
เครื่องมือที่นักวิทยาศาสตร์ข้อมูลของคุณจำเป็นต้องมีประสิทธิภาพ
เผยแพร่แล้ว: 2022-04-28ในโพสต์ก่อนหน้านี้ เราได้พูดถึงวิธี สร้างแผนงานด้านวิทยาศาสตร์ข้อมูล และกำหนด ข้อมูลที่คุณจะใช้ เพื่อช่วยให้นักวิทยาศาสตร์ข้อมูลที่เพิ่งได้รับการว่าจ้างใหม่เริ่มดำเนินการได้ แต่การมีแนวคิด ข้อมูล และนักวิทยาศาสตร์ข้อมูลที่ดีนั้นไม่เพียงพอ นักวิทยาศาสตร์ข้อมูลต้องการเครื่องมือที่ทรงพลังเพื่อทำงานอย่างมีประสิทธิภาพ ในโพสต์นี้ เราจะพูดถึงประเภทของเครื่องมือที่จำเป็นสำหรับนักวิทยาศาสตร์ข้อมูลทั่วไปในการประสบความสำเร็จ
ชั้นข้อมูล
ผลิตภัณฑ์เทคโนโลยีสมัยใหม่สามารถสร้างข้อมูลได้มากมาย เช่น คลิกสตรีม การวัดและส่งข้อมูลทางไกล เนื้อหาที่ผู้ใช้สร้างขึ้น เช่น ความคิดเห็นหรือบทวิจารณ์ และจุดสัมผัสประสบการณ์ลูกค้า เป็นต้น จำเป็นอย่างยิ่งที่จะต้องระบุตำแหน่ง จัดทำแผนที่ และโหลดลงในตำแหน่งศูนย์กลางแห่งเดียวหากเป็นไปได้ ที่เก็บข้อมูลส่วนกลางนี้คือชั้นข้อมูลของการดำเนินงานด้าน Data Science ของคุณ
คลังข้อมูล
หากข้อมูลส่วนใหญ่ของคุณมีอยู่ในฐานข้อมูลเชิงสัมพันธ์ (หรือที่มักเรียกว่าฐานข้อมูล SQL) สิ่งหนึ่งที่ง่ายและดีที่สุดที่คุณสามารถทำได้สำหรับผู้มุ่งหวัง Data Scientist คือการสร้าง Data Warehouse
โดยทั่วไปแล้ว ข้อมูลจะไม่ถูกเก็บรวบรวมเพื่อจุดประสงค์ที่ชัดเจนในการ "ทำวิทยาศาสตร์ข้อมูล"; ตัวอย่างเช่น ไซต์อีคอมเมิร์ซรวบรวมบทวิจารณ์ของลูกค้าในฐานข้อมูลเพื่อให้สามารถแสดงบทวิจารณ์บนหน้าเว็บ ไม่ใช่เพื่อให้นักวิทยาศาสตร์ข้อมูลสามารถดำเนินการประมวลผลภาษาธรรมชาติเพื่อค้นหารูปแบบในบทวิจารณ์ ซึ่งหมายความว่าถึงแม้จะรวบรวมบทวิจารณ์ แต่ก็ยากและใช้เวลานานในการวิเคราะห์
คลังข้อมูลคือฐานข้อมูล SQL ที่มีข้อมูลทั้งหมดที่จำเป็นสำหรับการวิเคราะห์และระบบธุรกิจอัจฉริยะในองค์กรของคุณ หากออกแบบสถาปัตยกรรมอย่างถูกต้อง คลังข้อมูลสามารถสืบค้นได้อย่างรวดเร็ว ปรับขนาดได้ง่าย และจะมีข้อมูลทั้งหมดที่ Data Scientist ของคุณต้องการเพื่อให้เป็นไปตามวัตถุประสงค์ของคุณ การมีสิ่งนี้สร้างขึ้น ก่อนที่จะ นำ Data Scientist เข้ามาจะช่วยลดเวลาที่เสียไปในการรอการเข้าถึงข้อมูลหรือการสืบค้นฐานข้อมูลที่ช้า
ผู้ให้บริการระบบคลาวด์รายใหญ่ทั้งหมดมีเทคโนโลยีคลังข้อมูลบางประเภท ซึ่งง่ายต่อการติดตั้งและปรับขนาด Amazon Web Services (AWS) ให้บริการ Amazon Redshift และ Redshift Spectrum, Google มี Google BigQuery และ Microsoft เสนอ Azure SQL Data Warehouse
Data Lakes
คลังข้อมูลมีประสิทธิภาพและมีประโยชน์ตราบเท่าที่ข้อมูลของคุณสามารถโหลดลงในฐานข้อมูล SQL ได้ อย่างไรก็ตาม วิธีนี้ใช้ไม่ได้ผลเสมอไป องค์กรเทคโนโลยีสมัยใหม่หลายแห่งจัดการกับข้อมูลที่มีโครงสร้างกึ่งโครงสร้างหรือไม่มีโครงสร้าง ซึ่งในกรณีนี้ การโหลดลงในคลังข้อมูลนั้นค่อนข้างท้าทาย ซึ่งสร้างขึ้นโดยเนื้อแท้สำหรับข้อมูลที่มีโครงสร้าง ในกรณีนี้ เราอาจต้องการเริ่มต้นด้วย Data Lake Data Lake คือที่เก็บข้อมูลที่มีการจัดระเบียบซึ่งมีข้อมูลทั้งหมดที่สร้างโดยองค์กรของคุณ ซึ่งมักจะอยู่ในรูปแบบดิบ
ในการใช้ Data Lake อย่างมีประสิทธิภาพ คุณจะต้องใช้เครื่องมือเพื่อดำเนินการสืบค้นข้อมูลขนาดใหญ่และวิเคราะห์ข้อมูลที่มีอยู่ใน Data Lake เครื่องมือสืบค้นข้อมูลเป็นส่วนหนึ่งของคลังข้อมูล แต่คุณจะต้องเลือกเครื่องมือสืบค้นข้อมูลเพื่อจับคู่กับ Data Lake ของคุณ ตามเนื้อผ้า สิ่งนี้ทำโดยใช้เฟรมเวิร์กที่เรียกว่า Apache Hadoop ซึ่งเป็นชุดเครื่องมือซอฟต์แวร์สำหรับดำเนินการคำนวณตามกำหนดเวลาหรือเป็นชุดสำหรับชุดข้อมูลจำนวนมหาศาล
เครื่องมือทั่วไปอีกตัวหนึ่งสำหรับการสืบค้น Data Lake คือ Apache Spark ซึ่งช่วยให้ Data Scientists ทำงานแบบโต้ตอบกับชุดข้อมูลขนาดใหญ่ได้โดยใช้ภาษาโปรแกรมที่ต้องการ (python หรือ R) เพื่อให้เข้าใจวิธีการทำงานของ Data Lake ได้ดีขึ้น ให้ดูอินโฟกราฟิกที่สร้างโดย G2 Crowd Learning Hub
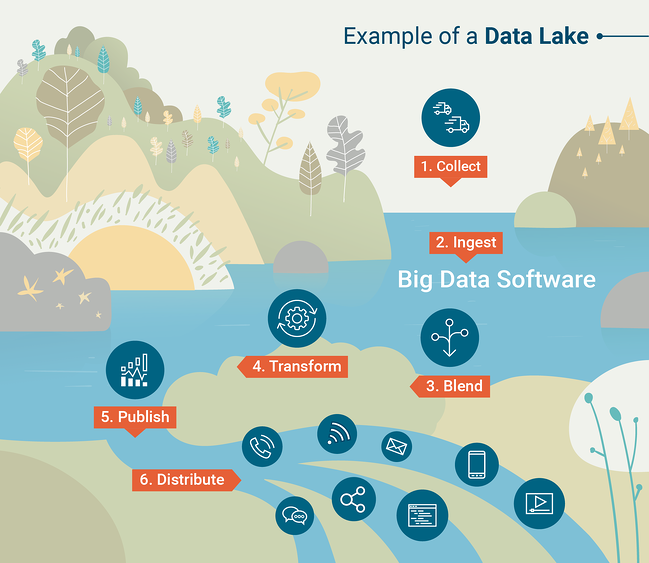
ที่มา: G2 Crowd
ชั้นคอมพิวเตอร์
นักวิทยาศาสตร์ข้อมูลทำสิ่งต่าง ๆ ในองค์กรต่าง ๆ แต่สิ่งหนึ่งที่คงที่คือพวกเขาจะต้องทำการกระทืบตัวเลขที่ค่อนข้างหนัก ในการทำเช่นนี้ Data Scientist ต้องใช้แล็ปท็อปที่ทรงพลัง และอาจต้องใช้เครื่องมือคำนวณเพิ่มเติม ทั้งนี้ขึ้นอยู่กับฟังก์ชันที่จะดำเนินการ เครื่องมือที่มีให้สำหรับการคำนวณจากชั้นคำนวณของการดำเนินการด้านวิทยาศาสตร์ข้อมูลของคุณ

สำหรับงานประจำวัน
ประสิทธิภาพการทำงานของ Data Scientist ของคุณสามารถปรับปรุงได้อย่างมากโดยการจัดหาอุปกรณ์ที่มีกำลังประมวลผลจำนวนมาก เครื่องมือทั่วไปสำหรับการวิเคราะห์ข้อมูลคือ R หรือ Python ที่มีโน้ตบุ๊ก Jupyter และเครื่องมือเหล่านี้ขึ้นอยู่กับการจัดเก็บชุดข้อมูลและดำเนินการคำนวณในหน่วยความจำ ซึ่งทำให้เป็นเรื่องปกติที่ Data Scientist จะใช้หน่วยความจำของแล็ปท็อปอย่างเต็มที่ ส่งผลให้งานช้าหรือสูญหาย ในการต่อสู้กับปัญหานี้ ให้เลือก RAM มากที่สุดเท่าที่จะเป็นไปได้เมื่อซื้อแล็ปท็อปสำหรับนักวิทยาศาสตร์ข้อมูลของคุณ
เครื่องมือคอมพิวเตอร์สำหรับการเรียนรู้ของเครื่อง
เทคนิคการเรียนรู้ด้วยเครื่องสมัยใหม่ทำได้ดีอย่างน่าทึ่งในการทำสิ่งต่างๆ เช่น การจดจำภาพหรือใบหน้า การประมวลผลภาษาที่เป็นธรรมชาติ และงานอื่นๆ อีกมากมายที่คอมพิวเตอร์แทบนึกไม่ถึงเมื่อสองสามปีก่อน แต่ความก้าวหน้าเหล่านี้ต้องแลกมาด้วยต้นทุน: การสร้างโมเดลการเรียนรู้ของเครื่องต้องใช้พลังประมวลผลมหาศาล ซึ่งมากกว่าแล็ปท็อปส่วนใหญ่
ความก้าวหน้าที่สำคัญอย่างหนึ่งคือการพัฒนาการประมวลผล GPU (หน่วยประมวลผลกราฟิก) สำหรับการเรียนรู้ของเครื่อง เดิมที GPU ได้รับการออกแบบมาเป็นเครื่องมือสำหรับการเรนเดอร์กราฟิกที่ซับซ้อนอย่างมีประสิทธิภาพ ทำให้ CPU (หน่วยประมวลผลกลาง) ว่างทำอย่างอื่นได้ แม้ว่า CPU จะได้รับการออกแบบมาเพื่อทำงานที่ซับซ้อนทีละตัว แต่ GPU ได้รับการออกแบบให้ทำงานง่ายๆ ได้ครั้งละหลายพันงาน รูปแบบการคำนวณนี้เหมาะสำหรับคณิตศาสตร์ที่การเรียนรู้เชิงลึกและวิธีการเรียนรู้ของเครื่องที่ซับซ้อนอื่นๆ นักวิจัยและนักพัฒนาของแมชชีนเลิร์นนิงได้เรียนรู้ที่จะใช้ประโยชน์จากการประมวลผลด้วย GPU เพื่อเร่งกระบวนการสร้างโมเดลเหล่านี้
เพื่อใช้ประโยชน์จากการประมวลผล GPU คุณต้องเข้าถึงคอมพิวเตอร์ที่มี GPU แยก ตามเนื้อผ้าจะพบได้ในคอมพิวเตอร์สำหรับเล่นเกม แต่เมื่อการประมวลผลด้วย GPU ได้รับความนิยม GPU แบบแยกจึงแพร่หลายมากขึ้นในคอมพิวเตอร์ระดับมืออาชีพระดับไฮเอนด์
คลาวด์คอมพิวติ้ง
สำหรับองค์กรส่วนใหญ่ มีข้อดีมากมายในการทำให้แมชชีนเลิร์นนิงทำงานบนคลาวด์ได้จริง บริการต่างๆ เช่น Google Cloud Platform, Amazon Web Services, Microsoft Azure และอื่นๆ อนุญาตให้ผู้ใช้เช่าอินสแตนซ์เสมือนของคอมพิวเตอร์ที่มีอุปกรณ์ครบครันซึ่งอยู่ในศูนย์ข้อมูลแห่งใดแห่งหนึ่ง อินสแตนซ์ระบบคลาวด์สามารถเข้าถึงได้อย่างปลอดภัยจากคอมพิวเตอร์ทุกเครื่องที่เชื่อมต่อกับอินเทอร์เน็ต ซึ่งหมายความว่าวิธีนี้ ไม่ จำเป็นต้องมีนักวิทยาศาสตร์ข้อมูลของคุณมีแล็ปท็อปเฉพาะทาง มีข้อดีที่สำคัญอื่นๆ บางประการของการประมวลผลแบบคลาวด์
ข้อได้เปรียบที่ชัดเจนที่สุดคือความสามารถในการปรับขนาด หากคุณต้องการพลังการประมวลผลที่มากขึ้นสำหรับโปรเจ็กต์ใหม่ คุณสามารถจัดสรรทรัพยากรเพิ่มเติมได้ทันทีโดยเพิ่มการชำระเงินรายเดือนของคุณไปยังบริการคลาวด์ และทรัพยากรสามารถลดขนาดลงได้อย่างรวดเร็วเช่นกัน คุณยังสามารถเลือกที่จะเรียกใช้หลายอินสแตนซ์: อินสแตนซ์ที่ใช้พลังงานต่ำสำหรับการประมวลผลแบบวันต่อวัน และอินสแตนซ์ที่ขับเคลื่อนสูงกว่าซึ่งเปิดใช้งานสำหรับการยกของหนักเท่านั้น ซึ่งเป็นเรื่องปกติโดยเฉพาะอย่างยิ่งเมื่อต้องใช้การประมวลผล GPU เนื่องจากอินสแตนซ์ที่เปิดใช้งาน GPU มักจะมีราคาแพงกว่า
ข้อดีอีกประการหนึ่งคือความปลอดภัยของข้อมูล ไม่ใช่ความคิดที่ดีที่สุดที่จะดาวน์โหลดข้อมูลไปยังแล็ปท็อปส่วนตัวของคุณเพื่อการวิเคราะห์ โดยเฉพาะอย่างยิ่งหากข้อมูลนั้นมีความละเอียดอ่อน การใช้ผู้ให้บริการระบบคลาวด์รายเดียวกันในการจัดเก็บและประมวลผลเป็นวิธีหนึ่งในการรักษาความปลอดภัยให้กับข้อมูลของคุณมากขึ้น
ร่วมมือกับนักวิทยาศาสตร์ข้อมูลของคุณ
เป็นเรื่องน่าเสียดายที่องค์กรต่างๆ จะจ้างนักวิทยาศาสตร์ข้อมูลแต่ล้มเหลวในการจัดหาเครื่องมือและอุปกรณ์ที่จำเป็นต่อการประสบความสำเร็จ
เตรียมพร้อมที่จะรับฟัง Data Scientist คนใหม่ของคุณ โดยเฉพาะอย่างยิ่งหากคุณจ้าง Data Scientist มากประสบการณ์และมีประสบการณ์ทำงานประเภทนี้ในวงกว้างในบริษัทอื่น หากคุณไม่แน่ใจว่าเครื่องมือใดที่จำเป็นในการเสริมศักยภาพ Data Scientist ให้เตรียมพร้อมที่จะร่วมมือกับเขาหรือเธอในแผนงาน Data Science ที่มีแนวคิด ข้อมูล และทรัพยากรในการคำนวณ