
300 Juta Siswa, 300 Miliar Wawasan – Jatuh Cinta dengan Data dalam Pendidikan
Diterbitkan: 2016-04-07Tampilan Dalam Eksklusif Di Lab Ilmu Data Embibe
[Ini adalah bagian kedua dari seri Bagaimana Kami Menggunakan Teknologi Dalam dan Ilmu Data untuk Mempersonalisasi Pendidikan]
Kami membangun Embibe dengan visi tunggal: untuk memaksimalkan hasil pembelajaran dalam skala besar. Membuat dampak positif pada hasil belajar pengguna adalah masalah yang sulit, tetapi penting, untuk dipecahkan. Faktanya, ada sejumlah sub-masalah terbuka non-sepele, yang masing-masing perlu dipecahkan untuk mewujudkan tujuan mulia yang secara sengaja dan positif mempengaruhi hasil belajar.
Tapi pertama-tama, apa itu hasil belajar? Dan mengapa kita peduli dengan mereka?
Dalam dunia yang sangat kompetitif saat ini, seorang siswa sebagian besar diukur dengan seberapa banyak dia dapat mencetak gol dalam ujian kompetitif atau bahkan kelas sekolah. Skornya dapat memiliki dampak yang signifikan pada pilihan karirnya. Untuk tujuan artikel ini, mari kita membingkai hasil belajar sebagai fungsi dari potensi bawaan siswa dan juga yang dapat dilatih, untuk mempelajari, menyerap, dan menerapkan materi konten secara optimal, dalam batasan waktu yang ditentukan secara ketat; sehingga dia dapat memaksimalkan nilainya dalam konteks akademik kompetitif tertentu.
Di negara berkembang seperti India, rasio siswa-guru sangat miring dan guru tidak dapat secara efektif memberikan perhatian yang dipersonalisasi pada tingkat individu. Hal ini menyebabkan dilema, mengingat bahwa setiap siswa belajar dan menyerap informasi dengan kecepatan yang berbeda dan memiliki tingkat bakat yang berbeda. Efek samping yang diketahui dari ketidakmampuan guru untuk memberikan perhatian yang dipersonalisasi adalah bahwa untuk setiap kelas/kumpulan siswa tertentu, materi pembelajaran selalu disajikan untuk memenuhi siswa "rata-rata". Oleh karena itu, siswa yang sangat cerdas tidak mencapai potensi penuh mereka dan tidak akan dapat benar-benar melenturkan otot akademik mereka, sementara siswa yang lebih lemah secara skolastik akan mengalami kesulitan mengatasi sisa kelas. Namun, platform dan sistem pembelajaran online yang ada tidak dapat benar-benar memfasilitasi pembelajaran yang dipersonalisasi di tingkat siswa.
Sebagian besar sistem saat ini hanya menjelaskan seberapa baik siswa dapat mencocokkan solusi mereka dengan modul uji seperti yang ditentukan oleh beberapa administrator sistem. Pembelajaran yang dipersonalisasi untuk ujian kompetitif harus memaksimalkan nilai siswa untuk target akademik apa pun dalam waktu terbatas yang tersedia baginya. Pembelajaran yang dipersonalisasi juga harus secara konstruktif mengatasi kesenjangan kemampuan siswa tidak hanya pada tingkat pengetahuan atau bakat, tetapi juga pada tingkat sikap dan perilaku. Kurangnya alat yang efektif untuk pembelajaran yang dipersonalisasi, yang dirancang secara khusus dan tepat untuk setiap siswa, bertanggung jawab atas ketidakmampuannya untuk menyadari potensinya dalam mencapai nilai maksimal dalam ujian apa pun.
Dalam artikel ini, tim ilmu data embibe akan meletakkan dasar dari berbagai masalah terkait data yang saling berhubungan yang perlu ditangani untuk memaksimalkan hasil pembelajaran, dan khususnya, peningkatan skor. Ada dua dimensi utama untuk masalah ini – Penyerapan Konten dan Pengiriman Konten. Setiap dimensi menghadirkan tantangan unik di sejumlah bidang yang pasti akan memukau ilmuwan data mana pun.
Penyerapan Konten
Penyerapan konten secara otomatis
Puluhan papan silabus, ribuan bab dan konsep, dan puluhan ribu institut dan sekolah menghasilkan ratusan ribu pertanyaan dan jawaban yang dihasilkan dan digunakan oleh instruktur setiap tahun. Bayangkan jika setiap siswa dapat menguji pengetahuan mereka sebelum ujian pada setiap subset, atau semua pertanyaan ini, bersama dengan mendapatkan penjelasan terperinci tentang jawaban yang benar, dan kesalahan umum yang dibuat. Untuk mewujudkannya, kami memanfaatkan pengenalan karakter optik (OCR) dan pembelajaran mesin untuk membangun kerangka kerja penyerapan otomatis kami sendiri yang akan sangat skalabel, benar-benar multibahasa, dan minimal bergantung pada masukan manusia. Dan kesenangan tidak berhenti di situ. Kerangka kerja ini juga akan dapat menyerap konten tulisan tangan dengan cara penulis-agnostik, sehingga dengan cepat menambah gudang pertanyaan, jawaban, konsep, penjelasan, dan pengetahuan kami yang sudah fantastis.
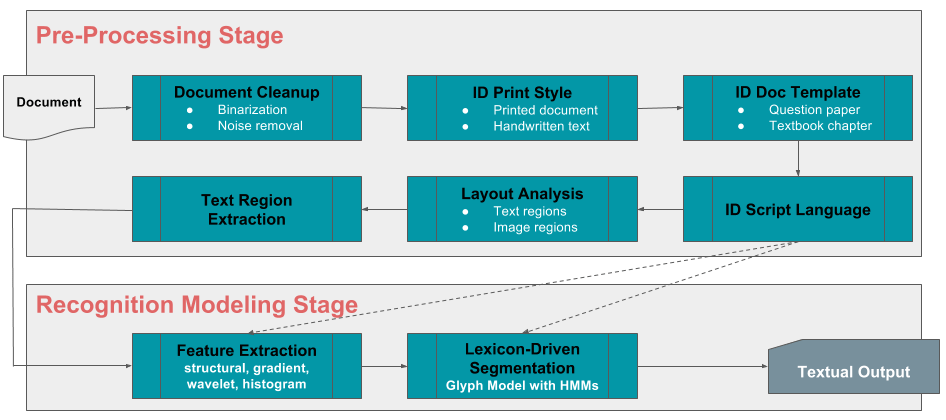
Penandaan konsep
Baiklah, jadi sekarang kita memiliki pertanyaan, jawaban, konsep, dan bab yang semuanya diserap ke dalam gudang data yang sangat besar. Akan menyakitkan untuk secara manual menandai setiap pertanyaan atau bab dengan konsep yang relevan, atau sebaliknya. Ilmu Data untuk menyelamatkan! Menggunakan ide-ide mutakhir dari klasifikasi teks, pemodelan topik, dan pembelajaran mendalam, kami secara otomatis menandai konsep ke pertanyaan, jawaban, dan bab.

Pilihan konsep paling populer yang dijelajahi oleh pengguna Embibe menggunakan fitur Belajar, pada bulan Desember 2015, Januari 2016, dan Februari 2016.
Basis data kami sebelumnya yang berisi kumpulan benih konten yang diberi tag secara manual berkualitas tinggi sangat penting saat kami mengekstrak fitur linguistik, leksikal, dan peka konteks, untuk melatih model pemberian tag teks canggih untuk semua data baru yang diserap ke dalam sistem.
Pengayaan metadata
Ada banyak informasi yang tersedia secara online hari ini tentang topik apa pun yang ingin dipelajari. Ide dan konsep dibangun satu sama lain. Misalnya, Hukum Pertama Termodinamika terkait dengan konsep sistem termodinamika, yang pada gilirannya terkait dengan konsep kapasitas panas spesifik gas, kekekalan energi mekanik, dan kerja yang dilakukan oleh gas, antara lain. Kerangka penyerapan konten kami mencakup komponen pengayaan data yang secara otomatis merayapi web dan menandai konten dengan beragam media seperti penjelasan teks, tautan video, definisi, komentar pengguna, dan diskusi forum, semuanya dengan tetap menghormati hak cipta, dan mengaitkan kepemilikan dengan benar pada konten yang bersumber . Kekayaan informasi yang tersedia ini juga memungkinkan untuk secara otomatis menghubungkan konsep-konsep terkait dalam struktur pohon. Menggunakan ide-ide dari bidang teori grafik, penambangan teks, dan propagasi label pada struktur yang jarang, kami membuat tautan dan interkoneksi antara konsep yang berbagi hubungan sumber→target.
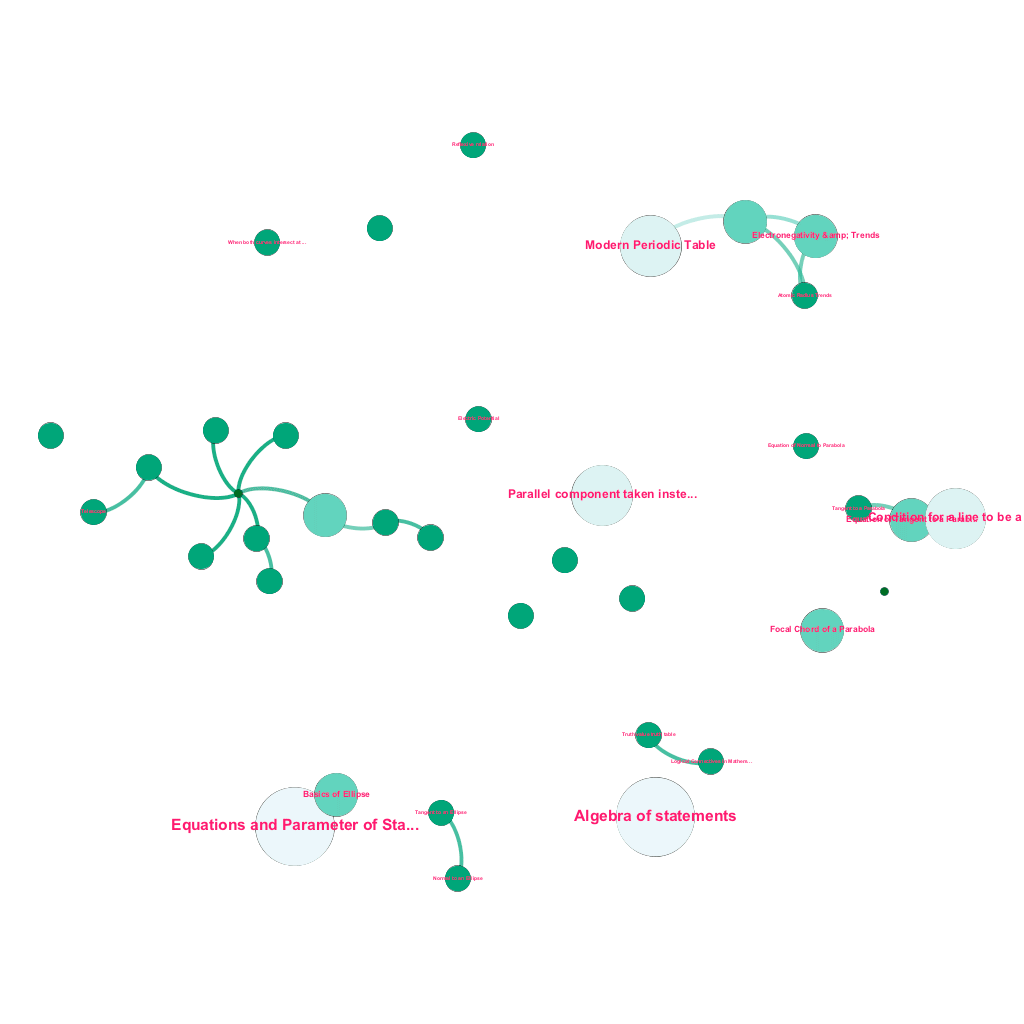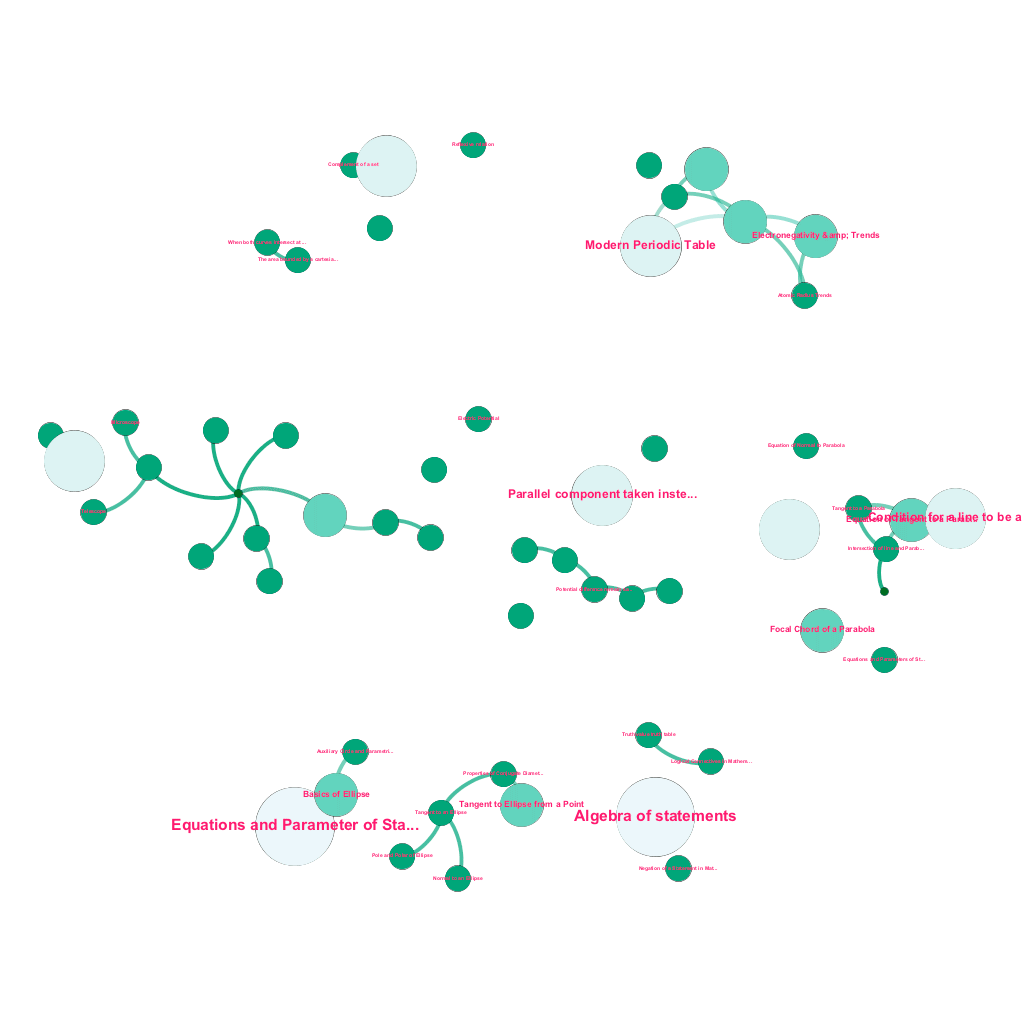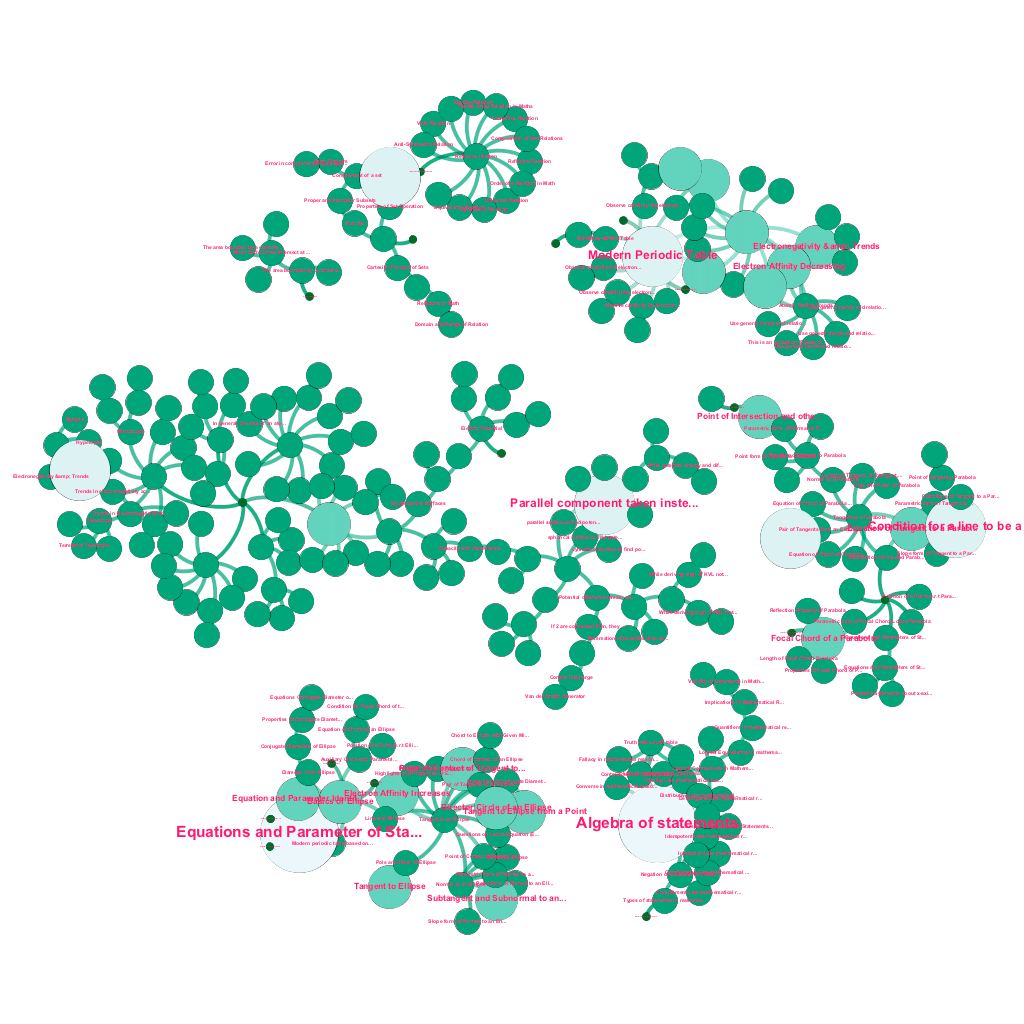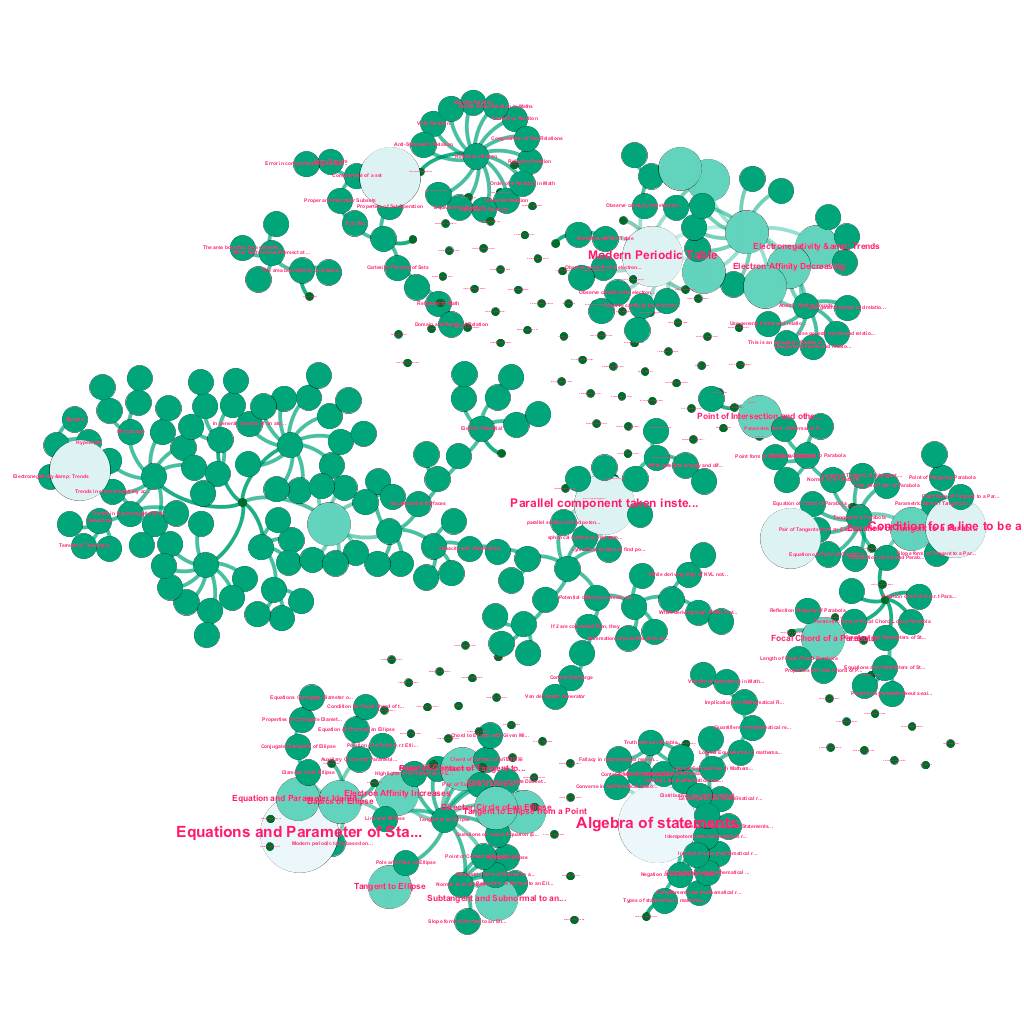
Pembuatan pohon konsep secara otomatis, untuk subset ide dari Matematika, masing-masing terhubung ke satu atau banyak konsep terkait
Pengelompokan pertanyaan serupa
Jika Anda sedang mempersiapkan ujian, apakah Anda ingin berlatih pertanyaan yang sama berulang-ulang? Itu tidak akan membantu. Sebaliknya, bayangkan betapa bermanfaatnya mempraktekkan serangkaian kecil pertanyaan relevan yang akan membantu Anda menguasai konsep atau bab baru sepenuhnya. Dengan akses kami ke ratusan ribu pertanyaan, kami telah mengembangkan kemampuan untuk mengelompokkan pertanyaan berdasarkan kesamaan di sejumlah dimensi – antara lain bertarget konten, uji konsep, tingkat kesulitan, dan tujuan ujian.
Pengelompokan teks berdasarkan ruang informasi semantik laten, dan kombinasinya dengan ruang fitur kategoris dan numerik lainnya memungkinkan kita untuk secara tepat mengelompokkan semesta pertanyaan kita ke dalam bidang minat yang dapat disesuaikan untuk setiap individu menggunakan Embibe. Selain itu, sumber data tekstual yang kaya ini yang telah kami ubah menjadi ruang fitur numerik yang kuat yang terkait dengan kluster konsep memungkinkan kami sedikit mengganggu data yang ada untuk menghasilkan ekspresi ruang pertanyaan yang berpotensi tak terbatas. Lebih banyak pertanyaan saat dijalankan, belum pernah terlihat sebelumnya! Ini memungkinkan kami untuk memberi pengguna nilai maksimum untuk waktu yang mereka habiskan di platform kami.
Pengiriman Konten
Profil pengguna
Kami melacak setiap gerakan yang dilakukan pengguna di Embibe. Jutaan percobaan dan percobaan yang dilakukan oleh pengguna kami selama tiga tahun terakhir dikalibrasi dalam ruang data dengan ribuan dimensi. Ini berarti ruang miliaran titik data yang dapat kami tambang untuk menggali lebih dalam ke data perilaku pengguna kami dan menghasilkan wawasan yang berkorelasi dengan bagaimana pembelajaran terjadi. Setiap upaya tambahan oleh pengguna, mengubah kemampuannya untuk mendapatkan skor lebih tinggi pada konsep yang ditandai pada upaya itu, bersama dengan konsep sebelumnya dan selanjutnya yang terhubung. Masalah super kompleks ini melibatkan pemanfaatan ide dari pemrosesan matriks yang jarang, algoritma komputasi dalam teori grafik, dan teori respons item untuk membangun profil pengguna yang kuat dan adaptif yang berskala dengan basis pengguna kami yang terus bertambah.
Direkomendasikan untukmu:

Apa Arti Ketentuan Anti-Profiteering Bagi Startup India?

Bagaimana Startup Edtech Membantu Tenaga Kerja India Meningkatkan Keterampilan & Menjadi Siap Masa Depan...

Saham Teknologi Zaman Baru Minggu Ini: Masalah Zomato Berlanjut, EaseMyTrip Posting Stro...

Startup India Mengambil Jalan Pintas Dalam Mengejar Pendanaan

Platform Pemasaran Digital Logicserve Bags Pendanaan INR 80 Cr, Berganti Nama Sebagai LS Dig...

Laporan Memperingatkan Pengawasan Peraturan yang Diperbarui Pada Lendingtech Space
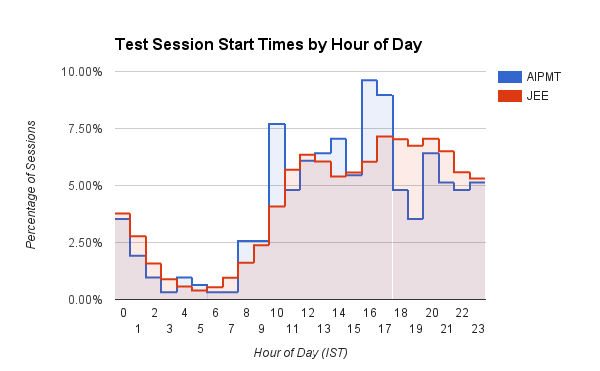
Grafik batang menarik yang menunjukkan waktu (jam dalam sehari di IST) saat pengguna memulai sesi pengujian mereka di Embibe. Pengguna medis (AIPMT) memiliki lonjakan yang pasti sekitar jam 10 pagi dan antara jam 3 sore sampai jam 5 sore. Pengguna Engineering (JEE), di sisi lain, menunjukkan waktu mulai sesi yang meningkat secara bertahap seiring berjalannya hari, yang mencapai puncaknya sekitar jam 4 sore hingga 8 malam. Siswa JEE juga secara konsisten memulai lebih banyak sesi latihan antara jam 5 sore dan 3 pagi dibandingkan dengan siswa AIPMT. Kami menduga dokter lebih disiplin!

Instrumentasi dan pengukuran aktivitas pengguna kami yang ekstensif pada tingkat yang sangat terperinci memberi kami kemampuan untuk menyimpulkan preferensi laten yang terkait dengan gaya belajar yang terkait dengan pengguna individu. Misalnya, siswa tertentu dapat belajar, dan setelah itu mengerjakan tes, lebih baik dengan bantuan penjelasan video, dibandingkan dengan siswa lain yang lebih menyukai deskripsi tekstual yang ekstensif, atau siswa lain yang belajar dengan mengerjakan langkah demi langkah melalui contoh masalah yang dipecahkan. Kami dapat memetakan pengguna ke model teoretis gaya belajar yang dipelajari dengan baik seperti Model Dunn dan Dunn (Dunn & Dunn 1989), atau Model Gaya Pikiran Gregorc (Gregorc 1982) untuk secara otomatis menyesuaikan kursus latihan perbaikan dan membantu pengguna menuju peningkatan skor.
Penggabungan pengguna
Cohorting adalah masalah pengelompokan klasik. Pengguna dikelompokkan berdasarkan pola penggunaan mereka sehubungan dengan fitur produk serta pola kinerja mereka sehubungan dengan sesi tes, latihan, dan revisi. Setiap pengguna dipetakan ke ruang fitur dimensi tinggi dari ribuan atribut, yang mencakup ukuran statis dan temporal. Kohort pada ukuran temporal memberi kita kemampuan untuk memulai aktivitas rendah dan pengguna baru dengan menetapkan kemungkinan lintasan kohort untuk pengguna ini berdasarkan aktivitas awal mereka. Pengumpulan pengguna adalah persyaratan inti untuk fitur sains mendalam tingkat tinggi kami seperti pembelajaran adaptif mikro, pembuatan umpan balik otomatis, dan rekomendasi konten.
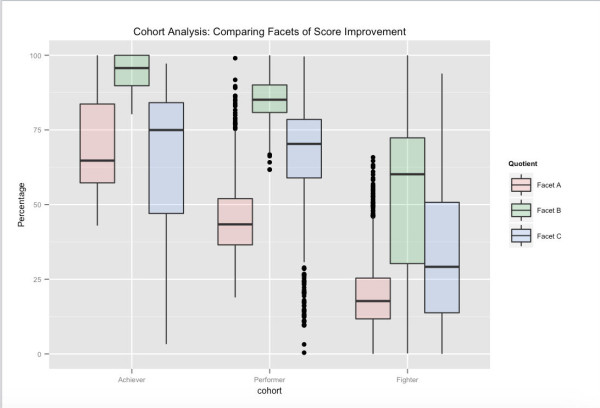
Satu pandangan yang mungkin dari kelompok pengguna – terkait dengan kinerja pengujian jangka panjang. Berdasarkan skor tes keseluruhan mereka, Achievers adalah braket persentil teratas pengguna di Embibe, Performers braket berikutnya, dan Fighters braket terakhir. Berbagai aspek yang ditampilkan, berhubungan dengan berbagai aspek peningkatan skor yang telah kami kelompokkan ke dalam ruang fitur kami. Misalnya, kita dapat melihat bahwa meskipun Facet_A bervariasi secara signifikan di seluruh kohort, dengan menargetkan umpan balik ke dan memengaruhi faset pembelajaran lainnya, dimungkinkan untuk mendorong pengguna ke kohort yang lebih tinggi berikutnya.
Pembelajaran mikro-adaptif
Pengiriman konten dan umpan balik berukuran kecil adalah kunci untuk belajar online secara efektif. Umumnya, pengguna menghabiskan waktu antara 30 menit hingga satu jam untuk online, mempraktikkan konsep dan pertanyaan. Dalam rentang waktu yang singkat ini, sangat penting untuk memaksimalkan dampak dari setiap sesi yang terikat waktu. Setiap sesi adalah aset bagi pengguna untuk memaksimalkan pembelajaran, dan ini paling baik dilakukan dengan strategi ukuran gigitan. Mesin mikro-adaptif kami untuk sesi latihan, mengambil profil pengguna dan atribut kelompok bersama dengan pohon pengetahuan kami dari 11.000 (dan terus bertambah!) meta-atribut konsep yang saling terkait sebagai masukan, dan memastikan bahwa urutan pertanyaan, petunjuk yang diberikan, dan just- umpan balik inline cerdas tepat waktu beradaptasi secara tepat dengan pengguna untuk meningkatkan hasil belajarnya pada tujuan kecil apa pun. Setiap konsumsi konten atau umpan balik seukuran gigitan akan memengaruhi kalibrasi kemahiran pengguna terhadap pohon pengetahuan konsep kami yang luas. Teknik pemrosesan matriks yang jarang, teori respons item, dan algoritme grafik memandu adaptasi mikro pembelajaran.
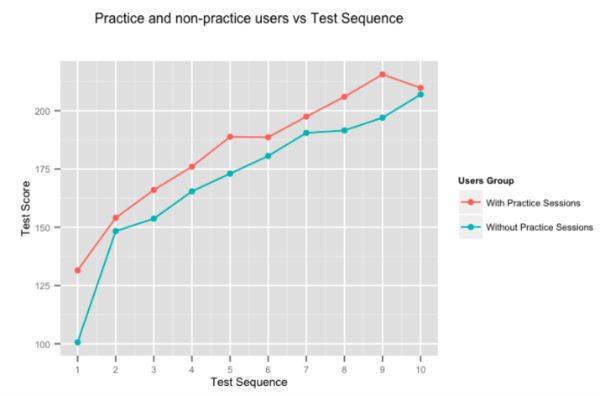
Cukup jelas bahwa latihan membuat seseorang sempurna, tetapi kami memutuskan untuk tetap menjalankan angka. Gambar di atas menunjukkan peningkatan skor rata-rata pengguna, untuk tes berturut-turut yang diberikan oleh pengguna yang menghabiskan waktu pada sesi latihan adaptif kami, dan mereka yang tidak. Pengguna yang berlatih di Embibe secara konsisten mengungguli mereka yang tidak dengan hampir 10% tes-on-tes.
Sistem umpan balik dan rekomendasi
Umpan balik dan sistem rekomendasi Embibe (yang telah kami ajukan patennya) dirancang dan dibuat untuk satu tujuan – untuk memaksimalkan peningkatan skor pengguna. Kami melengkapi dan menafsirkan ribuan sinyal tentang upaya pengguna selama sesi latihan dan tes, dan mengubah sinyal ini menjadi ruang dimensi tinggi dengan ribuan fitur untuk setiap pengguna. Menggunakan penambangan pola statistik pada ruang fitur upaya pengguna kami yang besar, kami telah memusatkan perhatian pada kumpulan parameter peringkat yang secara positif menaikkan skor pengguna. Parameter ini diberi kode mesin sebagai kapsul umpan balik peningkatan skor tepat waktu yang sangat bertarget, dan dikirimkan ke pengguna saat dia melanjutkan sesi latihannya. Umpan balik dan rekomendasi mengungkapkan kelemahan dan strategi yang dapat dia adopsi untuk memaksimalkan skornya.
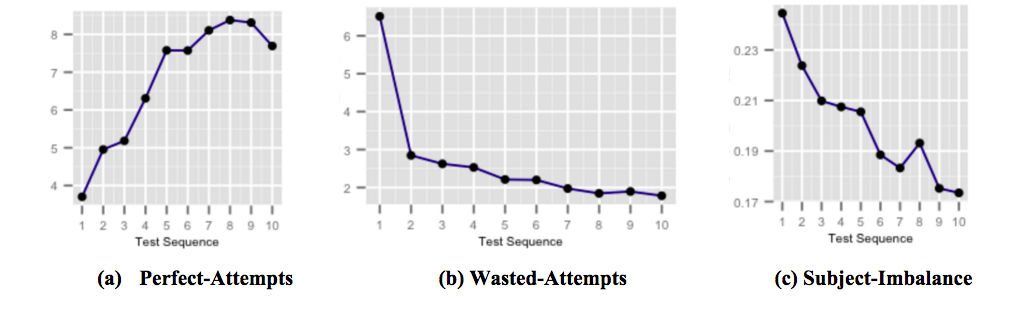
Gambar di atas menunjukkan bagaimana kapsul umpan balik just-in-time kami yang sangat bertarget untuk peningkatan skor memengaruhi kinerja siswa saat pengguna terpapar, dan menjadi sadar akan jebakan pengambilan tes yang umum. Gambar (a) menunjukkan jumlah rata-rata percobaan sempurna yang meningkat selama pengujian berturut-turut. Upaya sempurna adalah upaya yang dijawab dengan benar dalam beberapa waktu yang ditentukan. Gambar (b) menunjukkan jumlah rata-rata upaya yang sia-sia menurun selama pengujian berturut-turut. Upaya yang sia-sia adalah upaya yang salah dijawab di mana siswa memiliki lebih banyak waktu yang bisa dihabiskan untuk memikirkan pertanyaan itu. Dan gambar (c) menunjukkan rata-rata penurunan ketidakseimbangan subjek-akurasi selama tes berturut-turut. Ketidakseimbangan subjek-akurasi didefinisikan sebagai perbedaan antara akurasi tertinggi dan terendah di antara semua subjek dalam setiap tes yang diambil oleh pengguna. Ketidakseimbangan subjek-akurasi yang lebih tinggi menyiratkan bahwa pengguna kurang siap untuk mata pelajaran tertentu dibandingkan dengan mata pelajaran lain.
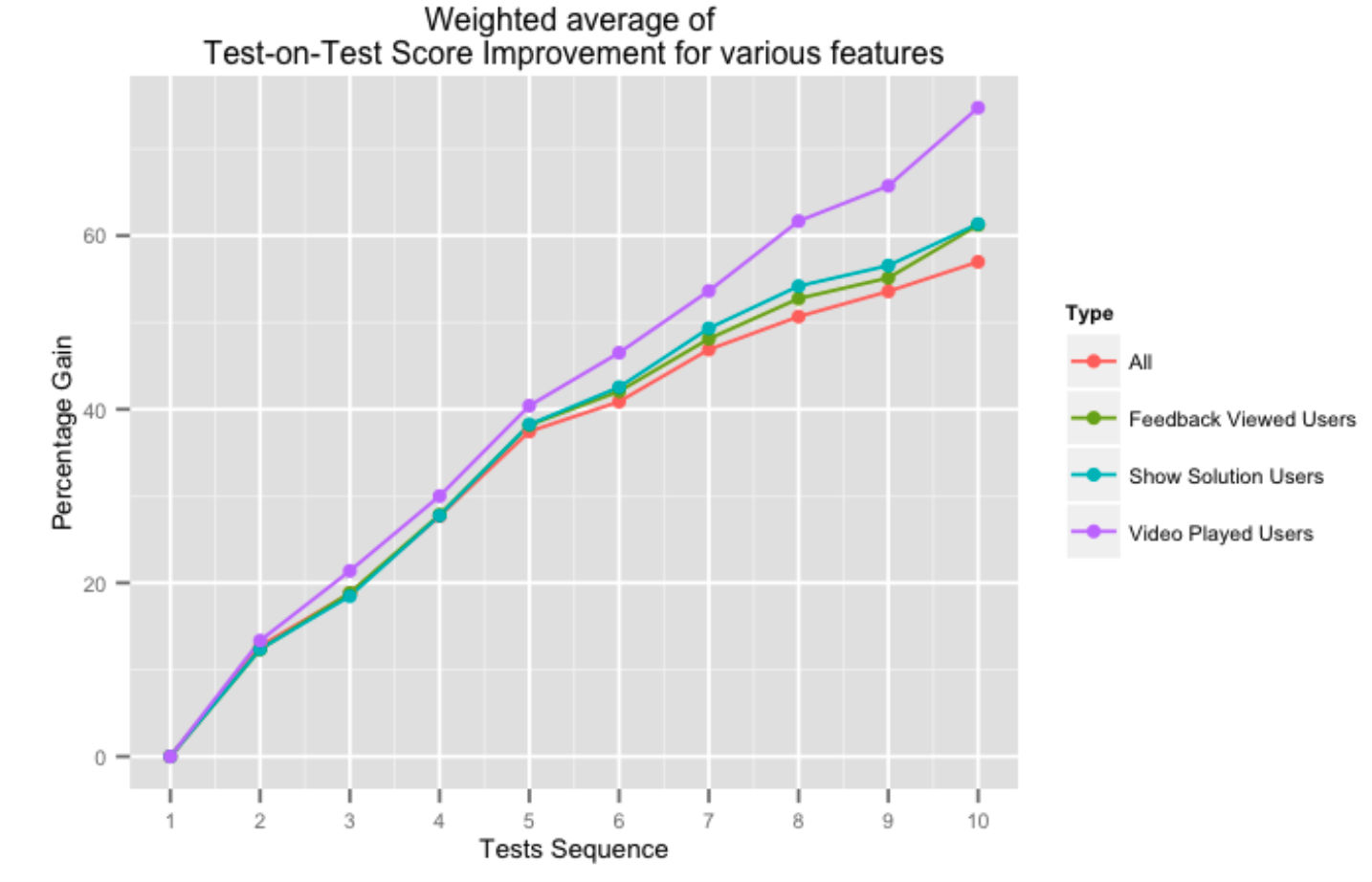
Gambar di atas menunjukkan persentase perolehan skor tes-di-tes berturut-turut untuk pengguna yang memanfaatkan berbagai aspek sistem umpan balik kami. Mengambil bantuan dari platform kami dalam bentuk solusi video, atau umpan balik tes secara keseluruhan, berdampak positif pada skor tes-di-tes, terutama saat pengguna menyelesaikan lebih banyak tes.
Memperkirakan peningkatan skor
Bagi pengguna yang sedang mempersiapkan ujian dalam bentuk apa pun, peningkatan skor adalah aspek terpenting yang memengaruhi hasil belajar. Kekayaan data perilaku kami memberi kami kemampuan untuk belajar dari tindakan pengguna di masa lalu, dengan mengukur bagaimana perilaku mereka selama dan setelah mengikuti tes di Embibe memengaruhi peningkatan skor. Penambangan data untuk pola statistik dalam penggunaan, aktivitas, dan fitur perilaku, di antara berbagai kelompok pengguna, memberi kami bukti yang didukung sains tentang efektivitas platform kami.
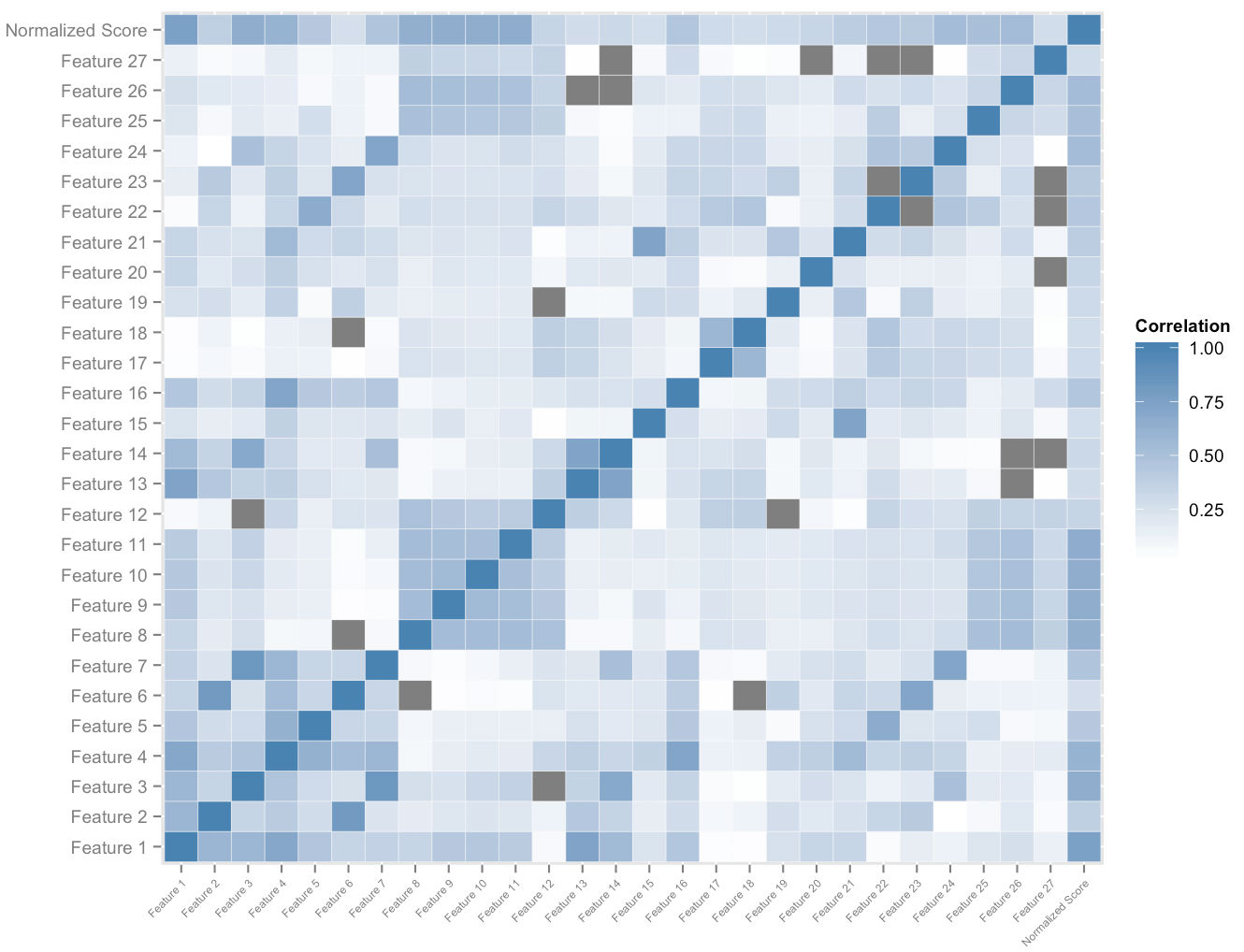
Gambar di atas menunjukkan subset dari ruang fitur yang kami buat per pengguna. Analisis korelasi silang pada ruang fitur dan skor yang dinormalisasi secara keseluruhan memberi kita urutan pada kepentingan fitur relatif. Ini, bersama dengan analisis dominasi empiris, memungkinkan kami untuk mengukur kuantum dampak setiap fitur pada kontribusinya terhadap peningkatan skor. Kombinasi yang tepat dari kecepatan yang paling penting dari fitur-fitur ini memungkinkan kami untuk secara kuantitatif menetapkan ukuran peningkatan skor potensial untuk setiap siswa, yang beradaptasi dengannya saat dia menggunakan platform.
Ini adalah masa-masa yang menggembirakan bagi bidang pendidikan, terutama di India dan negara berkembang lainnya. Ada kebutuhan mendesak untuk menerapkan sains yang mendalam, dengan fokus yang kuat pada penggunaan data dan wawasan yang dapat diberikannya, untuk membawa pendidikan dan pembelajaran ke tingkat berikutnya. Platform penyerapan dan pengiriman konten kami sedang dibangun di atas prinsip-prinsip ilmiah yang kuat, dan membantu pengguna menyadari nilai besar pada Embibe dalam bentuk peningkatan skor dalam rentang waktu persiapan yang terbatas. Kerangka pembelajaran mikro-adaptif kami yang memanfaatkan umpan balik dan rekomendasi khusus pengguna, yang disesuaikan secara tepat untuk pengguna, berdasarkan klasifikasi kelompok mereka serta karakteristik perilaku, memungkinkan pengguna untuk memiliki pengalaman yang memuaskan di Embibe. Ini adalah langkah-langkah konkrit pertama menuju pemecahan masalah dampak positif hasil belajar. Ini adalah pembelajaran yang dipersonalisasi.
Dalam posting ini, kami menyentuh berbagai sub-masalah yang perlu dipecahkan untuk menggerakkan kami di sepanjang jalan untuk mempengaruhi hasil belajar. Dalam posting kami berikutnya, kami akan berbicara tentang bagaimana kami mengukur dan melacak berbagai metrik di Embibe yang terkait dengan pengguna kami dan aktivitas mereka, agar kami dapat memantau perkembangan produk kami, pertumbuhannya, dan efektivitasnya sebagai tujuan belajar online.
Kami selalu mencari orang pintar yang jahat untuk ditambahkan ke peringkat kami di Lab Ilmu Data. Jika Anda senang menguji hipotesis, menjalankan regresi, memfaktorkan matriks yang sangat besar, menertawakan data besar, meluncurkan pekerjaan pengurangan peta, membangun model topik di atas teks tidak terstruktur yang berantakan, menambang data yang berisik untuk pola statistik, menyerap segunung data dari data terbuka sumber, memperdebatkan nilai-p, melatih jaringan saraf dan jaring kepercayaan yang mendalam, beralih antara python dan R, memutar visualisasi, dan membuat skrip, Anda akan menyukainya di sini!
Kirimkan kepada kami resume Anda di jobs.<id>@embibe.com, di mana:
<id> adalah bilangan yang dibentuk dengan 8 digit bukan nol pertama dari nilai fungsi kerapatan probabilitas untuk distribusi normal, dibulatkan menjadi 19 digit presisi, dan
mu adalah angka ke-26 dalam deret Padovan, dan
sigma adalah angka ke-17 dalam deret Fibonacci mulai dari 1, dan
x adalah bilangan prima ke-1002
Tim kami terdiri dari Keyur Faldu ( Chief Data Scientist), Achint Thomas ( Principal Data Scientist) dan Chintan Donda (Data Scientist).
Referensi
- Inventarisasi gaya belajar . Lawrence, KS: Sistem Harga.
- Gregorc AF, (1982). Model Gaya Pikiran: Teori, Prinsip, dan Aplikasi. Maynard, MA: Sistem Gabriel.
Embibe baru saja menyelesaikan 3 tahun di pasar sebagai salah satu perusahaan terkemuka dalam analisis data pendidikan. Siswa telah menghabiskan lebih dari 100 ribu jam untuk produk pada bulan Maret 2016 saja tanpa investasi dalam pemasaran berbayar.