
데이터 과학자가 효과적인 데 필요한 도구
게시 됨: 2022-04-28이전 게시물에서 우리는 데이터 과학 로드맵을 구축하는 방법과 새로 고용된 데이터 과학자가 기초를 다지는 데 사용할 데이터를 결정 하는 방법에 대해 논의했습니다. 그러나 좋은 아이디어, 데이터, 데이터 과학자가 있는 것만으로는 충분하지 않습니다. 데이터 과학자는 업무를 효과적으로 수행하기 위해 강력한 도구가 필요합니다. 이 게시물에서는 일반적인 데이터 과학자가 성공하는 데 필요한 도구 유형에 대해 설명합니다.
데이터 계층
최신 기술 제품은 클릭스트림, 원격 측정, 댓글이나 리뷰와 같은 사용자 생성 콘텐츠, 고객 경험 터치포인트 등 많은 데이터를 생성할 수 있습니다. 이 데이터를 찾아 매핑하고 가능한 경우 단일 중앙 위치에 로드하는 것이 중요합니다. 이 중앙 데이터 저장소는 데이터 과학 작업의 데이터 계층입니다.
데이터 웨어하우스
데이터의 대부분이 관계형 데이터베이스(또는 흔히 SQL 데이터베이스라고 하는 것)에 있는 경우 장래의 데이터 과학자를 위해 할 수 있는 가장 쉽고 최선의 방법 중 하나는 데이터 웨어하우스 를 구축하는 것 입니다.
데이터는 일반적으로 "데이터 과학 수행"의 명시적인 목적으로 수집되지 않습니다. 예를 들어, 전자 상거래 사이트는 데이터 과학자가 자연어 처리를 수행하여 리뷰에서 패턴을 발견할 수 있도록 리뷰가 페이지에 표시될 수 있도록 데이터베이스에 고객 리뷰를 수집합니다. 즉, 리뷰를 수집하더라도 분석하는 데 어렵고 시간이 많이 걸립니다.
데이터 웨어하우스는 조직의 분석 및 비즈니스 인텔리전스에 필요한 모든 데이터를 포함하는 SQL 데이터베이스입니다. 올바르게 설계되면 데이터 웨어하우스는 쿼리가 빠르고 확장이 쉬우며 데이터 과학자가 목표를 달성하는 데 필요한 모든 데이터를 포함합니다. 데이터 과학자를 데려오기 전에 이것을 구축 하면 데이터 액세스를 기다리거나 느린 데이터베이스를 쿼리하는 데 낭비되는 시간을 줄일 수 있습니다.
모든 주요 클라우드 제공업체는 설정 및 확장이 쉬운 일부 유형의 데이터 웨어하우스 기술을 제공합니다. Amazon Web Services(AWS) 는 Amazon Redshift 및 Redshift Spectrum을 제공하고 Google은 Google BigQuery 를 제공하며 Microsoft는 Azure SQL Data Warehouse를 제공합니다.
데이터 레이크
데이터 웨어하우스는 데이터를 SQL 데이터베이스에 로드할 수 있는 한 강력하고 유용합니다. 그러나 이것이 항상 실용적인 것은 아닙니다. 많은 현대 기술 조직은 반정형 또는 비정형 데이터를 처리하며, 이 경우 본질적으로 정형 데이터용으로 구축된 데이터 웨어하우스에 로드하는 것이 상당히 어려울 수 있습니다. 이 경우 Data Lake 로 시작하는 것이 좋습니다. 데이터 레이크는 조직에서 생성한 모든 데이터를 일반적으로 원시 형식으로 포함하는 조직화된 데이터 저장소입니다.
데이터 레이크를 효과적으로 활용하려면 데이터 레이크에 포함된 데이터에 대한 대규모 쿼리 및 분석을 수행하는 도구가 필요합니다. 쿼리 도구는 데이터 웨어하우스의 일부이지만 데이터 레이크와 페어링하려면 쿼리 도구를 선택해야 합니다. 전통적으로 이것은 Apache Hadoop 이라는 프레임워크를 사용하여 수행되었습니다. 이 프레임워크는 방대한 데이터 세트에 대해 예약 또는 일괄 계산을 수행하기 위한 소프트웨어 도구 세트입니다.
데이터 레이크 쿼리를 위한 또 다른 일반적인 도구는 데이터 과학자가 선호하는 프로그래밍 언어(python 또는 R)를 사용하여 빅 데이터 세트와 대화식으로 작업할 수 있는 Apache Spark입니다. 데이터 레이크의 작동 방식을 더 잘 이해하려면 G2 Crowd Learning Hub에서 만든 이 인포그래픽을 확인하십시오.
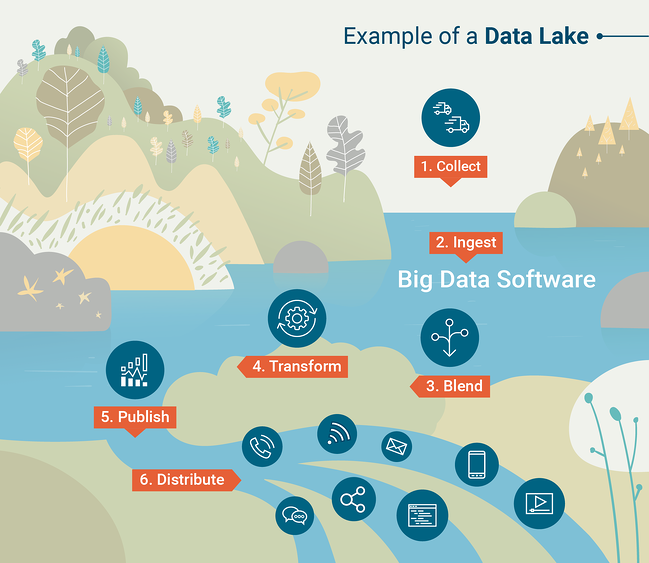
출처: G2 Crowd
컴퓨팅 계층
데이터 과학자는 조직마다 다른 작업을 수행하지만 한 가지 변함없는 사실은 꽤 많은 수의 크런칭을 수행해야 한다는 것입니다. 이를 위해 데이터 과학자는 강력한 노트북이 필요하며 수행할 기능에 따라 추가 계산 도구가 필요할 수 있습니다. 계산에 사용할 수 있는 도구는 데이터 과학 작업의 계산 계층을 형성합니다.

일상 업무용
장비에 대량의 컴퓨팅 성능을 제공하면 데이터 과학자의 생산성이 크게 향상될 수 있습니다. 데이터 분석을 위한 일반적인 도구는 R 또는 Python with Jupyter notebook이며 이러한 도구는 데이터 세트를 저장하고 메모리에 계산을 수행하는 데 의존합니다. 이로 인해 데이터 과학자가 랩톱의 메모리를 최대한 활용하여 작업 속도가 느려지거나 손실이 발생하는 것이 일반적입니다. 이 문제를 해결하려면 데이터 과학자를 위해 랩톱을 구입할 때 가능한 한 많은 RAM을 선택하십시오.
기계 학습을 위한 컴퓨팅 도구
현대의 기계 학습 기술은 이미지나 얼굴 인식, 자연어 처리, 몇 년 전만 해도 컴퓨터에서는 거의 상상할 수 없었던 더 많은 작업을 수행하는 데 놀라울 정도로 뛰어납니다. 그러나 이러한 발전에는 대가가 따릅니다. 기계 학습 모델을 구축하려면 대부분의 랩톱에서 볼 수 있는 것보다 더 많은 계산 능력이 필요합니다.
한 가지 중요한 발전은 기계 학습을 위한 GPU(그래픽 처리 장치) 컴퓨팅의 개발입니다. GPU는 원래 복잡한 그래픽을 효율적으로 렌더링하기 위한 도구로 설계되었으며 CPU(중앙 처리 장치)가 다른 작업을 수행할 수 있도록 합니다. CPU는 복잡한 작업을 한 번에 하나씩 수행하도록 설계되었지만 GPU는 한 번에 수천 개의 매우 간단한 작업을 수행하도록 설계되었습니다. 이 계산 스타일은 딥 러닝 및 기타 복잡한 기계 학습 방법이 사용하는 수학에 적합합니다. 머신 러닝 연구원과 개발자는 GPU 컴퓨팅을 활용하여 이러한 모델을 구축하는 프로세스를 가속화하는 방법을 배웠습니다.
GPU 컴퓨팅을 활용하려면 개별 GPU가 있는 컴퓨터에 액세스해야 합니다. 전통적으로 이것은 게임용 컴퓨터에서 볼 수 있었지만 GPU 컴퓨팅이 인기를 얻으면서 고급 전문 컴퓨터에서 개별 GPU를 더 널리 사용할 수 있게 되었습니다.
클라우드 컴퓨팅
대부분의 조직에서 실제로 모든 기계 학습 작업을 클라우드에서 유지하면 많은 이점이 있습니다. Google Cloud Platform, Amazon Web Services, Microsoft Azure 등과 같은 서비스를 통해 사용자는 데이터 센터 중 하나에 있는 잘 갖춰진 컴퓨터의 가상 인스턴스를 임대할 수 있습니다. 클라우드 인스턴스는 인터넷에 연결된 모든 컴퓨터에서 안전하게 액세스할 수 있습니다. 즉, 이 접근 방식에서는 데이터 과학자가 특수 랩톱을 가질 필요 가 없습니다 . 클라우드 컴퓨팅에는 몇 가지 다른 주요 이점이 있습니다.
가장 확실한 장점은 확장성입니다. 새 프로젝트에 더 많은 컴퓨팅 성능이 필요한 경우 클라우드 서비스에 대한 월별 지불액을 늘려 추가 리소스를 즉시 마샬링할 수 있습니다. 그리고 리소스도 마찬가지로 빠르게 축소할 수 있습니다. 여러 인스턴스를 실행하도록 선택할 수도 있습니다. 일상적인 컴퓨팅을 위한 저전력 인스턴스와 무거운 작업을 위해서만 켜진 고성능 인스턴스입니다. 이는 GPU 지원 인스턴스가 더 비싼 경향이 있기 때문에 특히 GPU 컴퓨팅이 필요할 때 일반적입니다.
또 다른 장점은 데이터 보안입니다. 특히 데이터가 민감한 경우 분석을 위해 데이터를 개인 랩톱에 다운로드하는 것은 좋은 생각이 아닙니다. 스토리지 및 계산에 동일한 클라우드 제공업체를 사용하는 것은 데이터를 보다 안전하게 유지하는 한 가지 방법입니다.
데이터 과학자와 협업
유감스럽게도 조직에서 데이터 과학자를 고용하지만 성공에 필요한 도구와 장비를 제공하지 못하는 경우가 너무 많습니다.
새로운 데이터 과학자의 말을 들을 준비를 하십시오. 다른 회사에서 이러한 유형의 작업을 대규모로 수행한 경험이 있는 노련한 데이터 과학자를 고용하는 경우 특히 그렇습니다. 데이터 과학자에게 권한을 부여하는 데 어떤 도구가 필요한지 확실하지 않은 경우 아이디어, 데이터 및 계산 리소스가 포함된 데이터 과학 로드맵에서 데이터 과학자와 협력할 준비를 하십시오.