
300 milhões de estudantes, 300 bilhões de insights – apaixonados por dados na educação
Publicados: 2016-04-07Uma visão interna exclusiva do laboratório de ciência de dados da Embibe
[Esta é a segunda parte da série Como estamos usando a tecnologia profunda e a ciência de dados para personalizar a educação]
Construímos a Embibe com uma visão singular: maximizar os resultados de aprendizagem em escala. Causar um impacto positivo no resultado de aprendizagem de um usuário é um problema difícil, mas importante, de resolver. Na verdade, existem vários subproblemas abertos não triviais, cada um dos quais precisa ser resolvido para atingir o objetivo elevado de afetar intencionalmente e positivamente os resultados da aprendizagem.
Mas primeiro, quais são os resultados da aprendizagem? E por que nos importamos com eles?
No mundo altamente competitivo de hoje, um aluno é medido em grande parte por quanto ele pode marcar em um exame competitivo ou até mesmo na sala de aula da escola. Sua pontuação pode ter um impacto significativo em suas opções de carreira. Para os propósitos deste artigo, vamos enquadrar os resultados de aprendizagem em função do potencial inato e treinável de um aluno, para aprender, absorver e aplicar o conteúdo de maneira otimizada, dentro de restrições de tempo estritamente especificadas; para que ela possa maximizar sua pontuação em qualquer contexto acadêmico competitivo específico.
Em países em desenvolvimento, como a Índia, a proporção aluno-professor é altamente distorcida e os professores não podem efetivamente fornecer atenção personalizada em nível individual. Isso leva a um dilema, uma vez que cada aluno aprende e absorve informações em ritmos diferentes e tem diferentes níveis de aptidão. Um conhecido efeito colateral da incapacidade dos professores de fornecer atenção personalizada é que, para qualquer sala de aula/coleção de alunos, o material de aprendizagem é sempre apresentado para atender ao aluno “médio”. Portanto, alunos muito brilhantes não atingem todo o seu potencial e não serão capazes de realmente flexionar seus músculos acadêmicos, enquanto alunos escolarmente mais fracos terão dificuldade em lidar com o resto da sala de aula. No entanto, as plataformas e sistemas de aprendizado on-line existentes não são capazes de realmente facilitar o aprendizado personalizado no nível do aluno.
A maioria dos sistemas atuais considera apenas o quão bem um aluno pode combinar suas soluções para testar módulos conforme especificado por algum administrador do sistema. O aprendizado personalizado para exames competitivos deve maximizar a pontuação de um aluno para qualquer objetivo acadêmico no tempo limitado disponível para ele. A aprendizagem personalizada também deve abordar de forma construtiva as lacunas de habilidade do aluno, não apenas no nível de conhecimento ou aptidão, mas também nos níveis atitudinal e comportamental. Esta falta de ferramentas eficazes de aprendizagem personalizada, adaptadas especificamente e precisamente para cada aluno, é responsável por ela não ser capaz de realizar seu potencial em alcançar a pontuação máxima possível em qualquer exame.
Neste artigo, a equipe de ciência de dados da embibe estabelecerá as bases dos vários problemas relacionados a dados interconectados que precisam ser abordados para maximizar os resultados de aprendizado e, especificamente, a melhoria da pontuação. Existem duas dimensões principais para este problema – Ingestão de Conteúdo e Entrega de Conteúdo. Cada dimensão apresenta desafios únicos em várias áreas que certamente fascinarão qualquer cientista de dados.
Ingestão de conteúdo
Ingestão automática de conteúdo
Dezenas de quadros de programas, milhares de capítulos e conceitos e dezenas de milhares de institutos e escolas resultam em centenas de milhares de perguntas e respostas geradas e usadas por instrutores todos os anos. Imagine se todos os alunos fossem capazes de testar seus conhecimentos antes dos exames em qualquer subconjunto, ou em todas essas perguntas, além de obter explicações detalhadas sobre as respostas corretas e os erros comuns cometidos. Para tornar isso realidade, estamos aproveitando o reconhecimento óptico de caracteres (OCR) e o aprendizado de máquina para construir nossa própria estrutura de ingestão automatizada que será altamente escalável, verdadeiramente multilíngue e minimamente dependente da entrada humana. E a diversão não para por aí. A estrutura também será capaz de ingerir conteúdo manuscrito de maneira independente do escritor, aumentando rapidamente nosso já fantástico repositório de perguntas, respostas, conceitos, explicações e conhecimento.
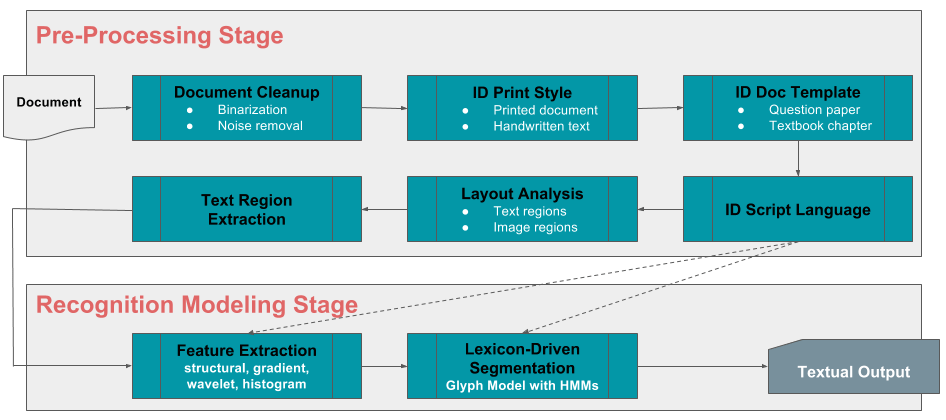
Marcação de conceito
Tudo bem, agora temos perguntas, respostas, conceitos e capítulos, todos ingeridos em um enorme data warehouse. Seria doloroso marcar manualmente cada pergunta ou capítulo com seus conceitos relevantes, ou vice-versa. Ciência de dados ao resgate! Usando ideias de ponta de classificação de texto, modelagem de tópicos e aprendizado profundo, nós automaticamente marcamos conceitos para perguntas, respostas e capítulos.

Uma seleção dos conceitos mais populares navegados pelos usuários do Embibe usando o recurso Aprender, nos meses de dezembro de 2015, janeiro de 2016 e fevereiro de 2016.
Nossos bancos de dados anteriores contendo conjuntos de sementes de conteúdo com tags manuais de alta qualidade são fundamentais, pois extraímos recursos linguísticos, lexicais e sensíveis ao contexto, para treinar modelos de tag de texto de última geração para todos os novos dados que são ingeridos em nosso sistemas.
Enriquecimento de metadados
Há uma riqueza de informações disponíveis on-line hoje sobre qualquer tópico sobre o qual se deseja aprender. Ideias e conceitos são construídos uns sobre os outros. Por exemplo, a Primeira Lei da Termodinâmica está relacionada ao conceito de sistema termodinâmico, que por sua vez está relacionado aos conceitos de capacidade calorífica específica dos gases, conservação da energia mecânica e trabalho realizado por um gás, entre outros. Nossa estrutura de ingestão de conteúdo inclui componentes de enriquecimento de dados que rastreiam automaticamente a Web e marcam conteúdo com diversas mídias como explicações de texto, links de vídeo, definições, comentários de usuários e discussões em fóruns, tudo isso respeitando os direitos autorais e atribuindo adequadamente a propriedade do conteúdo de origem . Essa riqueza de informações disponíveis também permite conectar automaticamente conceitos relacionados em uma estrutura de árvore. Usando idéias dos campos da teoria dos grafos, mineração de texto e propagação de rótulos em estruturas esparsas, criamos links e interconexões entre conceitos que compartilham uma relação origem→destino.
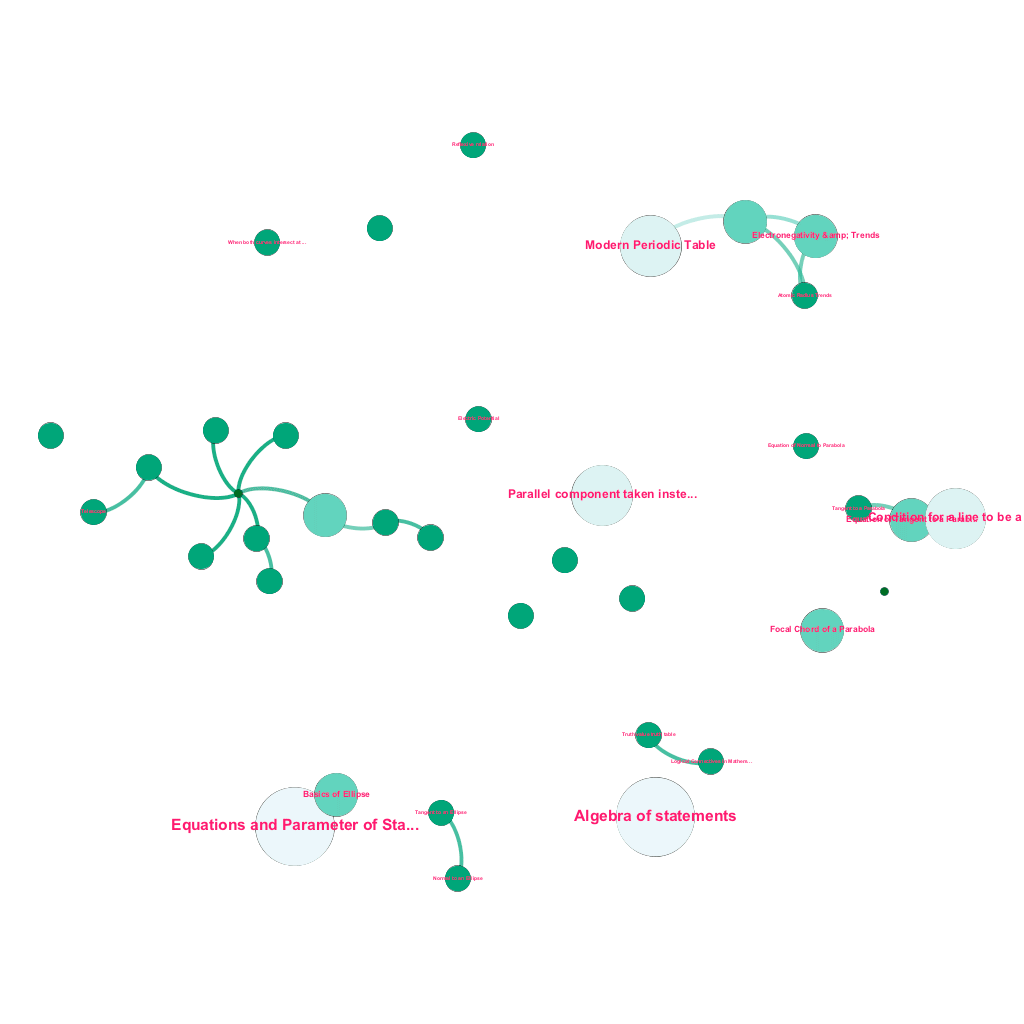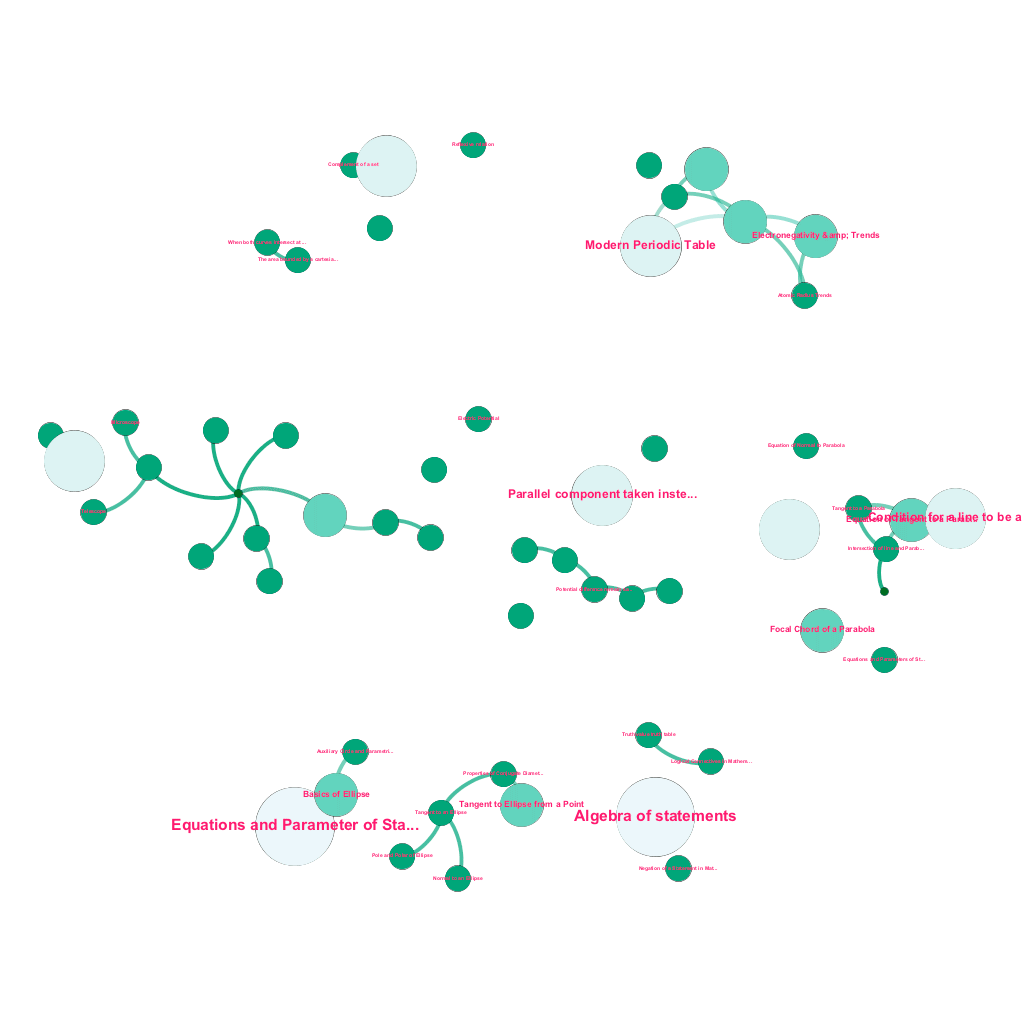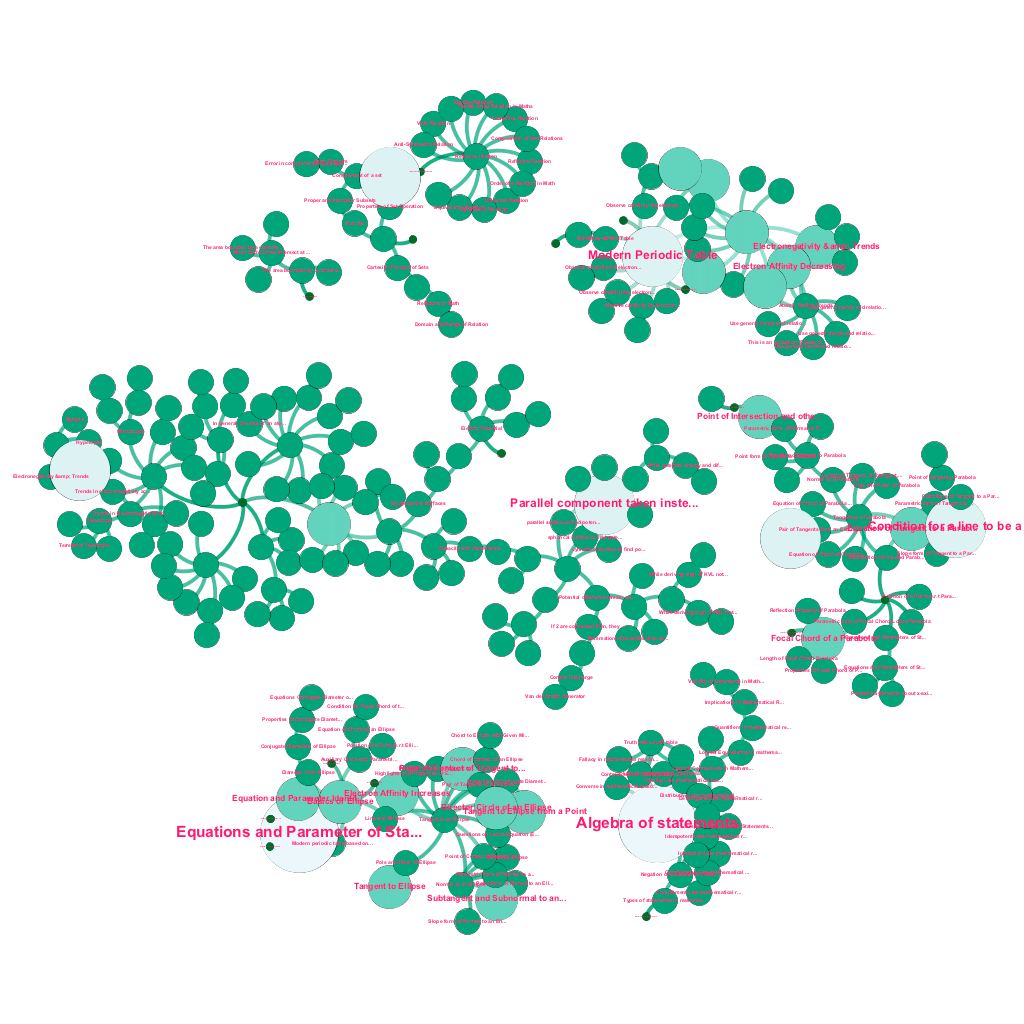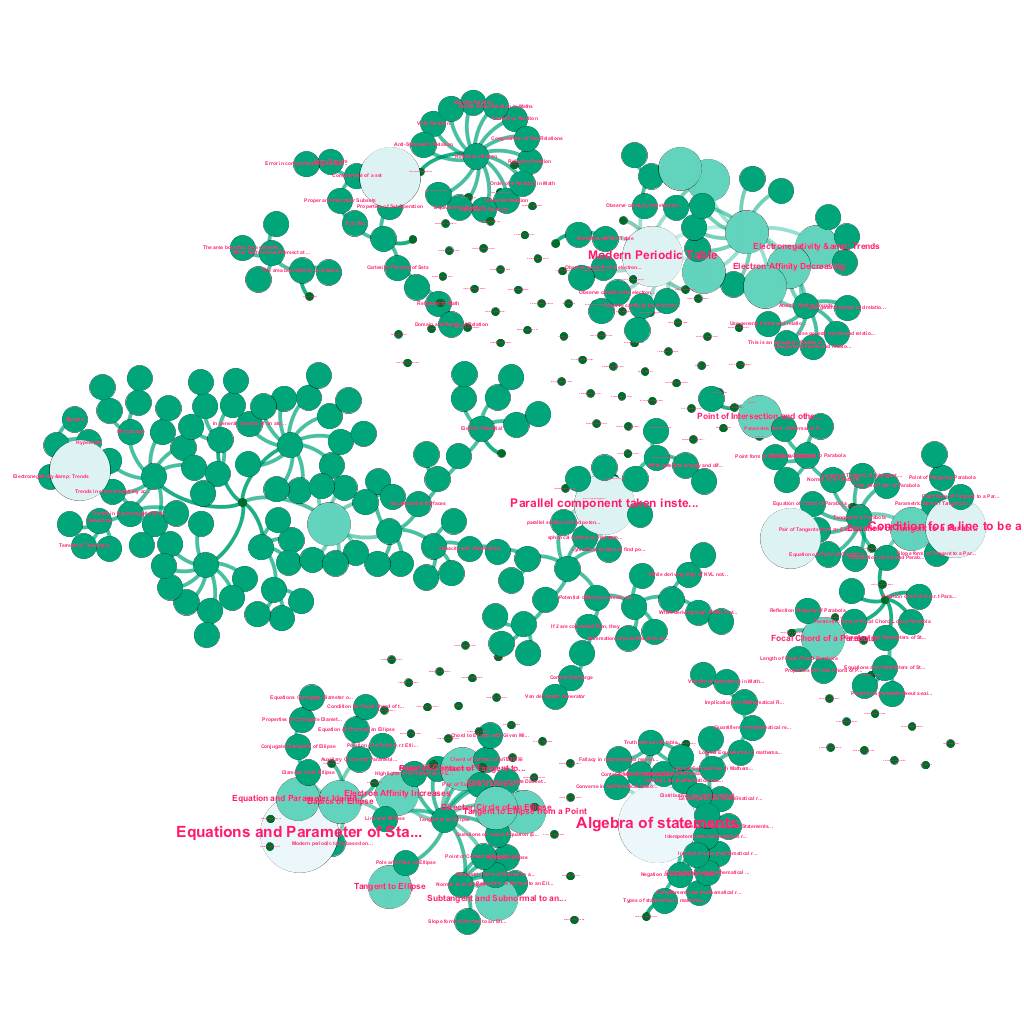
Construção automatizada de uma árvore de conceitos, para um subconjunto de ideias da Matemática, cada uma conectada a um ou vários conceitos relacionados
Agrupamento de perguntas semelhantes
Se você estivesse se preparando para um exame, gostaria de praticar a mesma pergunta várias vezes? Isso não seria útil. Por outro lado, imagine como seria imensamente útil praticar um pequeno conjunto de perguntas relevantes que o ajudariam a dominar completamente algum novo conceito ou capítulo. Com nosso acesso a centenas de milhares de perguntas, desenvolvemos a capacidade de agrupar perguntas com base na semelhança em várias dimensões – conteúdo direcionado, testado por conceito, nível de dificuldade e objetivos do exame, entre outros.
O agrupamento de texto baseado em espaços de informação semântica latente e sua combinação com outros espaços de características categóricas e numéricas nos permitem agrupar com precisão nosso universo de perguntas em áreas de interesse que podem ser adaptadas para cada indivíduo usando o Embibe. Além disso, esse rico recurso de dados textuais que transformamos em robustos espaços numéricos de recursos relacionados a clusters conceituais nos permite perturbar levemente os dados existentes para gerar expressões potencialmente infinitas do espaço de perguntas. Mais perguntas em tempo de execução, nunca visto antes! Isso nos permite oferecer aos usuários o valor máximo pelo tempo gasto em nossa plataforma.
Entrega de conteúdo
Perfil do usuário
Nós rastreamos cada movimento que um usuário faz no Embibe. As milhões de tentativas de prática e teste feitas por nossos usuários nos últimos três anos são calibradas em um espaço de dados de muitos milhares de dimensões. Isso se traduz em um espaço de bilhões de pontos de dados que podemos explorar para aprofundar os dados comportamentais de nossos usuários e gerar insights que se correlacionam com a forma como o aprendizado acontece. Cada tentativa adicional de um usuário ajusta sua capacidade de pontuar mais alto nos conceitos marcados para essa tentativa, juntamente com os conceitos anteriores e posteriores conectados. Esse problema super complexo envolve o aproveitamento de ideias de processamento de matrizes esparsas, algoritmos computacionais em teoria de grafos e teoria de resposta de item para construir perfis de usuário robustos e adaptáveis que se adaptam à nossa crescente base de usuários.
Recomendado para você:

O que significa a provisão antilucratividade para startups indianas?

Como as startups de Edtech estão ajudando a qualificação da força de trabalho da Índia e se preparando para o futuro

Ações de tecnologia da nova era esta semana: os problemas do Zomato continuam, EaseMyTrip publica...

Startups indianas pegam atalhos em busca de financiamento

Plataforma de marketing digital Logicserve Bags Financiamento de INR 80 Cr, renomeia como LS Dig...

Relatório adverte sobre o escrutínio regulatório renovado no espaço Lendingtech
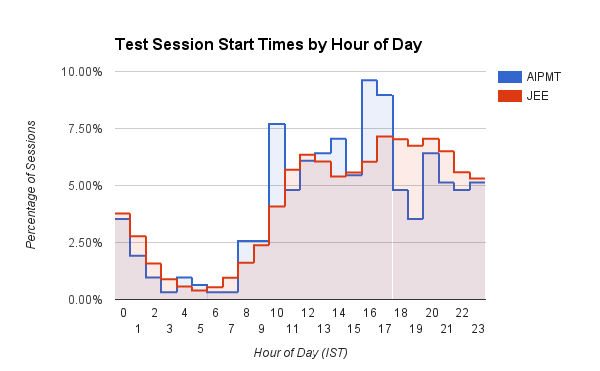
Um gráfico de barras interessante que mostra a hora (hora do dia no IST) em que os usuários iniciam suas sessões de teste no Embibe. Os usuários médicos (AIPMT) têm um pico definido por volta das 10h e entre 15h e 17h. Os usuários de engenharia (JEE), por outro lado, mostram um aumento gradual dos horários de início das sessões à medida que o dia avança, com picos por volta das 16h às 20h. Os alunos da JEE também começam consistentemente mais sessões de prática entre as 17h e as 3h em comparação com os alunos da AIPMT. Estamos supondo que os médicos são mais disciplinados!

Nossa extensa instrumentação e medição da atividade do usuário em um nível muito granular nos dá a capacidade de inferir preferências latentes relacionadas a estilos de aprendizagem associados a usuários individuais. Por exemplo, certos alunos podem aprender e, posteriormente, ter um desempenho melhor com a ajuda de explicações em vídeo, em comparação com outros alunos que preferem descrições textuais extensas, ou ainda outros que aprendem trabalhando passo a passo por meio de exemplos resolvidos. Podemos mapear os usuários para modelos teóricos bem estudados de estilos de aprendizagem, como o Modelo de Dunn e Dunn (Dunn & Dunn 1989), ou o Modelo de Estilos da Mente de Gregorc (Gregorc 1982) para adaptar automaticamente cursos de prática corretiva e ajudar o usuário a melhorar a pontuação.
Coorte de usuários
Coorte é um problema clássico de agrupamento. Os usuários são agrupados com base em seus padrões de uso em relação aos recursos do produto, bem como em seus padrões de desempenho em relação às sessões de teste, prática e revisão. Cada usuário é mapeado para um espaço de recursos de alta dimensão com muitos milhares de atributos, que incluem medidas estáticas e temporais. A coorte em medidas temporais nos dá a capacidade de iniciar a baixa atividade a frio e novos usuários, atribuindo prováveis trajetórias de coorte a esses usuários com base em sua atividade inicial. A coorte de usuários é um requisito essencial para nossos recursos de ciência profunda de nível superior, como aprendizado microadaptativo, geração automatizada de feedback e recomendação de conteúdo.
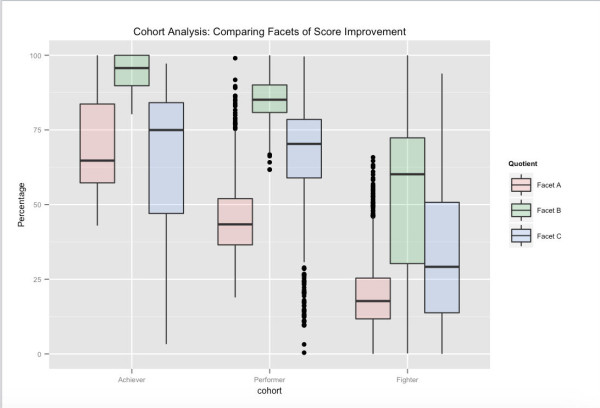
Uma visão possível de coortes de usuários – vinculada ao desempenho de teste de longo prazo. Com base nas pontuações gerais dos testes, os Empreendedores são a faixa de percentil superior de usuários em Embibe, os Artistas a próxima faixa e os Lutadores a faixa final. As várias facetas mostradas estão relacionadas a diferentes aspectos de melhoria de pontuação nos quais agrupamos nosso espaço de recursos. Por exemplo, podemos ver que, embora Facet_A varie significativamente entre as coortes, ao direcionar o feedback e afetar outras facetas de aprendizado, é possível empurrar os usuários para a próxima coorte superior.
Aprendizagem microadaptativa
A entrega de conteúdo e feedback em tamanho reduzido é a chave para o aprendizado online eficaz. Geralmente, os usuários passam entre 30 minutos a uma hora online, praticando conceitos e perguntas. Dentro desse curto período de tempo, é muito importante maximizar o impacto de cada sessão com limite de tempo. Cada sessão é um recurso para o usuário maximizar o aprendizado, e isso é melhor realizado com a estratégia de tamanho reduzido. Nosso mecanismo de microadaptação para sessões práticas, leva o perfil de um usuário e atributos de coorte junto com nossa árvore de conhecimento de 11.000 (e crescendo!) meta-atributos de conceitos interligados como entrada, e garante que o sequenciamento de perguntas, dicas fornecidas e apenas- O feedback in-line inteligente em tempo real se adapta precisamente ao usuário para melhorar seu resultado de aprendizado em qualquer objetivo pequeno. Cada pequeno consumo de conteúdo ou feedback afetará a calibração de proficiência do usuário em relação à nossa extensa árvore de conceitos de conhecimento. Técnicas de processamento de matrizes esparsas, teoria de resposta ao item e algoritmos de grafos orientam a micro adaptabilidade do aprendizado.
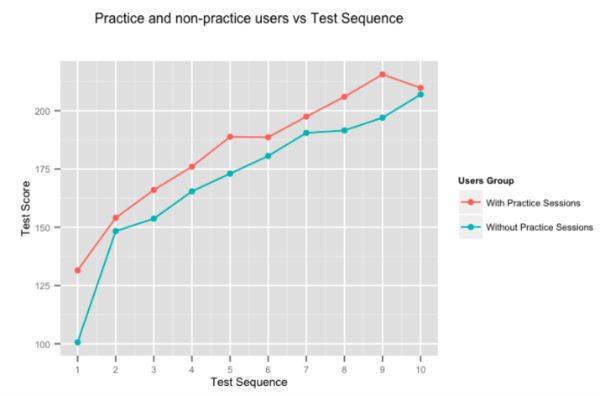
É bastante óbvio que a prática torna a pessoa perfeita, mas decidimos executar os números de qualquer maneira. A figura acima mostra a melhoria da pontuação média dos usuários, para testes sucessivos dados por usuários que gastam tempo em nossas sessões de prática adaptativa e aqueles que não o fazem. Os usuários que praticam no Embibe superam consistentemente aqueles que não praticam em quase 10% teste-a-teste.
Sistema de feedback e recomendação
O sistema de feedback e recomendação da Embibe (no qual já registramos patentes) foi projetado e construído para um propósito – maximizar a melhoria da pontuação de um usuário. Instrumentamos e interpretamos milhares de sinais sobre as tentativas de um usuário durante as sessões de prática e teste e transformamos esses sinais em um espaço de alta dimensão de milhares de recursos para cada usuário. Usando a mineração de padrões estatísticos em nosso enorme espaço de recursos de tentativa de usuário, nos concentramos nos conjuntos de parâmetros classificados que aumentam positivamente a pontuação de um usuário. Esses parâmetros são codificados por máquina como cápsulas just-in-time altamente direcionadas de feedback de melhoria de pontuação e entregues ao usuário enquanto ele continua com sua sessão de prática. O feedback e as recomendações expõem fraquezas e estratégias que ela pode adotar para maximizar sua pontuação.
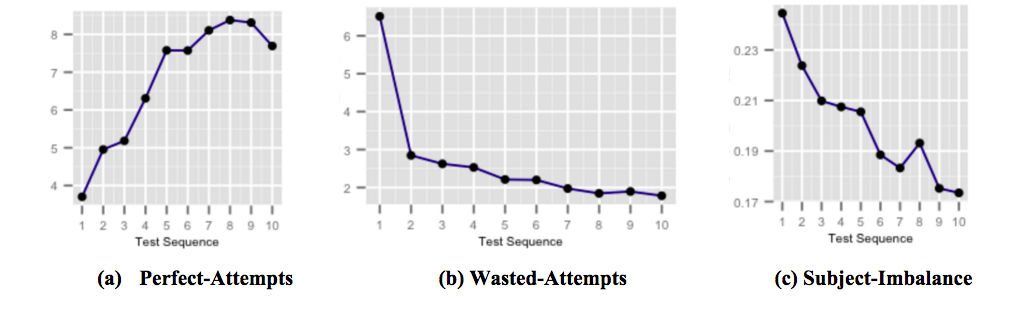
As figuras acima mostram como nossas cápsulas de feedback just-in-time altamente direcionadas para melhoria de pontuação afetam o desempenho do aluno à medida que o usuário é exposto e fica ciente das armadilhas comuns ao fazer o teste. A Figura (a) mostra o número médio de tentativas perfeitas aumentando ao longo de testes sucessivos. Tentativas-perfeitas são tentativas que são respondidas corretamente dentro de algum tempo estipulado. A Figura (b) mostra o número médio de tentativas desperdiçadas diminuindo ao longo de testes sucessivos. Tentativas desperdiçadas são tentativas que são respondidas incorretamente onde o aluno teve mais tempo que poderia ter sido gasto pensando sobre a questão. E a figura (c) mostra a média do desequilíbrio sujeito-precisão diminuindo ao longo de testes sucessivos. O desequilíbrio de precisão de assunto é definido como a diferença entre a maior e a menor precisão entre todos os assuntos em qualquer teste realizado por um usuário. Um maior desequilíbrio de precisão de assunto implica que o usuário está menos preparado para determinados assuntos em comparação com outros assuntos.
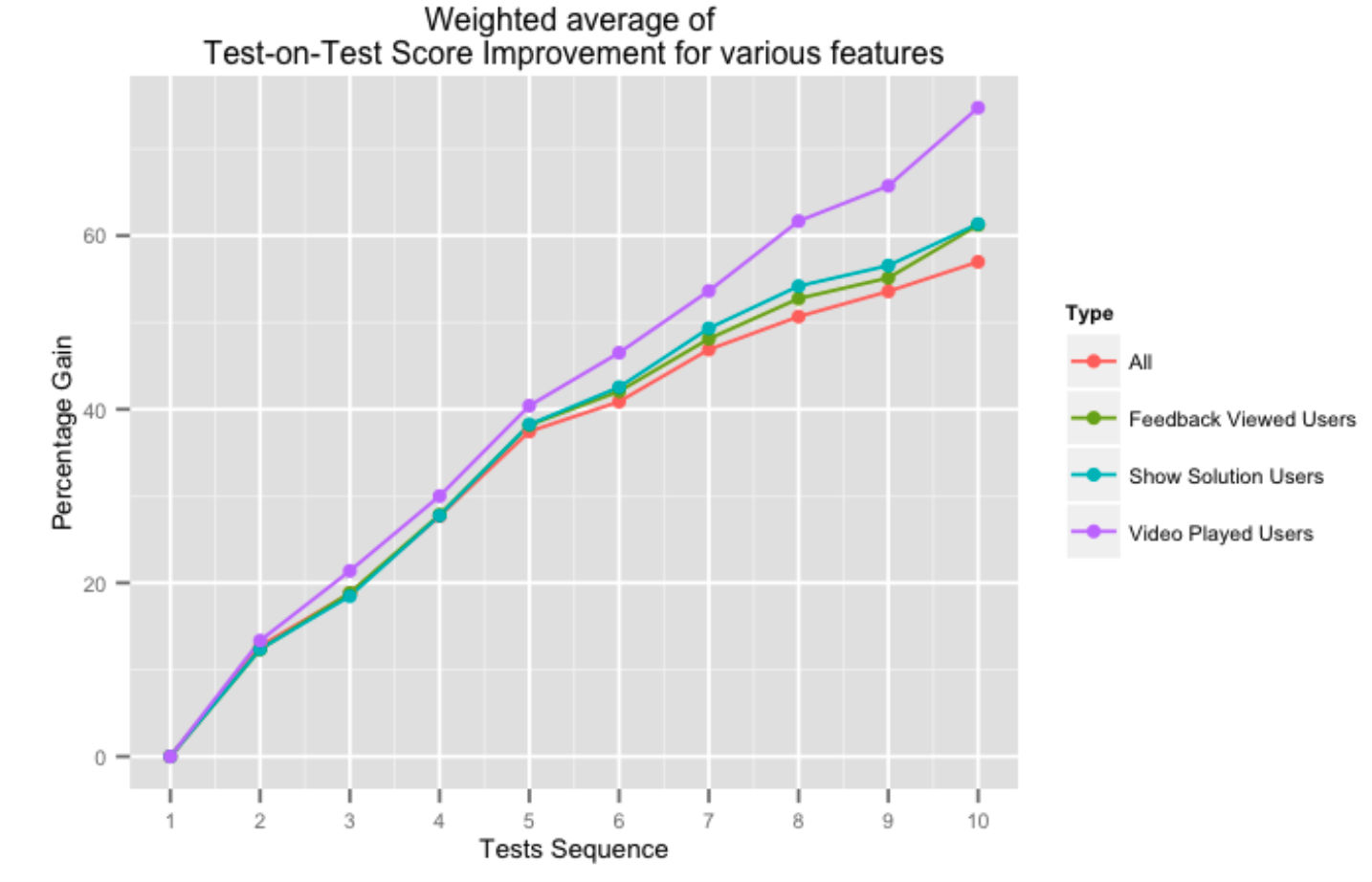
A figura acima mostra o ganho percentual em pontuações sucessivas de testes para usuários que utilizam vários aspectos do nosso sistema de feedback. Receber ajuda de nossa plataforma na forma de soluções de vídeo ou feedback geral do teste afeta positivamente as pontuações de teste em teste, especialmente quando o usuário conclui mais testes.
Estimativa de melhoria de pontuação
Para os usuários que estão se preparando para exames de qualquer tipo, a melhoria da pontuação é o aspecto mais importante para afetar os resultados do aprendizado. Nossa riqueza de dados comportamentais nos dá a capacidade de aprender com as ações anteriores dos usuários, medindo como seu comportamento durante e depois de fazer testes no Embibe afeta a melhoria da pontuação. A mineração de dados para padrões estatísticos de uso, atividade e recursos comportamentais, entre vários grupos de usuários, nos dá uma prova científica da eficácia de nossa plataforma.
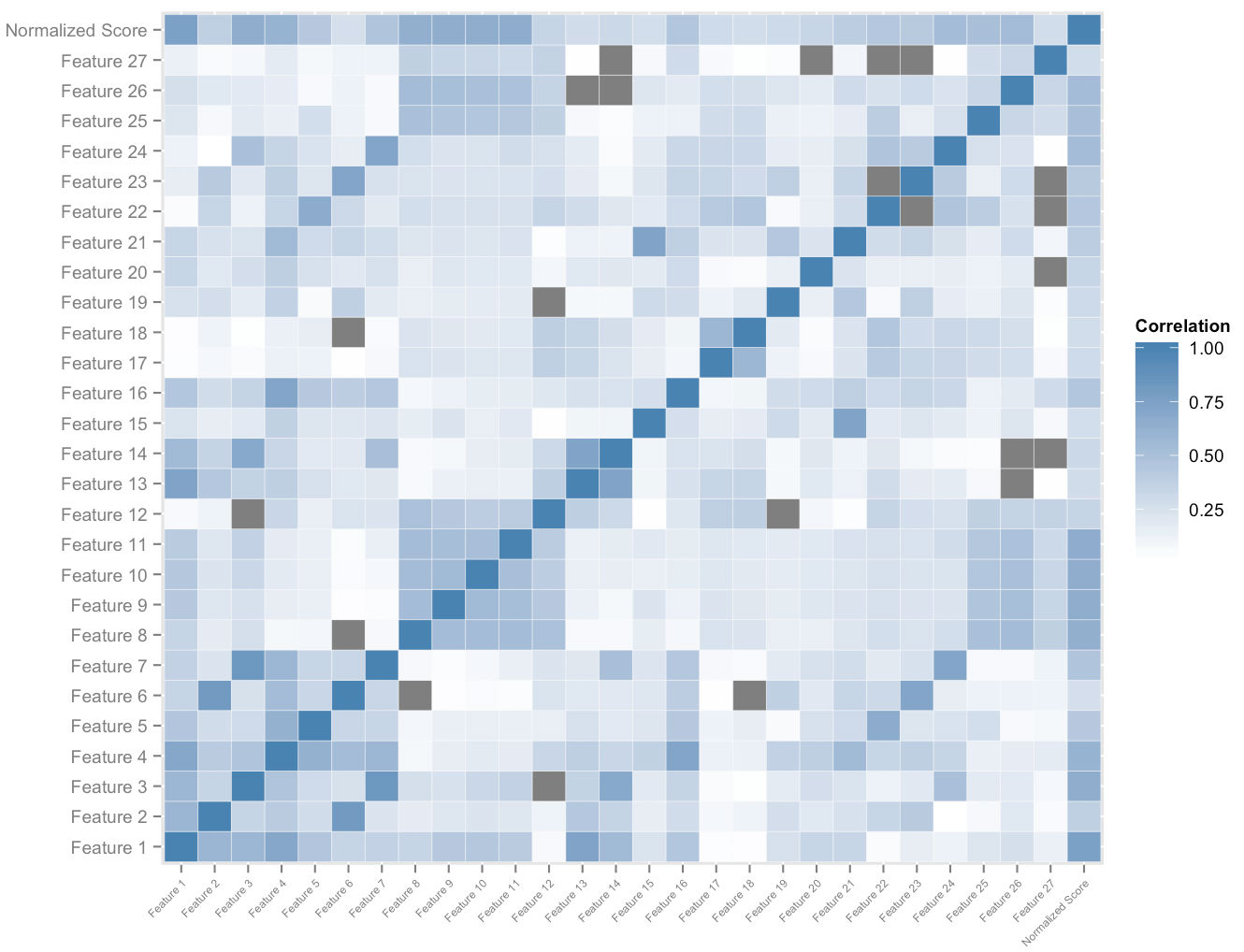
A figura acima mostra um subconjunto do espaço de recursos que construímos por usuário. A análise de correlação cruzada no espaço de recursos e as pontuações normalizadas gerais nos dá uma ordenação da importância relativa dos recursos. Isso, juntamente com a análise de dominância empírica, nos permite medir o quantum de impacto de cada recurso em sua contribuição para a melhoria da pontuação. Uma combinação apropriadamente ponderada das velocidades dos mais importantes desses recursos nos permite atribuir quantitativamente uma medida de melhoria de pontuação potencial a cada aluno, que se adapta a ele à medida que usa a plataforma.
Estes são tempos emocionantes para o campo da educação, especialmente na Índia e em outros países em desenvolvimento. Há uma necessidade urgente de aplicar ciência profunda, com forte foco no uso de dados e nos insights que eles podem fornecer, a fim de levar a educação e o aprendizado para o próximo nível. Nossas plataformas de ingestão e entrega de conteúdo estão sendo construídas com base em sólidos princípios científicos e estão ajudando os usuários a obterem imenso valor no Embibe na forma de melhoria de pontuação dentro de prazos de preparação restritos. Nossa estrutura de aprendizado microadaptável que utiliza feedback e recomendações específicos do usuário, adaptados precisamente aos usuários, com base em suas classificações de coorte e características comportamentais, permitem que os usuários tenham uma experiência gratificante no Embibe. Estes são os primeiros passos concretos para resolver o problema de impactar positivamente os resultados da aprendizagem. Isso é aprendizado personalizado.
Neste post, abordamos vários subproblemas que precisam ser resolvidos para nos mover ao longo do caminho para afetar os resultados da aprendizagem. Em nosso próximo post, falaremos sobre como medimos e acompanhamos diversas métricas na Embibe relacionadas aos nossos usuários e suas atividades, para que possamos acompanhar o pulso de nosso produto, seu crescimento e sua eficácia como um destino de aprendizagem online.
Estamos sempre à procura de pessoas inteligentes e perversas para adicionar às nossas fileiras no Data Science Lab. Se você gosta de testar hipóteses, executar regressões, fatorar matrizes gigantescas, rir na cara de big data, disparar trabalhos de redução de mapa, construir modelos de tópicos sobre texto desestruturado confuso, minerar dados ruidosos para padrões estatísticos, ingerir montanhas de dados de dados abertos fontes, argumentando valores-p, treinando redes neurais e redes de crenças profundas, alternando entre python e R, girando visualizações e scripts de shells, você vai adorar aqui!
Envie-nos o seu currículo em jobs.<id>@embibe.com, onde:
<id> é o número formado com os 8 primeiros dígitos diferentes de zero do valor da função densidade de probabilidade para a distribuição normal, arredondado para 19 dígitos de precisão, e
mu é o 26º número na sequência Padovan, e
sigma é o 17º número na sequência de Fibonacci começando em 1, e
x é o 1002º número primo
Nossa equipe é composta por Keyur Faldu ( Cientista de Dados Chefe), Achint Thomas ( Cientista de Dados Principal) e Chintan Donda ( Cientista de Dados).
Referências
- Inventário de estilos de aprendizagem . Lawrence, KS: Price Systems.
- Gregório AF, (1982). Modelo de estilos mentais: teoria, princípios e aplicações. Maynard, MA: Gabriel Systems.
A Embibe completou recentemente 3 anos no mercado como uma das principais empresas em análise de dados educacionais. Os alunos gastaram mais de 100 mil horas no produto apenas em março de 2016, sem nenhum investimento em marketing pago.