
300 millions d'étudiants, 300 milliards d'idées - Amoureux des données dans l'éducation
Publié: 2016-04-07Un regard exclusif sur le laboratoire de science des données d'Embibe
[Ceci est la deuxième partie de la série Comment nous utilisons la technologie profonde et la science des données pour personnaliser l'éducation]
Nous avons construit Embibe avec une vision singulière : maximiser les résultats d'apprentissage à grande échelle. Avoir un impact positif sur les résultats d'apprentissage d'un utilisateur est un problème difficile, mais important, à résoudre. En fait, il existe un certain nombre de sous-problèmes ouverts non triviaux, dont chacun doit être résolu afin de réaliser le noble objectif d'affecter intentionnellement et positivement les résultats d'apprentissage.
Mais d'abord, quels sont les résultats d'apprentissage? Et pourquoi nous soucions-nous d'eux ?
Dans le monde hautement compétitif d'aujourd'hui, un étudiant est mesuré dans une large mesure par ce qu'il peut obtenir à un concours ou même en classe. Son score peut avoir un impact significatif sur ses options de carrière. Aux fins de cet article, encadrons les résultats d'apprentissage en fonction du potentiel inné et formable d'un étudiant, pour apprendre, absorber et appliquer le contenu de manière optimale, dans des contraintes de temps strictement spécifiées ; afin qu'elle puisse maximiser son score dans n'importe quel contexte académique compétitif particulier.
Dans les pays en développement comme l'Inde, le ratio élèves-enseignant est très asymétrique et les enseignants ne peuvent pas fournir efficacement une attention personnalisée au niveau individuel. Cela conduit à un dilemme, étant donné que chaque élève apprend et absorbe des informations à des rythmes différents et a différents niveaux d'aptitude. Un effet secondaire connu de l'incapacité des enseignants à fournir une attention personnalisée est que, pour une classe ou un groupe d'élèves donné, le matériel d'apprentissage est toujours présenté pour répondre aux besoins de l'élève « moyen ». Par conséquent, les étudiants très brillants n'atteignent pas leur plein potentiel et ne seront pas en mesure de vraiment déployer leurs muscles académiques, tandis que les étudiants scolairement plus faibles auront du mal à faire face au reste de la classe. Cependant, les plateformes et les systèmes d'apprentissage en ligne existants ne sont pas en mesure de véritablement faciliter l'apprentissage personnalisé au niveau de l'élève.
La plupart des systèmes actuels ne tiennent compte que de la capacité d'un étudiant à faire correspondre ses solutions aux modules de test, comme spécifié par un administrateur du système. L'apprentissage personnalisé pour les concours devrait maximiser le score d'un étudiant pour n'importe quel objectif académique dans le temps limité dont il dispose. L'apprentissage personnalisé devrait également aborder de manière constructive les lacunes de l'élève, non seulement au niveau des connaissances ou des aptitudes, mais également au niveau des attitudes et du comportement. Ce manque d'outils efficaces pour un apprentissage personnalisé, adaptés spécifiquement et précisément à chaque élève, est responsable de son incapacité à réaliser son potentiel en obtenant le score maximum possible à un examen donné.
Dans cet article, l'équipe de science des données d'embibe jettera les bases des divers problèmes interconnectés liés aux données qui doivent être résolus afin de maximiser les résultats d'apprentissage, et plus particulièrement, l'amélioration des scores. Ce problème comporte deux dimensions principales : l'ingestion de contenu et la diffusion de contenu. Chaque dimension pose des défis uniques dans un certain nombre de domaines qui ne manqueront pas de fasciner tout scientifique des données.
Ingestion de contenu
Ingestion automatique de contenu
Des dizaines de tableaux de programme, des milliers de chapitres et de concepts, et des dizaines de milliers d'instituts et d'écoles donnent lieu à des centaines de milliers de questions et réponses générées et utilisées par les instructeurs chaque année. Imaginez si chaque élève pouvait tester ses connaissances avant les examens sur n'importe quel sous-ensemble, ou sur toutes ces questions, tout en obtenant des explications détaillées sur les bonnes réponses et les erreurs courantes commises. Afin d'en faire une réalité, nous tirons parti de la reconnaissance optique de caractères (OCR) et de l'apprentissage automatique pour créer notre propre cadre d'ingestion automatisé qui sera hautement évolutif, véritablement multilingue et peu dépendant de l'intervention humaine. Et le plaisir ne s'arrête pas là. Le cadre pourra également ingérer du contenu manuscrit de manière indépendante de l'auteur, ajoutant ainsi rapidement à notre référentiel déjà fantastique de questions, réponses, concepts, explications et connaissances.
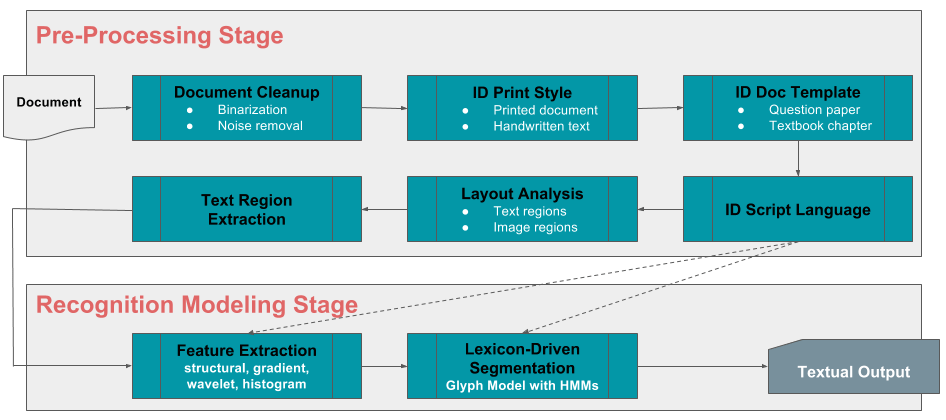
Balisage conceptuel
Très bien, nous avons maintenant des questions, des réponses, des concepts et des chapitres tous ingérés dans un énorme entrepôt de données. Il serait pénible de baliser manuellement chaque question ou chapitre avec ses concepts pertinents, ou vice versa. La science des données à la rescousse ! À l'aide d'idées de pointe issues de la classification de textes, de la modélisation de sujets et de l'apprentissage en profondeur, nous marquons automatiquement les concepts aux questions, réponses et chapitres.

Une sélection des concepts les plus populaires tels que parcourus par les utilisateurs d'Embibe à l'aide de la fonction Apprendre, au cours des mois de décembre 2015, janvier 2016 et février 2016.
Nos bases de données antérieures contenant des ensembles de graines de contenu balisé manuellement de haute qualité sont essentielles pour extraire des fonctionnalités linguistiques, lexicales et contextuelles, pour former des modèles de balisage de texte de pointe pour toutes les nouvelles données qui sont ingérées dans notre systèmes.
Enrichissement des métadonnées
Il existe une mine d'informations disponibles en ligne aujourd'hui sur n'importe quel sujet que l'on souhaite connaître. Les idées et les concepts se construisent les uns sur les autres. Par exemple, la première loi de la thermodynamique est liée au concept de système thermodynamique, qui à son tour est lié aux concepts de capacités thermiques spécifiques des gaz, de conservation de l'énergie mécanique et de travail effectué par un gaz, entre autres. Notre cadre d'ingestion de contenu comprend des composants d'enrichissement de données qui explorent automatiquement le Web et balisent le contenu avec des éléments multimédias aussi divers que des explications textuelles, des liens vidéo, des définitions, des commentaires d'utilisateurs et des discussions de forum, tout en respectant les droits d'auteur et en attribuant correctement la propriété du contenu source. . Cette richesse d'informations disponibles permet également de connecter automatiquement des concepts connexes dans une arborescence. En utilisant des idées issues des domaines de la théorie des graphes, du text mining et de la propagation d'étiquettes sur des structures creuses, nous créons des liens et des interconnexions entre des concepts qui partagent une relation source→cible.
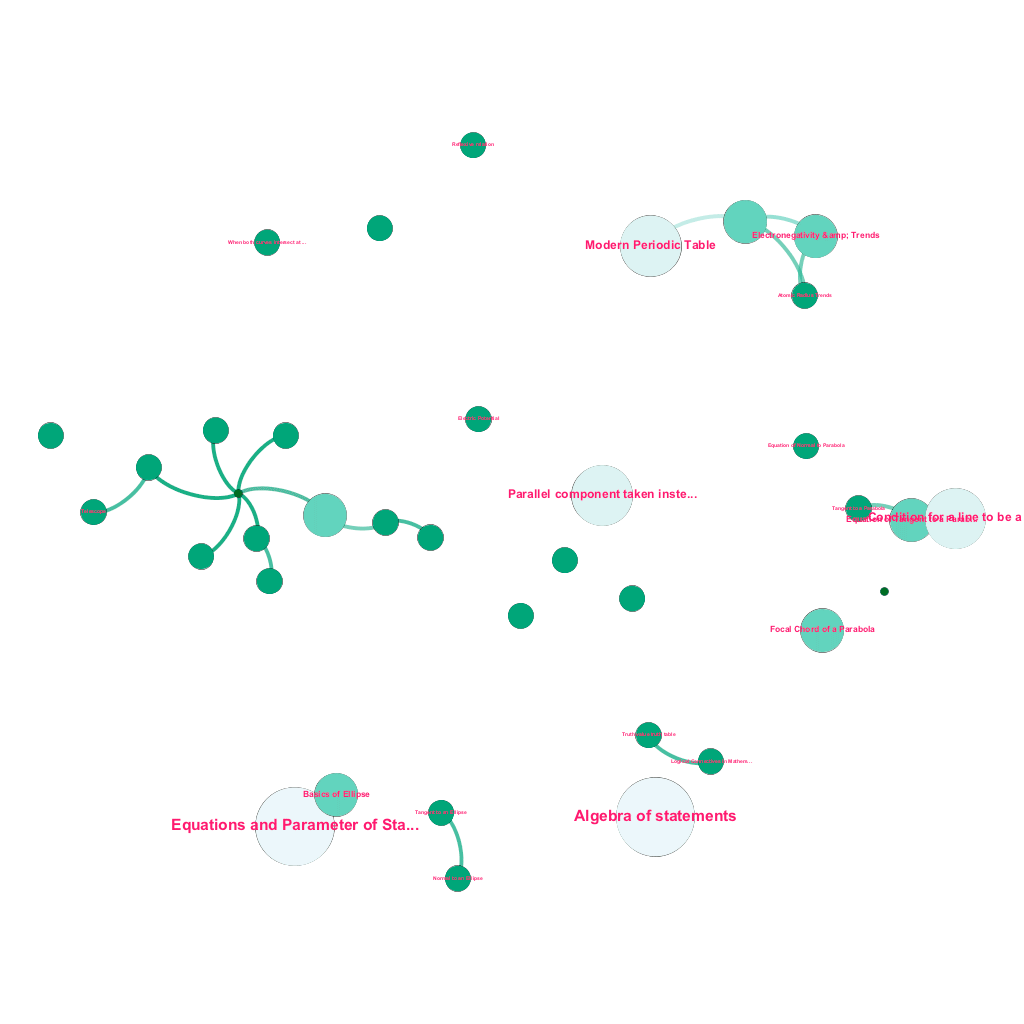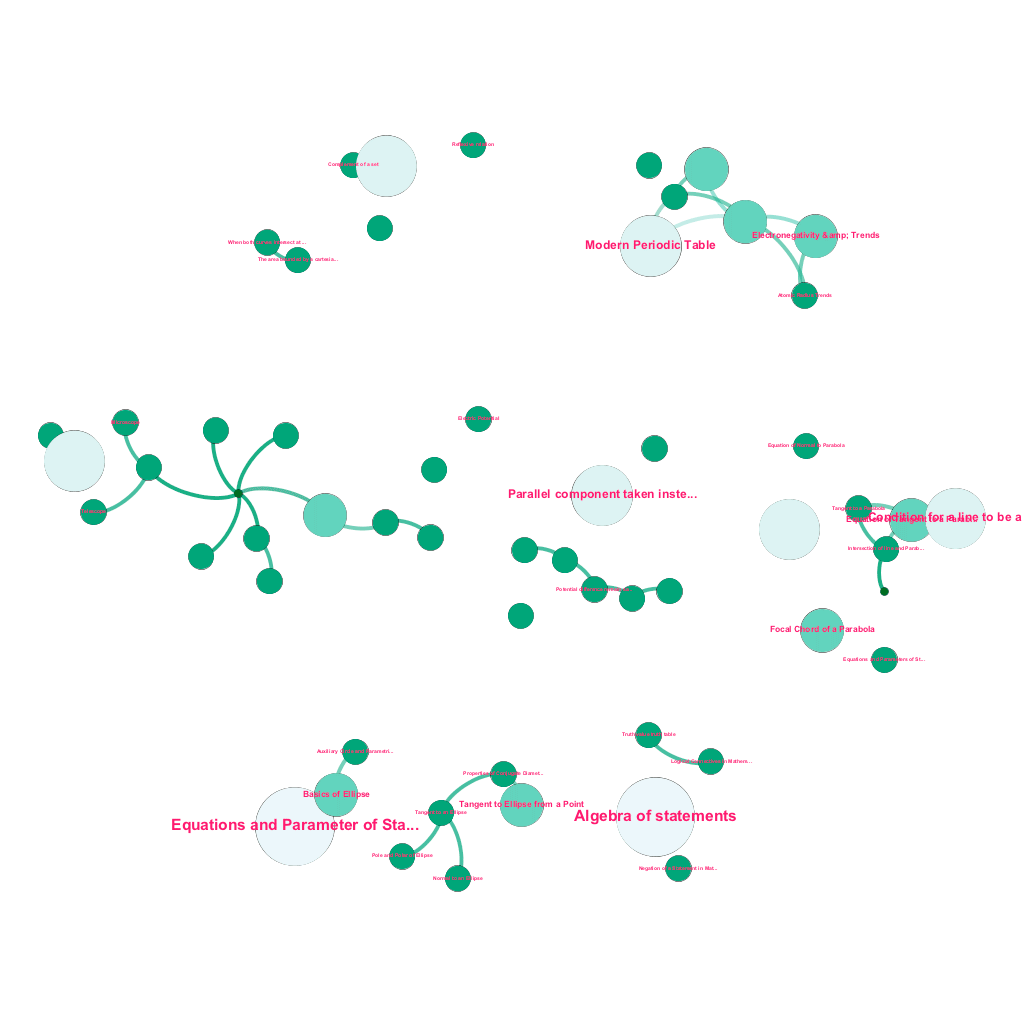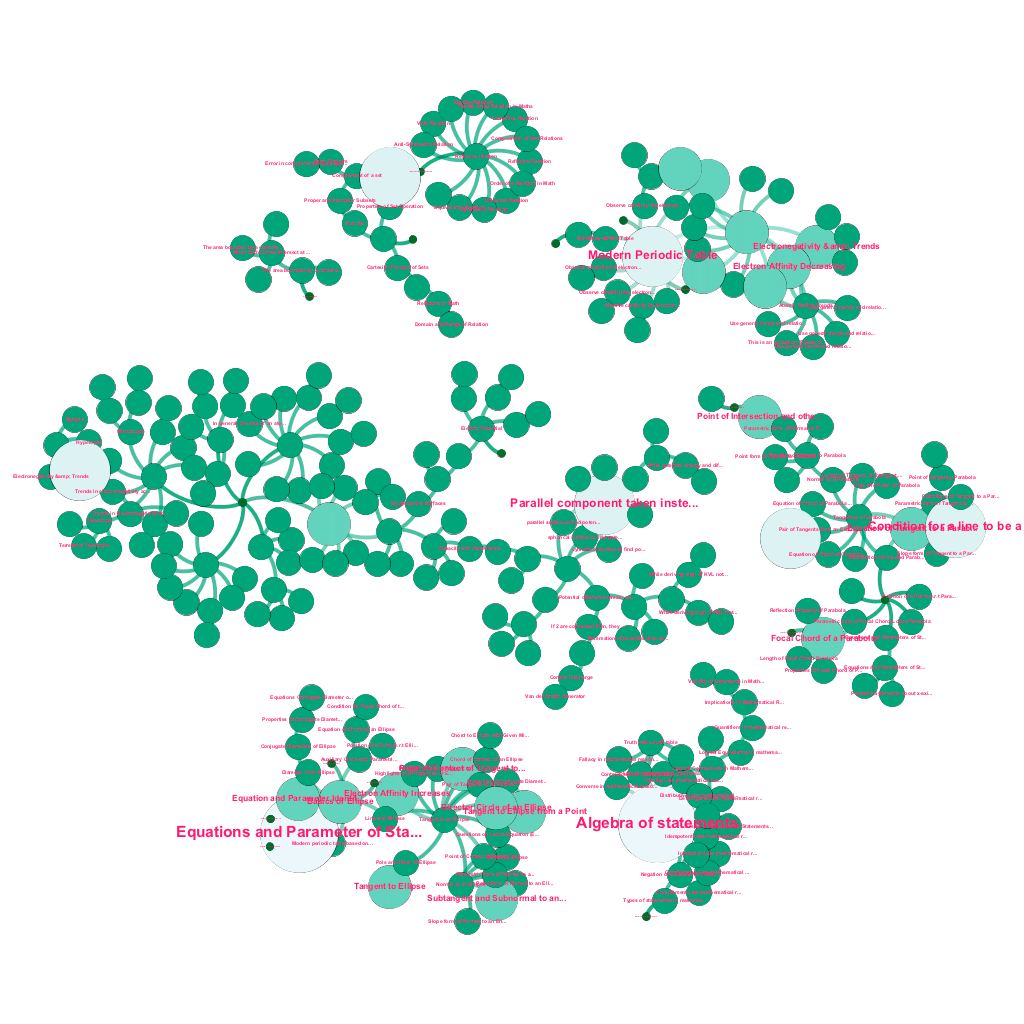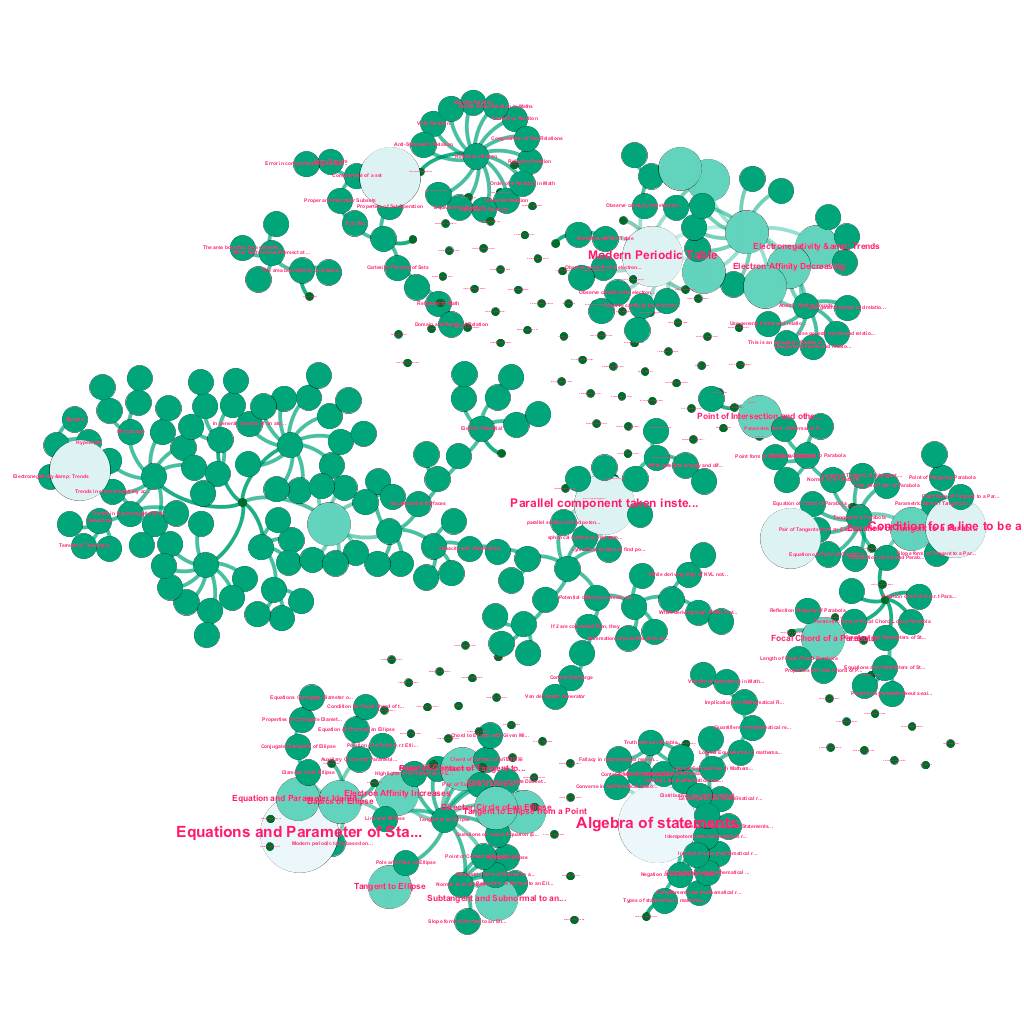
Construction automatisée d'un arbre de concepts, pour un sous-ensemble d'idées de mathématiques, chacune connectée à un ou plusieurs concepts connexes
Regroupement de questions similaires
Si vous vous prépariez à un examen, voudriez-vous répéter la même question encore et encore ? Cela ne serait pas utile. À l'inverse, imaginez à quel point il serait extrêmement utile de pratiquer un petit ensemble de questions pertinentes qui vous aideront à maîtriser complètement un nouveau concept ou un nouveau chapitre. Grâce à notre accès à des centaines de milliers de questions, nous avons développé la capacité de regrouper les questions en fonction de la similarité dans un certain nombre de dimensions - ciblées sur le contenu, testées par le concept, le niveau de difficulté et les objectifs de l'examen, entre autres.
Le regroupement de textes basé sur des espaces d'informations sémantiques latentes et leur combinaison avec d'autres espaces de caractéristiques catégoriques et numériques nous permettent de regrouper précisément notre univers de questions dans des domaines d'intérêt qui peuvent être adaptés à chaque individu utilisant Embibe. De plus, cette riche ressource de données textuelles que nous avons transformées en espaces de caractéristiques numériques robustes liés aux clusters de concepts nous permet de perturber légèrement les données existantes pour générer des expressions potentiellement infinies de l'espace des questions. Plus de questions au moment de l'exécution, du jamais vu auparavant ! Cela nous permet de valoriser au maximum les utilisateurs pour leur temps passé sur notre plateforme.
Livraison de contenu
Profilage des utilisateurs
Nous suivons chaque mouvement qu'un utilisateur fait sur Embibe. Les millions de tentatives de pratique et de test effectuées par nos utilisateurs au cours des trois dernières années sont calibrées dans un espace de données de plusieurs milliers de dimensions. Cela se traduit par un espace de milliards de points de données que nous pouvons exploiter pour approfondir les données comportementales de nos utilisateurs et générer des informations en corrélation avec la façon dont l'apprentissage se produit. Chaque tentative supplémentaire d'un utilisateur modifie sa capacité à obtenir un score plus élevé sur les concepts associés à cette tentative, ainsi que sur les concepts précédents et suivants connectés. Ce problème super complexe implique de tirer parti des idées du traitement des matrices creuses, des algorithmes de calcul dans la théorie des graphes et de la théorie de la réponse aux éléments pour créer des profils d'utilisateurs robustes et adaptatifs qui évoluent avec notre base d'utilisateurs croissante.
Recommandé pour vous:

Que signifie la disposition anti-profit pour les startups indiennes ?

Comment les startups Edtech aident la main-d'œuvre indienne à se perfectionner et à se préparer pour l'avenir...

Stocks technologiques de la nouvelle ère cette semaine : les problèmes de Zomato continuent, EaseMyTrip publie des...

Les startups indiennes prennent des raccourcis à la recherche de financement

La plate-forme de marketing numérique Logicserve met en sac un financement INR 80 Cr et se rebaptise LS Dig ...

Un rapport met en garde contre un examen réglementaire renouvelé sur l'espace Lendingtech
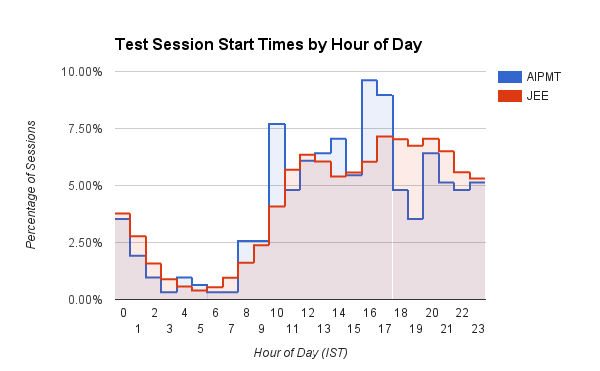
Un graphique à barres intéressant qui montre l'heure (heure de la journée dans IST) à laquelle les utilisateurs commencent leurs sessions de test sur Embibe. Les utilisateurs médicaux (AIPMT) ont un pic défini vers 10h et entre 15h et 17h. Les utilisateurs de l'ingénierie (JEE), d'autre part, affichent des heures de début de session qui augmentent progressivement au fur et à mesure que la journée avance, qui culmine vers 16h00 à 20h00. Les étudiants JEE commencent également systématiquement plus de séances d'entraînement entre 17 heures et 3 heures du matin par rapport aux étudiants AIPMT. Nous supposons que les médecins sont plus disciplinés !

Notre vaste instrumentation et mesure de l'activité des utilisateurs à un niveau très granulaire nous permet de déduire les préférences latentes liées aux styles d'apprentissage associés aux utilisateurs individuels. Par exemple, certains étudiants peuvent mieux apprendre, puis réussir des tests, à l'aide d'explications vidéo, par rapport à d'autres étudiants qui préfèrent des descriptions textuelles détaillées, ou encore à d'autres qui apprennent en travaillant étape par étape à travers des exemples de problèmes résolus. Nous pouvons mapper les utilisateurs sur des modèles théoriques bien étudiés de styles d'apprentissage comme le modèle Dunn et Dunn (Dunn & Dunn 1989) ou le modèle de styles d'esprit de Gregorc (Gregorc 1982) pour adapter automatiquement les cours de rattrapage et aider l'utilisateur à améliorer ses scores.
Regroupement d'utilisateurs
La cohorte est un problème de clustering classique. Les utilisateurs sont regroupés en fonction de leurs modèles d'utilisation en ce qui concerne les fonctionnalités du produit ainsi que de leurs modèles de performance en ce qui concerne les sessions de test, de pratique et de révision. Chaque utilisateur est mappé sur un espace de caractéristiques de grande dimension de plusieurs milliers d'attributs, qui incluent des mesures statiques et temporelles. La cohorte sur des mesures temporelles nous donne la possibilité de démarrer à froid une faible activité et de nouveaux utilisateurs en attribuant des trajectoires de cohorte probables à ces utilisateurs en fonction de leur activité initiale. La cohorte d'utilisateurs est une exigence essentielle pour nos fonctionnalités de science approfondie de haut niveau telles que l'apprentissage micro-adaptatif, la génération automatisée de commentaires et la recommandation de contenu.
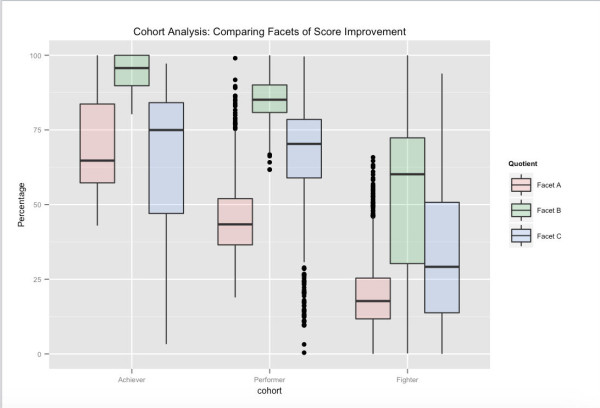
Une vue possible des cohortes d'utilisateurs - liée aux performances des tests à long terme. Sur la base de leurs résultats globaux aux tests, les Performers sont la tranche supérieure du centile des utilisateurs sur Embibe, les Performers la tranche suivante et les Fighters la tranche finale. Les différentes facettes présentées sont liées à différents aspects de l'amélioration du score dans lesquels nous avons regroupé notre espace de fonctionnalités. Par exemple, nous pouvons voir que même si Facet_A varie considérablement d'une cohorte à l'autre, en ciblant les commentaires et en affectant d'autres facettes d'apprentissage, il est possible de pousser les utilisateurs dans la cohorte supérieure suivante.
Apprentissage micro-adaptatif
La livraison de contenu et de commentaires en une bouchée est la clé d'un apprentissage en ligne efficace. Généralement, les utilisateurs passent entre 30 minutes et une heure en ligne, à pratiquer des concepts et des questions. Dans ce court laps de temps, il est très important de maximiser l'impact de chaque session limitée dans le temps. Chaque session est un atout pour l'utilisateur afin de maximiser l'apprentissage, et cela est mieux accompli avec la stratégie de la taille d'une bouchée. Notre moteur micro-adaptatif pour les séances d'entraînement, prend en entrée le profil d'un utilisateur et les attributs de cohorte ainsi que notre arbre de connaissances de 11 000 (et en croissance !) méta-attributs de concepts interconnectés, et garantit que l'ordre des questions, les conseils fournis et juste- La rétroaction en ligne intelligente en temps réel s'adapte précisément à l'utilisateur afin d'améliorer ses résultats d'apprentissage sur n'importe quel objectif de la taille d'une bouchée. Chaque petite consommation de contenu ou de commentaires aura un impact sur l'étalonnage des compétences de l'utilisateur par rapport à notre vaste arbre de connaissances des concepts. Les techniques de traitement des matrices creuses, la théorie de la réponse aux items et les algorithmes de graphes guident la micro-adaptabilité de l'apprentissage.
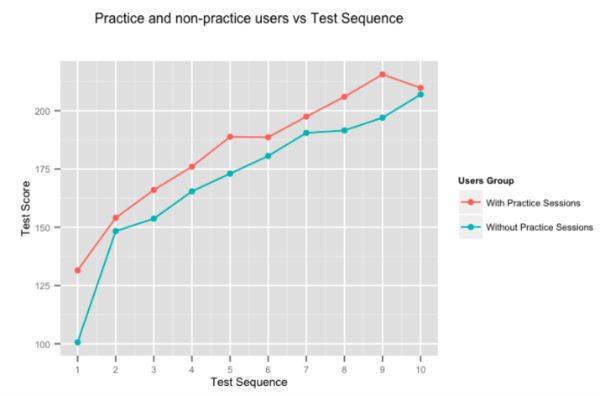
Il est assez évident que la pratique rend parfait, mais nous avons quand même décidé d'utiliser les chiffres. La figure ci-dessus montre l'amélioration moyenne du score des utilisateurs, pour les tests successifs donnés par les utilisateurs qui passent du temps sur nos séances de pratique adaptative, et ceux qui ne le font pas. Les utilisateurs qui pratiquent sur Embibe surpassent systématiquement ceux qui ne le font pas de près de 10% test sur test.
Système de feedback et de recommandation
Le système de commentaires et de recommandations d'Embibe (sur lequel nous avons déjà déposé des brevets) est conçu et construit dans un seul but - maximiser l'amélioration du score d'un utilisateur. Nous instrumentons et interprétons des milliers de signaux sur les tentatives d'un utilisateur pendant les séances d'entraînement et de test, et transformons ces signaux en un espace de grande dimension de milliers de fonctionnalités pour chaque utilisateur. En utilisant l'exploration de modèles statistiques sur notre vaste espace de fonctionnalités de tentatives d'utilisateurs, nous nous sommes concentrés sur les ensembles classés de paramètres qui augmentent positivement le score d'un utilisateur. Ces paramètres sont codés par machine sous la forme de capsules très ciblées et ponctuelles de commentaires sur l'amélioration du score, et transmises à l'utilisateur pendant qu'il poursuit sa séance d'entraînement. Les commentaires et les recommandations exposent les faiblesses et les stratégies qu'elle peut adopter pour maximiser son score.
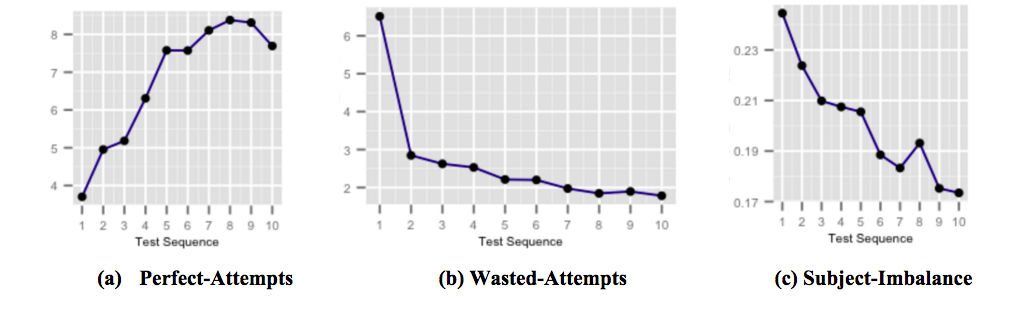
Les chiffres ci-dessus montrent comment nos capsules de rétroaction très ciblées juste à temps pour l'amélioration des scores affectent les performances des élèves lorsque l'utilisateur est exposé et prend conscience des pièges courants des tests. La figure (a) montre le nombre moyen de tentatives parfaites augmentant au fil des tests successifs. Les tentatives parfaites sont des tentatives auxquelles il est répondu correctement dans un délai stipulé. La figure (b) montre le nombre moyen de tentatives infructueuses diminuant au fil des tests successifs. Les tentatives infructueuses sont des tentatives auxquelles on répond de manière incorrecte et où l'élève a eu plus de temps qu'il aurait pu consacrer à la réflexion sur la question. Et la figure (c) montre que le déséquilibre moyen de précision du sujet diminue au fil des tests successifs. Le déséquilibre de précision des sujets est défini comme la différence entre les précisions les plus élevées et les plus faibles parmi tous les sujets de tout test effectué par un utilisateur. Un déséquilibre de précision du sujet plus élevé implique que l'utilisateur est moins préparé pour certains sujets par rapport à d'autres sujets.
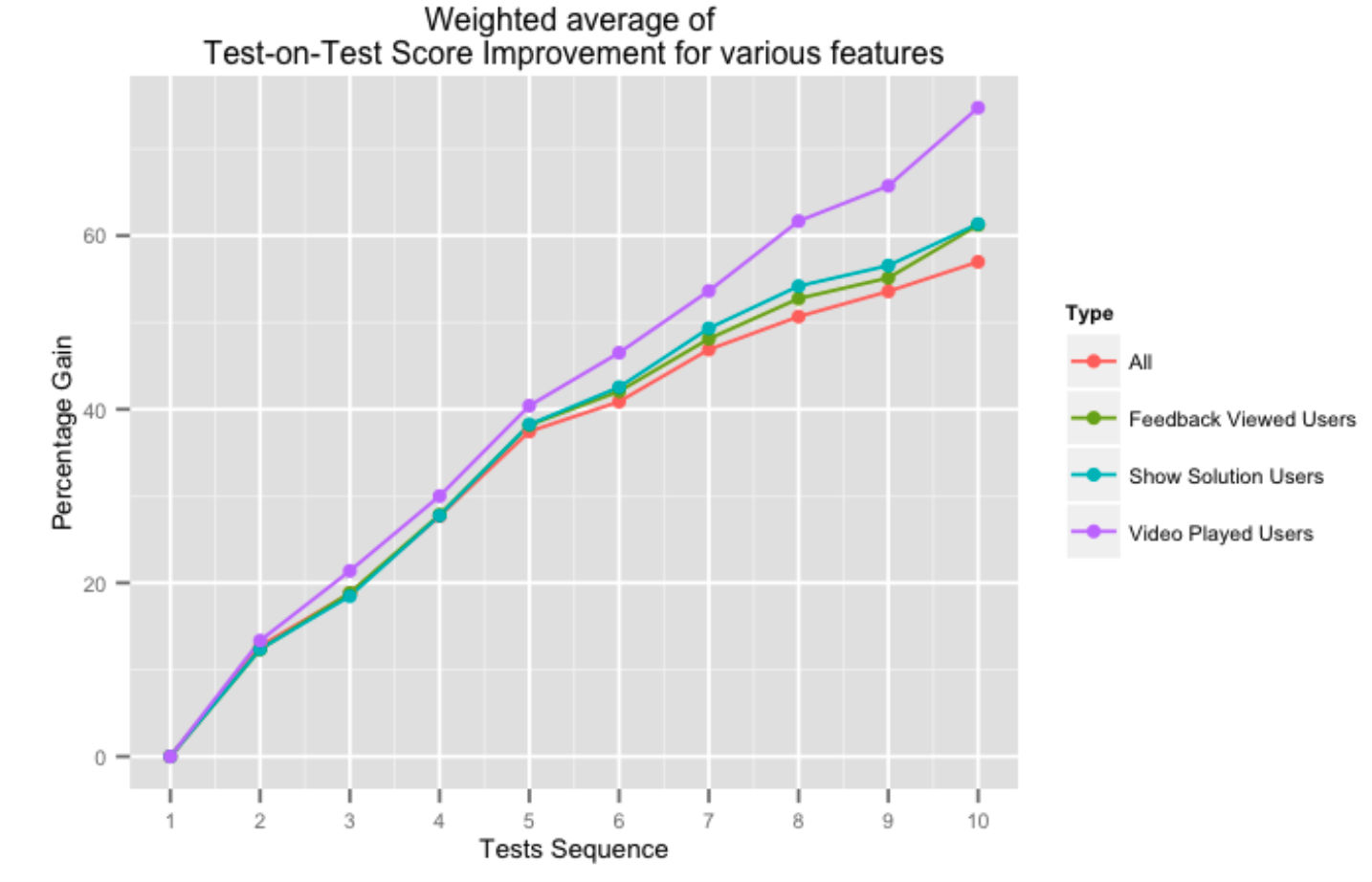
La figure ci-dessus montre le pourcentage de gain dans les scores test sur test successifs pour les utilisateurs qui utilisent divers aspects de notre système de rétroaction. L'aide de notre plate-forme sous la forme de solutions vidéo ou de commentaires généraux sur les tests a un impact positif sur les scores de test sur test, en particulier lorsque l'utilisateur effectue plus de tests.
Estimation de l'amélioration du score
Pour les utilisateurs qui se préparent à des examens de toutes sortes, l'amélioration des scores est l'aspect le plus important pour affecter les résultats d'apprentissage. Notre richesse de données comportementales nous donne la possibilité d'apprendre des actions passées des utilisateurs, en mesurant comment leur comportement pendant et après avoir passé des tests sur Embibe affecte l'amélioration du score. L'exploration de données pour les modèles statistiques d'utilisation, d'activité et de caractéristiques comportementales, parmi diverses cohortes d'utilisateurs, nous donne une preuve scientifique de l'efficacité de notre plateforme.
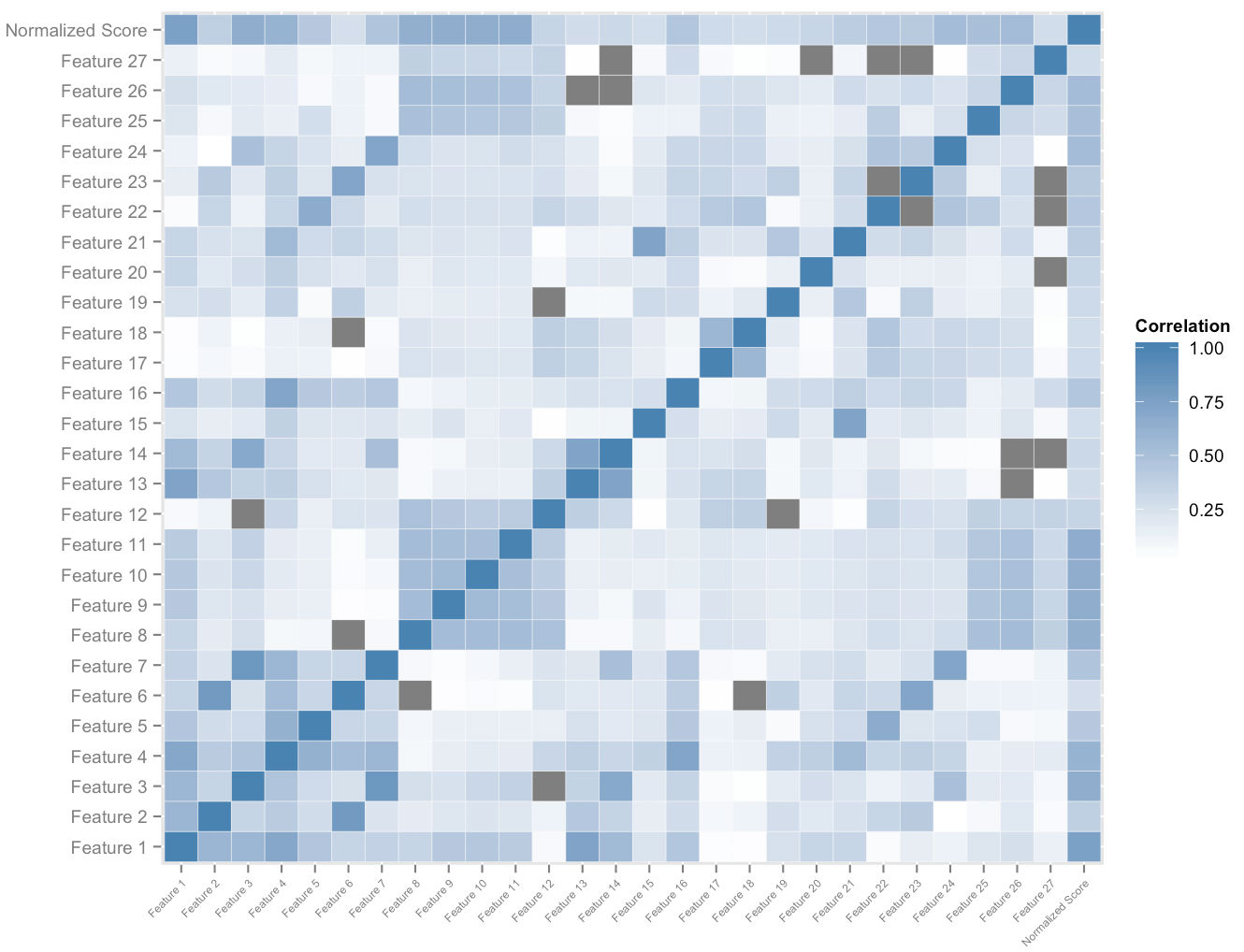
La figure ci-dessus montre un sous-ensemble de l'espace de fonctionnalités que nous construisons par utilisateur. L'analyse de corrélation croisée sur l'espace des caractéristiques et les scores normalisés globaux nous donne un ordre sur l'importance relative des caractéristiques. Ceci, associé à une analyse de dominance empirique, nous permet de mesurer le quantum d'impact de chaque caractéristique sur sa contribution à l'amélioration du score. Une combinaison pondérée de manière appropriée des vitesses de la plus importante de ces caractéristiques nous permet d'attribuer quantitativement une mesure d'amélioration potentielle du score à chaque élève, qui s'adapte à elle lorsqu'elle utilise la plateforme.
Ce sont des moments passionnants pour le domaine de l'éducation, en particulier en Inde et dans d'autres pays en développement. Il est urgent d'appliquer la science approfondie, en mettant fortement l'accent sur l'utilisation des données et les informations qu'elles peuvent fournir, afin de faire passer l'éducation et l'apprentissage au niveau supérieur. Nos plates-formes d'ingestion et de diffusion de contenu sont construites sur des principes scientifiques solides et aident les utilisateurs à réaliser une valeur immense sur Embibe sous la forme d'une amélioration des scores dans des délais de préparation limités. Notre cadre d'apprentissage micro-adaptatif qui utilise des commentaires et des recommandations spécifiques à l'utilisateur, adaptés précisément aux utilisateurs, en fonction de leurs classifications de cohorte ainsi que des caractéristiques comportementales, permet aux utilisateurs d'avoir une expérience enrichissante sur Embibe. Ce sont les premières étapes concrètes vers la résolution du problème de l'impact positif sur les résultats d'apprentissage. C'est un apprentissage personnalisé.
Dans cet article, nous avons abordé divers sous-problèmes qui doivent être résolus pour nous faire progresser sur la voie de l'impact sur les résultats d'apprentissage. Dans notre prochain article, nous parlerons de la façon dont nous mesurons et suivons diverses mesures chez Embibe qui sont liées à nos utilisateurs et à leur activité, afin que nous puissions garder un œil sur le pouls de notre produit, sa croissance et son efficacité en tant que une destination d'apprentissage en ligne.
Nous sommes toujours à la recherche de gens malins et intelligents à ajouter à nos rangs au Data Science Lab. Si vous aimez tester des hypothèses, exécuter des régressions, factoriser des matrices gigantesques, rire au nez des mégadonnées, lancer des tâches de réduction de carte, créer des modèles de sujet sur du texte désordonné et non structuré, extraire des données bruyantes pour des modèles statistiques, ingérer des montagnes de données à partir de données ouvertes sources, discuter des valeurs p, former des réseaux de neurones et des réseaux de croyances profondes, basculer entre python et R, faire tourner des visualisations et des shells de script, vous allez adorer ici !
Envoyez-nous un message avec votre CV à jobs.<id>@embibe.com, où :
<id> est le nombre formé avec les 8 premiers chiffres non nuls de la valeur de la fonction de densité de probabilité pour la distribution normale, arrondi à 19 chiffres de précision, et
mu est le 26e nombre de la séquence padouane, et
sigma est le 17e nombre de la séquence de Fibonacci commençant à 1, et
x est le 1002ème nombre premier
Notre équipe est composée de Keyur Faldu ( Chief Data Scientist), Achint Thomas ( Principal Data Scientist) et Chintan Donda (Data Scientist).
Références
- Inventaire des styles d'apprentissage . Lawrence, KS : Systèmes de prix.
- Gregorc AF, (1982). Modèle de styles d'esprit : théorie, principes et applications. Maynard, MA : Systèmes Gabriel.
Embibe a récemment terminé 3 ans sur le marché en tant que l'une des principales entreprises d'analyse de données sur l'éducation. Les étudiants ont passé plus de 100 000 heures sur le produit rien qu'en mars 2016, sans aucun investissement dans le marketing payant.