
Die Tools, die Ihr Data Scientist benötigt, um effektiv zu sein
Veröffentlicht: 2022-04-28In früheren Beiträgen haben wir besprochen, wie man eine Data-Science-Roadmap erstellt und festlegt, welche Daten Sie verwenden werden , um einem neu eingestellten Data Scientist zu helfen, durchzustarten. Aber es reicht nicht aus, gute Ideen, Daten und einen Data Scientist zu haben: Der Data Scientist braucht leistungsstarke Tools, um seine Arbeit effektiv zu erledigen. In diesem Beitrag werden wir die Arten von Tools besprechen, die ein typischer Data Scientist benötigt, um erfolgreich zu sein.
Die Datenschicht
Moderne Technologieprodukte können viele Daten generieren: Clickstreams, Telemetrie, nutzergenerierte Inhalte wie Kommentare oder Rezensionen und Touchpoints zur Kundenerfahrung, um nur einige zu nennen. Es ist entscheidend, dass diese Daten lokalisiert, kartiert und wenn möglich an einem einzigen zentralen Ort geladen werden. Dieser zentrale Datenspeicher ist die Datenschicht Ihres Data-Science-Betriebs.
Data Warehouse
Wenn der Großteil Ihrer Daten in relationalen Datenbanken (oder sogenannten SQL-Datenbanken) vorhanden ist, ist das Erstellen eines Data Warehouse eine der einfachsten und besten Aufgaben für Ihren angehenden Data Scientist .
Daten werden in der Regel nicht für den ausdrücklichen Zweck der „Datenwissenschaft“ erhoben; Beispielsweise sammelt eine E-Commerce-Website Kundenbewertungen in einer Datenbank, damit die Bewertungen auf einer Seite angezeigt werden können, nicht damit Data Scientists eine natürliche Sprachverarbeitung durchführen können, um Muster in den Bewertungen zu entdecken. Dies bedeutet, dass die Bewertungen zwar gesammelt werden, aber schwierig und zeitaufwändig zu analysieren sind.
Ein Data Warehouse ist eine SQL-Datenbank, die alle Daten enthält, die für Analysen und Business Intelligence in Ihrem Unternehmen erforderlich sind. Bei richtiger Architektur sind Data Warehouses schnell abzufragen, einfach zu skalieren und enthalten alle Daten, die Ihr Data Scientist benötigt, um Ihre Ziele zu erreichen. Wenn Sie dies vor dem Hinzuziehen eines Datenwissenschaftlers erstellen, wird die Zeit, die mit dem Warten auf den Zugriff auf Daten oder dem Abfragen langsamer Datenbanken verschwendet wird, reduziert.
Alle großen Cloud-Anbieter bieten irgendeine Art von Data-Warehouse-Technologie an, die einfach einzurichten und zu skalieren ist. Amazon Web Services (AWS) bietet Amazon Redshift und Redshift Spectrum, Google hat Google BigQuery und Microsoft bietet Azure SQL Data Warehouse an.
Datenseen
Data Warehouses sind leistungsstark und nützlich, solange Ihre Daten in eine SQL-Datenbank geladen werden können. Dies ist jedoch nicht immer praktikabel. Viele moderne Technologieunternehmen arbeiten mit halbstrukturierten oder unstrukturierten Daten. In diesem Fall kann es ziemlich schwierig sein, sie in ein Data Warehouse zu laden, das von Natur aus für strukturierte Daten ausgelegt ist. In diesem Fall ziehen wir es vielleicht vor, mit einem Data Lake zu beginnen . Ein Data Lake ist ein organisierter Datenspeicher, der alle von Ihrer Organisation generierten Daten enthält, normalerweise in einem Rohformat.
Um einen Data Lake effektiv zu nutzen, benötigen Sie Tools, um umfangreiche Abfragen und Analysen der im Data Lake enthaltenen Daten durchzuführen. Abfragetools sind fester Bestandteil eines Data Warehouse, aber Sie müssen ein Abfragetool auswählen, das mit Ihrem Data Lake gekoppelt werden soll. Traditionell wurde dies mit einem Framework namens Apache Hadoop durchgeführt , einer Reihe von Softwaretools zur Durchführung geplanter oder Batch-Berechnungen mit enormen Datenmengen.
Ein weiteres gängiges Tool zum Abfragen von Data Lakes ist Apache Spark, das es Data Scientists ermöglicht, interaktiv mit großen Datensätzen zu arbeiten, indem sie ihre bevorzugte Programmiersprache (Python oder R) verwenden. Um besser zu verstehen, wie Data Lakes funktionieren, sehen Sie sich diese Infografik an, die vom G2 Crowd Learning Hub erstellt wurde.
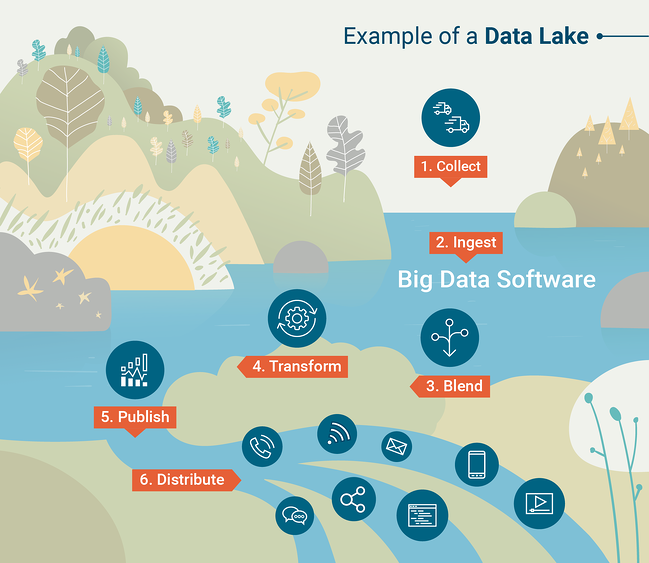
Quelle: G2 Crowd
Die Rechenschicht
Datenwissenschaftler machen in verschiedenen Organisationen unterschiedliche Dinge, aber eine Konstante ist, dass sie einige ziemlich schwere Zahlen knacken müssen. Dazu benötigt ein Datenwissenschaftler einen leistungsstarken Laptop, und je nach auszuführenden Funktionen benötigt er möglicherweise zusätzliche Berechnungstools. Die für die Berechnung bereitgestellten Tools bilden die Berechnungsschicht Ihres Data-Science-Vorgangs.

Für die tägliche Arbeit
Die Produktivität Ihres Datenwissenschaftlers kann erheblich verbessert werden, indem Geräte mit einer großen Menge an Rechenleistung bereitgestellt werden. Typische Tools für die Datenanalyse sind R oder Python mit Jupyter-Notebook, und diese Tools sind darauf angewiesen, Datensätze zu speichern und Berechnungen im Arbeitsspeicher durchzuführen. Daher ist es üblich, dass ein Data Scientist den Arbeitsspeicher seines Laptops voll ausschöpft, was zu langsamer oder sogar verlorener Arbeit führt. Um dieses Problem zu bekämpfen, wählen Sie beim Kauf eines Laptops für Ihren Data Scientist so viel RAM wie möglich.
Computerwerkzeuge für maschinelles Lernen
Moderne maschinelle Lerntechniken sind erstaunlich gut darin, Dinge wie das Erkennen von Bildern oder Gesichtern, die Verarbeitung natürlicher Sprache und viele weitere Aufgaben zu erledigen, die für einen Computer noch vor wenigen Jahren fast undenkbar waren. Diese Fortschritte haben jedoch ihren Preis: Das Erstellen von Modellen für maschinelles Lernen erfordert eine immense Rechenleistung – mehr als in den meisten Laptops zu finden ist.
Ein wichtiger Fortschritt ist die Entwicklung von GPU (Graphics Processing Unit)-Computing für maschinelles Lernen. GPUs wurden ursprünglich als Werkzeuge zum effizienten Rendern komplexer Grafiken entwickelt, wodurch die CPU (Central Processing Unit) für andere Dinge frei wird. Während eine CPU darauf ausgelegt ist, komplexe Aufgaben einzeln auszuführen, sind GPUs darauf ausgelegt, sehr einfache Aufgaben zu Tausenden gleichzeitig auszuführen. Diese Art der Berechnung ist perfekt für die Mathematik, die Deep Learning und andere komplexe maschinelle Lernmethoden verwenden. Forscher und Entwickler des maschinellen Lernens haben gelernt, GPU-Computing zu nutzen, um den Prozess der Erstellung dieser Modelle zu beschleunigen.
Um GPU-Computing nutzen zu können, benötigen Sie Zugriff auf einen Computer mit separater GPU. Traditionell war dies in Gaming-Computern zu finden, aber mit zunehmender Popularität von GPU-Computing sind diskrete GPUs auf professionellen High-End-Computern immer häufiger verfügbar.
Cloud Computing
Für die meisten Unternehmen bietet es viele Vorteile, die gesamte maschinelle Lernarbeit in der Cloud zu belassen. Dienste wie Google Cloud Platform, Amazon Web Services, Microsoft Azure und andere ermöglichen es Benutzern, eine virtuelle Instanz eines gut ausgestatteten Computers zu mieten, der sich in einem ihrer Rechenzentren befindet. Auf die Cloud-Instanzen kann sicher von jedem mit dem Internet verbundenen Computer aus zugegriffen werden, was bedeutet, dass Ihr Data Scientist für diesen Ansatz keinen speziellen Laptop benötigt. Es gibt noch ein paar andere große Vorteile von Cloud Computing.
Der offensichtlichste Vorteil ist die Skalierbarkeit. Wenn Sie mehr Rechenleistung für ein neues Projekt benötigen, können zusätzliche Ressourcen sofort bereitgestellt werden, indem Sie Ihre monatliche Zahlung an den Cloud-Service erhöhen. Und ebenso schnell lassen sich Ressourcen wieder herunterskalieren. Sie können sogar mehrere Instanzen ausführen: eine Instanz mit geringerer Leistung für die tägliche Datenverarbeitung und eine Instanz mit höherer Leistung, die nur für schweres Heben eingeschaltet ist. Dies ist vor allem dann üblich, wenn GPU-Computing erforderlich ist, da GPU-fähige Instanzen tendenziell teurer sind.
Ein weiterer Vorteil ist die Datensicherheit. Es ist nicht die beste Idee, Daten zur Analyse auf Ihren persönlichen Laptop herunterzuladen, insbesondere wenn diese Daten vertraulich sind. Die Verwendung desselben Cloud-Anbieters für Speicherung und Berechnung ist eine Möglichkeit, Ihre Daten sicherer zu halten.
Arbeiten Sie mit Ihrem Data Scientist zusammen
Leider kommt es allzu häufig vor, dass Unternehmen einen Datenwissenschaftler einstellen, ihm aber nicht die Werkzeuge und Geräte zur Verfügung stellen, die für den Erfolg erforderlich sind.
Seien Sie darauf vorbereitet, Ihrem neuen Data Scientist zuzuhören. Dies gilt insbesondere, wenn Sie einen erfahrenen Data Scientist einstellen, der Erfahrung mit dieser Art von Arbeit in großem Maßstab bei anderen Unternehmen hat. Wenn Sie sich nicht sicher sind, welche Tools Sie benötigen, um den Data Scientist zu befähigen, bereiten Sie sich darauf vor, mit ihm oder ihr an einer Data Science-Roadmap zusammenzuarbeiten, die Ideen, Daten und Rechenressourcen enthält.