
データサイエンティストが効果を発揮するために必要なツール
公開: 2022-04-28以前の投稿では、データサイエンスのロードマップを作成し、新しく採用されたデータサイエンティストが着手するのに役立つデータを決定する方法について説明しました。 しかし、優れたアイデア、データ、およびデータサイエンティストがいるだけでは十分ではありません。データサイエンティストは、仕事を効果的に行うための強力なツールを必要としています。 この投稿では、一般的なデータサイエンティストが成功するために必要なツールの種類について説明します。
データレイヤー
最新のテクノロジー製品は、クリックストリーム、テレメトリ、コメントやレビューなどのユーザー生成コンテンツ、カスタマーエクスペリエンスのタッチポイントなど、多くのデータを生成できます。 このデータを特定し、マッピングし、可能であれば、単一の中央の場所にロードすることが重要です。 この中央データストアは、データサイエンスオペレーションのデータレイヤーです。
データウェアハウス
データの大部分がリレーショナルデータベース(またはSQLデータベースと呼ばれることが多い)に存在する場合、将来のデータサイエンティストのためにできる最も簡単で最良のことの1つは、データウェアハウスを構築することです。
データは通常、「データサイエンスを行う」という明確な目的のために収集されることはありません。 たとえば、eコマースサイトはデータベースに顧客のレビューを収集して、レビューをページに表示できるようにします。データサイエンティストが自然言語処理を実行して、レビューのパターンを発見できるようにするためではありません。 つまり、レビューは収集されますが、分析するのは困難で時間がかかります。
データウェアハウスは、組織の分析とビジネスインテリジェンスに必要なすべてのデータを含むSQLデータベースです。 正しく設計されていれば、データウェアハウスはクエリをすばやく実行でき、拡張も簡単で、データサイエンティストが目的を達成するために必要なすべてのデータが含まれます。 データサイエンティストを導入する前にこれを構築しておくと、データへのアクセスを待機したり、低速なデータベースにクエリを実行したりするために浪費される時間を削減できます。
すべての主要なクラウドプロバイダーは、セットアップと拡張が容易な、ある種のデータウェアハウステクノロジーを提供しています。 アマゾンウェブサービス(AWS)はアマゾンレッドシフトとレッドシフトスペクトラムを提供し、グーグルはグーグルビッグクエリを提供し、マイクロソフトはアズールSQLデータウェアハウスを提供します。
データレイク
データウェアハウスは、データをSQLデータベースにロードできる限り、強力で便利です。 ただし、これは必ずしも実用的ではありません。 現代の技術組織の多くは、半構造化または非構造化のデータを扱っています。その場合、本質的に構造化データ用に構築されたデータウェアハウスにロードするのは非常に困難です。 この場合、データレイクから始めることをお勧めします。 データレイクは、組織によって生成されたすべてのデータを、通常は生の形式で含む、組織化されたデータストアです。
データレイクを効果的に利用するには、データレイクに含まれるデータに対して大規模なクエリと分析を実行するためのツールが必要になります。 クエリツールはデータウェアハウスの一部ですが、データレイクとペアリングするにはクエリツールを選択する必要があります。 従来、これはApache Hadoopと呼ばれるフレームワークを使用して行われていました。これは、膨大なデータセットに対してスケジュールされた計算またはバッチ計算を実行するためのソフトウェアツールのセットです。
データレイクをクエリするためのもう1つの一般的なツールは、Apache Sparkです。これにより、データサイエンティストは、好みのプログラミング言語(pythonまたはR)を使用してビッグデータセットをインタラクティブに操作できます。 データレイクがどのように機能するかをよりよく理解するには、G2 CrowdLearningHubによって作成されたこのインフォグラフィックを確認してください。
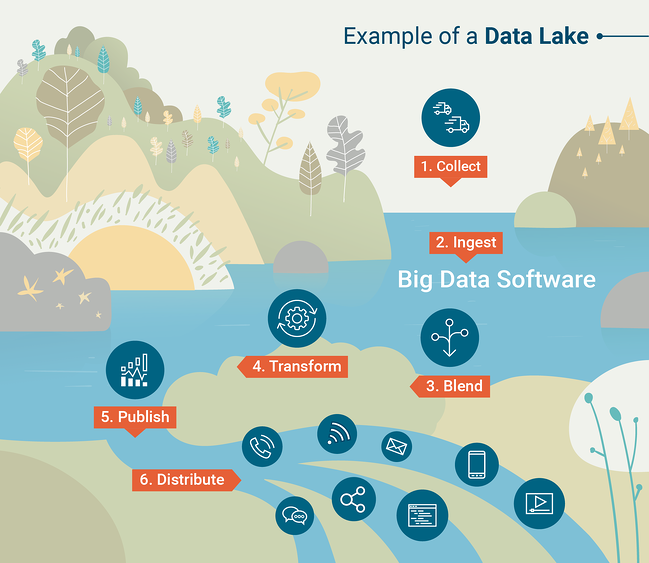
出典:G2 Crowd
コンピューティングレイヤー
データサイエンティストはさまざまな組織でさまざまなことを行いますが、1つの定数は、かなり大量の処理を実行する必要があるということです。 これを行うには、データサイエンティストは強力なラップトップを必要とし、実行する機能によっては、追加の計算ツールが必要になる場合があります。 計算に使用できるツールは、データサイエンスオペレーションの計算レイヤーを形成します。

日常業務用
データサイエンティストの生産性は、機器に大量の計算能力を提供することで大幅に向上させることができます。 データ分析の一般的なツールは、Jupyterノートブックを備えたRまたはPythonであり、これらのツールは、データセットの保存とメモリへの計算の実行に依存しています。 これにより、データサイエンティストがラップトップのメモリを最大限に活用することが一般的になり、作業が遅くなったり、失われたりする可能性があります。 この問題に対処するには、データサイエンティスト用のラップトップを購入するときに、可能な限り多くのRAMを選択してください。
機械学習用のコンピューティングツール
最新の機械学習技術は、画像や顔の認識、自然言語処理など、数年前でもコンピューターではほとんど想像もできなかった多くのタスクを実行するのに驚くほど優れています。 ただし、これらの進歩にはコストがかかります。機械学習モデルの構築には、ほとんどのラップトップに見られる以上の膨大な計算能力が必要です。
重要な進歩の1つは、機械学習用のGPU(グラフィックスプロセッシングユニット)コンピューティングの開発です。 GPUは元々、複雑なグラフィックスを効率的にレンダリングするためのツールとして設計されており、CPU(中央処理装置)を解放して他のことを実行できます。 CPUは一度に1つずつ複雑なタスクを実行するように設計されていますが、GPUは一度に数千の非常に単純なタスクを実行するように設計されています。 このスタイルの計算は、深層学習やその他の複雑な機械学習手法で使用される数学に最適です。 機械学習の研究者と開発者は、GPUコンピューティングを利用して、これらのモデルを構築するプロセスを加速することを学びました。
GPUコンピューティングを利用するには、ディスクリートGPUを搭載したコンピューターにアクセスする必要があります。 従来、これはゲーミングコンピューターで見られましたが、GPUコンピューティングの人気が高まるにつれ、ディスクリートGPUがハイエンドのプロフェッショナルコンピューターでより広く利用できるようになりました。
クラウドコンピューティング
ほとんどの組織にとって、実際にすべての機械学習をクラウド上で維持することには多くの利点があります。 Google Cloud Platform、Amazon Web Services、Microsoft Azureなどのサービスを使用すると、ユーザーはデータセンターの1つにある設備の整ったコンピューターの仮想インスタンスをレンタルできます。 クラウドインスタンスには、インターネットに接続されているどのコンピューターからでも安全にアクセスできます。つまり、このアプローチでは、データサイエンティストが専用のラップトップを持っている必要はありません。 クラウドコンピューティングには、他にもいくつかの大きな利点があります。
最も明らかな利点はスケーラビリティです。 新しいプロジェクトでより多くのコンピューティング能力が必要な場合は、クラウドサービスへの毎月の支払いを増やすことで、追加のリソースを即座にマーシャリングできます。 また、リソースを同じ速さで縮小できます。 複数のインスタンスを実行することを選択することもできます。日常のコンピューティング用の低電力のインスタンスと、重労働の場合にのみオンになる高電力のインスタンスです。 GPU対応のインスタンスはより高価になる傾向があるため、これは特にGPUコンピューティングが必要な場合に一般的です。
もう1つの利点は、データのセキュリティです。 特にそのデータが機密である場合、分析のために個人のラップトップにデータをダウンロードすることは最善の考えではありません。 ストレージと計算に同じクラウドプロバイダーを使用することは、データをより安全に保つための1つの方法です。
データサイエンティストとのコラボレーション
残念ながら、組織がデータサイエンティストを雇うことはあまりにも一般的ですが、成功するために必要なツールと機器を組織に提供することはできません。
新しいデータサイエンティストに耳を傾ける準備をしてください。 これは、他の企業でこの種の作業を大規模に行った経験のある経験豊富なデータサイエンティストを採用している場合に特に当てはまります。 データサイエンティストに力を与えるために必要なツールがわからない場合は、アイデア、データ、計算リソースを含むデータサイエンスロードマップで彼または彼女と協力する準備をしてください。