
您的數據科學家需要有效的工具
已發表: 2022-04-28在之前的文章中,我們討論瞭如何構建數據科學路線圖並確定您將使用哪些數據來幫助新聘用的數據科學家開始工作。 但僅僅擁有好的想法、數據和數據科學家是不夠的:數據科學家需要強大的工具來有效地完成他們的工作。 在這篇文章中,我們將討論典型數據科學家成功所需的工具類型。
數據層
現代技術產品可以生成大量數據:點擊流、遙測、用戶生成的內容(如評論或評論)以及客戶體驗接觸點等等。 對這些數據進行定位、映射並在可能的情況下加載到單個中心位置至關重要。 這個中央數據存儲是數據科學操作的數據層。
數據倉庫
如果您的大部分數據存在於關係數據庫(或通常稱為 SQL 數據庫)中,那麼您可以為未來的數據科學家做的最簡單和最好的事情之一就是構建數據倉庫。
收集數據通常不是為了“做數據科學”的明確目的; 例如,電子商務網站將客戶評論收集到數據庫中,以便將評論顯示在頁面上,而不是讓數據科學家執行自然語言處理以發現評論中的模式。 這意味著,儘管收集了評論,但分析起來既困難又耗時。
數據倉庫是一個 SQL 數據庫,其中包含組織中分析和商業智能所需的所有數據。 如果架構正確,數據倉庫可以快速查詢、易於擴展,並將包含數據科學家實現目標所需的所有數據。 在引入數據科學家之前構建它可以減少等待訪問數據或查詢慢速數據庫所浪費的時間。
所有主要的雲提供商都提供某種類型的數據倉庫技術,這些技術易於設置和擴展。 Amazon Web Services (AWS)提供 Amazon Redshift 和 Redshift Spectrum,Google 提供Google BigQuery ,Microsoft 提供Azure SQL 數據倉庫。
數據湖
只要您的數據可以加載到 SQL 數據庫中,數據倉庫就非常強大且有用。 然而,這並不總是實用的。 許多現代科技組織處理半結構化或非結構化的數據,在這種情況下,加載到數據倉庫中可能會非常具有挑戰性,而數據倉庫本身就是為結構化數據構建的。 在這種情況下,我們可能更喜歡從Data Lake開始。 數據湖是一個有組織的數據存儲,其中包含您的組織生成的所有數據,通常採用原始格式。
為了有效利用數據湖,您將需要工具來對數據湖中包含的數據執行大規模查詢和分析。 查詢工具是數據倉庫的重要組成部分,但您需要選擇一個查詢工具來與您的數據湖配對。 傳統上,這是通過稱為Apache Hadoop的框架完成的,這是一組用於對大量數據執行計劃或批量計算的軟件工具。
查詢數據湖的另一個常用工具是 Apache Spark,它允許數據科學家使用他們首選的編程語言(python 或 R)以交互方式處理大數據集。 為了更好地了解數據湖的工作原理,請查看 G2 Crowd Learning Hub 創建的此信息圖。
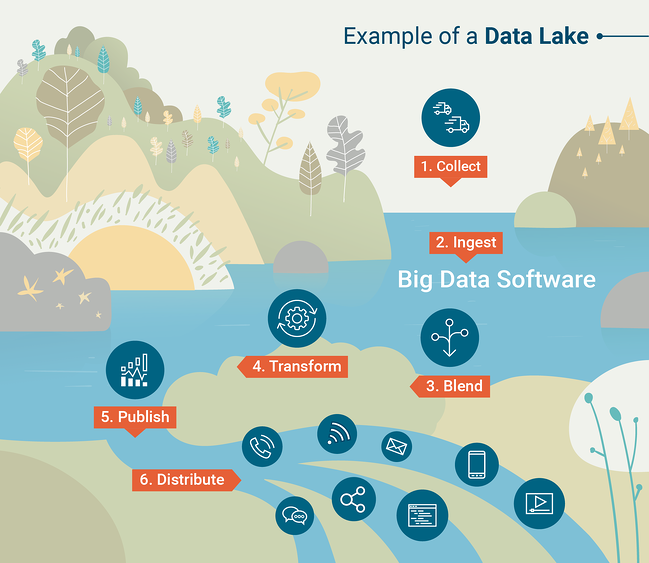
資料來源:G2 人群

計算層
數據科學家在不同的組織做不同的事情,但不變的一點是他們需要執行一些相當繁重的數字運算。 為此,數據科學家需要一台功能強大的筆記本電腦,並且根據他們將執行的功能,他們可能需要額外的計算工具。 可用於計算的工具構成了數據科學操作的計算層。
日常工作
通過提供具有大量計算能力的設備,可以大大提高您的數據科學家的工作效率。 用於數據分析的典型工具是帶有 Jupyter notebook 的 R 或 Python,這些工具依賴於在內存中存儲數據集和執行計算。 這使得數據科學家通常會最大限度地使用筆記本電腦的內存,從而導致工作緩慢甚至丟失。 為了解決這個問題,在為您的數據科學家購買筆記本電腦時選擇盡可能多的 RAM。
機器學習計算工具
現代機器學習技術在處理圖像或面部識別、自然語言處理以及更多甚至在幾年前計算機幾乎無法想像的任務方面表現出色。 但這些進步是有代價的:構建機器學習模型需要巨大的計算能力——比大多數筆記本電腦都多。
一項重要的進步是用於機器學習的 GPU(圖形處理單元)計算的發展。 GPU 最初被設計為有效渲染複雜圖形的工具,從而釋放 CPU(中央處理單元)來做其他事情。 CPU 旨在一次執行一項複雜任務,而 GPU 旨在一次執行數千個非常簡單的任務。 這種計算方式非常適合深度學習和其他復雜機器學習方法使用的數學。 機器學習研究人員和開發人員已經學會利用 GPU 計算來加速構建這些模型的過程。
要利用 GPU 計算,您需要使用具有獨立 GPU 的計算機。 傳統上,這將在遊戲計算機中找到,但隨著 GPU 計算的普及,離散 GPU 在高端專業計算機上變得更加廣泛。
雲計算
對於大多數組織而言,實際上將所有機器學習工作保留在雲端有很多優勢。 谷歌云平台、亞馬遜網絡服務、微軟 Azure 等服務允許用戶租用位於其數據中心的設備齊全的計算機的虛擬實例。 可以從任何連接到 Internet 的計算機安全地訪問云實例,這意味著這種方法不需要您的數據科學家擁有專門的筆記本電腦。 雲計算還有其他一些主要優勢。
最明顯的優勢是可擴展性。 如果您需要為新項目提供更多計算能力,可以通過增加每月支付給雲服務的費用來立即調集額外資源。 資源可以以同樣快的速度縮減。 您甚至可以選擇運行多個實例:用於日常計算的功率較低的實例,以及僅在繁重工作時才打開的功率較高的實例。 這很常見,尤其是在需要 GPU 計算時,因為啟用 GPU 的實例往往更昂貴。
另一個優勢是數據安全。 將數據下載到您的個人筆記本電腦進行分析並不是最好的主意,尤其是在這些數據很敏感的情況下。 使用相同的雲提供商進行存儲和計算是確保數據更安全的一種方法。
與您的數據科學家合作
不幸的是,組織會聘請數據科學家但未能為他們提供成功所需的工具和設備的情況太常見了。
準備好傾聽您的新數據科學家的意見。 如果您正在聘請一位經驗豐富的數據科學家,並在其他公司大規模從事此類工作,則尤其如此。 如果您不確定需要哪些工具來授權數據科學家,請準備好與他或她合作制定包含想法、數據和計算資源的數據科學路線圖。