
Las herramientas que su científico de datos necesita para ser eficaz
Publicado: 2022-04-28En publicaciones anteriores, hemos discutido cómo crear una hoja de ruta de ciencia de datos y determinar qué datos usará para ayudar a un científico de datos recién contratado a ponerse en marcha. Pero no es suficiente tener buenas ideas, datos y un científico de datos: el científico de datos necesita herramientas poderosas para hacer su trabajo de manera efectiva. En esta publicación, analizaremos los tipos de herramientas necesarias para que un científico de datos típico tenga éxito.
La capa de datos
Los productos de tecnología moderna pueden generar una gran cantidad de datos: secuencias de clics, telemetría, contenido generado por el usuario, como comentarios o reseñas, y puntos de contacto de la experiencia del cliente, por nombrar algunos. Es fundamental que estos datos se ubiquen, mapeen y, si es posible, se carguen en una única ubicación central. Este almacén de datos central es la capa de datos de su operación de ciencia de datos.
Almacenes de datos
Si la mayoría de sus datos se encuentran en bases de datos relacionales (o lo que a menudo se denomina bases de datos SQL), entonces una de las mejores y más fáciles cosas que puede hacer por su posible científico de datos es crear un almacén de datos .
Por lo general, los datos no se recopilan con el propósito expreso de "hacer ciencia de datos"; por ejemplo, un sitio de comercio electrónico recopila reseñas de clientes en una base de datos para que las reseñas se puedan mostrar en una página, no para que los científicos de datos puedan realizar un procesamiento de lenguaje natural para descubrir patrones en las reseñas. Esto significa que, aunque se recopilan las reseñas, su análisis es difícil y requiere mucho tiempo.
Un almacén de datos es una base de datos SQL que contiene todos los datos necesarios para el análisis y la inteligencia comercial en su organización. Si se diseñan correctamente, los almacenes de datos son rápidos de consultar, fáciles de escalar y contendrán todos los datos que su científico de datos necesita para alcanzar sus objetivos. Tener esto construido antes de traer a un científico de datos reducirá el tiempo perdido esperando el acceso a los datos o consultando bases de datos lentas.
Todos los principales proveedores de nube proporcionan algún tipo de tecnología de almacenamiento de datos, que es fácil de configurar y escalar. Amazon Web Services (AWS) proporciona Amazon Redshift y Redshift Spectrum, Google tiene Google BigQuery y Microsoft ofrece Azure SQL Data Warehouse.
Lagos de datos
Los almacenes de datos son poderosos y útiles siempre que sus datos se puedan cargar en una base de datos SQL. Sin embargo, esto no siempre es práctico. Muchas organizaciones tecnológicas modernas manejan datos que están semiestructurados o no estructurados, en cuyo caso puede ser bastante difícil cargarlos en un almacén de datos, que está construido inherentemente para datos estructurados. En este caso, quizás prefiramos comenzar con un Data Lake . Un lago de datos es un almacén de datos organizado que contiene todos los datos generados por su organización, generalmente en un formato sin procesar.
Para utilizar un lago de datos de manera efectiva, necesitará herramientas para realizar consultas y análisis a gran escala de los datos contenidos en el lago de datos. Las herramientas de consulta son parte integral de un almacén de datos, pero deberá elegir una herramienta de consulta para emparejar con su lago de datos. Tradicionalmente, esto se ha hecho con un marco llamado Apache Hadoop , un conjunto de herramientas de software para realizar cálculos programados o por lotes en enormes conjuntos de datos.
Otra herramienta común para consultar lagos de datos es Apache Spark, que permite a los científicos de datos trabajar de forma interactiva con grandes conjuntos de datos utilizando su lenguaje de programación preferido (python o R). Para comprender mejor cómo funcionan los lagos de datos, consulte esta infografía creada por G2 Crowd Learning Hub.
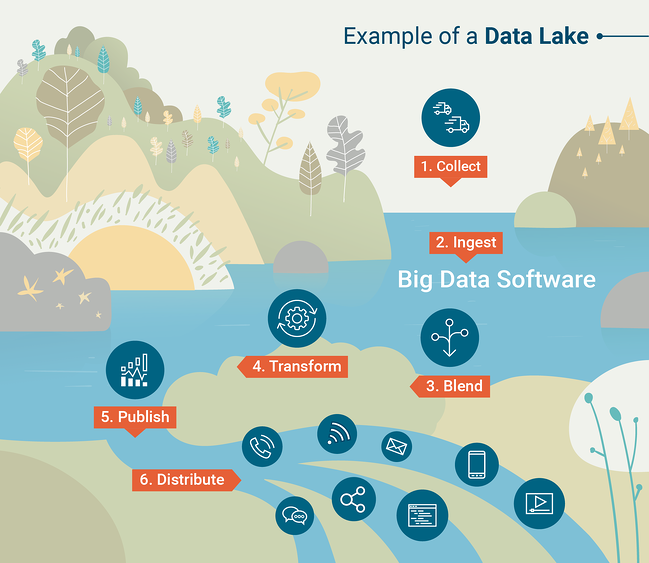
Fuente: Multitud G2
La capa de cómputo
Los científicos de datos hacen cosas diferentes en diferentes organizaciones, pero una constante es que necesitarán realizar algunos cálculos numéricos bastante pesados. Para hacer esto, un científico de datos requiere una computadora portátil potente y, según las funciones que realizará, es posible que necesite herramientas de cálculo adicionales. Las herramientas disponibles para el cálculo forman la capa de cálculo de su operación de ciencia de datos.

Para el trabajo diario
La productividad de su científico de datos se puede mejorar en gran medida al proporcionar equipos con una gran cantidad de potencia informática. Las herramientas típicas para el análisis de datos son R o Python con Jupyter Notebook, y estas herramientas dependen del almacenamiento de conjuntos de datos y la realización de cálculos en la memoria. Esto hace que sea común para un científico de datos maximizar la memoria de su computadora portátil, lo que resulta en un trabajo lento o incluso perdido. Para combatir este problema, elija la mayor cantidad de RAM posible cuando compre una computadora portátil para su científico de datos.
Herramientas informáticas para el aprendizaje automático
Las técnicas modernas de aprendizaje automático son asombrosamente buenas para hacer cosas como reconocer imágenes o rostros, procesar lenguaje natural y muchas más tareas que eran casi inimaginables para una computadora incluso hace unos años. Pero estos avances tienen un costo: la creación de modelos de aprendizaje automático requiere una potencia computacional inmensa, más de la que se puede encontrar en la mayoría de las computadoras portátiles.
Un avance importante es el desarrollo de la computación GPU (Unidad de procesamiento de gráficos) para el aprendizaje automático. Las GPU se diseñaron originalmente como herramientas para renderizar gráficos complejos de manera eficiente, liberando la CPU (Unidad central de procesamiento) para hacer otras cosas. Mientras que una CPU está diseñada para realizar tareas complejas una a la vez, las GPU están diseñadas para realizar miles de tareas muy simples a la vez. Este estilo de cálculo es perfecto para las matemáticas que utilizan el aprendizaje profundo y otros métodos complejos de aprendizaje automático. Los investigadores y desarrolladores de aprendizaje automático han aprendido a aprovechar la computación GPU para acelerar el proceso de creación de estos modelos.
Para aprovechar la computación GPU, necesita acceso a una computadora con una GPU discreta. Tradicionalmente, esto se encontraría en las computadoras para juegos, pero a medida que la computación con GPU ha ganado popularidad, las GPU discretas se han vuelto más disponibles en las computadoras profesionales de alta gama.
Computación en la nube
Para la mayoría de las organizaciones, mantener todo el trabajo de aprendizaje automático en la nube tiene muchas ventajas. Servicios como Google Cloud Platform, Amazon Web Services, Microsoft Azure y otros permiten a los usuarios alquilar una instancia virtual de una computadora bien equipada ubicada en uno de sus centros de datos. Se puede acceder a las instancias de la nube de forma segura desde cualquier computadora conectada a Internet, lo que significa que este enfoque no requiere que su científico de datos tenga una computadora portátil especializada. Hay algunas otras ventajas importantes de la computación en la nube.
La ventaja más obvia es la escalabilidad. Si necesita más poder de cómputo para un nuevo proyecto, los recursos adicionales se pueden ordenar instantáneamente al aumentar su pago mensual al servicio en la nube. Y los recursos se pueden reducir con la misma rapidez. Incluso puede optar por ejecutar varias instancias: una instancia de menor potencia para la informática diaria y una instancia de mayor potencia que solo se enciende para trabajos pesados. Esto es común, especialmente cuando se requiere computación GPU, ya que las instancias habilitadas para GPU tienden a ser más caras.
Otra ventaja es la seguridad de los datos. No es la mejor idea descargar datos a su computadora portátil personal para analizarlos, especialmente si esos datos son confidenciales. Usar el mismo proveedor de nube para almacenamiento y computación es una forma de mantener sus datos más seguros.
Colabore con su científico de datos
Desafortunadamente, es demasiado común que las organizaciones contraten a un científico de datos pero no les proporcionen las herramientas y el equipo necesarios para tener éxito.
Prepárese para escuchar a su nuevo científico de datos. Esto es especialmente cierto si está contratando a un científico de datos con experiencia en la realización de este tipo de trabajo a escala en otras empresas. Si no está seguro de qué herramientas necesitará para empoderar al científico de datos, prepárese para colaborar con él o ella en una hoja de ruta de ciencia de datos que incluya ideas, datos y recursos computacionales.