
300 مليون طالب ، 300 مليار نظرة ثاقبة - في حب البيانات في التعليم
نشرت: 2016-04-07نظرة داخلية حصرية على مختبر علوم البيانات في Embibe
[هذا هو الجزء الثاني من سلسلة كيف نستخدم التكنولوجيا العميقة وعلوم البيانات لتخصيص التعليم]
لقد قمنا ببناء Embibe برؤية فريدة: لتعظيم نتائج التعلم على نطاق واسع. يعد إحداث تأثير إيجابي على نتائج التعلم للمستخدم مشكلة صعبة ولكنها مهمة يجب حلها. في الواقع ، هناك عدد من المشاكل الفرعية المفتوحة غير التافهة ، كل منها يحتاج إلى حل من أجل تحقيق الهدف السامي المتمثل في التأثير بشكل مقصود وإيجابي على نتائج التعلم.
لكن أولاً ، ما هي نتائج التعلم؟ ولماذا نهتم بهم؟
في عالم اليوم شديد التنافسية ، يُقاس الطالب إلى حد كبير بمدى قدرته على التسجيل في امتحان تنافسي أو حتى فصل دراسي في المدرسة. يمكن أن يكون لدرجاتها تأثير كبير على خياراتها المهنية. لأغراض هذه المقالة ، دعنا نضع نتائج التعلم كوظيفة لإمكانيات الطالب الفطرية وكذلك القابلة للتدريب ، لتعلم واستيعاب وتطبيق مواد المحتوى على النحو الأمثل ، ضمن قيود زمنية محددة بدقة ؛ حتى تتمكن من زيادة درجاتها إلى الحد الأقصى في أي سياق أكاديمي تنافسي معين.
في البلدان النامية مثل الهند ، تكون نسبة الطلاب إلى المدرسين شديدة الانحراف ولا يستطيع المعلمون توفير الاهتمام الشخصي بشكل فعال على المستوى الفردي. يؤدي هذا إلى معضلة ، نظرًا لأن كل طالب يتعلم ويستوعب المعلومات بمعدلات مختلفة ولديه مستويات مختلفة من الكفاءة. أحد الآثار الجانبية المعروفة لعدم قدرة المعلمين على توفير الاهتمام الشخصي هو أنه بالنسبة لأي فصل دراسي معين / مجموعة من الطلاب ، يتم تقديم المواد التعليمية دائمًا لتلبية احتياجات الطالب "المتوسط". لذلك ، لا يصل الطلاب المتميزون جدًا إلى إمكاناتهم الكاملة ولن يكونوا قادرين على استعراض عضلاتهم الأكاديمية حقًا ، بينما سيواجه الطلاب الأضعف في الدراسة صعوبة في التعامل مع بقية الفصل الدراسي. ومع ذلك ، فإن أنظمة وأنظمة التعلم الموجودة عبر الإنترنت ليست قادرة حقًا على تسهيل التعلم الشخصي على مستوى الطلاب.
تفسر معظم الأنظمة الحالية فقط مدى قدرة الطالب على مطابقة حلولهم لوحدات الاختبار كما هو محدد من قبل بعض مسؤولي النظام. يجب أن يزيد التعلم المخصص للامتحانات التنافسية من درجة الطالب إلى أقصى حد لأي هدف أكاديمي في الوقت المحدود المتاح لها. يجب أن يعالج التعلم المخصص بشكل بناء فجوات قدرة الطالب ليس فقط على مستوى المعرفة أو الكفاءة ، ولكن أيضًا على المستويات السلوكية والسلوكية. هذا النقص في الأدوات الفعالة للتعلم الشخصي ، والمصممة خصيصًا وبدقة لكل طالب ، هي المسؤولة عن عدم قدرتها على تحقيق إمكاناتها في تحقيق أقصى درجة ممكنة في أي اختبار معين.
في هذه المقالة ، سيضع فريق علم البيانات في embibe الأساس للعديد من المشكلات المرتبطة بالبيانات المترابطة التي يجب معالجتها من أجل تعظيم نتائج التعلم ، وعلى وجه التحديد ، تحسين النتيجة. هناك نوعان من الأبعاد الرئيسية لهذه المشكلة - "بث المحتوى" و "تسليم المحتوى". يفرض كل بُعد تحديات فريدة في عدد من المجالات التي من المؤكد أنها ستذهل أي عالم بيانات.
استيعاب المحتوى
العرض التلقائي للمحتوى
عشرات من لوحات المناهج ، وآلاف الفصول والمفاهيم ، وعشرات الآلاف من المعاهد والمدارس ينتج عنها مئات الآلاف من الأسئلة والأجوبة التي يتم إنشاؤها واستخدامها من قبل المعلمين كل عام. تخيل لو كان كل طالب قادرًا على اختبار معرفته قبل الاختبارات على أي مجموعة فرعية ، أو كل هذه الأسئلة ، إلى جانب الحصول على تفسيرات مفصلة حول الإجابات الصحيحة ، والأخطاء الشائعة التي ارتكبت. من أجل جعل هذا الأمر حقيقة واقعة ، فإننا نستفيد من التعرف الضوئي على الأحرف (OCR) والتعلم الآلي لبناء إطار عمل آلي خاص بنا سيكون قابلاً للتطوير بشكل كبير ، ومتعدد اللغات حقًا ، ومعتمد إلى الحد الأدنى على المدخلات البشرية. والمرح لا يتوقف عند هذا الحد. سيكون إطار العمل أيضًا قادرًا على استيعاب المحتوى المكتوب بخط اليد بطريقة حيادية للكاتب ، وبالتالي إضافة سريعة إلى مستودعنا الرائع بالفعل من الأسئلة والإجابات والمفاهيم والتفسيرات والمعرفة.
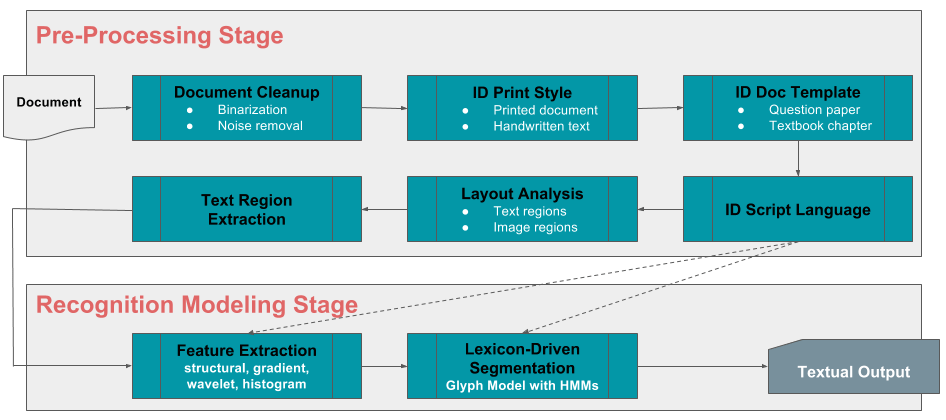
وضع علامات على المفهوم
حسنًا ، لدينا الآن أسئلة وإجابات ومفاهيم وفصول تم استيعابها جميعًا في مستودع بيانات ضخم. سيكون من المؤلم وضع علامة يدويًا على كل سؤال أو فصل بالمفاهيم ذات الصلة ، أو العكس. علم البيانات للإنقاذ! باستخدام الأفكار المتطورة من تصنيف النص ونمذجة الموضوع والتعلم العميق ، نقوم تلقائيًا بتمييز المفاهيم على الأسئلة والإجابات والفصول.

مجموعة مختارة من المفاهيم الأكثر شيوعًا كما تم تصفحها بواسطة مستخدمي Embibe باستخدام ميزة Learn ، في شهور ديسمبر 2015 ويناير 2016 وفبراير 2016.
تعد قواعد البيانات السابقة الخاصة بنا التي تحتوي على مجموعات أولية من المحتوى عالي الجودة الذي تم وضع علامة عليه يدويًا مفيدة لأننا نستخرج الميزات اللغوية والمعجمية والحساسة للسياق ، لتدريب أحدث نماذج وضع العلامات النصية لجميع البيانات الجديدة التي يتم استيعابها في الأنظمة.
إثراء البيانات الوصفية
هناك ثروة من المعلومات المتاحة عبر الإنترنت اليوم حول أي موضوع يرغب المرء في التعرف عليه. الأفكار والمفاهيم مبنية على بعضها البعض. على سبيل المثال ، يرتبط القانون الأول للديناميكا الحرارية بمفهوم النظام الديناميكي الحراري ، والذي يرتبط بدوره بمفاهيم السعات الحرارية المحددة للغازات ، والحفاظ على الطاقة الميكانيكية ، والعمل الذي يقوم به الغاز ، من بين أمور أخرى. يتضمن إطار عمل المحتوى الخاص بنا مكونات إثراء البيانات التي تزحف تلقائيًا إلى الويب وتضع علامة على المحتوى باستخدام أجزاء متنوعة من الوسائط مثل التفسيرات النصية ، وروابط الفيديو ، والتعريفات ، وتعليقات المستخدم ، ومناقشات المنتدى ، كل ذلك مع احترام حقوق النشر ، وإسناد الملكية بشكل صحيح إلى المحتوى المصدر . هذه الثروة من المعلومات المتاحة تجعل من الممكن أيضًا ربط المفاهيم ذات الصلة تلقائيًا في بنية شجرة. باستخدام أفكار من مجالات نظرية الرسم البياني ، والتنقيب عن النص ، وانتشار الملصقات على هياكل متفرقة ، نقوم بإنشاء روابط وترابط بين المفاهيم التي تشترك في علاقة المصدر → الهدف.
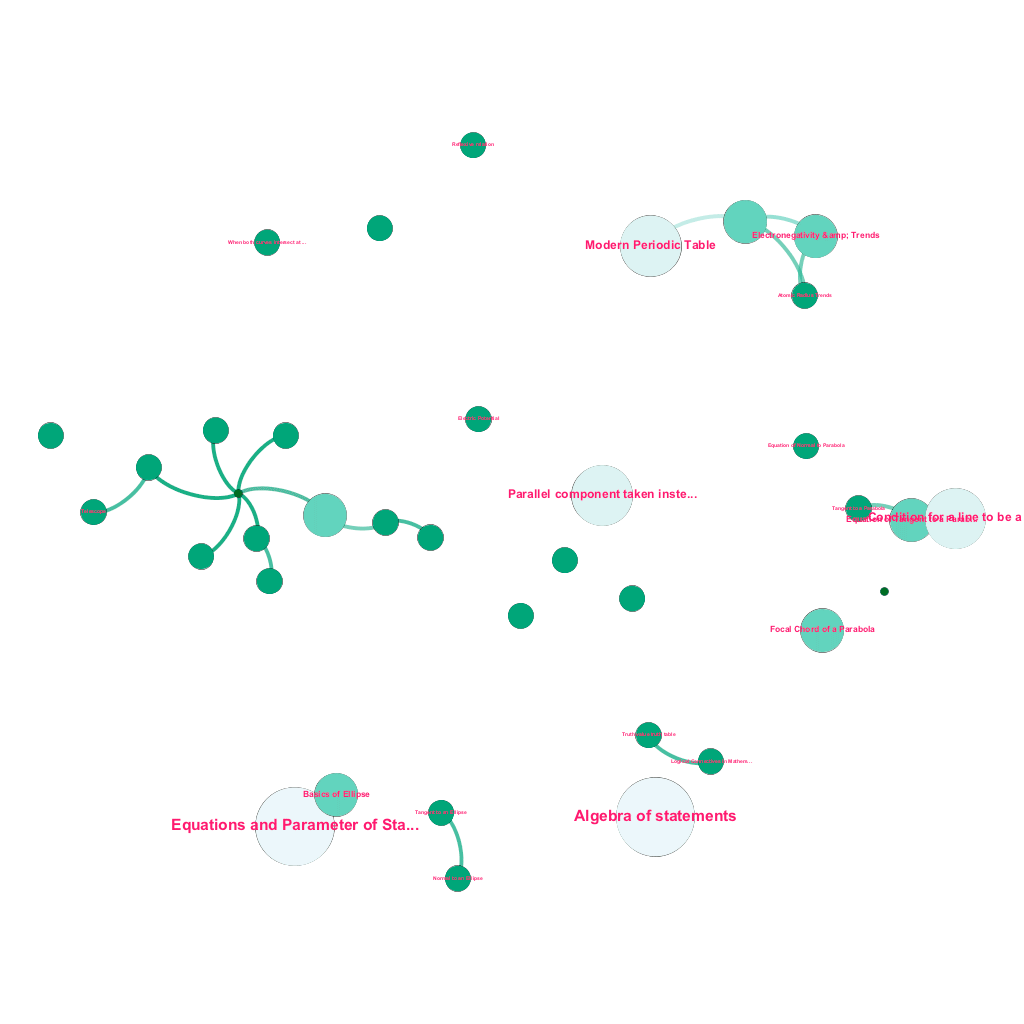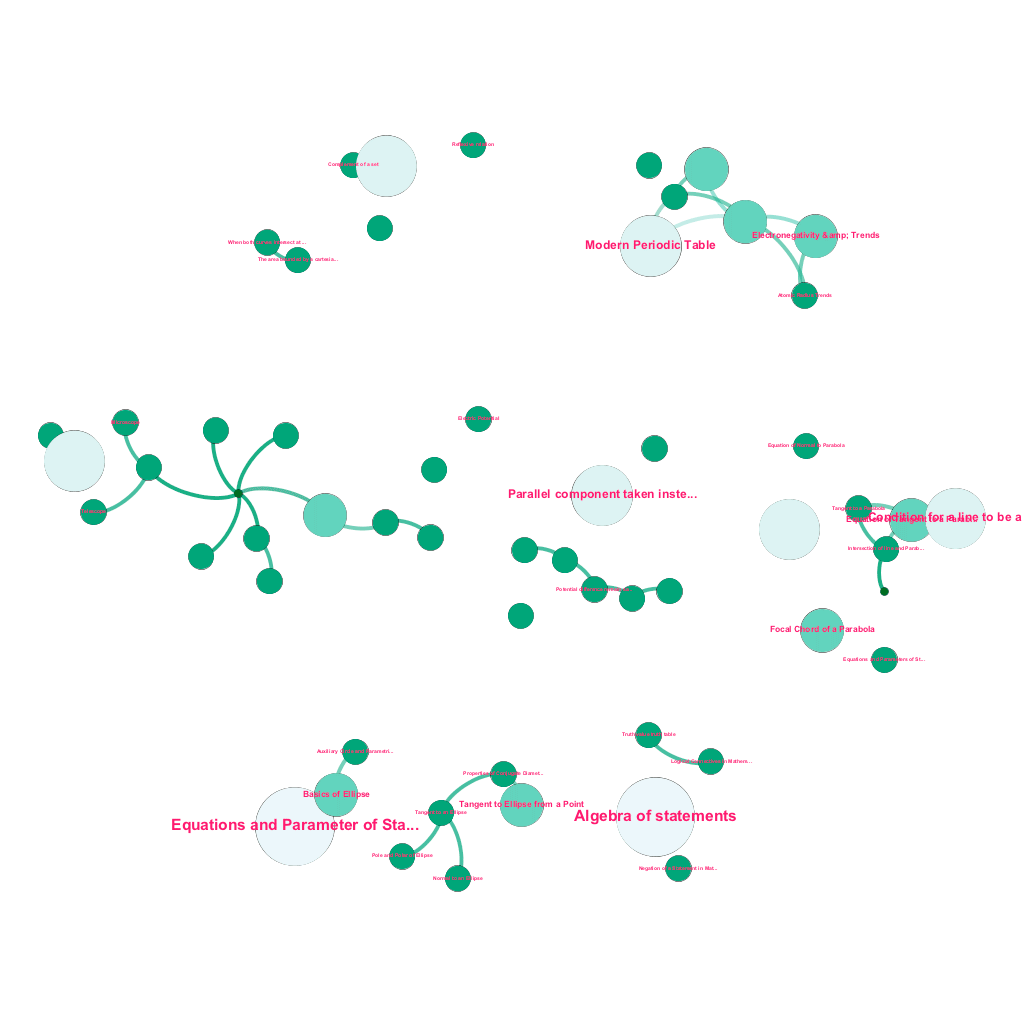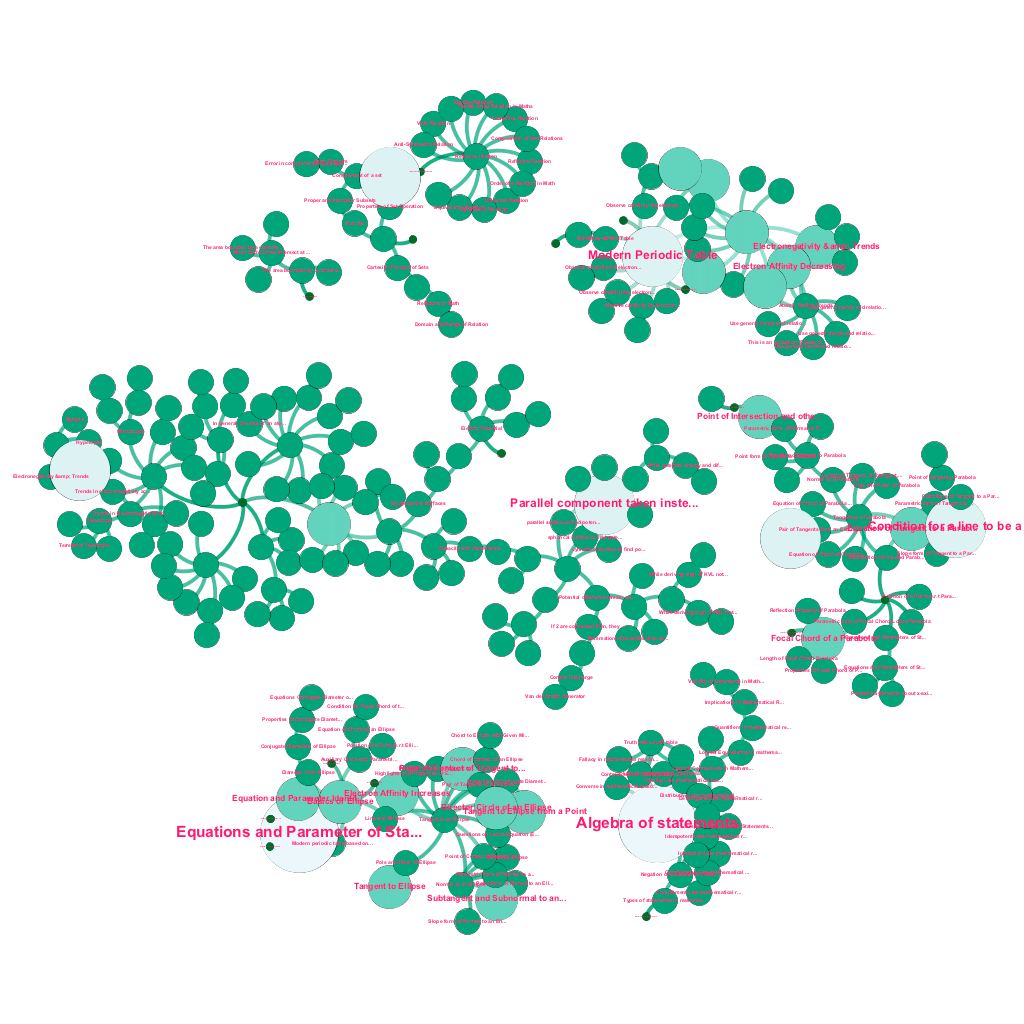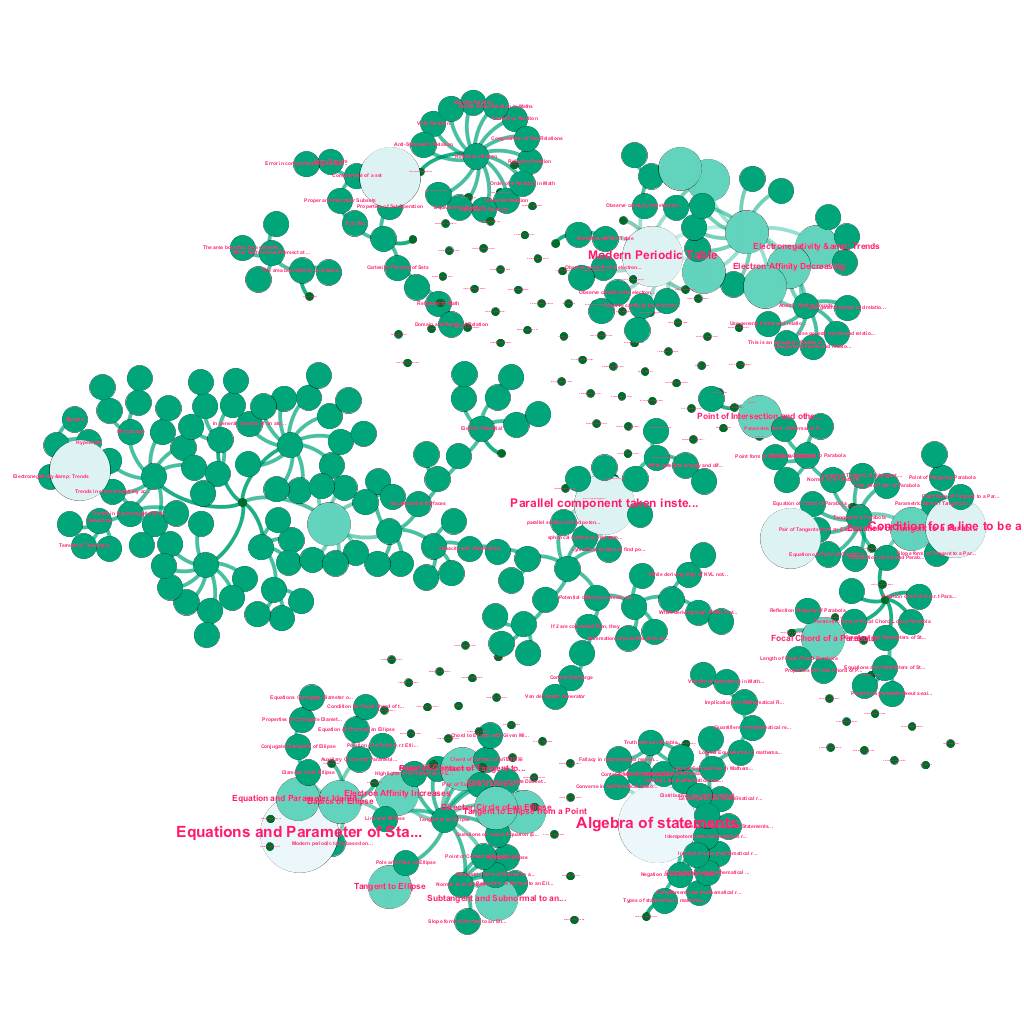
البناء الآلي لشجرة المفاهيم ، لمجموعة فرعية من الأفكار من الرياضيات ، كل منها مرتبط بواحد أو أكثر من المفاهيم ذات الصلة
تجميع الأسئلة المماثلة
إذا كنت تستعد لامتحان ، فهل ترغب في ممارسة نفس السؤال مرارًا وتكرارًا؟ هذا لن يكون مفيدا على العكس من ذلك ، تخيل كم سيكون مفيدًا للغاية ممارسة مجموعة صغيرة من الأسئلة ذات الصلة التي ستساعدك تمامًا على إتقان مفهوم أو فصل جديد. من خلال وصولنا إلى مئات الآلاف من الأسئلة ، قمنا بتطوير القدرة على تجميع الأسئلة بناءً على التشابه عبر عدد من الأبعاد - من بين أمور أخرى ، استهداف المحتوى ، واختبار المفهوم ، ومستوى الصعوبة ، وأهداف الاختبار.
يسمح لنا تجميع النص استنادًا إلى مساحات المعلومات الدلالية الكامنة ، ودمجها مع مساحات الميزات الفئوية والرقمية الأخرى ، بتجميع عالم الأسئلة بدقة في مجالات الاهتمام التي يمكن تخصيصها لكل فرد باستخدام Embibe. بالإضافة إلى ذلك ، فإن هذا المورد الغني للبيانات النصية الذي قمنا بتحويله إلى مساحات ميزة رقمية قوية تتعلق بمجموعات المفاهيم يتيح لنا تشويشًا طفيفًا للبيانات الموجودة لإنشاء تعبيرات لا نهائية محتملة لمساحة السؤال. المزيد من الأسئلة في وقت التشغيل ، لم أر من قبل! يتيح لنا ذلك منح المستخدمين أقصى قيمة للوقت الذي يقضونه على نظامنا الأساسي.
تقديم المحتوى
تحديد سمات المستخدم
نحن نتتبع كل حركة يقوم بها المستخدم على Embibe. تمت معايرة الملايين من محاولات الممارسة والاختبار التي قام بها مستخدمونا على مدار السنوات الثلاث الماضية في مساحة بيانات من عدة آلاف من الأبعاد. يُترجم هذا إلى مساحة من المليارات من نقاط البيانات التي يمكننا استخراجها للتعمق في البيانات السلوكية لمستخدمينا وإنشاء رؤى ترتبط بكيفية حدوث التعلم. كل محاولة إضافية من قبل المستخدم ، تعدل من قدرته على الحصول على درجة أعلى في المفاهيم التي تم وضع علامة عليها لتلك المحاولة ، إلى جانب المفاهيم السابقة واللاحقة. تتضمن هذه المشكلة الفائقة التعقيد الاستفادة من الأفكار من معالجة المصفوفة المتفرقة ، والخوارزميات الحسابية في نظرية الرسم البياني ، ونظرية استجابة العنصر لبناء ملفات تعريف مستخدم قوية وقابلة للتكيف تتناسب مع قاعدة مستخدمينا المتزايدة.
موصى به لك:

ماذا يعني توفير مكافحة الربح بالنسبة للشركات الهندية الناشئة؟

كيف تساعد الشركات الناشئة في تكنولوجيا التعليم في تطوير مهارات القوى العاملة في الهند وتصبح جاهزة للمستقبل ...

الأسهم التقنية في العصر الجديد هذا الأسبوع: مشاكل Zomato مستمرة ، EaseMyTrip تنشر Stro ...

تتخذ الشركات الهندية الناشئة اختصارات في مطاردة للتمويل

منصة التسويق الرقمي Logicserve Bags INR 80 Cr Funding، Rbrands as LS Dig ...

تقرير يحذر من تجديد التدقيق التنظيمي على Lendingtech Space
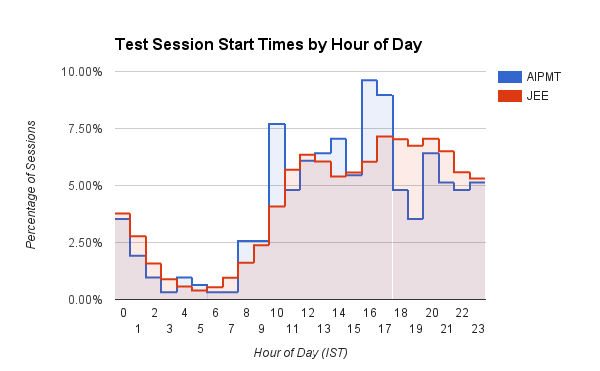
رسم بياني شريطي مثير للاهتمام يعرض الوقت (ساعة من اليوم في IST) الذي يبدأ فيه المستخدمون جلسات اختبارهم على Embibe. مستخدمو الخدمات الطبية (AIPMT) لديهم ارتفاع محدد في حوالي الساعة 10 صباحًا وبين 3 مساءً إلى 5 مساءً. من ناحية أخرى ، يُظهر مستخدمو الهندسة (JEE) أوقات بدء الجلسة المتزايدة تدريجياً مع تقدم اليوم ، والتي تبلغ ذروتها حوالي 4 مساءً إلى 8 مساءً. يبدأ طلاب JEE أيضًا باستمرار المزيد من جلسات التدريب بين الساعة 5 مساءً و 3 صباحًا مقارنة بطلاب AIPMT. نحن نخمن أن الأطباء أكثر انضباطًا!

تمنحنا أجهزتنا الشاملة وقياس نشاط المستخدم على مستوى دقيق للغاية القدرة على استنتاج التفضيلات الكامنة المتعلقة بأنماط التعلم المرتبطة بالمستخدمين الفرديين. على سبيل المثال ، قد يتعلم بعض الطلاب ، ثم يؤدون الاختبارات بعد ذلك ، بشكل أفضل بمساعدة تفسيرات الفيديو ، مقارنة بالطلاب الآخرين الذين يفضلون الأوصاف النصية الشاملة ، أو لا يزالون يتعلمون من خلال العمل خطوة بخطوة من خلال أمثلة تم حلها. يمكننا تعيين المستخدمين لنماذج نظرية مدروسة جيدًا لأنماط التعلم مثل نموذج Dunn and Dunn (Dunn & Dunn 1989) أو نموذج أنماط العقل في Gregorc (Gregorc 1982) لتصميم دورات تدريبية علاجية تلقائيًا ومساعدة المستخدم على تحسين النتيجة.
تجميع المستخدمين
التجميع هو مشكلة تجميع تقليدية. يتم تجميع المستخدمين بناءً على أنماط استخدامهم فيما يتعلق بميزات المنتج بالإضافة إلى أنماط أدائهم فيما يتعلق بجلسات الاختبار والممارسة والمراجعة. يتم تعيين كل مستخدم إلى مساحة ميزة عالية الأبعاد تتكون من عدة آلاف من السمات ، والتي تتضمن مقاييس ثابتة وكذلك زمنية. يمنحنا التجميع على المقاييس الزمنية القدرة على البدء البارد بنشاط منخفض ومستخدمين جدد من خلال تعيين مسارات مجموعة محتملة لهؤلاء المستخدمين بناءً على نشاطهم الأولي. تعد مجموعة المستخدمين مطلبًا أساسيًا لميزات العلوم العميقة ذات المستوى الأعلى مثل التعلم التكيفي الجزئي وإنشاء التعليقات التلقائية وتوصية المحتوى.
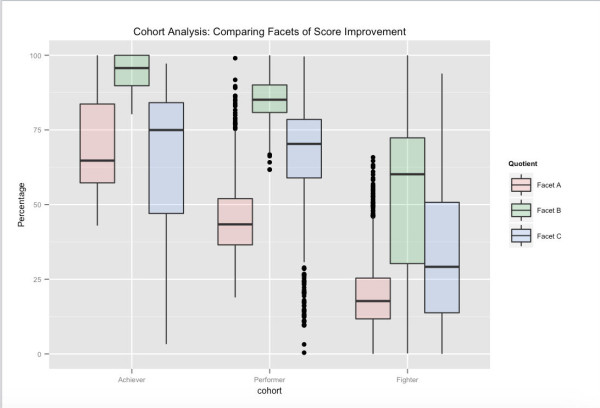
عرض واحد ممكن لمجموعات المستخدمين - مرتبط بأداء الاختبار على المدى الطويل. استنادًا إلى درجات الاختبار الإجمالية الخاصة بهم ، فإن Achievers هم الشريحة المئوية الأعلى للمستخدمين في Embibe ، و Performers الفئة التالية ، و Fighters الفئة النهائية. الجوانب المختلفة الموضحة تتعلق بجوانب مختلفة لتحسين النتيجة التي قمنا بتجميع مساحة الميزات الخاصة بنا فيها. على سبيل المثال ، يمكننا أن نرى أنه على الرغم من اختلاف Facet_A بشكل كبير عبر المجموعات ، من خلال استهداف التعليقات والتأثير على جوانب التعلم الأخرى ، فمن الممكن دفع المستخدمين إلى المجموعة النموذجية الأعلى التالية.
التعلم الجزئي التكيفي
يعد تقديم المحتوى والتعليقات بحجم صغير أمرًا أساسيًا للتعلم الفعال عبر الإنترنت. بشكل عام ، يقضي المستخدمون ما بين 30 دقيقة إلى ساعة عبر الإنترنت ، للتدرب على المفاهيم والأسئلة. خلال هذه الفترة الزمنية القصيرة ، من المهم للغاية زيادة تأثير كل جلسة محددة زمنياً. كل جلسة هي أحد الأصول للمستخدم لتحقيق أقصى قدر من التعلم ، ويتم تحقيق ذلك بشكل أفضل باستخدام استراتيجية صغيرة الحجم. يأخذ محركنا التكيفي الجزئي لجلسات التدريب ملف تعريف المستخدم وسمات المجموعة جنبًا إلى جنب مع شجرة معرفتنا المكونة من 11000 (وتزايد!) من السمات الوصفية للمفاهيم المترابطة كمدخلات ، ويضمن أن تسلسل الأسئلة ، والتلميحات المقدمة ، و- تتكيف التعليقات المضمنة الذكية في الوقت المناسب تمامًا مع المستخدم من أجل تحسين نتائج التعلم الخاصة بها على أي هدف صغير الحجم. سيؤثر كل استهلاك صغير الحجم للمحتوى أو التعليقات على معايرة كفاءة المستخدم مقابل شجرة المعرفة الشاملة للمفاهيم. تقنيات معالجة المصفوفة المتفرقة ، ونظرية استجابة العنصر ، وخوارزميات الرسم البياني توجه التكيف الجزئي للتعلم.
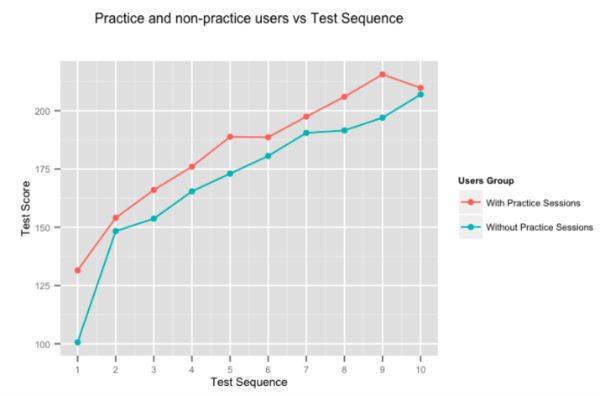
من الواضح إلى حد ما أن الممارسة تجعل المرء مثاليًا ، لكننا قررنا إجراء الأرقام على أي حال. يوضح الشكل أعلاه متوسط درجة تحسين المستخدمين ، للاختبارات المتتالية التي قدمها المستخدمون الذين يقضون وقتًا في جلسات التدريب التكيفية ، وأولئك الذين لا يفعلون ذلك. المستخدمون الذين يتدربون على Embibe يتفوقون باستمرار على أولئك الذين لا يقومون بالاختبار في الاختبار بنسبة 10٪ تقريبًا.
نظام التغذية الراجعة والتوصية
تم تصميم وبناء نظام التعليقات والتوصيات الخاص بـ Embibe (الذي قدمنا عليه براءات الاختراع بالفعل) لغرض واحد - لزيادة تحسين درجة المستخدم إلى أقصى حد. نقوم بصك وتفسير آلاف الإشارات حول محاولات المستخدم أثناء جلسات التدريب والاختبار ، ونحول هذه الإشارات إلى مساحة عالية الأبعاد تضم آلاف الميزات لكل مستخدم. باستخدام التنقيب عن الأنماط الإحصائية في مساحة ميزة محاولة المستخدم الهائلة ، قمنا بالتركيز على مجموعات المعلمات المرتبة التي تزيد بشكل إيجابي من نقاط المستخدم. يتم ترميز هذه المعلمات آليًا على أنها كبسولات عالية الاستهداف في الوقت المناسب لملاحظات تحسين النتيجة ، ويتم تسليمها إلى المستخدم أثناء استمرارها في جلسة التدريب الخاصة بها. تكشف الملاحظات والتوصيات نقاط الضعف والاستراتيجيات التي يمكن أن تتبناها لزيادة درجاتها إلى أقصى حد.
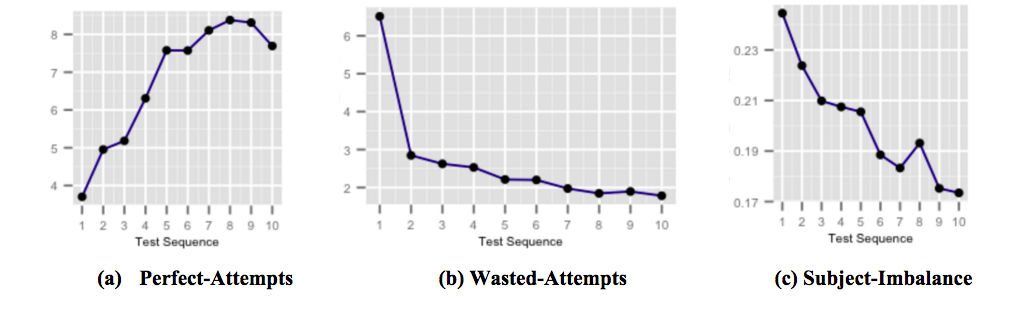
توضح الأرقام أعلاه كيف تؤثر كبسولات التعليقات في الوقت المناسب المستهدفة للغاية لتحسين النتيجة على أداء الطلاب حيث يتعرض المستخدم لها ، ويصبح على دراية بالمزالق الشائعة أثناء إجراء الاختبارات. يوضح الشكل (أ) متوسط عدد محاولات الكمال المتزايدة على الاختبارات المتتالية. المحاولات المثالية هي محاولات يتم الرد عليها بشكل صحيح خلال فترة زمنية محددة. يوضح الشكل (ب) متوسط عدد المحاولات الضائعة المتناقصة على مدى الاختبارات المتتالية. المحاولات الضائعة هي محاولات يتم الرد عليها بشكل غير صحيح حيث يكون لدى الطالب المزيد من الوقت الذي كان يمكن أن يقضيه في التفكير في السؤال. ويوضح الشكل (ج) انخفاض متوسط عدم توازن الدقة في الموضوع على مدى الاختبارات المتتالية. يُعرَّف عدم توازن دقة الموضوع بأنه الاختلاف بين أعلى وأدنى درجات الدقة بين جميع المواد في أي اختبار يجريه المستخدم. يشير الاختلال في دقة الموضوع إلى أن المستخدم أقل استعدادًا لموضوعات معينة مقارنة بالموضوعات الأخرى.
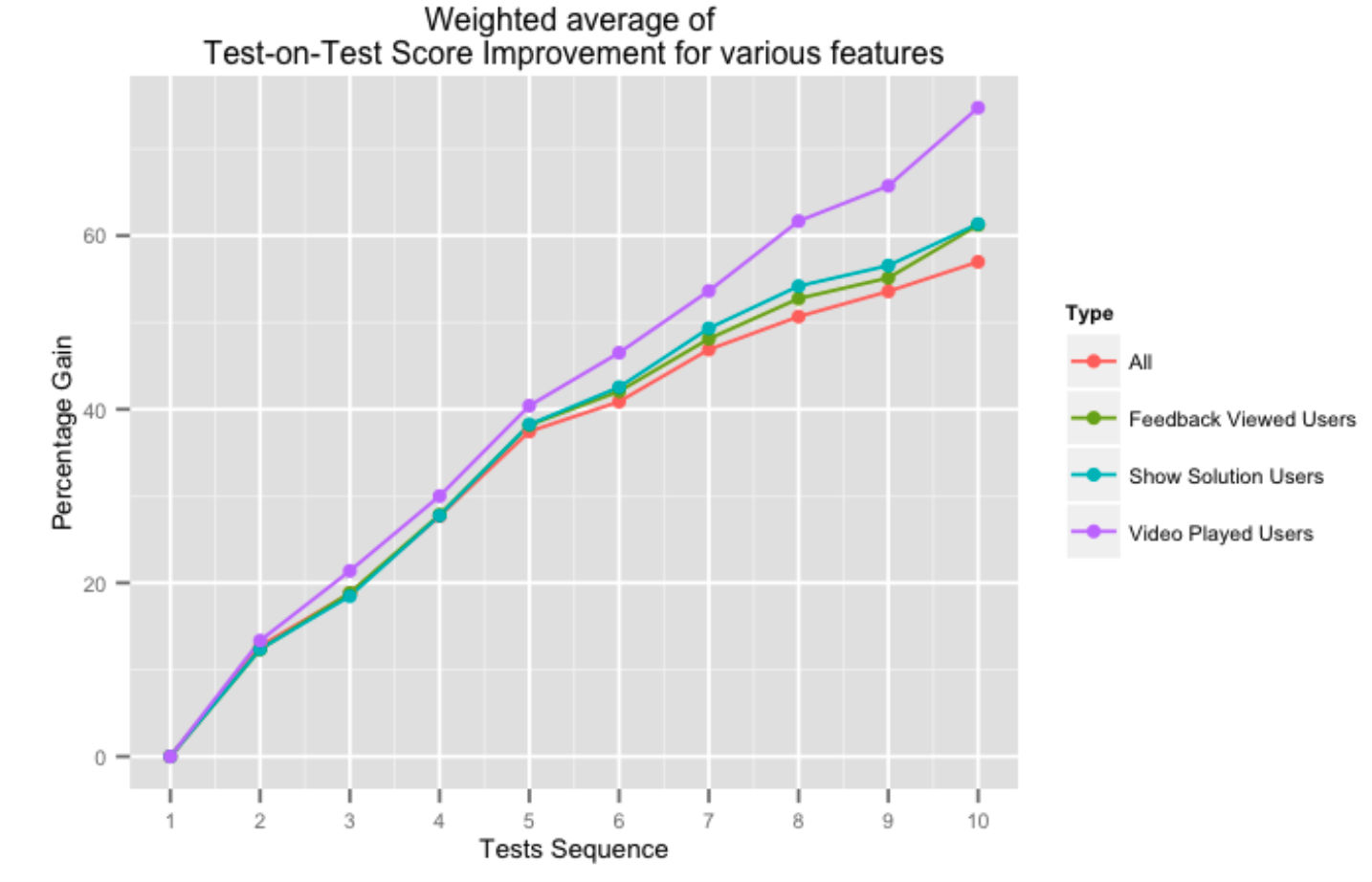
يوضح الشكل أعلاه نسبة المكاسب في الدرجات المتتالية للاختبار على الاختبار للمستخدمين الذين يستخدمون جوانب مختلفة من نظام التعليقات. الحصول على المساعدة من نظامنا الأساسي في شكل حلول الفيديو ، أو ملاحظات الاختبار الشاملة ، يؤثر بشكل إيجابي على درجات الاختبار في الاختبار ، خاصةً عندما يكمل المستخدم المزيد من الاختبارات.
تقدير تحسين النتيجة
بالنسبة للمستخدمين الذين يستعدون للامتحانات من أي نوع ، فإن تحسين الدرجة هو أهم جانب في التأثير على نتائج التعلم. تمنحنا ثروتنا من البيانات السلوكية القدرة على التعلم من الإجراءات السابقة للمستخدمين ، من خلال قياس كيفية تأثير سلوكهم أثناء وبعد إجراء الاختبارات على Embibe على تحسين النتيجة. يمنحنا التنقيب عن البيانات للأنماط الإحصائية في الاستخدام والنشاط والميزات السلوكية ، بين مجموعات مختلفة من المستخدمين ، دليلًا مدعومًا علميًا على فعالية نظامنا الأساسي.
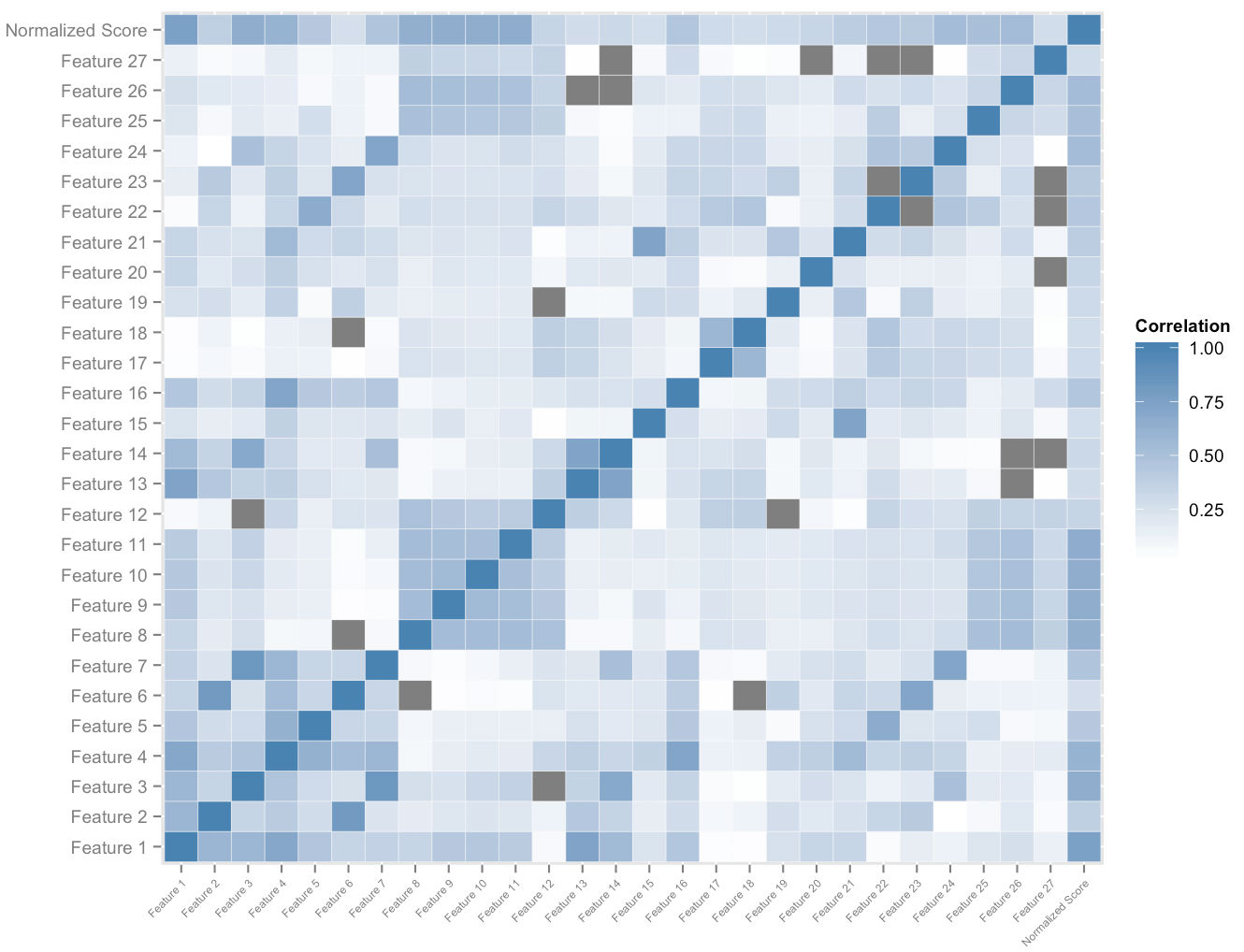
يوضح الشكل أعلاه مجموعة فرعية من مساحة الميزة التي نبنيها لكل مستخدم. يمنحنا تحليل الارتباط المتبادل في مساحة الميزة والنتائج المقيسة الإجمالية ترتيبًا لأهمية الميزة النسبية. هذا ، جنبًا إلى جنب مع تحليل الهيمنة التجريبية ، يسمح لنا بقياس مقدار تأثير كل ميزة على مساهمتها في تحسين النتيجة. تتيح لنا مجموعة مرجحة بشكل مناسب من سرعات أهم هذه الميزات تحديد مقياس كمي لتحسين النتيجة المحتملة لكل طالب يتكيف معها أثناء استخدام النظام الأساسي.
هذه أوقات مثيرة في مجال التعليم ، خاصة في الهند والدول النامية الأخرى. هناك حاجة ملحة لتطبيق العلم العميق ، مع التركيز القوي على استخدام البيانات والأفكار التي يمكن أن توفرها ، من أجل نقل التعليم والتعلم إلى المستوى التالي. يتم إنشاء منصات عرض المحتوى وتسليمه على مبادئ علمية متينة ، وتساعد المستخدمين على إدراك قيمة هائلة على Embibe في شكل تحسين النتيجة خلال فترات إعداد محدودة. يتيح إطار التعلم الصغير التكيفي الخاص بنا والذي يستخدم التعليقات والتوصيات الخاصة بالمستخدم ، والمصممة بدقة للمستخدمين ، بناءً على تصنيفات مجموعاتهم بالإضافة إلى الخصائص السلوكية ، للمستخدمين الحصول على تجربة مرضية على Embibe. هذه هي أولى الخطوات الملموسة نحو حل مشكلة التأثير الإيجابي على نتائج التعلم. هذا هو التعلم الشخصي.
في هذا المنشور ، تطرقنا إلى العديد من المشكلات الفرعية التي يجب حلها لتحريكنا على طول الطريق للتأثير على نتائج التعلم. في مقالنا التالي ، سنتحدث عن كيفية قياس وتتبع المقاييس المختلفة في Embibe المتعلقة بمستخدمينا ونشاطهم ، حتى نتمكن من متابعة نبض منتجنا ونموه وفعاليته وجهة تعلم عبر الإنترنت.
نحن نبحث دائمًا عن الأشرار الأذكياء لإضافتهم إلى صفوفنا في مختبر علوم البيانات. إذا كنت تستمتع باختبار الفرضيات ، وتشغيل الانحدارات ، والتعامل مع المصفوفات العملاقة ، والضحك في وجه البيانات الضخمة ، وإطلاق وظائف الحد من الخريطة ، وبناء نماذج موضوعية على نص غير منظم فوضوي ، واستخراج البيانات المزعجة للأنماط الإحصائية ، واستيعاب كميات ضخمة من البيانات من البيانات المفتوحة المصادر ، ومناقشة القيم p ، وتدريب الشبكات العصبية وشبكات المعتقدات العميقة ، والتبديل بين Python و R ، وتدوير التصورات ، وقذائف البرمجة النصية ، ستحبها هنا!
اترك لنا سطرًا بسيرتك الذاتية في الوظائف. <id> @ embibe.com ، حيث:
<id> هو الرقم المكون من أول 8 أرقام غير صفرية من قيمة دالة كثافة الاحتمال للتوزيع الطبيعي ، مقربًا إلى 19 رقمًا من الدقة ، و
mu هو الرقم 26 في تسلسل Padovan ، و
سيجما هو الرقم 17 في تسلسل فيبوناتشي الذي يبدأ من 1 و
x هو العدد الأولي 1002
يتألف فريقنا من Keyur Faldu ( كبير علماء البيانات) و Achint Thomas ( عالم البيانات الرئيسي) و Chintan Donda ( عالم البيانات).
مراجع
- جرد أسلوب التعلم . لورانس ، كانساس: أنظمة الأسعار.
- جريجورك ايه اف (1982). نموذج أنماط العقل: النظرية والمبادئ والتطبيقات. ماينارد ، ماجستير: أنظمة غابرييل.
أكملت Embibe مؤخرًا 3 سنوات في السوق باعتبارها واحدة من الشركات الرائدة في تحليلات بيانات التعليم. أمضى الطلاب أكثر من 100 ألف ساعة على المنتج في مارس 2016 وحده دون أي استثمار في التسويق المدفوع.