
3 億人の学生、3 億の洞察 – 教育におけるデータへの愛
公開: 2016-04-07Embibe のデータ サイエンス ラボを独占的に紹介
[これは、教育をパーソナライズするためにディープ テクノロジーとデータ サイエンスをどのように使用しているかというシリーズの第 2 部です]
Embibe は、学習成果を大規模に最大化するという 1 つのビジョンを持って構築されました。 ユーザーの学習成果にプラスの影響を与えることは、解決が困難ですが、重要な問題です。 実際、学習成果に意図的かつ積極的に影響を与えるという高い目標を実現するために、それぞれを解決する必要があるいくつかの自明ではない未解決のサブ問題があります。
しかし、最初に、学習成果とは何ですか? そして、なぜ私たちはそれらを気にかけているのでしょうか?
今日の非常に競争の激しい世界では、生徒は競争力のある試験や学校の教室でどれだけ得点できるかによって大部分が測定されます。 彼女のスコアは、彼女のキャリアの選択肢に大きな影響を与える可能性があります。 この記事の目的のために、厳密に指定された時間の制約内で、コンテンツを最適に学習、吸収、適用するために、学習成果を学生の生来の能力と訓練可能な可能性の関数として組み立てましょう。 彼女が特定の競争の激しい学問的状況でスコアを最大化できるようにします。
インドのような発展途上国では、生徒と教師の比率が大きく偏っており、教師は個人レベルで個別化された注意を効果的に提供できません。 これは、各生徒がさまざまな速度で情報を学習および吸収し、さまざまなレベルの適性を持っていることを考えると、ジレンマにつながります。 教師が個別の注意を払うことができないことの既知の副作用は、特定の教室/生徒の集まりに対して、学習教材が常に「平均的な」生徒に対応するように提示されることです。 したがって、非常に優秀な生徒はその可能性を最大限に発揮できず、真に学問的な力を発揮することができず、学力の弱い生徒は教室の残りの部分に対処するのに苦労します. しかし、既存のオンライン学習プラットフォームやシステムでは、学生レベルでの個別学習を真に促進することはできません。
現在のほとんどのシステムは、システムの管理者によって指定されたように、学生がソリューションをテスト モジュールにどれだけうまく適合させることができるかを説明するだけです。 競争力のある試験のためのパーソナライズされた学習は、限られた時間の中で、あらゆる学業目標の学生のスコアを最大化する必要があります。 個別化された学習は、知識や適性レベルだけでなく、態度や行動レベルでも学生の能力のギャップに建設的に対処する必要があります。 個々の生徒に合わせて特別かつ正確に調整された、パーソナライズされた学習のための効果的なツールがこのように不足しているため、生徒は、特定の試験で可能な限り最高のスコアを達成する可能性を実現できていません。
この記事では、embibe のデータ サイエンス チームが、学習成果を最大化し、具体的にはスコアを改善するために対処する必要がある、相互に関連するさまざまなデータ関連の問題の基礎を築きます。 この問題には、コンテンツの取り込みとコンテンツの配信という 2 つの主要な側面があります。 各次元は、あらゆるデータ サイエンティストを確実に魅了する多くの分野で独自の課題をもたらします。
コンテンツの取り込み
コンテンツの自動取り込み
数十のシラバス ボード、数千の章と概念、および数万の教育機関と学校から、毎年数十万の質問と回答が生成され、インストラクターによって使用されます。 すべての生徒が、試験前にこれらの質問の一部またはすべてについて自分の知識をテストでき、正解やよくある間違いについての詳細な説明を受けられるとしたらどうでしょう。 これを実現するために、私たちは光学式文字認識 (OCR) と機械学習を活用して、非常にスケーラブルで真に多言語であり、人間の入力への依存を最小限に抑える独自の自動取り込みフレームワークを構築しています。 楽しみはそれだけではありません。 このフレームワークはまた、ライターにとらわれない方法で手書きのコンテンツを取り込むことができるため、質問、回答、概念、説明、および知識の既に素晴らしいレポジトリに急速に追加されます。
コンセプトのタグ付け
これで、質問、回答、概念、章がすべて大規模なデータ ウェアハウスに取り込まれました。 各質問または章に関連する概念を手動でタグ付けするのは大変です。その逆も同様です。 データサイエンスが助けに! テキスト分類、トピック モデリング、ディープ ラーニングから得た最先端のアイデアを使用して、概念を質問、回答、章に自動的にタグ付けします。

2015 年 12 月、2016 年 1 月、および 2016 年 2 月に、Embibe ユーザーが学習機能を使用して参照した最も人気のある概念の選択。
手動でタグ付けされた高品質のコンテンツのシード セットを含む以前のデータベースは、言語的、語彙的、および文脈依存の特徴を抽出する際に役立ち、Google に取り込まれるすべての新しいデータに対して最先端のテキスト タグ付けモデルをトレーニングします。システム。
メタデータ強化
今日、知りたいトピックに関する豊富な情報がオンラインで入手できます。 アイデアとコンセプトは相互に構築されます。 たとえば、熱力学の第一法則は熱力学系の概念に関連しており、熱力学系は気体の比熱容量、機械的エネルギーの保存、気体が行う仕事などの概念に関連しています。 当社のコンテンツ取り込みフレームワークには、ウェブを自動的にクロールし、テキストの説明、ビデオ リンク、定義、ユーザーのコメント、フォーラム ディスカッションなどの多様なメディアでコンテンツにタグを付けるデータ エンリッチメント コンポーネントが含まれています。これらはすべて、著作権を尊重し、ソース コンテンツの所有権を適切に帰属させます。 . この豊富な利用可能な情報により、関連する概念をツリー構造で自動的に接続することもできます。 グラフ理論、テキスト マイニング、疎構造のラベル伝播の分野からのアイデアを使用して、ソース→ターゲットの関係を共有する概念間のリンクと相互接続を作成します。
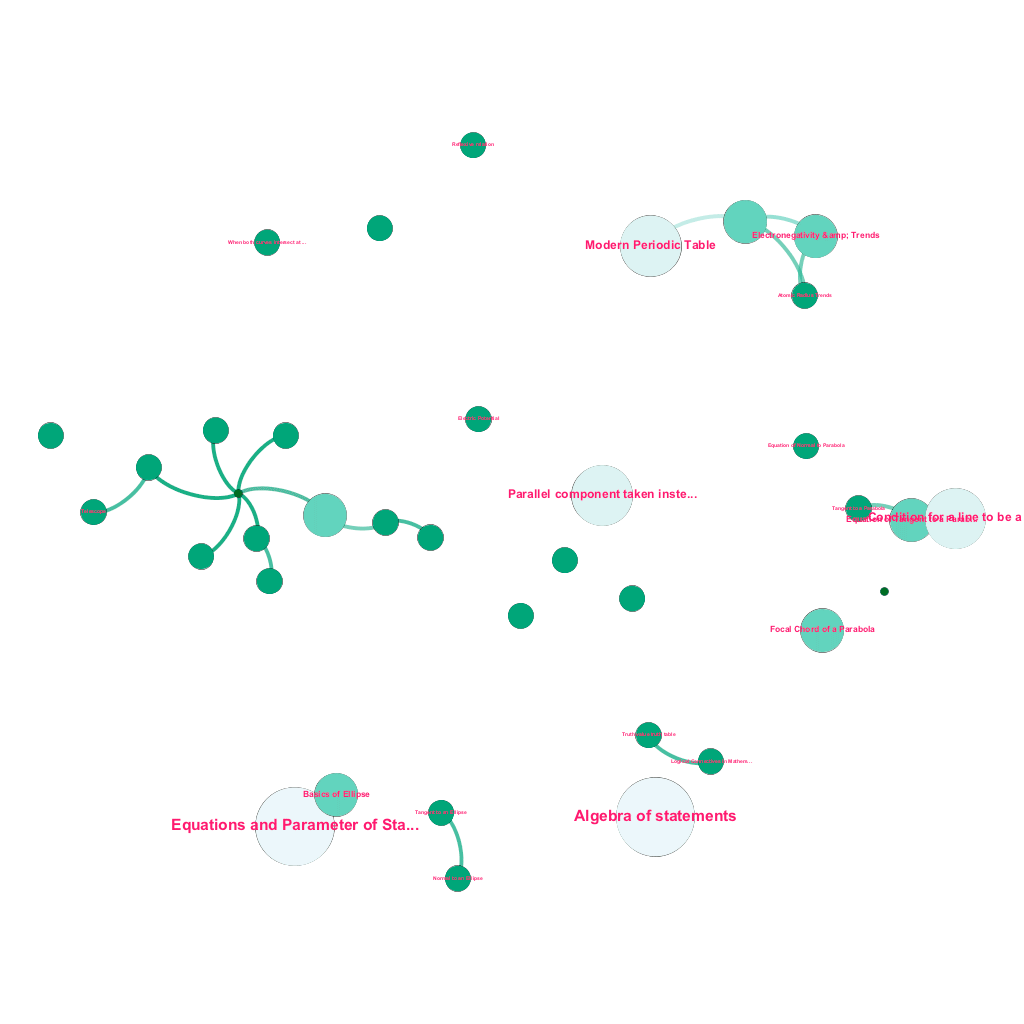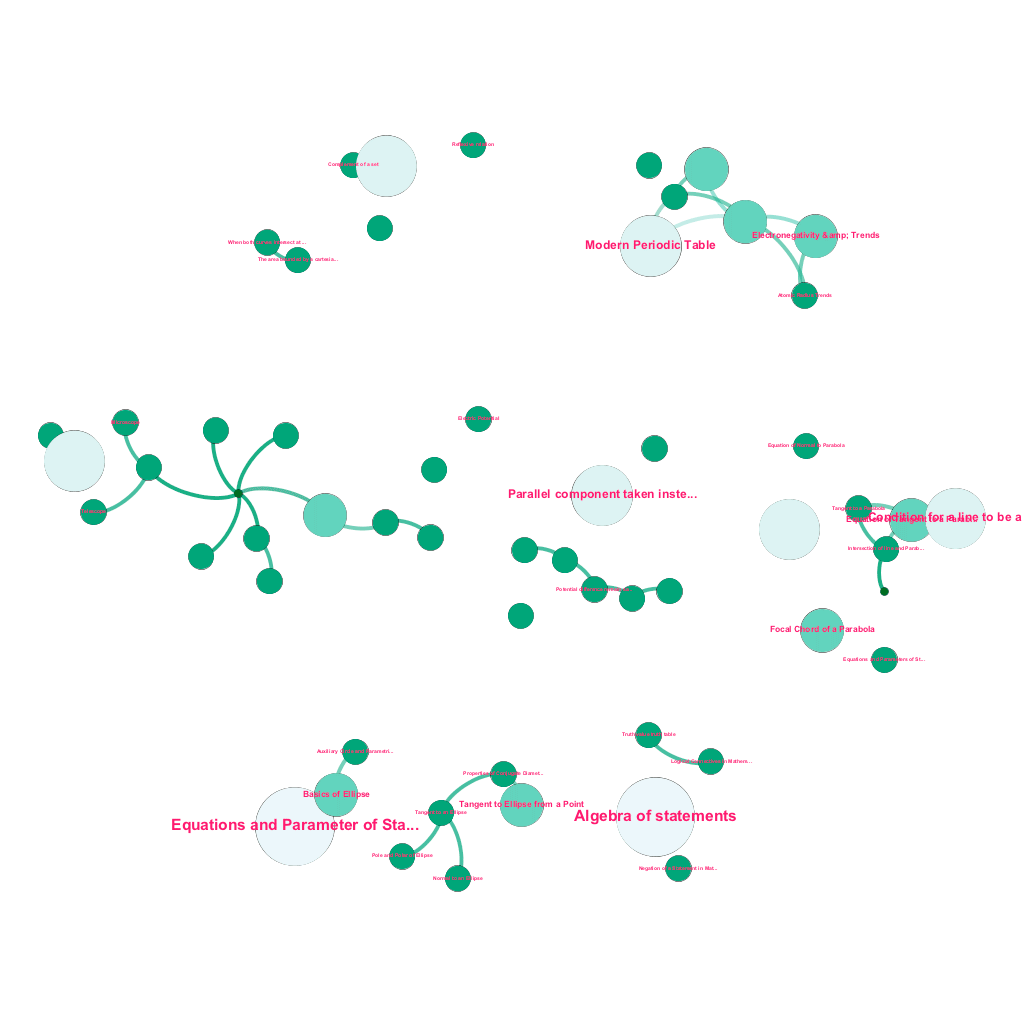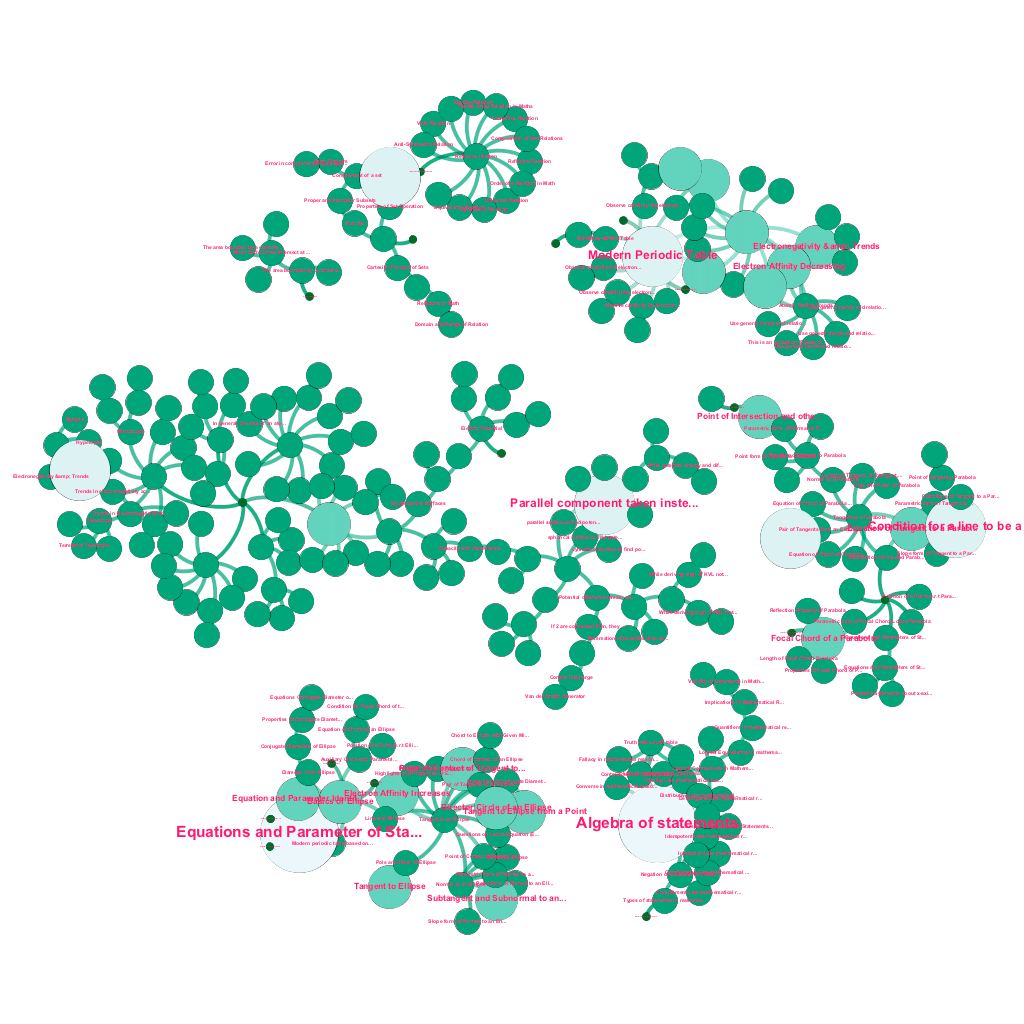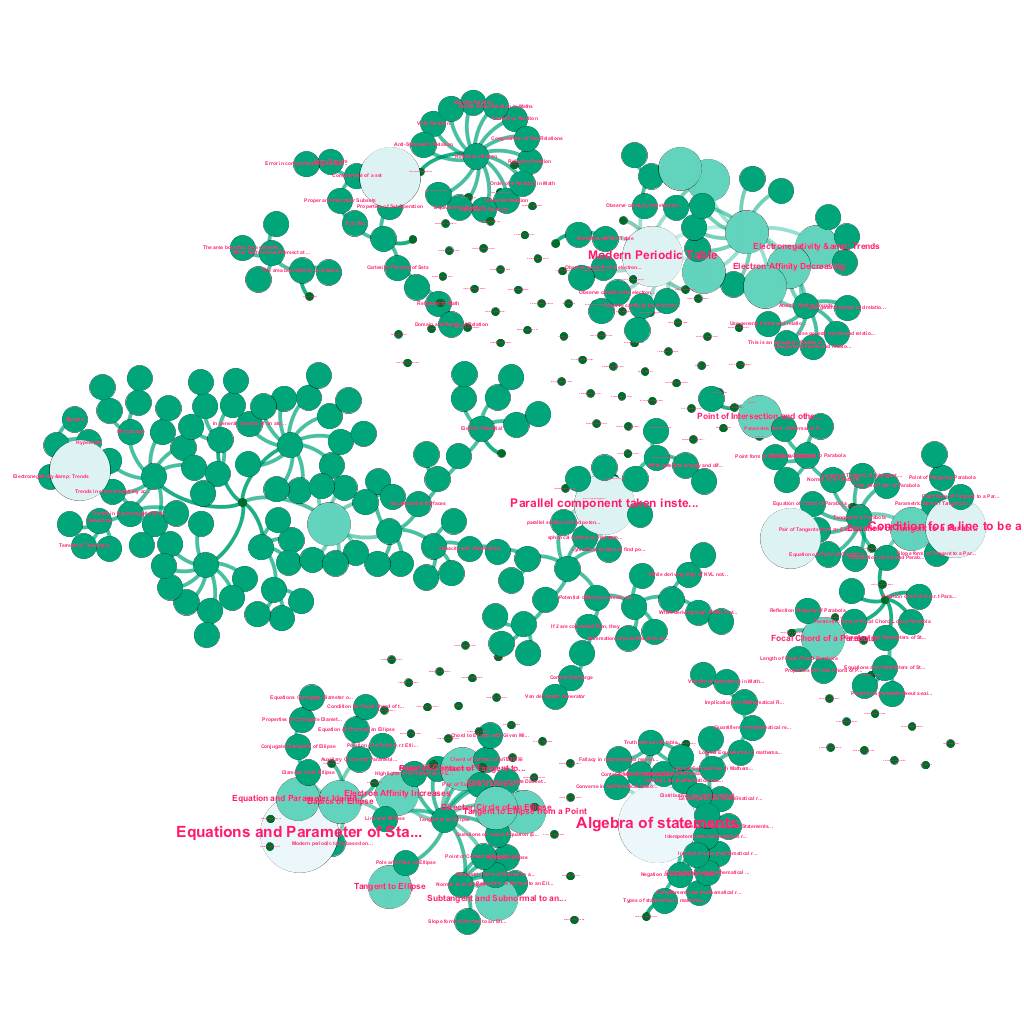
それぞれが 1 つまたは多くの関連する概念に接続されている、数学からのアイデアのサブセットに対する概念ツリーの自動構築
類似質問クラスタリング
試験の準備をしているとしたら、同じ問題を何度も練習したいと思いますか? それは役に立ちません。 逆に、いくつかの新しい概念や章を完全に習得するのに役立つ関連する質問の小さなセットを練習することがどれほど役立つか想像してみてください. 何十万もの質問にアクセスできるため、コンテンツ ターゲット、コンセプト テスト、難易度、試験の目標など、さまざまな側面にわたる類似性に基づいて質問をクラスター化する機能を開発しました。
潜在的な意味情報空間に基づくテキスト クラスタリング、および他のカテゴリおよび数値特徴空間との組み合わせにより、Embibe を使用して各個人に合わせて調整できる関心領域に、質問の宇宙を正確にグループ化することができます。 さらに、概念クラスターに関連する堅牢な数値特徴空間に変換したテキスト データの豊富なリソースにより、既存のデータをわずかに摂動させて、質問空間の潜在的に無限の表現を生成することができます。 これまで見たことのない、実行時のより多くの質問! これにより、ユーザーが当社のプラットフォームで費やした時間に対して最大の価値を提供できます。
コンテンツ配信
ユーザープロファイリング
ユーザーが Embibe で行うすべての動きを追跡します。 過去 3 年間にユーザーが行った何百万回もの練習とテストの試みは、何千もの次元のデータ空間で調整されています。 これは、ユーザーの行動データを深く掘り下げて学習方法と相関する洞察を生成するためにマイニングできる数十億のデータ ポイントの空間に変換されます。 ユーザーがさらに試行するたびに、その試行にタグ付けされた概念、および関連する前後の概念でより高いスコアを獲得する能力が微調整されます。 この非常に複雑な問題には、スパース マトリックス処理、グラフ理論の計算アルゴリズム、アイテム応答理論のアイデアを活用して、拡大するユーザー ベースに合わせてスケーリングする堅牢で適応性のあるユーザー プロファイルを構築することが含まれます。
あなたにおすすめ:

反営利条項はインドのスタートアップ企業にとって何を意味するのか?

Edtech スタートアップがインドの労働力のスキルアップと将来への準備をどのように支援しているか...

今週の新時代のテック株:Zomatoのトラブルは続き、EaseMyTripはスト...

インドの新興企業は資金調達を求めて近道をする

デジタル マーケティング プラットフォームの Logicserve が 80 億ルピーの資金を調達し、LS Dig...

レポートは、Lendingtechスペースに対する新たな規制精査を警告しています
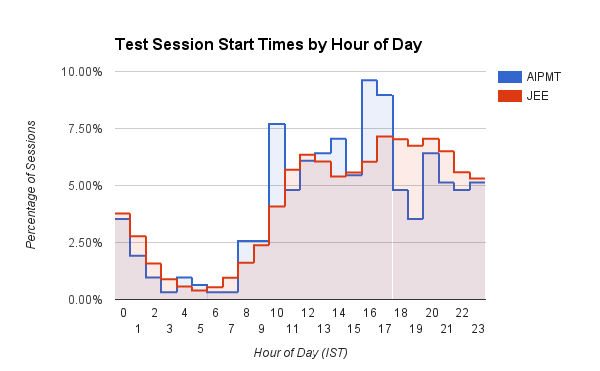
ユーザーが Embibe でテスト セッションを開始する時間 (IST の時間) を示す興味深い棒グラフ。 医療 (AIPMT) ユーザーには、午前 10 時頃と午後 3 時から午後 5 時の間に明確なスパイクがあります。 一方、エンジニアリング (JEE) ユーザーは、1 日が進むにつれてセッションの開始時間が徐々に長くなり、午後 4 時から午後 8 時頃にピークに達します。 また、JEE の学生は、AIPMT の学生と比較して、午後 5 時から午前 3 時までの間に一貫してより多くの練習セッションを開始します。 医者はもっと規律があると思います!

非常に詳細なレベルでのユーザー アクティビティの広範な計測と測定により、個々のユーザーに関連付けられた学習スタイルに関連する潜在的な好みを推測することができます。 たとえば、特定の生徒は、テキストによる説明を好む他の生徒や、解決された例の問題を段階的に学習する他の生徒と比較して、ビデオの説明の助けを借りて、学習し、その後テストを行うことができます。 Dunn and Dunn Model (Dunn & Dunn 1989) や Gregorc の Mind Styles Model (Gregorc 1982) などのよく研究された学習スタイルの理論モデルにユーザーをマッピングして、練習の修正コースを自動的に調整し、ユーザーがスコアの改善に向けて支援できるようにします。
ユーザーのコホーティング
コホーティングは、古典的なクラスタリングの問題です。 ユーザーは、製品機能に関する使用パターンと、テスト、練習、および改訂セッションに関するパフォーマンス パターンに基づいてグループ化されます。 各ユーザーは、数千の属性からなる高次元の特徴空間にマッピングされます。これには、静的な測定と一時的な測定が含まれます。 一時的な尺度でのコホーティングにより、初期アクティビティに基づいてこれらのユーザーに推定コホート トラジェクトリを割り当てることで、低アクティビティおよび新規ユーザーをコールド スタートすることができます。 ユーザー コホーティングは、マイクロ適応学習、自動フィードバック生成、コンテンツ レコメンデーションなど、より高度なディープ サイエンス機能のコア要件です。
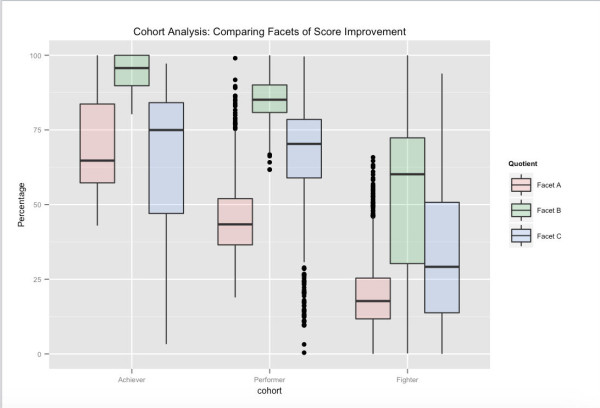
ユーザー コホートの 1 つの考えられるビュー – 長期的なテスト パフォーマンスに関連付けられています。 全体的なテスト スコアに基づいて、Achibers は Embibe のユーザーの上位パーセンタイル ブラケット、Performers は次のブラケット、Fighters は最終ブラケットです。 示されているさまざまな側面は、特徴空間をクラスター化したスコア改善のさまざまな側面に関連しています。 たとえば、Facet_A はコホート間で大きく異なりますが、フィードバックを他の学習ファセットに向けて影響を与えることで、ユーザーを次の上位コホートに押し込むことができることがわかります。
マイクロ適応学習
オンラインで効果的に学習するには、コンテンツとフィードバックを簡潔に提供することが重要です。 通常、ユーザーは 30 分から 1 時間オンラインで概念や質問の練習に費やします。 この短い期間内で、時間制限のある各セッションの効果を最大化することが非常に重要です。 各セッションは、学習を最大化するためのユーザーにとっての資産であり、これは一口サイズの戦略で最もよく達成されます. 練習セッション用のマイクロ適応エンジンは、ユーザーのプロファイルとコホートの属性を、11,000 の (そして増え続けている) 連結された概念のメタ属性のナレッジ ツリーと共に入力として受け取り、質問の順序付け、提供されるヒント、およびちょうど-インタイムのインテリジェントなインライン フィードバックは、ユーザーに正確に適応し、どんな小さな目標でも学習成果を向上させます。 コンテンツやフィードバックを少しずつ消費することで、広範な概念のナレッジ ツリーに対するユーザーの習熟度の調整に影響を与えます。 疎行列処理技術、アイテム応答理論、およびグラフ アルゴリズムは、学習のマイクロ適応性を導きます。
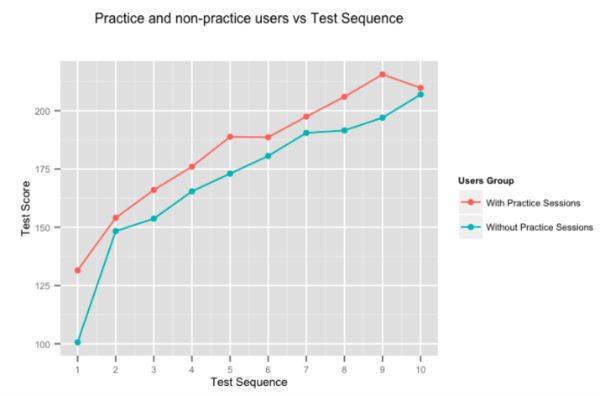
練習すれば完璧になることは明らかですが、とにかく数字を実行することにしました。 上の図は、アダプティブ プラクティス セッションに時間を費やすユーザーとそうでないユーザーが実施した一連のテストについて、ユーザーの平均スコアの改善を示しています。 Embibe で練習しているユーザーは、そうでないユーザーよりも一貫してほぼ 10% のテスト オン テストでスコアを上回っています。
フィードバックと推奨システム
Embibe のフィードバックおよびレコメンデーション システム (既に特許を申請済み) は、ユーザーのスコアの改善を最大化するという 1 つの目的のために設計および構築されています。 練習およびテストセッション中のユーザーの試みに関する何千もの信号を計測して解釈し、これらの信号を各ユーザーの何千もの機能の高次元空間に変換します。 大規模なユーザー試行機能スペースで統計パターン マイニングを使用して、ユーザーのスコアを積極的に押し上げるランク付けされた一連のパラメーターに照準を合わせました。 これらのパラメーターは、スコア改善フィードバックの高度に的を絞ったジャストインタイム カプセルとして機械コード化され、ユーザーが練習セッションを続けている間に配信されます。 フィードバックと推奨事項により、スコアを最大化するために採用できる弱点と戦略が明らかになります。
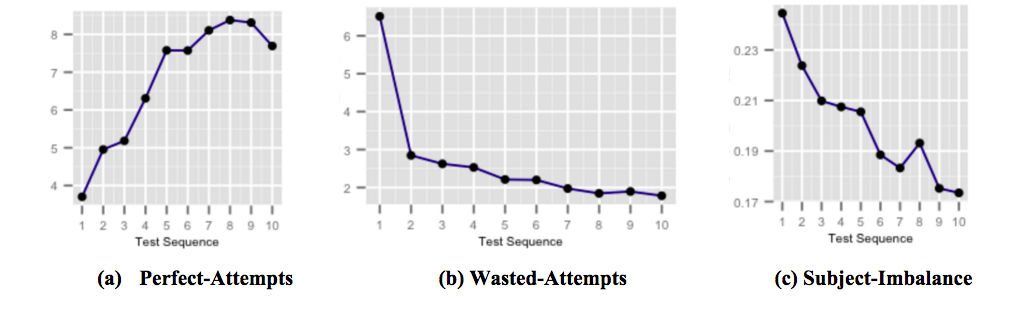
上の図は、スコア向上のための高度に的を絞ったジャストインタイム フィードバック カプセルが、ユーザーがさらされたときに生徒のパフォーマンスにどのように影響し、一般的なテスト受験の落とし穴に気付くかを示しています。 図 (a) は、連続したテストで増加する完全な試行の平均数を示しています。 完全試行とは、規定された時間内に正しく回答された試行です。 図 (b) は、連続したテストで減少する無駄な試行の平均回数を示しています。 無駄な試行とは、学生が問題について考えるのに費やすことができたはずのより多くの時間を持っていたにもかかわらず、誤って回答された試行です. また、図 (c) は、平均的な被験者精度の不均衡が連続したテストで減少していることを示しています。 被験者の精度の不均衡は、ユーザーが受けたテストのすべての被験者の最高精度と最低精度の差として定義されます。 主題精度の不均衡が高いということは、ユーザーが特定の主題に対して他の主題に比べて準備ができていないことを意味します。
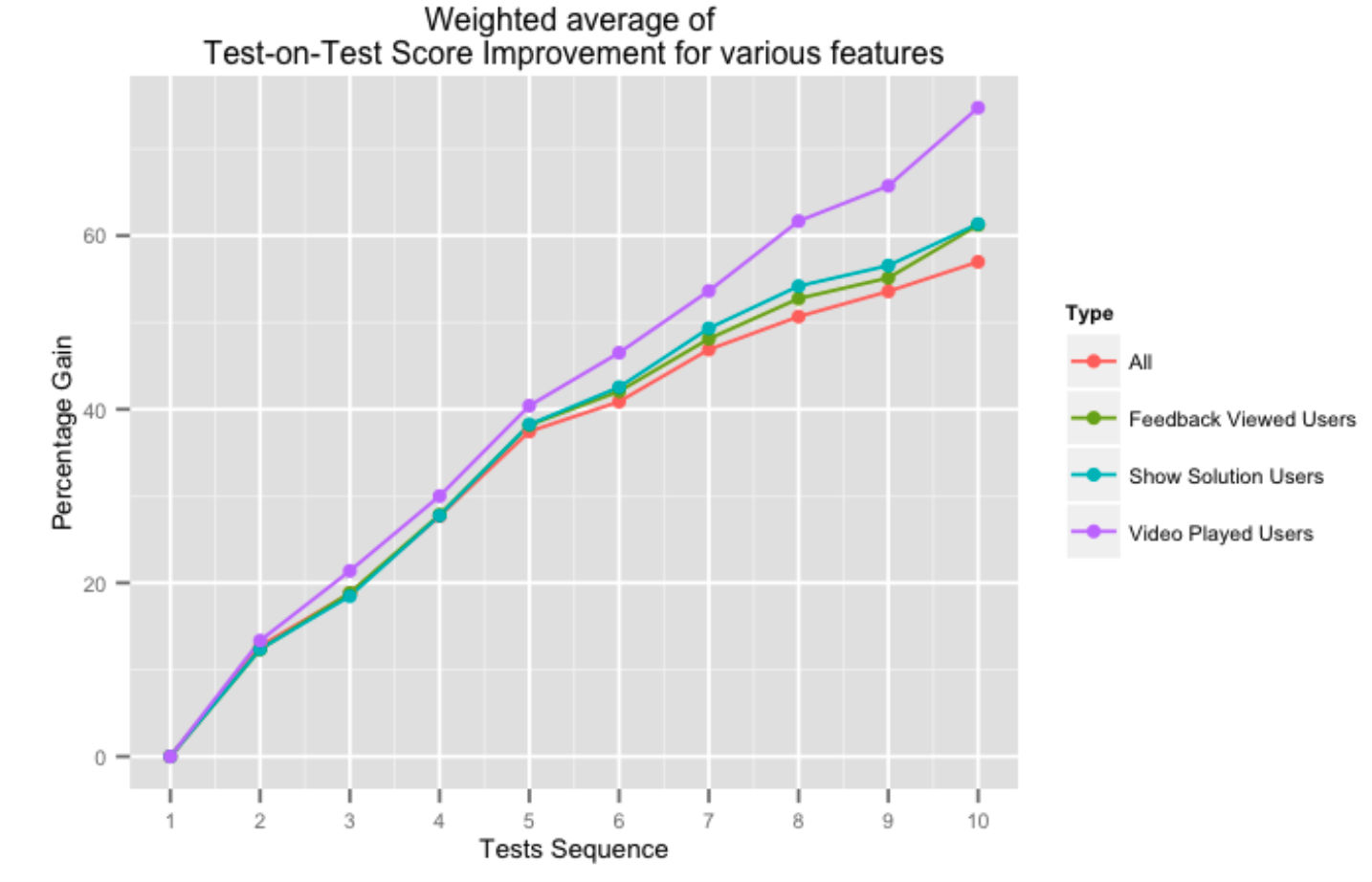
上の図は、フィードバック システムのさまざまな側面を利用したユーザーの連続テスト オン テスト スコアの増加率を示しています。 ビデオ ソリューションまたは全体的なテスト フィードバックの形で当社のプラットフォームから支援を受けることは、特にユーザーがより多くのテストを完了するにつれて、テスト オン テストのスコアにプラスの影響を与えます。
スコア改善の見積もり
あらゆる種類の試験の準備をしているユーザーにとって、スコアの向上は学習成果に影響を与える最も重要な側面です。 Embibe でのテスト中およびテスト後のユーザーの行動がスコアの向上にどのように影響するかを測定することにより、豊富な行動データにより、ユーザーの過去の行動から学ぶことができます。 さまざまなユーザー コホートにおける使用、アクティビティ、および行動機能の統計パターンのデータ マイニングにより、プラットフォームの有効性を科学的に裏付けた証拠が得られます。
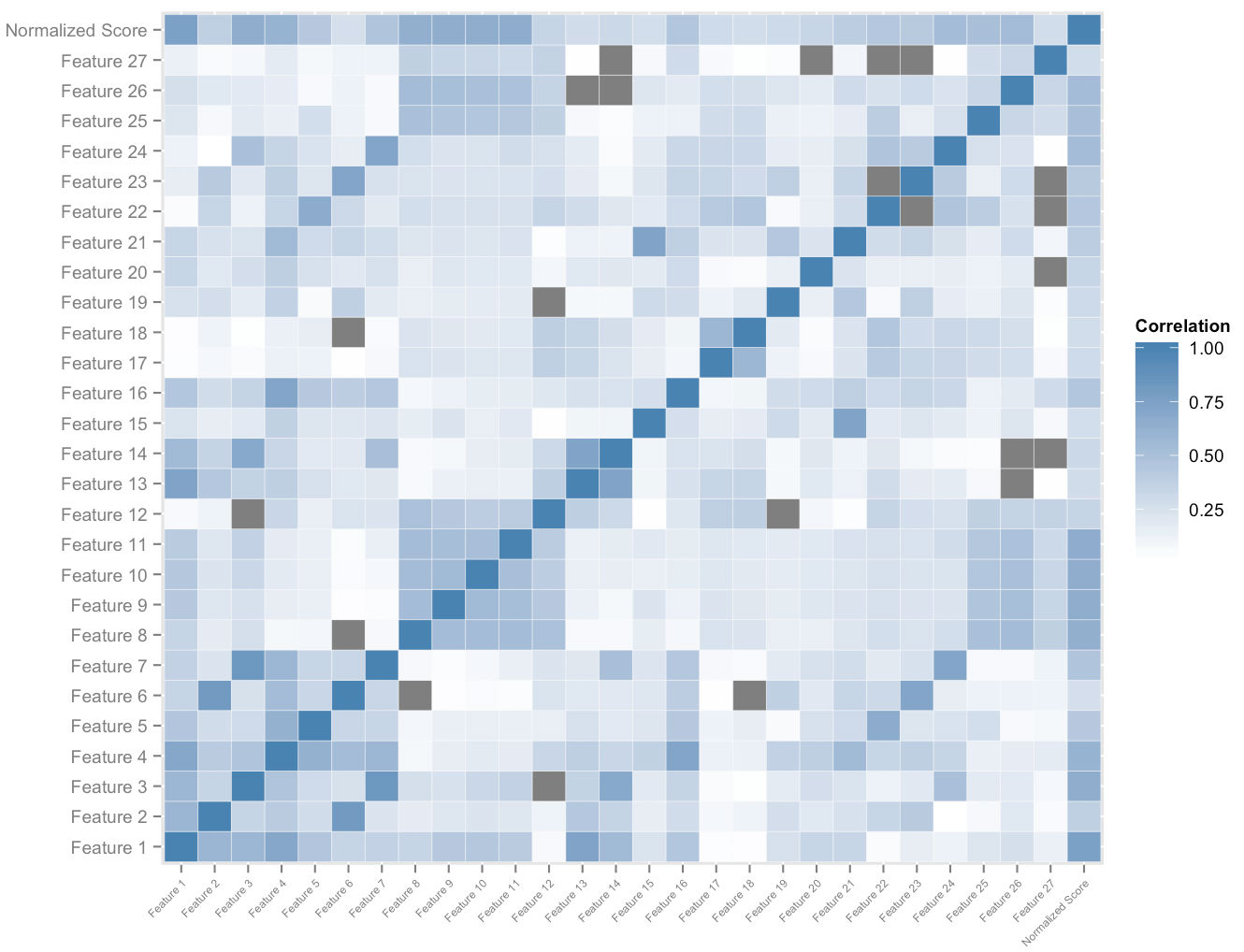
上の図は、ユーザーごとに構築する特徴空間のサブセットを示しています。 特徴空間と全体的な正規化されたスコアの相互相関分析により、相対的な特徴の重要度に関する順序付けが得られます。 これは、経験的優位性分析と合わせて、スコア改善への貢献に対する各機能の影響の量を測定することを可能にします。 これらの機能の最も重要な速度の適切に重み付けされた組み合わせにより、各生徒に潜在的なスコア改善の尺度を定量的に割り当てることができます。
特にインドやその他の発展途上国では、教育分野にとって刺激的な時代です。 教育と学習を次のレベルに引き上げるために、データとそれが提供できる洞察の使用に重点を置いて、深い科学を適用することが緊急に必要です。 当社のコンテンツ取り込みおよび配信プラットフォームは、確固たる科学的原則に基づいて構築されており、制限された準備期間内でスコアを改善するという形で、Embibe の計り知れない価値をユーザーが実現するのに役立っています。 コホート分類と行動特性に基づいてユーザーに合わせて正確に調整された、ユーザー固有のフィードバックと推奨事項を利用する当社のマイクロアダプティブ学習フレームワークにより、ユーザーは Embibe で充実した体験をすることができます。 これらは、学習成果にプラスの影響を与えるという問題を解決するための最初の具体的なステップです。 これが個別学習です。
この投稿では、学習成果に影響を与える道に沿って私たちを動かすために解決する必要があるさまざまなサブ問題に触れました. 次の投稿では、Embibe でユーザーとその活動に関連するさまざまな指標をどのように測定および追跡するかについて説明します。オンライン学習の目的地。
私たちは、データ サイエンス ラボの仲間に加わってくれる邪悪な賢い人々を常に探しています。 仮説のテスト、回帰の実行、巨大な行列の因数分解、ビッグデータに直面したときの笑い、map-reduce ジョブの開始、乱雑な非構造化テキストに対するトピック モデルの構築、ノイズの多いデータの統計パターンのマイニング、オープン データからの大量のデータの取り込みが好きな方ソース、p 値の議論、ニューラル ネットワークと深い信念ネットのトレーニング、Python と R の切り替え、ビジュアライゼーションのスピンアップ、シェルのスクリプト作成など、ここで気に入るはずです!
履歴書を添えて、jobs.<id>@embibe.com までご連絡ください。
<id> は、正規分布の確率密度関数の値のゼロ以外の最初の 8 桁で形成され、19 桁の精度に丸められた数値です。
mu はパドバン数列の 26 番目の数です。
sigma は、1 から始まるフィボナッチ数列の 17 番目の数です。
x は 1002 番目の素数
私たちのチームは、Keyur Faldu (チーフ データ サイエンティスト)、 Achint Thomas (プリンシパル データ サイエンティスト)、 Chintan Donda (データサイエンティスト) で構成されています。
参考文献
- 学習スタイルのインベントリ. ローレンス、カンザス州: 価格システム。
- グレゴクAF、(1982)。 マインド スタイル モデル: 理論、原則、およびアプリケーション。 マサチューセッツ州メイナード: Gabriel Systems.
Embibe は最近、教育データ分析の主要企業の 1 つとして市場で 3 年間を過ごしました。 2016 年 3 月だけで、学生はこの製品に 10 万時間を費やしましたが、有料マーケティングへの投資はまったくありませんでした。