
Eliminando la confusión: Data Warehouse vs. Data Lake vs. Data Lakehouse
Publicado: 2022-03-11Luchando por aprovechar la expansión de datos, los CIO de todas las industrias enfrentan desafíos difíciles. Uno de ellos es dónde almacenar todos los datos de su empresa para ofrecer análisis de datos sólidos.
Tradicionalmente ha habido dos soluciones de almacenamiento de datos: almacenes de datos y lagos de datos.
Los almacenes de datos almacenan principalmente datos estructurados y transformados de sistemas operativos y transaccionales, y se utilizan para consultas rápidas y complejas a través de estos datos históricos.
Los lagos de datos actúan como un volcado, almacenando todo tipo de datos, incluidos datos semiestructurados y no estructurados. Potencian el análisis avanzado, como el análisis de transmisión para el procesamiento de datos en vivo o el aprendizaje automático.
Históricamente, los almacenes de datos eran costosos de implementar porque era necesario pagar tanto por el espacio de almacenamiento como por los recursos informáticos, además de las habilidades para mantenerlos. A medida que el costo del almacenamiento ha disminuido, los almacenes de datos se han abaratado. Algunos creen que los lagos de datos (tradicionalmente una alternativa más rentable) ahora están muertos. Algunos argumentan que los lagos de datos todavía están de moda. Mientras tanto, otros hablan de una nueva solución híbrida de almacenamiento de datos: data lakehouses.
¿Cuál es el trato con cada uno de ellos? Echemos un vistazo de cerca.
Este blog explora las diferencias clave entre almacenes de datos, lagos de datos y casas de lagos de datos, pilas tecnológicas populares y casos de uso. También proporciona consejos para elegir la solución adecuada para su empresa, aunque esta es complicada.
¿Qué es un almacén de datos?
Los almacenes de datos están diseñados para almacenar datos estructurados y seleccionados, organizando conjuntos de datos en tablas y columnas. Estos datos están fácilmente disponibles para los usuarios para la inteligencia comercial, los tableros y los informes tradicionales.
Arquitectura del almacén de datos
Una arquitectura de tres niveles es el enfoque más utilizado para diseñar almacenes de datos. Comprende:
- Nivel inferior: un área de preparación y el servidor de base de datos del almacén de datos que se utiliza para cargar datos de varias fuentes. Un proceso de extracción, transformación y carga (ETL) es un enfoque tradicional para enviar datos al almacén de datos
- Nivel medio: un servidor para el procesamiento analítico en línea (OLAP) que reorganiza los datos en un formato multidimensional para cálculos rápidos
- Nivel superior: API y herramientas de interfaz para trabajar con datos
Figura 1: Arquitectura de referencia del almacén de datos
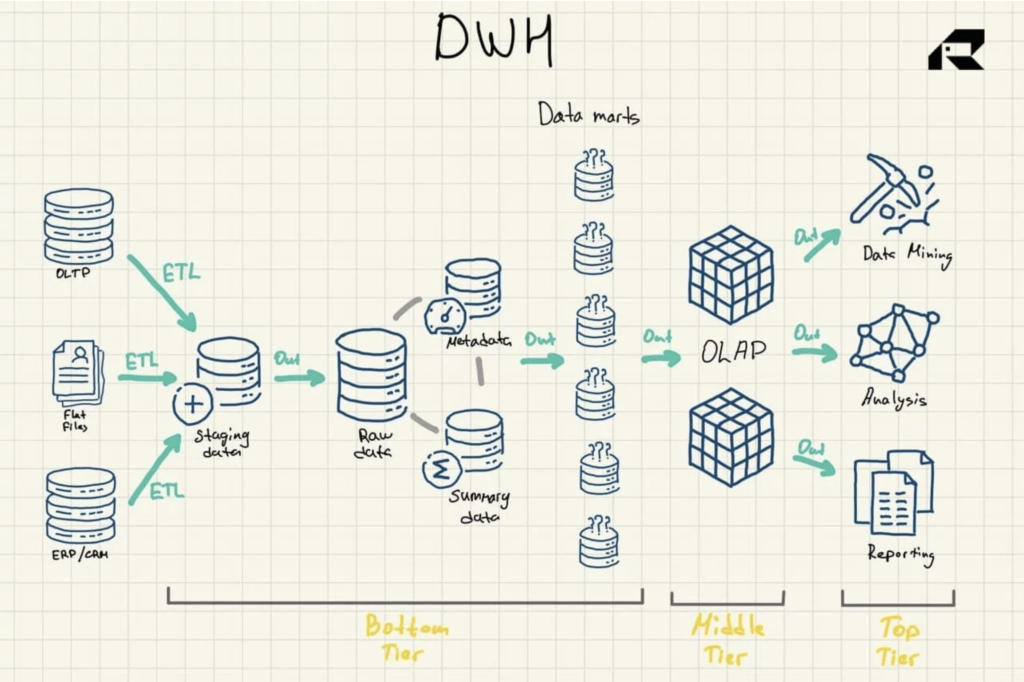
Hay otros tres componentes vitales de un almacén de datos que deben mencionarse: el data mart, el almacenamiento de datos operativos y los metadatos. Los data marts pertenecen al nivel inferior. Almacenan subconjuntos de los datos del almacén de datos, sirviendo a líneas comerciales individuales.
Los almacenes de datos operativos actúan como un repositorio que proporciona una instantánea de los datos más actuales de la organización para generar informes operativos basados en consultas simples. Pueden usarse como una capa intermedia entre las fuentes de datos y el almacén de datos.
También hay metadatos, datos que describen los datos del almacén de datos, que se almacenan en repositorios especiales, también en la capa inferior.
Evolución y tecnologías del almacén de datos
Los almacenes de datos existen desde hace algunas décadas.
Tradicionalmente, los almacenes de datos se alojaban en las instalaciones, lo que significaba que las empresas tenían que comprar todo el hardware e implementar el software localmente, ya sea sistemas pagos o de código abierto. También necesitaban todo un equipo de TI para mantener el almacén de datos. En el lado positivo, los almacenes de datos tradicionales estaban brindando (y aún lo hacen hoy en día) un rápido tiempo de conocimiento sin problemas de latencia, control total de los datos junto con un cien por ciento de privacidad y un riesgo de seguridad minimizado.
Con la ubicuidad de la nube, muchas organizaciones ahora eligen migrar a soluciones de almacenamiento de datos en la nube donde todos los datos se almacenan en una nube. También se analiza en una nube, utilizando algún tipo de motor de consulta integrado.
Hay una variedad de soluciones establecidas de almacenamiento de datos en la nube en el mercado. Cada proveedor ofrece su conjunto único de capacidades de almacén y diferentes modelos de precios. Por ejemplo, Amazon Redshift está organizado como un almacén de datos tradicional. Copo de nieve es similar. Microsoft Azure es un almacén de datos SQL, mientras que Google BigQuery se basa en una arquitectura sin servidor que ofrece, en esencia, software como servicio (SaaS), en lugar de infraestructura o plataforma como servicio como, por ejemplo, Amazon Redshift.
Entre las soluciones de almacenamiento de datos locales más conocidas se encuentran IBM Db2, Oracle Autonomous Database, IBM Netezza, Teradata Vantage, SAP HANA y Exasol. También están disponibles en la nube.
Los almacenes de datos basados en la nube son obviamente más baratos porque no hay necesidad de comprar o implementar servidores físicos. Los usuarios pagan solo por el espacio de almacenamiento y la potencia informática según sea necesario. Las soluciones en la nube también son mucho más fáciles de escalar o integrar con otros servicios.
Al atender necesidades comerciales altamente específicas con la mejor calidad de datos y conocimientos rápidos, los almacenes de datos están aquí para quedarse por mucho tiempo.
Casos de uso del almacén de datos
Los almacenes de datos ofrecen análisis de alta velocidad y alto rendimiento en petabytes y petabytes de datos históricos.
Están diseñados fundamentalmente para consultas de tipo BI. Un almacén de datos podría dar una respuesta sobre, por ejemplo, las ventas en un período de tiempo particular, agrupadas por región o división, y los movimientos de ventas año tras año. Los casos de uso clave para los almacenes de datos son:
- Informes transaccionales para ofrecer una imagen del rendimiento empresarial
- Análisis/informes ad-hoc para proporcionar respuestas a desafíos comerciales independientes y "únicos"
- Minería de datos para extraer conocimiento útil y patrones ocultos de los datos para resolver problemas complejos del mundo real
- Presentación dinámica a través de la visualización de datos
- Profundización para recorrer las dimensiones jerárquicas de los datos para obtener detalles
Tener datos comerciales estructurados en una ubicación de fácil acceso fuera de las bases de datos operativas es muy importante para cualquier empresa madura de datos.
Sin embargo, los almacenes de datos tradicionales no son compatibles con la tecnología de big data.
También se actualizan por lotes, con registros de todas las fuentes procesados periódicamente de una sola vez, lo que significa que los datos pueden volverse obsoletos en el momento en que se acumulan para el análisis. El lago de datos parece resolver estas limitaciones. Con una compensación. Vamos a explorar.
¿Qué es un lago de datos?
Los lagos de datos recopilan principalmente datos sin procesar sin refinar en su forma original. Otra diferencia clave entre el lago de datos y el almacén de datos es que los lagos de datos almacenan estos datos sin organizarlos en relaciones lógicas que se denominan esquemas. Sin embargo, así es como permiten análisis más sofisticados.
Los lagos de datos extraen (i) datos transaccionales de aplicaciones comerciales como ERP, CRM o SCM, (ii) documentos en formatos .csv y .txt, (iii) datos semiestructurados como formatos XML, JSON y AVRO, (iv) registros de dispositivos y sensores IoT, y (v) archivos de imágenes, audio, binarios y PDF.
Arquitectura del lago de datos
Los lagos de datos utilizan una arquitectura plana para el almacenamiento de datos. Sus componentes clave son:
- Zona de bronce para todos los datos ingeridos en el lago. Los datos se almacenan tal cual para patrones por lotes o como conjuntos de datos agregados para cargas de trabajo de transmisión.
- Zona plateada donde se filtran y enriquecen los datos para su exploración según las necesidades del negocio
- Zona dorada donde se almacenan datos seleccionados y bien estructurados para aplicar herramientas de BI y algoritmos de ML. Esta zona a menudo presenta un almacén de datos operativos que alimenta los almacenes de datos tradicionales y los mercados de datos.
- Sandbox donde se pueden experimentar los datos para la validación y prueba de hipótesis. Se implementa como una base de datos completamente separada para Hadoop u otras tecnologías NoSQL o como parte de la zona dorada.
Figura 2: Arquitectura de referencia del lago de datos
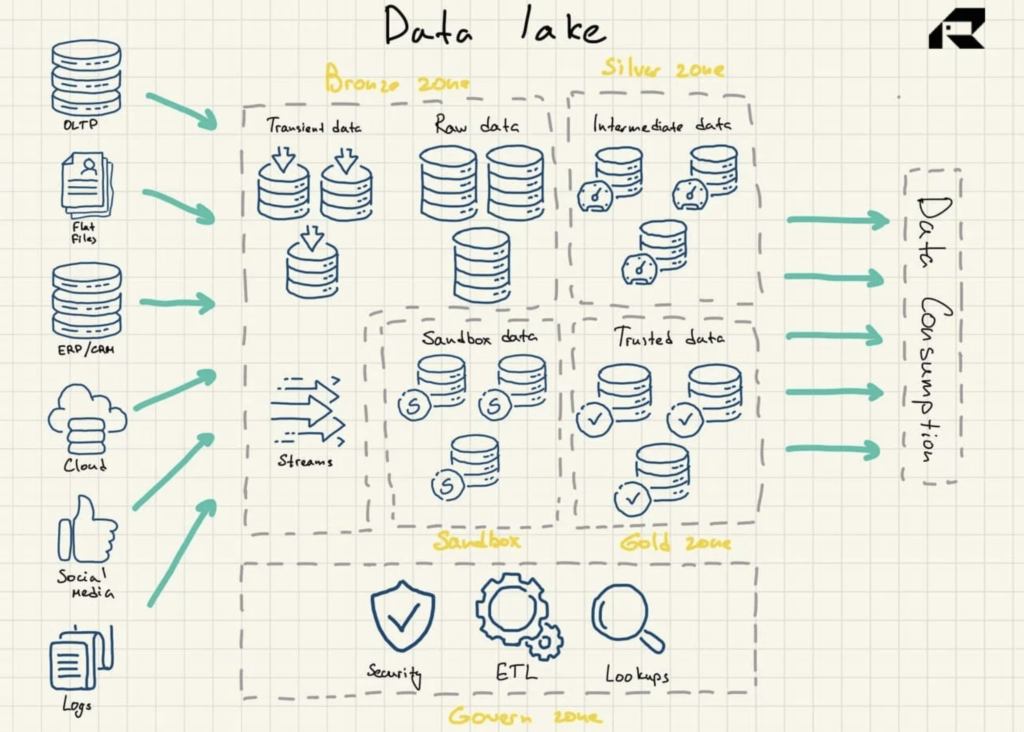
Los lagos de datos no contienen inherentemente capacidades de análisis. Sin ellos, solo almacenan datos sin procesar que no son útiles por derecho propio. Por lo tanto, las organizaciones crean almacenes de datos o aprovechan otras herramientas además de los lagos de datos para utilizar los datos.
Para asegurarse de que un lago de datos no se convierta en un pantano de datos, es importante contar con una estrategia de gestión de datos eficiente para incluir el gobierno de datos y la gestión de metadatos integrados en el diseño del lago de datos. En un mundo ideal, los datos que se encuentran en un lago de datos deben catalogarse, indexarse, validarse y estar fácilmente disponibles para los usuarios de datos. Sin embargo, esto rara vez es un caso y muchos proyectos de lagos de datos fallan. Esto se puede evitar: independientemente de la madurez de un equipo de datos, es fundamental instalar al menos controles esenciales para hacer cumplir la validación y la calidad de los datos.
Evolución y tecnologías del lago de datos
El auge de los grandes datos a principios de la década de 2000 ha traído grandes oportunidades y grandes desafíos para las organizaciones. Las empresas necesitaban nueva tecnología para analizar estos conjuntos de datos masivos, desordenados y de crecimiento ridículamente rápido para capturar un impacto comercial de los grandes datos.
En 2008, Apache Hadoop ideó una innovadora tecnología de código abierto para recopilar y procesar datos no estructurados a gran escala, allanando el camino para el análisis de big data y los lagos de datos. Poco después, surgió Apache Spark. Era más fácil de usar. Además, proporcionó capacidades para crear y entrenar modelos ML, consultar datos estructurados mediante SQL y procesar datos en tiempo real.
Hoy en día, los lagos de datos son principalmente repositorios alojados en la nube. Todos los principales proveedores de la nube, como AWS, Azure y Google, ofrecen lagos de datos basados en la nube con servicios rentables de almacenamiento de objetos. Sus plataformas vienen con varios servicios de gestión de datos para automatizar la implementación. En un escenario, por ejemplo, un lago de datos podría consistir en un sistema de almacenamiento de datos como el Sistema de archivos distribuidos de Hadoop (HDFS) o Amazon S3 integrado con una solución de almacenamiento de datos en la nube como Amazon Redshift. Estos componentes se desvincularían de los servicios en el ecosistema que podrían incluir Amazon EMR para el procesamiento de datos, Amazon Glue que proporciona el catálogo de datos y la funcionalidad de transformación, el servicio de consulta de Amazon Athena o Amazon Elasticsearch Service que se utiliza para crear un índice y un repositorio de metadatos. datos. Los lagos de datos locales siguen siendo comunes debido a las preocupaciones habituales de la nube, como la seguridad, la privacidad o la latencia.

También hay proveedores de almacenamiento local que ofrecen algunos productos para lagos de datos, pero sus ofertas de lagos de datos, sin embargo, no están bien definidas. A diferencia de los almacenes de datos, los lagos de datos no cuentan con muchos años de implementación en el mundo real. Todavía hay muchas críticas que describen el concepto de lago de datos como borroso y mal definido. Los críticos también argumentan que pocas personas en cualquier organización tienen las habilidades (o el entusiasmo) para ejecutar cargas de trabajo exploratorias contra datos sin procesar.
La idea de que los lagos de datos deben usarse como un depósito central para los datos de todas las empresas debe abordarse con precaución, dicen. También se ha hablado provocativamente de que los días de los lagos de datos están contados. Se citan las siguientes razones:
- Los lagos de datos no pueden escalar los recursos de cómputo de manera eficiente bajo demanda (bueno, esto se debe a que, en primer lugar, no están previstos en el diseño)
- Los lagos de datos conllevan una gran deuda tecnológica, ya que su creación se debe principalmente a la exageración del marketing, en lugar de razones técnicas (lo mismo ha sucedido con muchos almacenes de datos).
- Con el auge de las soluciones de almacenamiento de datos en la nube, los lagos de datos ya no ofrecen beneficios de costos significativos (el problema de los costos no es tan sencillo como es difícil pronosticar los costos de computación)
Tal crítica es una parte inherente de cualquier tecnología más joven. Sin embargo, los lagos de datos tienen casos de uso claros, como el análisis de transmisión. Y aún así, no amenazan los almacenes de datos. En algún momento, los lagos de datos incluso triunfaron sobre los almacenes de datos, ofreciendo capacidades de análisis más amplias, rentabilidad y flexibilidad en términos de datos almacenados. Sin embargo, a medida que las tecnologías de almacenamiento de datos han madurado, muchos están de acuerdo en que ahora no hay un ganador obvio. En general, es recomendable mantenerlos a ambos o... optar por una arquitectura híbrida. sigue leyendo
Casos de uso del lago de datos
La idea principal de los lagos de datos es dar acceso comercial a todos los datos disponibles de todas las fuentes lo más rápido posible. Los lagos de datos no solo dan una imagen de lo que sucedió ayer. Los lagos de datos, que almacenan cantidades masivas de datos, están diseñados para permitir que las organizaciones aprendan más sobre el presente (usando análisis de transmisión) y el futuro (usando soluciones de big data, incluido el análisis predictivo y el aprendizaje automático). Los casos de uso clave para los lagos de datos son:
- Alimentar un almacén de datos empresarial con conjuntos de datos
- Realización de análisis de flujo
- Implementación de proyectos de ML
- Creación de gráficos de análisis avanzados con herramientas de BI empresarial establecidas desde hace mucho tiempo, como Tableau o MS Power BI
- Creación de soluciones de análisis de datos personalizadas
- Ejecución de análisis de causa raíz que permite a los equipos de datos rastrear los problemas hasta sus raíces
Con fuertes habilidades de ingeniería de datos para mover datos sin procesar a un entorno de análisis, los lagos de datos pueden ser extremadamente relevantes. Permiten que los equipos experimenten con datos para comprender cómo pueden ser útiles. Esto podría implicar la creación de modelos para profundizar en los datos y probar diferentes esquemas para ver los datos de nuevas formas. Los lagos de datos también permiten lidiar con flujos de datos que provienen de registros web y sensores de IoT y no son adecuados para un enfoque de almacenamiento de datos tradicional.
En resumen, los lagos de datos permiten a las organizaciones descubrir patrones, anticipar cambios o encontrar oportunidades comerciales potenciales en torno a nuevos productos o procesos actuales. Utilizados para diferentes necesidades comerciales, los lagos de datos y los almacenes de datos a menudo se implementan en conjunto. Antes de pasar al siguiente concepto de almacenamiento de datos, recapitulemos rápidamente las diferencias clave entre el almacén de datos y el lago de datos.
Almacén de datos frente a lago de datos
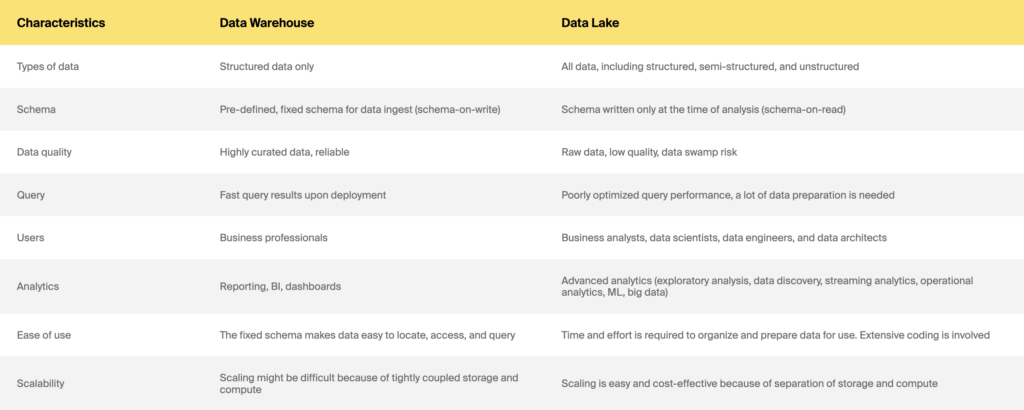
¿Qué pasa con una nueva arquitectura híbrida, data lakehouses?
Dejando a un lado el marketing, la idea clave sobre una casa de lago de datos es llevar el poder de cómputo a un lago de datos. Arquitectónicamente, la casa del lago de datos generalmente consta de:
- Capa de almacenamiento para almacenar datos en formatos abiertos (por ejemplo, Parquet). Esta capa se puede denominar lago de datos y está separada de la capa informática.
- Capa de computación que brinda a la organización capacidades de almacén, que admite la administración de metadatos, la indexación, la aplicación de esquemas y las transacciones ACID (Atomicidad, Consistencia, Confiabilidad y Durabilidad)
- Capa de API para acceder a activos de datos
- Capa de servicio para admitir varias cargas de trabajo, desde informes hasta BI, ciencia de datos o aprendizaje automático.
Figura 3: Arquitectura de referencia de Data Lakehouse
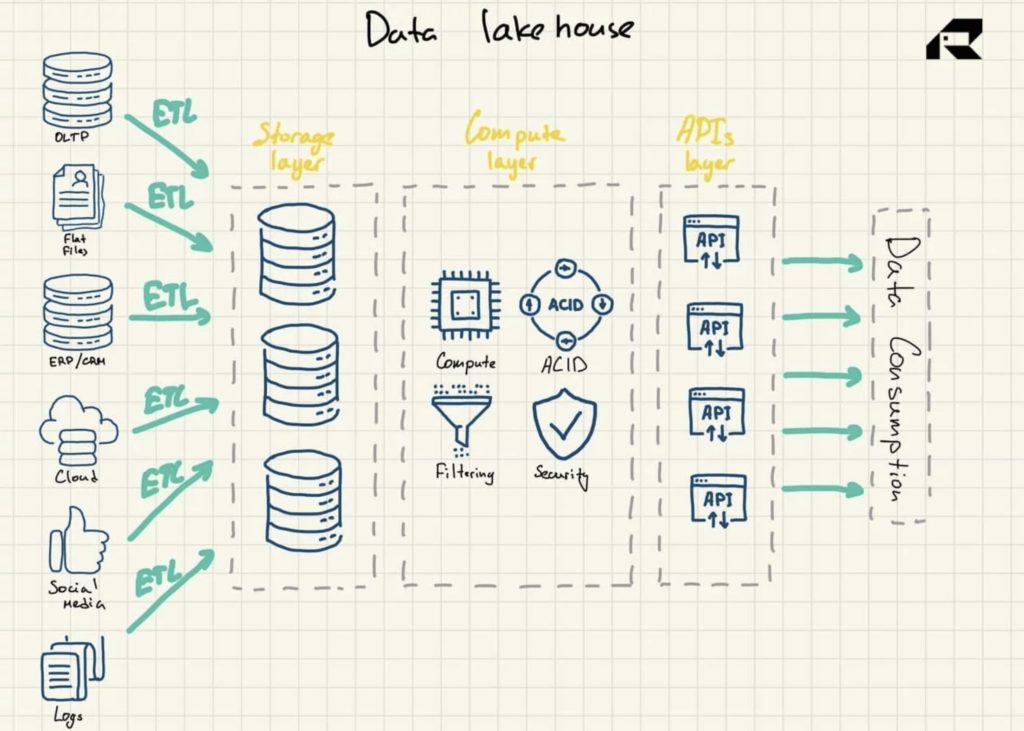
Promocionado como una solución que combina lo mejor de ambos mundos, el lago de datos aborda ambos:
- Restricciones del almacén de datos, incluida la falta de soporte de análisis de datos avanzados que se basan tanto en datos estructurados como no estructurados y costos de escalamiento significativos con los almacenes de datos tradicionales que no separan el almacenamiento de los recursos informáticos.
- Desafíos del lago de datos, incluida la duplicación de datos, la calidad de los datos y la necesidad de acceder a múltiples sistemas para diversas tareas o implementar integraciones complejas con herramientas de análisis
Data Lakehouse es un nuevo avance en la escena del análisis de datos. El concepto se utilizó por primera vez en 2017 en relación con la plataforma Snowflake. En 2019, AWS utilizó el término data lakehouse para describir su servicio Amazon Redshift Spectrum que permite a los usuarios de su servicio de almacenamiento de datos Amazon Redshift buscar en los datos almacenados en Amazon S3. En 2020, el término data lakehouse se generalizó y Databricks lo adoptó para su plataforma Delta Lake.
El lago de datos podría tener un futuro brillante por delante, ya que las empresas de todos los sectores están adoptando la IA para mejorar las operaciones de servicio, ofrecer productos y servicios innovadores o impulsar el éxito del marketing. Los datos estructurados de los sistemas operativos entregados por los almacenes de datos no son adecuados para el análisis inteligente, mientras que los lagos de datos simplemente no están diseñados para prácticas sólidas de gobierno, seguridad o cumplimiento ACID.
Lago de datos frente a casa del lago de datos
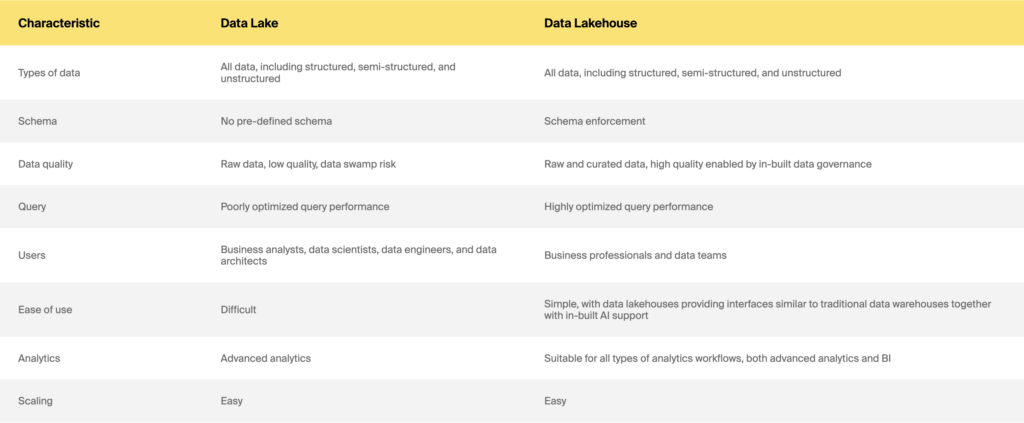
De modo que almacén de datos frente a lago de datos frente a casa de lago de datos: cuál elegir
Ya sea que desee crear una solución de almacenamiento de datos desde cero o modernizar su sistema heredado para admitir ML o mejorar el rendimiento, la respuesta correcta no será fácil. Todavía hay mucho lío sobre las diferencias clave, los beneficios y los costos, con las ofertas y los modelos de precios de los proveedores en rápida evolución. Además, siempre es un proyecto difícil, incluso si cuenta con la aceptación de las partes interesadas. Sin embargo, hay algunas consideraciones clave al elegir el almacén de datos frente al lago de datos frente al lago de datos.
La pregunta principal que debe responder es: ¿POR QUÉ? Un buen punto a recordar aquí es que las diferencias clave entre el almacén de datos, los lagos y las casas de los lagos no radican en la tecnología. Se trata de satisfacer diferentes necesidades comerciales. Entonces, ¿por qué necesita una solución de almacenamiento de datos en primer lugar? ¿Es para informes regulares, inteligencia comercial, análisis en tiempo real, ciencia de datos u otro análisis sofisticado? ¿Es la consistencia de los datos o la puntualidad más importante para las necesidades de su negocio? Dedique algún tiempo a desarrollar casos de uso. Sus necesidades de análisis deben estar bien definidas. También debe comprender profundamente a sus usuarios y conjuntos de habilidades. Algunas reglas generales son:
- Un almacén de datos es una buena apuesta si tiene preguntas exactas y sabe qué resultados de análisis desea obtener con regularidad.
- Si se encuentra en una industria altamente regulada como la atención médica o los seguros, es posible que deba cumplir con las regulaciones de informes extensas sobre todo. Por lo tanto, un almacén de datos será una mejor opción.
- Si sus KPI y requisitos de informes se pueden abordar con un análisis histórico simple, un lago de datos o una solución híbrida será una exageración. Vaya con un almacén de datos en su lugar.
- Si su equipo de datos busca un análisis experimental y exploratorio, elija un lago de datos o una solución híbrida. Sin embargo, necesitará sólidas habilidades de análisis de datos para trabajar con datos no estructurados.
- Si usted es una organización madura de datos que quiere aprovechar la tecnología de aprendizaje automático, una solución híbrida o un lago de datos será una opción natural.
Considere también su presupuesto y limitaciones de tiempo. Seguramente, los lagos de datos son más rápidos de construir que los almacenes de datos y probablemente más baratos. Es posible que desee implementar su iniciativa de forma incremental y agregar capacidades a medida que aumenta la escala. Si desea modernizar su sistema de almacenamiento de datos heredado, nuevamente, debe preguntarse POR QUÉ necesita esto. ¿Es demasiado lento? ¿O no le permite ejecutar consultas en conjuntos de datos más grandes? ¿Faltan algunos datos? ¿Quieres sacar un tipo diferente de análisis? Su organización ha gastado mucho dinero en el sistema heredado, por lo que definitivamente necesita un caso de negocios sólido para deshacerse de él. Átelo también a un ROI. Las arquitecturas de almacenamiento de datos aún están madurando. Es imposible decir con certeza cómo evolucionarán. Sin embargo, independientemente del camino que tome, es útil reconocer las trampas comunes y aprovechar al máximo la tecnología que ya está aquí.
Esperamos que este artículo haya aclarado algunas confusiones sobre los almacenes de datos, los lagos de datos y las casas de lagos de datos. Si todavía tiene preguntas o necesita las mejores habilidades tecnológicas o consejos para construir su solución de almacenamiento de datos, envíe un mensaje a ITRex. Ellos te ayudarán.
Publicado originalmente en https://itrexgroup.com el 23 de febrero de 2022.