
นักเรียน 300 ล้านคน ข้อมูลเชิงลึก 300 พันล้าน – รักข้อมูลในการศึกษา
เผยแพร่แล้ว: 2016-04-07เจาะลึกข้อมูลภายในห้องปฏิบัติการวิทยาศาสตร์ข้อมูลของ Embibe
[นี่เป็นส่วนที่สองของซีรีส์ How We Are Use Deep Tech และ Data Science เพื่อปรับแต่งการศึกษา]
เราสร้าง Embibe ด้วยวิสัยทัศน์เดียว: เพื่อเพิ่มผลลัพธ์การเรียนรู้ตามขนาด การสร้างผลกระทบเชิงบวกต่อผลการเรียนรู้ของผู้ใช้เป็นปัญหาที่ยากแต่สำคัญที่ต้องแก้ไข ในความเป็นจริง มีปัญหาย่อยเปิดที่ไม่สำคัญจำนวนหนึ่ง ซึ่งแต่ละปัญหาต้องได้รับการแก้ไขเพื่อให้บรรลุเป้าหมายที่สูงส่งของการตั้งใจและส่งผลในเชิงบวกต่อผลลัพธ์การเรียนรู้
แต่ก่อนอื่น ผลลัพธ์การเรียนรู้คืออะไร? และทำไมเราถึงสนใจพวกเขา?
ในโลกที่มีการแข่งขันสูงในปัจจุบัน นักเรียนถูกวัดในระดับมากด้วยคะแนนที่เธอสามารถทำได้ในการสอบแข่งขันหรือแม้แต่ในห้องเรียนของโรงเรียน คะแนนของเธออาจมีผลกระทบอย่างมากต่อทางเลือกในอาชีพของเธอ สำหรับวัตถุประสงค์ของบทความนี้ ให้เรากำหนดกรอบผลการเรียนรู้ในฐานะหน้าที่ของศักยภาพโดยกำเนิดของนักเรียนและศักยภาพในการฝึกอบรม เพื่อเรียนรู้ ซึมซับ และนำเนื้อหาไปใช้อย่างเหมาะสมที่สุดภายในเวลาจำกัดที่กำหนดอย่างเคร่งครัด เพื่อให้เธอได้คะแนนสูงสุดในบริบททางวิชาการที่มีการแข่งขันสูง
ในประเทศกำลังพัฒนา เช่น อินเดีย อัตราส่วนนักเรียนต่อครูมีความเบ้สูง และครูไม่สามารถให้ความสนใจเป็นรายบุคคลในระดับบุคคลได้อย่างมีประสิทธิภาพ สิ่งนี้นำไปสู่ภาวะที่กลืนไม่เข้าคายไม่ออกเนื่องจากนักเรียนแต่ละคนเรียนรู้และดูดซับข้อมูลในอัตราที่แตกต่างกันและมีระดับความถนัดที่แตกต่างกัน ผลข้างเคียงที่ทราบกันดีของการที่ครูไม่สามารถให้ความสนใจเป็นรายบุคคลคือสำหรับห้องเรียน/กลุ่มนักเรียนใดก็ตาม สื่อการเรียนรู้จะถูกนำเสนอเสมอเพื่อรองรับนักเรียน "โดยเฉลี่ย" ดังนั้นนักเรียนที่เก่งมากจะไม่บรรลุศักยภาพสูงสุดและจะไม่สามารถงอกล้ามเนื้อทางวิชาการได้อย่างแท้จริง ในขณะที่นักเรียนที่อ่อนแอกว่าจะมีปัญหาในการรับมือกับชั้นเรียนที่เหลือ อย่างไรก็ตาม แพลตฟอร์มและระบบการเรียนรู้ออนไลน์ที่มีอยู่ไม่สามารถอำนวยความสะดวกในการเรียนรู้ส่วนบุคคลในระดับนักเรียนได้อย่างแท้จริง
ระบบปัจจุบันส่วนใหญ่จะพิจารณาเฉพาะว่านักเรียนสามารถจับคู่โซลูชันของตนเพื่อทดสอบโมดูลได้ดีเพียงใดตามที่ผู้ดูแลระบบบางคนกำหนด การเรียนรู้ส่วนบุคคลสำหรับการสอบแข่งขันควรเพิ่มคะแนนของนักเรียนให้สูงสุดสำหรับเป้าหมายทางวิชาการใดๆ ในเวลาที่จำกัดสำหรับเธอ การเรียนรู้เฉพาะบุคคลควรแก้ไขช่องว่างความสามารถของนักเรียนอย่างสร้างสรรค์ ไม่เพียงแต่ในระดับความรู้หรือความถนัดเท่านั้น แต่ยังรวมถึงระดับทัศนคติและพฤติกรรมด้วย การขาดเครื่องมือที่มีประสิทธิภาพสำหรับการเรียนรู้ส่วนบุคคล ซึ่งปรับแต่งมาโดยเฉพาะและแม่นยำสำหรับนักเรียนแต่ละคน ทำให้เธอไม่สามารถตระหนักถึงศักยภาพของเธอในการบรรลุคะแนนสูงสุดที่เป็นไปได้ในการสอบที่กำหนด
ในบทความนี้ ทีมวิทยาศาสตร์ข้อมูลของ Embibe จะวางรากฐานของปัญหาต่างๆ ที่เกี่ยวข้องกับข้อมูลที่เชื่อมโยงถึงกัน ซึ่งจำเป็นต้องได้รับการแก้ไขเพื่อเพิ่มผลลัพธ์การเรียนรู้ให้สูงสุด และโดยเฉพาะอย่างยิ่ง การปรับปรุงคะแนน ปัญหานี้มีสองมิติหลัก – การนำเข้าเนื้อหาและการจัดส่งเนื้อหา แต่ละมิติก่อให้เกิดความท้าทายที่แตกต่างกันไปในหลายด้าน ซึ่งจะทำให้นักวิทยาศาสตร์ด้านข้อมูลต้องทึ่งอย่างแน่นอน
การนำเข้าเนื้อหา
การนำเข้าเนื้อหาโดยอัตโนมัติ
กระดานหลักสูตรนับสิบ บทและแนวคิดนับพัน สถาบันและโรงเรียนหลายหมื่นแห่ง ส่งผลให้เกิดคำถามและคำตอบหลายแสนรายการที่สร้างและใช้งานโดยอาจารย์ผู้สอนทุกปี ลองนึกภาพว่านักเรียนทุกคนสามารถทดสอบความรู้ของตนก่อนสอบในชุดย่อยใดๆ หรือคำถามเหล่านี้ทั้งหมด พร้อมกับรับคำอธิบายโดยละเอียดเกี่ยวกับคำตอบที่ถูกต้อง และข้อผิดพลาดทั่วไปที่เกิดขึ้น ในการทำให้สิ่งนี้เป็นจริง เรากำลังใช้ประโยชน์จากการรู้จำอักขระด้วยแสง (OCR) และการเรียนรู้ของเครื่องเพื่อสร้างเฟรมเวิร์กการนำเข้าอัตโนมัติของเราเองที่จะสามารถปรับขนาดได้สูง พูดได้หลายภาษาอย่างแท้จริง และขึ้นอยู่กับอินพุตของมนุษย์น้อยที่สุด และความสนุกไม่ได้หยุดเพียงแค่นั้น เฟรมเวิร์กนี้ยังสามารถนำเข้าเนื้อหาที่เขียนด้วยลายมือในลักษณะที่ผู้เขียนไม่เชื่อเรื่องพระเจ้า จึงเป็นการเพิ่มคลังคำถาม คำตอบ แนวคิด คำอธิบาย และความรู้ที่ยอดเยี่ยมอยู่แล้วอย่างรวดเร็ว
การติดแท็กแนวคิด
เอาล่ะ ตอนนี้เรามีคำถาม คำตอบ แนวคิด และบทต่างๆ ที่รวมเข้าไปในคลังข้อมูลขนาดใหญ่ การติดแท็กคำถามหรือบทแต่ละบทด้วยตนเองด้วยแนวคิดที่เกี่ยวข้องอาจเป็นเรื่องที่เจ็บปวด หรือในทางกลับกัน Data Science ช่วยชีวิต! การใช้แนวคิดที่ล้ำสมัยตั้งแต่การจัดประเภทข้อความ การสร้างแบบจำลองหัวข้อ และการเรียนรู้เชิงลึก เราแท็กแนวคิดไปที่คำถาม คำตอบ และบทต่างๆ โดยอัตโนมัติ

การเลือกแนวคิดยอดนิยมที่ผู้ใช้ Embibe เรียกดูโดยใช้คุณลักษณะ Learn ในเดือนธันวาคม 2015 มกราคม 2016 และกุมภาพันธ์ 2016
ฐานข้อมูลก่อนหน้าของเราที่มีชุดเนื้อหาที่ติดแท็กด้วยตนเองคุณภาพสูงนั้นมีประโยชน์เมื่อเราแยกคุณลักษณะทางภาษา ศัพท์ และบริบทที่ละเอียดอ่อน เพื่อฝึกโมเดลการติดแท็กข้อความที่ทันสมัยสำหรับข้อมูลใหม่ทั้งหมดที่เรานำเข้ามา ระบบต่างๆ
การปรับปรุงข้อมูลเมตา
มีข้อมูลออนไลน์มากมายในปัจจุบันในหัวข้อใด ๆ ที่คุณต้องการเรียนรู้ แนวคิดและแนวคิดสร้างต่อกัน ตัวอย่างเช่น กฎข้อที่หนึ่งของอุณหพลศาสตร์เกี่ยวข้องกับแนวคิดของระบบอุณหพลศาสตร์ ซึ่งในทางกลับกันก็เกี่ยวข้องกับแนวคิดเกี่ยวกับความจุความร้อนจำเพาะของก๊าซ การอนุรักษ์พลังงานกล และงานที่ทำโดยก๊าซ เป็นต้น กรอบงานการนำเข้าเนื้อหาของเราประกอบด้วยองค์ประกอบการตกแต่งข้อมูลที่รวบรวมข้อมูลเว็บโดยอัตโนมัติและติดแท็กเนื้อหาด้วยสื่อที่หลากหลาย เช่น คำอธิบายข้อความ ลิงก์วิดีโอ คำจำกัดความ การแสดงความคิดเห็นของผู้ใช้ และการอภิปรายในฟอรัม โดยทั้งหมดต้องเคารพลิขสิทธิ์ และแสดงความเป็นเจ้าของในเนื้อหาที่มาจากแหล่งที่มาอย่างเหมาะสม . ข้อมูลที่มีอยู่มากมายนี้ยังทำให้สามารถเชื่อมต่อแนวคิดที่เกี่ยวข้องในโครงสร้างแบบต้นไม้ได้โดยอัตโนมัติ การใช้แนวคิดจากสาขาของทฤษฎีกราฟ การทำเหมืองข้อความ และการเผยแพร่ป้ายกำกับบนโครงสร้างแบบเบาบาง เราสร้างลิงก์และการเชื่อมต่อระหว่างแนวคิดที่มีความสัมพันธ์แบบต้นทาง→เป้าหมายร่วมกัน
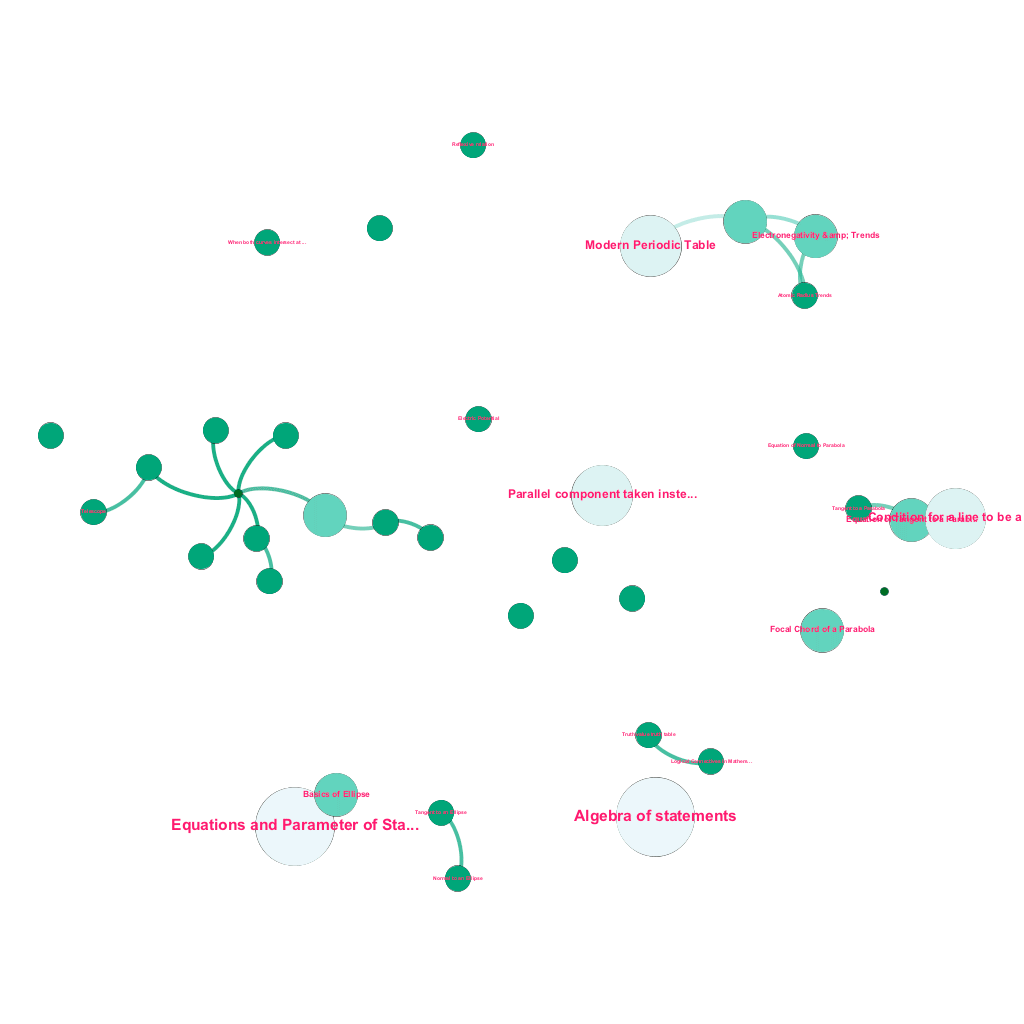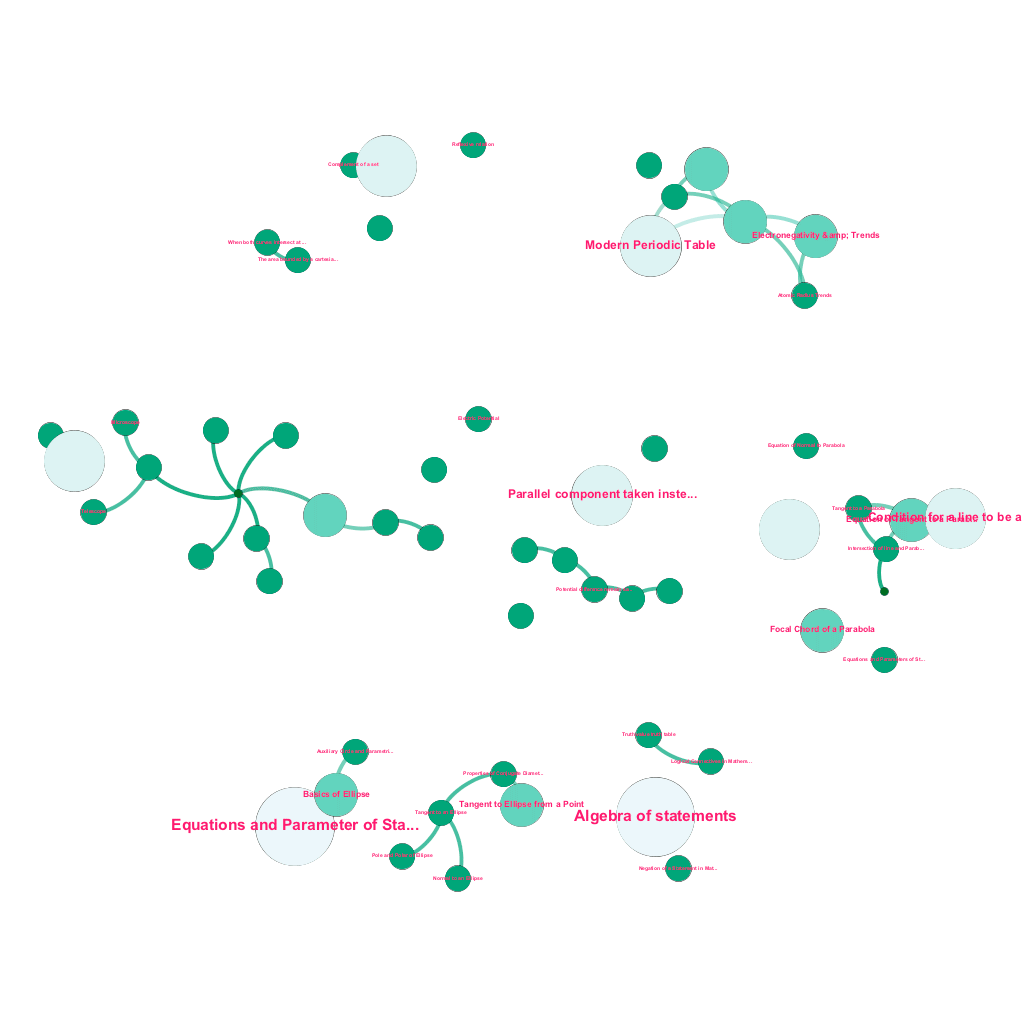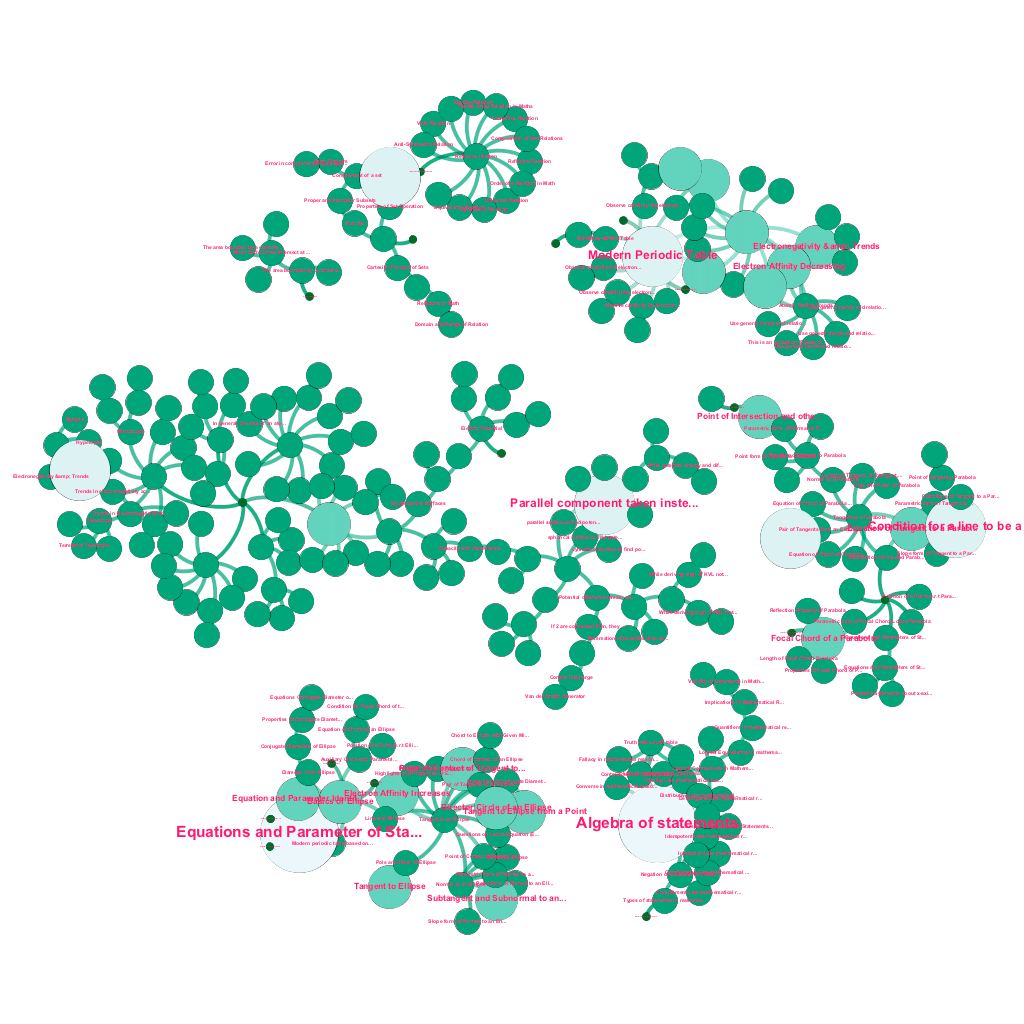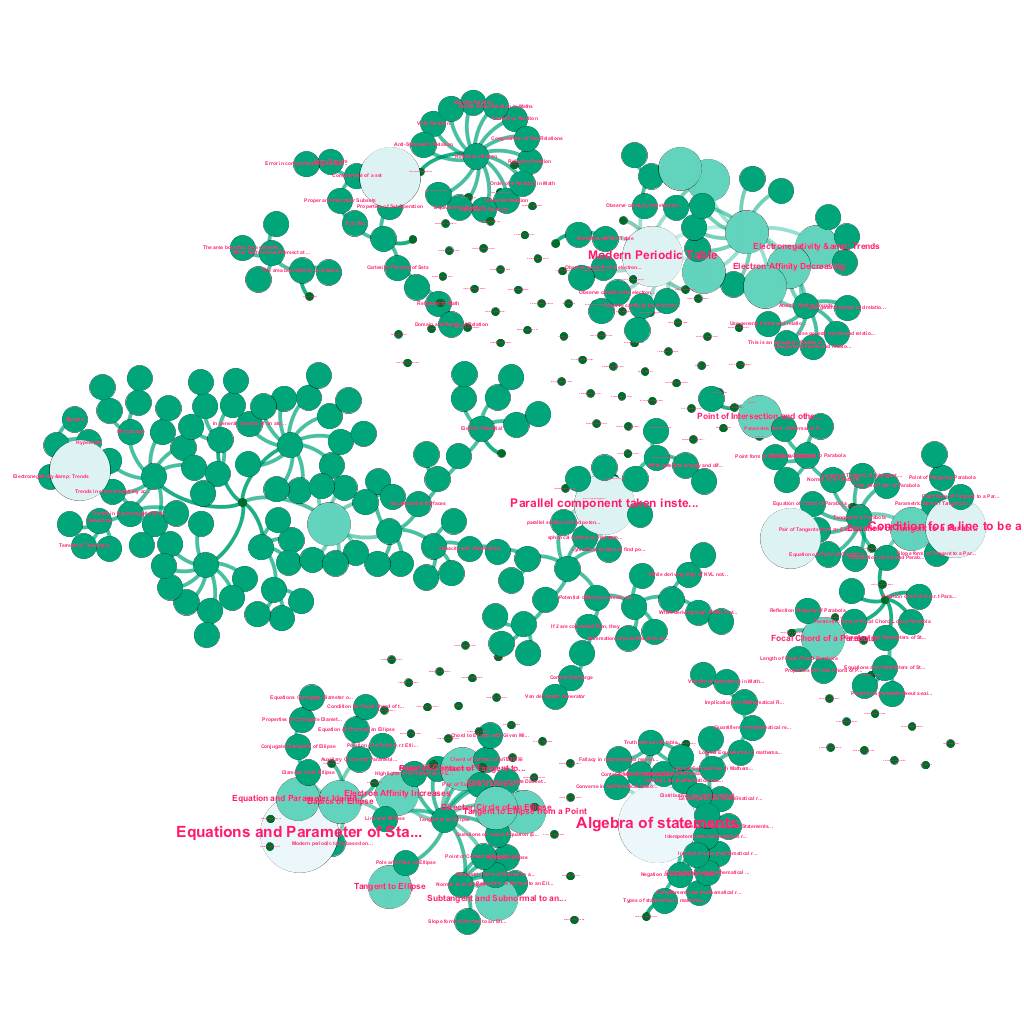
การสร้างแบบอัตโนมัติของแผนผังแนวคิด สำหรับชุดย่อยของแนวคิดจากคณิตศาสตร์ โดยแต่ละแนวคิดจะเชื่อมโยงกับแนวคิดที่เกี่ยวข้องตั้งแต่หนึ่งแนวคิดขึ้นไป
การจัดกลุ่มคำถามที่คล้ายกัน
หากคุณกำลังเตรียมสอบ คุณต้องการที่จะฝึกคำถามเดิมซ้ำแล้วซ้ำอีกหรือไม่? นั่นจะไม่เป็นประโยชน์ ในทางกลับกัน ลองนึกภาพว่ามีประโยชน์อย่างมากเพียงใดในการฝึกฝนคำถามที่เกี่ยวข้องชุดเล็ก ๆ ซึ่งจะช่วยให้คุณเชี่ยวชาญแนวคิดหรือบทใหม่ ๆ ได้อย่างสมบูรณ์ ด้วยการเข้าถึงคำถามนับแสนคำถาม เราได้พัฒนาความสามารถในการจัดกลุ่มคำถามตามความคล้ายคลึงกันในหลายมิติ – กำหนดเป้าหมายเนื้อหา ทดสอบแนวคิด ระดับความยาก และเป้าหมายการสอบ และอื่นๆ
การจัดกลุ่มข้อความตามพื้นที่ข้อมูลความหมายแฝง และการรวมกันกับช่องว่างด้านหมวดหมู่และตัวเลขช่วยให้เราจัดกลุ่มคำถามในจักรวาลของเราได้อย่างแม่นยำในพื้นที่ที่น่าสนใจซึ่งสามารถปรับแต่งให้เหมาะกับแต่ละบุคคลโดยใช้ Embibe นอกจากนี้ แหล่งข้อมูลที่เป็นข้อความจำนวนมากซึ่งเราได้แปลงเป็นพื้นที่คุณลักษณะตัวเลขที่มีประสิทธิภาพซึ่งเกี่ยวข้องกับคลัสเตอร์แนวคิด ทำให้เรารบกวนข้อมูลที่มีอยู่เล็กน้อยเพื่อสร้างนิพจน์ที่อาจไม่มีที่สิ้นสุดของพื้นที่คำถาม คำถามเพิ่มเติมในเวลาทำงาน ไม่เคยเห็นมาก่อน! ซึ่งช่วยให้เรามอบคุณค่าสูงสุดแก่ผู้ใช้สำหรับเวลาที่ใช้บนแพลตฟอร์มของเรา
การจัดส่งเนื้อหา
โปรไฟล์ผู้ใช้
เราติดตามทุกการเคลื่อนไหวที่ผู้ใช้ทำบน Embibe ความพยายามฝึกฝนและทดสอบนับล้านครั้งโดยผู้ใช้ของเราในช่วงสามปีที่ผ่านมาได้รับการปรับเทียบในพื้นที่ข้อมูลหลายพันมิติ ซึ่งแปลเป็นพื้นที่จุดข้อมูลหลายพันล้านจุดที่เราขุดได้เพื่อเจาะลึกข้อมูลพฤติกรรมของผู้ใช้ และสร้างข้อมูลเชิงลึกที่สัมพันธ์กับการเรียนรู้ที่เกิดขึ้น ความพยายามเพิ่มเติมแต่ละครั้งโดยผู้ใช้ ปรับแต่งความสามารถของเธอในการทำคะแนนให้สูงขึ้นในแนวคิดที่ติดแท็กความพยายามนั้น ควบคู่ไปกับแนวคิดก่อนหน้าและที่ประสบความสำเร็จที่เชื่อมโยงกัน ปัญหาที่ซับซ้อนมากนี้เกี่ยวข้องกับการใช้ประโยชน์จากแนวคิดจากการประมวลผลเมทริกซ์แบบกระจาย อัลกอริธึมการคำนวณในทฤษฎีกราฟ และทฤษฎีการตอบสนองรายการเพื่อสร้างโปรไฟล์ผู้ใช้ที่แข็งแกร่งและปรับเปลี่ยนได้ซึ่งปรับขนาดตามฐานผู้ใช้ที่กำลังเติบโตของเรา
แนะนำสำหรับคุณ:

บทบัญญัติต่อต้านการแสวงหากำไรสำหรับสตาร์ทอัพในอินเดียมีความหมายอย่างไร?

Edtech Startups ช่วยให้แรงงานอินเดียเพิ่มพูนทักษะและเตรียมพร้อมสู่อนาคตได้อย่างไร...

หุ้นเทคโนโลยียุคใหม่ในสัปดาห์นี้: ปัญหาของ Zomato ยังคงดำเนินต่อไป, EaseMyTrip Posts Stro...

สตาร์ทอัพอินเดียใช้ทางลัดในการไล่ล่าหาทุน

แพลตฟอร์มการตลาดดิจิทัล Logicserve ระดมทุน INR 80 Cr รีแบรนด์เป็น LS Dig...

รายงานเตือนให้มีการพิจารณาทบทวนกฎข้อบังคับเกี่ยวกับ Lendingtech Space
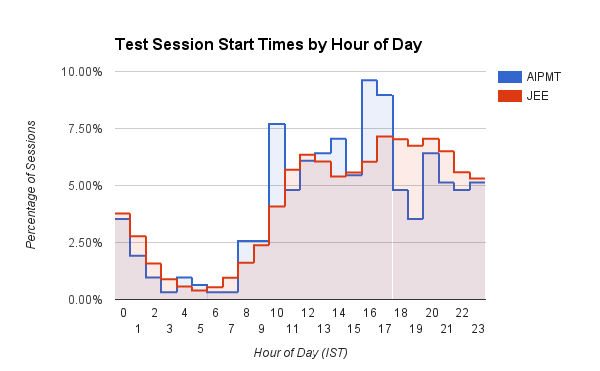
กราฟแท่งที่น่าสนใจซึ่งแสดงเวลา (ชั่วโมงของวันใน IST) ที่ผู้ใช้เริ่มเซสชันการทดสอบบน Embibe ผู้ใช้ทางการแพทย์ (AIPMT) มีการเพิ่มขึ้นอย่างรวดเร็วในช่วงเวลาประมาณ 10.00 น. และระหว่าง 15.00 น. ถึง 17.00 น. ในทางกลับกัน ผู้ใช้วิศวกรรม (JEE) จะแสดงเวลาเริ่มต้นเซสชันที่เพิ่มขึ้นเรื่อยๆ ตามวันที่ดำเนินไป ซึ่งสูงสุดประมาณ 16:00 น. ถึง 20:00 น. นักเรียน JEE ยังเริ่มการฝึกซ้อมอย่างต่อเนื่องระหว่างเวลา 17.00 น. ถึง 03.00 น. เมื่อเทียบกับนักเรียน AIPMT เราเดาว่าหมอมีวินัยมากกว่า!

เครื่องมือและการวัดผลกิจกรรมของผู้ใช้ที่ครอบคลุมของเราในระดับที่ละเอียดมากช่วยให้เราสามารถอนุมานการตั้งค่าที่แฝงซึ่งเกี่ยวข้องกับรูปแบบการเรียนรู้ที่เกี่ยวข้องกับผู้ใช้แต่ละราย ตัวอย่างเช่น นักเรียนบางคนอาจเรียนรู้และหลังจากนั้นทำแบบทดสอบได้ดีกว่าโดยใช้คำอธิบายวิดีโอ เมื่อเทียบกับนักเรียนคนอื่นๆ ที่ชอบคำอธิบายที่เป็นข้อความที่กว้างขวาง หรือแม้แต่คนอื่นๆ ที่เรียนรู้โดยการทำงานทีละขั้นตอนผ่านปัญหาตัวอย่างที่แก้ไขแล้ว เราสามารถจับคู่ผู้ใช้กับแบบจำลองทางทฤษฎีของรูปแบบการเรียนรู้ที่ศึกษาอย่างดี เช่น Dunn and Dunn Model (Dunn & Dunn 1989) หรือ Mind Styles Model ของ Gregorc (Gregorc 1982) เพื่อปรับแต่งหลักสูตรการปฏิบัติการแก้ไขโดยอัตโนมัติและช่วยให้ผู้ใช้มีการปรับปรุงคะแนน
กลุ่มผู้ใช้
Cohorting เป็นปัญหาการจัดกลุ่มแบบคลาสสิก ผู้ใช้จะถูกจัดกลุ่มตามรูปแบบการใช้งานที่เกี่ยวกับคุณลักษณะของผลิตภัณฑ์ ตลอดจนรูปแบบประสิทธิภาพที่เกี่ยวข้องกับการทดสอบ การปฏิบัติ และช่วงการแก้ไข ผู้ใช้แต่ละรายถูกแมปไปยังพื้นที่คุณลักษณะที่มีมิติสูงของแอตทริบิวต์หลายพันรายการ ซึ่งรวมถึงการวัดแบบคงที่และแบบชั่วคราว การจัดกลุ่มตามมาตรการชั่วคราวช่วยให้เราสามารถเริ่มกิจกรรมที่ต่ำและผู้ใช้ใหม่โดยกำหนดเส้นทางโควตที่น่าจะเป็นให้กับผู้ใช้เหล่านี้ตามกิจกรรมเริ่มต้นของพวกเขา การจัดกลุ่มผู้ใช้เป็นข้อกำหนดหลักสำหรับคุณลักษณะทางวิทยาศาสตร์เชิงลึกระดับสูงของเรา เช่น การเรียนรู้แบบไมโครที่ปรับเปลี่ยนได้ การสร้างคำติชมอัตโนมัติ และการแนะนำเนื้อหา
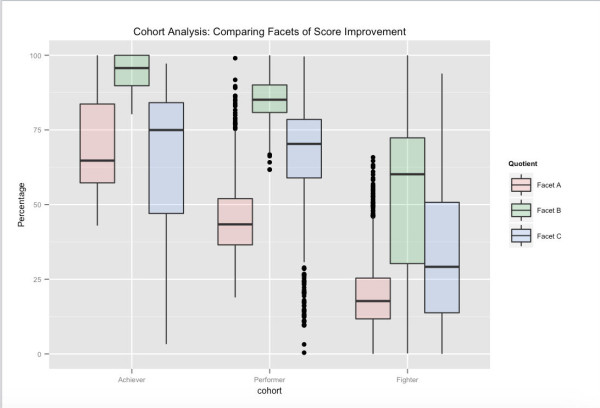
มุมมองที่เป็นไปได้ของกลุ่มผู้ใช้ – เชื่อมโยงกับประสิทธิภาพการทดสอบในระยะยาว จากคะแนนการทดสอบโดยรวมของพวกเขา Achievers คือกลุ่มเปอร์เซ็นไทล์บนสุดของผู้ใช้ใน Embibe, นักแสดงในสายถัดไป และนักสู้ในสายสุดท้าย แง่มุมต่างๆ ที่แสดง เกี่ยวข้องกับแง่มุมต่างๆ ของการปรับปรุงคะแนนที่เราได้จัดกลุ่มพื้นที่คุณลักษณะไว้ ตัวอย่างเช่น เราเห็นได้ว่าแม้ว่า Facet_A จะแตกต่างกันอย่างมากในกลุ่มประชากรตามรุ่น การกำหนดเป้าหมายความคิดเห็นและส่งผลกระทบต่อแง่มุมการเรียนรู้อื่นๆ มีความเป็นไปได้ที่จะผลักดันผู้ใช้เข้าสู่กลุ่มประชากรกลุ่มถัดไปที่สูงขึ้น
การเรียนรู้แบบไมโครดัดแปลง
การส่งเนื้อหาและคำติชมในปริมาณมากเป็นกุญแจสำคัญในการเรียนรู้ออนไลน์อย่างมีประสิทธิภาพ โดยทั่วไป ผู้ใช้จะใช้เวลาออนไลน์ระหว่าง 30 นาทีถึงหนึ่งชั่วโมงเพื่อฝึกฝนแนวคิดและคำถาม ภายในช่วงเวลาสั้นๆ นี้ สิ่งสำคัญคือต้องเพิ่มผลกระทบของเซสชันที่มีกรอบเวลาแต่ละครั้งให้มากที่สุด แต่ละเซสชันเป็นสินทรัพย์สำหรับผู้ใช้ในการเรียนรู้สูงสุด และวิธีนี้ทำได้ดีที่สุดด้วยกลยุทธ์ขนาดพอเหมาะ เอ็นจิ้น micro-adaptive ของเราสำหรับช่วงฝึกซ้อม ใช้โปรไฟล์ของผู้ใช้และแอตทริบิวต์ตามรุ่นพร้อมกับแผนผังความรู้ของเราที่มีแอตทริบิวต์ meta-attributes ของแนวคิดที่เชื่อมโยงถึง 11,000 (และเพิ่มขึ้นเรื่อยๆ!) เป็นอินพุต และทำให้แน่ใจว่าการเรียงลำดับคำถาม คำแนะนำที่ให้ไว้ และเพียง- คำติชมแบบอินไลน์ที่ชาญฉลาดในเวลาที่เหมาะสมจะปรับให้เข้ากับผู้ใช้ได้อย่างแม่นยำ เพื่อปรับปรุงผลการเรียนรู้ของเธอในทุกเป้าหมาย การบริโภคเนื้อหาหรือข้อเสนอแนะในขนาดกัดแต่ละครั้งจะส่งผลต่อการสอบเทียบความสามารถของผู้ใช้กับโครงสร้างความรู้ที่กว้างขวางของแนวคิดของเรา เทคนิคการประมวลผลเมทริกซ์แบบกระจัดกระจาย ทฤษฎีการตอบสนองรายการ และอัลกอริธึมกราฟเป็นแนวทางในการปรับตัวเชิงจุลภาคของการเรียนรู้
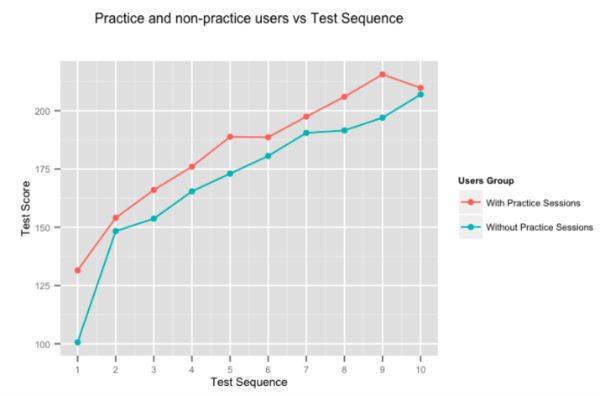
เห็นได้ชัดว่าการฝึกฝนทำให้สิ่งหนึ่งสมบูรณ์แบบ แต่เราตัดสินใจที่จะใช้ตัวเลขอยู่ดี รูปด้านบนแสดงคะแนนเฉลี่ยที่เพิ่มขึ้นของผู้ใช้ สำหรับการทดสอบต่อเนื่องที่กำหนดโดยผู้ใช้ที่ใช้เวลาในเซสชันการฝึกปฏิบัติที่ปรับเปลี่ยนได้ของเรา และผู้ที่ไม่ได้ทำการทดสอบ ผู้ใช้ที่ฝึกฝนบน Embibe อย่างสม่ำเสมอได้คะแนนเหนือกว่าผู้ที่ไม่ได้ทำการทดสอบเมื่อทำการทดสอบเกือบ 10%
ระบบข้อเสนอแนะและข้อเสนอแนะ
ระบบข้อเสนอแนะและข้อเสนอแนะของ Embibe (ซึ่งเราได้ยื่นจดสิทธิบัตรแล้ว) ได้รับการออกแบบและสร้างขึ้นเพื่อจุดประสงค์เดียว – เพื่อเพิ่มการปรับปรุงคะแนนของผู้ใช้ให้ได้มากที่สุด เราใช้เครื่องมือและตีความสัญญาณหลายพันรายการเกี่ยวกับความพยายามของผู้ใช้ในระหว่างการฝึกซ้อมและการทดสอบ และแปลงสัญญาณเหล่านี้เป็นพื้นที่มิติสูงของคุณลักษณะหลายพันรายการสำหรับผู้ใช้แต่ละราย ด้วยการใช้การทำเหมืองรูปแบบทางสถิติในพื้นที่คุณลักษณะความพยายามของผู้ใช้จำนวนมาก เราได้ให้ความสำคัญกับชุดพารามิเตอร์ที่จัดอันดับซึ่งช่วยเพิ่มคะแนนของผู้ใช้ในทางบวก พารามิเตอร์เหล่านี้ถูกเข้ารหัสด้วยเครื่องเป็นแคปซูลตอบรับการปรับปรุงคะแนนที่ตรงเป้าหมายอย่างตรงเป้าหมาย และส่งมอบให้กับผู้ใช้ในขณะที่เธอฝึกซ้อมต่อไป ข้อเสนอแนะและคำแนะนำเผยให้เห็นจุดอ่อนและกลยุทธ์ที่เธอสามารถนำมาใช้เพื่อเพิ่มคะแนนสูงสุดของเธอ
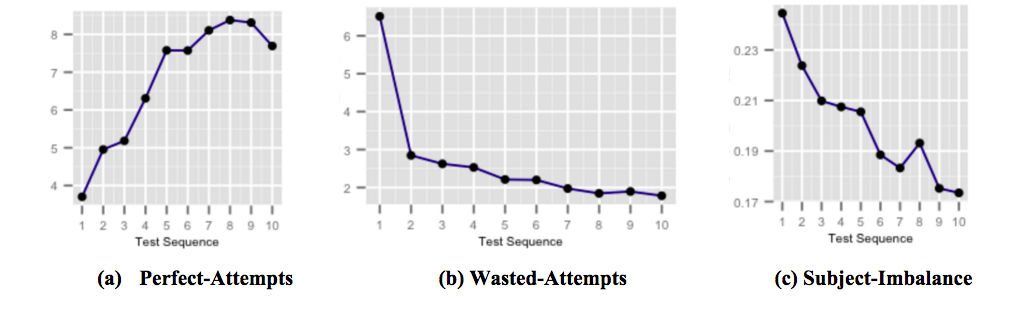
ตัวเลขด้านบนแสดงให้เห็นว่าแคปซูลผลตอบรับแบบทันท่วงทีที่มีเป้าหมายสูงสำหรับการปรับปรุงคะแนนมีผลต่อประสิทธิภาพของนักเรียนอย่างไรเมื่อผู้ใช้สัมผัส และตระหนักถึงข้อผิดพลาดในการทำข้อสอบทั่วไป รูปที่ (a) แสดงจำนวนเฉลี่ยของความพยายามที่สมบูรณ์แบบที่เพิ่มขึ้นจากการทดสอบที่ต่อเนื่องกัน ความพยายามที่สมบูรณ์แบบคือความพยายามที่ตอบถูกภายในเวลาที่กำหนด รูปที่ (b) แสดงจำนวนเฉลี่ยของความพยายามที่สูญเปล่าซึ่งลดลงจากการทดสอบต่อเนื่องกัน ความพยายามที่สูญเปล่าคือความพยายามที่ตอบผิดโดยที่นักเรียนมีเวลามากขึ้นที่สามารถคิดเกี่ยวกับคำถามได้ และรูปที่ (c) แสดงค่าเฉลี่ยของเรื่อง-ความแม่นยำ-ความไม่สมดุลลดลงจากการทดสอบต่อเนื่องกัน ความแม่นยำของหัวเรื่อง - ความแม่นยำ - ความไม่สมดุลถูกกำหนดให้เป็นความแตกต่างระหว่างความแม่นยำสูงสุดและต่ำสุดในทุกวิชาในการทดสอบที่ดำเนินการโดยผู้ใช้ ความแม่นยำของหัวเรื่อง-ความแม่นยำ-ความไม่สมดุลที่สูงขึ้นหมายความว่าผู้ใช้มีความพร้อมสำหรับวิชาบางวิชาน้อยกว่าเมื่อเปรียบเทียบกับวิชาอื่นๆ
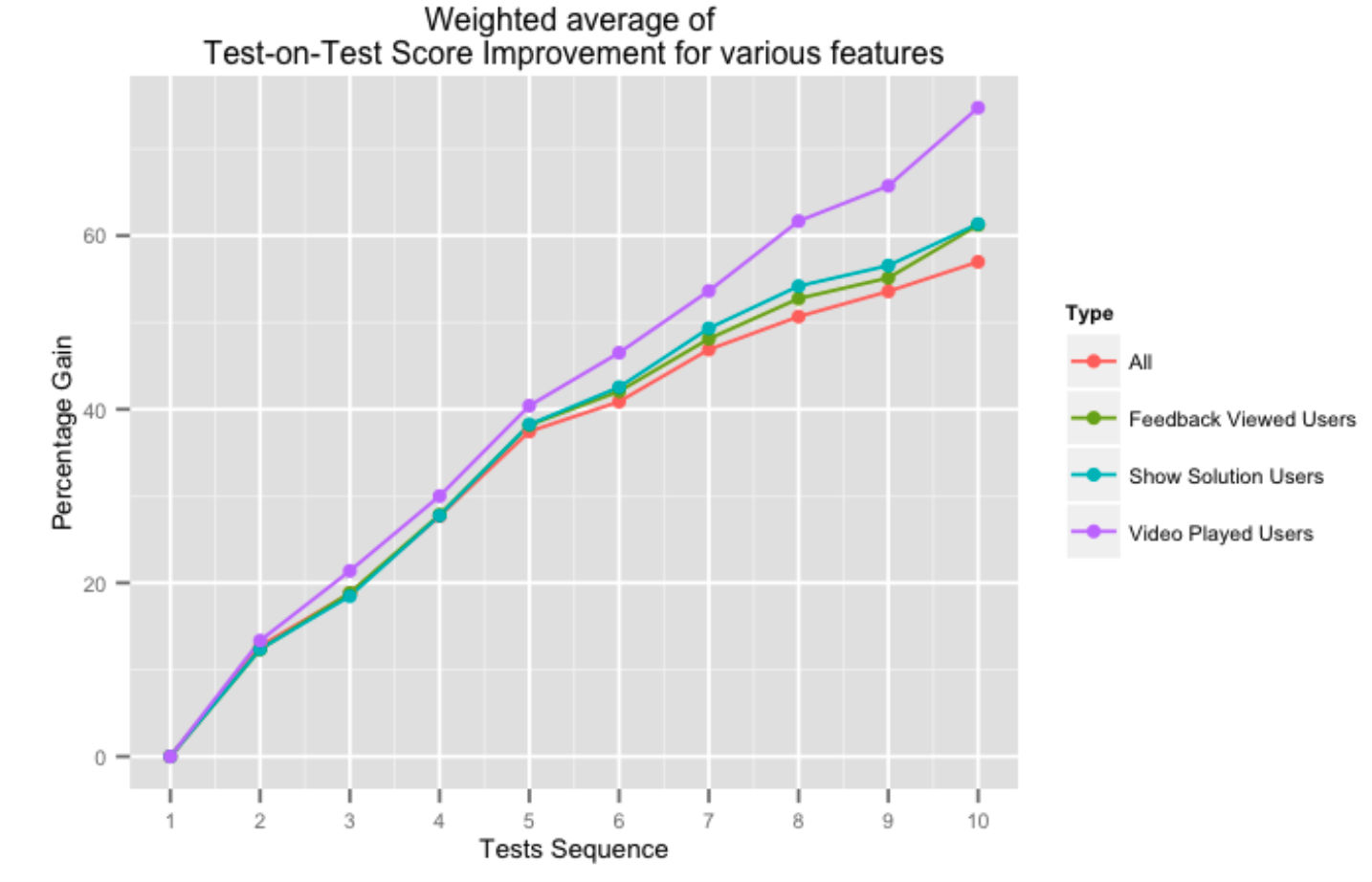
รูปด้านบนแสดงเปอร์เซ็นต์ที่เพิ่มขึ้นในคะแนนการทดสอบบนการทดสอบที่ต่อเนื่องกันสำหรับผู้ใช้ที่ใช้ระบบคำติชมของเราในด้านต่างๆ การให้ความช่วยเหลือจากแพลตฟอร์มของเราในรูปแบบของโซลูชันวิดีโอ หรือผลตอบรับการทดสอบโดยรวม ส่งผลในเชิงบวกต่อคะแนนการทดสอบเมื่อทำการทดสอบ โดยเฉพาะอย่างยิ่งเมื่อผู้ใช้ทำการทดสอบเสร็จสิ้นมากขึ้น
ประมาณการการปรับปรุงคะแนน
สำหรับผู้ใช้ที่กำลังเตรียมตัวสอบ การปรับปรุงคะแนนเป็นสิ่งสำคัญที่สุดในการส่งผลต่อผลลัพธ์การเรียนรู้ ข้อมูลพฤติกรรมมากมายของเราช่วยให้เราสามารถเรียนรู้จากการกระทำในอดีตของผู้ใช้ โดยการวัดว่าพฤติกรรมของพวกเขาในระหว่างและหลังจากทำการทดสอบกับ Embibe ส่งผลต่อการปรับปรุงคะแนนอย่างไร การทำเหมืองข้อมูลสำหรับรูปแบบทางสถิติในการใช้งาน กิจกรรม และคุณลักษณะด้านพฤติกรรมในกลุ่มผู้ใช้ต่างๆ ทำให้เราได้หลักฐานทางวิทยาศาสตร์สนับสนุนถึงประสิทธิภาพของแพลตฟอร์มของเรา
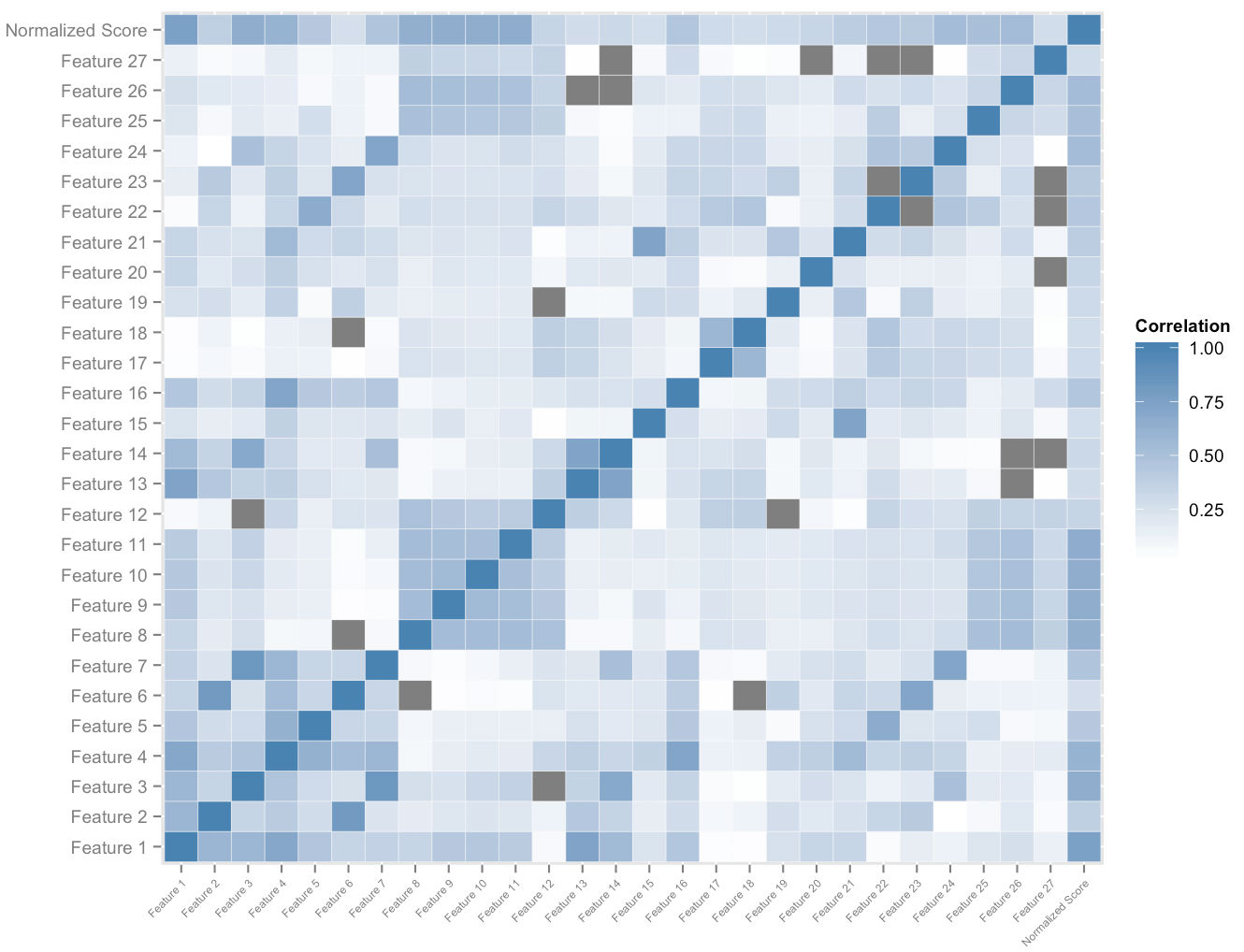
รูปด้านบนแสดงส่วนย่อยของพื้นที่คุณลักษณะที่เราสร้างต่อผู้ใช้ การวิเคราะห์สหสัมพันธ์ข้ามบนพื้นที่คุณลักษณะและคะแนนที่เป็นมาตรฐานโดยรวมช่วยให้เราจัดลำดับความสำคัญของคุณลักษณะที่เกี่ยวข้องได้ ร่วมกับการวิเคราะห์การครอบงำเชิงประจักษ์ช่วยให้เราสามารถวัดควอนตัมของผลกระทบของแต่ละคุณลักษณะที่มีต่อการมีส่วนร่วมในการปรับปรุงคะแนน การถ่วงน้ำหนักอย่างเหมาะสมของความเร็วของคุณลักษณะที่สำคัญที่สุดเหล่านี้ช่วยให้เราสามารถกำหนดการวัดผลการปรับปรุงคะแนนที่เป็นไปได้สำหรับนักเรียนแต่ละคนในเชิงปริมาณ ซึ่งจะปรับให้เข้ากับเธอขณะที่เธอใช้แพลตฟอร์ม
นี่เป็นช่วงเวลาที่น่าตื่นเต้นสำหรับสาขาการศึกษา โดยเฉพาะอย่างยิ่งในอินเดียและประเทศกำลังพัฒนาอื่นๆ มีความจำเป็นเร่งด่วนในการใช้วิทยาศาสตร์เชิงลึก โดยมุ่งเน้นที่การใช้ข้อมูลและข้อมูลเชิงลึกที่สามารถให้ได้ เพื่อนำการศึกษาและการเรียนรู้ไปสู่ระดับต่อไป แพลตฟอร์มการส่งผ่านข้อมูลและการนำส่งเนื้อหาของเราสร้างขึ้นบนหลักการทางวิทยาศาสตร์ที่มั่นคง และกำลังช่วยให้ผู้ใช้ตระหนักถึงคุณค่ามหาศาลของ Embibe ในรูปแบบของการปรับปรุงคะแนนภายในช่วงเวลาที่จำกัดในการเตรียมการ เฟรมเวิร์กการเรียนรู้แบบไมโครที่ปรับเปลี่ยนได้ของเราซึ่งใช้ข้อเสนอแนะและคำแนะนำเฉพาะผู้ใช้ ซึ่งปรับให้เหมาะกับผู้ใช้อย่างแม่นยำ โดยอิงตามการจำแนกประเภทตามรุ่นและลักษณะพฤติกรรม ช่วยให้ผู้ใช้มีประสบการณ์ที่เติมเต็มบน Embibe นี่เป็นขั้นตอนแรกที่เป็นรูปธรรมในการแก้ปัญหาผลกระทบเชิงบวกต่อผลลัพธ์การเรียนรู้ นี่คือการเรียนรู้ส่วนบุคคล
ในโพสต์นี้ เราได้กล่าวถึงปัญหาย่อยต่างๆ ที่ต้องแก้ไขเพื่อขับเคลื่อนเราไปตามเส้นทางที่ส่งผลต่อผลลัพธ์การเรียนรู้ ในโพสต์ถัดไป เราจะพูดถึงวิธีที่เราวัดและติดตามตัวชี้วัดต่างๆ ที่ Embibe ที่เกี่ยวข้องกับผู้ใช้ของเราและกิจกรรมของพวกเขา เพื่อให้เราสามารถจับตาดูจังหวะของผลิตภัณฑ์ การเติบโต และประสิทธิผลของมัน ปลายทางการเรียนรู้ออนไลน์
เรามักจะมองหาคนฉลาดที่ชั่วร้ายเพื่อเพิ่มอันดับของเราที่ Data Science Lab หากคุณชอบการทดสอบสมมติฐาน การถดถอย การแยกตัวประกอบเมทริกซ์ขนาดมหึมา การหัวเราะเมื่อเผชิญกับข้อมูลขนาดใหญ่ การเลิกจ้างงานการลดแผนที่ การสร้างแบบจำลองหัวข้อเหนือข้อความที่ไม่มีโครงสร้างที่ยุ่งเหยิง การขุดข้อมูลที่มีเสียงดังสำหรับรูปแบบทางสถิติ การนำเข้าข้อมูลจำนวนมากจากข้อมูลเปิด แหล่งที่มา การโต้เถียงค่า p การฝึกอบรมโครงข่ายประสาทเทียมและเครือข่ายความเชื่อลึก การสลับระหว่าง python และ R การหมุนการสร้างภาพข้อมูล และเปลือกสคริปต์ คุณจะหลงรักที่นี่!
แจ้งประวัติย่อของคุณมาที่ jobs.<id>@embibe.com โดยที่:
<id> คือตัวเลขที่เกิดจาก 8 หลักแรกที่ไม่ใช่ศูนย์ของค่าของฟังก์ชันความหนาแน่นของความน่าจะเป็นสำหรับการแจกแจงแบบปกติ ปัดเศษเป็นตัวเลขความแม่นยำ 19 หลัก และ
mu เป็นหมายเลขที่ 26 ในลำดับ Padovan และ
ซิกม่าเป็นตัวเลขที่ 17 ในลำดับฟีโบนักชีเริ่มต้นที่ 1 และ
x คือจำนวนเฉพาะที่ 1002
ทีมงานของเราประกอบด้วย Keyur Faldu ( หัวหน้านักวิทยาศาสตร์ข้อมูล), Achint Thomas ( หัวหน้านักวิทยาศาสตร์ข้อมูล) และ Chintan Donda ( นักวิทยาศาสตร์ข้อมูล)
อ้างอิง
- การเรียนรู้สินค้าคงคลัง สไตล์ Lawrence, แคนซัส: ระบบราคา
- เกรกอค เอเอฟ, (1982). แบบจำลองลักษณะความคิด: ทฤษฎี หลักการ และการประยุกต์ เมย์นาร์ด แมสซาชูเซตส์: Gabriel Systems
Embibe เพิ่งเสร็จสิ้น 3 ปีในตลาดในฐานะหนึ่งในบริษัทชั้นแนวหน้าในด้านการวิเคราะห์ข้อมูลการศึกษา นักเรียนใช้เวลามากกว่า 100,000 ชั่วโมงกับผลิตภัณฑ์ในเดือนมีนาคม 2016 เพียงลำพังโดยไม่มีการลงทุนในด้านการตลาดแบบชำระเงิน