
Depășirea confuziei: Data Warehouse vs. Data Lake vs. Data Lakehouse
Publicat: 2022-03-11Luptându-se să valorifice extinderea datelor, CIO din toate industriile se confruntă cu provocări grele. Unul dintre ele este locul unde să stocheze toate datele întreprinderii lor pentru a oferi analize solide ale datelor.
În mod tradițional, au existat două soluții de stocare a datelor: depozite de date și lacuri de date.
Depozitele de date stochează în principal date transformate, structurate din sisteme operaționale și tranzacționale și sunt utilizate pentru interogări complexe rapide în aceste date istorice.
Lacurile de date acționează ca un dump, stochând tot felul de date, inclusiv date semi-structurate și nestructurate. Acestea permit analize avansate, cum ar fi analiza în flux, pentru procesarea datelor în direct sau învățarea automată.
Din punct de vedere istoric, depozitele de date erau costisitoare pentru a fi lansate, deoarece trebuia să plătiți atât spațiul de stocare, cât și resursele de calcul, în afară de abilitățile de întreținere a acestora. Pe măsură ce costul stocării a scăzut, depozitele de date au devenit mai ieftine. Unii cred că lacurile de date (în mod tradițional o alternativă mai eficientă din punct de vedere al costurilor) sunt acum moarte. Unii susțin că lacurile de date sunt încă la modă. Între timp, alții vorbesc despre o nouă soluție hibridă de stocare a datelor - data lakehouses.
Care este treaba cu fiecare dintre ei? Să aruncăm o privire atentă.
Acest blog explorează diferențele cheie dintre depozitele de date, lacurile de date și lacurile de date, stivele tehnologice populare și cazurile de utilizare. De asemenea, oferă sfaturi pentru alegerea soluției potrivite pentru compania dvs., deși aceasta este dificilă.
Ce este un depozit de date?
Depozitele de date sunt concepute pentru a stoca date structurate, organizate, organizând seturi de date în tabele și coloane. Aceste date sunt ușor disponibile pentru utilizatori pentru informații tradiționale de business, tablouri de bord și raportare.
Arhitectura depozitului de date
O arhitectură cu trei niveluri este abordarea cea mai frecvent utilizată pentru proiectarea depozitelor de date. Acesta cuprinde:
- Nivelul inferior: o zonă de pregătire și serverul de baze de date al depozitului de date care este utilizat pentru a încărca date din diverse surse. Un proces de extracție, transformare și încărcare (ETL) este o abordare tradițională pentru împingerea datelor în depozitul de date
- Nivelul mediu: un server pentru procesarea analitică online (OLAP) care reorganizează datele într-un format multidimensional pentru calcule rapide
- Nivelul superior: API-uri și instrumente de front-end pentru lucrul cu date
Figura 1: Arhitectura de referință a depozitului de date
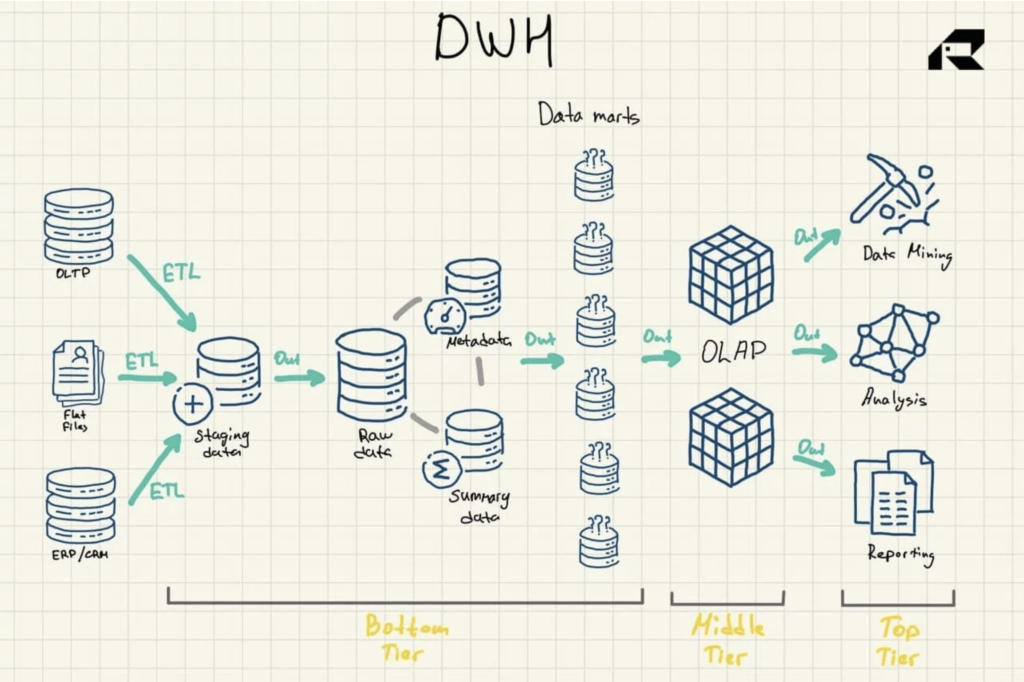
Există alte trei componente vitale ale unui depozit de date care ar trebui menționate: data mart-ul, stocarea datelor operaționale și metadatele. Martele de date aparțin nivelului inferior. Acestea stochează subseturi de date din depozitul de date, deservind linii de afaceri individuale.
Depozitele de date operaționale acționează ca un depozit, oferind un instantaneu al celor mai recente date ale organizației pentru raportarea operațională bazată pe interogări simple. Ele pot fi utilizate ca un strat intermediar între sursele de date și depozitul de date.
Există, de asemenea, metadate - date care descriu datele din depozitul de date - care sunt stocate în depozite speciale, de asemenea, în stratul inferior.
Evoluția și tehnologiile depozitului de date
Depozitele de date există de câteva decenii.
În mod tradițional, depozitele de date erau găzduite la sediu, ceea ce înseamnă că companiile trebuiau să achiziționeze tot hardware-ul și să implementeze software-ul la nivel local, fie sisteme plătite, fie sisteme open-source. De asemenea, aveau nevoie de o întreagă echipă IT pentru a întreține depozitul de date. Pe partea bună, depozitele tradiționale de date aduceau (și o fac și astăzi) un timp rapid până la înțelegere, fără probleme de latență, control total al datelor împreună cu confidențialitate sută la sută și risc de securitate minimizat.
Cu ubicuitatea cloud, multe organizații aleg acum să migreze la soluții de depozit de date în cloud, unde toate datele sunt stocate într-un cloud. Este analizat și într-un nor, folosind un anumit tip de motor de interogare integrat.
Există o varietate de soluții de depozit de date în cloud consacrate pe piață. Fiecare furnizor oferă setul său unic de capabilități de depozit și diferite modele de prețuri. De exemplu, Amazon Redshift este organizat ca un depozit de date tradițional. Fulgul de zăpadă este la fel. Microsoft Azure este un depozit de date SQL, în timp ce Google BigQuery se bazează pe o arhitectură fără server, care oferă în esență software-as-a-service (SaaS), mai degrabă decât infrastructură sau platform-as-a-service, cum ar fi, de exemplu, Amazon Redshift.
Printre soluțiile de depozit de date bine-cunoscute se numără IBM Db2, Oracle Autonomous Database, IBM Netezza, Teradata Vantage, SAP HANA și Exasol. Sunt disponibile și pe cloud.
Depozitele de date bazate pe cloud sunt, evident, mai ieftine, deoarece nu este nevoie să cumpărați sau să lansați servere fizice. Utilizatorii plătesc doar pentru spațiul de stocare și puterea de calcul, după cum este necesar. Soluțiile cloud sunt, de asemenea, mult mai ușor de scalat sau integrat cu alte servicii.
Servind nevoi de afaceri foarte specifice, cu date de calitate superioară și informații rapide, depozitele de date sunt aici pentru a rămâne mult timp.
Cazuri de utilizare a depozitului de date
Depozitele de date oferă analize de mare viteză și de înaltă performanță pe petabytes și petabytes de date istorice.
Ele sunt concepute în mod fundamental pentru interogări de tip BI. Un depozit de date poate oferi un răspuns despre, de exemplu, vânzările într-o anumită perioadă de timp, grupate după regiune sau divizie și mișcările anuale ale vânzărilor. Cazurile de utilizare cheie pentru depozitele de date sunt:
- Raportare tranzacțională pentru a oferi o imagine a performanței afacerii
- Analiză/raportare ad-hoc pentru a oferi răspunsuri la provocările de afaceri de sine stătătoare și „unice”.
- Exploatarea datelor pentru a extrage cunoștințe utile și modele ascunse din date pentru a rezolva probleme complexe din lumea reală
- Prezentare dinamică prin vizualizarea datelor
- Detaliați pentru a parcurge dimensiunile ierarhice ale datelor pentru detalii
A avea date de afaceri structurate într-o locație ușor accesibilă în afara bazelor de date operaționale este destul de important pentru orice companie matură de date.
Cu toate acestea, depozitele tradiționale de date nu acceptă tehnologia big data.
Ele sunt, de asemenea, actualizate în lot, cu înregistrările din toate sursele procesate periodic dintr-o singură mișcare, ceea ce înseamnă că datele pot deveni obținute în momentul în care sunt acumulate pentru analiză. Lacul de date pare să rezolve aceste constrângeri. Cu un compromis. Să explorăm.
Ce este un lac de date?
Lacurile de date colectează în mare parte date brute nerafinate în forma sa originală. O altă diferență cheie între lacul de date și depozitul de date este că lacurile de date stochează aceste date fără a le aranja în relații logice care se numesc scheme. Cu toate acestea, acesta este modul în care permit analize mai sofisticate.
Lacurile de date extrag (i) date tranzacționale din aplicații de afaceri, cum ar fi ERP, CRM sau SCM, (ii) documente în formatele .csv și .txt, (iii) date semi-structurate, cum ar fi formatele XML, JSON și AVRO, (iv) jurnalele dispozitivului și senzorii IoT și (v) imaginile, fișierele audio, binare, PDF.
Arhitectura lacului de date
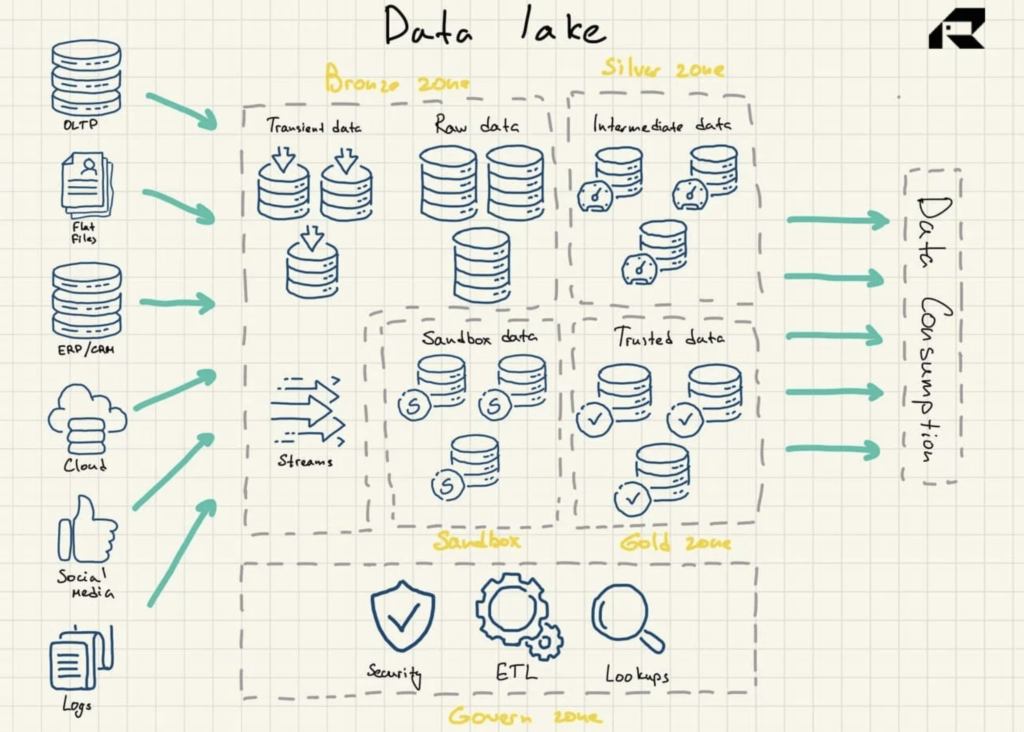
Lacurile de date folosesc o arhitectură plată pentru stocarea datelor. Componentele sale cheie sunt:
- Zona de bronz pentru toate datele ingerate în lac. Datele sunt stocate fie ca atare pentru modele de loturi, fie ca seturi de date agregate pentru încărcături de lucru în flux
- Zona de argint în care datele sunt filtrate și îmbogățite pentru explorare în funcție de nevoile afacerii
- Zona de aur în care sunt stocate date bine structurate și bine structurate pentru aplicarea instrumentelor BI și a algoritmilor ML. Această zonă are adesea un depozit de date operațional care alimentează depozitele tradiționale de date și magazinele de date
- Sandbox unde datele pot fi experimentate pentru validarea ipotezelor și teste. Este implementat fie ca bază de date complet separată pentru Hadoop sau alte tehnologii NoSQL, fie ca parte a zonei de aur.
Figura 2: Arhitectura de referință Data Lake
Lacurile de date nu conțin în mod inerent capabilități de analiză. Fără ele, ele stochează doar date brute care nu sunt utile în sine. Deci, organizațiile construiesc depozite de date sau folosesc alte instrumente pe deasupra lacurilor de date pentru a folosi datele.
Pentru a vă asigura că un lac de date nu se transformă într-o mlaștină de date, este important să aveți o strategie eficientă de gestionare a datelor care să includă guvernanța încorporată a datelor și gestionarea metadatelor în proiectarea lacului de date. Într-o lume ideală, datele aflate într-un lac de date ar trebui catalogate, indexate, validate și ușor accesibile utilizatorilor de date. Totuși, acesta este rareori un caz și multe proiecte de lacuri de date eșuează. Acest lucru poate fi evitat: indiferent de maturitatea unei echipe de date, este esențial să instalați cel puțin controale esențiale pentru a impune validarea și calitatea datelor.
Evoluția și tehnologiile lacului de date
Creșterea datelor mari la începutul anilor 2000 a adus atât mari oportunități, cât și mari provocări pentru organizații. Afacerile aveau nevoie de noi tehnologii pentru a analiza aceste seturi de date masive, dezordonate și ridicol de rapidă, pentru a capta impactul asupra afacerii din big data.
În 2008, Apache Hadoop a venit cu o tehnologie open-source inovatoare pentru colectarea și procesarea datelor nestructurate la scară masivă, deschizând calea pentru analiza big data și lacurile de date. La scurt timp după, a apărut Apache Spark. A fost mai ușor de folosit. În plus, a oferit capabilități pentru construirea și instruirea modelelor ML, interogarea datelor structurate folosind SQL și procesarea datelor în timp real.
Astăzi, lacurile de date sunt în mod predominant depozite găzduite în cloud. Toți furnizorii de top, cum ar fi AWS, Azure și Google, oferă lacuri de date bazate pe cloud cu servicii de stocare a obiectelor rentabile. Platformele lor vin cu diverse servicii de gestionare a datelor pentru a automatiza implementarea. Într-un scenariu, de exemplu, un lac de date ar putea consta dintr-un sistem de stocare a datelor precum Hadoop Distributed File System (HDFS) sau Amazon S3 integrat cu o soluție de depozit de date în cloud precum Amazon Redshift. Aceste componente ar fi decuplate de serviciile din ecosistem, care ar putea include Amazon EMR pentru procesarea datelor, Amazon Glue care oferă catalogul de date și funcționalitatea de transformare, serviciul de interogare Amazon Athena sau Amazon Elasticsearch Service care este utilizat pentru a construi un depozit de metadate și un index. date. Lacurile de date locale sunt încă comune din cauza preocupărilor obișnuite despre cloud, cum ar fi securitatea, confidențialitatea sau latența.

Există, de asemenea, furnizori de stocare on-premise care oferă unele produse pentru lacurile de date, dar ofertele lor de lacuri de date, totuși, nu sunt bine definite. Spre deosebire de depozitele de date, lacurile de date nu au mulți ani de implementări în lumea reală în spate. Există încă multe critici care descriu conceptul de lac de date ca fiind neclar și prost definit. Criticii susțin, de asemenea, că puțini oameni din orice organizație au abilitățile (sau entuziasmul de altfel) pentru a rula sarcini de lucru exploratorii pe baza datelor brute.
Ideea că lacurile de date ar trebui folosite ca depozit central pentru datele tuturor întreprinderilor trebuie abordată cu prudență, spun ei. De asemenea, a existat o discuție provocatoare că zilele lacului de date sunt numărate. Sunt invocate următoarele motive:
- Lacurile de date nu pot scala resursele de calcul în mod eficient la cerere (ei bine, acest lucru se datorează faptului că nu sunt proiectate în primul rând)
- Lacurile de date au o mare datorie tehnologică, crearea lor fiind determinată în primul rând de hype-ul de marketing, mai degrabă decât de motive tehnice (același lucru s-a întâmplat și cu multe depozite de date)
- Odată cu creșterea soluțiilor de depozit de date în cloud, lacurile de date nu mai oferă beneficii semnificative în ceea ce privește costurile (problema costurilor nu este atât de simplă, deoarece este greu de prognozat costurile de calcul)
O astfel de critică este o parte inerentă a oricărei tehnologii mai tinere. Cu toate acestea, lacurile de date au cazuri de utilizare clare, cum ar fi analiza în flux. Și totuși, nu amenință depozitele de date. La un moment dat, lacurile de date au triumfat chiar asupra depozitelor de date, oferind capabilități de analiză mai largi, rentabilitate și flexibilitate în ceea ce privește datele stocate. Cu toate acestea, pe măsură ce tehnologiile de depozit de date s-au maturizat, mulți sunt de acord că acum nu există un câștigător evident. În general, este recomandabil să le mențineți pe amândouă sau... alegeți o arhitectură hibridă. Citește mai departe.
Cazuri de utilizare a lacului de date
Ideea principală despre lacurile de date este de a oferi afacerilor acces la toate datele disponibile din toate sursele cât mai repede posibil. Lacurile de date nu oferă doar o imagine a ceea ce s-a întâmplat ieri. Stochând cantități masive de date, lacurile de date sunt concepute pentru a permite organizațiilor să învețe mai multe atât despre prezent (folosind analize de streaming) cât și despre viitor (folosind soluții de date mari, inclusiv analize predictive și învățare automată). Cazurile de utilizare cheie pentru lacurile de date sunt:
- Alimentarea unui depozit de date al întreprinderii cu seturi de date
- Efectuarea analizei fluxului
- Implementarea proiectelor ML
- Crearea de diagrame de analiză avansată folosind instrumente BI de lungă durată, cum ar fi Tableau sau MS Power BI
- Construirea de soluții personalizate de analiză a datelor
- Rularea analizei cauzei principale care permite echipelor de date să urmărească problemele până la rădăcini
Cu abilități puternice de inginerie a datelor pentru a muta datele brute într-un mediu de analiză, lacurile de date pot fi extrem de relevante. Acestea permit echipelor să experimenteze cu date pentru a înțelege cum pot fi utile. Acest lucru ar putea implica construirea de modele pentru a săpa prin date și a încerca diferite scheme pentru a vizualiza datele în moduri noi. Lacurile de date permit, de asemenea, lupta cu datele fluxului care vin din jurnalele web și senzorii IoT și nu sunt potrivite pentru o abordare tradițională a depozitului de date.
Pe scurt, lacurile de date permit organizațiilor să descopere tipare, să anticipeze schimbări sau să găsească potențiale oportunități de afaceri în jurul unor noi produse sau procese curente. Folosite pentru diferite nevoi de afaceri, lacurile de date și depozitele de date sunt adesea implementate în tandem. Înainte de a trece la următorul concept de stocare a datelor, să recapitulăm rapid diferențele cheie dintre depozitul de date și lacul de date.
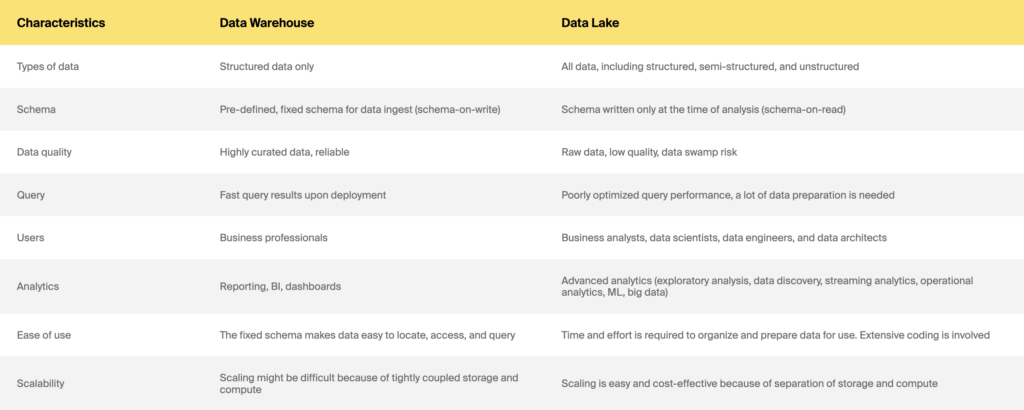
Depozitul de date vs. lac de date
Ce zici de o nouă arhitectură hibridă, data lakehouses?
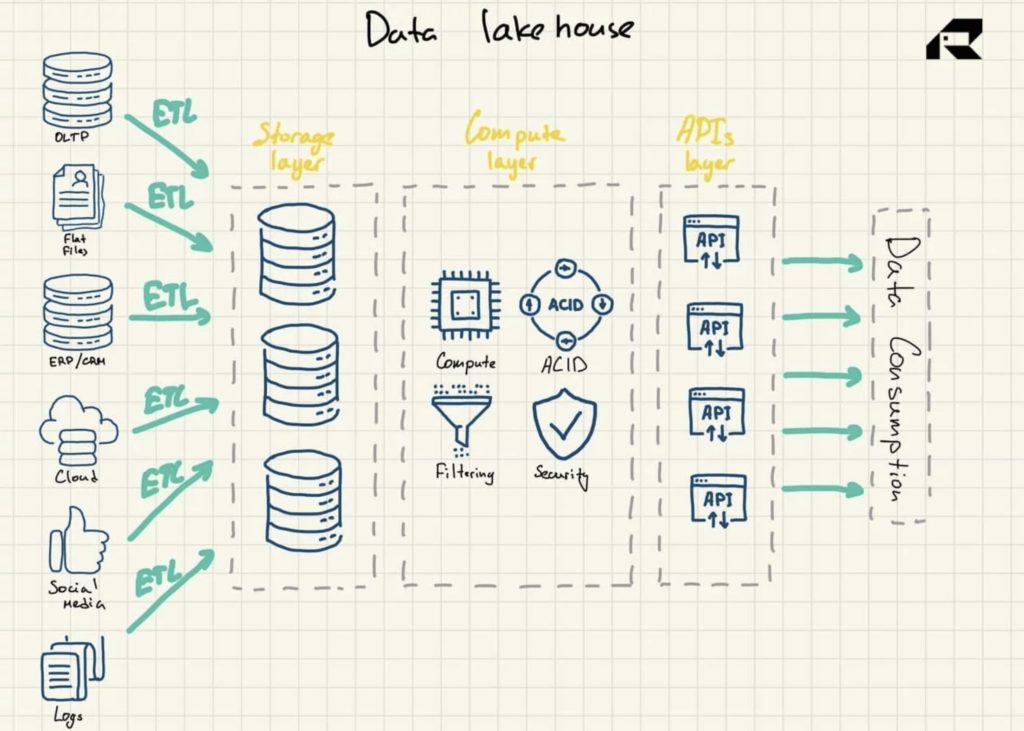
Pe lângă marketing, ideea cheie despre un data lakehouse este de a aduce putere de calcul unui data lake. Din punct de vedere arhitectural, data lakehouse constă de obicei din:
- Strat de stocare pentru stocarea datelor în formate deschise (de exemplu, Parchet). Acest strat poate fi numit un lac de date și este separat de stratul de calcul
- Stratul de calcul care oferă organizației capabilități de depozit, care sprijină gestionarea metadatelor, indexarea, aplicarea schemei și tranzacțiile ACID (atomicitate, consistență, fiabilitate și durabilitate).
- Stratul API pentru a accesa activele de date
- Strat de servire pentru a suporta diverse sarcini de lucru, de la raportare la BI, știința datelor sau învățarea automată.
Figura 3: Arhitectura de referință Data Lakehouse
Prezentat ca o soluție care se căsătorește cu cele mai bune din ambele lumi, data lakehouse se adresează ambelor:
- Constrângeri ale depozitului de date, inclusiv lipsa suportului pentru analiza avansată a datelor care se bazează atât pe date structurate, cât și pe date nestructurate și costuri semnificative de scalare cu depozitele tradiționale de date care nu separă stocarea de resursele de calcul
- Provocări ale lacului de date, inclusiv duplicarea datelor, calitatea datelor și necesitatea de a accesa mai multe sisteme pentru diverse sarcini sau de a implementa integrări complexe cu instrumente de analiză
Data Lakehouse este un nou progres în scena analizei datelor. Conceptul a fost folosit pentru prima dată în 2017 în legătură cu platforma Snowflake. În 2019, AWS a folosit termenul data lakehouse pentru a descrie serviciul său Amazon Redshift Spectrum, care permite utilizatorilor serviciului său de depozit de date Amazon Redshift să caute prin datele stocate în Amazon S3. În 2020, termenul data lakehouse a intrat în uz pe scară largă, Databricks adoptându-l pentru platforma sa Delta Lake.
Data Lakehouse ar putea avea un viitor strălucit, deoarece companiile din industrii adoptă AI pentru a îmbunătăți operațiunile de servicii, pentru a oferi produse și servicii inovatoare sau pentru a conduce succesul în marketing. Datele structurate din sistemele operaționale furnizate de depozitele de date nu sunt potrivite pentru analiza inteligentă, în timp ce lacurile de date pur și simplu nu sunt concepute pentru practici solide de guvernanță, securitate sau conformitate cu ACID.
Data Lake vs. Data Lakehouse
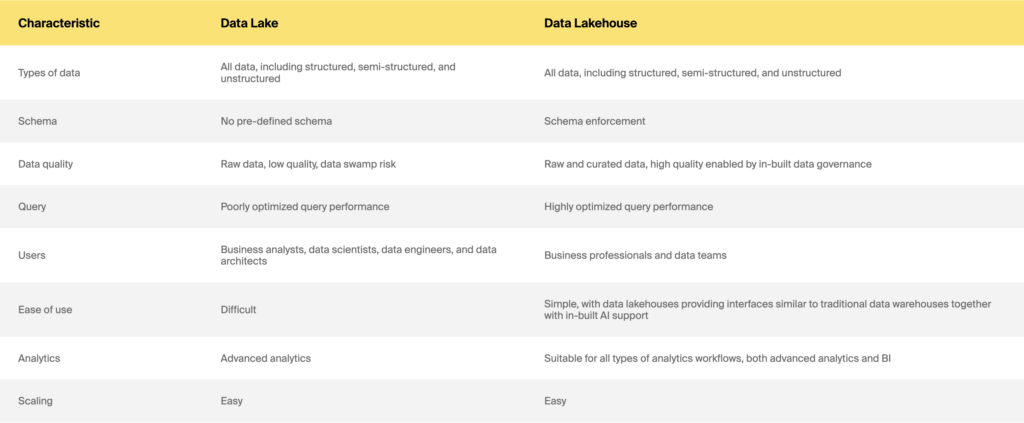
Deci data warehouse vs. data lake vs. data lakehouse: pe care să alegi
Indiferent dacă doriți să construiți o soluție de stocare a datelor de la zero sau să vă modernizați sistemul vechi pentru a sprijini ML sau pentru a îmbunătăți performanța, răspunsul corect nu va fi ușor. Există încă multă mizerie cu privire la diferențele cheie, beneficiile și costurile, cu ofertele și modelele de prețuri de la furnizori care evoluează rapid. În plus, este întotdeauna un proiect dificil, chiar dacă aveți acceptul părților interesate. Cu toate acestea, există câteva considerente cheie atunci când alegeți depozitul de date vs. data lake vs. data lakehouse.
Întrebarea principală la care ar trebui să răspunzi este: DE CE. Un punct bun de reținut aici este că diferențele esențiale dintre depozitul de date, lacuri și lacuri nu se află în tehnologie. Acestea sunt legate de satisfacerea diferitelor nevoi de afaceri. Deci, de ce aveți nevoie de o soluție de stocare a datelor în primul rând? Este pentru raportare regulată, business intelligence, analiză în timp real, știința datelor sau alte analize sofisticate? Este coerența datelor sau oportunitatea mai importantă pentru nevoile afacerii dvs.? Petreceți ceva timp dezvoltării cazurilor de utilizare. Nevoile dvs. de analiză ar trebui să fie bine definite. Ar trebui să vă înțelegeți profund utilizatorii și seturile de abilități. Câteva reguli de bază sunt:
- Un depozit de date este un pariu bun dacă aveți întrebări exacte și știți ce rezultate de analiză doriți să obțineți în mod regulat.
- Dacă vă aflați într-o industrie foarte reglementată, cum ar fi asistența medicală sau asigurările, este posibil să trebuiască să respectați reglementările extinse de raportare, mai ales. Deci, un depozit de date va fi o alegere mai bună.
- Dacă KPI-urile și cerințele de raportare pot fi abordate cu o simplă analiză istorică, un lac de date sau o soluție hibridă va fi exagerat. Mergeți cu un depozit de date.
- Dacă echipa dvs. de date urmează analize experimentale și exploratorii, alegeți un lac de date sau o soluție hibridă. Cu toate acestea, veți avea nevoie de abilități puternice de analiză a datelor pentru a lucra cu date nestructurate.
- Dacă sunteți o organizație matură a datelor care dorește să folosească tehnologia de învățare automată, o soluție hibridă sau un lac de date va fi o potrivire naturală.
Luați în considerare, de asemenea, bugetul și constrângerile de timp. Lacurile de date sunt cu siguranță mai rapide de construit decât depozitele de date și probabil mai ieftine. Poate doriți să vă implementați inițiativa treptat și să adăugați capabilități pe măsură ce creșteți. Dacă doriți să vă modernizați sistemul de stocare a datelor, atunci din nou, ar trebui să vă întrebați DE CE aveți nevoie de acest lucru. Este prea lent? Sau nu vă permite să executați interogări pe seturi de date mai mari? Lipsesc unele date? Doriți să scoateți un alt tip de analiză? Organizația dvs. a cheltuit o mulțime de bani pe sistemul moștenit, așa că aveți nevoie cu siguranță de un caz de afaceri solid pentru a renunța la el. Leagă-l și de un ROI. Arhitecturile de stocare a datelor sunt încă în curs de maturizare. Este imposibil de spus cu siguranță cum vor evolua. Cu toate acestea, indiferent de calea pe care o veți urma, este util să recunoașteți capcanele comune și să profitați la maximum de tehnologia care este deja aici.
Sperăm că acest articol a clarificat unele confuzii despre depozitele de date vs. lacurile de date vs. lacurile de date. Dacă mai aveți întrebări sau aveți nevoie de abilități sau sfaturi tehnologice de vârf pentru a vă construi soluția de stocare a datelor, trimiteți ITRex. Ei te vor ajuta.
Publicat inițial la https://itrexgroup.com pe 23 februarie 2022.