
300 Milyon Öğrenci, 300 Milyar İçgörü – Eğitimde Verilere Aşık
Yayınlanan: 2016-04-07Embibe'nin Veri Bilimi Laboratuvarına Özel Bir Bakış
[Bu, Eğitimi Kişiselleştirmek İçin Derin Teknoloji ve Veri Bilimini Nasıl Kullanıyoruz serisinin ikinci kısmıdır]
Embibe'yi tek bir vizyonla oluşturduk: öğrenme sonuçlarını geniş ölçekte en üst düzeye çıkarmak. Bir kullanıcının öğrenme çıktısı üzerinde olumlu bir etki yaratmak, çözülmesi zor ama önemli bir problemdir. Aslında, öğrenme çıktılarını kasıtlı olarak ve olumlu yönde etkilemeye yönelik yüce hedefi gerçekleştirmek için her birinin çözülmesi gereken bir dizi önemsiz olmayan açık alt problem vardır.
Ama önce, öğrenme çıktıları nelerdir? Ve neden onları önemsiyoruz?
Günümüzün son derece rekabetçi dünyasında, bir öğrenci büyük ölçüde rekabetçi bir sınavda veya hatta okul sınıfında ne kadar puan alabileceğiyle ölçülür. Puanının kariyer seçenekleri üzerinde önemli bir etkisi olabilir. Bu makalenin amaçları doğrultusunda, öğrenme çıktılarını, öğrencinin doğuştan gelen ve eğitilebilir potansiyelinin bir işlevi olarak çerçevelendirelim, kesin olarak belirlenmiş zaman kısıtlamaları dahilinde içerik materyalini en iyi şekilde öğrenme, özümseme ve uygulama; böylece herhangi bir rekabetçi akademik bağlamda puanını en üst düzeye çıkarabilir.
Hindistan gibi gelişmekte olan ülkelerde, öğrenci/öğretmen oranı oldukça çarpıktır ve öğretmenler, bireysel düzeyde kişiselleştirilmiş ilgiyi etkin bir şekilde sağlayamazlar. Bu, her öğrencinin bilgiyi farklı oranlarda öğrenip özümsediği ve farklı yetenek seviyelerine sahip olduğu göz önüne alındığında, bir ikileme yol açar. Öğretmenlerin kişiselleştirilmiş ilgi gösterememesinin bilinen bir yan etkisi, herhangi bir sınıf/öğrenci koleksiyonu için öğrenme materyalinin her zaman "ortalama" öğrenciye hitap edecek şekilde sunulmasıdır. Bu nedenle, çok parlak öğrenciler tam potansiyellerine ulaşamazlar ve akademik kaslarını gerçekten esnetemezler, skolastik olarak daha zayıf öğrenciler ise sınıfın geri kalanıyla başa çıkmakta zorlanırlar. Ancak, mevcut çevrimiçi öğrenme platformları ve sistemleri, öğrenci düzeyinde kişiselleştirilmiş öğrenmeyi gerçekten kolaylaştıramaz.
Mevcut sistemlerin çoğu, yalnızca bir öğrencinin çözümlerini sistemin bazı yöneticileri tarafından belirtildiği gibi test modülleriyle ne kadar iyi eşleştirebileceğini hesaba katar. Rekabetçi sınavlar için kişiselleştirilmiş öğrenim, bir öğrencinin kendisine sunulan sınırlı sürede herhangi bir akademik hedef için puanını en üst düzeye çıkarmalıdır. Kişiselleştirilmiş öğrenme, aynı zamanda, öğrencinin yetenek boşluklarını yalnızca bilgi veya yetenek düzeyinde değil, aynı zamanda tutumsal ve davranışsal düzeylerde de yapıcı bir şekilde ele almalıdır. Her öğrenci için özel olarak ve kesin olarak uyarlanmış kişiselleştirilmiş öğrenim için bu etkili araçların eksikliği, herhangi bir sınavda mümkün olan en yüksek puanı elde etme potansiyelini gerçekleştirememesinden sorumludur.
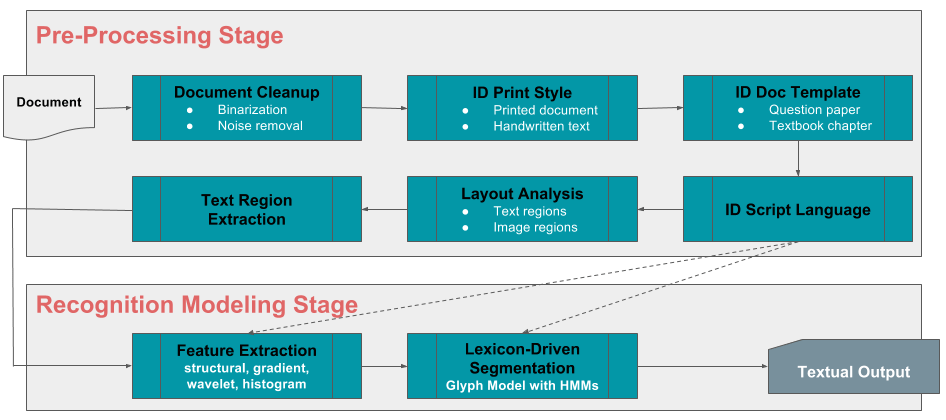
Bu makalede, embebe'nin veri bilimi ekibi, öğrenme sonuçlarını en üst düzeye çıkarmak ve özellikle puan iyileştirmeyi en üst düzeye çıkarmak için ele alınması gereken, birbiriyle bağlantılı çeşitli veriyle ilgili sorunların temelini oluşturacaktır. Bu sorunun iki ana boyutu vardır – İçerik Alımı ve İçerik Teslimatı. Her boyut, herhangi bir veri bilimcisini mutlaka büyüleyecek bir dizi alanda benzersiz zorluklar doğurur.
İçerik Besleme
İçeriğin otomatik olarak alınması
Düzinelerce müfredat panosu, binlerce bölüm ve kavram ve on binlerce enstitü ve okul, her yıl eğitmenler tarafından üretilen ve kullanılan yüz binlerce soru ve cevapla sonuçlanmaktadır. Her öğrencinin sınavlardan önce herhangi bir alt kümede veya tüm bu sorularda bilgilerini test edebildiğini ve doğru cevaplar ve yapılan yaygın hatalar hakkında ayrıntılı açıklamalar aldığını hayal edin. Bunu gerçeğe dönüştürmek için, yüksek düzeyde ölçeklenebilir, gerçekten çok dilli ve minimum düzeyde insan girdisine bağlı olacak kendi otomatik besleme çerçevemizi oluşturmak için optik karakter tanıma (OCR) ve makine öğreniminden yararlanıyoruz. Ve eğlence burada bitmiyor. Çerçeve aynı zamanda yazardan bağımsız bir tarzda el yazısı içeriği alabilecek ve böylece zaten fantastik olan soru, cevap, kavram, açıklama ve bilgi depomuza hızla eklenecektir.
Konsept etiketleme
Pekala, şimdi hepsi büyük bir veri ambarına alınan sorularımız, cevaplarımız, kavramlarımız ve bölümlerimiz var. Her soruyu veya bölümü ilgili kavramlarla manuel olarak etiketlemek veya tam tersini yapmak acı verici olacaktır. Kurtarmaya Veri Bilimi! Metin sınıflandırması, konu modellemesi ve derin öğrenmeden en son fikirleri kullanarak kavramları otomatik olarak sorulara, yanıtlara ve bölümlere etiketliyoruz.

Aralık 2015, Ocak 2016 ve Şubat 2016 aylarında Öğren özelliğini kullanan Embibe kullanıcıları tarafından göz atılan en popüler kavramlardan bir seçki.
Yüksek kaliteli manuel olarak etiketlenmiş içeriğin tohum kümelerini içeren önceki veritabanlarımız, bizim içine alınan tüm yeni veriler için son teknoloji metin etiketleme modellerini eğitmek için dilsel, sözcüksel ve bağlama duyarlı özellikleri çıkardığımız için yararlıdır. sistemler.
Meta veri zenginleştirme
Bugün, bir kişinin öğrenmek istediği herhangi bir konuda çevrimiçi olarak çok sayıda bilgi bulunmaktadır. Fikirler ve kavramlar birbirinin üzerine inşa edilir. Örneğin, Termodinamiğin Birinci Yasası, diğerlerinin yanı sıra gazların özgül ısı kapasiteleri, mekanik enerjinin korunumu ve bir gaz tarafından yapılan iş kavramlarıyla ilgili olan bir termodinamik sistem kavramıyla ilgilidir. İçerik alma çerçevemiz, web'i otomatik olarak tarayan ve içeriği metin açıklamaları, video bağlantıları, tanımlar, kullanıcı yorumları ve forum tartışmaları gibi çeşitli medya parçalarıyla etiketleyen ve bunların tümü telif haklarına saygı duyarak ve kaynaklı içeriğe uygun şekilde sahiplik atfeden veri zenginleştirme bileşenlerini içerir. . Bu mevcut bilgi zenginliği, ilgili kavramları bir ağaç yapısında otomatik olarak bağlamayı da mümkün kılar. Seyrek yapılar üzerinde çizge teorisi, metin madenciliği ve etiket yayılımı alanlarından gelen fikirleri kullanarak, bir kaynak-hedef ilişkisini paylaşan kavramlar arasında bağlantılar ve ara bağlantılar yaratırız.
Her biri bir veya daha fazla ilgili kavramla bağlantılı Matematikten bir fikir alt kümesi için bir kavram ağacının otomatik olarak oluşturulması
Benzer sorular kümeleme
Bir sınava hazırlanıyor olsaydınız, aynı soruyu tekrar tekrar denemek ister miydiniz? Bu yardımcı olmaz. Tersine, yeni bir kavram veya bölümde tamamen ustalaşmanıza yardımcı olacak küçük bir dizi ilgili soru alıştırmasının ne kadar yararlı olacağını hayal edin. Yüz binlerce soruya erişimimizle, diğerlerinin yanı sıra içerik hedefli, konsept testli, zorluk seviyesi ve sınav hedefleri gibi bir dizi boyutta benzerliğe dayalı soruları kümeleme yeteneği geliştirdik.
Gizli anlamsal bilgi alanlarına dayalı metin kümeleme ve bunların diğer kategorik ve sayısal özellik alanlarıyla birleşimi, soru evrenimizi Embibe kullanarak her bireye göre uyarlanabilecek ilgi alanları içinde hassas bir şekilde gruplandırmamıza olanak tanır. Ek olarak, kavram kümeleriyle ilgili sağlam sayısal özellik uzaylarına dönüştürdüğümüz bu zengin metinsel veri kaynağı, soru uzayının potansiyel olarak sonsuz ifadelerini oluşturmak için mevcut verileri biraz bozmamıza izin veriyor. Çalışma zamanında daha fazla soru, daha önce hiç görülmemiş! Bu, kullanıcılara platformumuzda harcadıkları zaman için maksimum değeri vermemize olanak tanır.
İçerik Teslimatı
Kullanıcı profili oluşturma
Bir kullanıcının Embibe'de yaptığı her hareketi takip ediyoruz. Kullanıcılarımız tarafından son üç yılda yapılan milyonlarca uygulama ve test denemesi, binlerce boyutlu bir veri alanında kalibre edilir. Bu, kullanıcılarımızın davranışsal verilerinin derinliklerine inmek ve öğrenmenin nasıl gerçekleştiğiyle ilişkili içgörüler oluşturmak için benim yapabileceğimiz milyarlarca veri noktasından oluşan bir alana dönüşüyor. Bir kullanıcı tarafından yapılan her ek deneme, bağlantılı önceki ve sonraki kavramlarla birlikte, o denemeyle etiketlenen kavramlarda daha yüksek puan alma becerisini geliştirir. Bu süper karmaşık problem, büyüyen kullanıcı tabanımızla ölçeklenen sağlam ve uyarlanabilir kullanıcı profilleri oluşturmak için seyrek matris işleme, grafik teorisindeki hesaplama algoritmaları ve öğe yanıt teorisinden fikirlerden yararlanmayı içerir.
Sizin için tavsiye edilen:

Anti-Profiteing Hükmü Hintli Startuplar İçin Ne Anlama Geliyor?

Edtech Startup'ları Hindistan'ın İşgücünün Becerilerini Geliştirmesine ve Geleceğe Hazır Olmasına Nasıl Yardımcı Oluyor?

Bu Hafta Yeni Çağ Teknoloji Hisseleri: Zomato'nun Sorunları Devam Ediyor, EaseMyTrip Gönderileri Stro...

Hintli Startup'lar Finansman İçin Kısayollar Kullanıyor

Dijital Pazarlama Platformu Logicserve Çantaları 80 INR Cr Finansmanı, LS Dig Olarak Yeniden Markala...

Rapor, Lendingtech Alanına İlişkin Yenilenen Düzenleyici İncelemeye Karşı Uyarıyor
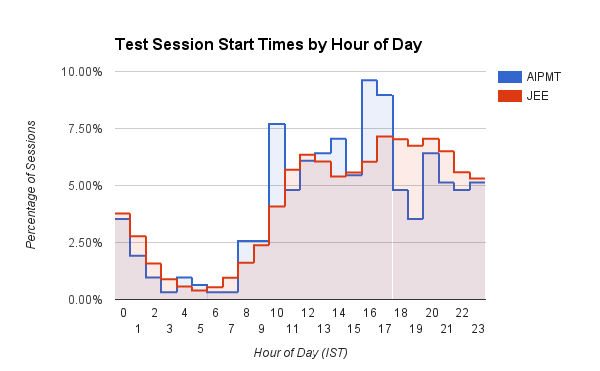
Kullanıcıların Embibe'de test oturumlarına başladıkları zamanı (IST'de günün saati) gösteren ilginç bir çubuk grafik. Medikal (AIPMT) kullanıcıları, sabah 10 civarında ve öğleden sonra 3 ile akşam 5 arasında tanımlanmış bir artışa sahiptir. Mühendislik (JEE) kullanıcıları ise gün ilerledikçe kademeli olarak artan oturum başlama zamanlarını gösteriyor ve bu da saat 16:00 ile 20:00 arasında zirve yapıyor. JEE öğrencileri ayrıca AIPMT öğrencilerine kıyasla sürekli olarak 17:00 ile 03:00 arasında daha fazla uygulama oturumu başlatırlar. Doktorların daha disiplinli olduğunu tahmin ediyoruz!

Kapsamlı enstrümantasyonumuz ve kullanıcı etkinliğinin çok ayrıntılı bir düzeyde ölçülmesi, bize bireysel kullanıcılarla ilişkili öğrenme stilleriyle ilgili gizli tercihleri çıkarma yeteneği verir. Örneğin, bazı öğrenciler, kapsamlı metinsel açıklamaları tercih eden diğer öğrencilere veya çözülmüş örnek problemler aracılığıyla adım adım çalışarak öğrenen diğer öğrencilere kıyasla, video açıklamaların yardımıyla daha iyi öğrenebilir ve daha sonra testlerde daha iyi performans gösterebilir. Kullanıcıları, iyileştirici uygulama kurslarını otomatik olarak uyarlamak ve kullanıcının puan iyileştirmesine yardımcı olmak için Dunn ve Dunn Modeli (Dunn & Dunn 1989) veya Gregorc's Mind Styles Modeli (Gregorc 1982) gibi iyi çalışılmış teorik öğrenme stilleri modelleriyle eşleştirebiliriz.
Kullanıcı grubu
Kohortlama, klasik bir kümeleme problemidir. Kullanıcılar, ürün özelliklerine göre kullanım biçimlerine ve test, uygulama ve revizyon oturumlarına göre performans biçimlerine göre gruplandırılır. Her kullanıcı, statik ve zamansal ölçüleri içeren binlerce öznitelikten oluşan yüksek boyutlu bir özellik uzayına eşlenir. Zamansal ölçümler üzerinde grup oluşturmak, bu kullanıcılara ilk etkinliklerine göre olası grup yörüngeleri atayarak, düşük etkinlik ve yeni kullanıcılara soğuk başlangıç yapma yeteneği verir. Kullanıcı grubu oluşturma, mikro uyarlanabilir öğrenme, otomatik geri bildirim oluşturma ve içerik önerisi gibi üst düzey derin bilim özelliklerimiz için temel bir gereksinimdir.
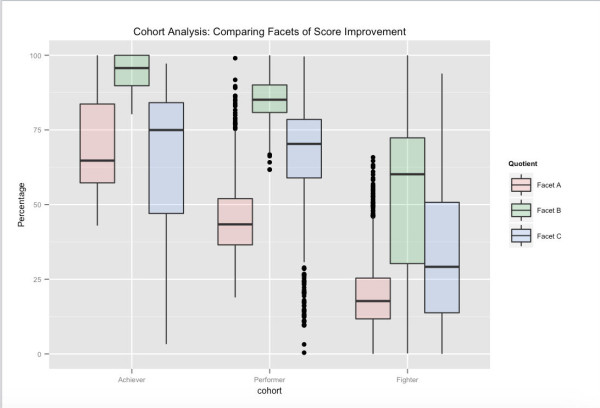
Kullanıcı gruplarının olası bir görünümü - uzun vadeli test performansına bağlı. Genel test puanlarına göre, Achiever'lar Embibe'deki kullanıcıların en üst yüzdelik dilimi, bir sonraki grup olan Performers ve son grup olan Fighters'tır. Gösterilen çeşitli yönler, özellik alanımızı kümelendirdiğimiz puan iyileştirmesinin farklı yönleriyle ilgilidir. Örneğin, Facet_A'nın gruplar arasında önemli ölçüde değişse de, geri bildirimi hedefleyerek ve diğer öğrenme yönlerini etkileyerek, kullanıcıları bir sonraki üst gruba itmenin mümkün olduğunu görebiliriz.
Mikro uyarlanabilir öğrenme
İçeriğin ve geri bildirimin ısırık boyutunda teslimi, etkili bir şekilde çevrimiçi öğrenmenin anahtarıdır. Genel olarak, kullanıcılar 30 dakika ile bir saat arasında çevrimiçi olarak kavram ve sorular üzerinde çalışarak vakit geçirirler. Bu kısa zaman aralığında, zamana bağlı her oturumun etkisini en üst düzeye çıkarmak çok önemlidir. Her oturum, öğrenmeyi en üst düzeye çıkarmak için kullanıcı için bir varlıktır ve bu, en iyi ısırık boyutu stratejisiyle gerçekleştirilir. Alıştırma oturumları için mikro-uyarlanabilir motorumuz, girdi olarak 11.000 (ve büyüyen!) bağlantılı kavramların meta-özniteliklerinden oluşan bilgi ağacımızla birlikte bir kullanıcının profilini ve kohort niteliklerini alır ve soru sıralamasının, sağlanan ipuçlarının ve sadece- Zamanında akıllı satır içi geri bildirim, kullanıcının herhangi bir küçük hedefte öğrenme sonucunu iyileştirmek için kullanıcıya tam olarak uyum sağlar. Her bir lokmalık içerik veya geri bildirim tüketimi, kapsamlı bilgi ağacına göre kullanıcının yeterlilik kalibrasyonunu etkileyecektir. Seyrek matris işleme teknikleri, madde yanıt teorisi ve grafik algoritmaları, öğrenmenin mikro uyarlanabilirliğine rehberlik eder.
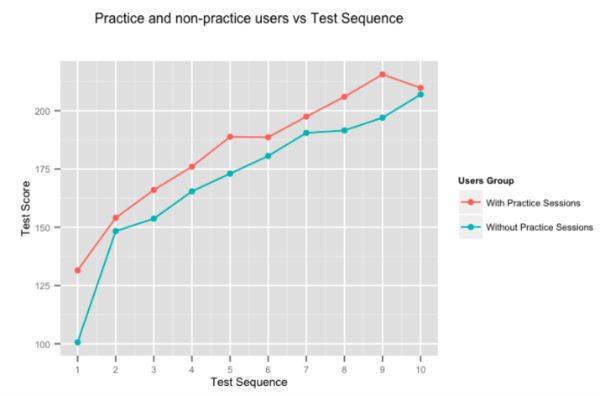
Pratik yapmanın insanı mükemmelleştirdiği oldukça açık, ama yine de sayıları çalıştırmaya karar verdik. Yukarıdaki şekil, uyarlamalı alıştırma oturumlarımızda zaman harcayan ve yapmayan kullanıcılar tarafından verilen ardışık testler için kullanıcıların ortalama puan gelişimini göstermektedir. Embibe üzerinde pratik yapan kullanıcılar, testte testte neredeyse %10 ile yapmayanları sürekli olarak geride bırakıyor.
Geri bildirim ve öneri sistemi
Embibe'nin geri bildirim ve öneri sistemi (zaten patentlerini aldık), tek bir amaç için tasarlanmış ve oluşturulmuştur – bir kullanıcının puan iyileştirmesini en üst düzeye çıkarmak. Uygulama ve test oturumları sırasında bir kullanıcının girişimleriyle ilgili binlerce sinyali alet edip yorumluyor ve bu sinyalleri her kullanıcı için binlerce özellikten oluşan yüksek boyutlu bir alana dönüştürüyoruz. Büyük kullanıcı denemesi özellik alanımızda istatistiksel kalıp madenciliğini kullanarak, bir kullanıcının puanını olumlu yönde artıran sıralanmış parametre setlerini sıfırladık. Bu parametreler, yüksek oranda hedeflenmiş tam zamanında puan iyileştirme geribildirim kapsülleri olarak makinede kodlanır ve uygulama oturumuna devam ederken kullanıcıya iletilir. Geri bildirim ve öneriler, puanını en üst düzeye çıkarmak için benimseyebileceği zayıflıkları ve stratejileri ortaya çıkarır.
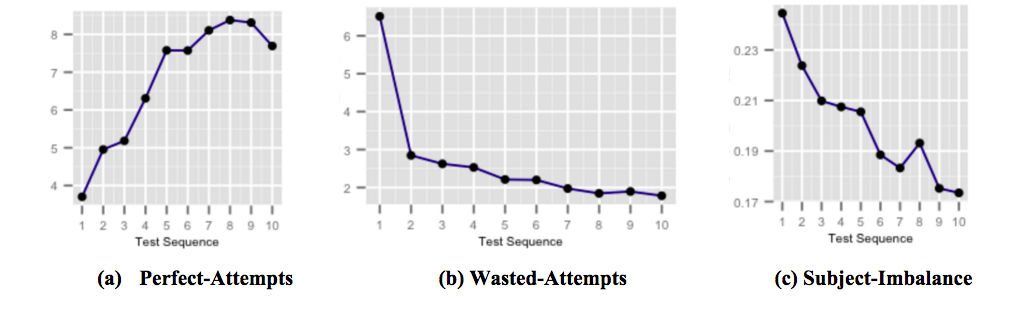
Yukarıdaki rakamlar, puan iyileştirme için yüksek oranda hedeflenmiş tam zamanında geri bildirim kapsüllerimizin, kullanıcı maruz kaldıkça öğrenci performansını nasıl etkilediğini ve yaygın test alma tuzaklarının farkına vardığını göstermektedir. Şekil (a), ardışık testlere göre artan ortalama mükemmel deneme sayısını göstermektedir. Mükemmel denemeler, belirli bir süre içinde doğru bir şekilde yanıtlanan girişimlerdir. Şekil (b), ardışık testlere göre azalan boşa giden girişimlerin ortalama sayısını göstermektedir. Boşa giden girişimler, öğrencinin soruyu düşünmek için harcayabileceği daha fazla zamana sahip olduğu durumlarda yanlış yanıtlanan girişimlerdir. Ve şekil (c), ardışık testler boyunca azalan ortalama konu-doğruluk-dengesizliği göstermektedir. Denek-doğruluk-dengesizlik, bir kullanıcı tarafından alınan herhangi bir testteki tüm denekler arasındaki en yüksek ve en düşük doğruluk arasındaki fark olarak tanımlanır. Daha yüksek bir konu-doğruluk-dengesizliği, kullanıcının diğer konulara kıyasla belirli konulara daha az hazırlıklı olduğu anlamına gelir.
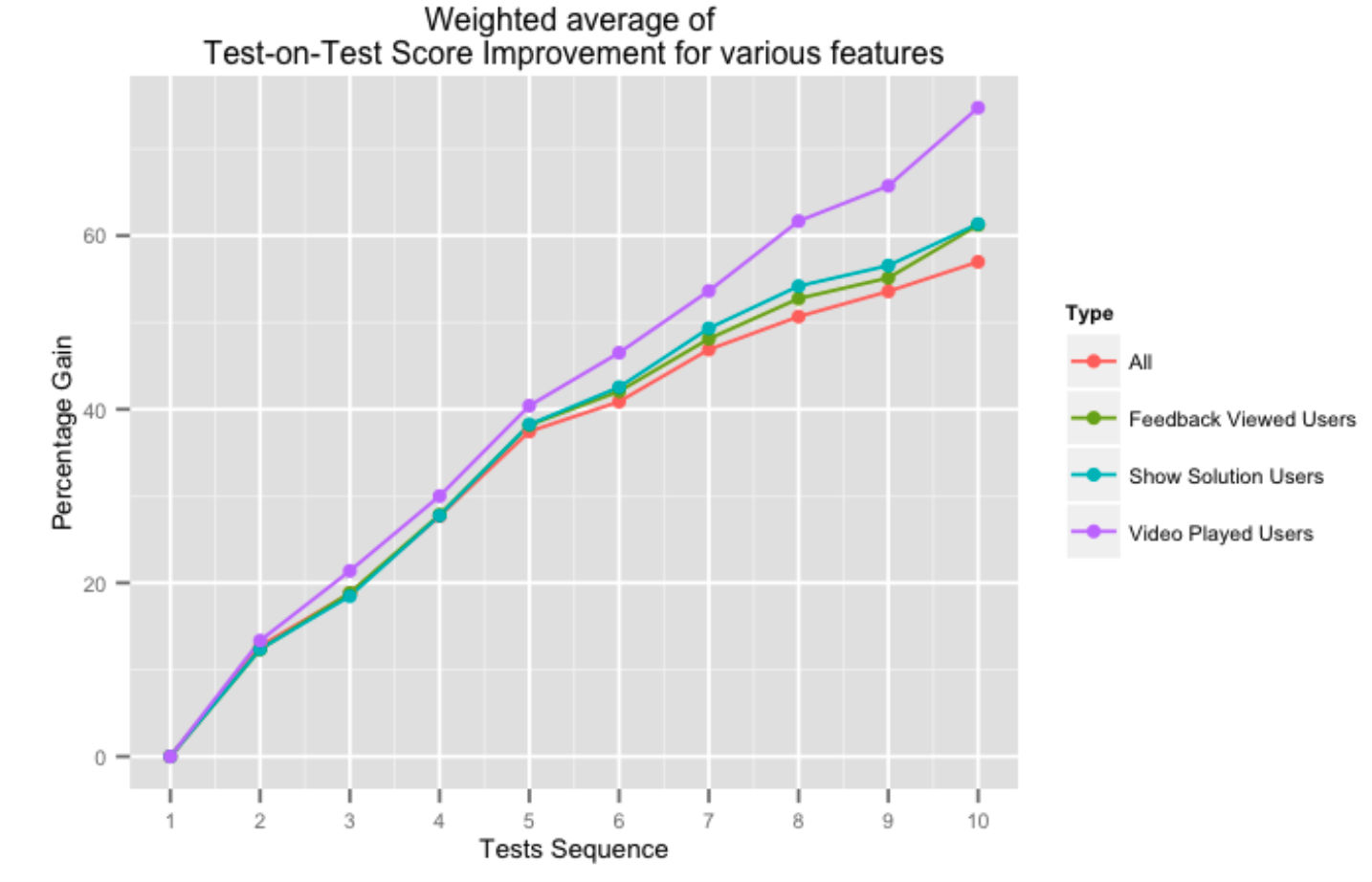
Yukarıdaki şekil, geri bildirim sistemimizin çeşitli yönlerini kullanan kullanıcılar için ardışık testte test puanlarındaki yüzde kazancını gösterir. Platformumuzdan video çözümleri veya genel test geri bildirimi şeklinde yardım almak, özellikle kullanıcı daha fazla test tamamladıkça, testte test puanlarını olumlu yönde etkiler.
Tahmini puan iyileştirme
Herhangi bir tür sınava hazırlanan kullanıcılar için, puan iyileştirme, öğrenme çıktılarını etkileyen en önemli unsurdur. Çok sayıda davranışsal verimiz, Embibe testleri sırasında ve sonrasındaki davranışlarının puan iyileştirmeyi nasıl etkilediğini ölçerek, kullanıcıların geçmiş eylemlerinden öğrenme yeteneği verir. Çeşitli kullanıcı grupları arasında kullanım, etkinlik ve davranış özelliklerindeki istatistiksel kalıplar için veri madenciliği, platformumuzun etkinliğinin bilim destekli kanıtını sunar.
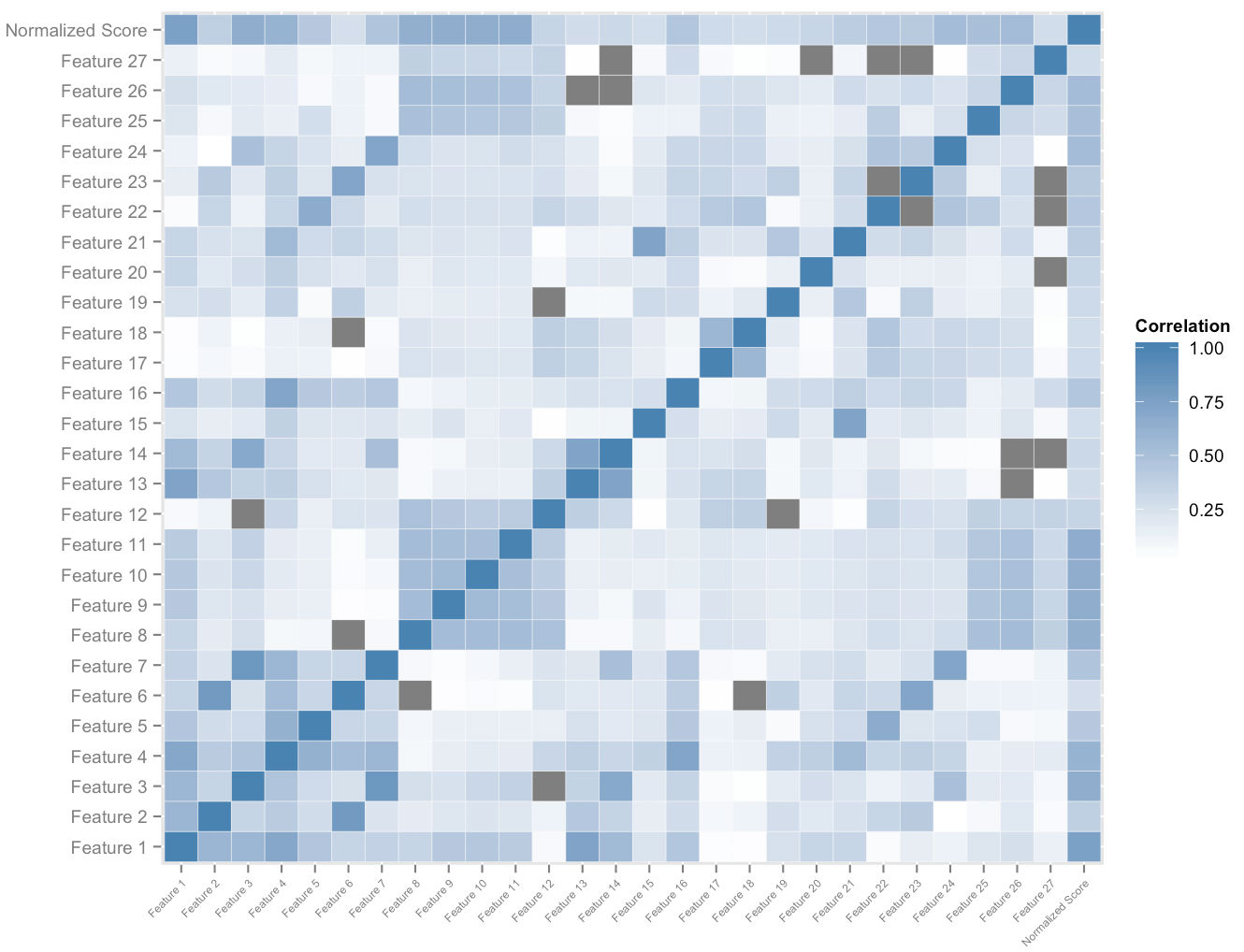
Yukarıdaki şekil, kullanıcı başına oluşturduğumuz özellik alanının bir alt kümesini göstermektedir. Özellik uzayı ve genel normalleştirilmiş puanlar üzerindeki çapraz korelasyon analizi, bize göreli özellik önemi hakkında bir sıralama verir. Bu, ampirik baskınlık analiziyle birlikte, her özelliğin puan iyileştirmeye katkısı üzerindeki etkisinin kuantumunu ölçmemize olanak tanır. Bu özelliklerin en önemlilerinin hızlarının uygun şekilde ağırlıklandırılmış bir kombinasyonu, platformu kullanırken ona uyum sağlayan her öğrenciye potansiyel puan iyileştirmesinin bir ölçüsünü nicel olarak atamamızı sağlar.
Bunlar, özellikle Hindistan ve diğer gelişmekte olan ülkelerde eğitim alanı için heyecan verici zamanlar. Eğitim ve öğrenimi bir sonraki seviyeye taşımak için, verileri ve sağlayabileceği içgörüleri kullanmaya güçlü bir şekilde odaklanarak derin bilimin uygulanmasına acil bir ihtiyaç vardır. İçerik alma ve sunma platformlarımız, sağlam bilimsel ilkeler üzerine inşa ediliyor ve kullanıcıların, kısıtlı hazırlık süreleri içinde puan iyileştirmesi şeklinde Embibe'de muazzam değer elde etmelerine yardımcı oluyor. Kullanıcıya özel geri bildirim ve önerileri kullanan, kohort sınıflandırmalarına ve davranış özelliklerine göre tam olarak kullanıcılara uyarlanmış mikro uyarlanabilir öğrenme çerçevemiz, kullanıcıların Embibe'de tatmin edici bir deneyim yaşamasına olanak tanır. Bunlar, öğrenme çıktılarını olumlu etkileme sorununu çözmeye yönelik ilk somut adımlardır. Bu kişiselleştirilmiş öğrenmedir.
Bu yazıda, bizi öğrenme çıktılarını etkileme yolunda ilerletmek için çözülmesi gereken çeşitli alt problemlere değindik. Bir sonraki yazımızda, ürünümüzün nabzını, büyümesini ve etkinliğini takip edebilmemiz için Embibe'de kullanıcılarımız ve etkinlikleriyle ilgili çeşitli metrikleri nasıl ölçtüğümüz ve takip ettiğimiz hakkında konuşacağız. bir çevrimiçi öğrenme hedefi.
Veri Bilimi Laboratuvarı'ndaki saflarımıza eklemek için her zaman kötü akıllı insanları arıyoruz. Hipotezleri test etmeyi, regresyonları çalıştırmayı, devasa matrisleri faktoring etmeyi, büyük veriler karşısında gülmeyi, harita küçültme işlerini kovmayı, dağınık yapılandırılmamış metinler üzerinde konu modelleri oluşturmayı, istatistiksel modeller için gürültülü verileri araştırmayı, açık verilerden dağlarca veriyi yutmayı seviyorsanız kaynaklar, p değerlerini tartışmak, sinir ağlarını ve derin inanç ağlarını eğitmek, python ve R arasında geçiş yapmak, görselleştirmeleri döndürmek ve kabukları komut dosyası yazmak, burayı seveceksiniz!
Jobs.<id>@embebe.com adresinden özgeçmişinizi bize yazın, burada:
<id>, normal dağılım için olasılık yoğunluk fonksiyonunun değerinin sıfır olmayan ilk 8 basamağı ile oluşturulan, 19 basamağa yuvarlanmış sayıdır ve
mu, Padovan dizisindeki 26. sayıdır ve
sigma, 1'den başlayan Fibonacci dizisindeki 17. sayıdır ve
x 1002. asal sayıdır
Ekibimiz Keyur Faldu ( Baş Veri Bilimcisi), Achint Thomas ( Baş Veri Bilimcisi) ve Chintan Donda'dan (Veri Bilimcisi) oluşmaktadır.
Referanslar
- Öğrenme stili envanteri . Lawrence, KS: Fiyat Sistemleri.
- Gregorc AF, (1982). Zihin Tarzları Modeli: Teori, İlkeler ve Uygulamalar. Maynard, MA: Gabriel Sistemleri.
Embibe, eğitim veri analitiğinde önde gelen şirketlerden biri olarak pazarda son 3 yılını tamamladı. Öğrenciler, yalnızca Mart 2016'da, ücretli pazarlamaya sıfır yatırımla ürüne 100.000 saatten fazla zaman harcadılar.