
Veri Bilimcinizin Etkili Olması İçin İhtiyaç Duyduğu Araçlar
Yayınlanan: 2022-04-28Önceki gönderilerde, bir veri bilimi yol haritasının nasıl oluşturulacağını ve yeni işe alınan bir veri bilimcisinin işe koyulmasına yardımcı olmak için hangi verileri kullanacağınızı belirledik. Ancak iyi fikirlere, verilere ve bir veri bilimcisine sahip olmak yeterli değildir: veri bilimcisinin işlerini etkili bir şekilde yapabilmesi için güçlü araçlara ihtiyacı vardır. Bu yazıda, tipik bir veri bilimcisinin başarılı olması için gereken araç türlerini tartışacağız.
Veri Katmanı
Modern teknoloji ürünleri çok sayıda veri üretebilir: tıklama akışları, telemetri, yorumlar veya incelemeler gibi kullanıcı tarafından oluşturulan içerik ve müşteri deneyimi temas noktaları bunlardan birkaçıdır. Bu verilerin bulunması, eşlenmesi ve mümkünse tek bir merkezi konuma yüklenmesi çok önemlidir. Bu merkezi veri deposu, Veri Bilimi işleminizin Veri Katmanıdır.
Veri depoları
Verilerinizin çoğu ilişkisel veritabanlarında (veya genellikle SQL veritabanları olarak adlandırılanlarda) mevcutsa, olası Veri Bilimciniz için yapabileceğiniz en kolay ve en iyi şeylerden biri bir Veri Ambarı oluşturmaktır .
Veriler tipik olarak “veri bilimi yapmak” gibi açık bir amaç için toplanmaz; örneğin, bir e-ticaret sitesi, veri bilimcilerinin incelemelerdeki kalıpları keşfetmek için doğal dil işlemesi yapabilmeleri için değil, incelemelerin bir sayfada görüntülenebilmesi için müşteri incelemelerini bir veritabanında toplar. Bu, incelemelerin toplanmasına rağmen analiz edilmesinin zor ve zaman alıcı olduğu anlamına gelir.
Veri ambarı, kuruluşunuzdaki analitik ve iş zekası için gerekli tüm verileri içeren bir SQL veritabanıdır. Doğru şekilde tasarlanmışsa, veri ambarlarının sorgulanması hızlıdır, ölçeklenmesi kolaydır ve Veri Bilimcinizin hedeflerinizi karşılaması için ihtiyaç duyduğu tüm verileri içerir. Bunu bir Veri Bilimcisi getirmeden önce oluşturmak, verilere erişimi beklemek veya yavaş veritabanlarını sorgulamak için harcanan zamanı azaltacaktır.
Tüm büyük bulut sağlayıcıları, kurulumu ve ölçeklenmesi kolay bir tür veri ambarı teknolojisi sağlar. Amazon Web Services (AWS) , Amazon Redshift ve Redshift Spectrum'u sağlar, Google'ın Google BigQuery'si vardır ve Microsoft, Azure SQL Veri Ambarı'nı sunar.
Veri Gölleri
Veri ambarları, verileriniz bir SQL veritabanına yüklenebildiği sürece güçlü ve kullanışlıdır. Ancak bu her zaman pratik değildir. Birçok modern teknoloji kuruluşu, yarı yapılandırılmış veya yapılandırılmamış verilerle ilgilenir; bu durumda, doğası gereği yapılandırılmış veriler için oluşturulmuş bir veri ambarına yüklemek oldukça zor olabilir. Bu durumda bir Data Lake ile başlamayı tercih edebiliriz . Veri gölü, kuruluşunuz tarafından oluşturulan tüm verileri genellikle ham biçimde içeren organize bir veri deposudur.
Bir veri gölünü etkin bir şekilde kullanmak için, veri gölünde bulunan veriler üzerinde büyük ölçekli sorgular ve analizler gerçekleştirecek araçlara ihtiyacınız olacaktır. Sorgulama araçları, bir veri ambarının parçasıdır, ancak veri gölünüzle eşleştirmek için bir sorgulama aracı seçmeniz gerekir. Geleneksel olarak, bu, muazzam veri kümeleri üzerinde planlanmış veya toplu hesaplamalar gerçekleştirmek için bir dizi yazılım aracı olan Apache Hadoop adlı bir çerçeve ile yapılmıştır .
Veri göllerini sorgulamak için başka bir yaygın araç, Veri Bilimcilerinin tercih ettikleri programlama dilini (python veya R) kullanarak büyük veri kümeleriyle etkileşimli olarak çalışmasına olanak tanıyan Apache Spark'tır. Veri göllerinin nasıl çalıştığını daha iyi anlamak için G2 Crowd Learning Hub tarafından oluşturulan bu bilgi grafiğine göz atın.
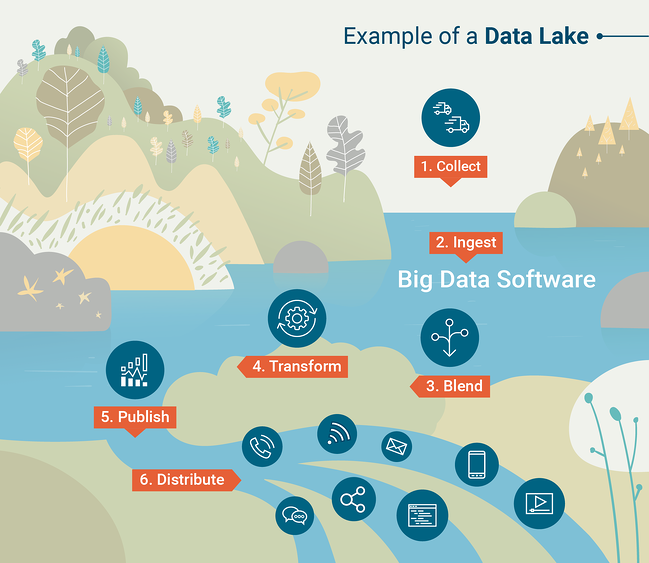
Kaynak: G2 Kalabalık
İşlem Katmanı
Veri Bilimcileri, farklı kuruluşlarda farklı şeyler yaparlar, ancak sabit olan bir şey, oldukça ağır bir sayı kırma işlemi gerçekleştirmeleri gerektiğidir. Bunu yapmak için bir veri bilimcisi güçlü bir dizüstü bilgisayara ihtiyaç duyar ve gerçekleştirecekleri işlevlere bağlı olarak ek hesaplama araçlarına ihtiyaç duyabilir. Hesaplama için kullanıma sunulan araçlar, veri bilimi operasyonunuzun hesaplama katmanını oluşturur.

Günlük Çalışmalar İçin
Veri Bilimcinizin üretkenliği, büyük miktarda bilgi işlem gücüne sahip ekipman sağlanarak büyük ölçüde artırılabilir. Veri analizi için tipik araçlar, Jupyter not defterine sahip R veya Python'dur ve bu araçlar, veri kümelerini depolamaya ve bellekte hesaplamalar gerçekleştirmeye bağlıdır. Bu, bir Veri Bilimcinin dizüstü bilgisayarlarının belleğini maksimuma çıkarmasını yaygın hale getirir, bu da işin yavaşlamasına ve hatta kaybedilmesine neden olur. Bu sorunla mücadele etmek için, veri bilimciniz için bir dizüstü bilgisayar satın alırken mümkün olan en fazla RAM'i seçin.
Makine Öğrenimi için Bilgi İşlem Araçları
Modern makine öğrenimi teknikleri, görüntüleri veya yüzleri tanıma, doğal dil işleme ve birkaç yıl önce bile bir bilgisayar için neredeyse hayal bile edilemeyen daha birçok görev gibi şeyleri yapmakta şaşırtıcı derecede iyidir. Ancak bu ilerlemelerin bir bedeli vardır: makine öğrenimi modelleri oluşturmak, çoğu dizüstü bilgisayarda bulunabilecek olandan daha fazla, muazzam bir hesaplama gücü gerektirir.
Önemli bir ilerleme, makine öğrenimi için GPU (Grafik İşleme Birimi) hesaplamasının geliştirilmesidir. GPU'lar başlangıçta karmaşık grafikleri verimli bir şekilde oluşturmak ve CPU'yu (Merkezi İşlem Birimi) başka şeyler yapmak için serbest bırakmak için araçlar olarak tasarlandı. Bir CPU, karmaşık görevleri birer birer gerçekleştirmek için tasarlanırken, GPU'lar aynı anda binlerce basit görevi gerçekleştirmek üzere tasarlanmıştır. Bu hesaplama stili, derin öğrenme ve diğer karmaşık makine öğrenimi yöntemlerinin kullandığı matematik için mükemmeldir. Makine öğrenimi araştırmacıları ve geliştiricileri, bu modelleri oluşturma sürecini hızlandırmak için GPU hesaplamayı kullanmayı öğrendi.
GPU hesaplamadan yararlanmak için ayrı bir GPU'ya sahip bir bilgisayara erişmeniz gerekir. Geleneksel olarak bu, oyun bilgisayarlarında bulunur, ancak GPU hesaplama popülerlik kazandıkça, ayrık GPU'lar ileri teknoloji profesyonel bilgisayarlarda daha yaygın olarak bulunur hale geldi.
Bulut bilişim
Çoğu kuruluş için, tüm makine öğreniminin bulutta çalışmasını sağlamanın birçok avantajı vardır. Google Cloud Platform, Amazon Web Services, Microsoft Azure ve diğerleri gibi hizmetler, kullanıcıların veri merkezlerinden birinde bulunan iyi donanımlı bir bilgisayarın sanal bir örneğini kiralamasına olanak tanır. Bulut örneklerine İnternet'e bağlı herhangi bir bilgisayardan güvenli bir şekilde erişilebilir, yani bu yaklaşım Veri Bilimcinizin özel bir dizüstü bilgisayara sahip olmasını gerektirmez . Bulut bilişimin birkaç önemli avantajı daha vardır.
En belirgin avantajı ölçeklenebilirliktir. Yeni bir proje için daha fazla bilgi işlem gücüne ihtiyacınız varsa, bulut hizmetine aylık ödemenizi artırarak ek kaynaklar anında sıralanabilir. Ve kaynaklar aynı hızla küçültülebilir. Hatta birden fazla bulut sunucusu çalıştırmayı da seçebilirsiniz: günlük bilgi işlem için daha düşük güçlü bir bulut sunucusu ve yalnızca ağır kaldırma için açık olan daha yüksek güçlü bir bulut sunucusu. Bu, özellikle GPU hesaplama gerektiğinde yaygındır, çünkü GPU etkin örnekler daha pahalı olma eğilimindedir.
Diğer bir avantaj ise veri güvenliğidir. Özellikle bu veriler hassassa, verileri analiz için kişisel dizüstü bilgisayarınıza indirmek en iyi fikir değildir. Depolama ve hesaplama için aynı bulut sağlayıcısını kullanmak, verilerinizi daha güvenli tutmanın bir yoludur.
Veri Bilimcinizle İşbirliği Yapın
Ne yazık ki, kuruluşların bir veri bilimcisi tutması, ancak onlara başarılı olmak için gerekli araç ve ekipmanı sağlayamaması çok yaygındır.
Yeni Veri Bilimcinizi dinlemeye hazır olun. Bu, özellikle diğer şirketlerde bu tür işleri geniş ölçekte yapma deneyimine sahip deneyimli bir Veri Bilimcisi tutuyorsanız geçerlidir. Data Scientist'i güçlendirmek için hangi araçlara ihtiyaç duyacağınızdan emin değilseniz, onunla fikirleri, verileri ve hesaplama kaynaklarını içeren bir Data Science yol haritası üzerinde işbirliği yapmaya hazır olun.