
300 миллионов студентов, 300 миллиардов идей — влюблены в данные в образовании
Опубликовано: 2016-04-07Эксклюзивный взгляд изнутри на лабораторию по науке о данных Embibe
[Это вторая часть серии статей о том, как мы используем глубокие технологии и науку о данных для персонализации образования]
Мы создали Embibe с единственной целью: максимизировать результаты обучения в любом масштабе. Оказание положительного влияния на результаты обучения пользователя — сложная, но важная задача, которую необходимо решить. На самом деле существует ряд нетривиальных открытых подзадач, каждая из которых должна быть решена для реализации высокой цели намеренного и положительного воздействия на результаты обучения.
Но прежде всего, что такое результаты обучения? И почему мы заботимся о них?
В сегодняшнем высококонкурентном мире учащийся в значительной степени измеряется тем, сколько он может набрать на конкурсном экзамене или даже в школьном классе. Ее оценка может оказать существенное влияние на ее варианты карьеры. Для целей этой статьи давайте сформулируем результаты обучения как функцию врожденного, а также обучаемого потенциала учащегося, чтобы оптимально изучать, усваивать и применять содержательный материал в строго определенные временные рамки; чтобы она могла максимизировать свой балл в любом конкретном соревновательном академическом контексте.
В развивающихся странах, таких как Индия, соотношение учеников и учителей сильно неравномерно, и учителя не могут эффективно обеспечивать персональное внимание на индивидуальном уровне. Это приводит к дилемме, учитывая, что каждый учащийся учится и усваивает информацию с разной скоростью и имеет разный уровень способностей. Известным побочным эффектом неспособности учителей обеспечить персональное внимание является то, что для любого данного класса/группы учащихся учебный материал всегда предоставляется для обслуживания «среднего» ученика. Таким образом, очень способные ученики не раскрывают весь свой потенциал и не смогут по-настоящему напрячь свои академические мускулы, в то время как ученикам, более слабым в учебе, будет трудно справиться с остальной частью класса. Однако существующие платформы и системы онлайн-обучения не могут по-настоящему способствовать персонализированному обучению на уровне учащихся.
Большинство современных систем учитывают только то, насколько хорошо учащийся может сопоставить свои решения с тестовыми модулями, как указано некоторым администратором системы. Индивидуальное обучение для конкурсных экзаменов должно максимизировать балл студента по любой академической цели за ограниченное время, доступное ему. Персонализированное обучение также должно конструктивно устранять пробелы в способностях учащегося не только на уровне знаний или способностей, но также на уровне установок и поведения. Это отсутствие эффективных инструментов для персонализированного обучения, разработанных конкретно и точно для каждого студента, является причиной того, что она не может реализовать свой потенциал в достижении максимально возможного балла на любом конкретном экзамене.
В этой статье группа специалистов по данным embibe заложит основу для различных взаимосвязанных проблем, связанных с данными, которые необходимо решить, чтобы добиться максимальных результатов обучения и, в частности, улучшения результатов. У этой проблемы есть два основных аспекта — прием контента и доставка контента. Каждое измерение ставит уникальные задачи в ряде областей, которые наверняка очаруют любого специалиста по данным.
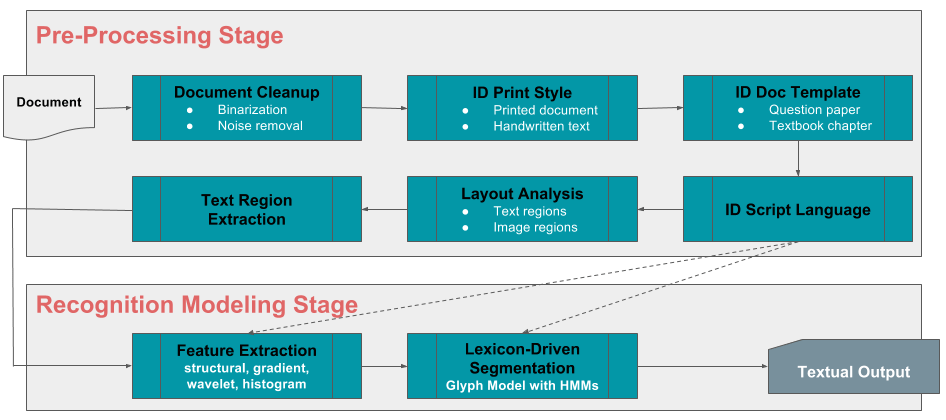
Загрузка контента
Автозагрузка контента
Десятки учебных досок, тысячи глав и понятий, десятки тысяч институтов и школ приводят к сотням тысяч вопросов и ответов, генерируемых и используемых преподавателями каждый год. Представьте, если бы каждый студент мог проверить свои знания перед экзаменом по любому подмножеству или всем этим вопросам, а также получить подробные объяснения правильных ответов и типичных ошибок. Чтобы воплотить это в жизнь, мы используем оптическое распознавание символов (OCR) и машинное обучение для создания собственной автоматизированной системы приема, которая будет масштабируемой, по-настоящему многоязычной и минимально зависящей от человеческого ввода. И на этом веселье не заканчивается. Фреймворк также сможет принимать рукописный контент независимо от автора, тем самым быстро добавляя к нашему и без того фантастическому хранилищу вопросов, ответов, концепций, объяснений и знаний.
Маркировка концепции
Итак, теперь у нас есть вопросы, ответы, концепции и главы, все они помещены в огромное хранилище данных. Было бы неудобно вручную помечать каждый вопрос или главу соответствующими понятиями или наоборот. Наука о данных спешит на помощь! Используя самые передовые идеи из классификации текстов, моделирования тем и глубокого обучения, мы автоматически присваиваем понятиям вопросы, ответы и главы.

Подборка наиболее популярных концепций, просмотренных пользователями Embibe с помощью функции «Обучение» в декабре 2015 г., январе 2016 г. и феврале 2016 г.
Наши предыдущие базы данных, содержащие исходные наборы высококачественного помеченного вручную контента, играют важную роль, поскольку мы извлекаем лингвистические, лексические и контекстно-зависимые функции для обучения современных моделей текстовых тегов для всех новых данных, поступающих в нашу систему. системы.
Обогащение метаданных
Сегодня в Интернете можно найти огромное количество информации по любой теме, о которой хочется узнать. Идеи и концепции строятся друг на друге. Например, Первый закон термодинамики связан с концепцией термодинамической системы, которая, в свою очередь, связана, среди прочего, с концепциями удельной теплоемкости газов, сохранения механической энергии и работы, совершаемой газом. Наша структура приема контента включает в себя компоненты обогащения данных, которые автоматически сканируют Интернет и помечают контент такими разнообразными фрагментами мультимедиа, как текстовые пояснения, ссылки на видео, определения, комментарии пользователей и обсуждения на форуме, при соблюдении авторских прав и надлежащем указании прав собственности на исходный контент. . Это богатство доступной информации также позволяет автоматически связывать связанные понятия в древовидную структуру. Используя идеи из области теории графов, интеллектуального анализа текста и распространения меток на разреженных структурах, мы создаем связи и взаимосвязи между понятиями, которые имеют отношение источник→цель.
Автоматическое построение дерева понятий для подмножества идей из математики, каждое из которых связано с одним или несколькими связанными понятиями.
Кластеризация похожих вопросов
Если бы вы готовились к экзамену, хотели бы вы повторять один и тот же вопрос снова и снова? Это было бы бесполезно. И наоборот, представьте, насколько полезно было бы попрактиковаться с небольшим набором соответствующих вопросов, которые помогут вам полностью освоить какую-то новую концепцию или главу. Имея доступ к сотням тысяч вопросов, мы разработали возможность группировать вопросы на основе сходства по ряду параметров — ориентированных на содержание, проверенных концепций, уровня сложности и целей экзамена, среди прочего.
Кластеризация текста, основанная на скрытых семантических информационных пространствах, и их комбинация с другими категориальными и числовыми пространствами признаков позволяют нам точно сгруппировать нашу совокупность вопросов в области интересов, которые могут быть адаптированы для каждого человека с помощью Embibe. Кроме того, этот богатый ресурс текстовых данных, которые мы преобразовали в надежные числовые пространства признаков, связанные с кластерами понятий, позволяет нам слегка искажать существующие данные для создания потенциально бесконечных выражений пространства вопросов. Больше вопросов во время выполнения, никогда не видел раньше! Это позволяет нам предоставлять пользователям максимальную ценность за время, проведенное на нашей платформе.
Доставка контента
Профилирование пользователей
Мы отслеживаем каждое движение пользователя на Embibe. Миллионы практических и тестовых попыток, предпринятых нашими пользователями за последние три года, откалиброваны в пространстве данных многих тысяч измерений. Это означает пространство из миллиардов точек данных, которые мы можем анализировать, чтобы углубиться в поведенческие данные наших пользователей и получить информацию, коррелирующую с тем, как происходит обучение. Каждая дополнительная попытка пользователя настраивает его способность набирать более высокие баллы по понятиям, помеченным для этой попытки, а также по связанным предшествующим и последующим понятиям. Эта сверхсложная задача включает в себя использование идей из обработки разреженных матриц, вычислительных алгоритмов в теории графов и теории отклика элементов для создания надежных и адаптивных профилей пользователей, которые масштабируются по мере роста нашей пользовательской базы.
Рекомендуется для вас:

Что означает положение о борьбе со спекуляцией для индийских стартапов?

Как стартапы Edtech помогают повысить квалификацию рабочей силы Индии и стать готовыми к будущему ...

Технологические акции нового века на этой неделе: проблемы Zomato продолжаются, EaseMyTrip публикует...

Индийские стартапы срезают путь в погоне за финансированием

Цифровая маркетинговая платформа Logicserve Bags Финансирование 80 CR INR, ребрендинг как LS Dig...

Отчет предупреждает о возобновлении нормативного контроля над Lendingtech Space
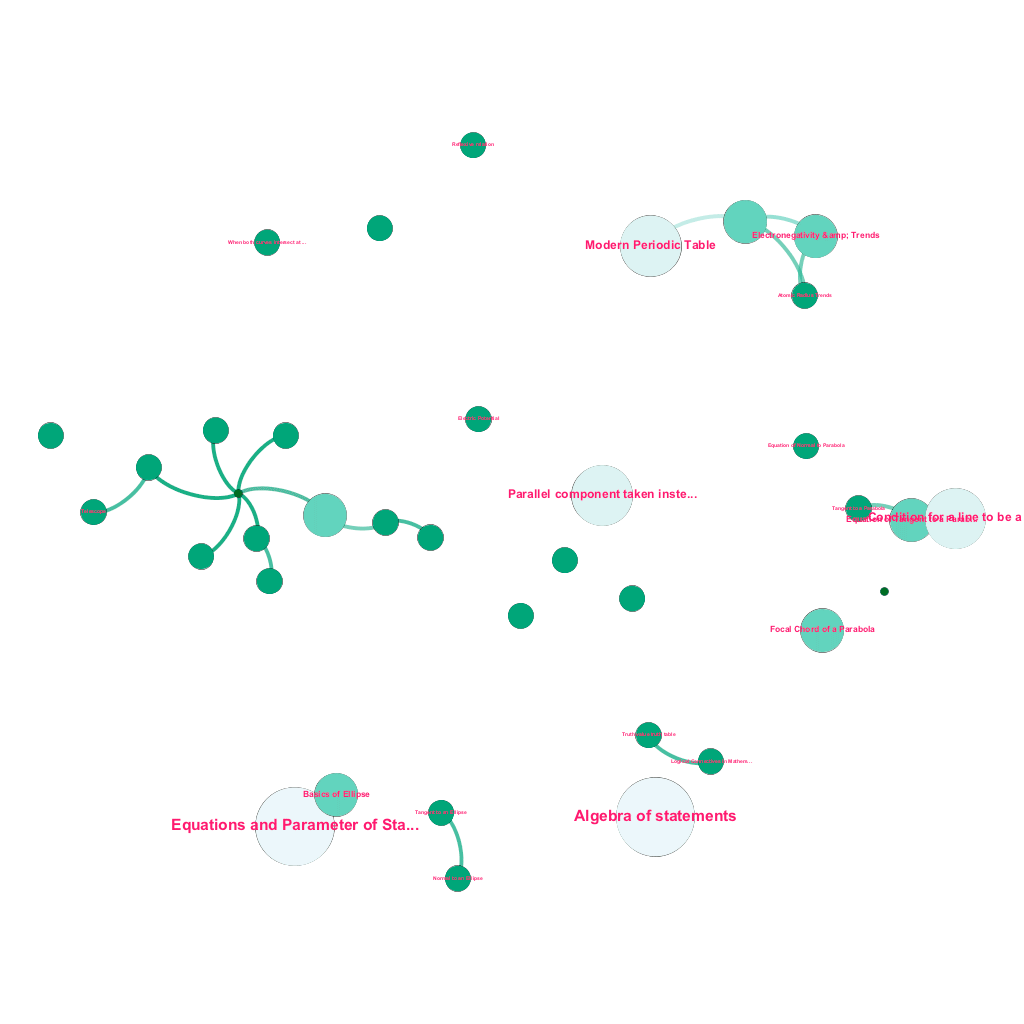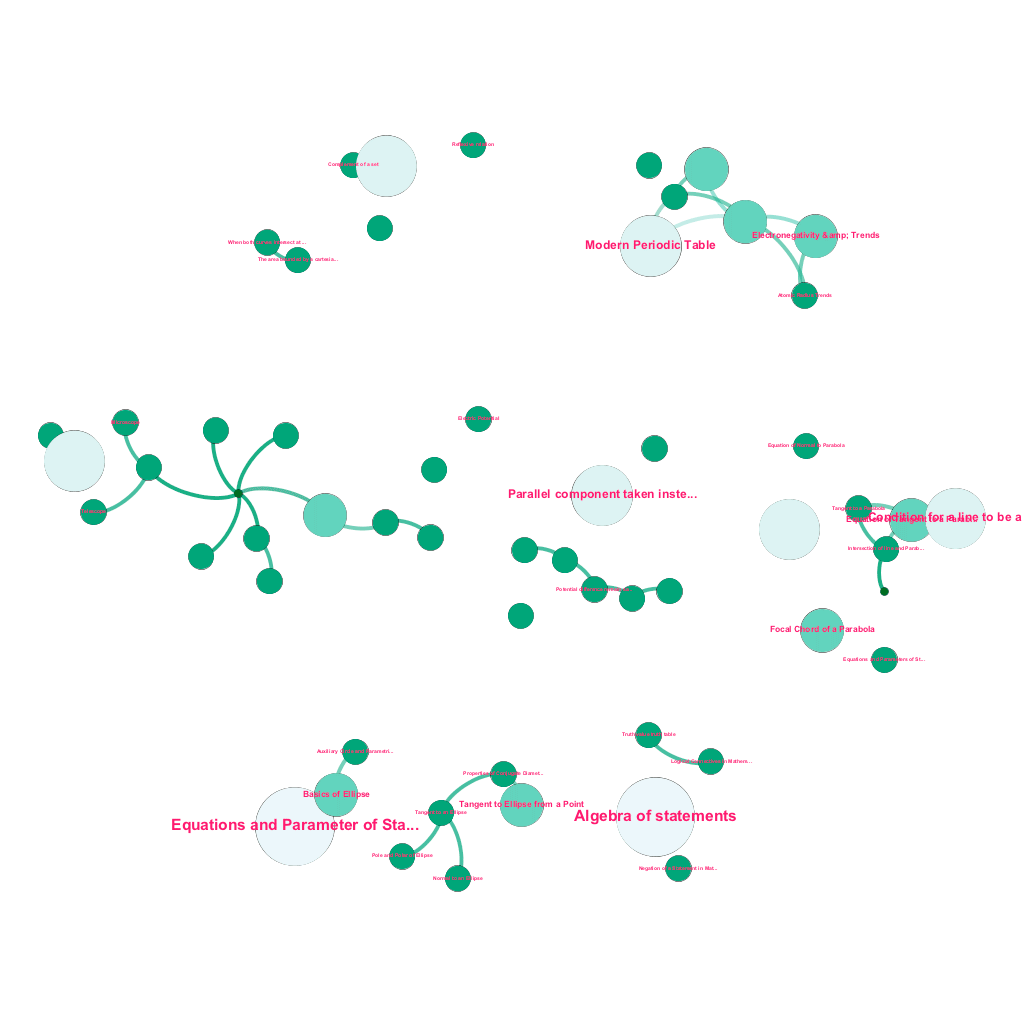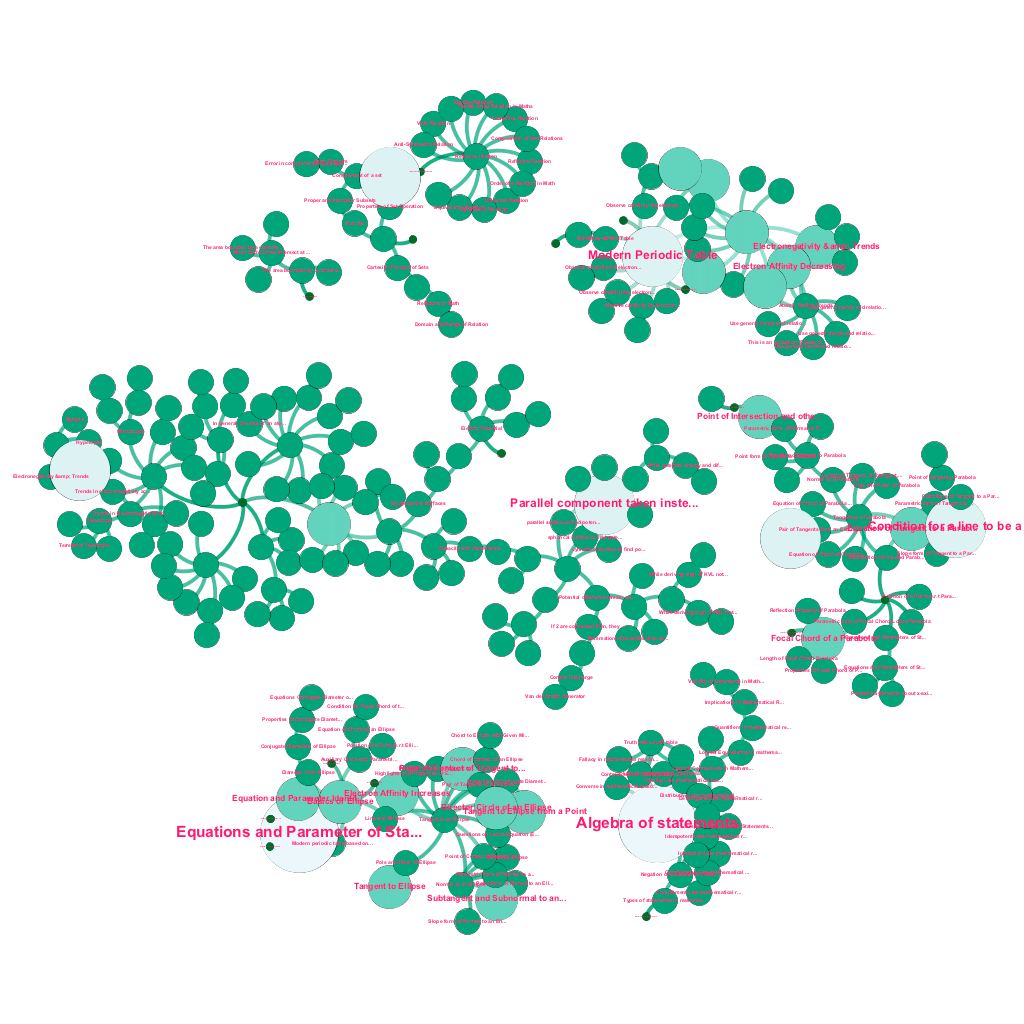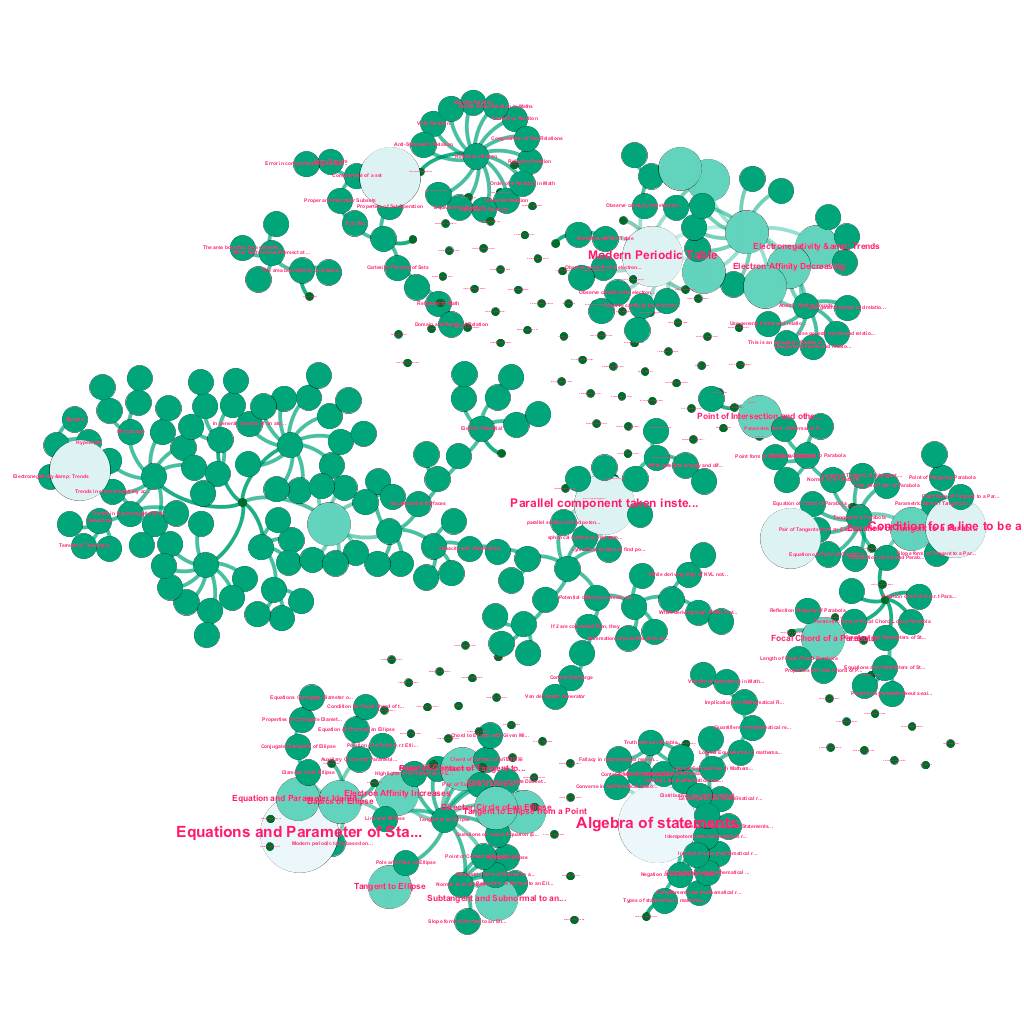
Интересная гистограмма, показывающая время (час дня в IST), когда пользователи начинают свои тестовые сеансы на Embibe. Медицинские пользователи (AIPMT) имеют определенный всплеск примерно в 10:00 и между 15:00 и 17:00. С другой стороны, инженеры (JEE) показывают постепенное увеличение времени начала сеанса в течение дня, которое достигает пика примерно с 16:00 до 20:00. Студенты JEE также постоянно начинают больше практических занятий с 17:00 до 3:00 по сравнению со студентами AIPMT. Мы предполагаем, что врачи стали более дисциплинированными!

Наш обширный инструментарий и измерение активности пользователей на очень детальном уровне дает нам возможность делать выводы о скрытых предпочтениях, связанных со стилями обучения, связанными с отдельными пользователями. Например, некоторые учащиеся могут учиться, а затем выполнять тесты лучше с помощью видеообъяснений, по сравнению с другими учащимися, которые предпочитают подробные текстовые описания, или теми, кто учится, шаг за шагом решая примеры задач. Мы можем сопоставить пользователей с хорошо изученными теоретическими моделями стилей обучения, такими как модель Данна и Данна (Dunn & Dunn, 1989) или модель стилей мышления Грегорка (Gregorc, 1982), чтобы автоматически адаптировать корректирующие курсы практики и помочь пользователю улучшить результаты.
Когортинг пользователей
Когортинг — классическая задача кластеризации. Пользователи группируются на основе их моделей использования в отношении функций продукта, а также моделей их производительности в отношении сеансов тестирования, практики и проверки. Каждый пользователь сопоставляется с многомерным пространством признаков, состоящим из многих тысяч атрибутов, которые включают в себя как статические, так и временные измерения. Когортинг по временным показателям дает нам возможность холодного старта низкой активности и новых пользователей, назначая этим пользователям вероятные когортные траектории на основе их первоначальной активности. Группировка пользователей является основным требованием для наших функций глубокой науки более высокого уровня, таких как микроадаптивное обучение, автоматическая генерация отзывов и рекомендации по контенту.
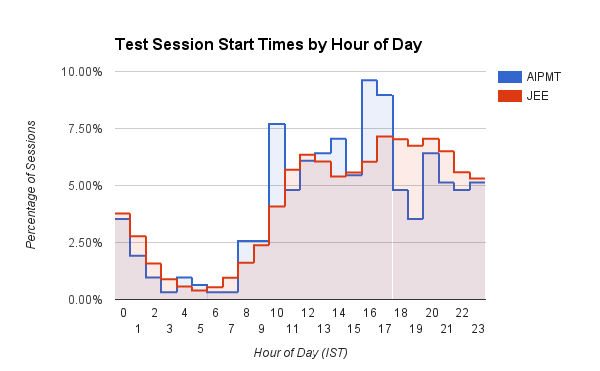
Одно из возможных представлений о когортах пользователей — привязано к результатам долгосрочных тестов. Основываясь на их общих результатах тестов, Достиженцы составляют верхнюю процентильную группу пользователей Embibe, Исполнители — следующую группу, а Бойцы — последнюю группу. Различные показанные аспекты относятся к различным аспектам улучшения оценки, в которые мы сгруппировали наше пространство признаков. Например, мы можем видеть, что, несмотря на то, что Facet_A значительно различается между когортами, нацеливая обратную связь на другие аспекты обучения и влияя на них, можно подтолкнуть пользователей к следующей более высокой когорте.
Микроадаптивное обучение
Предоставление контента размером с укус и обратная связь являются ключом к эффективному онлайн-обучению. Как правило, пользователи проводят в сети от 30 минут до часа, отрабатывая концепции и вопросы. В течение этого короткого промежутка времени очень важно максимизировать воздействие каждого ограниченного по времени сеанса. Каждый сеанс является активом для пользователя, позволяющим максимизировать обучение, и это лучше всего достигается с помощью стратегии размером с укус. Наш микроадаптивный механизм для практических занятий использует в качестве входных данных профиль пользователя и атрибуты когорты, а также наше дерево знаний из 11 000 (и их число растет!) своевременная интеллектуальная встроенная обратная связь точно адаптируется к пользователю, чтобы улучшить его результаты обучения при достижении любой небольшой цели. Каждое потребление контента или отзывов размером с укус будет влиять на калибровку навыков пользователя в соответствии с нашим обширным деревом знаний концепций. Методы обработки разреженных матриц, теория ответов на вопросы и алгоритмы графов обеспечивают микроадаптивность обучения.
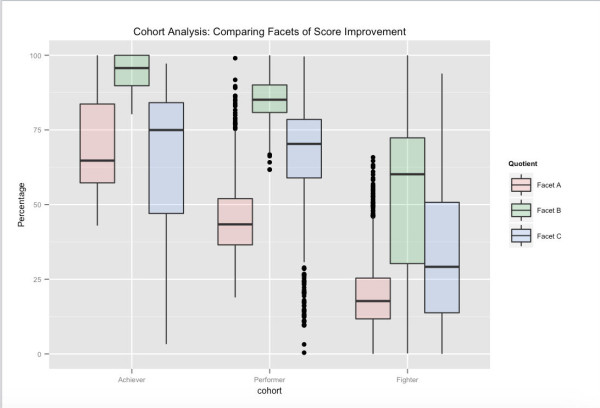
Совершенно очевидно, что практика делает человека совершенным, но мы все равно решили подсчитать. На приведенном выше рисунке показано среднее улучшение результатов пользователей для последовательных тестов, проведенных пользователями, которые проводят время на наших адаптивных практических занятиях, и теми, кто этого не делает. Пользователи, которые тренируются на Embibe, постоянно превосходят тех, кто этого не делает, почти на 10% в тесте за тестом.
Система обратной связи и рекомендаций
Система обратной связи и рекомендаций Embibe (на которую мы уже подали заявки на патенты) разработана и построена с одной целью — максимизировать улучшение результатов пользователя. Мы анализируем и интерпретируем тысячи сигналов о попытках пользователя во время практических и тестовых сессий и преобразовываем эти сигналы в многомерное пространство тысяч функций для каждого пользователя. Используя анализ статистических шаблонов в нашем огромном пространстве функций, основанных на попытках пользователей, мы сосредоточились на ранжированных наборах параметров, которые положительно влияют на оценку пользователя. Эти параметры закодированы машинным кодом в виде адресных мгновенных капсул с отзывами об улучшении оценки и доставляются пользователю, пока он продолжает свою тренировку. Отзывы и рекомендации выявляют слабые стороны и стратегии, которые она может использовать, чтобы максимизировать свой балл.
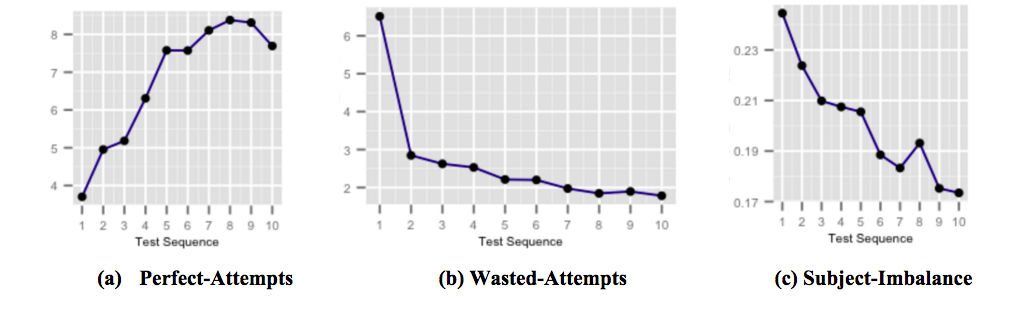
На приведенных выше рисунках показано, как наши узкоспециализированные капсулы обратной связи «точно в срок» для улучшения результатов влияют на успеваемость учащихся, поскольку пользователь сталкивается с распространенными ловушками при сдаче теста и узнает о них. На рисунке (а) показано увеличение среднего количества совершенных попыток по сравнению с последовательными тестами. Совершенные попытки — это попытки, на которые даны правильные ответы в течение определенного оговоренного времени. На рисунке (b) показано среднее количество потерянных попыток, уменьшающееся в ходе последовательных тестов. Напрасные попытки - это попытки с неправильным ответом, когда у студента было больше времени, чем можно было бы потратить на обдумывание вопроса. На рисунке (с) показано, как среднее значение дисбаланса предметной точности уменьшается в ходе последовательных тестов. Дисбаланс предметной точности определяется как разница между самой высокой и самой низкой точностью среди всех испытуемых в любом тесте, пройденном пользователем. Более высокий дисбаланс предметной точности означает, что пользователь менее подготовлен к определенным предметам по сравнению с другими предметами.
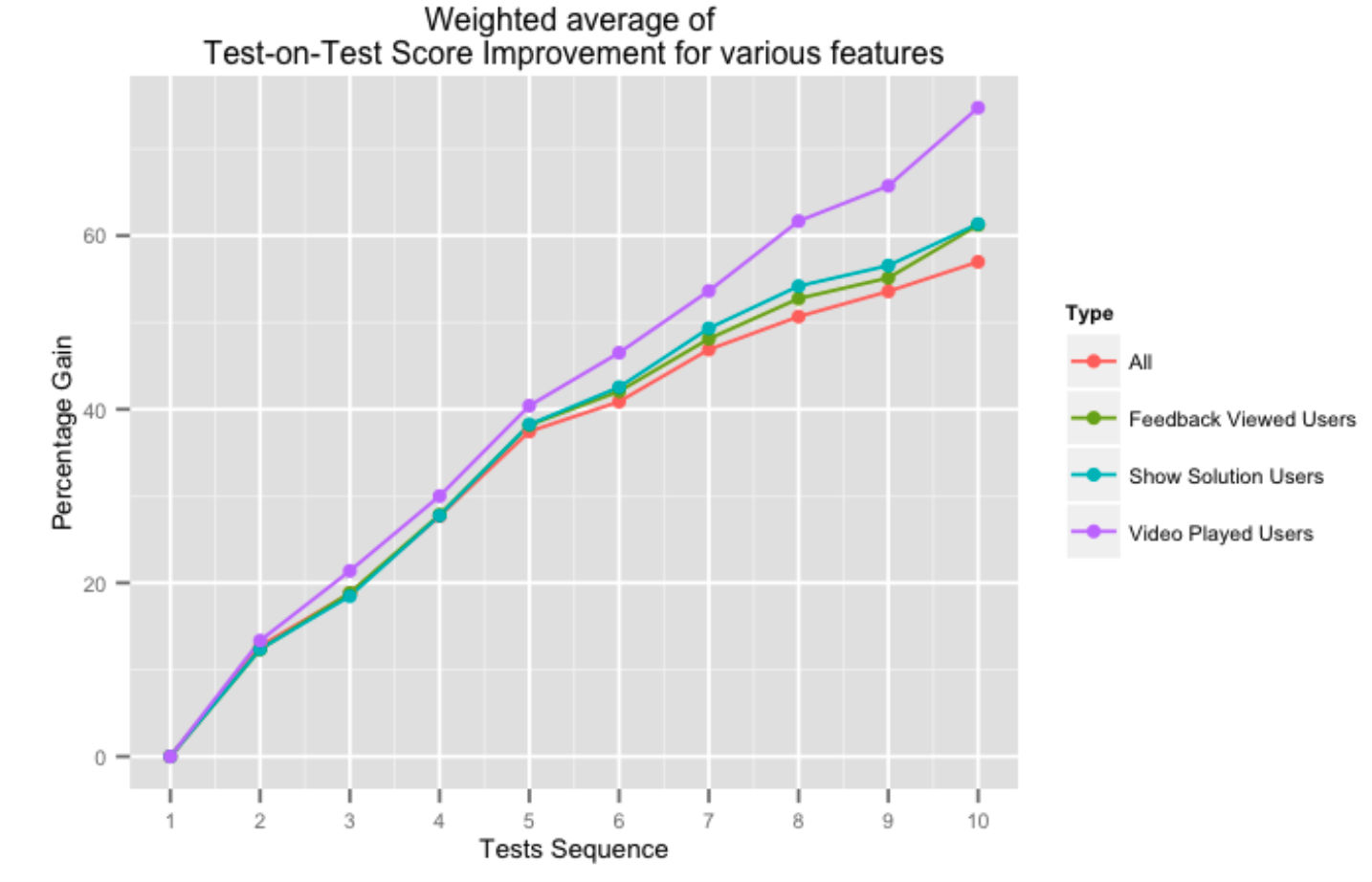
На приведенном выше рисунке показано процентное увеличение последовательных результатов теста за тестом для пользователей, которые используют различные аспекты нашей системы обратной связи. Получение помощи от нашей платформы в виде видеорешений или общих отзывов о тестах положительно влияет на результаты тестов, особенно по мере того, как пользователь выполняет больше тестов.
Оценка улучшения оценки
Для пользователей, которые готовятся к экзаменам любого рода, улучшение результатов является наиболее важным аспектом, влияющим на результаты обучения. Наше множество поведенческих данных дает нам возможность учиться на прошлых действиях пользователей, измеряя, как их поведение во время и после прохождения тестов на Embibe влияет на улучшение результатов. Интеллектуальный анализ данных для статистических моделей использования, активности и поведенческих характеристик среди различных групп пользователей дает нам научно обоснованное доказательство эффективности нашей платформы.
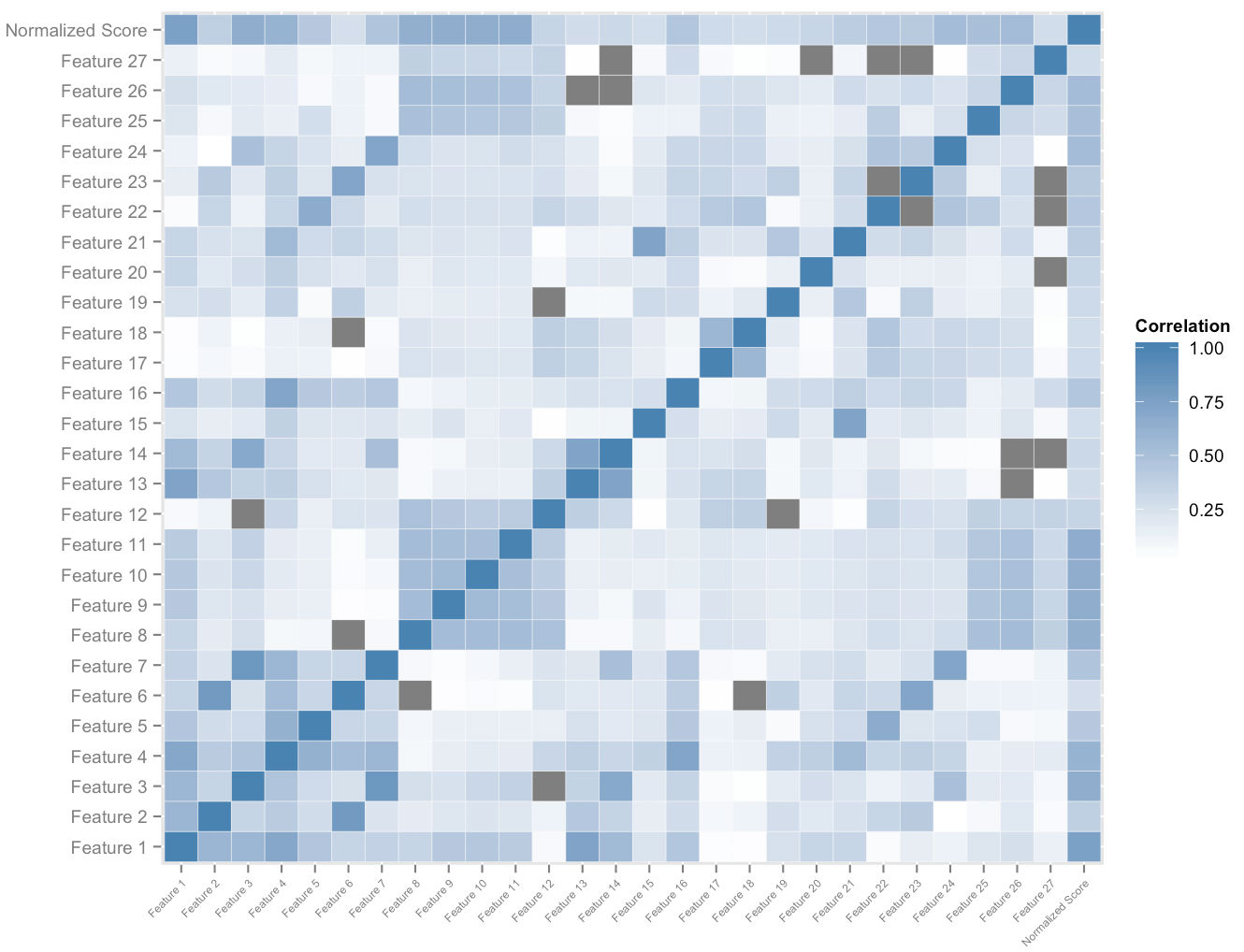
На рисунке выше показано подмножество пространства функций, которое мы создаем для каждого пользователя. Взаимный корреляционный анализ пространства признаков и общих нормализованных оценок дает нам порядок относительной важности признаков. Это, вместе с эмпирическим анализом доминирования, позволяет нам измерить количество влияния каждой функции на ее вклад в улучшение оценки. Соответствующим образом взвешенная комбинация скоростей наиболее важных из этих функций позволяет нам количественно определить меру потенциального улучшения результатов для каждого ученика, который адаптируется к нему по мере использования платформы.
Это захватывающее время для сферы образования, особенно в Индии и других развивающихся странах. Существует острая необходимость применять глубокую науку, уделяя особое внимание использованию данных и информации, которую они могут дать, чтобы вывести образование и обучение на новый уровень. Наши платформы приема и доставки контента строятся на прочных научных принципах и помогают пользователям осознать огромную ценность Embibe в виде улучшения результатов за ограниченные промежутки времени на подготовку. Наша микроадаптивная структура обучения, которая использует отзывы и рекомендации пользователей, точно адаптированные для пользователей, основанные на их когортных классификациях, а также на поведенческих характеристиках, позволяет пользователям получить полноценный опыт работы с Embibe. Это первые конкретные шаги к решению проблемы положительного влияния на результаты обучения. Это индивидуальное обучение.
В этом посте мы затронули различные подпроблемы, которые необходимо решить, чтобы продвинуться по пути к влиянию на результаты обучения. В следующем посте мы поговорим о том, как мы в Embibe измеряем и отслеживаем различные показатели, связанные с нашими пользователями и их активностью, чтобы мы могли держать руку на пульсе нашего продукта, его роста и эффективности по мере место для онлайн-обучения.
Мы всегда ищем злых умных людей, чтобы пополнить наши ряды в Data Science Lab. Если вам нравится проверять гипотезы, запускать регрессии, разлагать на множители огромные матрицы, смеяться над большими данными, запускать задания по уменьшению карты, строить тематические модели на основе беспорядочного неструктурированного текста, извлекать зашумленные данные для получения статистических закономерностей, поглощать горы данных из открытых данных источники, обсуждение p-значений, обучение нейронных сетей и сетей глубокого убеждения, переключение между Python и R, раскрутка визуализаций и скриптовые оболочки — вам здесь понравится!
Напишите нам свое резюме по адресу jobs.<id>@embibe.com, где:
<id> — число, образованное первыми 8 ненулевыми цифрами значения функции плотности вероятности для нормального распределения, округленное до 19 цифр точности, и
mu — 26-е число в последовательности Падована, а
сигма — это 17-е число в последовательности Фибоначчи, начиная с 1, и
х — 1002-е простое число
В нашу команду входят Кейур Фалду ( главный специалист по данным), Ачинт Томас ( главный специалист по данным) и Чинтан Донда (специалист по данным ).
использованная литература
- Инвентаризация стилей обучения . Лоуренс, Канзас: Ценовые системы.
- Грегорц А.Ф., (1982). Модель стилей разума: теория, принципы и приложения. Мейнард, Массачусетс: Системы Габриэля.
Embibe недавно завершила 3 года работы на рынке в качестве одной из передовых компаний в области анализа данных в сфере образования. Только в марте 2016 года студенты потратили более 100 000 часов на продукт, не инвестируя в платный маркетинг.