
混乱を切り抜ける:データウェアハウスvs.データレイクvs.データレイクハウス
公開: 2022-03-11データの無秩序な増加を利用するのに苦労しているため、業界全体のCIOは困難な課題に直面しています。 それらの1つは、堅牢なデータ分析を提供するために企業のすべてのデータを保存する場所です。
従来、データ用の2つのストレージソリューションがありました。データウェアハウスとデータレイクです。
データウェアハウスは、主に運用システムとトランザクションシステムからの変換された構造化データを格納し、この履歴データ全体の高速で複雑なクエリに使用されます。
データレイクはダンプとして機能し、半構造化データと非構造化データを含むすべての種類のデータを格納します。 これらは、ライブデータ処理や機械学習のためのストリーミング分析などの高度な分析を強化します。
歴史的に、データウェアハウスは、ストレージスペースとコンピューティングリソースの両方に、それらを維持するスキルとは別に支払う必要があるため、展開するのに費用がかかりました。 ストレージのコストが下がったため、データウェアハウスは安くなりました。 データレイク(従来はより費用効果の高い代替手段)が現在は機能していないと考える人もいます。 データレイクはまだ流行していると主張する人もいます。 一方、他の人々は、新しいハイブリッドデータストレージソリューションであるデータレイクハウスについて話し合っています。
それらのそれぞれとの取引は何ですか? よく見てみましょう。
このブログでは、データウェアハウス、データレイク、データレイクハウス、人気のある技術スタック、およびユースケースの主な違いについて説明します。 また、これは注意が必要ですが、会社に適したソリューションを選択するためのヒントも提供します。
データウェアハウスとは何ですか?
データウェアハウスは、構造化され、精選されたデータを格納し、データセットをテーブルと列に整理するように設計されています。 このデータは、従来のビジネスインテリジェンス、ダッシュボード、およびレポート用にユーザーが簡単に利用できます。
データウェアハウスアーキテクチャ
3層アーキテクチャは、データウェアハウスを設計するために最も一般的に使用されるアプローチです。 それは以下を含みます:
- 最下層:さまざまなソースからデータをロードするために使用されるデータウェアハウスのステージング領域とデータベースサーバー。 抽出、変換、および読み込み(ETL)プロセスは、データをデータウェアハウスにプッシュするための従来のアプローチです。
- 中間層:データを多次元形式に再編成して高速計算を行うオンライン分析処理(OLAP)用のサーバー
- トップティア:データを操作するためのAPIとフロントエンドツール
図1:データウェアハウスのリファレンスアーキテクチャ
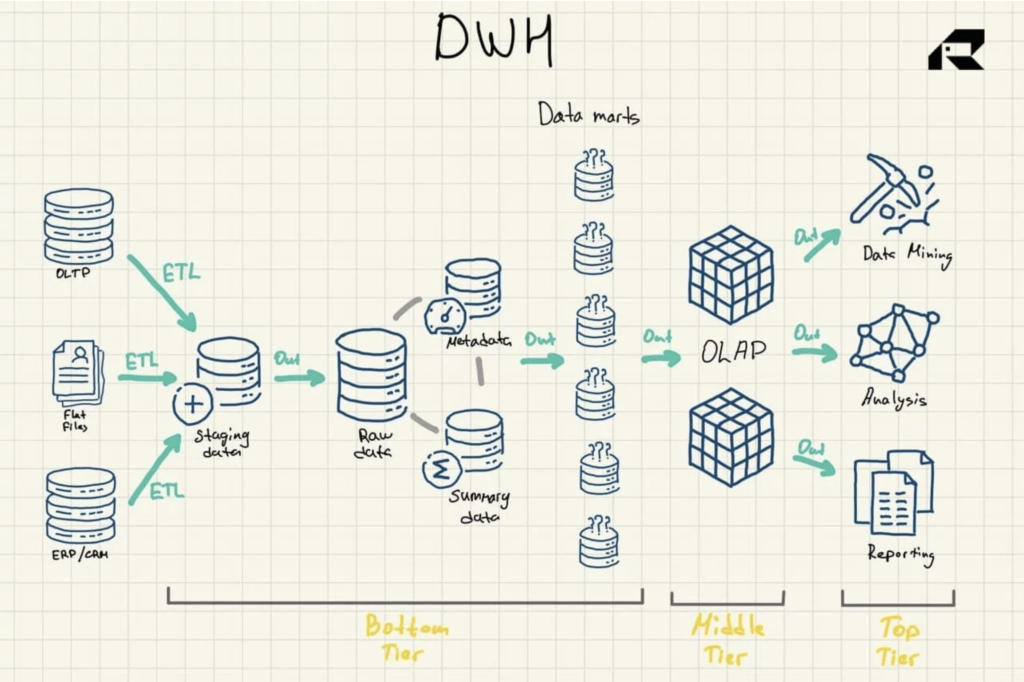
言及する必要があるデータウェアハウスの他の3つの重要なコンポーネントがあります:データマート、運用データストレージ、およびメタデータ。 データマートは最下層に属します。 データウェアハウスデータのサブセットを格納し、個々のビジネスラインにサービスを提供します。
運用データストアは、単純なクエリに基づく運用レポート用の組織の最新データのスナップショットを提供するリポジトリとして機能します。 これらは、データソースとデータウェアハウスの間の中間層として使用できます。
メタデータ(データウェアハウスデータを説明するデータ)もあり、これも最下層の専用リポジトリに保存されます。
データウェアハウスの進化とテクノロジー
データウェアハウスは数十年前から存在しています。
従来、データウェアハウスはオンプレミスでホストされていました。つまり、企業はすべてのハードウェアを購入し、有料またはオープンソースシステムのいずれかでソフトウェアをローカルに展開する必要がありました。 また、データウェアハウスを維持するためにITチーム全体が必要でした。 明るい面として、従来のデータウェアハウスは、遅延の問題がなく、データを完全に制御し、100%のプライバシーを確保し、セキュリティリスクを最小限に抑えながら、迅速な調査を実現していました(現在もそうしています)。
クラウドの普及により、多くの組織は現在、すべてのデータがクラウドに保存されるクラウドデータウェアハウスソリューションへの移行を選択しています。 ある種の統合クエリエンジンを使用して、クラウドでも分析されます。
市場にはさまざまな確立されたクラウドデータウェアハウスソリューションがあります。 各プロバイダーは、独自のウェアハウス機能とさまざまな価格設定モデルを提供しています。 たとえば、AmazonRedshiftは従来のデータウェアハウスとして編成されています。 スノーフレークも同様です。 Microsoft AzureはSQLデータウェアハウスですが、Google BigQueryは、たとえばAmazon Redshiftのようなインフラストラクチャやサービスとしてのプラットフォームではなく、本質的にサービスとしてのソフトウェア(SaaS)を提供するサーバーレスアーキテクチャに基づいています。
よく知られているオンプレミスのデータウェアハウスソリューションには、IBM Db2、Oracle Autonomous Database、IBM Netezza、Teradata Vantage、SAP HANA、Exasolがあります。 それらはクラウドでも利用できます。
クラウドベースのデータウェアハウスは、物理サーバーを購入したり展開したりする必要がないため、明らかに安価です。 ユーザーは、必要に応じてストレージスペースとコンピューティングパワーに対してのみ料金を支払います。 クラウドソリューションは、他のサービスとの拡張や統合もはるかに簡単です。
最高のデータ品質と迅速な洞察を備えた非常に具体的なビジネスニーズに対応するデータウェアハウスは、長く存続します。
データウェアハウスのユースケース
データウェアハウスは、ペタバイトおよびペタバイトの履歴データに関する高速で高性能な分析を提供します。
これらは基本的にBIタイプのクエリ用に設計されています。 データウェアハウスは、たとえば、地域または部門ごとにグループ化された特定の期間の売上、および売上の前年比の動きについての回答を提供する場合があります。 データウェアハウスの主な使用例は次のとおりです。
- ビジネスパフォーマンスの全体像を提供するためのトランザクションレポート
- スタンドアロンおよび「1回限りの」ビジネス上の課題に対する回答を提供するためのアドホック分析/レポート
- 複雑な現実世界の問題を解決するためにデータから有用な知識と隠されたパターンを抽出するためのデータマイニング
- データの視覚化による動的なプレゼンテーション
- 詳細については、ドリルダウンしてデータの階層ディメンションを確認してください
運用データベースの外部の簡単にアクセスできる1つの場所に構造化されたビジネスデータを配置することは、データが成熟している企業にとって非常に重要です。
ただし、従来のデータウェアハウスはビッグデータテクノロジーをサポートしていません。
また、バッチで更新され、すべてのソースからのレコードが一度に定期的に処理されます。つまり、分析のためにロールアップされるまでにデータが古くなる可能性があります。 データレイクはこれらの制約を解決しているようです。 トレードオフがあります。 探検しましょう。
データレイクとは何ですか?
データレイクは、ほとんどの場合、元の形式で未精製の生データを収集します。 データレイクとデータウェアハウスのもう1つの重要な違いは、データレイクは、スキーマと呼ばれる論理的な関係にデータを配置せずに、このデータを格納することです。 ただし、これがより高度な分析を可能にする方法です。
データレイクは、(i)ERP、CRM、SCMなどのビジネスアプリケーションからのトランザクションデータ、(ii).csvおよび.txt形式のドキュメント、(iii)XML、JSON、AVRO形式などの半構造化データを取り込みます。 (iv)デバイスログとIoTセンサー、および(v)画像、オーディオ、バイナリ、PDFファイル。
データレイクアーキテクチャ
データレイクは、データストレージにフラットアーキテクチャを使用します。 その主要なコンポーネントは次のとおりです。
- 湖に取り込まれたすべてのデータのブロンズゾーン。 データは、バッチパターンの場合はそのまま、またはストリーミングワークロードの場合は集約されたデータセットとして保存されます。
- ビジネスニーズに応じてデータをフィルタリングおよび強化して調査するシルバーゾーン
- BIツールとMLアルゴリズムを適用するために、厳選された適切に構造化されたデータが保存されるゴールドゾーン。 このゾーンには、従来のデータウェアハウスやデータマートにデータを提供する運用データストアが備わっていることがよくあります。
- 仮説の検証とテストのためにデータを実験できるサンドボックス。 これは、Hadoopまたは他のNoSQLテクノロジー用の完全に別個のデータベースとして、またはゴールドゾーンの一部として実装されます。
図2:データレイクリファレンスアーキテクチャ
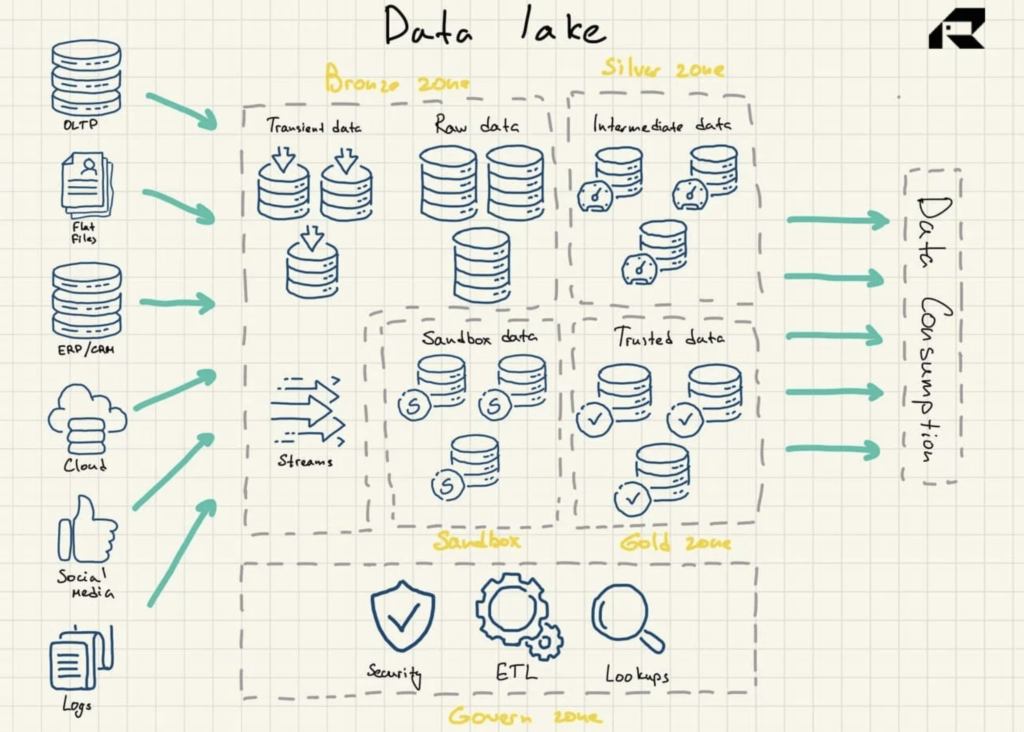
データレイクには、本質的に分析機能は含まれていません。 それらがなければ、それ自体では役に立たない生データを保存するだけです。 そのため、組織はデータウェアハウスを構築するか、データレイクの上に他のツールを活用してデータを使用します。
データレイクがデータスワンプにならないようにするには、データレイクの設計に組み込みのデータガバナンスとメタデータ管理を含める効率的なデータ管理戦略を立てることが重要です。 理想的な世界では、データレイクにあるデータは、カタログ化、インデックス作成、検証され、データユーザーが簡単に利用できるようにする必要があります。 ただし、これはめったに発生せず、多くのデータレイクプロジェクトは失敗します。 これは回避できます。データチームの成熟度に関係なく、データの検証と品質を強化するために、少なくとも不可欠なコントロールをインストールすることが重要です。
データレイクの進化とテクノロジー
2000年代初頭のビッグデータの台頭は、組織に大きなチャンスと大きな課題の両方をもたらしました。 ビジネスは、ビッグデータからビジネスへの影響を把握するために、これらの大規模で乱雑で途方もなく急成長しているデータセットを分析するための新しいテクノロジーを必要としていました。
2008年、Apache Hadoopは、非構造化データを大規模に収集および処理するための革新的なオープンソーステクノロジーを考案し、ビッグデータ分析とデータレイクへの道を開きました。 その後まもなく、ApacheSparkが登場しました。 使いやすかったです。 さらに、MLモデルの構築とトレーニング、SQLを使用した構造化データのクエリ、およびリアルタイムデータの処理のための機能を提供しました。
今日、データレイクは主にクラウドでホストされるリポジトリです。 AWS、Azure、Googleなどのすべてのトップクラウドプロバイダーは、費用対効果の高いオブジェクトストレージサービスを備えたクラウドベースのデータレイクを提供しています。 彼らのプラットフォームには、展開を自動化するためのさまざまなデータ管理サービスが付属しています。 たとえば、あるシナリオでは、データレイクは、Hadoop分散ファイルシステム(HDFS)などのデータストレージシステムや、AmazonRedshiftなどのクラウドデータウェアハウスソリューションと統合されたAmazonS3で構成されている場合があります。 これらのコンポーネントは、データ処理用のAmazon EMR、データカタログと変換機能を提供するAmazon Glue、Amazon Athenaクエリサービス、またはメタデータリポジトリとインデックスの構築に使用されるAmazonElasticsearchServiceを含むエコシステム内のサービスから切り離されます。データ。 セキュリティ、プライバシー、遅延などの通常のクラウドの懸念があるため、ローカルデータレイクは依然として一般的です。

データレイク向けにいくつかの製品を提供しているオンプレミスのストレージベンダーもありますが、データレイクの提供内容は明確に定義されていません。 データウェアハウスとは異なり、データレイクの背後には何年にもわたる実際の展開がありません。 データレイクの概念をぼやけて明確に定義されていないものとして説明する批判はまだたくさんあります。 批評家はまた、どの組織でも、生データに対して探索的ワークロードを実行するスキル(またはそのことに対する熱意)を持っている人はほとんどいないと主張しています。
データレイクをすべての企業のデータの中央リポジトリとして使用する必要があるという考えには、注意して取り組む必要があると彼らは言います。 データレイクの日数が数えられるという挑発的な話もありました。 次の理由が挙げられます。
- データレイクは、オンデマンドでコンピューティングリソースを効率的にスケーリングできません(これは、そもそも設計によって意図されたものではないためです)
- データレイクには大きな技術的負債があり、その作成は技術的な理由ではなく、主にマーケティングの誇大宣伝によって引き起こされています(同じことが多くのデータウェアハウスでも発生しています)
- クラウドデータウェアハウスソリューションの台頭により、データレイクはもはや大きなコストメリットを提供しなくなりました(コンピューティングコストを予測するのは難しいため、コストの問題はそれほど単純ではありません)
このような批判は、若いテクノロジーに固有の部分です。 ただし、データレイクには、ストリーミング分析などの明確なユースケースがあります。 そして今のところ、それらはデータウェアハウスを脅かしていません。 ある時点で、データレイクはデータウェアハウスに打ち勝ち、より幅広い分析機能、費用対効果、および保存されたデータに関する柔軟性を提供しました。 ただし、データウェアハウス技術が成熟するにつれて、多くの人が、現在、明らかな勝者がいないことに同意しています。 一般に、両方を維持するか、ハイブリッドアーキテクチャを採用することをお勧めします。 読む。
データレイクのユースケース
データレイクに関する主なアイデアは、すべてのソースから利用可能なすべてのデータにできるだけ早くアクセスできるようにすることです。 データレイクは、昨日何が起こったのかを示すだけではありません。 大量のデータを格納するデータレイクは、組織が現在(ストリーミング分析を使用)と将来(予測分析や機械学習などのビッグデータソリューションを使用)の両方について詳しく知ることができるように設計されています。 データレイクの主なユースケースは次のとおりです。
- エンタープライズデータウェアハウスにデータセットを提供する
- ストリーム分析の実行
- MLプロジェクトの実施
- TableauやMSPowerBIなどの老舗のエンタープライズBIツールを使用して高度な分析チャートを作成する
- カスタムデータ分析ソリューションの構築
- データチームが問題を根本原因まで追跡できるようにする根本原因分析の実行
生データを分析環境に移動するための強力なデータエンジニアリングスキルにより、データレイクは非常に関連性が高くなります。 これにより、チームはデータを実験して、データがどのように役立つかを理解できます。 これには、データを掘り下げてさまざまなスキーマを試し、新しい方法でデータを表示するためのモデルの構築が含まれる場合があります。 データレイクでは、WebログやIoTセンサーから流入するストリームデータとのラングリングも可能であり、従来のデータウェアハウスアプローチには適していません。
つまり、データレイクを使用すると、組織はパターンを発掘したり、変更を予測したり、新製品や現在のプロセスに関する潜在的なビジネスチャンスを見つけたりすることができます。 さまざまなビジネスニーズに使用されるデータレイクとデータウェアハウスは、多くの場合、連携して実装されます。 次のデータストレージの概念に移る前に、データウェアハウスとデータレイクの主な違いを簡単に要約しましょう。
データウェアハウスとデータレイク
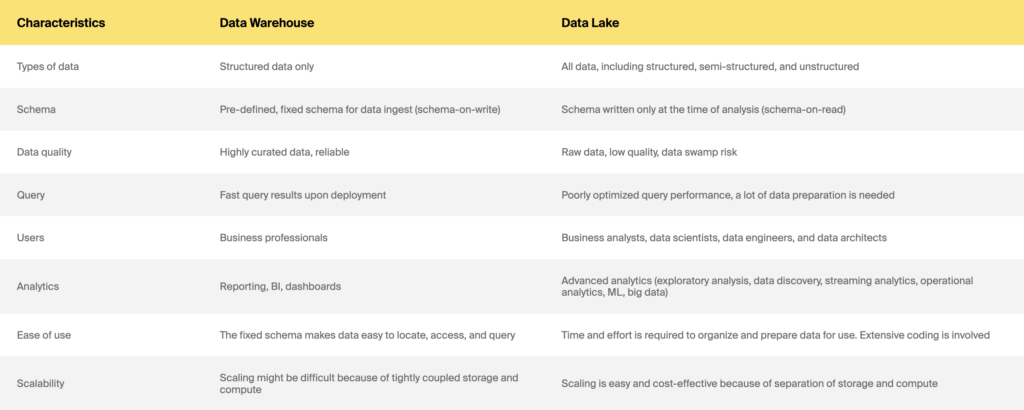
新しいハイブリッドアーキテクチャであるデータレイクハウスについてはどうでしょうか。
マーケティングはさておき、データレイクハウスに関する重要なアイデアは、データレイクにコンピューティングパワーをもたらすことです。 アーキテクチャ上、データレイクハウスは通常次のもので構成されます。
- オープンフォーマット(Parquetなど)でデータを保存するためのストレージレイヤー。 このレイヤーはデータレイクと呼ぶことができ、コンピューティングレイヤーから分離されています
- 組織にウェアハウス機能を提供し、メタデータ管理、インデックス作成、スキーマ施行、およびACID(Atomicity、Consistency、Reliability、およびDurability)トランザクションをサポートするコンピューティングレイヤー
- データアセットにアクセスするためのAPIレイヤー
- レポートからBI、データサイエンス、機械学習まで、さまざまなワークロードをサポートするサービングレイヤー。
図3:データレイクハウスリファレンスアーキテクチャ
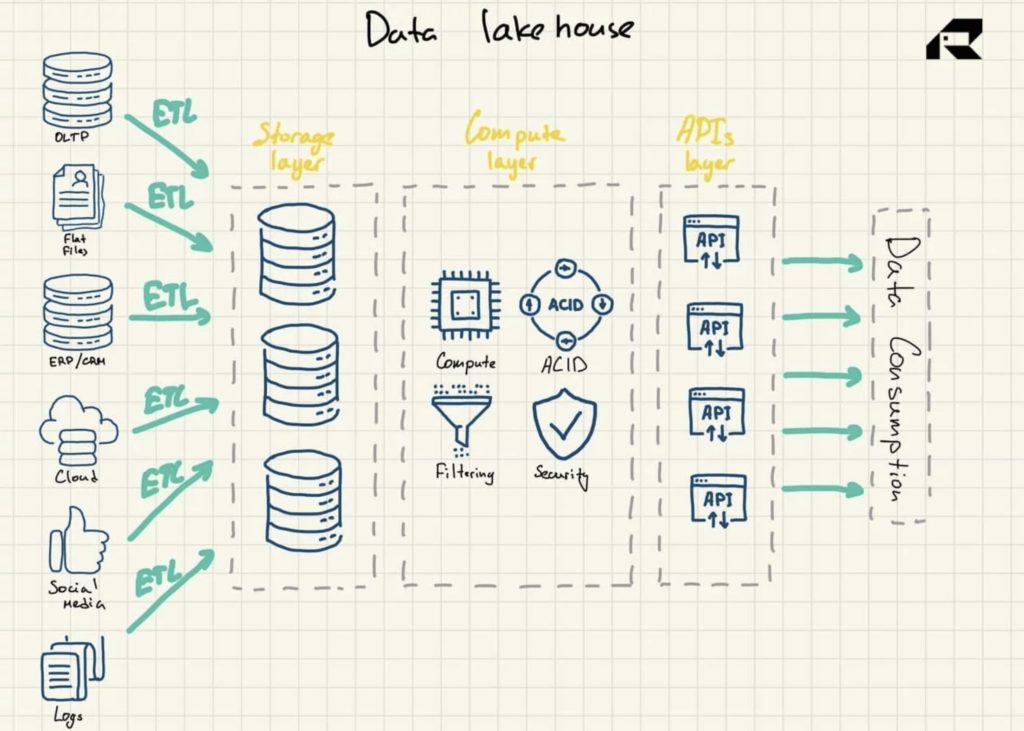
両方の長所を組み合わせたソリューションとして宣伝されているデータレイクハウスは、次の両方に対応しています。
- 構造化データと非構造化データの両方に依存する高度なデータ分析のサポートの欠如や、ストレージをコンピューティングリソースから分離しない従来のデータウェアハウスでの大幅なスケーリングコストなど、データウェアハウスの制約
- データの複製、データ品質、さまざまなタスクのために複数のシステムにアクセスしたり、分析ツールとの複雑な統合を実装したりする必要性など、データレイクの課題
データレイクハウスは、データ分析シーンの新たな進歩です。 このコンセプトは、2017年にスノーフレークプラットフォームに関連して最初に使用されました。 2019年、AWSはデータレイクハウスという用語を使用して、データウェアハウスサービスAmazonRedshiftのユーザーがAmazonS3に保存されているデータを検索できるようにするAmazonRedshiftSpectrumサービスを説明しました。 2020年に、データレイクハウスの用語が広く使用されるようになり、DatabricksはそれをDeltaLakeプラットフォームに採用しました。
データレイクハウスは、さまざまな業界の企業がAIを採用してサービス運用を改善したり、革新的な製品やサービスを提供したり、マーケティングの成功を促進したりするため、明るい未来を迎える可能性があります。 データウェアハウスによって提供される運用システムからの構造化データは、スマート分析には適していませんが、データレイクは、堅牢なガバナンスプラクティス、セキュリティ、またはACIDコンプライアンス向けに設計されていません。
データレイクとデータレイクハウス
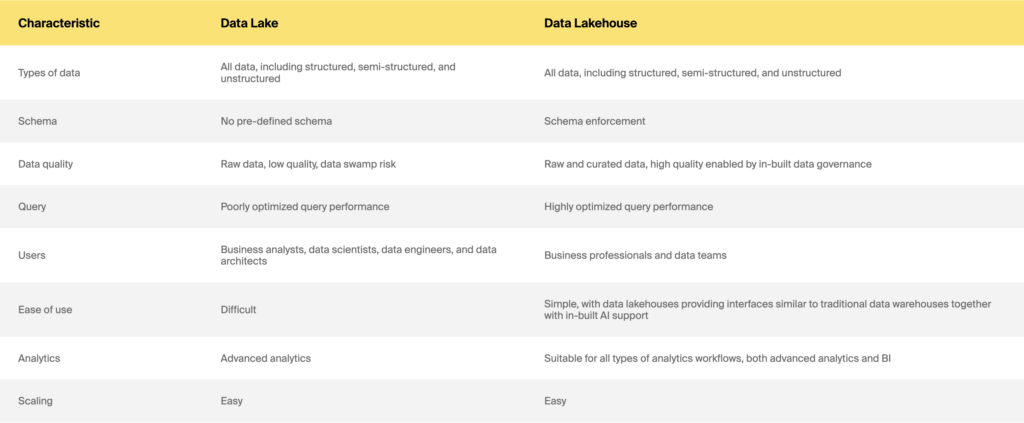
つまり、データウェアハウスとデータレイクとデータレイクハウスのどちらを選択するか
データストレージソリューションをゼロから構築する場合でも、レガシーシステムを最新化してMLをサポートしたり、パフォーマンスを向上させたりする場合でも、正しい答えは簡単ではありません。 主要な違い、利点、およびコストについてはまだ多くの混乱があり、ベンダーからの提供物と価格設定モデルは急速に進化しています。 その上、利害関係者の賛同があったとしても、それは常に難しいプロジェクトです。 ただし、データウェアハウス、データレイク、データレイクハウスを選択する際には、いくつかの重要な考慮事項があります。
あなたが答えるべき主な質問は:なぜです。 ここで覚えておくべき良い点は、データウェアハウス、湖、湖の家の主な違いはテクノロジーにあるのではないということです。 彼らはさまざまなビジネスニーズに対応することを目的としています。 では、そもそもなぜデータストレージソリューションが必要なのですか? 定期的なレポート、ビジネスインテリジェンス、リアルタイム分析、データサイエンス、またはその他の高度な分析用ですか? データの一貫性または適時性は、ビジネスニーズにとってより重要ですか? ユースケースの開発に時間をかけます。 分析のニーズは明確に定義する必要があります。 ユーザーとスキルセットについても深く理解する必要があります。 親指のいくつかのルールは次のとおりです。
- 正確な質問があり、定期的に取得したい分析結果がわかっている場合は、データウェアハウスが適しています。
- ヘルスケアや保険などの規制の厳しい業界にいる場合は、何よりも広範な報告規制に準拠する必要があります。 したがって、データウェアハウスの方が適しています。
- KPIとレポート要件に簡単な履歴分析で対処できる場合、データレイクまたはハイブリッドソリューションはやり過ぎになります。 代わりにデータウェアハウスを使用してください。
- データチームが実験的および探索的分析を行っている場合は、データレイクまたはハイブリッドソリューションを選択してください。 ただし、非構造化データを操作するには、強力なデータ分析スキルが必要です。
- 機械学習テクノロジーを活用したいデータ成熟した組織の場合、ハイブリッドソリューションまたはデータレイクが自然に適合します。
予算と時間の制約も考慮してください。 データレイクは確かにデータウェアハウスよりも構築が速く、おそらく安価です。 イニシアチブを段階的に実装し、スケールアップするにつれて機能を追加することをお勧めします。 従来のデータストレージシステムを最新化する場合は、なぜこれが必要なのかをもう一度尋ねる必要があります。 遅すぎますか? または、より大きなデータセットでクエリを実行することはできませんか? 一部のデータが欠落していますか? 別の種類の分析を引き出したいですか? あなたの組織はレガシーシステムに多額の費用を費やしているので、それを捨てるには確かに強力なビジネスケースが必要です。 ROIにも結び付けます。 データストレージアーキテクチャはまだ成熟しています。 それらがどのように進化するかを確実に言うことは不可能です。 ただし、どの方法をとっても、よくある落とし穴を認識し、すでにここにあるテクノロジーを最大限に活用することは有用です。
この記事で、データウェアハウス、データレイク、データレイクハウスに関する混乱が解消されたことを願っています。 それでも質問がある場合、またはデータストレージソリューションを構築するための最高の技術スキルやアドバイスが必要な場合は、ITRexに連絡してください。 彼らはあなたを助けます。
もともとは2022年2月23日にhttps://itrexgroup.comで公開されました。