
Eliminando a confusão: Data Warehouse vs. Data Lake vs. Data Lakehouse
Publicados: 2022-03-11Lutando para aproveitar a expansão de dados, os CIOs de todos os setores estão enfrentando desafios difíceis. Um deles é onde armazenar todos os dados de sua empresa para fornecer análises de dados robustas.
Tradicionalmente, existem duas soluções de armazenamento para dados: data warehouses e data lakes.
Os data warehouses armazenam principalmente dados estruturados e transformados de sistemas operacionais e transacionais e são usados para consultas complexas e rápidas nesses dados históricos.
Os data lakes atuam como um dump, armazenando todos os tipos de dados, incluindo dados semiestruturados e não estruturados. Eles capacitam análises avançadas, como análises de streaming para processamento de dados ao vivo ou aprendizado de máquina.
Historicamente, os data warehouses eram caros para implantar porque era necessário pagar tanto pelo espaço de armazenamento quanto pelos recursos de computação, além das habilidades para mantê-los. À medida que o custo do armazenamento diminuiu, os data warehouses tornaram-se mais baratos. Alguns acreditam que os data lakes (tradicionalmente uma alternativa mais econômica) agora estão mortos. Alguns argumentam que os data lakes ainda estão na moda. Enquanto isso, outros estão falando sobre uma nova solução híbrida de armazenamento de dados – data lakehouses.
Qual é o problema com cada um deles? Vamos dar uma olhada de perto.
Este blog explora as principais diferenças entre data warehouses, data lakes e data lakehouses, pilhas de tecnologia populares e casos de uso. Ele também fornece dicas para escolher a solução certa para sua empresa, embora esta seja complicada.
O que é um armazém de dados?
Os data warehouses são projetados para armazenar dados estruturados e selecionados, organizando conjuntos de dados em tabelas e colunas. Esses dados são facilmente disponibilizados aos usuários para business intelligence, painéis e relatórios tradicionais.
Arquitetura de armazenamento de dados
Uma arquitetura de três camadas é a abordagem mais comumente usada para projetar data warehouses. Compreende:
- Camada inferior: Uma área de preparação e o servidor de banco de dados do data warehouse que é usado para carregar dados de várias fontes. Um processo de extração, transformação e carregamento (ETL) é uma abordagem tradicional para enviar dados para o data warehouse
- Camada intermediária: um servidor para processamento analítico online (OLAP) que reorganiza os dados em um formato multidimensional para cálculos rápidos
- Nível superior: APIs e ferramentas de front-end para trabalhar com dados
Figura 1: Arquitetura de referência do data warehouse
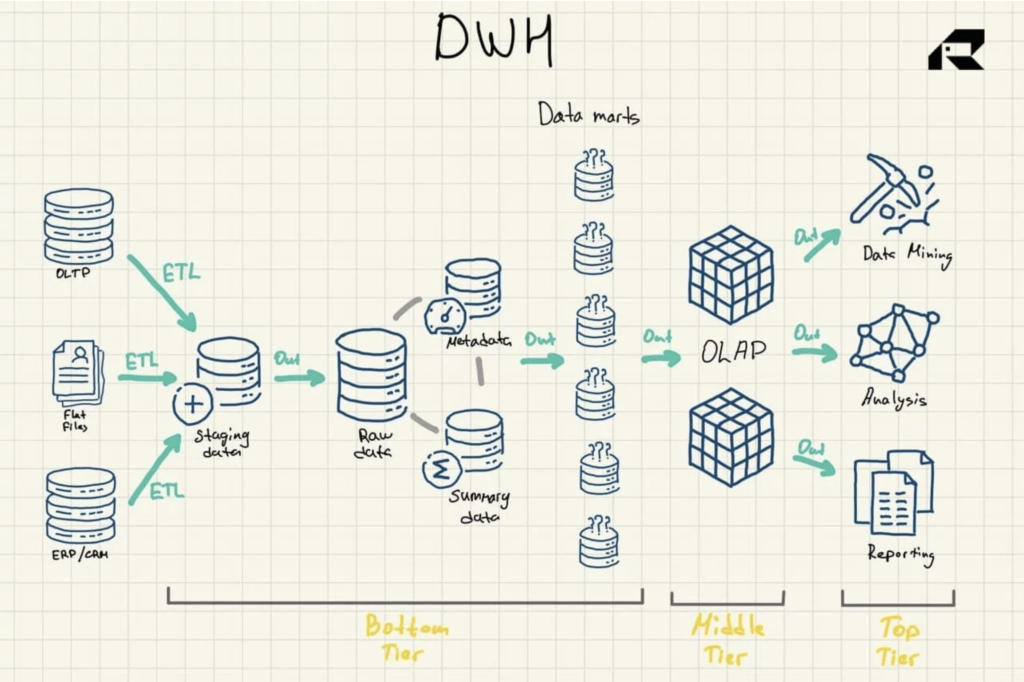
Há três outros componentes vitais de um data warehouse que devem ser mencionados: o data mart, o armazenamento de dados operacionais e os metadados. Os data marts pertencem à camada inferior. Eles armazenam subconjuntos dos dados do data warehouse, atendendo a linhas de negócios individuais.
Os armazenamentos de dados operacionais atuam como um repositório fornecendo um instantâneo dos dados mais atuais da organização para relatórios operacionais com base em consultas simples. Eles podem ser usados como uma camada intermediária entre as fontes de dados e o data warehouse.
Há também metadados — dados que descrevem os dados do data warehouse — que são armazenados em repositórios para fins especiais, também na camada inferior.
Evolução e tecnologias do data warehouse
Os data warehouses existem há algumas décadas.
Tradicionalmente, os data warehouses eram hospedados no local, o que significava que as empresas precisavam comprar todo o hardware e implantar o software localmente, seja em sistemas pagos ou de código aberto. Eles também precisavam de toda uma equipe de TI para manter o data warehouse. Pelo lado positivo, os data warehouses tradicionais estavam trazendo (e ainda o fazem hoje) um rápido tempo de percepção sem problemas de latência, controle total dos dados junto com cem por cento de privacidade e risco de segurança minimizado.
Com a onipresença na nuvem, muitas organizações agora optam por migrar para soluções de data warehouse na nuvem, onde todos os dados são armazenados em uma nuvem. Também é analisado em uma nuvem, usando algum tipo de mecanismo de consulta integrado.
Há uma variedade de soluções de armazenamento de dados em nuvem estabelecidas no mercado. Cada provedor oferece seu conjunto exclusivo de recursos de depósito e diferentes modelos de preços. Por exemplo, o Amazon Redshift é organizado como um data warehouse tradicional. Floco de neve é semelhante. O Microsoft Azure é um data warehouse SQL, enquanto o Google BigQuery é baseado em uma arquitetura sem servidor que oferece essencialmente software como serviço (SaaS), em vez de infraestrutura ou plataforma como serviço, como, por exemplo, o Amazon Redshift.
Entre as soluções de data warehouse locais bem conhecidas estão IBM Db2, Oracle Autonomous Database, IBM Netezza, Teradata Vantage, SAP HANA e Exasol. Eles também estão disponíveis na nuvem.
Os data warehouses baseados em nuvem são obviamente mais baratos porque não há necessidade de comprar ou implantar servidores físicos. Os usuários pagam apenas pelo espaço de armazenamento e poder de computação conforme necessário. As soluções em nuvem também são muito mais fáceis de dimensionar ou integrar com outros serviços.
Atendendo a necessidades de negócios altamente específicas com alta qualidade de dados e insights rápidos, os data warehouses estão aqui para ficar por muito tempo.
Casos de uso de data warehouse
Os data warehouses fornecem análises de alta velocidade e alto desempenho em petabytes e petabytes de dados históricos.
Eles são fundamentalmente projetados para consultas do tipo BI. Um data warehouse pode dar uma resposta sobre, por exemplo, vendas em um determinado período de tempo, agrupadas por região ou divisão, e movimentos de vendas ano a ano. Os principais casos de uso para data warehouses são:
- Relatórios transacionais para fornecer uma imagem do desempenho dos negócios
- Análise/relatório ad-hoc para fornecer respostas para desafios de negócios autônomos e “one-off”
- Mineração de dados para extrair conhecimento útil e padrões ocultos de dados para resolver problemas complexos do mundo real
- Apresentação dinâmica através de visualização de dados
- Aprofundamento para passar por dimensões hierárquicas de dados para obter detalhes
Ter dados de negócios estruturados em um local facilmente acessível fora dos bancos de dados operacionais é muito importante para qualquer empresa com maturidade de dados.
No entanto, os data warehouses tradicionais não suportam a tecnologia de big data.
Eles também são atualizados em lote, com registros de todas as fontes processados periodicamente de uma só vez, o que significa que os dados podem se tornar obsoletos no momento em que são acumulados para análise. O data lake parece resolver essas restrições. Com uma troca. Vamos explorar.
O que é um lago de dados?
Os data lakes geralmente coletam dados brutos não refinados em sua forma original. Outra diferença importante entre o data lake e o data warehouse é que os data lakes armazenam esses dados sem organizá-los em nenhum relacionamento lógico chamado de esquemas. No entanto, é assim que eles permitem análises mais sofisticadas.
Os data lakes extraem (i) dados transacionais de aplicativos de negócios, como ERP, CRM ou SCM, (ii) documentos nos formatos .csv e .txt, (iii) dados semiestruturados, como formatos XML, JSON e AVRO, (iv) logs de dispositivos e sensores IoT e (v) imagens, áudio, binários, arquivos PDF.
Arquitetura de data lake
Os data lakes usam uma arquitetura plana para armazenamento de dados. Seus principais componentes são:
- Zona de bronze para todos os dados ingeridos no lago. Os dados são armazenados no estado em que se encontram para padrões de lote ou como conjuntos de dados agregados para cargas de trabalho de streaming
- Zona Silver onde os dados são filtrados e enriquecidos para exploração de acordo com as necessidades do negócio
- Zona de ouro onde são armazenados dados bem estruturados e organizados para aplicação de ferramentas de BI e algoritmos de ML. Essa zona geralmente apresenta um armazenamento de dados operacional que alimenta data warehouses e data marts tradicionais
- Sandbox onde os dados podem ser experimentados para validação de hipóteses e testes. Ele é implementado como um banco de dados completamente separado para Hadoop ou outras tecnologias NoSQL ou como parte da zona de ouro.
Figura 2: Arquitetura de referência do Data Lake
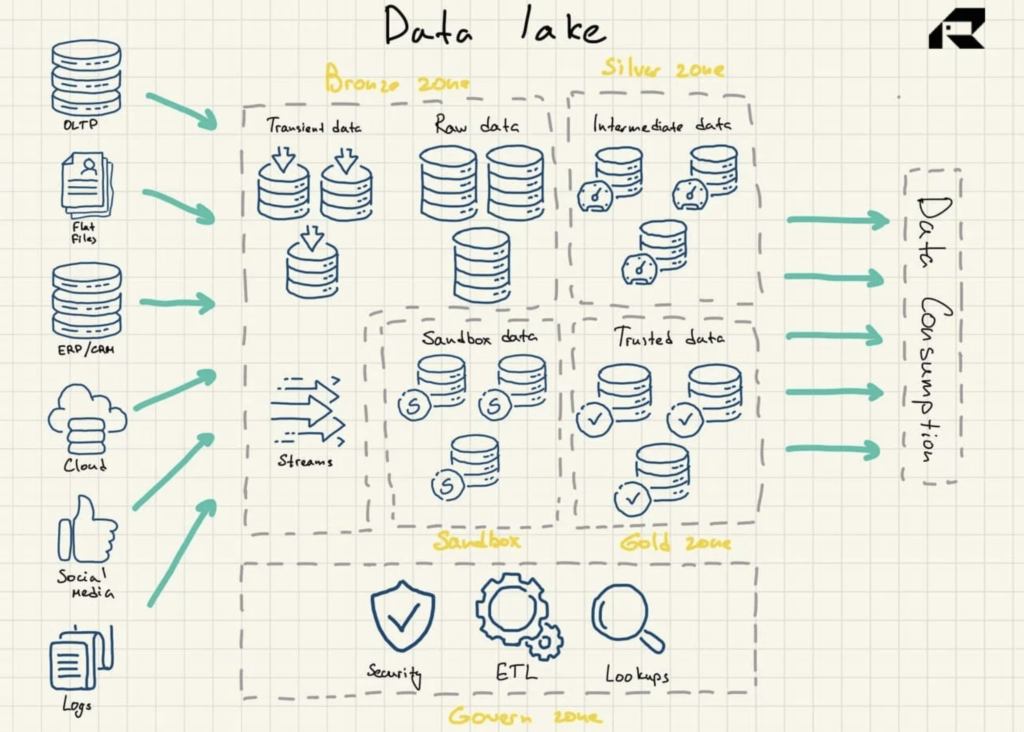
Os data lakes não contêm inerentemente recursos de análise. Sem eles, eles apenas armazenam dados brutos que não são úteis por si só. Assim, as organizações criam data warehouses ou aproveitam outras ferramentas em cima dos data lakes para colocar os dados em uso.
Para garantir que um data lake não se transforme em um pântano de dados, é importante ter uma estratégia de gerenciamento de dados eficiente para incluir governança de dados e gerenciamento de metadados integrados no design do data lake. Em um mundo ideal, os dados armazenados em um data lake devem ser catalogados, indexados, validados e facilmente disponíveis para os usuários de dados. Isso raramente é um caso e muitos projetos de data lake falham. Isso pode ser evitado: independentemente da maturidade de uma equipe de dados, é fundamental instalar pelo menos controles essenciais para impor a validação e a qualidade dos dados.
Evolução e tecnologias do data lake
A ascensão do big data no início dos anos 2000 trouxe grandes oportunidades e grandes desafios para as organizações. As empresas precisavam de novas tecnologias para analisar esses conjuntos de dados enormes, confusos e de crescimento ridiculamente rápido para capturar um impacto comercial do big data.
Em 2008, o Apache Hadoop apresentou uma tecnologia inovadora de código aberto para coletar e processar dados não estruturados em grande escala, abrindo caminho para análises de big data e data lakes. Pouco depois, o Apache Spark surgiu. Era mais fácil de usar. Além disso, forneceu recursos para criar e treinar modelos de ML, consultar dados estruturados usando SQL e processar dados em tempo real.
Hoje, os data lakes são predominantemente repositórios hospedados na nuvem. Todos os principais provedores de nuvem, como AWS, Azure e Google, oferecem data lakes baseados em nuvem com serviços de armazenamento de objetos econômicos. Suas plataformas vêm com vários serviços de gerenciamento de dados para automatizar a implantação. Em um cenário, por exemplo, um data lake pode consistir em um sistema de armazenamento de dados como o Hadoop Distributed File System (HDFS) ou o Amazon S3 integrado a uma solução de data warehouse em nuvem como o Amazon Redshift. Esses componentes seriam desacoplados de serviços no ecossistema que podem incluir Amazon EMR para processamento de dados, Amazon Glue que fornece o catálogo de dados e funcionalidade de transformação, o serviço de consulta Amazon Athena ou Amazon Elasticsearch Service que é usado para criar um repositório de metadados e índice dados. Os data lakes locais ainda são comuns devido a preocupações usuais na nuvem, como segurança, privacidade ou latência.

Há também fornecedores de armazenamento local que oferecem alguns produtos para data lakes, mas suas ofertas de data lakes, no entanto, não são bem definidas. Ao contrário dos data warehouses, os data lakes não têm muitos anos de implantações no mundo real por trás deles. Ainda há muitas críticas descrevendo o conceito de data lake como obscuro e mal definido. Os críticos também argumentam que poucas pessoas em qualquer organização têm as habilidades (ou entusiasmo para esse assunto) para executar cargas de trabalho exploratórias em dados brutos.
A ideia de que os data lakes devem ser usados como um repositório central para todos os dados das empresas precisa ser abordada com cautela, dizem eles. Também houve uma conversa provocativa de que os dias do data lake estão contados. São citados os seguintes motivos:
- Os data lakes não podem dimensionar recursos de computação de forma eficiente sob demanda (bem, isso ocorre porque eles não são planejados pelo design em primeiro lugar)
- Os data lakes carregam uma grande dívida de tecnologia, com sua criação impulsionada principalmente pelo hype de marketing, e não por razões técnicas (o mesmo aconteceu com muitos data warehouses também)
- Com o aumento das soluções de armazenamento de dados em nuvem, os data lakes não oferecem mais benefícios de custo significativos (a questão do custo não é tão direta, pois é difícil prever os custos de computação)
Tal crítica é uma parte inerente de qualquer tecnologia mais jovem. No entanto, os data lakes têm casos de uso claros, como análises de streaming. E ainda assim, eles não ameaçam os data warehouses. Em algum momento, os data lakes até triunfaram sobre os data warehouses, oferecendo recursos analíticos mais amplos, economia e flexibilidade em termos de dados armazenados. No entanto, à medida que as tecnologias de data warehouse amadureceram, muitos concordam que não há um vencedor óbvio agora. Geralmente é aconselhável manter os dois ou… optar por uma arquitetura híbrida. Leia.
Casos de uso do data lake
A ideia principal sobre os data lakes é dar aos negócios acesso a todos os dados disponíveis de todas as fontes o mais rápido possível. Os data lakes não fornecem apenas uma imagem do que aconteceu ontem. Armazenando grandes quantidades de dados, os data lakes são projetados para permitir que as organizações aprendam mais sobre o presente (usando análise de streaming) e o futuro (usando soluções de big data, incluindo análise preditiva e aprendizado de máquina). Os principais casos de uso para data lakes são:
- Alimentando um data warehouse corporativo com conjuntos de dados
- Como realizar análises de fluxo
- Implementação de projetos de ML
- Criação de gráficos de análise avançada usando ferramentas de BI corporativas estabelecidas há muito tempo, como Tableau ou MS Power BI
- Criando soluções de análise de dados personalizadas
- Executar análise de causa raiz que permite que as equipes de dados rastreiem os problemas até suas raízes
Com fortes habilidades de engenharia de dados para mover dados brutos para um ambiente de análise, os data lakes podem ser extremamente relevantes. Eles permitem que as equipes experimentem os dados para entender como eles podem ser úteis. Isso pode envolver a construção de modelos para explorar os dados e experimentar diferentes esquemas para visualizar os dados de novas maneiras. Os data lakes também permitem disputas com dados de fluxo que chegam de logs da Web e sensores de IoT e não são adequados para uma abordagem tradicional de data warehouse.
Em suma, os data lakes permitem que as organizações descubram padrões, antecipem mudanças ou encontrem potenciais oportunidades de negócios em torno de novos produtos ou processos atuais. Usados para diferentes necessidades de negócios, data lakes e data warehouses são frequentemente implementados em conjunto. Antes de passarmos para o próximo conceito de armazenamento de dados, vamos recapitular rapidamente as principais diferenças entre o data warehouse e o data lake.
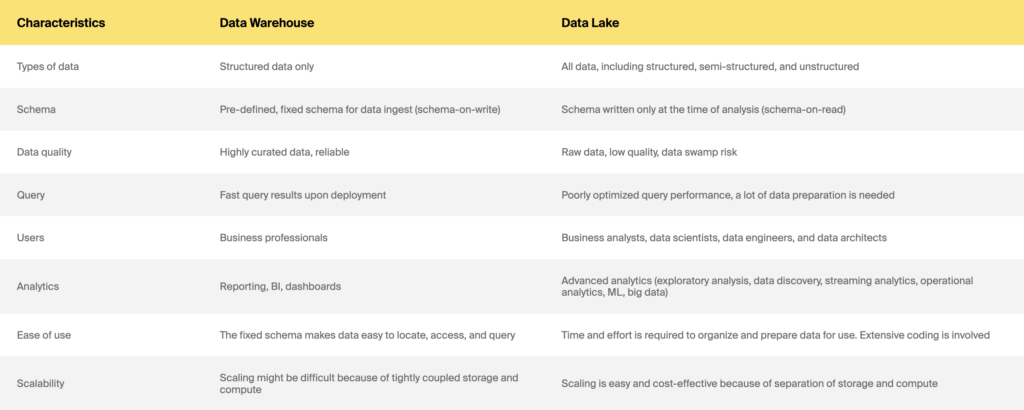
Data warehouse x data lake
Que tal uma nova arquitetura híbrida, data lakehouses?
Deixando de lado o marketing, a ideia-chave sobre um data lakehouse é trazer poder de computação para um data lake. Arquitetonicamente, o data lakehouse geralmente consiste em:
- Camada de armazenamento para armazenar dados em formatos abertos (por exemplo, Parquet). Essa camada pode ser chamada de data lake e é separada da camada de computação
- Camada de computação que fornece recursos de warehouse da organização, suportando gerenciamento de metadados, indexação, imposição de esquema e transações ACID (Atomicity, Consistency, Reliability, and Durability)
- Camada de APIs para acessar ativos de dados
- Camada de serviço para dar suporte a várias cargas de trabalho, de relatórios a BI, ciência de dados ou aprendizado de máquina.
Figura 3: Arquitetura de referência do Data Lakehouse
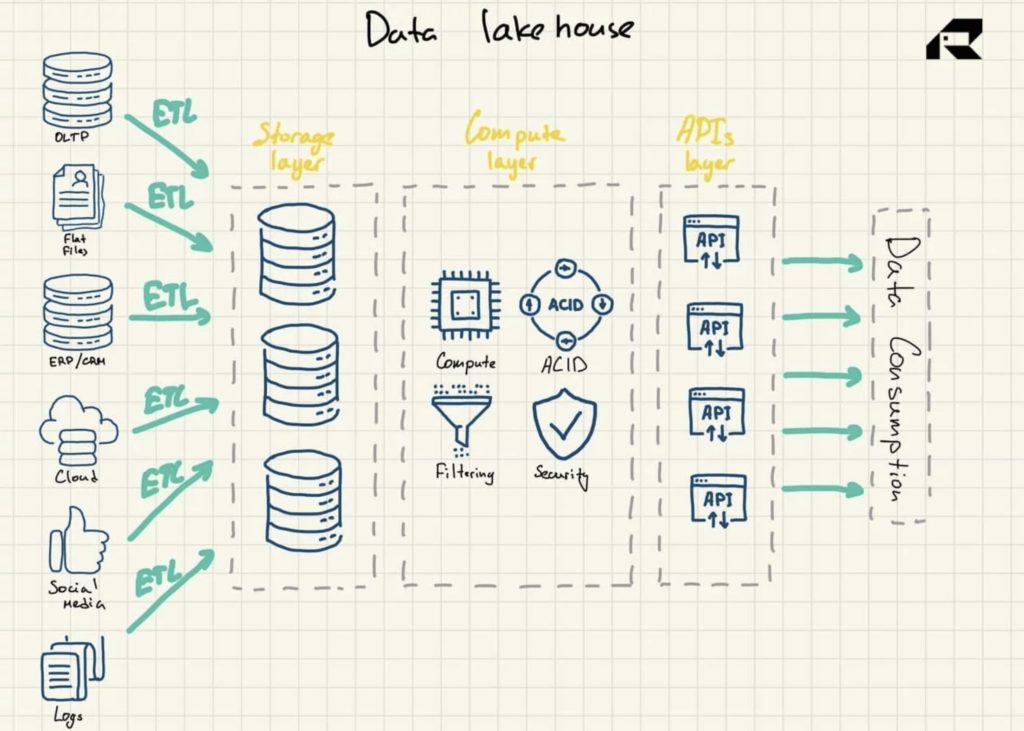
Apresentado como uma solução que casa o melhor dos dois mundos, o data lakehouse aborda ambos:
- Restrições de data warehouse, incluindo falta de suporte de análise de dados avançada que depende de dados estruturados e não estruturados e custos de dimensionamento significativos com data warehouses tradicionais que não separam armazenamento de recursos de computação
- Desafios do data lake, incluindo duplicação de dados, qualidade de dados e a necessidade de acessar vários sistemas para várias tarefas ou implementar integrações complexas com ferramentas de análise
O data lakehouse é um novo avanço no cenário de análise de dados. O conceito foi usado pela primeira vez em 2017 em relação à plataforma Snowflake. Em 2019, a AWS usou o termo data lakehouse para descrever seu serviço Amazon Redshift Spectrum, que permite aos usuários de seu serviço de data warehouse Amazon Redshift pesquisar dados armazenados no Amazon S3. Em 2020, o termo data lakehouse entrou em uso generalizado, com a Databricks adotando-o para sua plataforma Delta Lake.
O data lakehouse pode ter um futuro brilhante pela frente, já que empresas de todos os setores estão adotando a IA para melhorar as operações de serviço, oferecer produtos e serviços inovadores ou impulsionar o sucesso do marketing. Dados estruturados de sistemas operacionais fornecidos por data warehouses não são adequados para análises inteligentes, enquanto os data lakes simplesmente não são projetados para práticas robustas de governança, segurança ou conformidade com ACID.
Data lake vs. data lakehouse
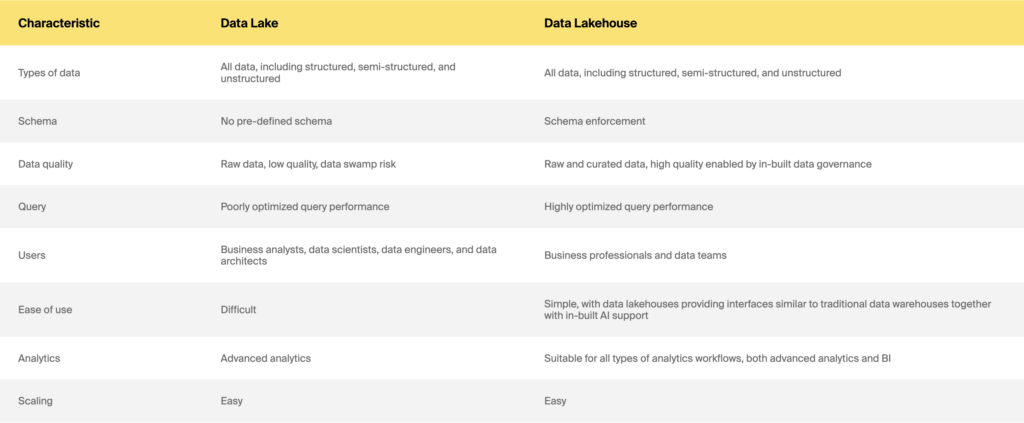
Então, data warehouse x data lake x data lakehouse: qual escolher
Se você deseja criar uma solução de armazenamento de dados do zero ou modernizar seu sistema legado para oferecer suporte a ML ou melhorar o desempenho, a resposta certa não será fácil. Ainda há muita confusão sobre as principais diferenças, benefícios e custos, com ofertas e modelos de preços de fornecedores evoluindo rapidamente. Além disso, é sempre um projeto difícil, mesmo que você tenha a adesão das partes interessadas. No entanto, há algumas considerações importantes ao escolher o data warehouse versus o data lake versus o data lakehouse.
A pergunta principal que você deve responder é: POR QUE. Um bom ponto aqui a ser lembrado é que as principais diferenças entre data warehouse, lagos e lakehouses não estão na tecnologia. Eles tratam de atender a diferentes necessidades de negócios. Então, por que você precisa de uma solução de armazenamento de dados em primeiro lugar? É para relatórios regulares, inteligência de negócios, análises em tempo real, ciência de dados ou outras análises sofisticadas? A consistência ou a pontualidade dos dados é mais importante para suas necessidades de negócios? Passe algum tempo desenvolvendo casos de uso. Suas necessidades de análise devem ser bem definidas. Você também deve entender profundamente seus usuários e conjuntos de habilidades. Algumas regras práticas são:
- Um data warehouse é uma boa aposta se você tiver perguntas exatas e souber quais resultados de análise deseja obter regularmente.
- Se você estiver em um setor altamente regulamentado, como saúde ou seguro, talvez seja necessário cumprir com os regulamentos de relatórios abrangentes acima de tudo. Portanto, um data warehouse será uma escolha melhor.
- Se seus KPIs e requisitos de relatórios puderem ser abordados com uma análise histórica simples, um data lake ou uma solução híbrida será um exagero. Vá com um data warehouse em vez disso.
- Se sua equipe de dados estiver atrás de análises experimentais e exploratórias, escolha um data lake ou uma solução híbrida. No entanto, você precisará de fortes habilidades de análise de dados para trabalhar com dados não estruturados.
- Se você é uma organização com maturidade de dados que deseja aproveitar a tecnologia de aprendizado de máquina, uma solução híbrida ou data lake será uma opção natural.
Considere também o seu orçamento e restrições de tempo. Os data lakes são certamente mais rápidos de construir do que os data warehouses e provavelmente mais baratos. Você pode querer implementar sua iniciativa de forma incremental e adicionar recursos à medida que aumenta. Se você deseja modernizar seu sistema de armazenamento de dados legado, novamente, pergunte POR QUE você precisa disso. É muito lento? Ou não permite que você execute consultas em conjuntos de dados maiores? Está faltando algum dado? Você quer extrair um tipo diferente de análise? Sua organização gastou muito dinheiro no sistema legado, então você definitivamente precisa de um caso de negócios forte para abandoná-lo. Amarre-o a um ROI também. As arquiteturas de armazenamento de dados ainda estão amadurecendo. É impossível dizer com certeza como eles vão evoluir. No entanto, não importa qual caminho você tome, é útil reconhecer as armadilhas comuns e aproveitar ao máximo a tecnologia que já está aqui.
Esperamos que este artigo tenha esclarecido alguma confusão sobre data warehouses versus data lakes versus data lakehouses. Se você ainda tiver dúvidas ou precisar de habilidades ou conselhos de tecnologia de ponta para criar sua solução de armazenamento de dados, fale com a ITRex. Eles ajudarão você.
Originalmente publicado em https://itrexgroup.com em 23 de fevereiro de 2022.