązanie do przechowywania danych od podstaw, czy zmodernizować swój starszy system, aby wspierać ML lub poprawić wydajność, właściwa odpowiedź nie będzie łatwa. Nadal jest dużo bałaganu co do kluczowych różnic, korzyści i kosztów, a oferty i modele cenowe dostawców szybko ewoluują. Poza tym zawsze jest to trudny projekt, nawet jeśli masz poparcie interesariuszy. Należy jednak wziąć pod uwagę kilka kluczowych kwestii, które należy wziąć pod uwagę przy wyborze hurtowni danych, Data Lake lub Data Lakehouse.
Podstawowe pytanie, na które powinieneś odpowiedzieć, to: DLACZEGO. Warto pamiętać, że kluczowe różnice między hurtowniami danych, jeziorami i domami na jeziorze nie tkwią w technologii. Chodzi o zaspokajanie różnych potrzeb biznesowych. Dlaczego więc potrzebujesz rozwiązania do przechowywania danych? Czy służy do regularnego raportowania, analizy biznesowej, analizy w czasie rzeczywistym, nauki o danych lub innych zaawansowanych analiz? Czy spójność lub terminowość danych jest ważniejsza dla potrzeb Twojej firmy? Poświęć trochę czasu na opracowanie przypadków użycia. Twoje potrzeby analityczne powinny być dobrze zdefiniowane. Powinieneś również dogłębnie zrozumieć swoich użytkowników i umiejętności. Kilka praktycznych zasad to:
- Hurtownia danych to dobry zakład, jeśli masz dokładne pytania i wiesz, jakie wyniki analiz chcesz regularnie uzyskiwać.
- Jeśli działasz w wysoce uregulowanej branży, takiej jak opieka zdrowotna lub ubezpieczenia, być może będziesz musiał przede wszystkim przestrzegać obszernych przepisów dotyczących raportowania. Zatem hurtownia danych będzie lepszym wyborem.
- Jeśli Twoje kluczowe wskaźniki efektywności i wymagania dotyczące raportowania można rozwiązać za pomocą prostej analizy historycznej, jezioro danych lub rozwiązanie hybrydowe będzie przesadą. Zamiast tego wybierz hurtownię danych.
- Jeśli Twój zespół ds. danych jest po analizie eksperymentalnej i eksploracyjnej, wybierz jezioro danych lub rozwiązanie hybrydowe. Jednak do pracy z nieustrukturyzowanymi danymi będziesz potrzebować silnych umiejętności analizy danych.
- Jeśli jesteś organizacją dojrzałą do przetwarzania danych, która chce wykorzystać technologię uczenia maszynowego, rozwiązanie hybrydowe lub jezioro danych będą naturalnym rozwiązaniem.
Weź również pod uwagę swój budżet i ograniczenia czasowe. Jeziora danych z pewnością buduje się szybciej niż hurtownie danych i prawdopodobnie są tańsze. Możesz chcieć wdrażać swoją inicjatywę stopniowo i dodawać możliwości w miarę zwiększania skali. Jeśli chcesz zmodernizować swój dotychczasowy system przechowywania danych, ponownie powinieneś zapytać, DLACZEGO tego potrzebujesz. Czy to za wolno? A może nie pozwala na uruchamianie zapytań na większych zestawach danych? Brakuje niektórych danych? Czy chcesz wyciągnąć inny rodzaj analityki? Twoja organizacja wydała dużo pieniędzy na stary system, więc zdecydowanie potrzebujesz solidnego uzasadnienia biznesowego, aby go porzucić. Powiąż go również z ROI. Architektury przechowywania danych wciąż dojrzewają. Nie można powiedzieć z całą pewnością, jak będą ewoluować. Jednak bez względu na to, którą ścieżką wybierzesz, warto rozpoznać typowe pułapki i jak najlepiej wykorzystać technologię, która już istnieje.
Mamy nadzieję, że ten artykuł wyjaśnił pewne zamieszanie związane z hurtowniami danych, jeziorami danych i jeziorami danych. Jeśli nadal masz pytania lub potrzebujesz najlepszych umiejętności technicznych lub porady, aby zbudować swoje rozwiązanie do przechowywania danych, napisz do ITRex. Oni ci pomogą.
Pierwotnie opublikowany na https://itrexgroup.com 23 lutego 2022 r.