
Les outils dont votre data scientist a besoin pour être efficace
Publié: 2022-04-28Dans les articles précédents, nous avons expliqué comment créer une feuille de route pour la science des données et déterminer quelles données vous utiliserez pour aider un scientifique des données nouvellement embauché à démarrer. Mais il ne suffit pas d'avoir de bonnes idées, des données et un data scientist : le data scientist a besoin d'outils puissants pour faire son travail efficacement. Dans cet article, nous discuterons des types d'outils requis pour qu'un data scientist typique réussisse.
La couche de données
Les produits technologiques modernes peuvent générer de nombreuses données : flux de clics, télémétrie, contenu généré par les utilisateurs, comme les commentaires ou les avis, et points de contact de l'expérience client, pour n'en nommer que quelques-uns. Il est essentiel que ces données soient localisées, cartographiées et, si possible, chargées dans un emplacement central unique. Ce magasin de données central est la couche de données de votre opération Data Science.
Entrepôts de données
Si la majorité de vos données existent dans des bases de données relationnelles (ou ce que l'on appelle souvent des bases de données SQL), l'une des choses les plus simples et les meilleures que vous puissiez faire pour votre futur Data Scientist est de créer un entrepôt de données .
Les données ne sont généralement pas collectées dans le but exprès de « faire de la science des données » ; par exemple, un site de commerce électronique collecte les avis des clients dans une base de données afin que les avis puissent être affichés sur une page, et non pour que les Data Scientists puissent effectuer un traitement du langage naturel pour découvrir des modèles dans les avis. Cela signifie que, bien que les avis soient collectés, ils sont difficiles et longs à analyser.
Un entrepôt de données est une base de données SQL qui contient toutes les données nécessaires à l'analyse et à l'informatique décisionnelle dans votre organisation. S'ils sont correctement architecturés, les entrepôts de données sont rapides à interroger, faciles à mettre à l'échelle et contiendront toutes les données dont votre Data Scientist a besoin pour atteindre vos objectifs. L' avoir construit avant de faire appel à un Data Scientist réduira le temps perdu à attendre l'accès aux données ou à interroger des bases de données lentes.
Tous les principaux fournisseurs de cloud proposent un type de technologie d'entrepôt de données, facile à configurer et à faire évoluer. Amazon Web Services (AWS) fournit Amazon Redshift et Redshift Spectrum, Google a Google BigQuery et Microsoft propose Azure SQL Data Warehouse.
Lacs de données
Les entrepôts de données sont puissants et utiles tant que vos données peuvent être chargées dans une base de données SQL. Cependant, ce n'est pas toujours pratique. De nombreuses organisations technologiques modernes traitent des données semi-structurées ou non structurées, auquel cas il peut être assez difficile de les charger dans un entrepôt de données, qui est intrinsèquement conçu pour les données structurées. Dans ce cas, nous pourrions préférer commencer avec un Data Lake . Un lac de données est un magasin de données organisé qui contient toutes les données générées par votre organisation, généralement dans un format brut.
Pour utiliser efficacement un lac de données, vous aurez besoin d'outils pour effectuer des requêtes et des analyses à grande échelle sur les données contenues dans le lac de données. Les outils d'interrogation font partie intégrante d'un entrepôt de données, mais vous devrez choisir un outil d'interrogation à coupler avec votre lac de données. Traditionnellement, cela se faisait avec un cadre appelé Apache Hadoop , un ensemble d'outils logiciels permettant d'effectuer des calculs planifiés ou par lots sur d'énormes ensembles de données.
Un autre outil courant pour interroger les lacs de données est Apache Spark, qui permet aux scientifiques de données de travailler de manière interactive avec de grands ensembles de données en utilisant leur langage de programmation préféré (python ou R). Pour mieux comprendre le fonctionnement des lacs de données, consultez cette infographie créée par G2 Crowd Learning Hub.
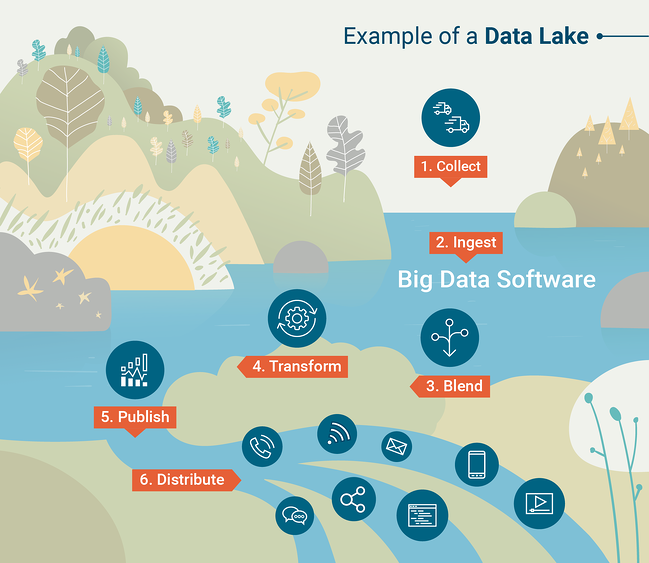
Source : Foule G2
La couche de calcul
Les Data Scientists font des choses différentes dans différentes organisations, mais une constante est qu'ils devront effectuer des calculs assez lourds. Pour ce faire, un data scientist a besoin d'un ordinateur portable puissant, et selon les fonctions qu'il va remplir, il peut avoir besoin d'outils de calcul supplémentaires. Les outils mis à disposition pour le calcul forment la couche de calcul de votre opération de science des données.

Pour le travail au quotidien
La productivité de votre Data Scientist peut être grandement améliorée en dotant un équipement d'une grande puissance de calcul. Les outils typiques d'analyse de données sont R ou Python avec le bloc-notes Jupyter, et ces outils dépendent du stockage des ensembles de données et de l'exécution de calculs en mémoire. Il est donc courant pour un Data Scientist de maximiser la mémoire de son ordinateur portable, ce qui entraîne un travail lent, voire perdu. Pour lutter contre ce problème, choisissez le plus de RAM possible lors de l'achat d'un ordinateur portable pour votre data scientist.
Outils informatiques pour l'apprentissage automatique
Les techniques modernes d'apprentissage automatique sont étonnamment efficaces pour faire des choses comme la reconnaissance d'images ou de visages, le traitement du langage naturel et bien d'autres tâches qui étaient presque inimaginables pour un ordinateur il y a encore quelques années. Mais ces avancées ont un coût : la création de modèles d'apprentissage automatique nécessite une puissance de calcul immense, supérieure à celle de la plupart des ordinateurs portables.
Une avancée importante est le développement de l'informatique GPU (unité de traitement graphique) pour l'apprentissage automatique. Les GPU ont été conçus à l'origine comme des outils pour rendre efficacement des graphiques complexes, libérant ainsi le CPU (Central Processing Unit) pour faire d'autres choses. Alors qu'un processeur est conçu pour effectuer des tâches complexes une par une, les GPU sont conçus pour effectuer des milliers de tâches très simples à la fois. Ce style de calcul est parfait pour les mathématiques utilisées par l'apprentissage en profondeur et d'autres méthodes complexes d'apprentissage automatique. Les chercheurs et les développeurs en apprentissage automatique ont appris à exploiter l'informatique GPU pour accélérer le processus de construction de ces modèles.
Pour tirer parti de l'informatique GPU, vous devez avoir accès à un ordinateur doté d'un GPU discret. Traditionnellement, cela se trouvait dans les ordinateurs de jeu, mais à mesure que l'informatique GPU a gagné en popularité, les GPU discrets sont devenus plus largement disponibles sur les ordinateurs professionnels haut de gamme.
Cloud computing
Pour la plupart des organisations, il y a de nombreux avantages à conserver tout le travail d'apprentissage automatique sur le cloud. Des services tels que Google Cloud Platform, Amazon Web Services, Microsoft Azure et d'autres permettent aux utilisateurs de louer une instance virtuelle d'un ordinateur bien équipé situé dans l'un de leurs centres de données. Les instances cloud sont accessibles en toute sécurité depuis n'importe quel ordinateur connecté à Internet, ce qui signifie que cette approche ne nécessite pas que votre Data Scientist dispose d'un ordinateur portable spécialisé. Il existe quelques autres avantages majeurs du cloud computing.
L'avantage le plus évident est l'évolutivité. Si vous avez besoin de plus de puissance de calcul pour un nouveau projet, des ressources supplémentaires peuvent être mobilisées instantanément en augmentant votre paiement mensuel au service cloud. Et les ressources peuvent être réduites tout aussi rapidement. Vous pouvez même choisir d'exécuter plusieurs instances : une instance moins puissante pour l'informatique au jour le jour et une instance plus puissante qui n'est activée que pour les gros travaux. Ceci est courant, en particulier lorsque le calcul GPU est requis, car les instances compatibles GPU ont tendance à être plus chères.
Un autre avantage est la sécurité des données. Ce n'est pas la meilleure idée de télécharger des données sur votre ordinateur portable personnel pour analyse, surtout si ces données sont sensibles. Utiliser le même fournisseur de cloud pour le stockage et le calcul est un moyen de sécuriser davantage vos données.
Collaborez avec votre Data Scientist
Il est malheureusement trop courant que les organisations embauchent un data scientist mais ne leur fournissent pas les outils et l'équipement nécessaires pour réussir.
Soyez prêt à écouter votre nouveau Data Scientist. Cela est particulièrement vrai si vous embauchez un Data Scientist chevronné ayant de l'expérience dans ce type de travail à grande échelle dans d'autres entreprises. Si vous n'êtes pas sûr des outils dont vous aurez besoin pour responsabiliser le scientifique des données, préparez-vous à collaborer avec lui sur une feuille de route de la science des données qui comprend des idées, des données et des ressources informatiques.