
Narzędzia, których potrzebuje Twój specjalista ds. danych, aby być skutecznym
Opublikowany: 2022-04-28W poprzednich postach omówiliśmy, jak zbudować mapę drogową nauki o danych i określić , których danych użyjesz, aby pomóc nowo zatrudnionym naukowcom danych rozpocząć pracę. Ale nie wystarczy mieć dobre pomysły, dane i naukowca danych: naukowiec potrzebuje potężnych narzędzi, aby skutecznie wykonywać swoją pracę. W tym poście omówimy rodzaje narzędzi wymaganych, aby typowy naukowiec danych odniósł sukces.
Warstwa danych
Nowoczesne produkty technologiczne mogą generować wiele danych: strumienie kliknięć, dane telemetryczne, treści generowane przez użytkowników, takie jak komentarze lub recenzje, oraz punkty styku z doświadczeniem klienta, żeby wymienić tylko kilka. Bardzo ważne jest, aby te dane były zlokalizowane, odwzorowane i, jeśli to możliwe, załadowane do jednej centralnej lokalizacji. Ten centralny magazyn danych jest warstwą danych operacji Data Science.
Magazyn danych
Jeśli większość Twoich danych znajduje się w relacyjnych bazach danych (lub tak często nazywanych bazami danych SQL), jedną z najłatwiejszych i najlepszych rzeczy, jakie możesz zrobić dla przyszłego naukowca danych, jest zbudowanie hurtowni danych .
Dane nie są zazwyczaj gromadzone w wyraźnym celu „badania danych”; na przykład witryna handlu elektronicznego gromadzi recenzje klientów w bazie danych, aby recenzje mogły być wyświetlane na stronie, a nie po to, aby naukowcy zajmujący się danymi mogli przetwarzać język naturalny w celu wykrycia wzorców w opiniach. Oznacza to, że chociaż opinie są zbierane, ich analiza jest trudna i czasochłonna.
Hurtownia danych to baza danych SQL, która zawiera wszystkie dane niezbędne do analiz i analizy biznesowej w Twojej organizacji. Prawidłowo zaprojektowane hurtownie danych są szybkie w zapytaniach, łatwe do skalowania i zawierają wszystkie dane, których potrzebuje specjalista ds. danych, aby osiągnąć założone cele. Zbudowanie tego przed zatrudnieniem Data Scientist zmniejszy czas marnowany na oczekiwanie na dostęp do danych lub wysyłanie zapytań do powolnych baz danych.
Wszyscy główni dostawcy usług w chmurze zapewniają pewien rodzaj technologii hurtowni danych, która jest łatwa do skonfigurowania i skalowania. Amazon Web Services (AWS) zapewnia Amazon Redshift i Redshift Spectrum, Google ma Google BigQuery , a Microsoft oferuje Azure SQL Data Warehouse.
Jeziora danych
Hurtownie danych są wydajne i przydatne, o ile dane można załadować do bazy danych SQL. Jednak nie zawsze jest to praktyczne. Wiele nowoczesnych organizacji technologicznych zajmuje się danymi, które są częściowo ustrukturyzowane lub nieustrukturyzowane. W takim przypadku załadowanie do hurtowni danych, która jest z natury zbudowana dla danych ustrukturyzowanych, może być dość trudne. W takim przypadku możemy woleć zacząć od Data Lake . Jezioro danych to zorganizowany magazyn danych, który zawiera wszystkie dane wygenerowane przez Twoją organizację, zwykle w formacie nieprzetworzonym.
Aby efektywnie wykorzystać Data Lake, będziesz potrzebować narzędzi do wykonywania zapytań na dużą skalę i analiz danych zawartych w Data Lake. Narzędzia do wysyłania zapytań są nieodłączną częścią hurtowni danych, ale musisz wybrać narzędzie do wysyłania zapytań do sparowania z jeziorem danych. Tradycyjnie robiono to za pomocą frameworka o nazwie Apache Hadoop , zestawu narzędzi programowych do wykonywania zaplanowanych lub wsadowych obliczeń na ogromnych zestawach danych.
Innym popularnym narzędziem do wykonywania zapytań dotyczących jezior danych jest Apache Spark, który umożliwia analitykom danych interaktywną pracę z dużymi zestawami danych przy użyciu preferowanego języka programowania (python lub R). Aby lepiej zrozumieć, jak działają jeziora danych, zapoznaj się z infografiką stworzoną przez G2 Crowd Learning Hub.
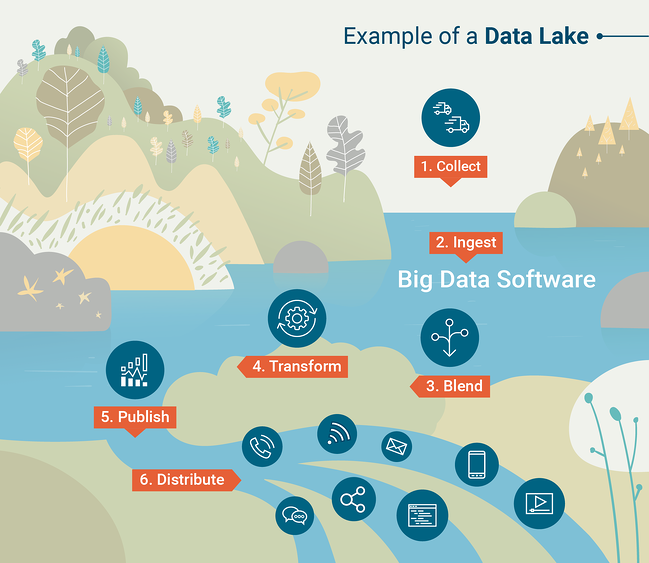
Źródło: G2 Crowd
Warstwa obliczeniowa
Naukowcy zajmujący się danymi robią różne rzeczy w różnych organizacjach, ale jedną stałą jest to, że będą musieli wykonać dość ciężkie przetwarzanie liczb. Aby to zrobić, analityk danych potrzebuje wydajnego laptopa, a w zależności od funkcji, które będą wykonywać, mogą potrzebować dodatkowych narzędzi obliczeniowych. Narzędzia udostępnione do obliczeń tworzą warstwę obliczeniową operacji analizy danych.

Do codziennej pracy
Wydajność Twojego analityka danych można znacznie zwiększyć, dostarczając sprzęt o dużej mocy obliczeniowej. Typowymi narzędziami do analizy danych są R lub Python z notatnikiem Jupyter, a narzędzia te zależą od przechowywania zestawów danych i wykonywania obliczeń w pamięci. To sprawia, że naukowcy zajmujący się danymi często maksymalizują pamięć swojego laptopa, co skutkuje spowolnieniem lub nawet utratą pracy. Aby rozwiązać ten problem, kupując laptopa dla swojego analityka danych, wybierz największą możliwą pamięć RAM.
Narzędzia komputerowe do uczenia maszynowego
Nowoczesne techniki uczenia maszynowego są zadziwiająco dobre w robieniu takich rzeczy, jak rozpoznawanie obrazów lub twarzy, przetwarzanie języka naturalnego i wiele innych zadań, które były prawie niewyobrażalne dla komputera nawet kilka lat temu. Ale te postępy mają swoją cenę: tworzenie modeli uczenia maszynowego wymaga ogromnej mocy obliczeniowej — większej niż w większości laptopów.
Jednym z ważnych postępów jest rozwój obliczeń GPU (Graphics Processing Unit) na potrzeby uczenia maszynowego. GPU zostały pierwotnie zaprojektowane jako narzędzia do wydajnego renderowania złożonej grafiki, uwalniając procesor (Central Processing Unit) do robienia innych rzeczy. Podczas gdy procesor jest przeznaczony do wykonywania złożonych zadań pojedynczo, procesory graficzne są zaprojektowane do wykonywania bardzo prostych zadań tysiące naraz. Ten styl obliczeń doskonale sprawdza się w matematyce wykorzystywanej przez głębokie uczenie i inne złożone metody uczenia maszynowego. Badacze i programiści zajmujący się uczeniem maszynowym nauczyli się wykorzystywać przetwarzanie GPU do przyspieszenia procesu budowania tych modeli.
Aby skorzystać z obliczeń GPU, potrzebujesz dostępu do komputera z oddzielnym GPU. Tradycyjnie można by to znaleźć w komputerach do gier, ale wraz ze wzrostem popularności obliczeń GPU, oddzielne procesory graficzne stały się szerzej dostępne w zaawansowanych komputerach profesjonalnych.
Chmura obliczeniowa
W przypadku większości organizacji istnieje wiele korzyści z faktycznego utrzymywania całego uczenia maszynowego w chmurze. Usługi takie jak Google Cloud Platform, Amazon Web Services, Microsoft Azure i inne pozwalają użytkownikom wynająć wirtualną instancję dobrze wyposażonego komputera znajdującego się w jednym z ich centrów danych. Dostęp do instancji w chmurze można bezpiecznie uzyskać z dowolnego komputera podłączonego do Internetu, co oznacza, że takie podejście nie wymaga posiadania przez analityka danych specjalistycznego laptopa. Istnieje kilka innych głównych zalet przetwarzania w chmurze.
Najbardziej oczywistą zaletą jest skalowalność. Jeśli potrzebujesz większej mocy obliczeniowej do nowego projektu, dodatkowe zasoby można natychmiast zebrać, zwiększając miesięczną opłatę za usługę w chmurze. A zasoby można równie szybko zmniejszyć. Możesz nawet zdecydować się na uruchomienie wielu instancji: instancję o niższej mocy do codziennego użytku i instancję o wyższej mocy, która jest włączana tylko do podnoszenia ciężkich przedmiotów. Jest to powszechne, zwłaszcza gdy wymagane jest przetwarzanie GPU, ponieważ instancje obsługujące GPU są zwykle droższe.
Kolejną zaletą jest bezpieczeństwo danych. Pobieranie danych na osobisty laptop w celu analizy nie jest najlepszym pomysłem, zwłaszcza jeśli są to dane wrażliwe. Korzystanie z tego samego dostawcy chmury do przechowywania i obliczeń to jeden ze sposobów na większe bezpieczeństwo danych.
Współpracuj ze swoim analitykiem danych
Niestety zbyt często zdarza się, że organizacje zatrudniają analityka danych, ale nie zapewniają im narzędzi i sprzętu niezbędnego do odniesienia sukcesu.
Przygotuj się na wysłuchanie swojego nowego naukowca ds. danych. Jest to szczególnie ważne, jeśli zatrudniasz doświadczonego analityka danych z doświadczeniem w wykonywaniu tego rodzaju prac na dużą skalę w innych firmach. Jeśli nie masz pewności, jakich narzędzi będziesz potrzebować, aby wzmocnić pozycję naukowca ds. danych, przygotuj się do współpracy z nim nad planem działania na rzecz nauki o danych, który zawiera pomysły, dane i zasoby obliczeniowe.