
我們如何使用深度技術和數據科學來個性化教育
已發表: 2016-01-29將技術融入 EdTech
考慮下圖。 想想你是怎麼長大的。 綠線可能是某人在生活中的實際潛力。 紅線是他們能夠完成的。 這是否反映了您早年的旅程? 這是否反映了您現在的旅程? 如果是這樣,你很有可能是在新興市場長大的。 像我這樣的。
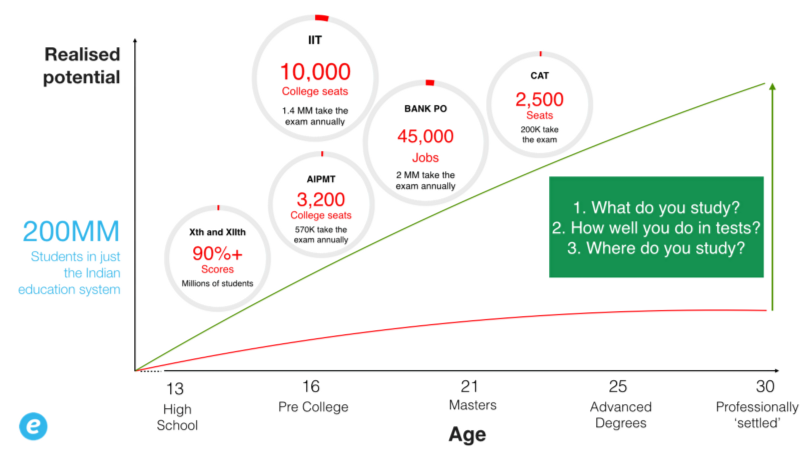
在印度等師生比例極低的國家,整個系統依靠一系列分數來評估一個人的職業潛力。 進入更好的學校和大學幾乎總是——完全取決於取得高分。 更好的學校和學院會自動確保更好的就業選擇。 在某些情況下,例如公共部門,這些分數也直接決定了獲得工作的機會。
因此,測試結果成為學習結果的代理,整個系統都在努力使測試分數最大化。 學習的樂趣在此過程中消失了。
獲得更好機會的關鍵與更好的教育有關。
獲得更好教育的鑰匙只是與一個數字相關聯。
讓我們舉個例子。 在選擇科目時,最多的印度父母希望他們的孩子學習工程學(23%)。 JEE(印度最難的工程考試)有一個篩選考試,150 萬學生在 180 分鐘內從大約 8,000 個概念中選出 90 多個問題,以清除截止分數。 在醫學、法律、管理、會計等領域也可以看到類似的動態。
匯豐銀行的一項研究表明,91% 的印度父母希望他們的孩子至少擁有本科或更高學位,88% 的父母希望他們獲得碩士學位甚至更高學位。 雖然中國支付額外補習費用的家長比例最大(74%),但印度(71%)和印度尼西亞(71%)緊隨其後。 因此,像 JEE 這樣的考試吸引每個學生每年大約 1000 美元的平均私人開支也就不足為奇了! (將其放在人均 GDP 為 1500 美元的背景下)。

人們會認為,在這種花費和緊迫感之後,學生將獲得相當好的教學水平和個性化指導。 家教行業的整個前提植根於著名的“Bloom's 2 sigma problem”,即“被輔導的學生平均在控制班學生的98%以上”。 問題是,在今天的印度——大多數教室都是這樣的——即使是在私人輔導模式中:

對於普通學生來說,獲得個性化反饋或指導的機會幾乎為零。 教師們特別將此類教室中的講座設計為單向互動,以確保大多數課程按時結束。 以確保在一天內可以將更多的“批次”擠進日程表中。 也有社會譴責反對提問。
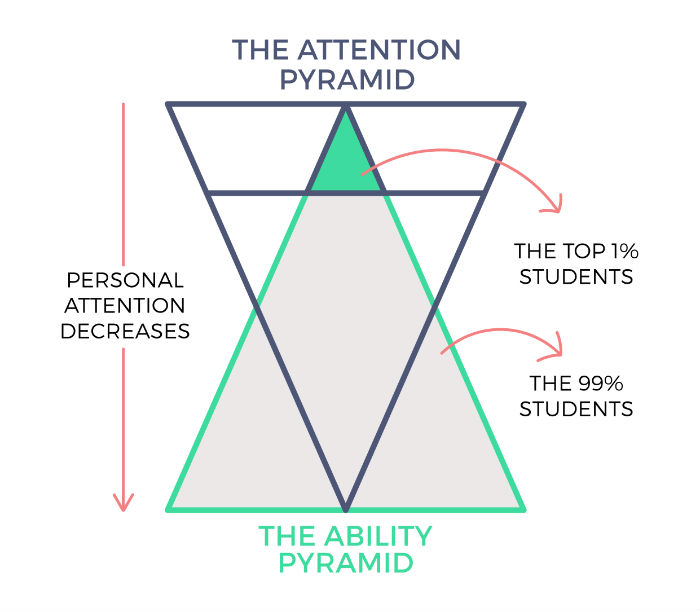
我最喜歡的說明我稱之為“注意力、能力和經濟悖論”的方式如下:
具有諷刺意味的是,如果我們將每個學生支付的錢疊加起來——看起來像這樣:
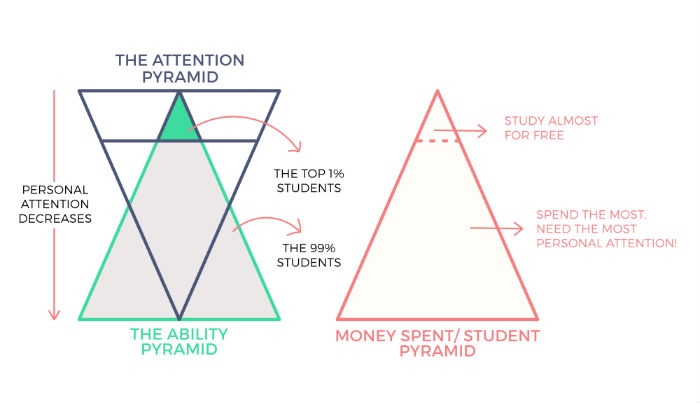
這是事情進一步走下坡路的地方。 最需要關注的學生是得到最少關注的學生。 事實上,他們開始在精神上檢查並留給自己的設備來解決動機、信心和其他行為問題。 所有這一切都在緊張的準備週期中。 更深層次的學術支持僅來自同行或訓練有素的代課教師,採用一對多的形式。
普通學生也將分數與自尊聯繫起來。 因為教育是這個國家真正的精英制度——很大一部分學生來自經濟拮据的背景。 父母花費他們的能力來幫助他們的孩子“得分更高”。 他們瘋狂地工作,試圖完全證明父母的花費和壓力。 甚至連一個分數都失去了,這讓情況變得更糟——例如,在 JEE 中,95% 的學生得分低於 30%,每個分數在功績名單上都相當於 10,000 個位置。 有時,這種壓力會導致令人心痛的悲劇。
這就是當今世界上人口最稠密國家的未來領導人追求教育的方式。 從一個數字來看,儘管學生幾乎是匿名的,但價值數十億美元的教育市場仍在蓬勃發展。 每年有 1500 萬新生兒出生,情況會如何好轉?
幸運的是,正如我在 embibe 的旅程中所意識到的那樣——深度技術和數據科學就是答案。 但首先,讓我們剝幾層洋蔥。
學習是一個連續體,但教育交付不是
直觀地說,很容易理解學習過程是一個連續的過程,每一層概念和每個年級都建立在以前級別的知識之上。
為你推薦:

反暴利條款對印度初創企業意味著什麼?

教育科技初創公司如何幫助印度的勞動力提高技能並為未來做好準備……

本週新時代科技股:Zomato 的麻煩仍在繼續,EaseMyTrip 發布強...

印度初創公司走捷徑尋求資金

數字營銷平台 Logicserve 獲得 80 盧比的資金,更名為 LS Dig...

報告警告對 Lendingtech Space 重新進行監管審查
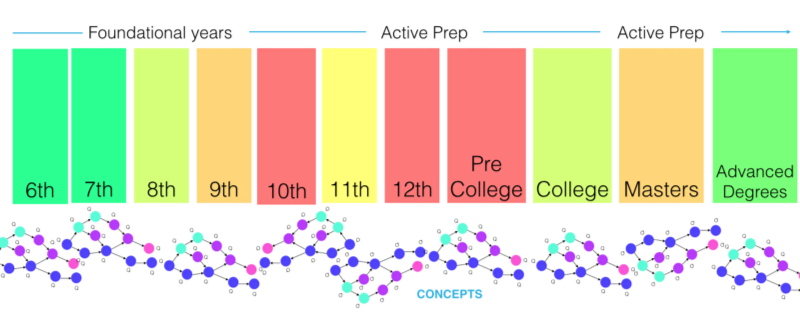
GPA 或基於百分比的年度學校評估讓位於標準化考試成績。 到了 10 年級,每個問題測試的平均概念從 1 增加到 3。死記硬背或最後一分鐘的死記硬背變得無效。 大學前考試準備的壓力越來越大——無論是美國的 SAT 還是印度的 JEE,中國的高考等等。大學後的樂趣仍在繼續,考試進一步決定就業結果,通常測試許多人對概念的理解幾年前。

因此,存在龐大的行業——在小範圍內解決特定的測試和等級問題。 其中一些(僅針對印度)如下所示。
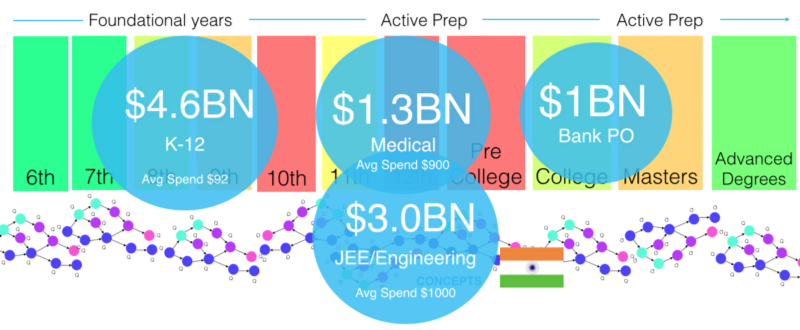
我的問題是這個行業的結構效率低下。 整個行業旨在適應教育交付的便利性,而不是最大限度地提高學生的成果。
通過這種分段的教育方式,學生從 5 歲到 30 歲的學習數據或信息沒有連續性。
我們的教育系統在結構上設計為不斷丟失和重新創建學生數據和上下文——這是解決技能問題的一種根本低效的方法,也是一種大規模的資源浪費。
在許多這樣的口袋裡,我聽到老師說: '如果你在九年級更努力學習,你的概念會在十一年級更清晰。 公共部門銀行見習官考試的量化能力以高中數學為基礎。 每個年級的及格分數平均為 35%——你幾乎可以忽略未來里程碑的關鍵組成部分,仍然通過課程。
如果沒有將跨年級和測試的學習聯繫起來的概念圖的細化和連續視圖,即使是最好的自適應學習解決方案也只能在其有限的內容允許的範圍內解決“局部最大值”。 該圖表還可以幫助教育企業有意義地解決流失這一古老的問題。
沒有任何東西可以不斷地推動學生如何——她今天學習的內容與未來的內容聯繫起來。
但是,技術可以改變這一切!
我學習了很多,但我不知道發生了什麼!
除了上面討論的連續性問題之外,新興市場的教育技術還必須解決第二個明顯的不匹配問題。 能力和實際分數之間的差異。
我們最近對學生失分的主要原因進行了一項小型調查。 前 5 個結果與學習無關:
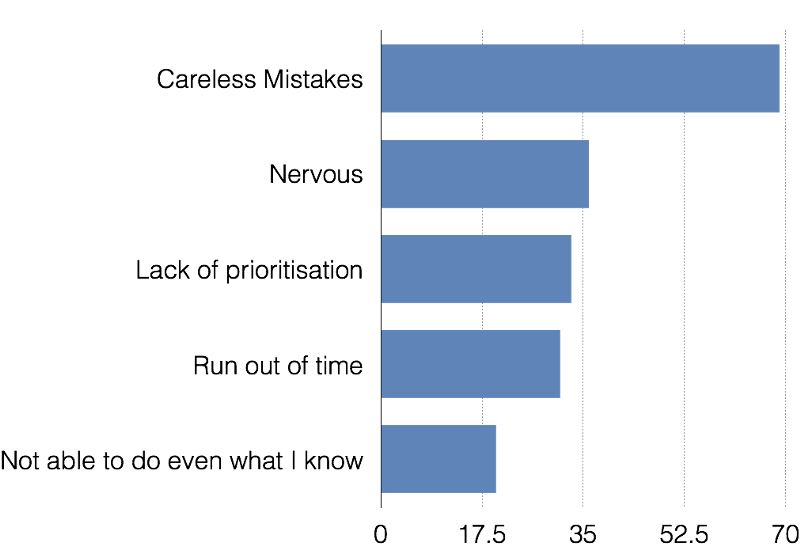
這意味著即使在學習之後——考試技巧和行為/信心等東西也成為實現分數的兩個最大槓桿。 問題是:如何控製或影響這些? 對於普通學生。 為大眾。
大問題——從零到一
我們後退一步,審視大型消費科技業務。 共同的主題非常有趣。 他們每個人都致力於以 10 倍的差異化方式和規模正確地解決一個問題。 對我們來說——教育技術的類比非常明確——個性化驅動的大規模學習成果。

三年前——embibe 開始了這段旅程。 對 Avichal Garg 的帖子“為什麼教育科技初創公司不成功”很感興趣,我們決心打造一款能夠真正影響新興市場學生表現的優質產品。 同時,確保供不應求的薪酬不足的教師不必承擔額外的工作量。
事實證明,通過讓學生詳細分析構成這些因素的參數,可以提高學術能力和考試技巧以及積極行為。
我們的研究提煉了超過 50 億條關於學生考試的見解,涉及 27 個參數。 這些參數可以預測和影響 93% 的分數。
這是 3 年多來與數百名教師交談、親自觀察數千次測試、分析 300 個城市的平台上數十萬小時的參與度的結果。
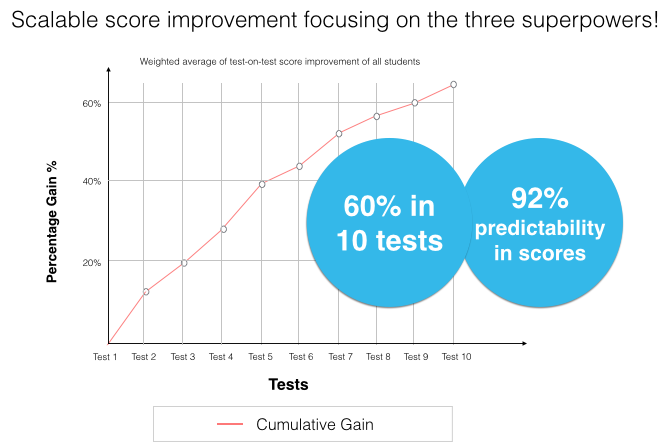
最棒的是這些參數是通用的,可以抽像到任何課程中。 我們的“教育基因組”——是來自科學和數學的極其密集的圖形概念。 它識別學生學習中字節大小的差距,並提供字節大小的學習來彌補它們。 該圖使學習成為超過 5 年教育的真正連續體,並且是我們自適應算法的支柱。

我們對行為和考試參數的關注也加快了分數的提高,而不是只關注學習。 短期的改進也是提高學生士氣的一大動力。 所有這些都導致對不耐煩的市場進行更深入的參與。
[vimeo 152049489 w=500 h=281]
此外,對該平台的投資確保了快速擴展以支持來自任何國家的任何課程的能力。 我們希望將來在教師、學生數據和個性化內容之間創建真正、有意義的融合。
新興市場仍然主要看到教育科技企業專注於在線構建內容。 相反,Embibe 正在為學生構建上下文以更有效地使用任何內容。 當賭注如此之高時,技術和數據科學在教育中的深度應用所產生的可能性會增加 10 倍。
我們很高興地宣布申請了首個為新興市場學生設計的個性化學習專利。 本文由 embibe 的首席數據科學家 Keyur Faldu 撰寫; 首席數據科學家,Achint Thomas 和我。 請繼續關注 embibe 令人興奮的數據科學實驗室等詳細信息。