
Memotong Kebingungan: Data Warehouse vs. Data Lake vs. Data Lakehouse
Diterbitkan: 2022-03-11Berjuang untuk memanfaatkan penyebaran data, CIO di seluruh industri menghadapi tantangan berat. Salah satunya adalah tempat untuk menyimpan semua data perusahaan mereka untuk memberikan analisis data yang kuat.
Secara tradisional ada dua solusi penyimpanan untuk data: gudang data dan danau data.
Gudang data terutama menyimpan data terstruktur dan tertransformasi dari sistem operasional dan transaksional, dan digunakan untuk kueri kompleks yang cepat di seluruh data historis ini.
Data lake bertindak sebagai dump, menyimpan semua jenis data, termasuk data semi-terstruktur dan tidak terstruktur. Mereka memberdayakan analitik lanjutan seperti analitik streaming untuk pemrosesan data langsung atau pembelajaran mesin.
Secara historis, gudang data mahal untuk diluncurkan karena Anda perlu membayar ruang penyimpanan dan sumber daya komputasi, selain dari keterampilan untuk memeliharanya. Karena biaya penyimpanan telah menurun, gudang data menjadi lebih murah. Beberapa orang percaya bahwa data lake (secara tradisional merupakan alternatif yang lebih hemat biaya) sekarang sudah mati. Beberapa berpendapat danau data masih trendi. Sementara itu, yang lain berbicara tentang solusi penyimpanan data hybrid baru — data lakehouses.
Apa urusannya dengan mereka masing-masing? Mari kita lihat dari dekat.
Blog ini mengeksplorasi perbedaan utama antara gudang data, data lake, dan data lakehouses, tumpukan teknologi populer, dan kasus penggunaan. Ini juga memberikan tips untuk memilih solusi yang tepat untuk perusahaan Anda, meskipun yang satu ini rumit.
Apa itu gudang data?
Gudang data dirancang untuk menyimpan data terstruktur dan terkurasi, mengatur kumpulan data dalam tabel dan kolom. Data ini tersedia dengan mudah bagi pengguna untuk intelijen bisnis tradisional, dasbor, dan pelaporan.
Arsitektur gudang data
Arsitektur tiga tingkat adalah pendekatan yang paling umum digunakan untuk merancang gudang data. Ini terdiri dari:
- Tingkat bawah: Area pementasan dan server database dari gudang data yang digunakan untuk memuat data dari berbagai sumber. Proses ekstraksi, transformasi, dan pemuatan (ETL) adalah pendekatan tradisional untuk memasukkan data ke dalam gudang data
- Tingkat menengah: Server untuk pemrosesan analitik online (OLAP) yang mengatur ulang data ke dalam format multidimensi untuk penghitungan cepat
- Tingkat teratas: API dan alat frontend untuk bekerja dengan data
Gambar 1: Arsitektur Referensi Data Warehouse
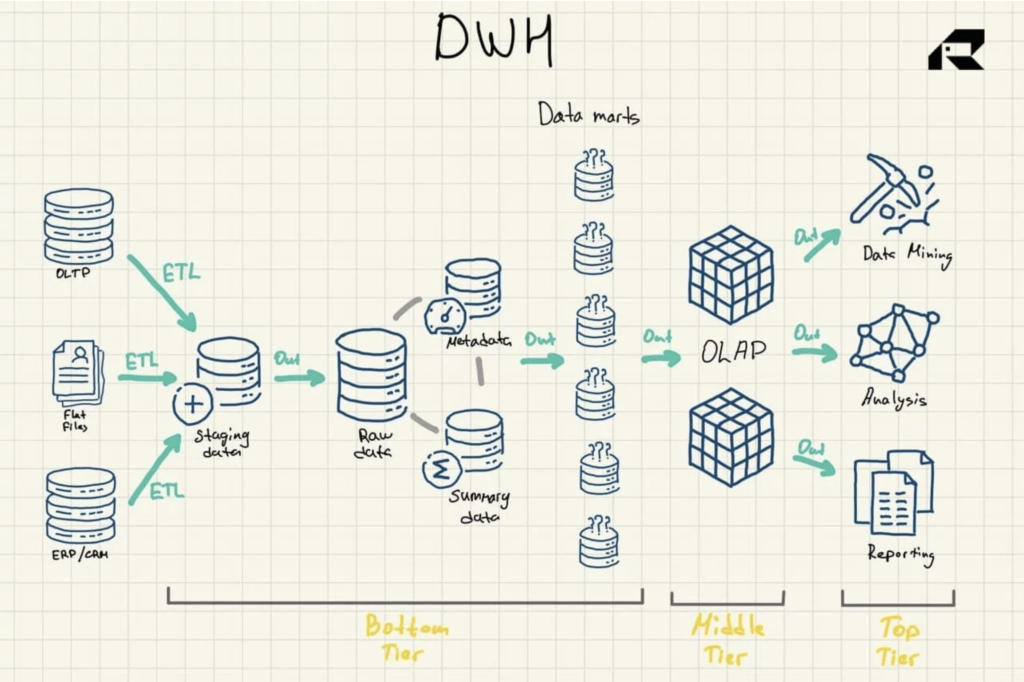
Ada tiga komponen penting lainnya dari gudang data yang harus disebutkan: data mart, penyimpanan data operasional, dan metadata. Data mart milik tingkat bawah. Mereka menyimpan subset dari data gudang data, melayani lini bisnis individu.
Penyimpanan data operasional bertindak sebagai repositori yang menyediakan snapshot dari data terkini organisasi untuk pelaporan operasional berdasarkan kueri sederhana. Mereka dapat digunakan sebagai lapisan sementara antara sumber data dan gudang data.
Ada juga metadata — data yang menjelaskan data gudang data — yang disimpan dalam repositori tujuan khusus, juga di lapisan bawah.
Evolusi dan teknologi gudang data
Gudang data telah ada selama beberapa dekade.
Secara tradisional, gudang data di-host di tempat, yang berarti perusahaan harus membeli semua perangkat keras dan menggunakan perangkat lunak secara lokal, baik sistem berbayar atau sumber terbuka. Mereka juga membutuhkan seluruh tim TI untuk memelihara gudang data. Sisi baiknya, gudang data tradisional menghadirkan (dan masih melakukannya hingga hari ini) pemahaman yang cepat tanpa masalah latensi, kontrol total data bersama dengan privasi seratus persen, dan risiko keamanan yang diminimalkan.
Dengan keberadaan cloud di mana-mana, banyak organisasi sekarang memilih untuk bermigrasi ke solusi gudang data cloud tempat semua data disimpan di cloud. Itu juga dianalisis di cloud, menggunakan beberapa jenis mesin kueri terintegrasi.
Ada berbagai solusi gudang data cloud yang mapan di pasar. Setiap penyedia menawarkan serangkaian kemampuan gudang yang unik dan model penetapan harga yang berbeda. Misalnya, Amazon Redshift diatur sebagai gudang data tradisional. Kepingan salju juga sama. Microsoft Azure adalah gudang data SQL, sedangkan Google BigQuery didasarkan pada arsitektur tanpa server yang pada dasarnya menawarkan software-as-a-service (SaaS), daripada infrastruktur atau platform-as-a-service seperti, misalnya, Amazon Redshift.
Di antara solusi gudang data lokal yang terkenal adalah IBM Db2, Oracle Autonomous Database, IBM Netezza, Teradata Vantage, SAP HANA, dan Exasol. Mereka juga tersedia di cloud.
Gudang data berbasis cloud jelas lebih murah karena tidak perlu membeli atau meluncurkan server fisik. Pengguna hanya membayar ruang penyimpanan dan daya komputasi sesuai kebutuhan. Solusi cloud juga jauh lebih mudah untuk diskalakan atau diintegrasikan dengan layanan lain.
Melayani kebutuhan bisnis yang sangat spesifik dengan kualitas data terbaik dan wawasan yang cepat, gudang data akan bertahan lama.
Kasus penggunaan gudang data
Gudang data memberikan analitik berkecepatan tinggi dan berkinerja tinggi pada petabyte dan petabyte data historis.
Mereka pada dasarnya dirancang untuk kueri tipe BI. Sebuah gudang data mungkin memberikan jawaban tentang, misalnya, penjualan dalam periode waktu tertentu, dikelompokkan berdasarkan wilayah atau divisi, dan pergerakan penjualan dari tahun ke tahun. Kasus penggunaan utama untuk gudang data adalah:
- Pelaporan transaksional untuk memberikan gambaran kinerja bisnis
- Analisis/pelaporan ad-hoc untuk memberikan jawaban atas tantangan bisnis yang berdiri sendiri dan "satu kali"
- Penambangan data untuk mengekstrak pengetahuan yang berguna dan pola tersembunyi dari data untuk memecahkan masalah dunia nyata yang kompleks
- Presentasi dinamis melalui visualisasi data
- Menelusuri untuk menelusuri dimensi hierarkis data untuk detailnya
Memiliki data bisnis terstruktur di satu lokasi yang mudah diakses di luar basis data operasional cukup penting bagi perusahaan dewasa data mana pun.
Namun, gudang data tradisional tidak mendukung teknologi data besar.
Mereka juga diperbarui dalam batch, dengan catatan dari semua sumber diproses secara berkala dalam sekali jalan, yang berarti bahwa data dapat menjadi basi pada saat digulung untuk analitik. Danau data tampaknya menyelesaikan kendala ini. Dengan pertukaran. Mari kita jelajahi.
Apa itu danau data?
Data lake sebagian besar mengumpulkan data mentah yang tidak dimurnikan dalam bentuk aslinya. Perbedaan utama lainnya antara data lake dan data warehouse adalah bahwa data lake menyimpan data ini tanpa mengaturnya ke dalam hubungan logis apa pun yang disebut skema. Namun, ini adalah cara mereka mengaktifkan analitik yang lebih canggih.
Data lake menarik (i) data transaksional dari aplikasi bisnis seperti ERP, CRM, atau SCM, (ii) dokumen dalam format .csv dan .txt, (iii) data semi terstruktur seperti format XML, JSON, dan AVRO, (iv) log perangkat dan sensor IoT, dan (v) gambar, audio, biner, file PDF.
Arsitektur danau data
Data lake menggunakan arsitektur datar untuk penyimpanan data. Komponen utamanya adalah:
- Zona perunggu untuk semua data yang diserap ke dalam danau. Data disimpan apa adanya untuk pola batch atau sebagai kumpulan data agregat untuk beban kerja streaming
- Zona perak tempat data disaring dan diperkaya untuk eksplorasi sesuai kebutuhan bisnis
- Zona emas tempat data yang dikuratori dan terstruktur dengan baik disimpan untuk menerapkan alat BI dan algoritme ML. Zona ini sering menampilkan penyimpanan data operasional yang menyediakan gudang data tradisional dan data mart
- Kotak pasir tempat data dapat dicoba untuk validasi dan pengujian hipotesis. Ini diimplementasikan baik sebagai database yang sepenuhnya terpisah untuk Hadoop atau teknologi NoSQL lainnya atau sebagai bagian dari zona emas.
Gambar 2: Arsitektur Referensi Data Lake
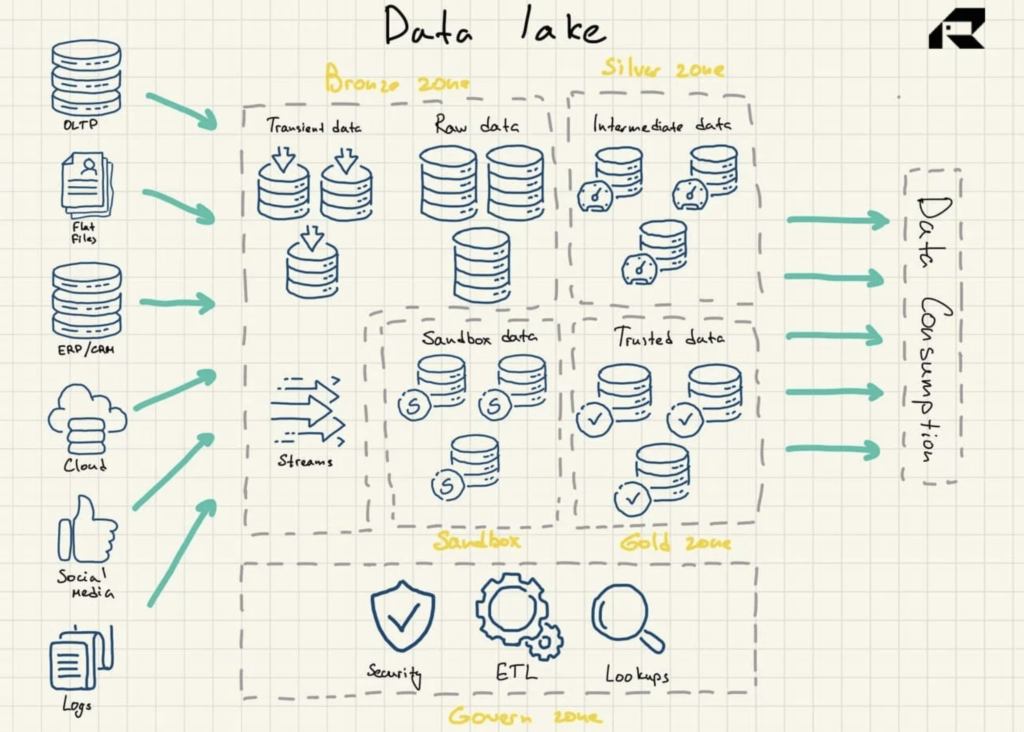
Data lake tidak secara inheren berisi kemampuan analitik. Tanpa mereka, mereka hanya menyimpan data mentah yang tidak berguna dengan sendirinya. Jadi, organisasi membangun gudang data atau memanfaatkan alat lain di atas danau data untuk menggunakan data.
Untuk memastikan data lake tidak berubah menjadi rawa data, penting untuk memiliki strategi pengelolaan data yang efisien untuk menyertakan tata kelola data bawaan dan manajemen metadata dalam desain data lake. Di dunia yang ideal, data yang ada di data lake harus dikatalogkan, diindeks, divalidasi, dan mudah tersedia bagi pengguna data. Ini jarang terjadi dan banyak proyek data lake gagal. Hal ini dapat dihindari: terlepas dari kematangan tim data, sangat penting untuk menginstal setidaknya kontrol penting untuk menegakkan validasi dan kualitas data.
Evolusi dan teknologi danau data
Munculnya data besar di awal 2000-an telah membawa peluang besar dan tantangan besar bagi organisasi. Bisnis membutuhkan teknologi baru untuk menganalisis kumpulan data yang besar, berantakan, dan tumbuh sangat cepat ini untuk menangkap dampak bisnis dari data besar.
Pada tahun 2008, Apache Hadoop hadir dengan teknologi open-source yang inovatif untuk mengumpulkan dan memproses data tidak terstruktur dalam skala besar, membuka jalan bagi analitik data besar dan data lake. Tak lama setelah itu, Apache Spark muncul. Itu lebih mudah digunakan. Selain itu, ini memberikan kemampuan untuk membangun dan melatih model ML, membuat kueri data terstruktur menggunakan SQL, dan memproses data waktu nyata.
Saat ini, data lake didominasi oleh repositori yang di-hosting-cloud. Semua penyedia cloud teratas seperti AWS, Azure, dan Google menawarkan data lake berbasis cloud dengan layanan penyimpanan objek yang hemat biaya. Platform mereka hadir dengan berbagai layanan manajemen data untuk mengotomatisasi penerapan. Dalam satu skenario, misalnya, data lake mungkin terdiri dari sistem penyimpanan data seperti Hadoop Distributed File System (HDFS) atau Amazon S3 yang terintegrasi dengan solusi gudang data cloud seperti Amazon Redshift. Komponen ini akan dipisahkan dari layanan dalam ekosistem yang mungkin mencakup Amazon EMR untuk pemrosesan data, Amazon Glue yang menyediakan katalog data dan fungsionalitas transformasi, layanan kueri Amazon Athena, atau Amazon Elasticsearch Service yang digunakan untuk membangun repositori metadata dan indeks data. Data lake lokal masih umum karena masalah cloud biasa seperti keamanan, privasi, atau latensi.

Ada juga vendor penyimpanan lokal yang menawarkan beberapa produk untuk data lake, namun penawaran data lake mereka tidak terdefinisi dengan baik. Tidak seperti gudang data, data lake tidak memiliki bertahun-tahun penerapan dunia nyata di belakangnya. Masih banyak kritik yang menggambarkan konsep data lake sebagai kabur dan tidak jelas. Kritikus juga berpendapat bahwa hanya sedikit orang di organisasi mana pun yang memiliki keterampilan (atau antusiasme dalam hal ini) untuk menjalankan beban kerja eksplorasi terhadap data mentah.
Gagasan bahwa data lake harus digunakan sebagai gudang pusat untuk semua data perusahaan perlu didekati dengan hati-hati, kata mereka. Ada juga pembicaraan provokatif bahwa hari-hari danau data diberi nomor. Alasan berikut dikutip:
- Data lake tidak dapat menskalakan sumber daya komputasi secara efisien sesuai permintaan (yah, ini karena mereka tidak dimaksudkan oleh desain sejak awal)
- Data lake membawa hutang teknologi yang besar, dengan penciptaannya terutama didorong oleh hype pemasaran, daripada alasan teknis (hal yang sama juga terjadi pada banyak gudang data)
- Dengan munculnya solusi gudang data cloud, data lake tidak lagi menawarkan manfaat biaya yang signifikan (masalah biaya tidak semudah itu karena sulit untuk memperkirakan biaya komputasi)
Kritik semacam itu adalah bagian yang tidak terpisahkan dari teknologi yang lebih muda. Namun, data lake memiliki kasus penggunaan yang jelas seperti analitik streaming. Dan dulu, mereka tidak mengancam gudang data. Pada titik tertentu, data lake bahkan mengalahkan gudang data, menawarkan kemampuan analitik yang lebih luas, efektivitas biaya, dan fleksibilitas dalam hal data yang disimpan. Namun, karena teknologi gudang data telah matang, banyak yang setuju bahwa tidak ada pemenang yang jelas sekarang. Biasanya disarankan untuk mempertahankan keduanya atau… menggunakan arsitektur hybrid. Baca terus.
Kasus penggunaan danau data
Ide utama tentang data lake adalah memberikan akses bisnis ke semua data yang tersedia dari semua sumber secepat mungkin. Data danau tidak hanya memberikan gambaran tentang apa yang terjadi kemarin. Menyimpan data dalam jumlah besar, data lake dirancang untuk memungkinkan organisasi mempelajari lebih lanjut tentang masa kini (menggunakan analitik streaming) dan masa depan (menggunakan solusi data besar, termasuk analitik prediktif dan pembelajaran mesin). Kasus penggunaan utama untuk data lake adalah:
- Memberi makan gudang data perusahaan dengan kumpulan data
- Melakukan analitik aliran
- Menerapkan proyek ML
- Membuat bagan analitik tingkat lanjut menggunakan alat BI perusahaan yang sudah lama ada seperti Tableau atau MS Power BI
- Membangun solusi analitik data khusus
- Menjalankan analisis akar masalah yang memungkinkan tim data melacak masalah hingga ke akarnya
Dengan keterampilan rekayasa data yang kuat untuk memindahkan data mentah ke lingkungan analitik, data lake bisa menjadi sangat relevan. Mereka memungkinkan tim untuk bereksperimen dengan data untuk memahami bagaimana hal itu dapat berguna. Ini mungkin melibatkan pembuatan model untuk menggali data dan mencoba skema yang berbeda untuk melihat data dengan cara baru. Data lake juga memungkinkan perselisihan dengan aliran data yang mengalir dari log web dan sensor IoT dan tidak cocok untuk pendekatan gudang data tradisional.
Singkatnya, data lake memungkinkan organisasi untuk menggali pola, mengantisipasi perubahan, atau menemukan peluang bisnis potensial seputar produk baru atau proses saat ini. Digunakan untuk kebutuhan bisnis yang berbeda, data lake dan data warehouse sering diimplementasikan secara bersamaan. Sebelum kita beralih ke konsep penyimpanan data berikutnya, mari kita rekap perbedaan utama antara gudang data dan danau data.
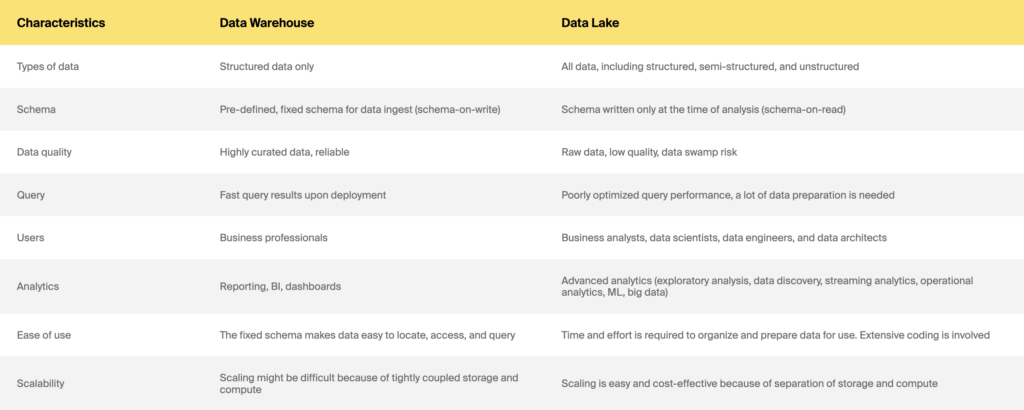
Gudang data vs. danau data
Bagaimana dengan arsitektur hybrid baru, data lakehouses?
Selain pemasaran, ide utama tentang data lakehouse adalah menghadirkan daya komputasi ke data lake. Secara arsitektural, data lakehouse biasanya terdiri dari:
- Lapisan penyimpanan untuk menyimpan data dalam format terbuka (misalnya, Parket). Lapisan ini bisa disebut danau data, dan dipisahkan dari lapisan komputasi
- Lapisan komputasi yang memberikan kemampuan gudang organisasi, mendukung manajemen metadata, pengindeksan, penegakan skema, dan transaksi ACID (Atomicity, Consistency, Reliability, and Durability)
- Lapisan API untuk mengakses aset data
- Melayani lapisan untuk mendukung berbagai beban kerja, mulai dari pelaporan hingga BI, ilmu data, atau pembelajaran mesin.
Gambar 3: Arsitektur Referensi Data Lakehouse
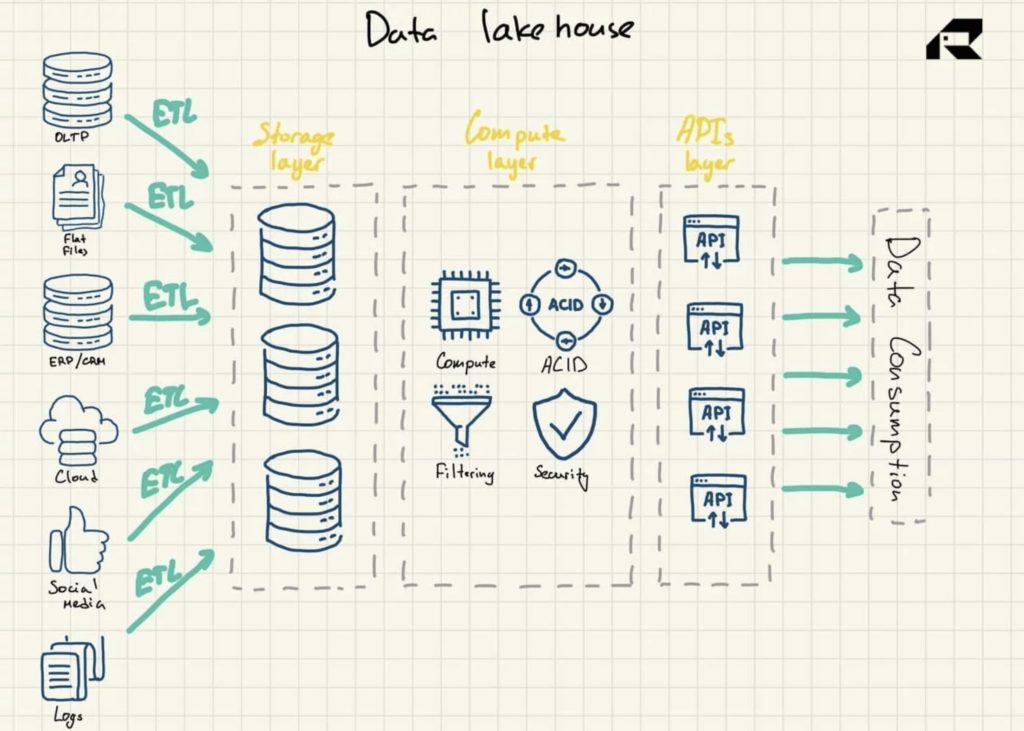
Disebut-sebut sebagai solusi yang menggabungkan yang terbaik dari kedua dunia, data lakehouse membahas keduanya:
- Kendala gudang data, termasuk kurangnya dukungan analitik data tingkat lanjut yang bergantung pada data terstruktur dan tidak terstruktur dan biaya penskalaan yang signifikan dengan gudang data tradisional yang tidak memisahkan penyimpanan dari sumber daya komputasi
- Tantangan data lake, termasuk duplikasi data, kualitas data, dan kebutuhan untuk mengakses beberapa sistem untuk berbagai tugas atau menerapkan integrasi kompleks dengan alat analitik
Data lakehouse adalah kemajuan baru dalam kancah analisis data. Konsep ini pertama kali digunakan pada tahun 2017 sehubungan dengan platform Snowflake. Pada tahun 2019, AWS menggunakan istilah data lakehouse untuk menggambarkan layanan Amazon Redshift Spectrum yang memungkinkan pengguna layanan gudang datanya Amazon Redshift untuk mencari melalui data yang disimpan di Amazon S3. Pada tahun 2020, istilah rumah danau data mulai digunakan secara luas, dengan Databricks mengadopsinya untuk platform Delta Lake-nya.
Data lakehouse mungkin memiliki masa depan yang cerah karena perusahaan di seluruh industri mengadopsi AI untuk meningkatkan operasi layanan, menawarkan produk dan layanan inovatif, atau mendorong kesuksesan pemasaran. Data terstruktur dari sistem operasional yang dikirimkan oleh gudang data tidak cocok untuk analitik cerdas, sementara data lake tidak dirancang untuk praktik tata kelola yang kuat, keamanan, atau kepatuhan ACID.
Data lake vs. data lakehouse
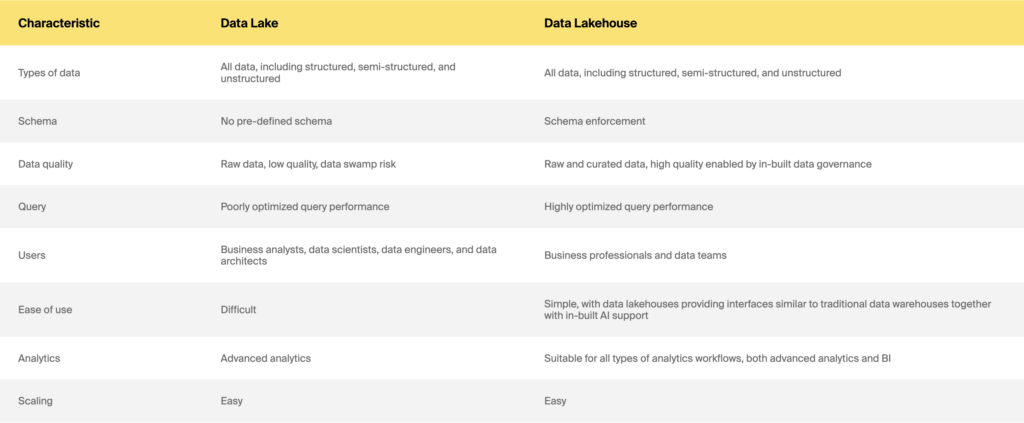
Jadi gudang data vs. data lake vs. data lakehouse: mana yang harus dipilih
Baik Anda ingin membangun solusi penyimpanan data dari awal atau memodernisasi sistem lawas Anda untuk mendukung ML atau meningkatkan kinerja, jawaban yang tepat tidak akan mudah. Masih ada banyak kekacauan tentang perbedaan utama, manfaat, dan biaya, dengan penawaran dan model penetapan harga dari vendor yang berkembang pesat. Selain itu, itu selalu merupakan proyek yang sulit bahkan jika Anda memiliki dukungan pemangku kepentingan. Namun, ada beberapa pertimbangan utama saat memilih gudang data vs. data lake vs. data lakehouse.
Pertanyaan utama yang harus Anda jawab adalah: MENGAPA. Hal yang baik untuk diingat di sini adalah bahwa perbedaan utama antara gudang data, danau, dan rumah danau tidak terletak pada teknologi. Mereka adalah tentang melayani kebutuhan bisnis yang berbeda. Jadi mengapa Anda membutuhkan solusi penyimpanan data? Apakah untuk pelaporan reguler, intelijen bisnis, analisis waktu nyata, ilmu data, atau analisis canggih lainnya? Apakah konsistensi data atau ketepatan waktu lebih penting untuk kebutuhan bisnis Anda? Luangkan waktu untuk mengembangkan kasus penggunaan. Kebutuhan analitik Anda harus didefinisikan dengan baik. Anda juga harus sangat memahami pengguna dan keahlian Anda. Beberapa aturan praktis adalah:
- Gudang data adalah taruhan yang bagus jika Anda memiliki pertanyaan yang tepat dan mengetahui hasil analitik apa yang ingin Anda dapatkan secara teratur.
- Jika Anda berada di industri yang sangat diatur seperti perawatan kesehatan atau asuransi, Anda mungkin harus mematuhi peraturan pelaporan yang ekstensif di atas segalanya. Jadi, gudang data akan menjadi pilihan yang lebih baik.
- Jika KPI dan persyaratan pelaporan Anda dapat diatasi dengan analisis historis sederhana, data lake atau solusi hibrida akan menjadi pekerjaan yang berlebihan. Pergi dengan gudang data sebagai gantinya.
- Jika tim data Anda menginginkan analisis eksperimental dan eksplorasi, pilih data lake atau solusi hibrida. Namun, Anda memerlukan keterampilan analisis data yang kuat untuk bekerja dengan data yang tidak terstruktur.
- Jika Anda adalah organisasi yang matang dengan data yang ingin memanfaatkan teknologi pembelajaran mesin, solusi hybrid atau data lake akan sangat cocok.
Pertimbangkan juga anggaran dan batasan waktu Anda. Data lake pasti lebih cepat dibangun daripada gudang data, dan mungkin lebih murah. Anda mungkin ingin menerapkan inisiatif Anda secara bertahap dan menambahkan kemampuan saat Anda meningkatkan skala. Jika Anda ingin memodernisasi sistem penyimpanan data lama Anda, sekali lagi, Anda harus bertanya MENGAPA Anda membutuhkan ini. Apakah terlalu lambat? Atau tidak memungkinkan Anda menjalankan kueri pada kumpulan data yang lebih besar? Apakah ada beberapa data yang hilang? Apakah Anda ingin mengeluarkan jenis analitik yang berbeda? Organisasi Anda telah menghabiskan banyak uang untuk sistem warisan, jadi Anda pasti membutuhkan kasus bisnis yang kuat untuk membuangnya. Ikat ke ROI juga. Arsitektur penyimpanan data masih matang. Tidak mungkin untuk mengatakan dengan pasti bagaimana mereka akan berkembang. Namun, tidak peduli jalan mana yang akan Anda ambil, akan berguna untuk mengenali jebakan umum dan memanfaatkan teknologi yang sudah ada di sini.
Kami harap artikel ini telah menghilangkan kebingungan tentang gudang data vs. data lake vs. data lakehouse. Jika Anda masih memiliki pertanyaan atau memerlukan keterampilan teknologi terbaik atau saran untuk membangun solusi penyimpanan data Anda, jangan lewatkan ITRex. Mereka akan membantu Anda.
Awalnya diterbitkan di https://itrexgroup.com pada 23 Februari 2022.