
300 milioni di studenti, 300 miliardi di approfondimenti – Innamorati dei dati nell'istruzione
Pubblicato: 2016-04-07Uno sguardo esclusivo all'interno del laboratorio di scienza dei dati di Embibe
[Questa è la seconda parte della serie Come utilizziamo la tecnologia approfondita e la scienza dei dati per personalizzare l'istruzione]
Abbiamo costruito Embibe con una visione unica: massimizzare i risultati di apprendimento su larga scala. Incidere positivamente sui risultati di apprendimento di un utente è un problema difficile, ma importante, da risolvere. In effetti, ci sono una serie di sottoproblemi aperti non banali, ognuno dei quali deve essere risolto per realizzare l'obiettivo nobile di influenzare intenzionalmente e positivamente i risultati dell'apprendimento.
Ma prima, quali sono i risultati dell'apprendimento? E perché ci teniamo a loro?
Nel mondo altamente competitivo di oggi, uno studente viene misurato in larga misura da quanto può segnare in un esame competitivo o persino in un'aula scolastica. Il suo punteggio può avere un impatto significativo sulle sue opzioni di carriera. Ai fini di questo articolo, inquadriamo i risultati dell'apprendimento in funzione del potenziale innato e formabile di uno studente, per apprendere, assorbire e applicare i contenuti in modo ottimale, entro limiti di tempo strettamente specificati; in modo che possa massimizzare il suo punteggio in qualsiasi particolare contesto accademico competitivo.
Nei paesi in via di sviluppo come l'India, il rapporto studenti-insegnanti è molto sbilanciato e gli insegnanti non possono fornire in modo efficace un'attenzione personalizzata a livello individuale. Questo porta a un dilemma, dato che ogni studente apprende e assorbe informazioni a velocità diverse e ha diversi livelli di attitudine. Un noto effetto collaterale dell'incapacità degli insegnanti di fornire un'attenzione personalizzata è che per ogni data classe/raccolta di studenti, il materiale didattico viene sempre presentato per soddisfare lo studente "medio". Pertanto, gli studenti molto brillanti non raggiungono il loro pieno potenziale e non saranno in grado di mostrare veramente i loro muscoli accademici, mentre gli studenti scolasticamente più deboli avranno difficoltà a far fronte al resto della classe. Tuttavia, le piattaforme e i sistemi di apprendimento online esistenti non sono in grado di facilitare veramente l'apprendimento personalizzato a livello di studente.
La maggior parte dei sistemi attuali tiene conto solo del modo in cui uno studente può abbinare le proprie soluzioni ai moduli di test come specificato da alcuni amministratori del sistema. L'apprendimento personalizzato per gli esami competitivi dovrebbe massimizzare il punteggio di uno studente per qualsiasi obiettivo accademico nel tempo limitato a sua disposizione. L'apprendimento personalizzato dovrebbe anche affrontare in modo costruttivo le lacune di abilità dello studente non solo a livello di conoscenze o attitudini, ma anche a livello attitudinale e comportamentale. Questa mancanza di strumenti efficaci per l'apprendimento personalizzato, su misura e precisamente per ogni studente, è responsabile del fatto che non sia in grado di realizzare il suo potenziale nel raggiungimento del punteggio massimo possibile in un dato esame.
In questo articolo, il team di scienza dei dati di embibe getterà le basi dei vari problemi correlati ai dati interconnessi che devono essere affrontati per massimizzare i risultati di apprendimento e, in particolare, il miglioramento del punteggio. Esistono due dimensioni principali di questo problema: importazione di contenuti e consegna di contenuti. Ogni dimensione pone sfide uniche in una serie di aree che sicuramente affascineranno qualsiasi scienziato di dati.
Ingestione di contenuti
Inserimento automatico dei contenuti
Decine di schede di programma, migliaia di capitoli e concetti e decine di migliaia di istituti e scuole generano centinaia di migliaia di domande e risposte generate e utilizzate dagli istruttori ogni anno. Immagina se ogni studente fosse in grado di testare le proprie conoscenze prima degli esami su qualsiasi sottoinsieme o tutte queste domande, oltre a ottenere spiegazioni dettagliate sulle risposte corrette e sugli errori comuni commessi. Affinché ciò diventi realtà, stiamo sfruttando il riconoscimento ottico dei caratteri (OCR) e l'apprendimento automatico per creare il nostro framework di importazione automatizzato che sarà altamente scalabile, veramente multilingue e minimamente dipendente dall'input umano. E il divertimento non finisce qui. Il framework sarà anche in grado di ingerire contenuti scritti a mano in modo indipendente dallo scrittore, aggiungendo così rapidamente al nostro già fantastico archivio di domande, risposte, concetti, spiegazioni e conoscenze.
Etichettatura concettuale
Bene, quindi ora abbiamo domande, risposte, concetti e capitoli tutti inseriti in un enorme data warehouse. Sarebbe doloroso etichettare manualmente ogni domanda o capitolo con i suoi concetti rilevanti, o viceversa. Data Science in soccorso! Utilizzando idee all'avanguardia dalla classificazione del testo, dalla modellazione degli argomenti e dal deep learning, tagghiamo automaticamente i concetti in domande, risposte e capitoli.

Una selezione dei concetti più popolari esplorati dagli utenti di Embibe utilizzando la funzione Impara, nei mesi di dicembre 2015, gennaio 2016 e febbraio 2016.
I nostri database precedenti contenenti set di semi di contenuti taggati manualmente di alta qualità sono strumentali poiché estraiamo funzionalità linguistiche, lessicali e sensibili al contesto, per addestrare modelli di codifica del testo all'avanguardia per tutti i nuovi dati che vengono inseriti nel nostro sistemi.
Arricchimento dei metadati
C'è una ricchezza di informazioni disponibili online oggi su qualsiasi argomento che si desidera conoscere. Idee e concetti si basano l'uno sull'altro. Ad esempio, la prima legge della termodinamica è correlata al concetto di sistema termodinamico, che a sua volta è correlato ai concetti di capacità termica specifica dei gas, conservazione dell'energia meccanica e lavoro svolto da un gas, tra gli altri. Il nostro framework di importazione dei contenuti include componenti di arricchimento dei dati che eseguono automaticamente la scansione del Web e taggano i contenuti con elementi multimediali così diversi come spiegazioni di testo, collegamenti a video, definizioni, commenti degli utenti e discussioni nei forum, il tutto nel rispetto dei diritti d'autore e attribuendo correttamente la proprietà ai contenuti di origine . Questa ricchezza di informazioni disponibili consente inoltre di collegare automaticamente concetti correlati in una struttura ad albero. Utilizzando idee dai campi della teoria dei grafi, del text mining e della propagazione di etichette su strutture sparse, creiamo collegamenti e interconnessioni tra concetti che condividono una relazione sorgente → destinazione.
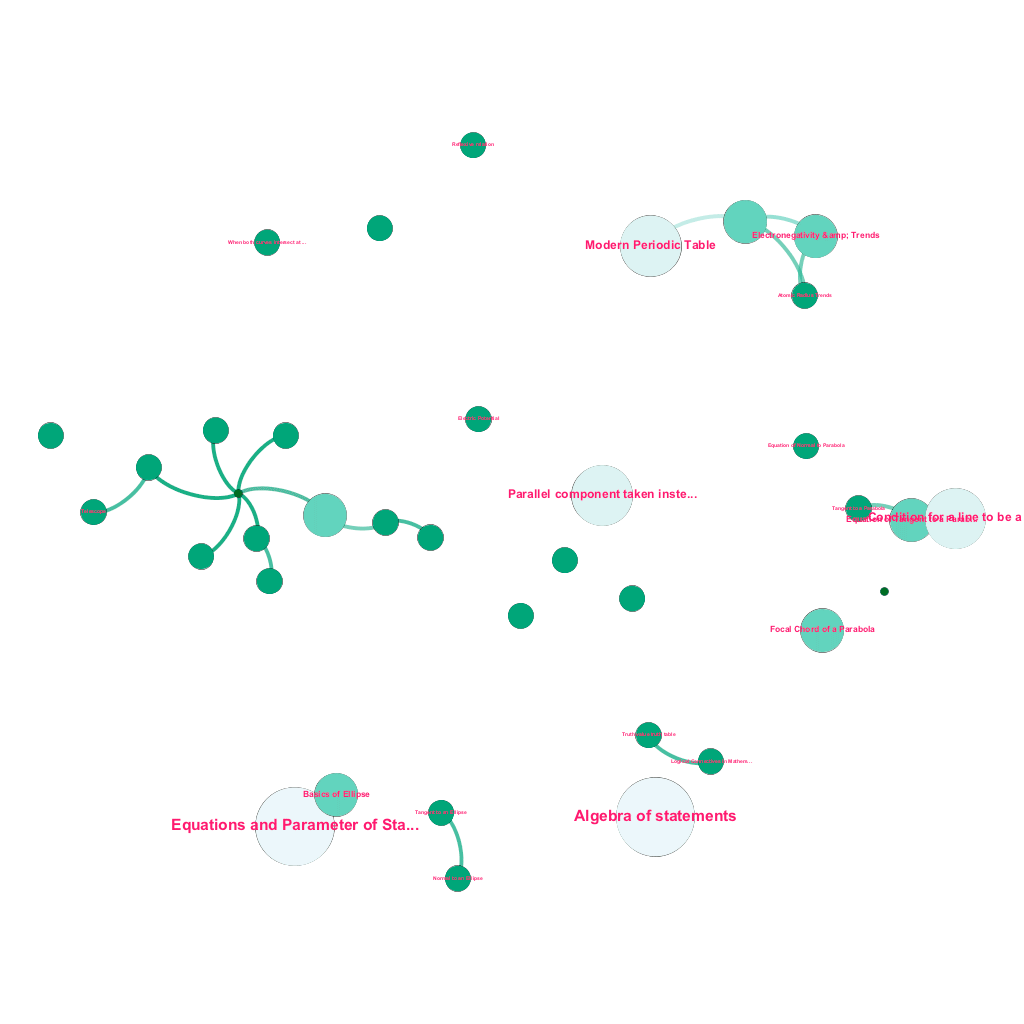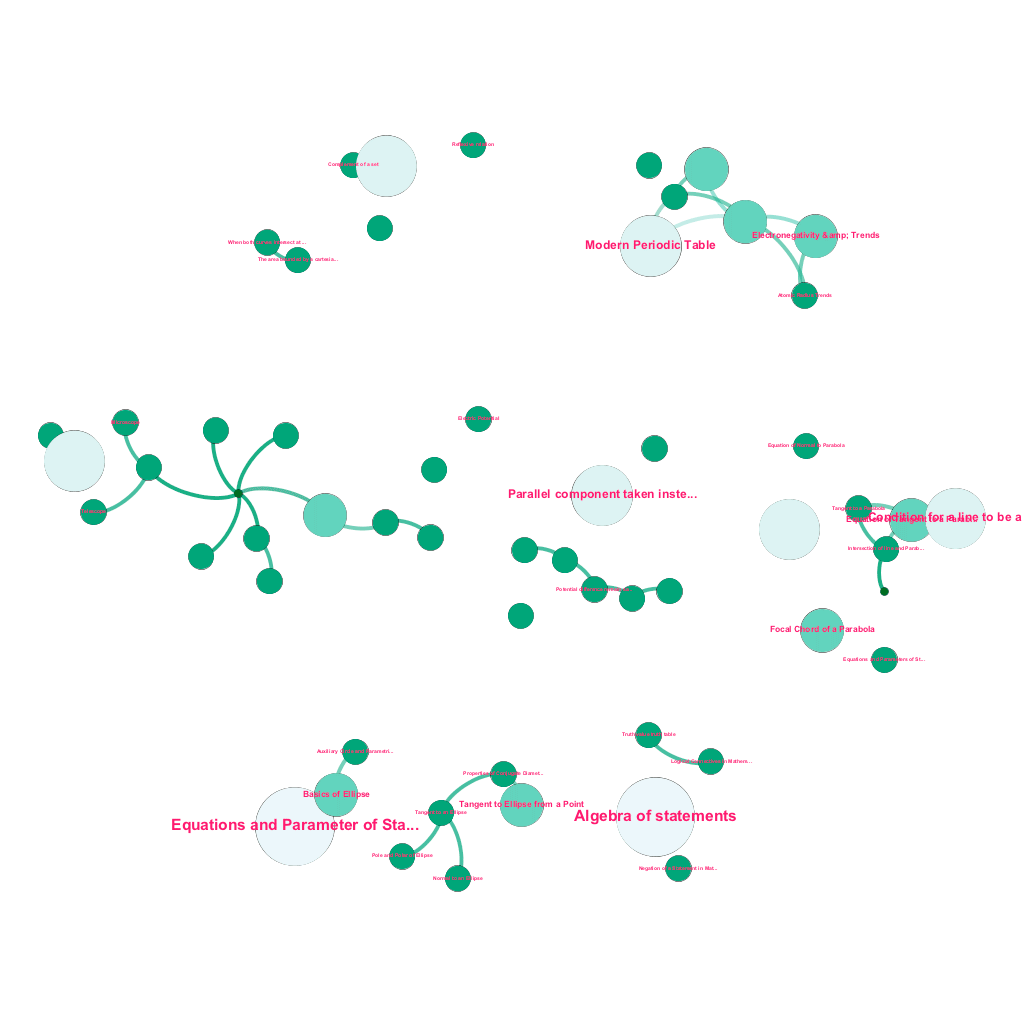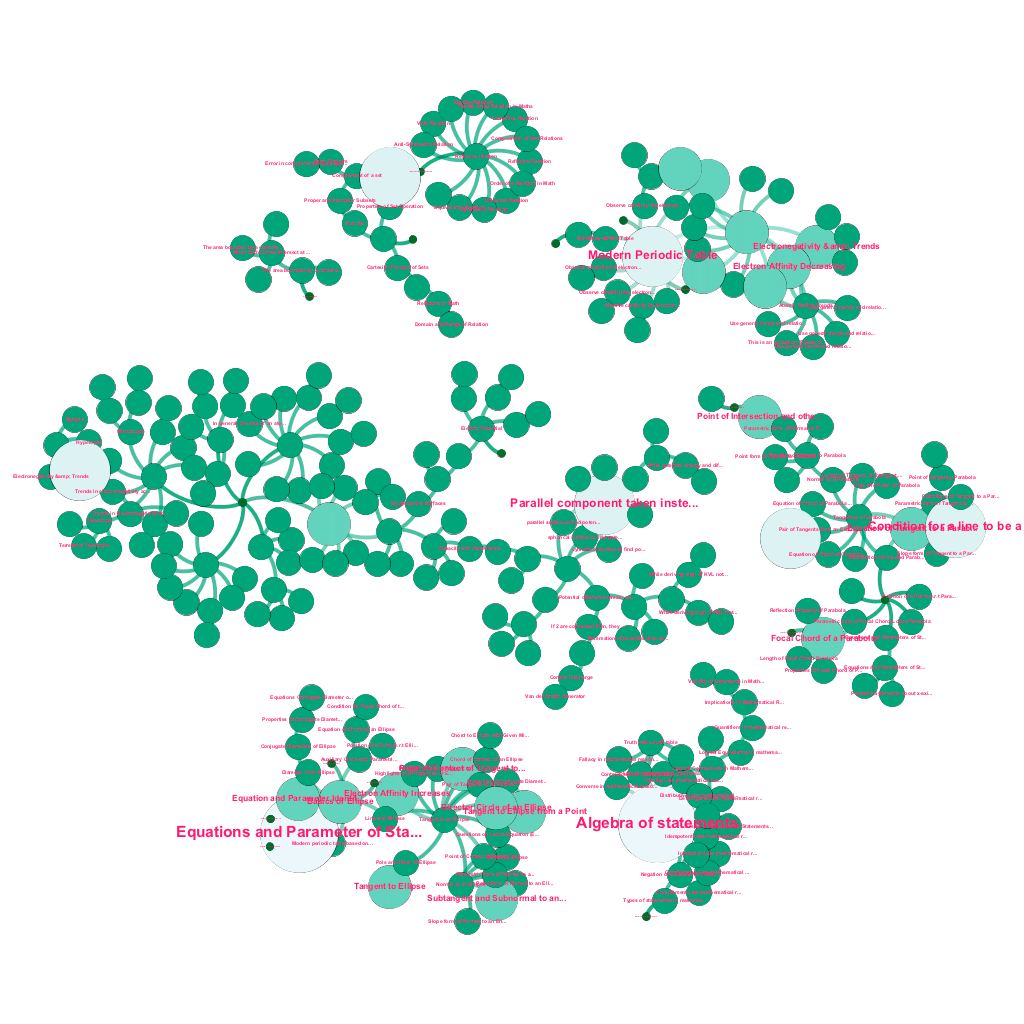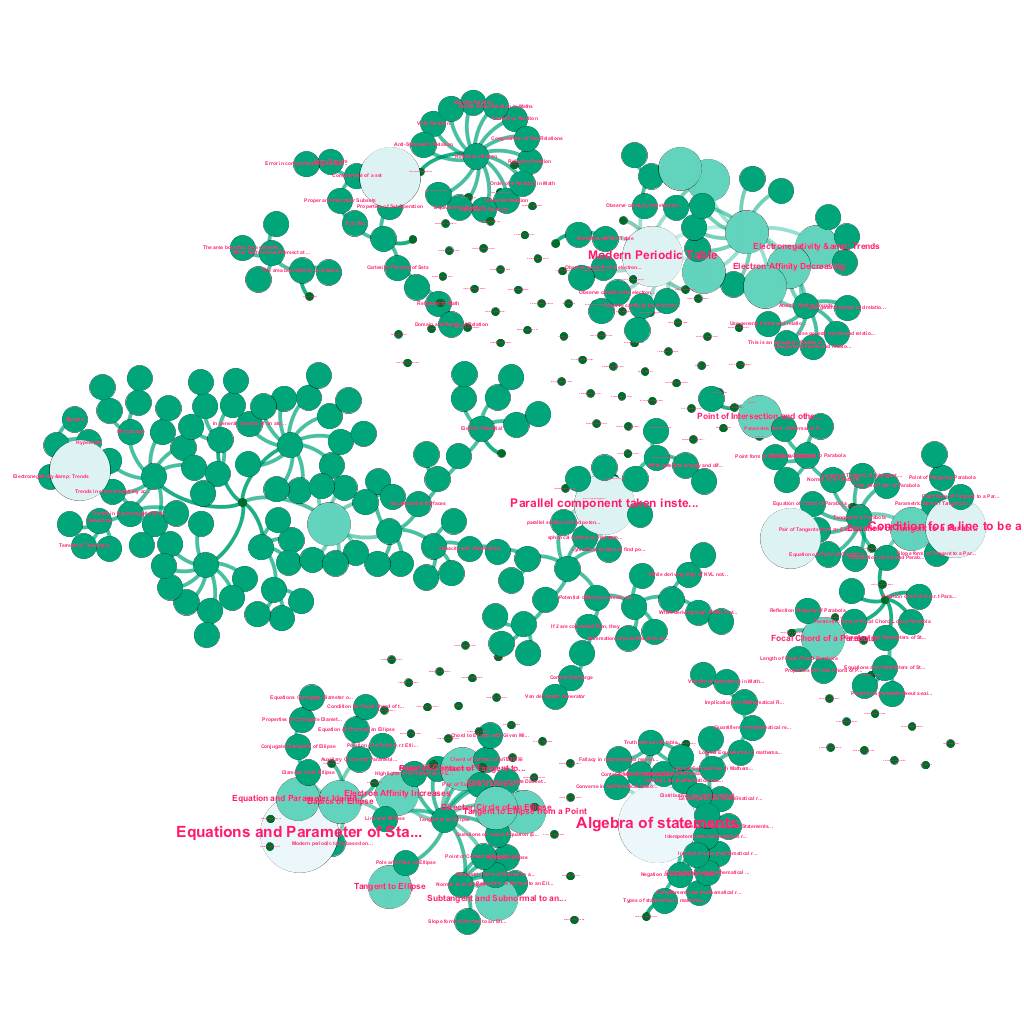
Creazione automatizzata di un albero di concetti, per un sottoinsieme di idee di matematica, ciascuna connessa a uno o più concetti correlati
Raggruppamento di domande simili
Se ti stessi preparando per un esame, vorresti esercitarti sulla stessa domanda più e più volte? Non sarebbe utile. Al contrario, immagina quanto sarebbe immensamente utile esercitarsi con una piccola serie di domande pertinenti che ti aiuteranno a padroneggiare completamente qualche nuovo concetto o capitolo. Con il nostro accesso a centinaia di migliaia di domande, abbiamo sviluppato la capacità di raggruppare le domande in base alla somiglianza su una serie di dimensioni: mirate al contenuto, testate sui concetti, livello di difficoltà e obiettivi dell'esame, tra le altre.
Il clustering del testo basato su spazi di informazioni semantiche latenti e la loro combinazione con altri spazi di funzionalità categoriali e numerici ci consentono di raggruppare con precisione il nostro universo di domande in aree di interesse che possono essere personalizzate per ogni individuo utilizzando Embibe. Inoltre, questa ricca risorsa di dati testuali che abbiamo trasformato in robusti spazi di funzionalità numerici relativi a cluster di concetti ci consente di perturbare leggermente i dati esistenti per generare espressioni potenzialmente infinite dello spazio delle domande. Altre domande in fase di esecuzione, mai viste prima! Questo ci permette di dare agli utenti il massimo valore per il loro tempo trascorso sulla nostra piattaforma.
Consegna dei contenuti
Profilazione utenti
Tracciamo ogni mossa che un utente fa su Embibe. I milioni di tentativi e prove effettuati dai nostri utenti negli ultimi tre anni sono calibrati in uno spazio dati di molte migliaia di dimensioni. Ciò si traduce in uno spazio di miliardi di punti dati che possiamo estrarre per scavare in profondità nei dati comportamentali dei nostri utenti e generare approfondimenti correlati al modo in cui avviene l'apprendimento. Ogni tentativo aggiuntivo da parte di un utente, modifica la sua capacità di ottenere un punteggio più alto sui concetti contrassegnati da quel tentativo, insieme ai concetti collegati precedenti e successivi. Questo problema super complesso comporta lo sfruttamento delle idee dall'elaborazione di matrici sparse, dagli algoritmi computazionali nella teoria dei grafi e dalla teoria della risposta degli elementi per costruire profili utente robusti e adattivi che si adattano alla nostra base di utenti in crescita.
Raccomandato per te:

Cosa significa la disposizione anti-profitto per le startup indiane?

In che modo le startup Edtech stanno aiutando la forza lavoro indiana a migliorare le competenze e a diventare pronte per il futuro...

Azioni tecnologiche new-age questa settimana: i problemi di Zomato continuano, EaseMyTrip pubblica stro...

Le startup indiane prendono scorciatoie alla ricerca di finanziamenti

Piattaforma di marketing digitale Logicserve Borse INR 80 Cr Finanziamenti, rinomina come LS Dig...

Il rapporto avverte di un rinnovato controllo normativo sullo spazio Lendingtech
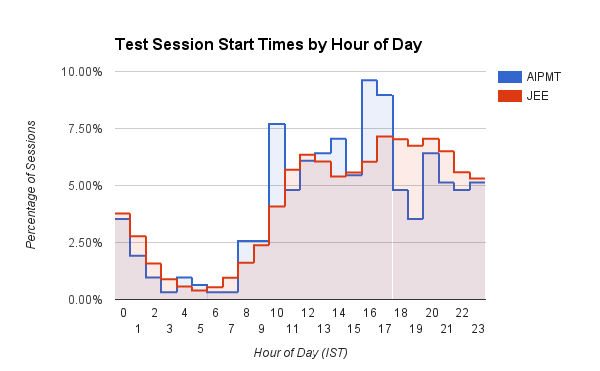
Un interessante grafico a barre che mostra l'ora (ora del giorno in IST) in cui gli utenti iniziano le loro sessioni di test su Embibe. Gli utenti medici (AIPMT) hanno un picco definito intorno alle 10:00 e tra le 15:00 e le 17:00. Gli utenti di Engineering (JEE), d'altra parte, mostrano orari di inizio sessione in graduale aumento con l'avanzare della giornata, con picchi tra le 16:00 e le 20:00. Gli studenti JEE iniziano anche costantemente più sessioni di pratica tra le 17:00 e le 3:00 rispetto agli studenti AIPMT. Immaginiamo che i medici siano più disciplinati!

La nostra vasta strumentazione e misurazione dell'attività degli utenti a un livello molto granulare ci dà la possibilità di dedurre preferenze latenti relative agli stili di apprendimento associati ai singoli utenti. Ad esempio, alcuni studenti possono imparare, e quindi svolgere i test, meglio con l'aiuto di spiegazioni video, rispetto ad altri studenti che preferiscono descrizioni testuali estese, o altri ancora che imparano lavorando passo dopo passo su problemi di esempio risolti. Possiamo mappare gli utenti su modelli teorici ben studiati di stili di apprendimento come il Dunn and Dunn Model (Dunn & Dunn 1989) o il Mind Styles Model di Gregorc (Gregorc 1982) per personalizzare automaticamente corsi di pratica correttivi e aiutare l'utente a migliorare il punteggio.
Coorte degli utenti
Il coorte è un classico problema di raggruppamento. Gli utenti sono raggruppati in base ai loro modelli di utilizzo rispetto alle caratteristiche del prodotto e ai loro modelli di prestazioni rispetto a sessioni di test, esercitazioni e revisioni. Ogni utente è mappato su uno spazio di funzionalità ad alta dimensione di molte migliaia di attributi, che includono misure statiche e temporali. Il coorte su misure temporali ci dà la possibilità di avviare a freddo una bassa attività e nuovi utenti assegnando probabili traiettorie di coorte a questi utenti in base alla loro attività iniziale. Il coorte degli utenti è un requisito fondamentale per le nostre funzionalità di deep science di livello superiore come l'apprendimento micro-adattivo, la generazione automatizzata di feedback e la raccomandazione dei contenuti.
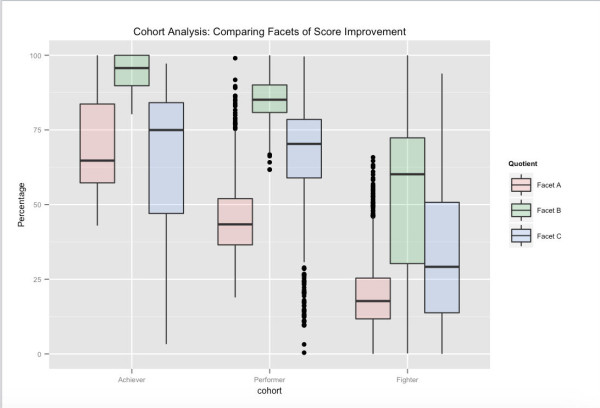
Una possibile visione delle coorti di utenti, legate alle prestazioni dei test a lungo termine. In base ai punteggi complessivi dei test, gli Achievers sono la fascia percentile più alta degli utenti su Embibe, gli Performers la fascia successiva e i Fighters la fascia finale. Le varie sfaccettature mostrate si riferiscono a diversi aspetti del miglioramento del punteggio in cui abbiamo raggruppato il nostro spazio di funzionalità. Ad esempio, possiamo vedere che anche se Facet_A varia in modo significativo tra le coorti, indirizzando il feedback e influenzando altri aspetti dell'apprendimento, è possibile spingere gli utenti nella successiva coorte superiore.
Apprendimento microadattivo
L'erogazione di contenuti e feedback di dimensioni ridotte è la chiave per l'apprendimento online in modo efficace. In genere, gli utenti trascorrono da 30 minuti a un'ora online, esercitandosi su concetti e domande. In questo breve lasso di tempo, è molto importante massimizzare l'impatto di ogni sessione limitata nel tempo. Ogni sessione è una risorsa per l'utente per massimizzare l'apprendimento, e questo si ottiene al meglio con la strategia di dimensioni ridotte. Il nostro motore micro-adattivo per sessioni di pratica, prende il profilo di un utente e gli attributi di coorte insieme al nostro albero delle conoscenze di 11.000 (e in crescita!) meta-attributi di concetti interconnessi come input e garantisce che la sequenza delle domande, i suggerimenti forniti e solo- il feedback in linea intelligente in tempo si adatta con precisione all'utente al fine di migliorare il suo risultato di apprendimento su qualsiasi obiettivo di dimensioni ridotte. Ogni consumo ridotto di contenuti o feedback avrà un impatto sulla calibrazione delle competenze dell'utente rispetto al nostro vasto albero di concetti di conoscenza. Tecniche di elaborazione di matrici sparse, teoria della risposta agli elementi e algoritmi grafici guidano la micro adattabilità dell'apprendimento.
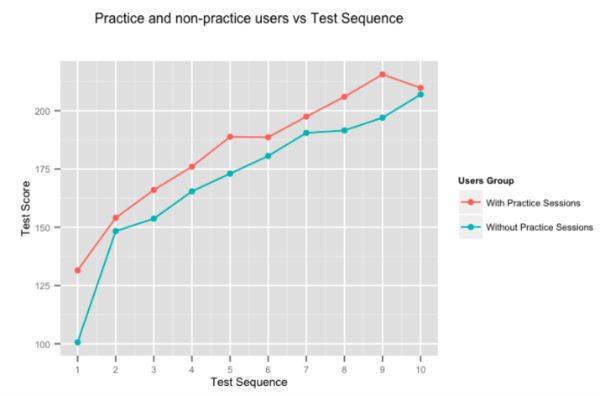
È abbastanza ovvio che la pratica rende uno perfetto, ma abbiamo deciso di eseguire comunque i numeri. La figura sopra mostra il miglioramento del punteggio medio degli utenti, per i test successivi forniti dagli utenti che trascorrono del tempo nelle nostre sessioni di pratica adattiva e quelli che non lo fanno. Gli utenti che si esercitano su Embibe superano costantemente quelli che non lo fanno di quasi il 10% test-on-test.
Sistema di feedback e raccomandazione
Il sistema di feedback e raccomandazione di Embibe (su cui abbiamo già depositato i brevetti) è progettato e realizzato per uno scopo: massimizzare il miglioramento del punteggio di un utente. Strumentiamo e interpretiamo migliaia di segnali sui tentativi di un utente durante le sessioni di pratica e test e trasformiamo questi segnali in uno spazio ad alta dimensione di migliaia di funzioni per ciascun utente. Utilizzando il pattern mining statistico sul nostro enorme spazio di funzionalità per i tentativi degli utenti, ci siamo concentrati sugli insiemi classificati di parametri che aumentano positivamente il punteggio di un utente. Questi parametri sono codificati automaticamente come capsule just-in-time altamente mirate di feedback sul miglioramento del punteggio e consegnati all'utente mentre continua con la sua sessione di pratica. Il feedback e le raccomandazioni espongono punti deboli e strategie che può adottare per massimizzare il suo punteggio.
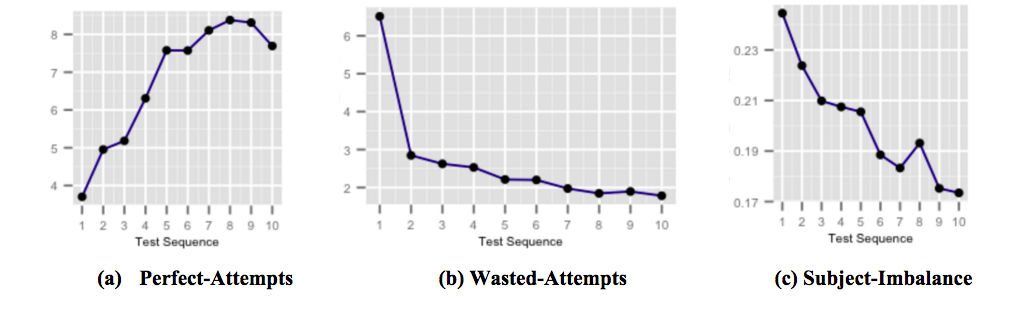
Le figure sopra mostrano come le nostre capsule di feedback just-in-time altamente mirate per il miglioramento del punteggio influiscano sulle prestazioni degli studenti quando l'utente è esposto e diventi consapevole delle insidie comuni nell'esecuzione dei test. La figura (a) mostra il numero medio di tentativi perfetti in aumento nei test successivi. I tentativi perfetti sono tentativi a cui viene data una risposta corretta entro un tempo stabilito. La figura (b) mostra il numero medio di tentativi sprecati in diminuzione rispetto ai test successivi. I tentativi sprecati sono tentativi a cui viene data una risposta errata in cui lo studente ha avuto più tempo che avrebbe potuto essere speso pensando alla domanda. E la figura (c) mostra lo squilibrio medio soggetto-accuratezza decrescente nei test successivi. Soggetto-accuratezza-sbilanciamento è definito come la differenza tra l'accuratezza più alta e quella più bassa tra tutti i soggetti in qualsiasi test effettuato da un utente. Uno squilibrio di accuratezza del soggetto maggiore implica che l'utente è meno preparato per determinati argomenti rispetto ad altri soggetti.
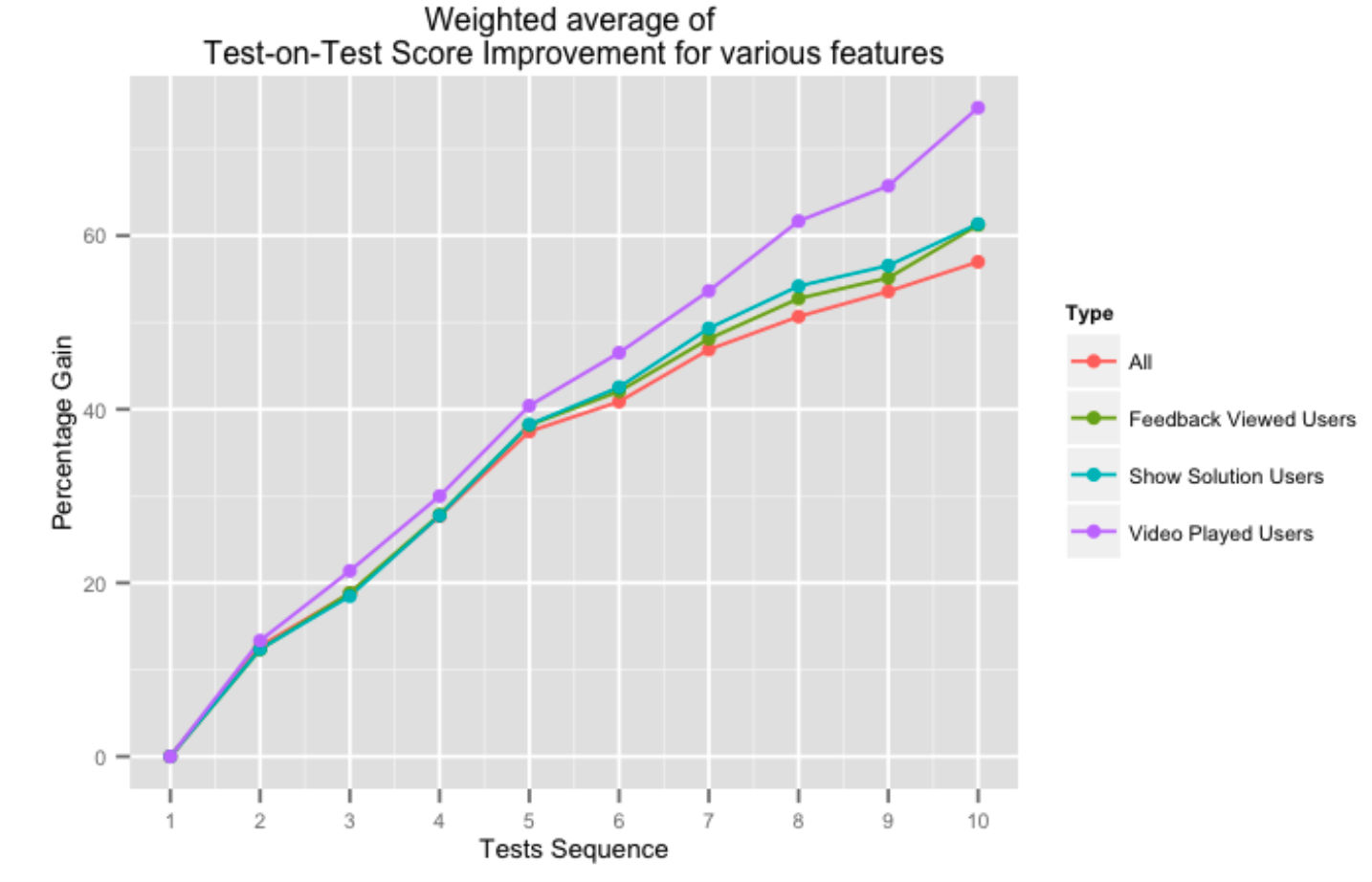
La figura sopra mostra l'aumento percentuale nei punteggi test-on-test successivi per gli utenti che utilizzano vari aspetti del nostro sistema di feedback. L'aiuto della nostra piattaforma sotto forma di soluzioni video o feedback generale sui test ha un impatto positivo sui punteggi dei test, soprattutto quando l'utente completa più test.
Stima del miglioramento del punteggio
Per gli utenti che si stanno preparando per esami di qualsiasi tipo, il miglioramento del punteggio è l'aspetto più importante per influenzare i risultati di apprendimento. La nostra ricchezza di dati comportamentali ci dà la possibilità di imparare dalle azioni passate degli utenti, misurando come il loro comportamento durante e dopo aver eseguito i test su Embibe influisca sul miglioramento del punteggio. Il data mining per modelli statistici in termini di utilizzo, attività e caratteristiche comportamentali, tra varie coorti di utenti, ci fornisce una prova scientifica dell'efficacia della nostra piattaforma.
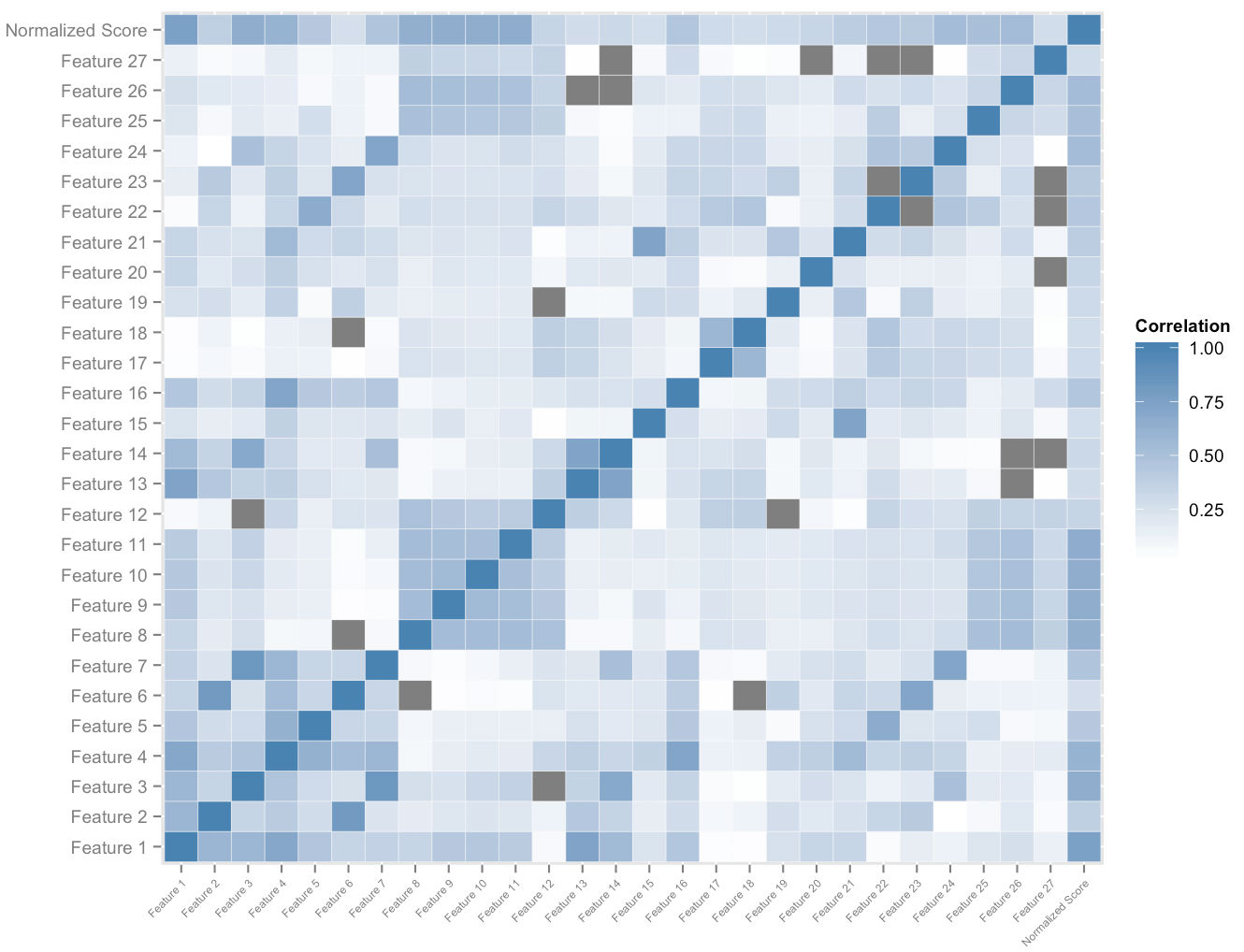
La figura sopra mostra un sottoinsieme dello spazio delle funzionalità che costruiamo per utente. L'analisi di correlazione incrociata sullo spazio delle caratteristiche e sui punteggi normalizzati complessivi ci fornisce un ordinamento sull'importanza relativa delle caratteristiche. Questo, insieme all'analisi empirica della dominanza, ci consente di misurare il quanto di impatto di ciascuna caratteristica sul suo contributo al miglioramento del punteggio. Una combinazione opportunamente ponderata delle velocità delle più importanti di queste caratteristiche ci consente di assegnare quantitativamente una misura del potenziale miglioramento del punteggio a ogni studente, che si adatta a lei mentre usa la piattaforma.
Questi sono tempi entusiasmanti per il campo dell'istruzione, specialmente in India e in altri paesi in via di sviluppo. È urgente applicare la scienza approfondita, con una forte attenzione all'utilizzo dei dati e delle intuizioni che possono fornire, al fine di portare l'istruzione e l'apprendimento al livello successivo. Le nostre piattaforme di importazione e consegna dei contenuti sono costruite su solidi principi scientifici e stanno aiutando gli utenti a realizzare un immenso valore su Embibe sotto forma di miglioramento del punteggio in tempi di preparazione limitati. Il nostro framework di apprendimento micro-adattivo che utilizza feedback e consigli specifici dell'utente, su misura per gli utenti, in base alle loro classificazioni di coorte e alle caratteristiche comportamentali, consente agli utenti di vivere un'esperienza appagante su Embibe. Questi sono i primi passi concreti per risolvere il problema dell'impatto positivo sui risultati dell'apprendimento. Questo è un apprendimento personalizzato.
In questo post, abbiamo toccato vari sottoproblemi che devono essere risolti per spostarci lungo la strada per influenzare i risultati dell'apprendimento. Nel nostro prossimo post parleremo di come misuriamo e monitoriamo le varie metriche di Embibe relative ai nostri utenti e alla loro attività, in modo da poter tenere un dito sul polso del nostro prodotto, sulla sua crescita e sulla sua efficacia come una destinazione di apprendimento online.
Siamo sempre alla ricerca di persone malvagie e intelligenti da aggiungere ai nostri ranghi al Data Science Lab. Se ti piace testare ipotesi, eseguire regressioni, fattorizzare matrici enormi, ridere di fronte ai big data, licenziare lavori di riduzione delle mappe, costruire modelli di argomenti su testo non strutturato disordinato, estrarre dati rumorosi per modelli statistici, ingerire montagne di dati da dati aperti fonti, litigare valori p, addestrare reti neurali e reti di credenze profonde, passare da Python a R, attivare visualizzazioni e scripting shell, lo adorerai qui!
Mandaci un messaggio con il tuo curriculum in offerte di lavoro.<id>@embibe.com, dove:
<id> è il numero formato con le prime 8 cifre diverse da zero del valore della funzione di densità di probabilità per la distribuzione normale, arrotondato a 19 cifre di precisione, e
mu è il 26° numero della sequenza padovana, e
sigma è il diciassettesimo numero nella sequenza di Fibonacci che inizia da 1, e
x è il 1002° numero primo
Il nostro team è composto da Keyur Faldu ( Chief Data Scientist), Achint Thomas ( Principal Data Scientist) e Chintan Donda (Data Scientist).
Riferimenti
- Inventario dello stile di apprendimento . Lawrence, KS: Sistemi di prezzo.
- Gregorc AF, (1982). Modello di stili mentali: teoria, principi e applicazioni. Maynard, MA: Gabriel Systems.
Embibe ha recentemente completato 3 anni sul mercato come una delle aziende leader nell'analisi dei dati dell'istruzione. Gli studenti hanno trascorso oltre 100.000 ore sul prodotto nel solo marzo 2016 con zero investimenti nel marketing a pagamento.