
300 Millionen Studenten, 300 Milliarden Einblicke – Verliebt in Daten in der Bildung
Veröffentlicht: 2016-04-07Ein exklusiver Einblick in das Data Science Lab von Embibe
[Dies ist der zweite Teil der Serie How We Are Use Deep Tech And Data Science To Personalize Education]
Wir haben Embibe mit einer einzigartigen Vision entwickelt: Lernergebnisse in großem Maßstab zu maximieren. Das Lernergebnis eines Benutzers positiv zu beeinflussen, ist ein schwieriges, aber wichtiges Problem, das es zu lösen gilt. Tatsächlich gibt es eine Reihe nicht trivialer offener Teilprobleme, von denen jedes gelöst werden muss, um das hochgesteckte Ziel zu erreichen, Lernergebnisse absichtlich und positiv zu beeinflussen.
Aber zuerst, was sind Lernergebnisse? Und warum kümmern wir uns um sie?
In der heutigen hart umkämpften Welt wird ein Schüler weitgehend daran gemessen, wie viel er in einer Wettbewerbsprüfung oder sogar in einem Schulklassenzimmer erzielen kann. Ihre Punktzahl kann einen erheblichen Einfluss auf ihre Karrieremöglichkeiten haben. Lassen Sie uns für die Zwecke dieses Artikels die Lernergebnisse als eine Funktion des angeborenen sowie trainierbaren Potenzials eines Schülers formulieren, um Inhaltsmaterial innerhalb genau festgelegter Zeitvorgaben optimal zu lernen, aufzunehmen und anzuwenden; damit sie ihre Punktzahl in einem bestimmten wettbewerbsorientierten akademischen Kontext maximieren kann.
In Entwicklungsländern wie Indien ist das Schüler-Lehrer-Verhältnis stark verzerrt und die Lehrer können auf individueller Ebene keine effektive personalisierte Aufmerksamkeit bieten. Dies führt zu einem Dilemma, da jeder Schüler Informationen mit unterschiedlicher Geschwindigkeit lernt und aufnimmt und über unterschiedliche Fähigkeiten verfügt. Ein bekannter Nebeneffekt der Unfähigkeit von Lehrern, personalisierte Aufmerksamkeit zu bieten, besteht darin, dass das Lernmaterial für ein bestimmtes Klassenzimmer / eine bestimmte Gruppe von Schülern immer so präsentiert wird, dass es dem „durchschnittlichen“ Schüler gerecht wird. Daher erreichen sehr begabte Schüler nicht ihr volles Potenzial und können ihre akademischen Muskeln nicht wirklich spielen lassen, während schulisch schwächere Schüler es schwer haben, mit dem Rest des Klassenzimmers zurechtzukommen. Bestehende Online-Lernplattformen und -systeme sind jedoch nicht in der Lage, personalisiertes Lernen auf Schülerebene wirklich zu erleichtern.
Die meisten aktuellen Systeme berücksichtigen nur, wie gut ein Student seine Lösungen mit Testmodulen abgleichen kann, wie von einem Administrator des Systems festgelegt. Personalisiertes Lernen für wettbewerbsfähige Prüfungen sollte die Punktzahl eines Schülers für jedes akademische Ziel in der begrenzten Zeit, die ihm zur Verfügung steht, maximieren. Personalisiertes Lernen sollte auch die Fähigkeitslücken des Schülers nicht nur auf Wissens- oder Eignungsebene, sondern auch auf Einstellungs- und Verhaltensebene konstruktiv angehen. Dieser Mangel an effektiven Tools für personalisiertes Lernen, die speziell und genau auf jeden Schüler zugeschnitten sind, ist dafür verantwortlich, dass sie ihr Potenzial nicht ausschöpfen kann, um in einer bestimmten Prüfung die maximal mögliche Punktzahl zu erreichen.
In diesem Artikel legt das Data-Science-Team von embibe den Grundstein für die verschiedenen miteinander verbundenen datenbezogenen Probleme, die angegangen werden müssen, um die Lernergebnisse und insbesondere die Verbesserung der Punktzahl zu maximieren. Dieses Problem hat zwei Hauptdimensionen – Content Ingestion und Content Delivery. Jede Dimension stellt einzigartige Herausforderungen in einer Reihe von Bereichen dar, die jeden Datenwissenschaftler faszinieren werden.
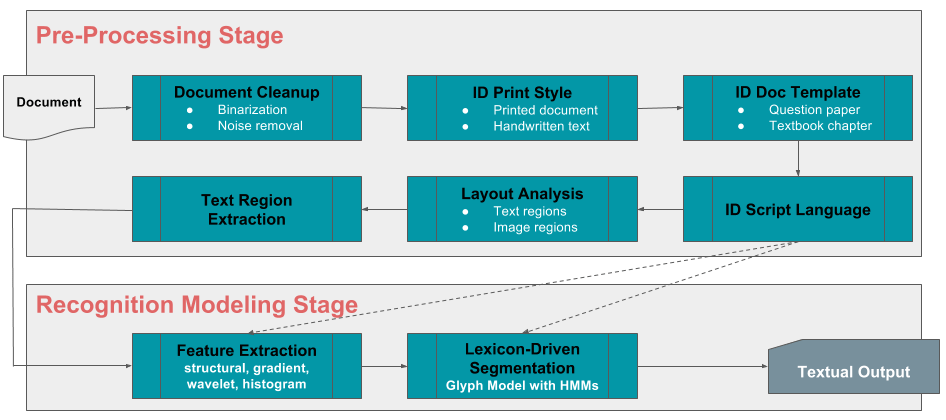
Aufnahme von Inhalten
Automatische Aufnahme von Inhalten
Dutzende von Lehrplantafeln, Tausende von Kapiteln und Konzepten und Zehntausende von Instituten und Schulen führen zu Hunderttausenden von Fragen und Antworten, die jedes Jahr von Ausbildern erstellt und verwendet werden. Stellen Sie sich vor, jeder Schüler könnte sein Wissen vor den Prüfungen zu einer Teilmenge oder allen diesen Fragen testen und gleichzeitig detaillierte Erklärungen zu den richtigen Antworten und häufigen Fehlern erhalten. Um dies Wirklichkeit werden zu lassen, nutzen wir optische Zeichenerkennung (OCR) und maschinelles Lernen, um unser eigenes automatisiertes Aufnahme-Framework aufzubauen, das hochgradig skalierbar, wirklich mehrsprachig und nur minimal von menschlicher Eingabe abhängig ist. Und der Spaß hört hier nicht auf. Das Framework wird auch in der Lage sein, handschriftliche Inhalte auf schriftstellerunabhängige Weise aufzunehmen und so unseren bereits fantastischen Vorrat an Fragen, Antworten, Konzepten, Erklärungen und Wissen schnell zu erweitern.
Konzept-Tagging
Okay, jetzt haben wir also Fragen, Antworten, Konzepte und Kapitel, die alle in ein riesiges Data Warehouse aufgenommen wurden. Es wäre mühsam, jede Frage oder jedes Kapitel manuell mit den relevanten Konzepten zu markieren oder umgekehrt. Data Science zur Rettung! Mithilfe modernster Ideen aus der Textklassifizierung, Themenmodellierung und Deep Learning versehen wir Konzepte automatisch mit Fragen, Antworten und Kapiteln.

Eine Auswahl der beliebtesten Konzepte, wie sie von Embibe-Benutzern mit der Lernfunktion in den Monaten Dezember 2015, Januar 2016 und Februar 2016 durchsucht wurden.
Unsere früheren Datenbanken, die Seed-Sets mit qualitativ hochwertigen, manuell getaggten Inhalten enthalten, sind von entscheidender Bedeutung, wenn wir linguistische, lexikalische und kontextsensitive Merkmale extrahieren, um hochmoderne Text-Tagging-Modelle für alle neuen Daten zu trainieren, die in unsere aufgenommen werden Systeme.
Anreicherung von Metadaten
Es gibt heute online eine Fülle von Informationen zu jedem Thema, über das man sich informieren möchte. Ideen und Konzepte bauen aufeinander auf. Beispielsweise bezieht sich der Erste Hauptsatz der Thermodynamik auf das Konzept eines thermodynamischen Systems, das wiederum unter anderem auf die Konzepte der spezifischen Wärmekapazitäten von Gasen, der Erhaltung der mechanischen Energie und der von einem Gas verrichteten Arbeit bezogen ist. Unser Content-Ingestion-Framework umfasst Datenanreicherungskomponenten, die das Web automatisch crawlen und Inhalte mit so unterschiedlichen Medienstücken wie Texterklärungen, Videolinks, Definitionen, Benutzerkommentaren und Forumsdiskussionen taggen, und das alles unter Wahrung des Urheberrechts und ordnungsgemäßer Zuweisung von Eigentumsrechten an Quellinhalten . Diese Fülle an verfügbaren Informationen ermöglicht es auch, verwandte Konzepte automatisch in einer Baumstruktur zu verbinden. Unter Verwendung von Ideen aus den Bereichen Graphentheorie, Textmining und Label-Propagation auf spärlichen Strukturen schaffen wir Verknüpfungen und Verbindungen zwischen Konzepten, die eine Quelle→Ziel-Beziehung teilen.
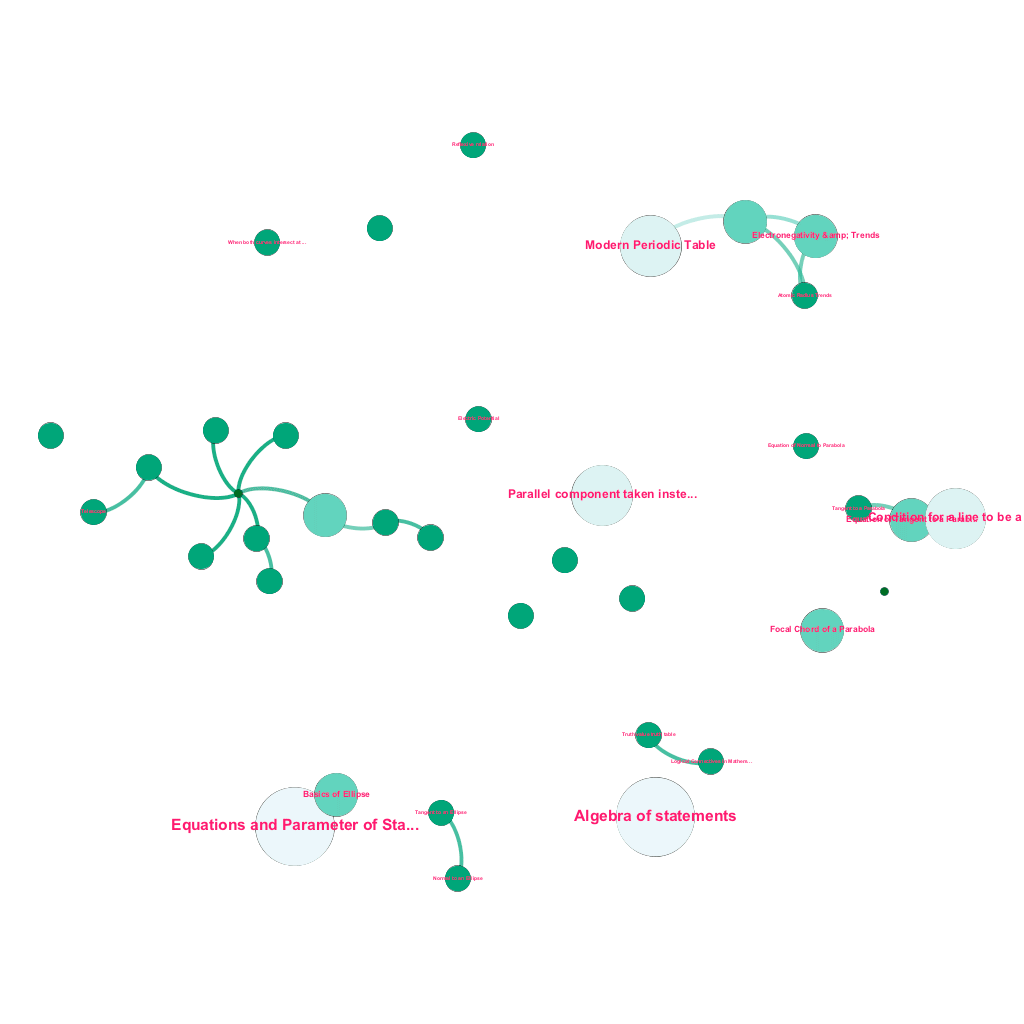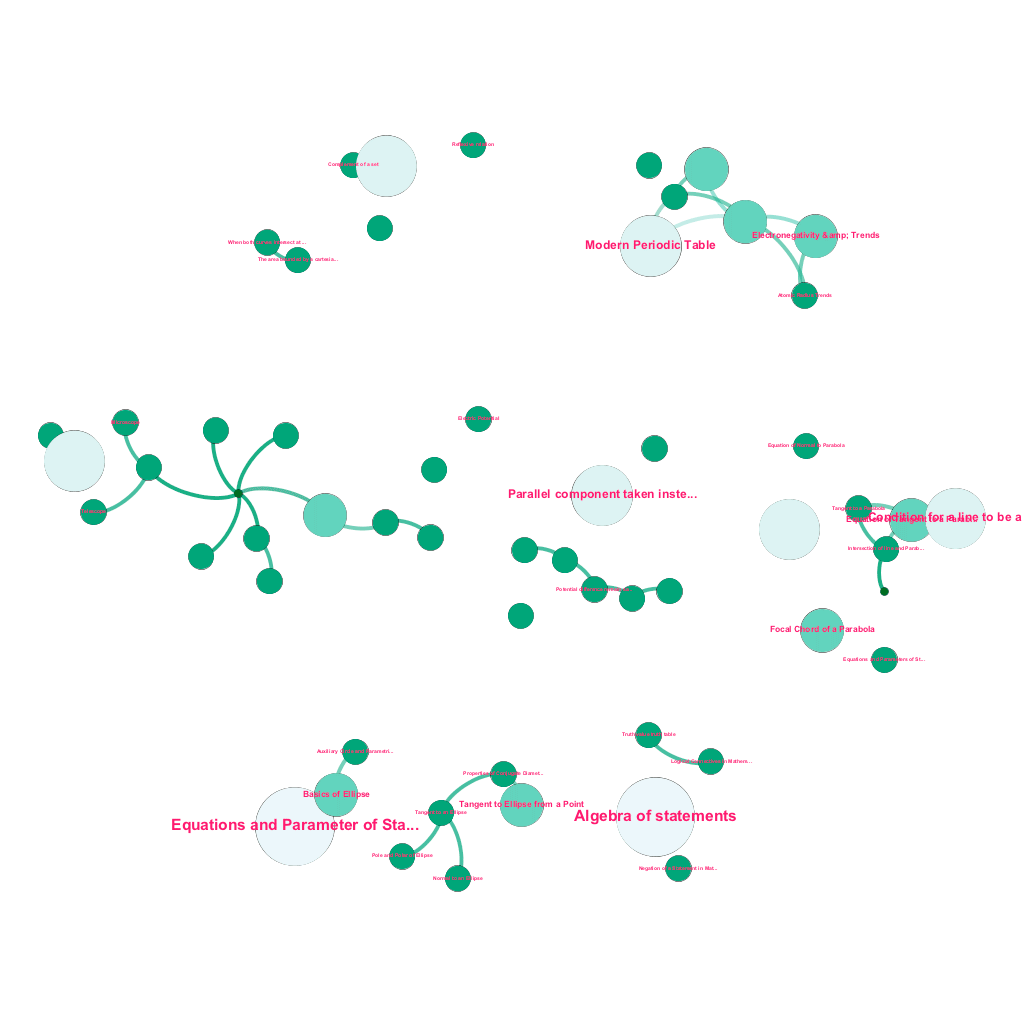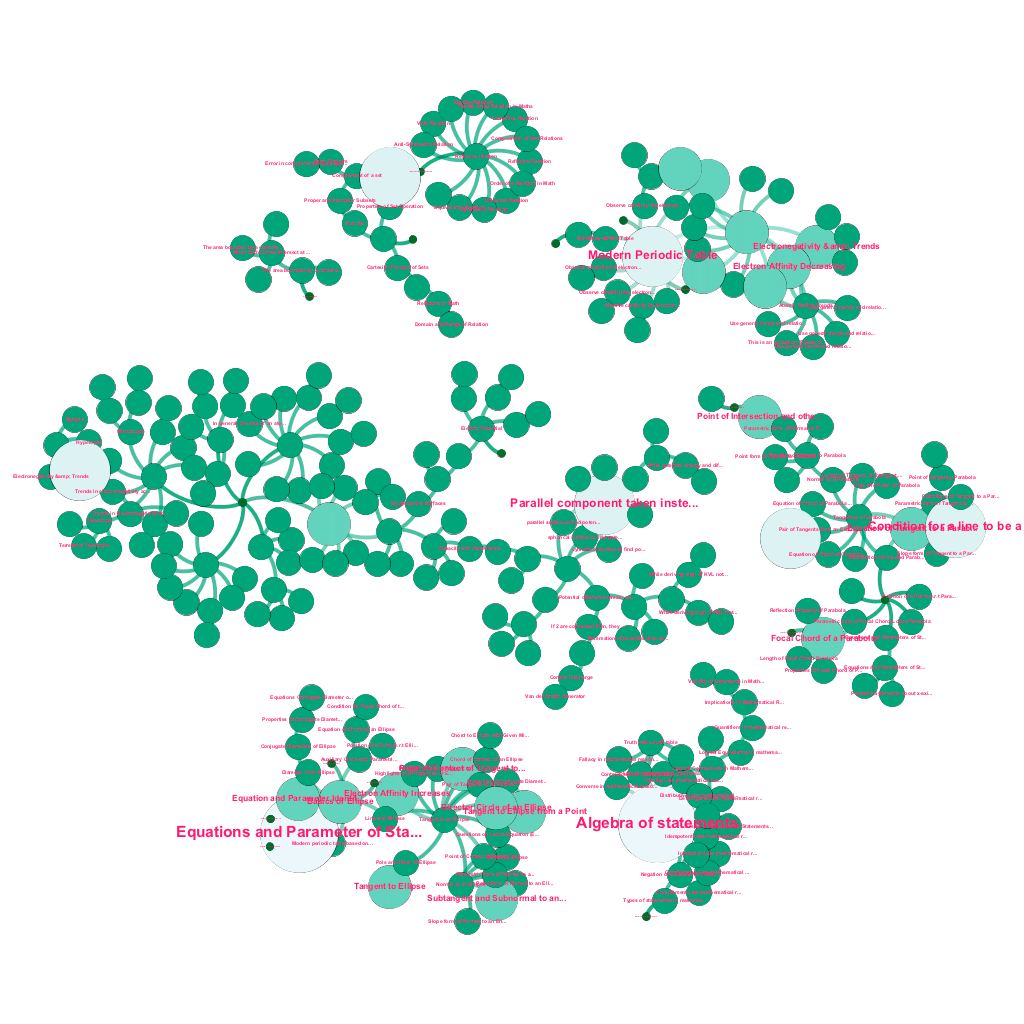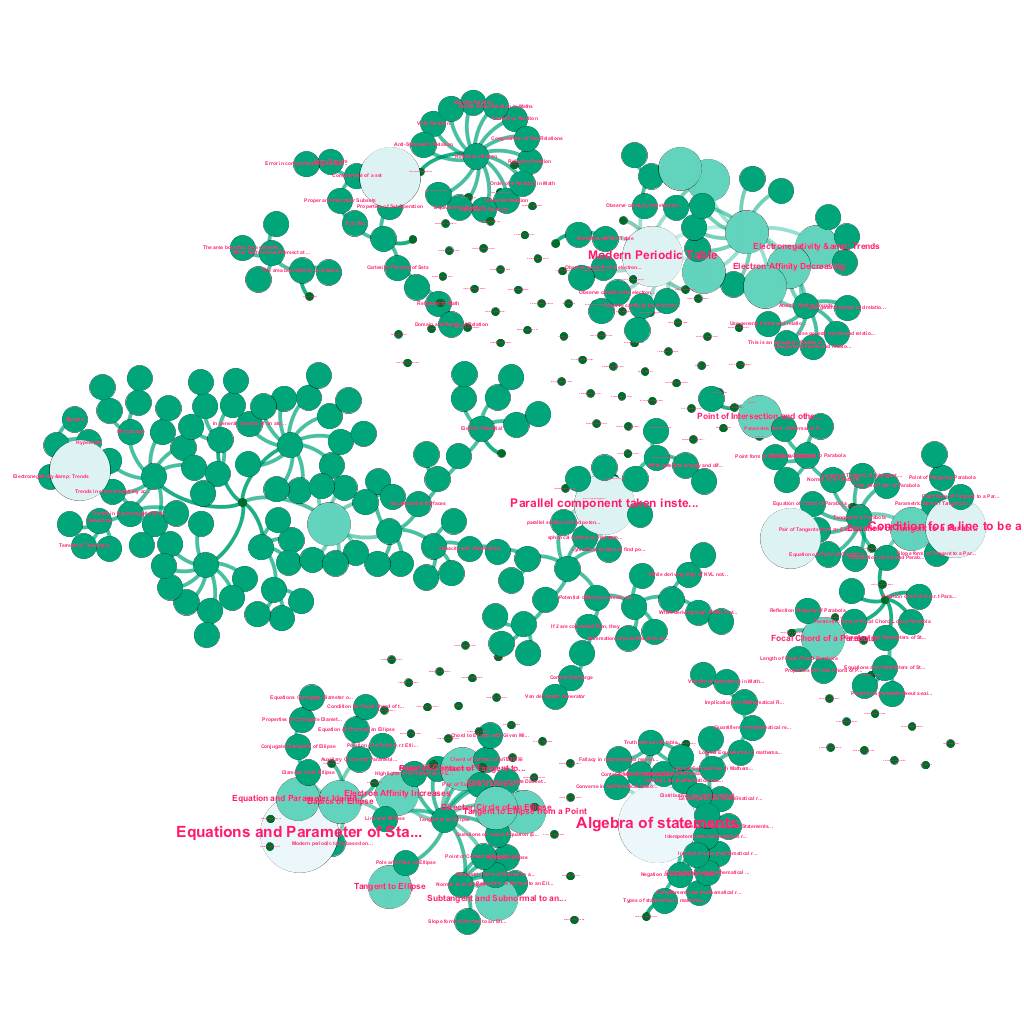
Automatisierter Aufbau eines Konzeptbaums für eine Teilmenge von Ideen aus der Mathematik, die jeweils mit einem oder mehreren verwandten Konzepten verbunden sind
Clustering ähnlicher Fragen
Wenn Sie sich auf eine Prüfung vorbereiten, würden Sie dieselbe Frage immer wieder üben wollen? Das wäre nicht hilfreich. Stellen Sie sich umgekehrt vor, wie immens nützlich es wäre, eine kleine Reihe relevanter Fragen zu üben, die Ihnen helfen, ein neues Konzept oder Kapitel vollständig zu meistern. Mit unserem Zugriff auf Hunderttausende von Fragen haben wir die Fähigkeit entwickelt, Fragen basierend auf Ähnlichkeiten über eine Reihe von Dimensionen hinweg zu gruppieren – unter anderem inhaltsorientiert, konzeptgetestet, Schwierigkeitsgrad und Prüfungsziele.
Text-Clustering basierend auf latenten semantischen Informationsräumen und deren Kombination mit anderen kategorialen und numerischen Merkmalsräumen ermöglichen es uns, unser Fragenuniversum präzise in Interessengebiete zu gruppieren, die mit Embibe auf jeden Einzelnen zugeschnitten werden können. Darüber hinaus ermöglicht uns diese reichhaltige Ressource an Textdaten, die wir in robuste numerische Merkmalsräume in Bezug auf Konzeptcluster umgewandelt haben, die vorhandenen Daten leicht zu stören, um potenziell unendliche Ausdrücke des Frageraums zu generieren. Mehr Fragen zur Laufzeit, nie zuvor gesehen! Auf diese Weise können wir den Benutzern den maximalen Wert für ihre auf unserer Plattform verbrachte Zeit bieten.
Inhalt liefern
Benutzerprofilierung
Wir verfolgen jede Bewegung, die ein Benutzer auf Embibe macht. Die Millionen von Übungs- und Testversuchen unserer Benutzer in den letzten drei Jahren sind in einem Datenraum von vielen tausend Dimensionen kalibriert. Dies bedeutet einen Bereich von Milliarden von Datenpunkten, die wir abbauen können, um tief in die Verhaltensdaten unserer Benutzer einzudringen und Erkenntnisse zu gewinnen, die mit dem Lernen korrelieren. Jeder zusätzliche Versuch eines Benutzers optimiert seine Fähigkeit, bei den mit diesem Versuch markierten Konzepten zusammen mit den damit verbundenen vorangehenden und nachfolgenden Konzepten eine höhere Punktzahl zu erreichen. Dieses superkomplexe Problem beinhaltet die Nutzung von Ideen aus der Sparse-Matrix-Verarbeitung, Rechenalgorithmen in der Graphentheorie und der Item-Response-Theorie, um robuste und anpassungsfähige Benutzerprofile zu erstellen, die mit unserer wachsenden Benutzerbasis skalieren.
Für dich empfohlen:

Was bedeutet die Anti-Profiteering-Bestimmung für indische Startups?

Wie Edtech-Startups Indiens Arbeitskräften helfen, sich weiterzubilden und zukunftsfähig zu werden ...

New-Age-Tech-Aktien in dieser Woche: Zomatos Probleme gehen weiter, EaseMyTrip-Posts steigen...

Indische Startups nehmen Abkürzungen bei der Jagd nach Finanzierung

Digitale Marketingplattform Logicserve Bags INR 80 Cr-Finanzierung, Umbenennung in LS Dig...

Bericht warnt vor erneuter behördlicher Prüfung von Lendingtech Space
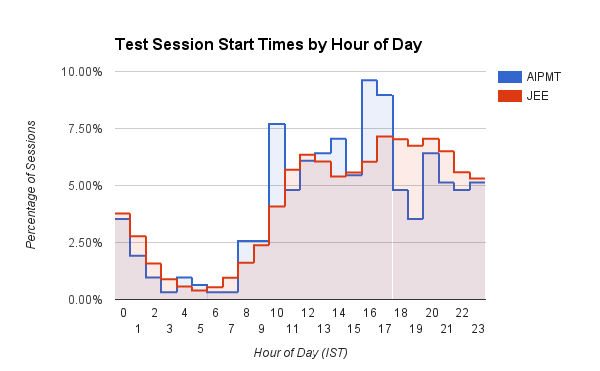
Ein interessantes Balkendiagramm, das die Uhrzeit (Tagesstunde in IST) anzeigt, zu der Benutzer ihre Testsitzungen auf Embibe starten. Medizinische (AIPMT) Benutzer haben eine definierte Spitze um 10:00 Uhr und zwischen 15:00 und 17:00 Uhr. Engineering (JEE)-Benutzer hingegen zeigen im Laufe des Tages allmählich zunehmende Sitzungsstartzeiten, die zwischen 16:00 und 20:00 Uhr ihren Höhepunkt erreichen. JEE-Studenten beginnen im Vergleich zu AIPMT-Studenten auch durchgängig mehr Übungssitzungen zwischen 17:00 und 3:00 Uhr. Wir vermuten, dass Ärzte disziplinierter sind!

Unsere umfassende Instrumentierung und Messung der Benutzeraktivität auf sehr granularer Ebene gibt uns die Möglichkeit, latente Präferenzen in Bezug auf Lernstile einzelner Benutzer abzuleiten. Beispielsweise können bestimmte Schüler mit Hilfe von Videoerklärungen besser lernen und anschließend Tests absolvieren als andere Schüler, die ausführliche Textbeschreibungen bevorzugen, oder wieder andere, die lernen, indem sie Schritt für Schritt durch gelöste Beispielprobleme arbeiten. Wir können Benutzer gut untersuchten theoretischen Modellen von Lernstilen wie dem Dunn-und-Dunn-Modell (Dunn & Dunn 1989) oder Gregorcs Mind-Styles-Modell (Gregorc 1982) zuordnen, um automatisch Abhilfemaßnahmen zu treffen und dem Benutzer zu helfen, die Punktzahl zu verbessern.
Benutzerkohorte
Kohortierung ist ein klassisches Clustering-Problem. Benutzer werden basierend auf ihren Nutzungsmustern in Bezug auf Produktfunktionen sowie ihren Leistungsmustern in Bezug auf Test-, Übungs- und Überarbeitungssitzungen gruppiert. Jeder Benutzer wird einem hochdimensionalen Merkmalsraum mit vielen tausend Attributen zugeordnet, die sowohl statische als auch zeitliche Maße umfassen. Die Kohortierung nach zeitlichen Maßen gibt uns die Möglichkeit, niedrige Aktivitäten und neue Benutzer kalt zu starten, indem wir diesen Benutzern basierend auf ihrer anfänglichen Aktivität wahrscheinliche Kohortenverläufe zuweisen. Die Benutzerkohortierung ist eine Kernvoraussetzung für unsere hochrangigen Deep-Science-Funktionen wie mikroadaptives Lernen, automatisierte Feedback-Generierung und Inhaltsempfehlung.
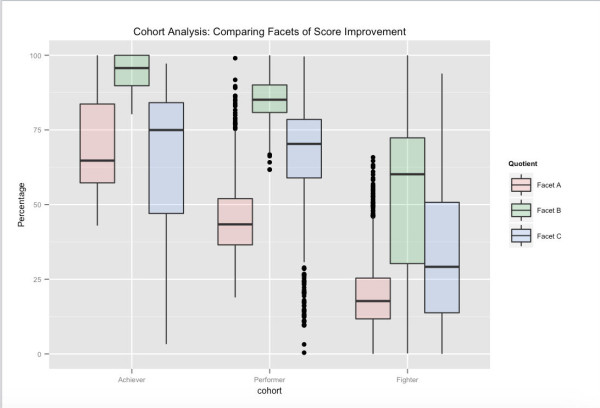
Eine mögliche Ansicht von Benutzerkohorten – gebunden an die langfristige Testleistung. Basierend auf ihren Gesamttestergebnissen sind Achiever das oberste Perzentil der Benutzer auf Embibe, Performer die nächste Gruppe und Kämpfer die letzte Gruppe. Die verschiedenen gezeigten Facetten beziehen sich auf verschiedene Aspekte der Punktzahlverbesserung, in die wir unseren Feature-Bereich gruppiert haben. Obwohl Facet_A zwischen den Kohorten erheblich variiert, können wir beispielsweise sehen, dass es möglich ist, Benutzer in die nächsthöhere Kohorte zu drängen, indem das Feedback auf andere Lernfacetten ausgerichtet ist und diese beeinflusst.
Mikroadaptives Lernen
Die mundgerechte Bereitstellung von Inhalten und Feedback ist der Schlüssel zum effektiven Online-Lernen. Im Allgemeinen verbringen Benutzer zwischen 30 Minuten und einer Stunde online, um Konzepte und Fragen zu üben. Innerhalb dieser kurzen Zeitspanne ist es sehr wichtig, die Wirkung jeder zeitgebundenen Sitzung zu maximieren. Jede Sitzung ist eine Bereicherung für den Benutzer, um das Lernen zu maximieren, und dies wird am besten mit der mundgerechten Strategie erreicht. Unsere mikroadaptive Engine für Übungssitzungen verwendet das Profil und die Kohortenattribute eines Benutzers zusammen mit unserem Wissensbaum aus 11.000 (und wachsend!) Metaattributen von miteinander verknüpften Konzepten als Eingabe und stellt sicher, dass die Reihenfolge der Fragen, die bereitgestellten Hinweise und genau- In-Time intelligentes Inline-Feedback passt sich genau an die Benutzerin an, um ihren Lernerfolg bei jedem mundgerechten Ziel zu verbessern. Jeder mundgerechte Konsum von Inhalten oder Feedback wirkt sich auf die Leistungskalibrierung des Benutzers anhand unseres umfangreichen Wissensbaums von Konzepten aus. Sparse-Matrix-Verarbeitungstechniken, Item-Response-Theorie und Graphalgorithmen leiten die Mikroadaptivität des Lernens.
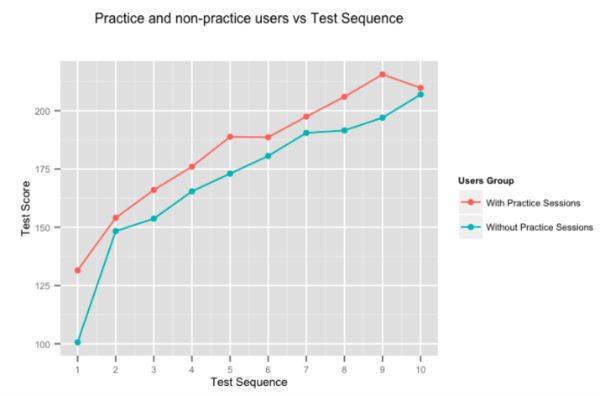
Es ist ziemlich offensichtlich, dass Übung einen perfekt macht, aber wir haben uns entschieden, die Zahlen trotzdem zu berechnen. Die obige Abbildung zeigt die durchschnittliche Punktzahlverbesserung von Benutzern für aufeinanderfolgende Tests, die von Benutzern durchgeführt wurden, die Zeit für unsere adaptiven Übungssitzungen aufwenden, und von Benutzern, die dies nicht tun. Benutzer, die auf Embibe üben, übertreffen diejenigen, die dies nicht tun, durchweg um fast 10 % von Test zu Test.
Feedback- und Empfehlungssystem
Das Feedback- und Empfehlungssystem von Embibe (für das wir bereits Patente angemeldet haben) wurde für einen Zweck entwickelt und gebaut – die Verbesserung der Punktzahl eines Benutzers zu maximieren. Wir instrumentieren und interpretieren Tausende von Signalen über die Versuche eines Benutzers während der Übungs- und Testsitzungen und verwandeln diese Signale in einen hochdimensionalen Raum mit Tausenden von Funktionen für jeden Benutzer. Mithilfe von statistischem Muster-Mining in unserem riesigen Funktionsbereich für Benutzerversuche haben wir uns auf die Ranglistensätze von Parametern konzentriert, die die Punktzahl eines Benutzers positiv beeinflussen. Diese Parameter werden maschinell als hochgradig zielgerichtete Just-in-Time-Feedbacks zur Verbesserung der Punktzahl kodiert und dem Benutzer geliefert, während er mit seiner Übungssitzung fortfährt. Das Feedback und die Empfehlungen zeigen Schwächen und Strategien auf, die sie anwenden kann, um ihre Punktzahl zu maximieren.
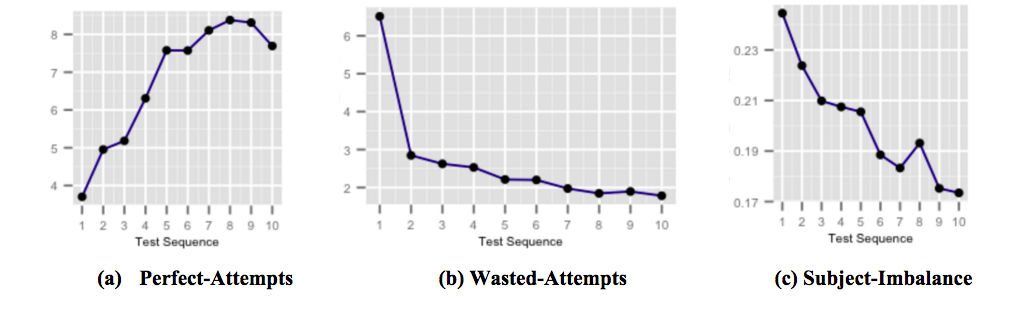
Die obigen Abbildungen zeigen, wie sich unsere hochgradig zielgerichteten Just-in-Time-Feedback-Kapseln zur Verbesserung der Punktzahl auf die Schülerleistung auswirken, wenn der Benutzer häufigen Fallstricken bei der Durchführung von Tests ausgesetzt ist und sich dessen bewusst wird. Abbildung (a) zeigt die durchschnittliche Anzahl perfekter Versuche, die über aufeinanderfolgende Tests zunimmt. Perfect-Versuche sind Versuche, die innerhalb einer vorgegebenen Zeit richtig beantwortet werden. Abbildung (b) zeigt die durchschnittliche Anzahl der vergeblichen Versuche, die über aufeinanderfolgende Tests abnimmt. Fehlversuche sind falsch beantwortete Versuche, bei denen der Schüler mehr Zeit hatte, um über die Frage nachzudenken. Und Abbildung (c) zeigt das durchschnittliche Subjekt-Genauigkeits-Ungleichgewicht, das über aufeinanderfolgende Tests abnimmt. Das Subjekt-Genauigkeits-Ungleichgewicht ist definiert als der Unterschied zwischen der höchsten und der niedrigsten Genauigkeit aller Subjekte in einem beliebigen Test, der von einem Benutzer durchgeführt wird. Ein höheres Fach-Genauigkeits-Ungleichgewicht impliziert, dass der Benutzer auf bestimmte Fächer im Vergleich zu anderen Fächern weniger vorbereitet ist.
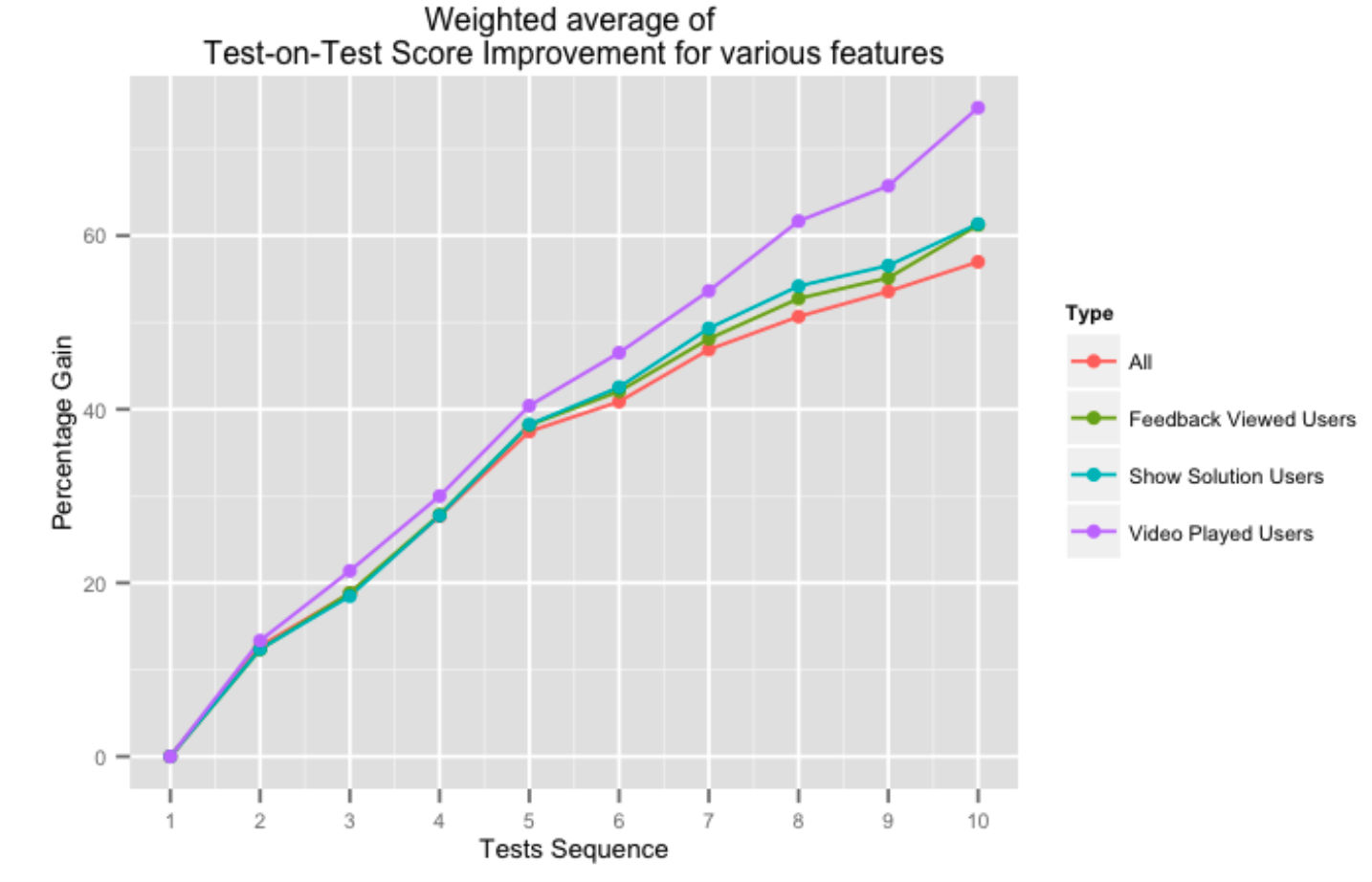
Die obige Abbildung zeigt den prozentualen Anstieg der aufeinanderfolgenden Test-auf-Test-Ergebnisse für Benutzer, die verschiedene Aspekte unseres Feedback-Systems nutzen. Die Unterstützung unserer Plattform in Form von Videolösungen oder allgemeinem Testfeedback wirkt sich positiv auf die Ergebnisse von Test zu Test aus, insbesondere wenn der Benutzer mehr Tests abschließt.
Bewertung der Verbesserung der Punktzahl
Für Benutzer, die sich auf Prüfungen jeglicher Art vorbereiten, ist die Verbesserung der Punktzahl der wichtigste Aspekt bei der Beeinflussung der Lernergebnisse. Unsere Fülle an Verhaltensdaten gibt uns die Möglichkeit, aus früheren Aktionen von Benutzern zu lernen, indem wir messen, wie sich ihr Verhalten während und nach der Durchführung von Tests auf Embibe auf die Verbesserung der Punktzahl auswirkt. Data Mining für statistische Nutzungs-, Aktivitäts- und Verhaltensmuster bei verschiedenen Nutzerkohorten liefert uns einen wissenschaftlich fundierten Beweis für die Effektivität unserer Plattform.
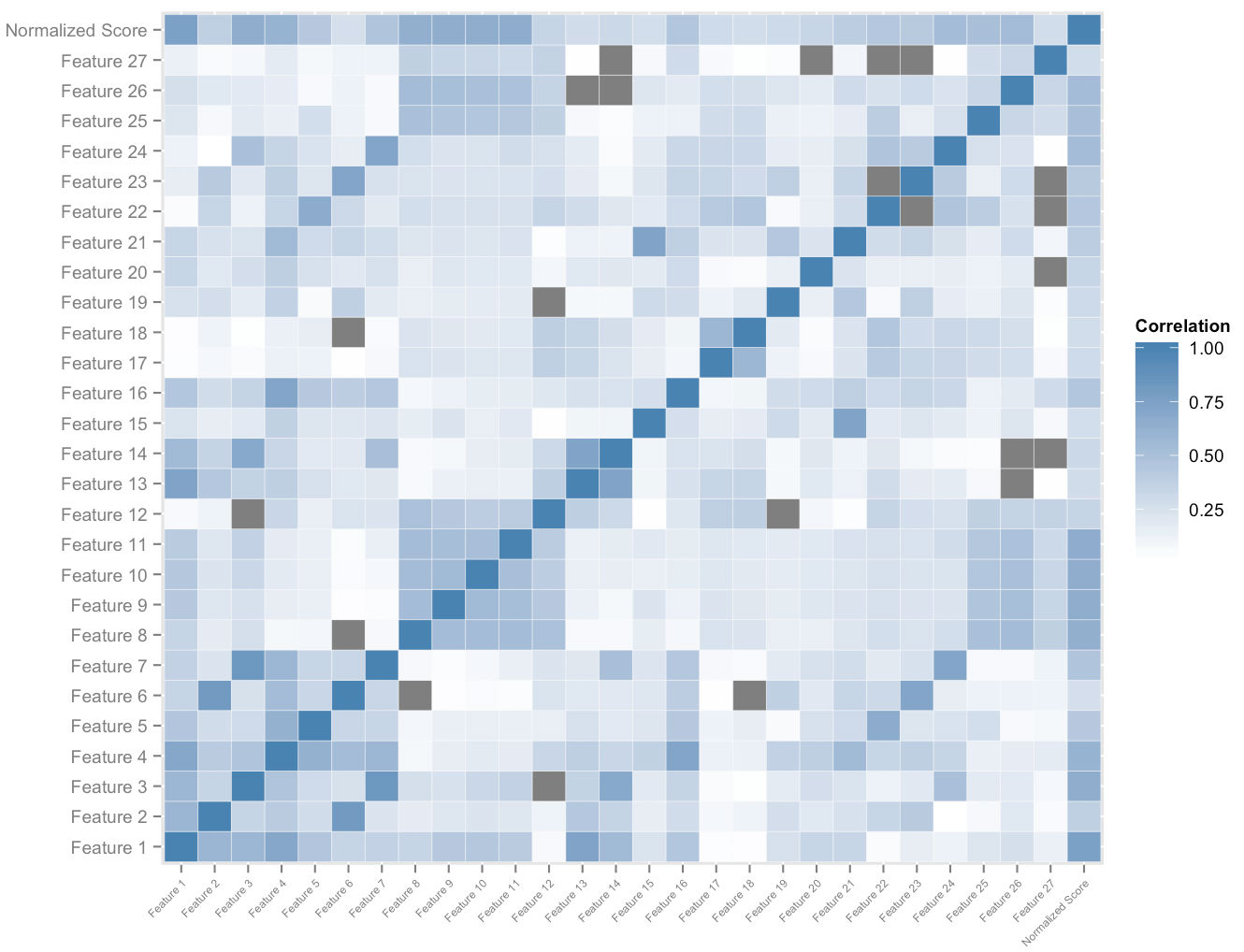
Die obige Abbildung zeigt eine Teilmenge des Funktionsraums, den wir pro Benutzer erstellen. Die Kreuzkorrelationsanalyse des Merkmalsraums und die insgesamt normalisierten Bewertungen geben uns eine Ordnung der relativen Merkmalsbedeutung. Zusammen mit der empirischen Dominanzanalyse ermöglicht uns dies, das Quantum der Auswirkungen jedes Merkmals auf seinen Beitrag zur Verbesserung der Punktzahl zu messen. Eine angemessen gewichtete Kombination der Geschwindigkeiten der wichtigsten dieser Merkmale ermöglicht es uns, jeder Schülerin, die sich bei der Nutzung der Plattform an sie anpasst, ein Maß für die potenzielle Verbesserung der Punktzahl quantitativ zuzuordnen.
Dies sind aufregende Zeiten für den Bildungsbereich, insbesondere in Indien und anderen Entwicklungsländern. Es besteht ein dringender Bedarf, Deep Science anzuwenden, mit einem starken Fokus auf der Nutzung von Daten und den Erkenntnissen, die sie liefern können, um Bildung und Lernen auf die nächste Stufe zu heben. Unsere Plattformen zur Aufnahme und Bereitstellung von Inhalten werden auf soliden wissenschaftlichen Prinzipien aufgebaut und helfen Benutzern dabei, den immensen Wert von Embibe in Form von Score-Verbesserungen innerhalb begrenzter Vorbereitungszeiträume zu realisieren. Unser mikroadaptiver Lernrahmen, der benutzerspezifisches Feedback und Empfehlungen verwendet, die genau auf Benutzer zugeschnitten sind, basierend auf ihren Kohortenklassifizierungen sowie Verhaltensmerkmalen, ermöglicht Benutzern eine erfüllende Erfahrung auf Embibe. Dies sind die ersten konkreten Schritte zur Lösung des Problems der positiven Beeinflussung von Lernergebnissen. Das ist personalisiertes Lernen.
In diesem Beitrag haben wir verschiedene Teilprobleme angesprochen, die gelöst werden müssen, um uns auf dem Weg zur Beeinflussung der Lernergebnisse voranzubringen. In unserem nächsten Beitrag werden wir darüber sprechen, wie wir bei Embibe verschiedene Metriken messen und verfolgen, die sich auf unsere Benutzer und ihre Aktivitäten beziehen, damit wir am Puls unseres Produkts, seines Wachstums und seiner Effektivität bleiben ein Online-Lernziel.
Wir sind immer auf der Suche nach schlauen Leuten, die unsere Reihen im Data Science Lab erweitern können. Wenn Sie gerne Hypothesen testen, Regressionen durchführen, riesige Matrizen faktorisieren, angesichts großer Datenmengen lachen, Map-Reduce-Jobs abfeuern, Themenmodelle über chaotischen unstrukturierten Text erstellen, verrauschte Daten für statistische Muster durchforsten, Berge von Daten aus offenen Daten aufnehmen Quellen, p-Werte argumentieren, neuronale Netze und Deep-Belief-Netze trainieren, zwischen Python und R wechseln, Visualisierungen hochdrehen und Shells skripten, Sie werden es hier lieben!
Senden Sie uns eine Nachricht mit Ihrem Lebenslauf an jobs.<id>@embibe.com, wo:
<id> ist die Zahl, die aus den ersten 8 Ziffern ungleich Null des Werts der Wahrscheinlichkeitsdichtefunktion für die Normalverteilung gebildet wird, auf 19 Stellen gerundet, und
mu ist die 26. Zahl in der Padovan-Sequenz, und
Sigma ist die 17. Zahl in der Fibonacci-Folge, beginnend bei 1, und
x ist die 1002. Primzahl
Unser Team besteht aus Keyur Faldu ( Chief Data Scientist), Achint Thomas ( Principal Data Scientist) und Chintan Donda (Data Scientist).
Verweise
- Bestandsaufnahme des Lernstils . Lawrence, KS: Preissysteme.
- Gregorc AF, (1982). Mind Styles Model: Theorie, Prinzipien und Anwendungen. Maynard, MA: Gabriel Systems.
Embibe hat kürzlich 3 Jahre auf dem Markt als eines der führenden Unternehmen im Bereich der Datenanalyse im Bildungsbereich abgeschlossen. Studenten haben allein im März 2016 über 100.000 Stunden mit dem Produkt verbracht, ohne in bezahltes Marketing investiert zu haben.