
您的数据科学家需要有效的工具
已发表: 2022-04-28在之前的文章中,我们讨论了如何构建数据科学路线图并确定您将使用哪些数据来帮助新聘用的数据科学家开始工作。 但仅仅拥有好的想法、数据和数据科学家是不够的:数据科学家需要强大的工具来有效地完成他们的工作。 在这篇文章中,我们将讨论典型数据科学家成功所需的工具类型。
数据层
现代技术产品可以生成大量数据:点击流、遥测、用户生成的内容(如评论或评论)以及客户体验接触点等等。 对这些数据进行定位、映射并在可能的情况下加载到单个中心位置至关重要。 这个中央数据存储是数据科学操作的数据层。
数据仓库
如果您的大部分数据存在于关系数据库(或通常称为 SQL 数据库)中,那么您可以为未来的数据科学家做的最简单和最好的事情之一就是构建数据仓库。
收集数据通常不是为了“做数据科学”的明确目的; 例如,电子商务网站将客户评论收集到数据库中,以便将评论显示在页面上,而不是让数据科学家执行自然语言处理以发现评论中的模式。 这意味着,尽管收集了评论,但分析起来既困难又耗时。
数据仓库是一个 SQL 数据库,其中包含组织中分析和商业智能所需的所有数据。 如果架构正确,数据仓库可以快速查询、易于扩展,并将包含数据科学家实现目标所需的所有数据。 在引入数据科学家之前构建它可以减少等待访问数据或查询慢速数据库所浪费的时间。
所有主要的云提供商都提供某种类型的数据仓库技术,这些技术易于设置和扩展。 Amazon Web Services (AWS)提供 Amazon Redshift 和 Redshift Spectrum,Google 提供Google BigQuery ,Microsoft 提供Azure SQL 数据仓库。
数据湖
只要您的数据可以加载到 SQL 数据库中,数据仓库就非常强大且有用。 然而,这并不总是实用的。 许多现代科技组织处理半结构化或非结构化的数据,在这种情况下,加载到数据仓库中可能会非常具有挑战性,而数据仓库本身就是为结构化数据构建的。 在这种情况下,我们可能更喜欢从Data Lake开始。 数据湖是一个有组织的数据存储,其中包含您的组织生成的所有数据,通常采用原始格式。
为了有效利用数据湖,您将需要工具来对数据湖中包含的数据执行大规模查询和分析。 查询工具是数据仓库的重要组成部分,但您需要选择一个查询工具来与您的数据湖配对。 传统上,这是通过称为Apache Hadoop的框架完成的,这是一组用于对大量数据执行计划或批量计算的软件工具。
查询数据湖的另一个常用工具是 Apache Spark,它允许数据科学家使用他们首选的编程语言(python 或 R)以交互方式处理大数据集。 为了更好地了解数据湖的工作原理,请查看 G2 Crowd Learning Hub 创建的此信息图。
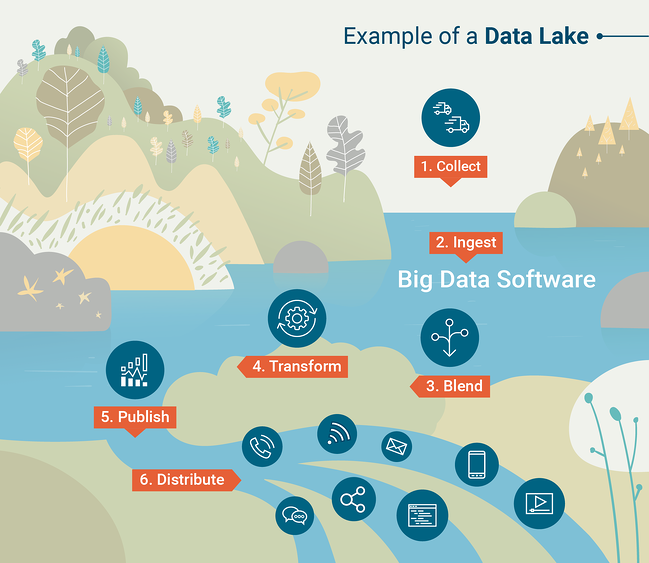
资料来源:G2 人群

计算层
数据科学家在不同的组织做不同的事情,但不变的一点是他们需要执行一些相当繁重的数字运算。 为此,数据科学家需要一台功能强大的笔记本电脑,并且根据他们将执行的功能,他们可能需要额外的计算工具。 可用于计算的工具构成了数据科学操作的计算层。
日常工作
通过提供具有大量计算能力的设备,可以大大提高您的数据科学家的工作效率。 用于数据分析的典型工具是带有 Jupyter notebook 的 R 或 Python,这些工具依赖于在内存中存储数据集和执行计算。 这使得数据科学家通常会最大限度地使用笔记本电脑的内存,从而导致工作缓慢甚至丢失。 为了解决这个问题,在为您的数据科学家购买笔记本电脑时选择尽可能多的 RAM。
机器学习计算工具
现代机器学习技术在处理图像或面部识别、自然语言处理以及更多甚至在几年前计算机几乎无法想象的任务方面表现出色。 但这些进步是有代价的:构建机器学习模型需要巨大的计算能力——比大多数笔记本电脑都多。
一项重要的进步是用于机器学习的 GPU(图形处理单元)计算的发展。 GPU 最初被设计为有效渲染复杂图形的工具,从而释放 CPU(中央处理单元)来做其他事情。 CPU 旨在一次执行一项复杂任务,而 GPU 旨在一次执行数千个非常简单的任务。 这种计算方式非常适合深度学习和其他复杂机器学习方法使用的数学。 机器学习研究人员和开发人员已经学会利用 GPU 计算来加速构建这些模型的过程。
要利用 GPU 计算,您需要使用具有独立 GPU 的计算机。 传统上,这将在游戏计算机中找到,但随着 GPU 计算的普及,离散 GPU 在高端专业计算机上变得更加广泛。
云计算
对于大多数组织而言,实际上将所有机器学习工作保留在云端有很多优势。 谷歌云平台、亚马逊网络服务、微软 Azure 等服务允许用户租用位于其数据中心的设备齐全的计算机的虚拟实例。 可以从任何连接到 Internet 的计算机安全地访问云实例,这意味着这种方法不需要您的数据科学家拥有专门的笔记本电脑。 云计算还有其他一些主要优势。
最明显的优势是可扩展性。 如果您需要为新项目提供更多计算能力,可以通过增加每月支付给云服务的费用来立即调集额外资源。 资源可以以同样快的速度缩减。 您甚至可以选择运行多个实例:用于日常计算的功率较低的实例,以及仅在繁重工作时才打开的功率较高的实例。 这很常见,尤其是在需要 GPU 计算时,因为启用 GPU 的实例往往更昂贵。
另一个优势是数据安全。 将数据下载到您的个人笔记本电脑进行分析并不是最好的主意,尤其是在这些数据很敏感的情况下。 使用相同的云提供商进行存储和计算是确保数据更安全的一种方法。
与您的数据科学家合作
不幸的是,组织会聘请数据科学家但未能为他们提供成功所需的工具和设备的情况太常见了。
准备好倾听您的新数据科学家的意见。 如果您正在聘请一位经验丰富的数据科学家,并在其他公司大规模从事此类工作,则尤其如此。 如果您不确定需要哪些工具来授权数据科学家,请准备好与他或她合作制定包含想法、数据和计算资源的数据科学路线图。