
ขจัดความสับสน: Data Warehouse กับ Data Lake กับ Data Lakehouse
เผยแพร่แล้ว: 2022-03-11CIO ในอุตสาหกรรมต่างๆ กำลังเผชิญกับความท้าทายที่ยากลำบากในการพยายามควบคุมการแผ่ขยายของข้อมูล หนึ่งในนั้นคือที่ที่จะจัดเก็บข้อมูลขององค์กรทั้งหมดเพื่อนำเสนอการวิเคราะห์ข้อมูลที่มีประสิทธิภาพ
ตามเนื้อผ้ามีโซลูชันการจัดเก็บข้อมูลสองแบบ: คลังข้อมูลและดาต้าเลค
คลังข้อมูลส่วนใหญ่จัดเก็บข้อมูลที่แปลงแล้ว มีโครงสร้างจากระบบปฏิบัติการและธุรกรรม และใช้สำหรับการค้นหาที่ซับซ้อนอย่างรวดเร็วในข้อมูลในอดีตนี้
Data Lake ทำหน้าที่เป็นดัมพ์ จัดเก็บข้อมูลทุกประเภท รวมถึงข้อมูลกึ่งโครงสร้างและที่ไม่มีโครงสร้าง พวกเขาสนับสนุนการวิเคราะห์ขั้นสูง เช่น การวิเคราะห์การสตรีมสำหรับการประมวลผลข้อมูลสดหรือการเรียนรู้ของเครื่อง
ในอดีต คลังข้อมูลมีราคาแพงในการเปิดตัว เนื่องจากคุณต้องจ่ายเงินสำหรับทั้งพื้นที่จัดเก็บและทรัพยากรในการคำนวณ นอกเหนือจากทักษะในการบำรุงรักษา เนื่องจากต้นทุนการจัดเก็บลดลง คลังข้อมูลจึงมีราคาถูกลง บางคนเชื่อว่า data lake (แต่เดิมเป็นทางเลือกที่คุ้มค่ากว่า) นั้นตายไปแล้ว บางคนโต้แย้งว่า data lake ยังคงเป็นกระแสนิยม ในขณะเดียวกัน คนอื่นๆ กำลังพูดถึงโซลูชันการจัดเก็บข้อมูลแบบไฮบริดแบบใหม่ — data lakehouses
แต่ละคนเกี่ยวอะไรด้วย? ลองมาดูอย่างใกล้ชิด
บล็อกนี้สำรวจความแตกต่างที่สำคัญระหว่างคลังข้อมูล Data Lake และ Data Lakehouse กองเทคโนโลยียอดนิยม และกรณีการใช้งาน นอกจากนี้ยังมีเคล็ดลับในการเลือกโซลูชันที่เหมาะสมสำหรับบริษัทของคุณ แม้ว่าจะเป็นเรื่องยากก็ตาม
คลังข้อมูลคืออะไร?
คลังข้อมูลได้รับการออกแบบมาเพื่อจัดเก็บข้อมูลที่มีโครงสร้าง จัดระเบียบ จัดระเบียบชุดข้อมูลในตารางและคอลัมน์ ข้อมูลนี้สามารถเข้าถึงได้ง่ายสำหรับผู้ใช้สำหรับ Business Intelligence แดชบอร์ด และการรายงานแบบดั้งเดิม
สถาปัตยกรรมคลังข้อมูล
สถาปัตยกรรมสามระดับเป็นวิธีที่ใช้กันมากที่สุดในการออกแบบคลังข้อมูล ประกอบด้วย:
- ระดับล่างสุด: พื้นที่จัดเตรียมและเซิร์ฟเวอร์ฐานข้อมูลของคลังข้อมูลที่ใช้โหลดข้อมูลจากแหล่งต่างๆ กระบวนการแยก แปลง และโหลด (ETL) เป็นแนวทางดั้งเดิมในการส่งข้อมูลไปยังคลังข้อมูล
- ระดับกลาง: เซิร์ฟเวอร์สำหรับการประมวลผลเชิงวิเคราะห์ออนไลน์ (OLAP) ที่จัดระเบียบข้อมูลใหม่ให้อยู่ในรูปแบบหลายมิติเพื่อการคำนวณที่รวดเร็ว
- ระดับบนสุด: API และเครื่องมือส่วนหน้าสำหรับการทำงานกับ data
รูปที่ 1: สถาปัตยกรรมอ้างอิงคลังข้อมูล
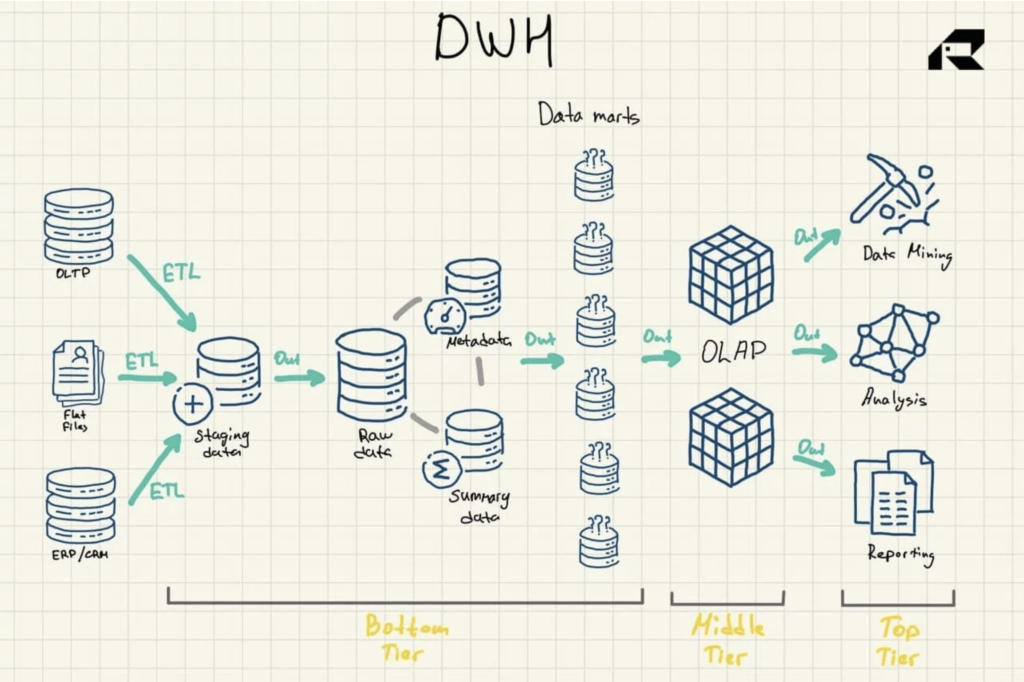
มีองค์ประกอบที่สำคัญอื่นๆ อีกสามองค์ประกอบของคลังข้อมูลที่ควรกล่าวถึง: ดาต้ามาร์ท การจัดเก็บข้อมูลในการดำเนินงาน และข้อมูลเมตา ดาต้ามาร์ทอยู่ในชั้นล่าง พวกเขาจัดเก็บชุดย่อยของข้อมูลคลังข้อมูล ซึ่งให้บริการแต่ละสายธุรกิจ
การจัดเก็บข้อมูลการดำเนินงานทำหน้าที่เป็นพื้นที่เก็บข้อมูลที่ให้ภาพรวมของข้อมูลล่าสุดขององค์กรสำหรับการรายงานการปฏิบัติงานตามการสืบค้นธรรมดา อาจใช้เป็นชั้นชั่วคราวระหว่างแหล่งข้อมูลและคลังข้อมูล
นอกจากนี้ยังมีข้อมูลเมตา — ข้อมูลที่อธิบายข้อมูลคลังข้อมูล — ซึ่งจัดเก็บไว้ในที่เก็บข้อมูลวัตถุประสงค์พิเศษ ที่ชั้นล่างเช่นกัน
วิวัฒนาการและเทคโนโลยีคลังข้อมูล
คลังข้อมูลมีมานานหลายทศวรรษแล้ว
ตามเนื้อผ้า คลังข้อมูลถูกโฮสต์ไว้ในสถานที่ หมายความว่าบริษัทต่างๆ ต้องซื้อฮาร์ดแวร์ทั้งหมดและปรับใช้ซอฟต์แวร์ในพื้นที่ ไม่ว่าจะเป็นระบบแบบชำระเงินหรือโอเพ่นซอร์ส พวกเขายังต้องการทีมไอทีทั้งหมดเพื่อดูแลคลังข้อมูล ในด้านที่สดใส คลังข้อมูลแบบดั้งเดิมกำลังนำเข้า (และยังคงทำเช่นนั้นในปัจจุบัน) เวลาในการทำความเข้าใจอย่างรวดเร็วโดยไม่มีปัญหาเวลาแฝง การควบคุมข้อมูลทั้งหมดพร้อมกับความเป็นส่วนตัวร้อยเปอร์เซ็นต์ และลดความเสี่ยงด้านความปลอดภัยให้เหลือน้อยที่สุด
ด้วยความแพร่หลายของระบบคลาวด์ ทำให้หลายองค์กรเลือกที่จะโยกย้ายไปยังโซลูชันคลังข้อมูลบนคลาวด์ที่ข้อมูลทั้งหมดถูกจัดเก็บไว้ในคลาวด์ มีการวิเคราะห์ในระบบคลาวด์ด้วยโดยใช้เอ็นจิ้นการสืบค้นแบบรวมบางประเภท
มีโซลูชันคลังข้อมูลบนคลาวด์ที่หลากหลายในตลาด ผู้ให้บริการแต่ละรายนำเสนอชุดความสามารถด้านคลังสินค้าและรูปแบบราคาที่แตกต่างกัน ตัวอย่างเช่น Amazon Redshift จัดเป็นคลังข้อมูลแบบดั้งเดิม เกล็ดหิมะก็เช่นเดียวกัน Microsoft Azure เป็นคลังข้อมูล SQL ในขณะที่ Google BigQuery อิงตามสถาปัตยกรรมแบบไร้เซิร์ฟเวอร์ที่นำเสนอในซอฟต์แวร์สำคัญในฐานะบริการ (SaaS) มากกว่าโครงสร้างพื้นฐานหรือแพลตฟอร์มในฐานะบริการ เช่น Amazon Redshift
โซลูชันคลังข้อมูลในสถานที่ที่รู้จักกันดี ได้แก่ IBM Db2, Oracle Autonomous Database, IBM Netezza, Teradata Vantage, SAP HANA และ Exasol พวกเขายังมีอยู่บนคลาวด์
คลังข้อมูลบนคลาวด์มีราคาถูกกว่าอย่างเห็นได้ชัด เนื่องจากไม่จำเป็นต้องซื้อหรือเปิดตัวเซิร์ฟเวอร์จริง ผู้ใช้จ่ายเฉพาะพื้นที่จัดเก็บและพลังประมวลผลเท่าที่จำเป็น โซลูชันระบบคลาวด์ยังปรับขนาดหรือผสานรวมกับบริการอื่นๆ ได้ง่ายกว่ามาก
ตอบสนองความต้องการทางธุรกิจที่มีความเฉพาะเจาะจงสูงด้วยคุณภาพข้อมูลระดับสูงและข้อมูลเชิงลึกที่รวดเร็ว คลังข้อมูลพร้อมที่จะอยู่ได้นาน
กรณีการใช้งานคลังข้อมูล
คลังข้อมูลนำเสนอการวิเคราะห์ที่รวดเร็วและมีประสิทธิภาพสูงในข้อมูลประวัติระดับเพตะไบต์และเพตะไบต์
ได้รับการออกแบบมาพื้นฐานสำหรับการสืบค้นประเภท BI คลังข้อมูลอาจให้คำตอบเกี่ยวกับการขายในช่วงเวลาหนึ่งๆ ที่จัดกลุ่มตามภูมิภาคหรือแผนก และความเคลื่อนไหวของยอดขายปีต่อปี กรณีการใช้งานที่สำคัญสำหรับคลังข้อมูลคือ:
- การรายงานธุรกรรมเพื่อนำเสนอภาพการดำเนินธุรกิจ
- การวิเคราะห์/การรายงานเฉพาะกิจเพื่อให้คำตอบสำหรับความท้าทายทางธุรกิจแบบ "ครั้งเดียว" แบบสแตนด์อโลน
- การขุดข้อมูลเพื่อดึงความรู้ที่เป็นประโยชน์และรูปแบบที่ซ่อนอยู่จากข้อมูลเพื่อแก้ปัญหาที่ซับซ้อนในโลกแห่งความเป็นจริง
- การนำเสนอแบบไดนามิกผ่านการสร้างภาพข้อมูล
- การเจาะลึกเพื่อดูรายละเอียดในมิติลำดับชั้นของข้อมูล
การมีโครงสร้างข้อมูลทางธุรกิจในตำแหน่งที่เข้าถึงได้ง่ายแห่งเดียวนอกฐานข้อมูลการปฏิบัติงานนั้นค่อนข้างสำคัญสำหรับบริษัทที่มีข้อมูลครบถ้วน
อย่างไรก็ตาม คลังข้อมูลแบบดั้งเดิมไม่รองรับเทคโนโลยีบิ๊กดาต้า
นอกจากนี้ยังได้รับการอัปเดตเป็นชุด โดยบันทึกจากแหล่งที่มาทั้งหมดจะถูกประมวลผลเป็นระยะในครั้งเดียว ซึ่งหมายความว่าข้อมูลอาจไม่มีข้อมูลเมื่อถึงเวลาที่รวบรวมเพื่อการวิเคราะห์ Data Lake ดูเหมือนจะแก้ไขข้อจำกัดเหล่านี้ได้ ด้วยข้อแลกเปลี่ยน มาสำรวจกัน
Data Lake คืออะไร?
Data Lake ส่วนใหญ่จะรวบรวมข้อมูลดิบที่ยังไม่ได้ปรับแต่งในรูปแบบดั้งเดิม ข้อแตกต่างที่สำคัญอีกประการระหว่าง data lake และ data data คือ data lake เก็บข้อมูลนี้โดยไม่ต้องจัดเรียงลงในความสัมพันธ์เชิงตรรกะที่เรียกว่าสคีมา อย่างไรก็ตาม นี่คือวิธีเปิดใช้งานการวิเคราะห์ที่ซับซ้อนยิ่งขึ้น
Data Lake ดึง (i) ข้อมูลธุรกรรมจากแอปพลิเคชันทางธุรกิจ เช่น ERP, CRM หรือ SCM (ii) เอกสารในรูปแบบ .csv และ .txt (iii) ข้อมูลกึ่งโครงสร้าง เช่น รูปแบบ XML, JSON และ AVRO (iv) บันทึกอุปกรณ์และเซ็นเซอร์ IoT และ (v) รูปภาพ เสียง ไบนารี ไฟล์ PDF
สถาปัตยกรรมดาต้าเลค
Data Lake ใช้สถาปัตยกรรมแบบเรียบสำหรับการจัดเก็บข้อมูล องค์ประกอบหลักของมันคือ:
- เขตบรอนซ์ สำหรับข้อมูลทั้งหมดที่นำเข้าไปยังทะเลสาบ ข้อมูลจะถูกจัดเก็บตามที่เป็นสำหรับรูปแบบแบทช์หรือเป็นชุดข้อมูลรวมสำหรับการสตรีมปริมาณงาน
- โซนเงิน ที่ข้อมูลถูกกรองและเสริมเพื่อการสำรวจตามความต้องการทางธุรกิจ
- โซนทอง ที่จัดเก็บข้อมูลที่มีการจัดโครงสร้างอย่างดีสำหรับการใช้เครื่องมือ BI และอัลกอริธึม ML โซนนี้มักจะมีการจัดเก็บข้อมูลการดำเนินงานที่ดึงข้อมูลคลังข้อมูลแบบดั้งเดิมและดาต้ามาร์ท
- แซ นด์บ็อกซ์ที่สามารถทดลองข้อมูลเพื่อตรวจสอบสมมติฐานและการทดสอบ มันถูกนำไปใช้เป็นฐานข้อมูลแยกต่างหากอย่างสมบูรณ์สำหรับ Hadoop หรือเทคโนโลยี NoSQL อื่น ๆ หรือเป็นส่วนหนึ่งของโซนทอง
รูปที่ 2: สถาปัตยกรรมอ้างอิง Data Lake
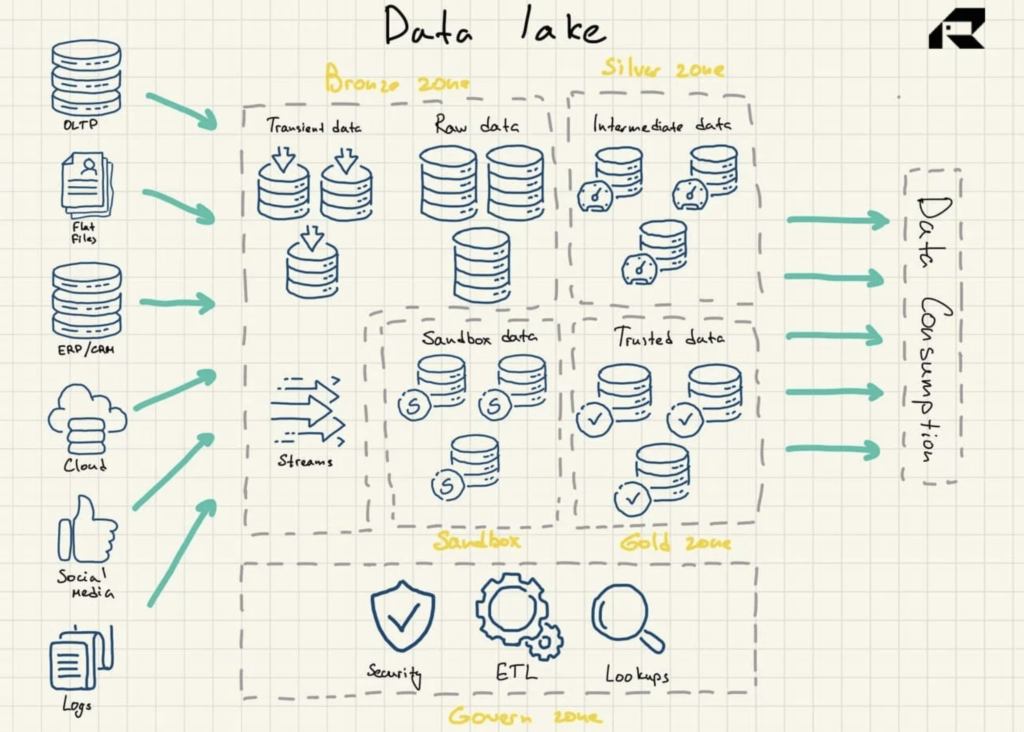
Data Lake ไม่มีความสามารถในการวิเคราะห์โดยเนื้อแท้ หากไม่มีพวกเขาก็จะเก็บข้อมูลดิบที่ไม่มีประโยชน์ในตัวเอง ดังนั้น องค์กรจึงสร้างคลังข้อมูลหรือใช้ประโยชน์จากเครื่องมืออื่นนอกเหนือจาก Data Lake เพื่อนำข้อมูลไปใช้
เพื่อให้แน่ใจว่า Data Lake จะไม่กลายเป็น Data Swamp สิ่งสำคัญคือต้องมีกลยุทธ์การจัดการข้อมูลที่มีประสิทธิภาพเพื่อรวมการจัดการข้อมูลในตัวและการจัดการ Metadata ในการออกแบบ Data Lake ในโลกอุดมคติ ข้อมูลที่อยู่ใน Data Lake ควรถูกจัดหมวดหมู่ จัดทำดัชนี ตรวจสอบ และเข้าถึงผู้ใช้ข้อมูลได้อย่างง่ายดาย กรณีนี้ไม่ค่อยเกิดขึ้น และโครงการ Data Lake จำนวนมากล้มเหลว สิ่งนี้สามารถหลีกเลี่ยงได้ ไม่ว่าทีมข้อมูลจะมีวุฒิภาวะใดก็ตาม การติดตั้งการควบคุมที่จำเป็นอย่างน้อยที่สุดเพื่อบังคับใช้การตรวจสอบความถูกต้องของข้อมูลและคุณภาพเป็นสิ่งสำคัญ
วิวัฒนาการและเทคโนโลยีของ Data Lake
การเพิ่มขึ้นของข้อมูลขนาดใหญ่ในช่วงต้นทศวรรษ 2000 ได้นำมาซึ่งโอกาสอันยิ่งใหญ่และความท้าทายที่ยิ่งใหญ่สำหรับองค์กร ธุรกิจต้องการเทคโนโลยีใหม่ ๆ เพื่อวิเคราะห์ชุดข้อมูลขนาดใหญ่ ยุ่งเหยิง และเติบโตอย่างรวดเร็วอย่างน่าขันเพื่อจับผลกระทบทางธุรกิจจากข้อมูลขนาดใหญ่
ในปี 2008 Apache Hadoop ได้คิดค้นเทคโนโลยีโอเพ่นซอร์สที่เป็นนวัตกรรมใหม่สำหรับการรวบรวมและประมวลผลข้อมูลที่ไม่มีโครงสร้างในขนาดมหึมา ปูทางสำหรับการวิเคราะห์ข้อมูลขนาดใหญ่และ Data Lake หลังจากนั้นไม่นาน Apache Spark ก็ปรากฏตัวขึ้น ใช้งานง่ายขึ้น นอกจากนี้ ยังให้ความสามารถในการสร้างและฝึกอบรมโมเดล ML การสืบค้นข้อมูลที่มีโครงสร้างโดยใช้ SQL และการประมวลผลข้อมูลแบบเรียลไทม์
ปัจจุบัน Data Lake เป็นที่เก็บที่โฮสต์บนคลาวด์เป็นหลัก ผู้ให้บริการระบบคลาวด์ชั้นนำทั้งหมด เช่น AWS, Azure และ Google นำเสนอ Data Lake บนคลาวด์พร้อมบริการพื้นที่จัดเก็บอ็อบเจ็กต์ที่คุ้มค่า แพลตฟอร์มของพวกเขามาพร้อมกับบริการจัดการข้อมูลที่หลากหลายเพื่อทำให้ใช้งานได้โดยอัตโนมัติ ในสถานการณ์หนึ่ง ตัวอย่างเช่น Data Lake อาจประกอบด้วยระบบจัดเก็บข้อมูล เช่น Hadoop Distributed File System (HDFS) หรือ Amazon S3 ที่ผสานรวมกับโซลูชันคลังข้อมูลบนระบบคลาวด์ เช่น Amazon Redshift ส่วนประกอบเหล่านี้จะแยกออกจากบริการในระบบนิเวศ ซึ่งอาจรวมถึง Amazon EMR สำหรับการประมวลผลข้อมูล, Amazon Glue ที่มีฟังก์ชันแค็ตตาล็อกข้อมูลและการแปลง, บริการสืบค้น Amazon Athena หรือ Amazon Elasticsearch Service ที่ใช้สร้างคลังข้อมูลเมตาและดัชนี ข้อมูล. Data Lake ในพื้นที่ยังคงพบเห็นได้ทั่วไปเนื่องจากความกังวลเกี่ยวกับระบบคลาวด์ตามปกติ เช่น ความปลอดภัย ความเป็นส่วนตัว หรือเวลาแฝง

นอกจากนี้ยังมีผู้จำหน่ายพื้นที่จัดเก็บข้อมูลในองค์กรที่นำเสนอผลิตภัณฑ์บางอย่างสำหรับ Data Lake แต่ข้อเสนอ Data Lake นั้นไม่ได้กำหนดไว้อย่างชัดเจน ต่างจากคลังข้อมูล Data Lake ไม่มีการปรับใช้ในโลกแห่งความเป็นจริงเป็นเวลาหลายปี ยังมีการวิพากษ์วิจารณ์มากมายที่อธิบายว่าแนวคิดของ data lake นั้นไม่ชัดเจนและไม่ชัดเจน นักวิจารณ์ยังโต้แย้งว่ามีคนเพียงไม่กี่คนในองค์กรใด ๆ ที่มีทักษะ (หรือความกระตือรือร้นในเรื่องนั้น) ในการดำเนินการสำรวจปริมาณงานกับข้อมูลดิบ
แนวคิดที่ว่า data lake ควรใช้เป็นที่เก็บข้อมูลส่วนกลางสำหรับข้อมูลขององค์กรทั้งหมด จะต้องได้รับการเข้าหาด้วยความระมัดระวัง นอกจากนี้ยังมีการพูดคุยที่ยั่วยุให้นับวันใน Data Lake เหตุผลต่อไปนี้ถูกอ้างถึง:
- Data Lake ไม่สามารถปรับขนาดทรัพยากรการประมวลผลได้อย่างมีประสิทธิภาพตามความต้องการ (ก็เพราะว่าไม่ได้ออกแบบมาตั้งแต่แรก)
- Data Lake มีหนี้สินด้านเทคโนโลยีจำนวนมาก โดยการสร้างของพวกเขาขับเคลื่อนโดยการโฆษณาทางการตลาดเป็นหลัก มากกว่าเหตุผลทางเทคนิค (เช่นเดียวกันกับคลังข้อมูลหลายแห่งเช่นกัน)
- ด้วยการเพิ่มขึ้นของโซลูชันคลังข้อมูลบนระบบคลาวด์ Data Lake ไม่ได้ให้ประโยชน์ด้านต้นทุนอย่างมีนัยสำคัญอีกต่อไป (ปัญหาด้านต้นทุนไม่ได้เกิดขึ้นอย่างตรงไปตรงมามากนัก เนื่องจากเป็นการยากที่จะคาดการณ์ต้นทุนการประมวลผล)
การวิพากษ์วิจารณ์ดังกล่าวเป็นส่วนหนึ่งของเทคโนโลยีรุ่นเยาว์ อย่างไรก็ตาม Data Lake มีกรณีการใช้งานที่ชัดเจน เช่น การวิเคราะห์การสตรีม ทว่ายังไม่คุกคามคลังข้อมูล ในบางจุด Data Lake มีชัยเหนือคลังข้อมูล โดยนำเสนอความสามารถในการวิเคราะห์ที่กว้างขึ้น ความคุ้มค่า และความยืดหยุ่นในแง่ของข้อมูลที่จัดเก็บ อย่างไรก็ตาม เนื่องจากเทคโนโลยีคลังข้อมูลได้เติบโตขึ้น หลายคนเห็นพ้องกันว่ายังไม่มีผู้ชนะที่ชัดเจนในตอนนี้ โดยทั่วไป แนะนำให้บำรุงรักษาทั้งสองอย่าง หรือ… เลือกใช้สถาปัตยกรรมแบบไฮบริด อ่านต่อ.
กรณีการใช้งาน Data Lake
แนวคิดหลักเกี่ยวกับ Data Lake คือการให้ธุรกิจเข้าถึงข้อมูลที่มีอยู่ทั้งหมดจากแหล่งที่มาทั้งหมดโดยเร็วที่สุด Data Lake ไม่เพียงแต่ให้ภาพเหตุการณ์เมื่อวานเท่านั้น การจัดเก็บข้อมูลจำนวนมหาศาล Data Lake ได้รับการออกแบบมาเพื่อให้องค์กรสามารถเรียนรู้เพิ่มเติมเกี่ยวกับทั้งในปัจจุบัน (โดยใช้การวิเคราะห์การสตรีม) และอนาคต (โดยใช้โซลูชัน Big Data รวมถึงการวิเคราะห์เชิงคาดการณ์และการเรียนรู้ของเครื่อง) กรณีการใช้งานที่สำคัญสำหรับ data lake คือ:
- การป้อนคลังข้อมูลขององค์กรด้วยชุดข้อมูล
- กำลังดำเนินการวิเคราะห์สตรีม
- การดำเนินโครงการ ML
- การสร้างแผนภูมิการวิเคราะห์ขั้นสูงโดยใช้เครื่องมือ BI ระดับองค์กรที่มีมายาวนาน เช่น Tableau หรือ MS Power BI
- การสร้างโซลูชันการวิเคราะห์ข้อมูลแบบกำหนดเอง
- เรียกใช้การวิเคราะห์สาเหตุที่ทำให้ทีมข้อมูลสามารถติดตามปัญหาไปยังรากของพวกเขาได้
ด้วยทักษะด้านวิศวกรรมข้อมูลที่แข็งแกร่งในการย้ายข้อมูลดิบไปยังสภาพแวดล้อมการวิเคราะห์ Data Lake จึงมีความเกี่ยวข้องอย่างยิ่ง ช่วยให้ทีมทดลองกับข้อมูลเพื่อทำความเข้าใจว่าข้อมูลดังกล่าวมีประโยชน์อย่างไร ซึ่งอาจเกี่ยวข้องกับการสร้างแบบจำลองเพื่อเจาะลึกข้อมูลและลองใช้สคีมาต่างๆ เพื่อดูข้อมูลด้วยวิธีใหม่ๆ Data Lake ยังอนุญาตให้มีการทะเลาะวิวาทกับข้อมูลสตรีมที่หลั่งไหลมาจากบันทึกการใช้เว็บและเซ็นเซอร์ IoT และไม่เหมาะกับแนวทางคลังข้อมูลแบบดั้งเดิม
กล่าวโดยย่อ Data Lake ช่วยให้องค์กรสามารถค้นพบรูปแบบ คาดการณ์การเปลี่ยนแปลง หรือค้นหาโอกาสทางธุรกิจที่อาจเกิดขึ้นจากผลิตภัณฑ์ใหม่หรือกระบวนการปัจจุบัน ใช้สำหรับความต้องการทางธุรกิจที่แตกต่างกัน ดาต้าเลคและคลังข้อมูลมักจะถูกนำไปใช้ควบคู่กัน ก่อนที่เราจะย้ายไปยังแนวคิดการจัดเก็บข้อมูลถัดไป เรามาสรุปความแตกต่างที่สำคัญระหว่างคลังข้อมูลและ Data Lake กันก่อน
คลังข้อมูลกับดาต้าเลค
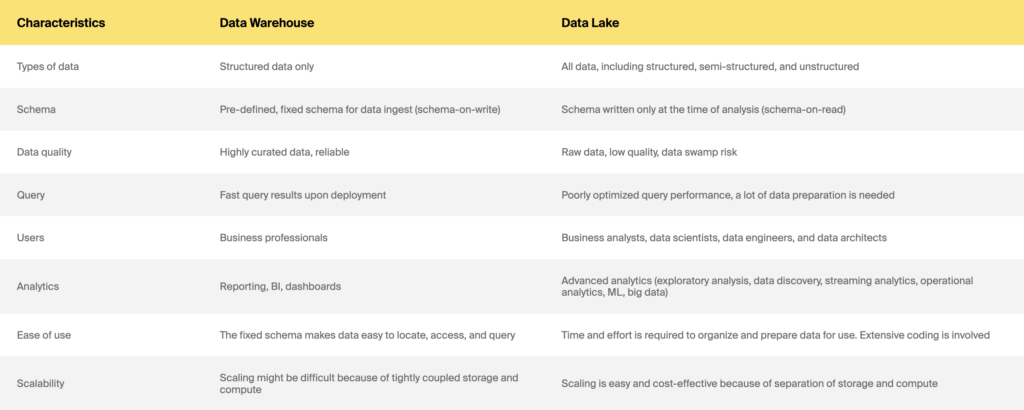
แล้วสถาปัตยกรรมไฮบริดใหม่ data lakehouses ล่ะ?
นอกเหนือจากการตลาดแล้ว แนวคิดหลักเกี่ยวกับ Data Lakehouse ก็คือการนำพลังการประมวลผลมาสู่ Data Lake ในทางสถาปัตยกรรม data lakehouse มักจะประกอบด้วย:
- ชั้น การจัดเก็บเพื่อจัดเก็บข้อมูลในรูปแบบเปิด (เช่น Parquet) เลเยอร์นี้สามารถเรียกได้ว่าเป็น data lake และแยกออกจากชั้นคอมพิวเตอร์
- เลเยอร์คอมพิวเตอร์ ที่ให้ความสามารถของคลังข้อมูลขององค์กร รองรับการจัดการข้อมูลเมตา การทำดัชนี การบังคับใช้สคีมา และธุรกรรม ACID (Atomicity, Consistency, Reliability และ Durability)
- เลเยอร์ API เพื่อเข้าถึงสินทรัพย์ข้อมูล
- เลเยอร์การให้บริการ เพื่อรองรับปริมาณงานต่างๆ ตั้งแต่การรายงานไปจนถึง BI วิทยาศาสตร์ข้อมูล หรือการเรียนรู้ของเครื่อง
รูปที่ 3: สถาปัตยกรรมอ้างอิง Data Lakehouse
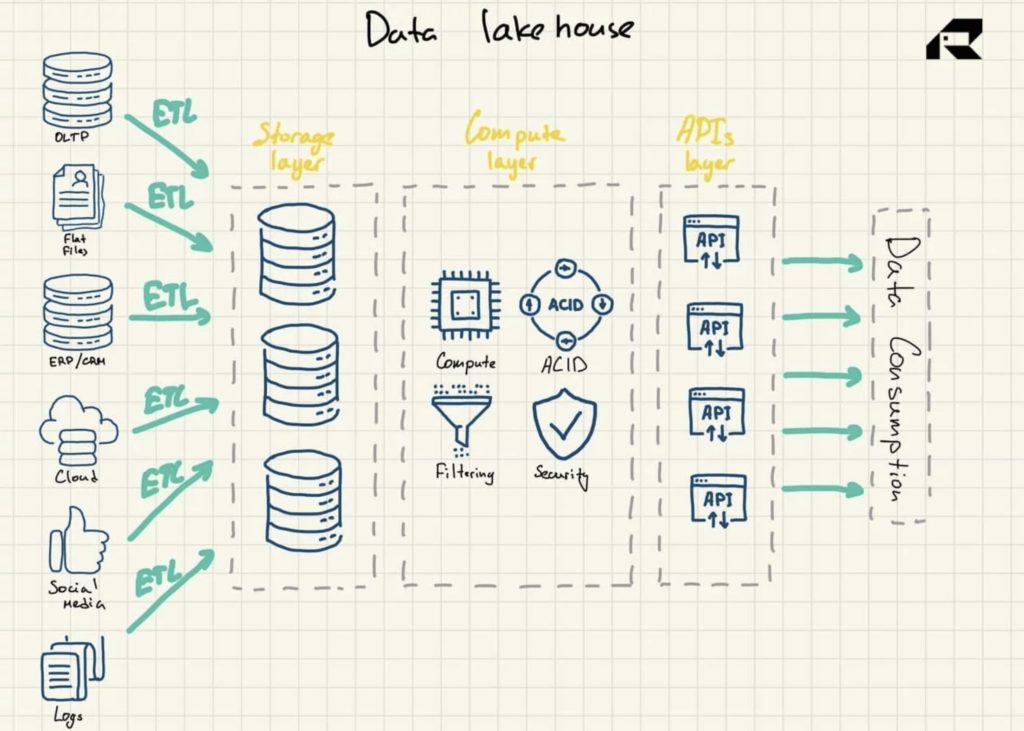
ได้รับการขนานนามว่าเป็นวิธีแก้ปัญหาที่แต่งงานกับสิ่งที่ดีที่สุดของทั้งสองโลก data lakehouse กล่าวถึงทั้งสอง:
- ข้อจำกัดของคลังข้อมูล รวมถึงการขาดการสนับสนุนการวิเคราะห์ข้อมูลขั้นสูงที่อาศัยทั้งข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง และค่าใช้จ่ายในการปรับขนาดที่สำคัญด้วยคลังข้อมูลแบบเดิมที่ไม่แยกการจัดเก็บออกจากทรัพยากรการประมวลผล
- ความท้าทายของ Data Lake รวมถึงการทำซ้ำของข้อมูล คุณภาพของข้อมูล และความจำเป็นในการเข้าถึงระบบหลายระบบสำหรับงานต่างๆ หรือใช้การผสานรวมที่ซับซ้อนกับเครื่องมือวิเคราะห์
Data Lakehouse เป็นความก้าวหน้าครั้งใหม่ในฉากการวิเคราะห์ข้อมูล แนวคิดนี้ใช้ครั้งแรกในปี 2560 โดยเกี่ยวข้องกับแพลตฟอร์ม Snowflake ในปี 2019 AWS ใช้คำศัพท์ data lakehouse เพื่ออธิบายบริการ Amazon Redshift Spectrum ที่อนุญาตให้ผู้ใช้บริการคลังข้อมูล Amazon Redshift ค้นหาผ่านข้อมูลที่จัดเก็บไว้ใน Amazon S3 ในปี 2020 คำว่า data lakehouse มีการใช้งานอย่างแพร่หลาย โดย Databricks นำมาใช้สำหรับแพลตฟอร์ม Delta Lake
Data Lakehouse อาจมีอนาคตที่สดใสในอนาคต เนื่องจากบริษัทในอุตสาหกรรมต่างๆ ต่างนำ AI มาใช้เพื่อปรับปรุงการดำเนินงานด้านบริการ นำเสนอผลิตภัณฑ์และบริการที่เป็นนวัตกรรมใหม่ หรือขับเคลื่อนความสำเร็จด้านการตลาด ข้อมูลที่มีโครงสร้างจากระบบปฏิบัติการที่จัดส่งโดยคลังข้อมูลนั้นไม่เหมาะสมสำหรับการวิเคราะห์อัจฉริยะ ในขณะที่ Data Lake ไม่ได้ถูกออกแบบมาสำหรับแนวทางการกำกับดูแลที่แข็งแกร่ง การรักษาความปลอดภัย หรือการปฏิบัติตามข้อกำหนดของ ACID
Data Lake กับ Data Lakehouse
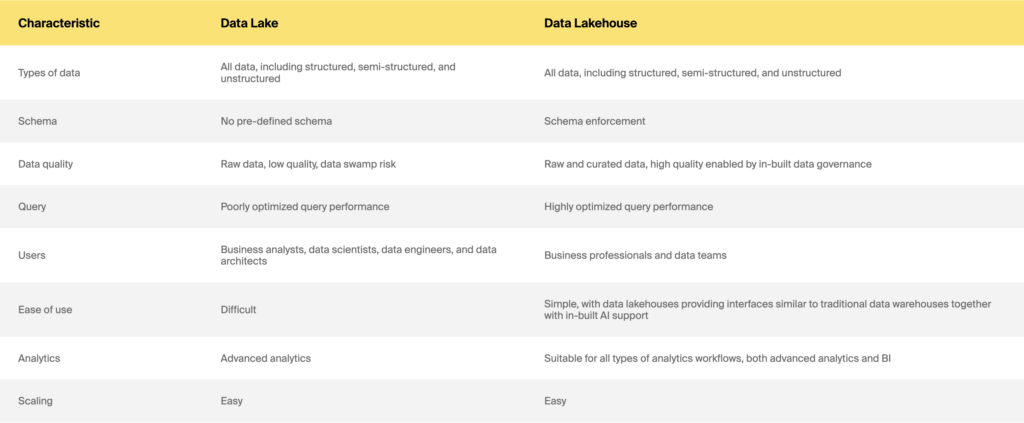
ดังนั้น คลังข้อมูล กับ ดาต้า เลค กับ ดาต้า เลคเฮาส์: อันไหนให้เลือก
ไม่ว่าคุณต้องการสร้างโซลูชันการจัดเก็บข้อมูลตั้งแต่เริ่มต้น หรือปรับปรุงระบบเดิมของคุณให้ทันสมัยเพื่อรองรับ ML หรือปรับปรุงประสิทธิภาพ คำตอบที่ถูกต้องนั้นไม่ใช่เรื่องง่าย ยังคงมีความยุ่งยากมากมายเกี่ยวกับความแตกต่าง ประโยชน์ และต้นทุนที่สำคัญ โดยการนำเสนอและรูปแบบการกำหนดราคาจากผู้ขายมีการพัฒนาอย่างรวดเร็ว นอกจากนี้ มันเป็นโครงการที่ยากเสมอ แม้ว่าคุณจะมีการซื้อจากผู้มีส่วนได้ส่วนเสียก็ตาม อย่างไรก็ตาม มีข้อควรพิจารณาที่สำคัญบางประการเมื่อเลือกคลังข้อมูลเทียบกับ Data Lake เทียบกับ Data Lakehouse
คำถามหลักที่คุณควรตอบคือ ทำไม จุดที่ดีที่ควรจำไว้คือความแตกต่างที่สำคัญระหว่างคลังข้อมูล ทะเลสาบ และบ้านริมทะเลสาบไม่ได้อยู่ที่เทคโนโลยี พวกเขากำลังตอบสนองความต้องการทางธุรกิจที่แตกต่างกัน เหตุใดคุณจึงต้องการโซลูชันการจัดเก็บข้อมูลตั้งแต่แรก? ใช้สำหรับการรายงานปกติ ระบบธุรกิจอัจฉริยะ การวิเคราะห์แบบเรียลไทม์ วิทยาศาสตร์ข้อมูล หรือการวิเคราะห์ที่ซับซ้อนอื่นๆ หรือไม่ ความสอดคล้องของข้อมูลหรือความตรงต่อเวลามีความสำคัญต่อความต้องการทางธุรกิจของคุณหรือไม่? ใช้เวลาพัฒนากรณีการใช้งาน ความต้องการด้านการวิเคราะห์ของคุณควรกำหนดไว้อย่างชัดเจน คุณควรเข้าใจผู้ใช้และชุดทักษะของคุณอย่างลึกซึ้งด้วย กฎทั่วไปบางประการคือ:
- คลังข้อมูลเป็นทางออกที่ดีหากคุณมีคำถามที่แน่นอนและทราบผลการวิเคราะห์ที่คุณต้องการได้รับอย่างสม่ำเสมอ
- หากคุณอยู่ในอุตสาหกรรมที่มีการควบคุมอย่างเข้มงวด เช่น การดูแลสุขภาพหรือการประกันภัย คุณอาจต้องปฏิบัติตามข้อบังคับการรายงานที่ครอบคลุมเหนือสิ่งอื่นใด ดังนั้นคลังข้อมูลจะเป็นทางเลือกที่ดีกว่า
- หาก KPI และข้อกำหนดการรายงานของคุณสามารถแก้ไขได้ด้วยการวิเคราะห์ในอดีตอย่างง่าย Data Lake หรือโซลูชันแบบไฮบริดจะเกินความสามารถ ไปกับคลังข้อมูลแทน
- หากทีมข้อมูลของคุณอยู่หลังการวิเคราะห์เชิงทดลองและเชิงสำรวจ ให้เลือก Data Lake หรือโซลูชันไฮบริด อย่างไรก็ตาม คุณจะต้องมีทักษะการวิเคราะห์ข้อมูลที่แข็งแกร่งเพื่อทำงานกับข้อมูลที่ไม่มีโครงสร้าง
- หากคุณเป็นองค์กรที่มีข้อมูลครบถ้วนที่ต้องการใช้ประโยชน์จากเทคโนโลยีการเรียนรู้ของเครื่อง โซลูชันไฮบริดหรือ Data Lake จะเหมาะสมอย่างยิ่ง
พิจารณาข้อจำกัดด้านงบประมาณและเวลาของคุณด้วย Data Lake สร้างได้เร็วกว่าคลังข้อมูลอย่างแน่นอน และอาจถูกกว่า คุณอาจต้องการใช้ความคิดริเริ่มของคุณทีละน้อยและเพิ่มความสามารถเมื่อคุณขยายขนาด หากคุณต้องการปรับปรุงระบบจัดเก็บข้อมูลแบบเดิมของคุณให้ทันสมัย คุณควรถามอีกครั้งว่าทำไมคุณถึงต้องการสิ่งนี้ มันช้าเกินไปหรือไม่? หรือไม่อนุญาตให้คุณเรียกใช้คิวรีในชุดข้อมูลที่ใหญ่กว่า ข้อมูลบางส่วนหายไปหรือไม่? คุณต้องการดึงการวิเคราะห์ประเภทอื่นออกมาหรือไม่? องค์กรของคุณใช้เงินไปเป็นจำนวนมากกับระบบเดิม ดังนั้นคุณจึงจำเป็นต้องมีกรณีศึกษาทางธุรกิจที่ชัดเจนเพื่อละทิ้งมัน ผูกเข้ากับ ROI ด้วย สถาปัตยกรรมการจัดเก็บข้อมูลยังคงเติบโตเต็มที่ เป็นไปไม่ได้ที่จะบอกว่าพวกเขาจะพัฒนาได้อย่างไร อย่างไรก็ตาม ไม่ว่าคุณจะเลือกเส้นทางใด การตระหนักถึงข้อผิดพลาดทั่วไปและใช้ประโยชน์สูงสุดจากเทคโนโลยีที่มีอยู่แล้วที่นี่ก็เป็นประโยชน์
เราหวังว่าบทความนี้จะช่วยขจัดความสับสนเกี่ยวกับคลังข้อมูลกับ Data Lake กับ Data Lakehouse หากคุณยังคงมีคำถามหรือต้องการทักษะด้านเทคโนโลยีชั้นยอดหรือคำแนะนำในการสร้างโซลูชันการจัดเก็บข้อมูล วางสาย ITRex พวกเขาจะช่วยคุณ
เผยแพร่ครั้งแรกที่ https://itrexgroup.com เมื่อวันที่ 23 กุมภาพันธ์ 2022