
300 millones de estudiantes, 300 mil millones de conocimientos: enamorados de los datos en la educación
Publicado: 2016-04-07Una mirada interna exclusiva al laboratorio de ciencia de datos de Embibe
[Esta es la segunda parte de la serie Cómo estamos utilizando la tecnología profunda y la ciencia de datos para personalizar la educación]
Construimos Embibe con una visión singular: maximizar los resultados de aprendizaje a escala. Lograr un impacto positivo en el resultado de aprendizaje de un usuario es un problema difícil, pero importante, de resolver. De hecho, hay una serie de subproblemas abiertos no triviales, cada uno de los cuales debe resolverse para lograr el elevado objetivo de afectar de manera intencional y positiva los resultados del aprendizaje.
Pero primero, ¿qué son los resultados del aprendizaje? ¿Y por qué nos preocupamos por ellos?
En el mundo altamente competitivo de hoy, un estudiante se mide en gran medida por cuánto puede obtener en un examen competitivo o incluso en el aula de la escuela. Su puntaje puede tener un impacto significativo en sus opciones de carrera. Para los propósitos de este artículo, enmarquemos los resultados del aprendizaje como una función del potencial innato y entrenable de un estudiante, para aprender, absorber y aplicar el contenido de manera óptima, dentro de limitaciones de tiempo estrictamente especificadas; para que pueda maximizar su puntaje en cualquier contexto académico competitivo en particular.
En países en desarrollo como la India, la proporción de alumnos por maestro es muy desigual y los maestros no pueden brindar una atención personalizada de manera efectiva a nivel individual. Esto lleva a un dilema, dado que cada estudiante aprende y absorbe información a ritmos diferentes y tiene diferentes niveles de aptitud. Un efecto secundario conocido de la incapacidad de los maestros para brindar una atención personalizada es que, para cualquier salón de clases/grupo de estudiantes, el material de aprendizaje siempre se presenta para atender al estudiante "promedio". Por lo tanto, los estudiantes muy brillantes no alcanzan su máximo potencial y no podrán realmente mostrar su músculo académico, mientras que los estudiantes con un nivel académico más bajo tendrán dificultades para lidiar con el resto del salón de clases. Sin embargo, las plataformas y los sistemas de aprendizaje en línea existentes no pueden facilitar verdaderamente el aprendizaje personalizado a nivel de estudiante.
La mayoría de los sistemas actuales solo tienen en cuenta qué tan bien un estudiante puede hacer coincidir sus soluciones con los módulos de prueba según lo especificado por algún administrador del sistema. El aprendizaje personalizado para los exámenes competitivos debería maximizar la puntuación de un estudiante para cualquier objetivo académico en el tiempo limitado que tiene disponible. El aprendizaje personalizado también debe abordar de manera constructiva las brechas de capacidad del estudiante, no solo a nivel de conocimientos o aptitudes, sino también a niveles de actitud y comportamiento. Esta falta de herramientas efectivas para el aprendizaje personalizado, diseñado de manera específica y precisa para cada estudiante, es la responsable de que no pueda desarrollar su potencial para lograr la máxima puntuación posible en un examen determinado.
En este artículo, el equipo de ciencia de datos de embibe sentará las bases de los diversos problemas relacionados con los datos interconectados que deben abordarse para maximizar los resultados del aprendizaje y, específicamente, mejorar la puntuación. Hay dos dimensiones principales en este problema: ingesta de contenido y entrega de contenido. Cada dimensión plantea desafíos únicos en una serie de áreas que seguramente fascinarán a cualquier científico de datos.
Ingestión de contenido
Ingestión automática de contenido
Docenas de tableros de programas, miles de capítulos y conceptos, y decenas de miles de institutos y escuelas dan como resultado cientos de miles de preguntas y respuestas generadas y utilizadas por los instructores cada año. Imagínese si todos los estudiantes pudieran probar su conocimiento antes de los exámenes en cualquier subconjunto, o en todas estas preguntas, además de obtener explicaciones detalladas sobre las respuestas correctas y los errores comunes cometidos. Para hacer esto realidad, estamos aprovechando el reconocimiento óptico de caracteres (OCR) y el aprendizaje automático para construir nuestro propio marco de ingesta automatizado que será altamente escalable, verdaderamente multilingüe y mínimamente dependiente de la intervención humana. Y la diversión no se detiene allí. El marco también podrá ingerir contenido escrito a mano de una manera independiente del escritor, lo que lo agregará rápidamente a nuestro ya fantástico repositorio de preguntas, respuestas, conceptos, explicaciones y conocimiento.
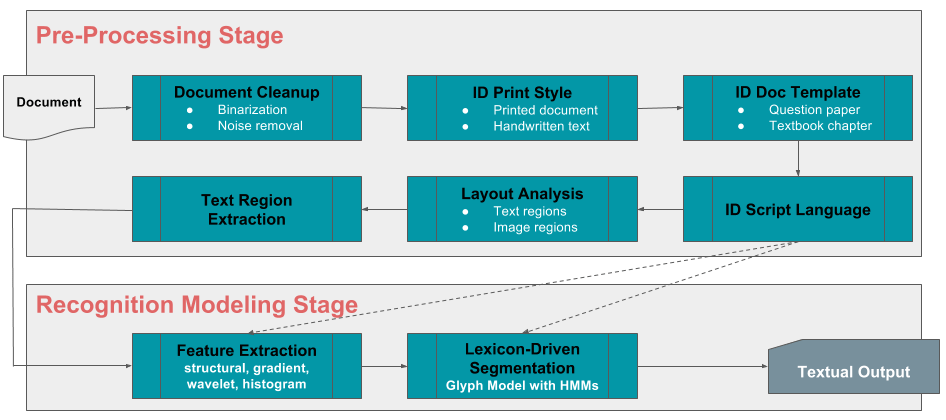
Etiquetado de conceptos
Muy bien, ahora tenemos preguntas, respuestas, conceptos y capítulos, todos ingeridos en un almacén de datos masivo. Sería doloroso etiquetar manualmente cada pregunta o capítulo con sus conceptos relevantes, o viceversa. ¡Ciencia de datos al rescate! Usando ideas de vanguardia de clasificación de texto, modelado de temas y aprendizaje profundo, automáticamente etiquetamos conceptos en preguntas, respuestas y capítulos.

Una selección de los conceptos más populares explorados por los usuarios de Embibe utilizando la función Aprender, en los meses de diciembre de 2015, enero de 2016 y febrero de 2016.
Nuestras bases de datos anteriores que contienen conjuntos de semillas de contenido etiquetado manualmente de alta calidad son fundamentales a medida que extraemos características lingüísticas, léxicas y sensibles al contexto, para entrenar modelos de etiquetado de texto de última generación para todos los datos nuevos que se incorporan en nuestro sistemas
Enriquecimiento de metadatos
Hay una gran cantidad de información disponible en línea hoy en día sobre cualquier tema que uno desee aprender. Las ideas y los conceptos se construyen unos sobre otros. Por ejemplo, la Primera Ley de la Termodinámica se relaciona con el concepto de sistema termodinámico, que a su vez se relaciona con los conceptos de capacidades caloríficas específicas de los gases, conservación de la energía mecánica y trabajo realizado por un gas, entre otros. Nuestro marco de ingestión de contenido incluye componentes de enriquecimiento de datos que rastrean automáticamente la web y etiquetan el contenido con elementos multimedia tan diversos como explicaciones de texto, enlaces de video, definiciones, comentarios de usuarios y debates en foros, todo ello respetando los derechos de autor y atribuyendo correctamente la propiedad del contenido de origen. . Esta gran cantidad de información disponible también hace posible conectar automáticamente conceptos relacionados en una estructura de árbol. Utilizando ideas de los campos de la teoría de grafos, la minería de texto y la propagación de etiquetas en estructuras dispersas, creamos vínculos e interconexiones entre conceptos que comparten una relación fuente→objetivo.
Construcción automatizada de un árbol de conceptos, para un subconjunto de ideas de Matemáticas, cada una conectada a uno o varios conceptos relacionados
Agrupación de preguntas similares
Si te estuvieras preparando para un examen, ¿te gustaría practicar la misma pregunta una y otra vez? Eso no sería útil. Por el contrario, imagina cuán inmensamente útil sería practicar un pequeño conjunto de preguntas relevantes que te ayudarán a dominar por completo algún concepto o capítulo nuevo. Con nuestro acceso a cientos de miles de preguntas, hemos desarrollado la capacidad de agrupar preguntas en función de la similitud en una serie de dimensiones: contenido específico, concepto probado, nivel de dificultad y objetivos del examen, entre otros.
La agrupación de texto basada en espacios de información semántica latente y su combinación con otros espacios de características numéricas y categóricas nos permite agrupar con precisión nuestro universo de preguntas en áreas de interés que se pueden adaptar para cada individuo usando Embibe. Además, este rico recurso de datos textuales que hemos transformado en sólidos espacios de características numéricas relacionados con grupos de conceptos nos permite perturbar ligeramente los datos existentes para generar expresiones potencialmente infinitas del espacio de preguntas. ¡Más preguntas en tiempo de ejecución, nunca antes vistas! Esto nos permite dar a los usuarios el máximo valor por el tiempo que pasan en nuestra plataforma.
Entrega de contenido
perfil de usuario
Hacemos un seguimiento de cada movimiento que hace un usuario en Embibe. Los millones de intentos de práctica y prueba realizados por nuestros usuarios durante los últimos tres años están calibrados en un espacio de datos de muchos miles de dimensiones. Esto se traduce en un espacio de miles de millones de puntos de datos que podemos extraer para profundizar en los datos de comportamiento de nuestros usuarios y generar información que se correlacione con la forma en que ocurre el aprendizaje. Cada intento adicional de un usuario modifica su capacidad para obtener una puntuación más alta en los conceptos etiquetados en ese intento, junto con los conceptos anteriores y posteriores conectados. Este problema supercomplejo implica aprovechar las ideas del procesamiento de matrices dispersas, los algoritmos computacionales en la teoría de gráficos y la teoría de respuesta de elementos para crear perfiles de usuario robustos y adaptables que se adapten a nuestra creciente base de usuarios.
Recomendado para ti:

¿Qué significa la disposición contra la especulación para las nuevas empresas indias?

Cómo las empresas emergentes de Edtech están ayudando a la fuerza laboral de la India a mejorar y prepararse para el futuro...

Acciones tecnológicas de la nueva era esta semana: los problemas de Zomato continúan, EaseMyTrip publica...

Startups indias toman atajos en busca de financiación

La plataforma de marketing digital Logicserve obtiene fondos de INR 80 Cr, cambia de marca como LS Dig...

Informe advierte sobre un escrutinio regulatorio renovado en Lendingtech Space
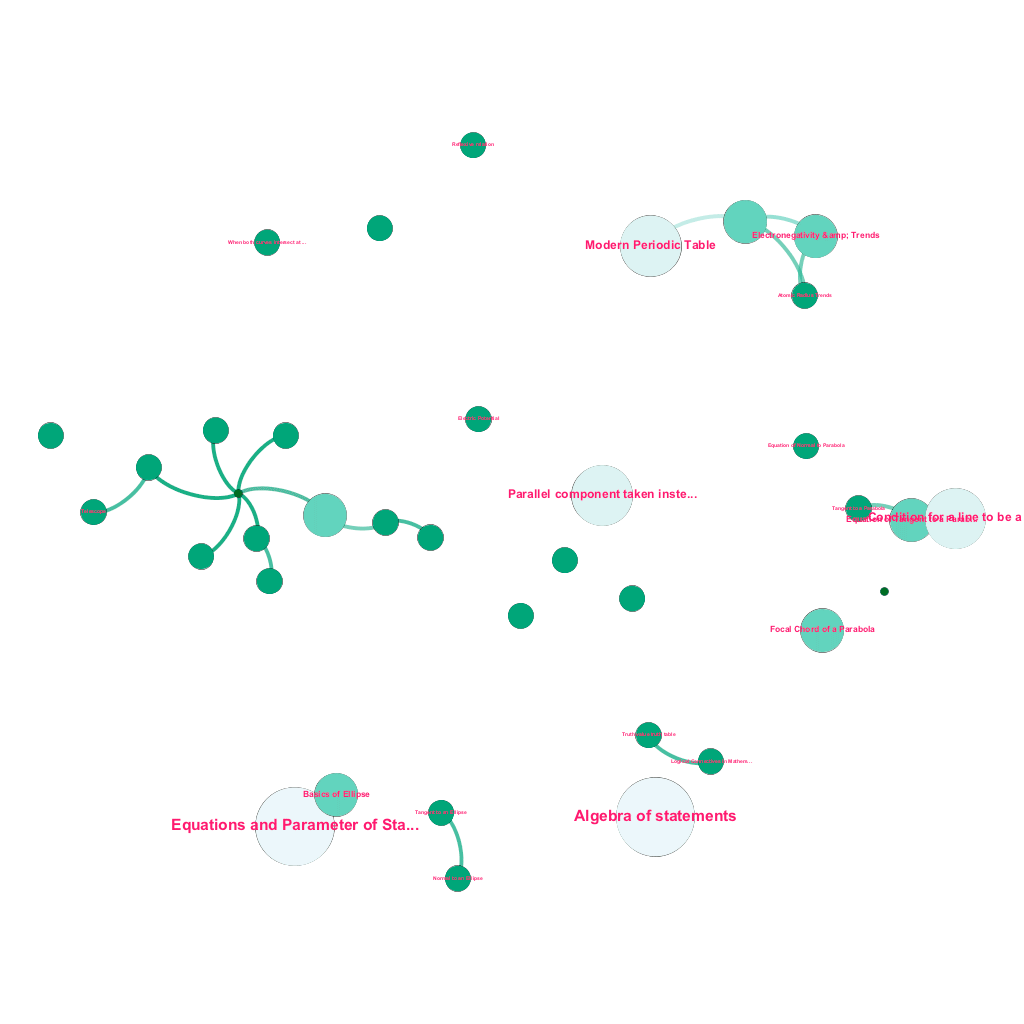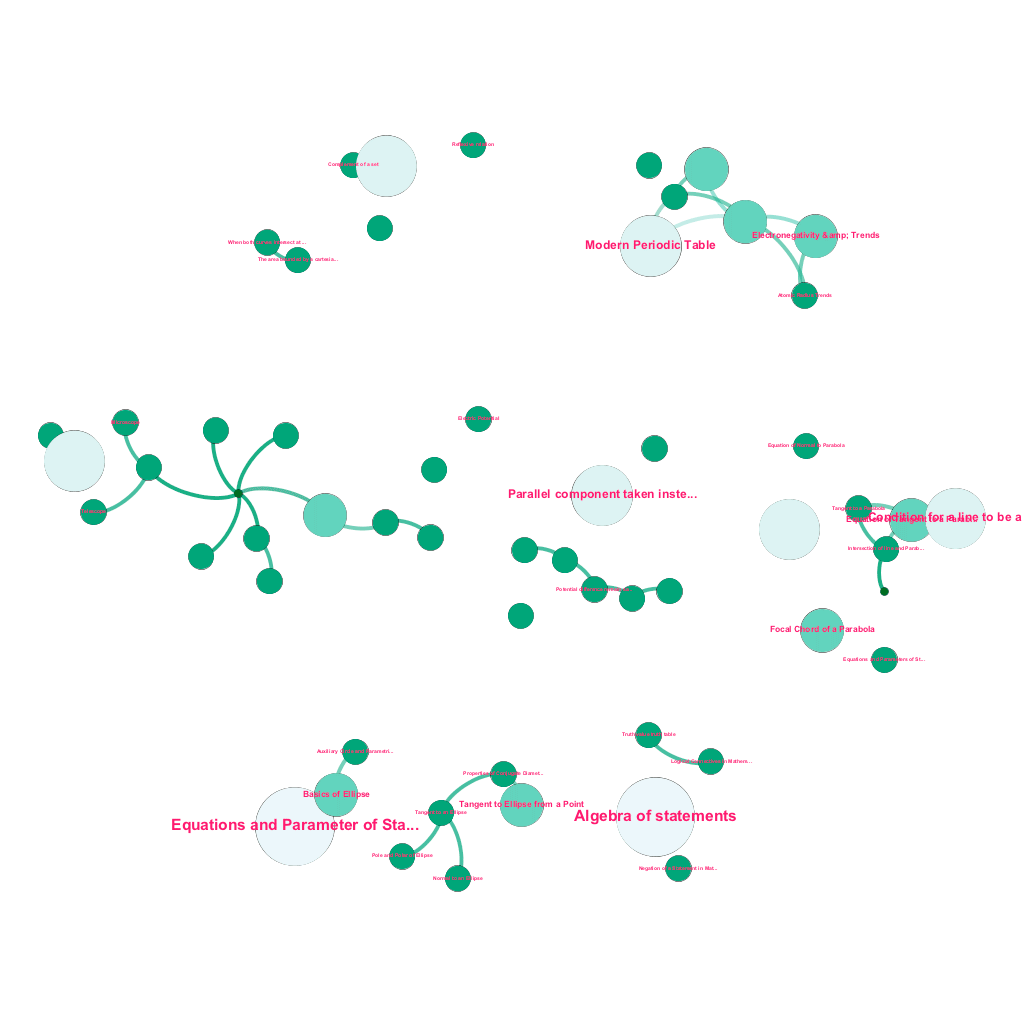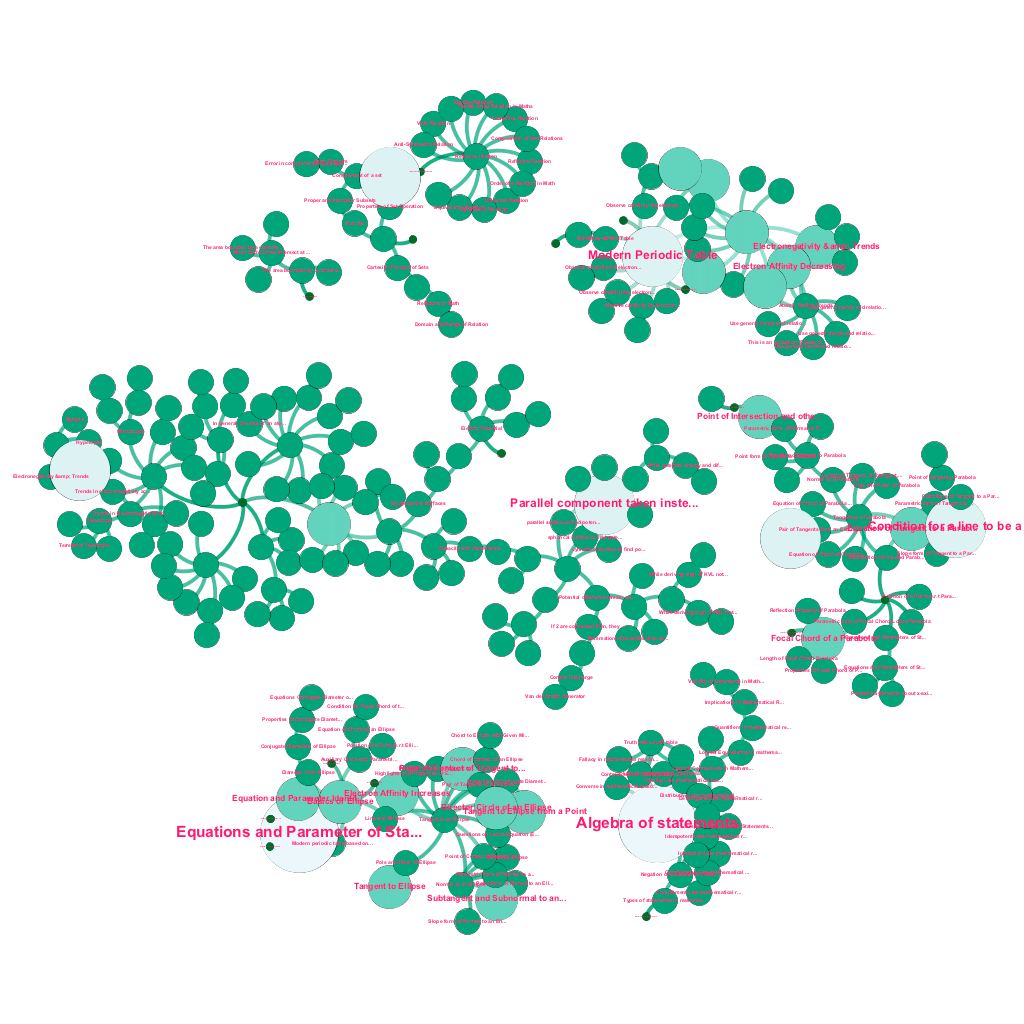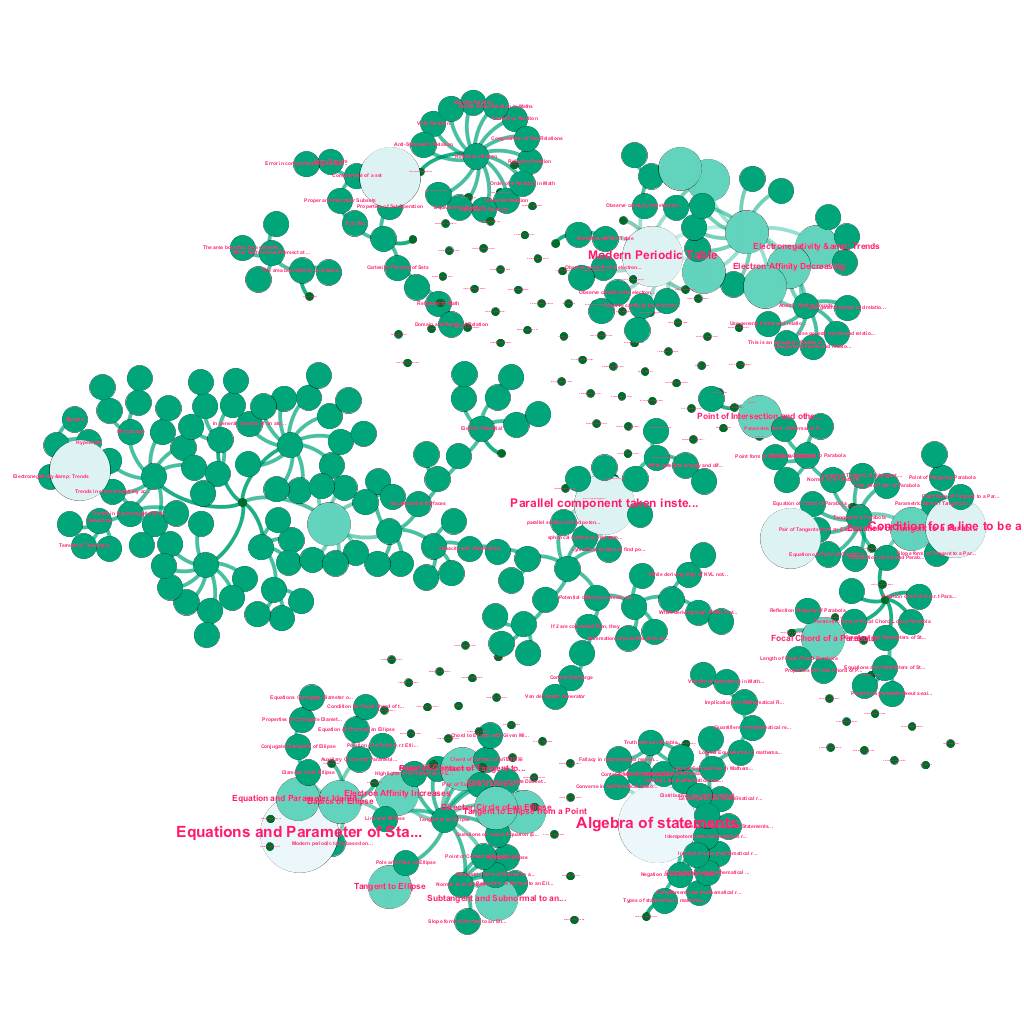
Un gráfico de barras interesante que muestra la hora (hora del día en IST) en la que los usuarios comienzan sus sesiones de prueba en Embibe. Los usuarios médicos (AIPMT) tienen un pico definido alrededor de las 10 a. m. y entre las 3 p. m. y las 5 p. m. Los usuarios de ingeniería (JEE), por otro lado, muestran un aumento gradual de los tiempos de inicio de sesión a medida que avanza el día, que alcanza su punto máximo entre las 4 p. m. y las 8 p. m. Los estudiantes de JEE también comienzan constantemente más sesiones de práctica entre las 5 p. m. y las 3 a. m. en comparación con los estudiantes de AIPMT. ¡Suponemos que los médicos son más disciplinados!

Nuestra amplia instrumentación y medición de la actividad del usuario a un nivel muy granular nos brinda la capacidad de inferir preferencias latentes relacionadas con los estilos de aprendizaje asociados con usuarios individuales. Por ejemplo, ciertos estudiantes pueden aprender, y luego rendir en las pruebas, mejor con la ayuda de explicaciones en video, en comparación con otros estudiantes que prefieren descripciones textuales extensas, o incluso otros que aprenden trabajando paso a paso a través de problemas de ejemplo resueltos. Podemos asignar usuarios a modelos teóricos bien estudiados de estilos de aprendizaje como el modelo de Dunn y Dunn (Dunn & Dunn 1989), o el modelo de estilos mentales de Gregorc (Gregorc 1982) para adaptar automáticamente cursos de práctica de recuperación y ayudar al usuario a mejorar la puntuación.
Cohortes de usuarios
La formación de cohortes es un problema clásico de agrupamiento. Los usuarios se agrupan según sus patrones de uso con respecto a las funciones del producto, así como sus patrones de rendimiento con respecto a las sesiones de prueba, práctica y revisión. Cada usuario está asignado a un espacio de características de alta dimensión de muchos miles de atributos, que incluyen medidas tanto estáticas como temporales. La cohorte de medidas temporales nos brinda la capacidad de iniciar en frío la baja actividad y los nuevos usuarios mediante la asignación de trayectorias de cohorte probables a estos usuarios en función de su actividad inicial. La agrupación de usuarios es un requisito fundamental para nuestras características de ciencia profunda de nivel superior, como el aprendizaje microadaptativo, la generación de comentarios automatizada y la recomendación de contenido.
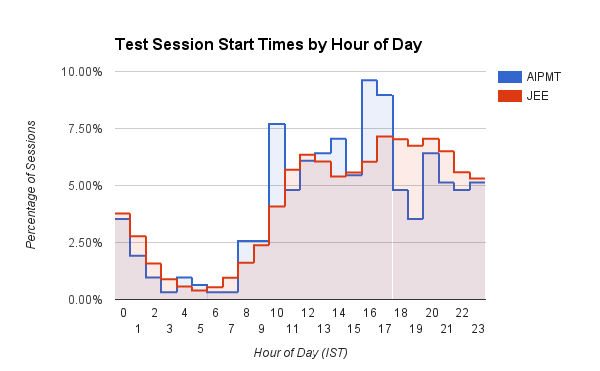
Una posible vista de las cohortes de usuarios: vinculada al rendimiento de la prueba a largo plazo. Según sus puntajes generales en las pruebas, los Triunfadores son el grupo de percentil superior de usuarios en Embibe, los Intérpretes el siguiente grupo y los Luchadores el grupo final. Las diversas facetas que se muestran se relacionan con diferentes aspectos de la mejora de la puntuación en los que hemos agrupado nuestro espacio de funciones. Por ejemplo, podemos ver que aunque Facet_A varía significativamente entre las cohortes, al dirigir la retroalimentación a otras facetas de aprendizaje y afectarlas, es posible empujar a los usuarios a la siguiente cohorte más alta.
Aprendizaje microadaptativo
La entrega de contenido y retroalimentación del tamaño de un bocado es clave para un aprendizaje en línea efectivo. Generalmente, los usuarios pasan entre 30 minutos y una hora en línea, practicando conceptos y preguntas. Dentro de este breve lapso de tiempo, es muy importante maximizar el impacto de cada sesión con límite de tiempo. Cada sesión es una ventaja para que el usuario maximice el aprendizaje, y esto se logra mejor con la estrategia del tamaño de un bocado. Nuestro motor de microadaptación para sesiones de práctica toma el perfil de un usuario y los atributos de la cohorte junto con nuestro árbol de conocimiento de 11,000 (¡y creciendo!) Metaatributos de conceptos interrelacionados como entrada, y asegura que la secuencia de preguntas, las sugerencias proporcionadas y simplemente- La retroalimentación en línea inteligente a tiempo se adapta con precisión al usuario para mejorar su resultado de aprendizaje en cualquier objetivo pequeño. Cada consumo de contenido o retroalimentación del tamaño de un bocado afectará la calibración de la competencia del usuario en comparación con nuestro extenso árbol de conocimientos de conceptos. Las técnicas de procesamiento de matrices dispersas, la teoría de respuesta al ítem y los algoritmos gráficos guían la microadaptabilidad del aprendizaje.
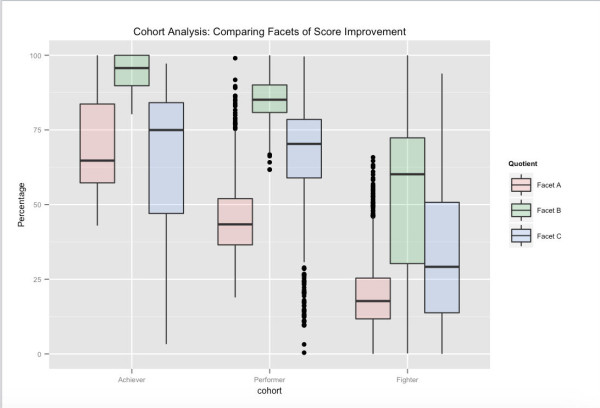
Es bastante obvio que la práctica hace que uno sea perfecto, pero decidimos hacer los números de todos modos. La figura anterior muestra la mejora de la puntuación media de los usuarios, para las sucesivas pruebas realizadas por los usuarios que dedican tiempo a nuestras sesiones de práctica adaptativa y los que no. Los usuarios que practican en Embibe constantemente superan a los que no lo hacen en casi un 10% de prueba en prueba.
Sistema de comentarios y recomendaciones.
El sistema de comentarios y recomendaciones de Embibe (sobre el cual ya hemos presentado patentes) está diseñado y creado con un propósito: maximizar la mejora de la puntuación de un usuario. Instrumentamos e interpretamos miles de señales sobre los intentos de un usuario durante las sesiones de práctica y prueba, y transformamos estas señales en un espacio de gran dimensión con miles de funciones para cada usuario. Usando la minería de patrones estadísticos en nuestro espacio masivo de características de intentos de usuario, nos hemos centrado en los conjuntos de parámetros clasificados que aumentan positivamente la puntuación de un usuario. Estos parámetros están codificados por máquina como cápsulas altamente específicas justo a tiempo de retroalimentación de mejora de puntaje, y se entregan al usuario mientras continúa con su sesión de práctica. Los comentarios y las recomendaciones exponen las debilidades y las estrategias que puede adoptar para maximizar su puntaje.
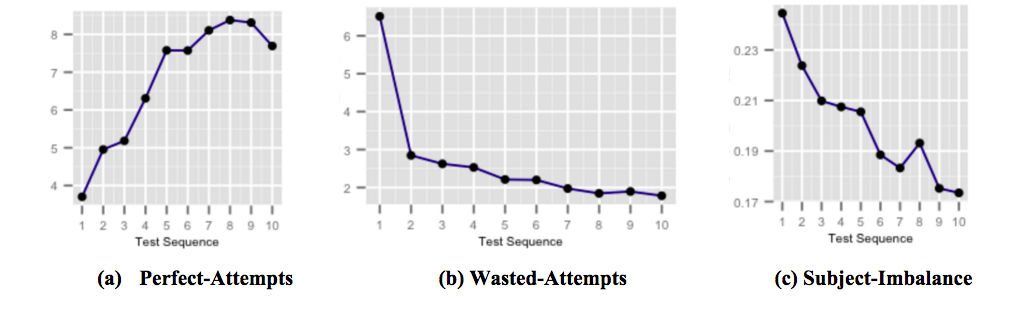
Las cifras anteriores muestran cómo nuestras cápsulas de retroalimentación altamente específicas justo a tiempo para mejorar el puntaje afectan el desempeño de los estudiantes a medida que el usuario está expuesto y se da cuenta de las trampas comunes para tomar exámenes. La figura (a) muestra el número promedio de intentos perfectos que aumentan en las pruebas sucesivas. Los intentos perfectos son intentos que se responden correctamente dentro de un tiempo estipulado. La figura (b) muestra la disminución del número promedio de intentos perdidos en pruebas sucesivas. Los intentos desperdiciados son intentos que se responden incorrectamente cuando el alumno tuvo más tiempo del que podría haber dedicado a pensar en la pregunta. Y la figura (c) muestra la disminución del desequilibrio de precisión sujeto promedio en pruebas sucesivas. El desequilibrio de precisión del sujeto se define como la diferencia entre las precisiones más alta y más baja entre todos los sujetos en cualquier prueba realizada por un usuario. Un mayor desequilibrio entre sujeto y precisión implica que el usuario está menos preparado para ciertos temas en comparación con otros.
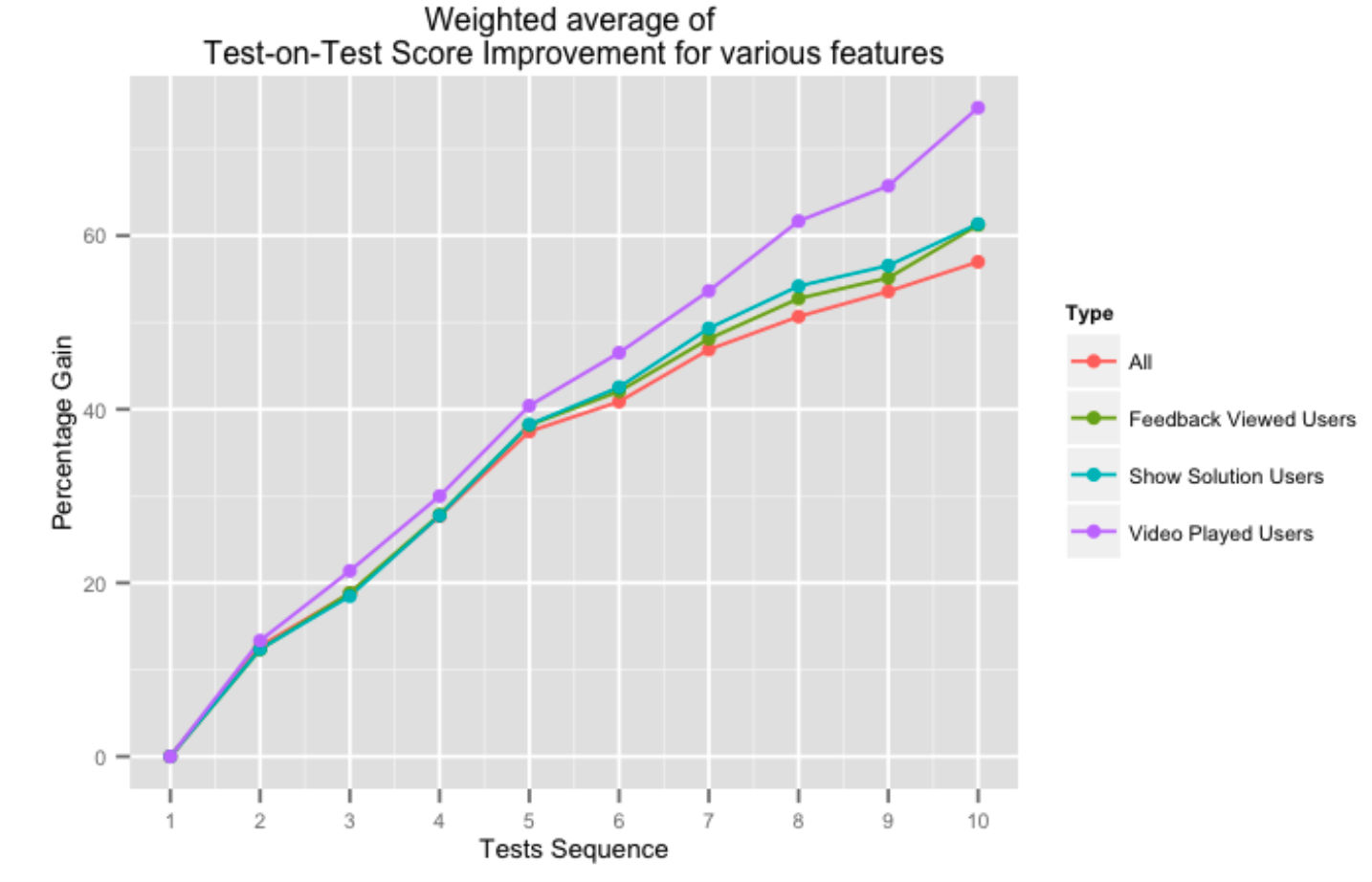
La figura anterior muestra el porcentaje de ganancia en puntajes sucesivos de prueba en prueba para usuarios que utilizan varios aspectos de nuestro sistema de comentarios. Tomar la ayuda de nuestra plataforma en forma de soluciones de video o comentarios generales de las pruebas tiene un impacto positivo en los puntajes de las pruebas, especialmente a medida que el usuario completa más pruebas.
Estimación de la mejora de la puntuación
Para los usuarios que se preparan para exámenes de cualquier tipo, la mejora de la puntuación es el aspecto más importante que influye en los resultados del aprendizaje. Nuestra gran cantidad de datos de comportamiento nos brinda la capacidad de aprender de las acciones pasadas de los usuarios, al medir cómo su comportamiento durante y después de realizar las pruebas en Embibe afecta la mejora de la puntuación. La extracción de datos para patrones estadísticos en el uso, la actividad y las características de comportamiento, entre varias cohortes de usuarios, nos brinda una prueba respaldada por la ciencia de la efectividad de nuestra plataforma.
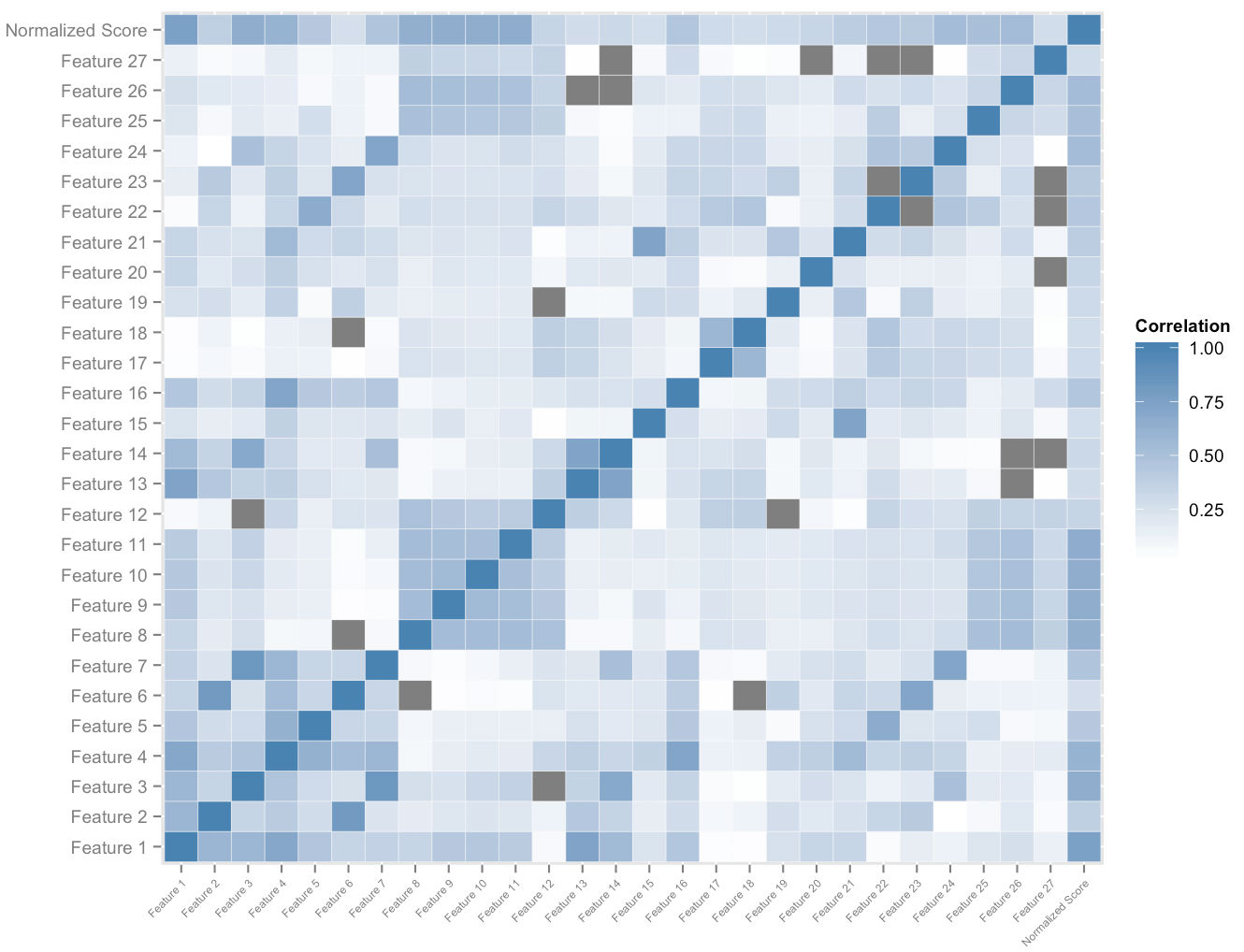
La figura anterior muestra un subconjunto del espacio de características que construimos por usuario. El análisis de correlación cruzada en el espacio de características y las puntuaciones normalizadas generales nos da un orden sobre la importancia relativa de las características. Esto, junto con el análisis de dominancia empírica, nos permite medir la cantidad de impacto de cada característica en su contribución a la mejora de la puntuación. Una combinación adecuadamente ponderada de las velocidades de las más importantes de estas características nos permite asignar cuantitativamente una medida de mejora potencial de puntaje a cada estudiante, que se adapta a ella a medida que usa la plataforma.
Estos son tiempos emocionantes para el campo de la educación, especialmente en India y otros países en desarrollo. Existe una necesidad urgente de aplicar ciencia profunda, con un fuerte enfoque en el uso de datos y los conocimientos que pueden proporcionar, para llevar la educación y el aprendizaje al siguiente nivel. Nuestras plataformas de ingestión y entrega de contenido se están construyendo sobre principios científicos sólidos y están ayudando a los usuarios a obtener un valor inmenso en Embibe en forma de mejora de puntaje dentro de períodos de tiempo de preparación limitados. Nuestro marco de aprendizaje microadaptativo que utiliza comentarios y recomendaciones específicos del usuario, adaptados precisamente a los usuarios, en función de sus clasificaciones de cohortes y características de comportamiento, permite a los usuarios tener una experiencia satisfactoria en Embibe. Estos son los primeros pasos concretos para resolver el problema de tener un impacto positivo en los resultados del aprendizaje. Esto es aprendizaje personalizado.
En esta publicación, abordamos varios subproblemas que deben resolverse para avanzar en el camino hacia los resultados de aprendizaje. En nuestra próxima publicación, hablaremos sobre cómo medimos y rastreamos varias métricas en Embibe que están relacionadas con nuestros usuarios y su actividad, para que podamos estar al tanto de nuestro producto, su crecimiento y su efectividad como un destino de aprendizaje en línea.
Siempre estamos buscando personas malvadas e inteligentes para agregar a nuestras filas en el Laboratorio de ciencia de datos. Si le gusta probar hipótesis, ejecutar regresiones, factorizar matrices enormes, reírse frente a los grandes datos, ejecutar trabajos de reducción de mapas, crear modelos de temas sobre texto desordenado no estructurado, extraer datos ruidosos para patrones estadísticos, ingerir montañas de datos de datos abiertos fuentes, discutiendo valores p, entrenando redes neuronales y redes de creencias profundas, cambiando entre python y R, acelerando visualizaciones y scripting shells, ¡te encantará aquí!
Envíenos un mensaje con su currículum a jobs.<id>@embibe.com, donde:
<id> es el número formado con los primeros 8 dígitos distintos de cero del valor de la función de densidad de probabilidad para la distribución normal, redondeado a 19 dígitos de precisión, y
mu es el número 26 en la secuencia de Padovan, y
sigma es el número 17 en la secuencia de Fibonacci que comienza en 1, y
x es el número primo número 1002
Nuestro equipo está formado por Keyur Faldu ( Científico de datos en jefe), Achint Thomas ( Científico de datos principal) y Chintan Donda ( Científico de datos).
Referencias
- Inventario de estilos de aprendizaje . Lawrence, KS: Sistemas de Precios.
- Gregorc AF, (1982). Modelo de estilos mentales: teoría, principios y aplicaciones. Maynard, MA: Sistemas Gabriel.
Embibe ha completado recientemente 3 años en el mercado como una de las principales empresas en análisis de datos educativos. Los estudiantes han pasado más de 100 000 horas en el producto solo en marzo de 2016 sin ninguna inversión en marketing de pago.