
300 de milioane de studenți, 300 de miliarde de informații – Îndrăgostit de date în educație
Publicat: 2016-04-07O privire exclusivă asupra laboratorului de știință a datelor de la Embibe
[Aceasta este a doua parte a seriei Cum folosim tehnologia profundă și știința datelor pentru a personaliza educația]
Am construit Embibe cu o viziune singulară: să maximizăm rezultatele învățării la scară. A avea un impact pozitiv asupra rezultatului de învățare al unui utilizator este o problemă dificilă, dar importantă de rezolvat. De fapt, există o serie de sub-probleme deschise non-triviale, fiecare dintre acestea trebuie rezolvată pentru a realiza obiectivul înalt de a afecta în mod intenționat și pozitiv rezultatele învățării.
Dar mai întâi, care sunt rezultatele învățării? Și de ce ne pasă de ei?
În lumea extrem de competitivă de astăzi, un elev este măsurat în mare măsură prin cât de mult poate nota la un examen competitiv sau chiar la o clasă de școală. Scorul ei poate avea un impact semnificativ asupra opțiunilor sale de carieră. În sensul acestui articol, să încadrăm rezultatele învățării ca o funcție a potențialului înnăscut și antrenabil al unui elev, pentru a învăța, absorbi și aplica materialul de conținut în mod optim, în limitele de timp strict specificate; astfel încât să își poată maximiza scorul în orice context academic competitiv.
În țările în curs de dezvoltare, cum ar fi India, raportul elev-profesor este foarte denaturat, iar profesorii nu pot oferi în mod eficient atenție personalizată la nivel individual. Acest lucru duce la o dilemă, dat fiind că fiecare elev învață și absoarbe informații în ritmuri diferite și are niveluri diferite de aptitudini. Un efect secundar cunoscut al incapacității profesorilor de a oferi o atenție personalizată este că, pentru orice sală de clasă/colecție de studenți, materialul de învățare este întotdeauna prezentat pentru a satisface elevul „mediu”. Prin urmare, studenții foarte strălucitori nu își ating întregul potențial și nu vor putea să-și flexeze cu adevărat mușchiul academic, în timp ce studenții mai slabi din punct de vedere școlar vor avea dificultăți în a face față cu restul clasei. Cu toate acestea, platformele și sistemele de învățare online existente nu sunt capabile să faciliteze cu adevărat învățarea personalizată la nivel de student.
Majoritatea sistemelor actuale țin cont doar de cât de bine un student își poate potrivi soluțiile cu modulele de testare, așa cum este specificat de un administrator al sistemului. Învățarea personalizată pentru examenele competitive ar trebui să maximizeze scorul unui student pentru orice țintă academică în timpul limitat disponibil pentru ea. Învățarea personalizată ar trebui, de asemenea, să abordeze în mod constructiv lacunele de abilități ale elevului nu numai la nivelul cunoștințelor sau aptitudinilor, ci și la niveluri atitudinii și comportamentale. Această lipsă de instrumente eficiente de învățare personalizată, adaptate în mod specific și precis pentru fiecare student, este responsabilă pentru faptul că ea nu își poate realiza potențialul în obținerea punctajului maxim posibil la orice examen dat.
În acest articol, echipa embibe de știință a datelor va pune bazele diferitelor probleme legate de date interconectate care trebuie abordate pentru a maximiza rezultatele învățării și, în special, pentru a îmbunătăți scorul. Există două dimensiuni majore ale acestei probleme – Ingestie de conținut și Livrare de conținut. Fiecare dimensiune pune provocări unice într-o serie de domenii care cu siguranță vor fascina orice cercetător de date.
Ingestie de conținut
Ingestie automată de conținut
Zeci de panouri de program, mii de capitole și concepte și zeci de mii de institute și școli au ca rezultat sute de mii de întrebări și răspunsuri generate și utilizate de instructori în fiecare an. Imaginați-vă dacă fiecare elev ar putea să-și testeze cunoștințele înainte de examene cu privire la orice subset sau la toate aceste întrebări, împreună cu obținerea de explicații detaliate despre răspunsurile corecte și despre greșelile comune făcute. Pentru ca acest lucru să devină realitate, valorificăm recunoașterea optică a caracterelor (OCR) și învățarea automată pentru a ne construi propriul cadru de asimilare automatizat, care va fi foarte scalabil, cu adevărat multilingv și va depinde minim de inputul uman. Iar distracția nu se oprește aici. Cadrul va putea, de asemenea, să ingereze conținut scris de mână într-un mod independent de scriitor, adăugând astfel rapid depozitului nostru deja fantastic de întrebări, răspunsuri, concepte, explicații și cunoștințe.
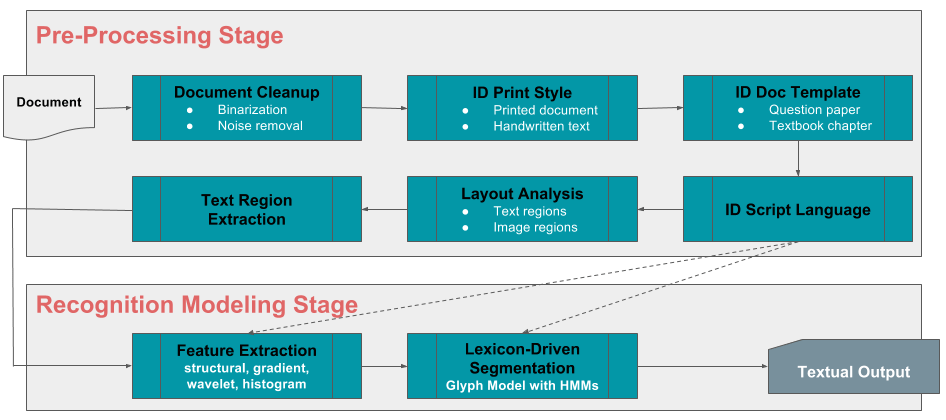
Etichetarea conceptului
Bine, așa că acum avem întrebări, răspunsuri, concepte și capitole, toate ingerate într-un depozit de date masiv. Ar fi dureros să etichetați manual fiecare întrebare sau capitol cu conceptele sale relevante, sau invers. Data Science la salvare! Folosind idei de vârf din clasificarea textului, modelarea subiectelor și învățarea profundă, etichetăm automat conceptele la întrebări, răspunsuri și capitole.

O selecție a celor mai populare concepte, așa cum au fost răsfoite de utilizatorii Embibe folosind funcția Învățare, în lunile decembrie 2015, ianuarie 2016 și februarie 2016.
Bazele noastre de date anterioare care conțin seturi de semințe de conținut etichetat manual de înaltă calitate sunt esențiale, deoarece extragem caracteristici lingvistice, lexicale și sensibile la context, pentru a pregăti modele de etichetare a textului de ultimă generație pentru toate noile date care sunt ingerate în sisteme.
Îmbogățirea metadatelor
Există o mulțime de informații disponibile online astăzi despre orice subiect despre care doriți să aflați. Ideile și conceptele se construiesc una pe cealaltă. De exemplu, prima lege a termodinamicii este legată de conceptul de sistem termodinamic, care, la rândul său, este legat de conceptele de capacități termice specifice ale gazelor, conservarea energiei mecanice și munca efectuată de un gaz, printre altele. Cadrul nostru de asimilare a conținutului include componente de îmbogățire a datelor care accesează automat cu crawlere web și etichetează conținutul cu elemente media atât de diverse, cum ar fi explicații de text, linkuri video, definiții, comentarii ale utilizatorilor și discuții pe forum, toate respectând drepturile de autor și atribuind în mod corespunzător dreptul de proprietate asupra conținutului sursă. . Această bogăție de informații disponibile face, de asemenea, posibilă conectarea automată a conceptelor înrudite într-o structură arborescentă. Folosind idei din domeniile teoriei grafurilor, text mining și propagarea etichetelor pe structuri rare, creăm legături și interconexiuni între concepte care împărtășesc o relație sursă→țintă.
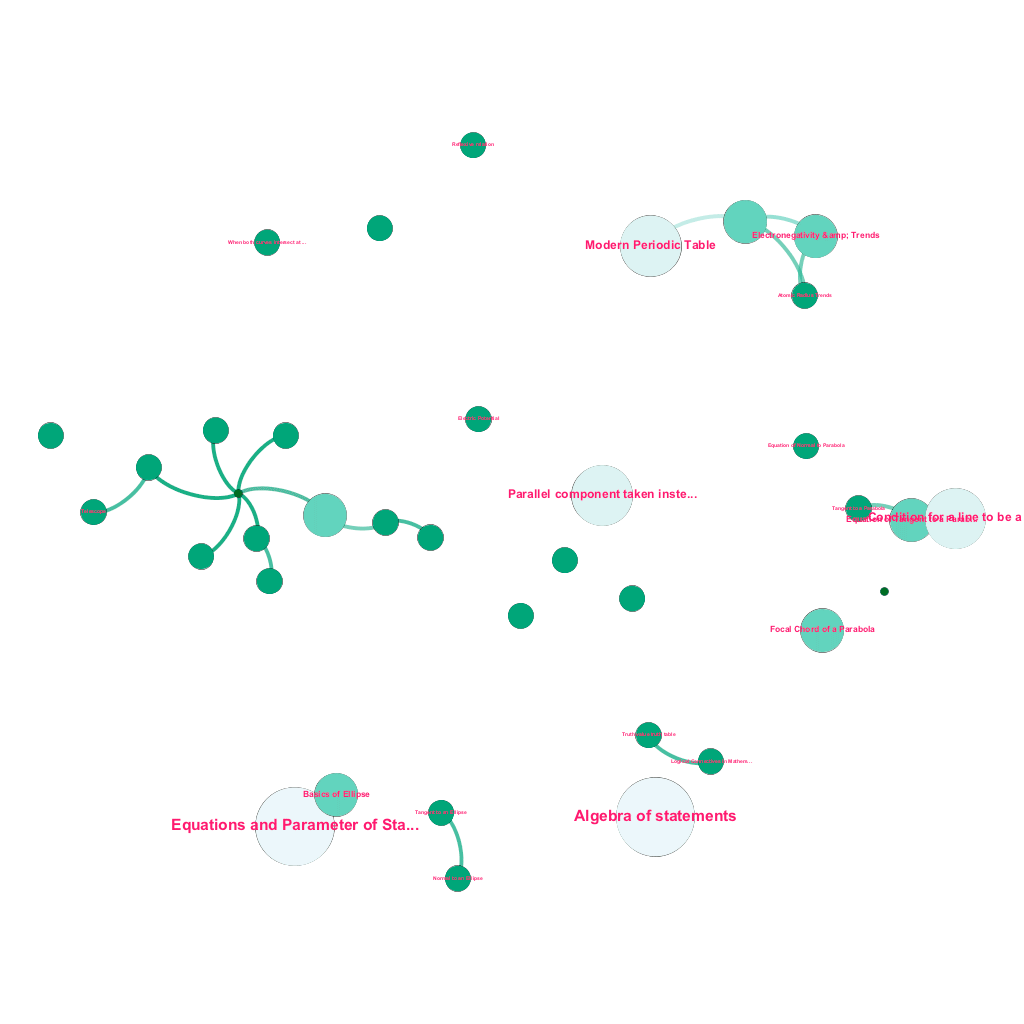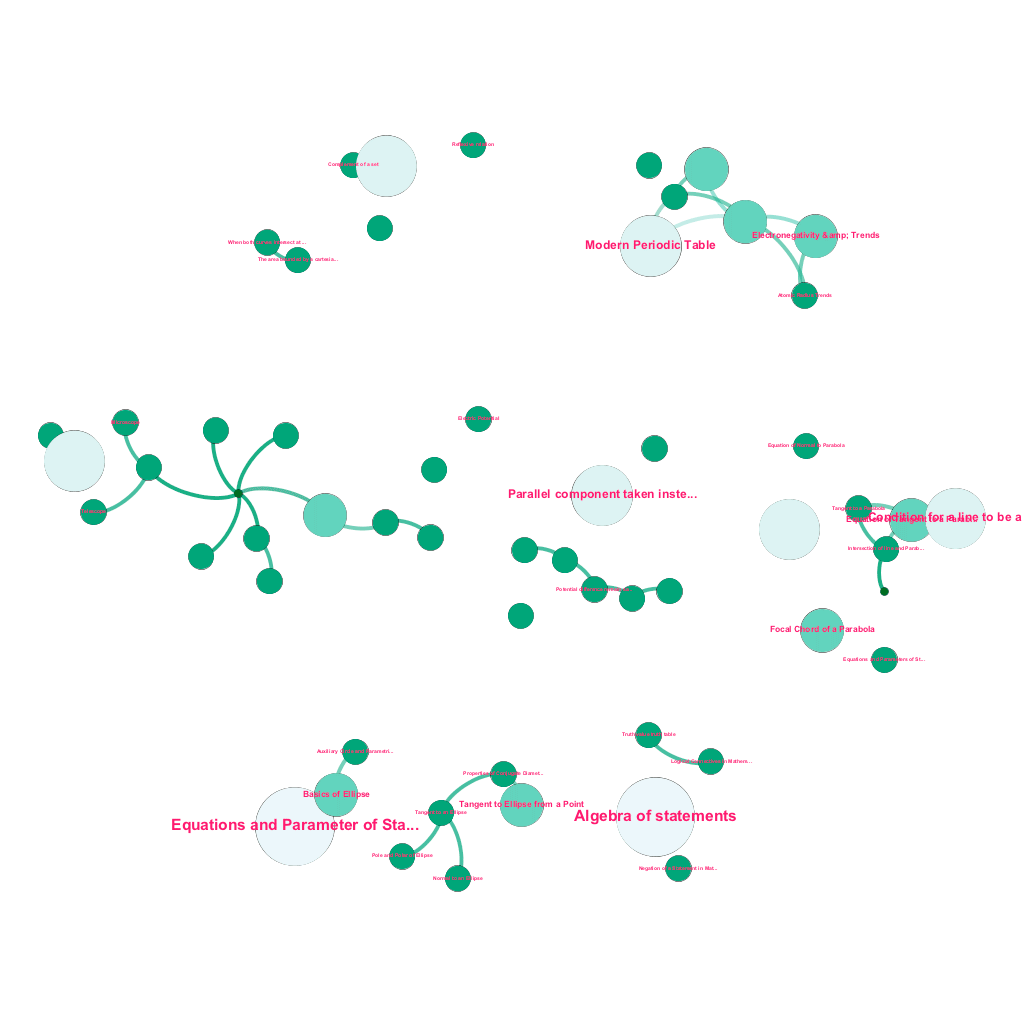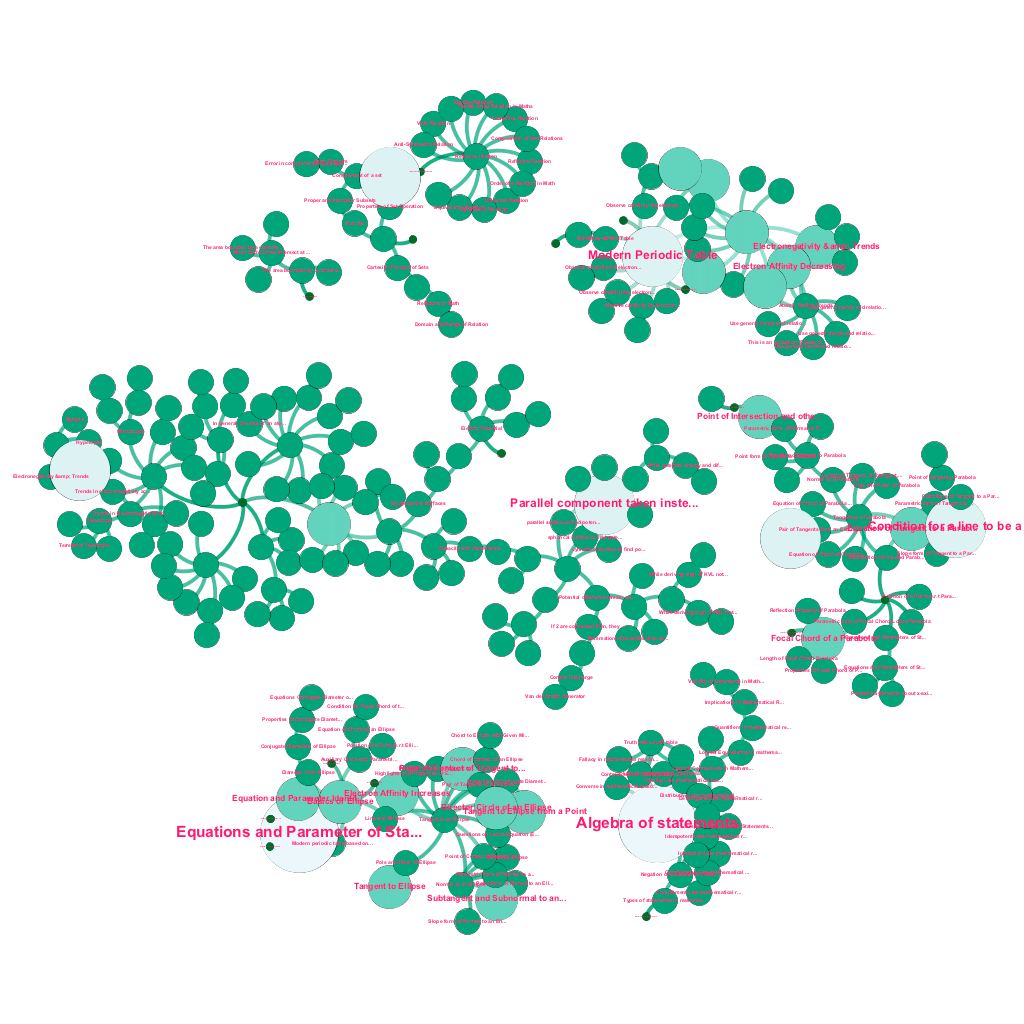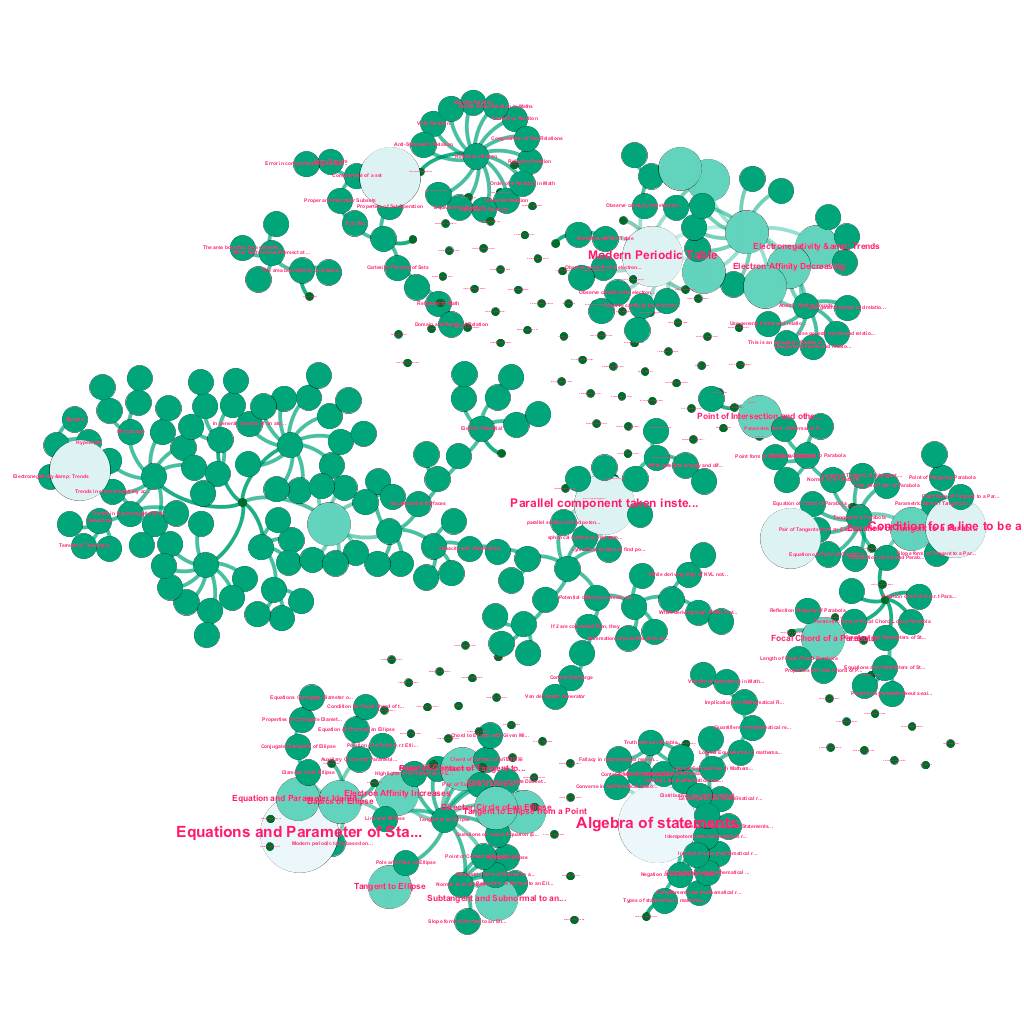
Construire automată a unui arbore de concepte, pentru un subset de idei din matematică, fiecare conectat la unul sau mai multe concepte înrudite
Întrebări similare grupări
Dacă te-ai pregăti pentru un examen, ai vrea să exersezi aceeași întrebare din nou și din nou? Asta nu ar fi de ajutor. În schimb, imaginați-vă cât de extrem de util ar fi să exersați un mic set de întrebări relevante care vă vor ajuta să stăpâniți complet un concept sau un capitol nou. Cu accesul nostru la sute de mii de întrebări, am dezvoltat capacitatea de a grupa întrebări pe baza similitudinii într-un număr de dimensiuni - vizate de conținut, testate de concept, nivel de dificultate și obiective ale examenului, printre altele.
Gruparea textului bazată pe spații de informații semantice latente și combinația lor cu alte spații de caracteristici categoriale și numerice ne permit să grupăm cu precizie universul nostru de întrebări în zone de interes care pot fi adaptate pentru fiecare individ folosind Embibe. În plus, această resursă bogată de date textuale pe care am transformat-o în spații de caracteristici numerice robuste legate de clusterele de concepte ne permite să perturbăm ușor datele existente pentru a genera expresii potențial infinite ale spațiului de întrebări. Mai multe întrebări în timpul execuției, nemaivăzute până acum! Acest lucru ne permite să oferim utilizatorilor valoarea maximă pentru timpul petrecut pe platforma noastră.
Livrarea de conținut
Profilarea utilizatorilor
Urmărim fiecare mișcare pe care o face un utilizator pe Embibe. Milioanele de practică și încercări de testare făcute de utilizatorii noștri în ultimii trei ani sunt calibrate într-un spațiu de date de multe mii de dimensiuni. Acest lucru se traduce într-un spațiu de miliarde de puncte de date pe care le putem extrage pentru a explora în profunzime datele comportamentale ale utilizatorilor noștri și pentru a genera perspective care se corelează cu modul în care se întâmplă învățarea. Fiecare încercare suplimentară a unui utilizator îi modifică capacitatea de a obține un scor mai mare la conceptele etichetate la acea încercare, împreună cu conceptele precedente și succesive conectate. Această problemă super complexă implică valorificarea ideilor din procesarea matricei rare, algoritmi de calcul în teoria graficelor și teoria răspunsului la item pentru a construi profiluri de utilizator robuste și adaptabile, care să se adapteze cu baza noastră de utilizatori în creștere.
Recomandat pentru tine:

Ce înseamnă prevederea anti-Profiteering pentru startup-urile indiene?

Cum startup-urile Edtech ajută forța de muncă din India să își îmbunătățească abilitățile și să devină pregătite pentru viitor...

Stocuri de tehnologie New-Age săptămâna aceasta: problemele Zomato continuă, EaseMyTrip postează Stro...

Startup-urile indiene iau comenzi rapide în căutarea finanțării

Platforma de marketing digital Logicserve are finanțare de 80 INR Cr, rebrand-urile ca LS Dig...

Raportul avertizează asupra unui control de reglementare reînnoit asupra spațiului Lendingtech
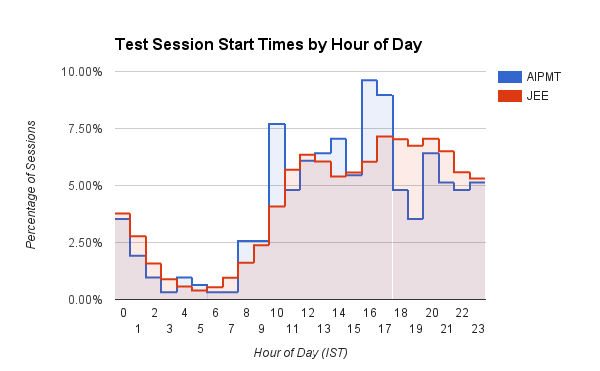
Un grafic cu bare interesant care arată ora (ora din zi în IST) la care utilizatorii își încep sesiunile de testare pe Embibe. Utilizatorii medicali (AIPMT) au un vârf definit în jurul orei 10:00 și între 15:00 și 17:00. Utilizatorii de inginerie (JEE), pe de altă parte, arată o creștere treptată a timpului de începere a sesiunii pe măsură ce ziua progresează, care atinge vârful în jurul orei 16:00 - 20:00. De asemenea, studenții JEE încep în mod constant mai multe sesiuni de practică între 17:00 și 3:00, comparativ cu studenții AIPMT. Bănuim că medicii sunt mai disciplinați!

Instrumentarea noastră extinsă și măsurarea activității utilizatorilor la un nivel foarte granular ne oferă posibilitatea de a deduce preferințe latente legate de stilurile de învățare asociate utilizatorilor individuali. De exemplu, anumiți studenți pot învăța și, ulterior, performează la teste, mai bine cu ajutorul explicațiilor video, în comparație cu alți studenți care preferă descrieri textuale extinse sau cu alții care învață lucrând pas cu pas prin probleme exemplificative rezolvate. Putem mapa utilizatorii la modele teoretice bine studiate ale stilurilor de învățare, cum ar fi Modelul Dunn și Dunn (Dunn și Dunn 1989) sau Modelul stilurilor mintale al lui Gregorc (Gregorc 1982) pentru a adapta automat cursurile de practică de remediere și pentru a ajuta utilizatorul să îmbunătățească scorul.
Cohortarea utilizatorilor
Cohortarea este o problemă clasică de grupare. Utilizatorii sunt grupați în funcție de modelele lor de utilizare în ceea ce privește caracteristicile produsului, precum și modelele de performanță în ceea ce privește sesiunile de testare, practică și revizuire. Fiecare utilizator este mapat la un spațiu de caracteristici dimensionale înalte cu multe mii de atribute, care includ măsuri statice și temporale. Cohortarea pe măsuri temporale ne oferă capacitatea de a începe la rece o activitate scăzută și noi utilizatori prin atribuirea unor traiectorii probabile de cohortă acestor utilizatori pe baza activității lor inițiale. Cohortarea utilizatorilor este o cerință de bază pentru caracteristicile noastre de știință profundă de nivel superior, cum ar fi învățarea micro-adaptativă, generarea automată de feedback și recomandarea de conținut.
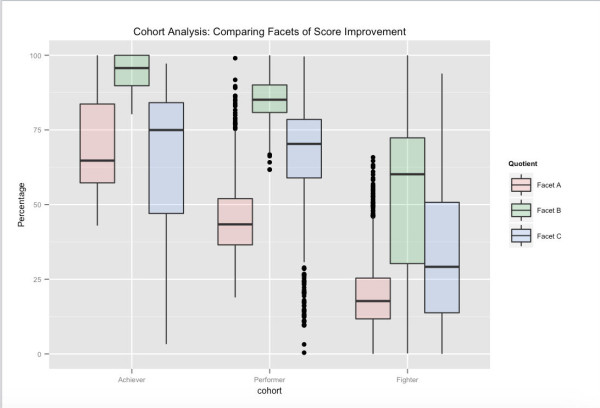
O posibilă vedere a cohortelor de utilizatori – legată de performanța testelor pe termen lung. Pe baza scorurilor lor generale ale testelor, Achievers sunt clasa superioară a utilizatorilor pe Embibe, Performers următoarea categorie și Fighters ultima categorie. Diferitele fațete prezentate se referă la diferite aspecte ale îmbunătățirii scorului în care ne-am grupat spațiul de caracteristici. De exemplu, putem vedea că, deși Facet_A variază semnificativ între cohorte, prin direcționarea feedback-ului către și afectarea altor fațete de învățare, este posibil să împingeți utilizatorii în următoarea cohortă superioară.
Învățare micro-adaptativă
Livrarea de conținut și feedback la dimensiuni mici este cheia pentru a învăța în mod eficient online. În general, utilizatorii petrec între 30 de minute și o oră online, exersând concepte și întrebări. În acest interval de timp scurt, este foarte important să maximizăm impactul fiecărei sesiuni limitate în timp. Fiecare sesiune este un atu pentru utilizator pentru a maximiza învățarea, iar acest lucru este cel mai bine realizat cu strategia de dimensiuni mici. Motorul nostru micro-adaptativ pentru sesiunile de practică, preia profilul unui utilizator și atributele de cohortă împreună cu arborele nostru de cunoștințe de 11.000 (și în creștere!) meta-atribute ale conceptelor interconectate ca intrare și asigură că secvențierea întrebărilor, sugestiile furnizate și doar- Feedback-ul inteligent în timp se adaptează exact utilizatorului pentru a-și îmbunătăți rezultatele învățării la orice obiectiv de dimensiuni mici. Fiecare consum de conținut sau feedback va avea un impact asupra calibrării competenței utilizatorului în raport cu arborele nostru extins de cunoștințe de concepte. Tehnicile rare de procesare a matricei, teoria răspunsului la item și algoritmii grafici ghidează micro-adaptabilitatea învățării.
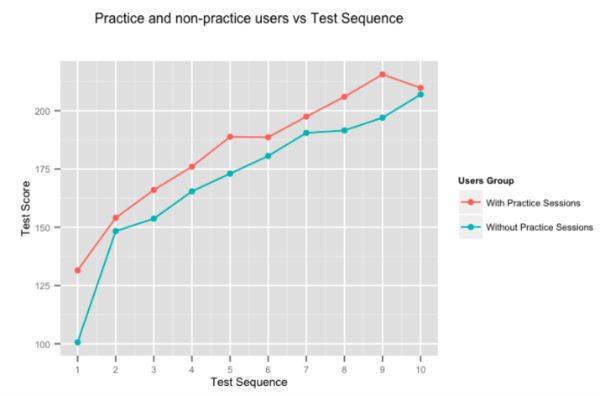
Este destul de evident că practica face unul perfect, dar am decis să rulăm numerele oricum. Figura de mai sus arată îmbunătățirea scorului mediu al utilizatorilor, pentru testele succesive oferite de utilizatorii care petrec timp în sesiunile noastre de antrenament adaptiv și de cei care nu o fac. Utilizatorii care practică pe Embibe îi depășesc în mod constant pe cei care nu fac test-on-test cu aproape 10%.
Sistem de feedback și recomandare
Sistemul de feedback și recomandări al lui Embibe (pentru care am depus deja brevete) este conceput și construit cu un singur scop - pentru a maximiza îmbunătățirea scorului unui utilizator. Instrumentăm și interpretăm mii de semnale despre încercările unui utilizator în timpul sesiunilor de practică și de testare și transformăm aceste semnale într-un spațiu dimensional înalt de mii de caracteristici pentru fiecare utilizator. Folosind extragerea de modele statistice în spațiul nostru masiv de caracteristici de încercare a utilizatorului, ne-am concentrat pe seturile de parametri clasificați care cresc în mod pozitiv scorul unui utilizator. Acești parametri sunt codificați de mașină ca capsule extrem de vizate de feedback de îmbunătățire a scorului și sunt livrați utilizatorului în timp ce aceasta își continuă sesiunea de antrenament. Feedback-ul și recomandările expun punctele slabe și strategiile pe care le poate adopta pentru a-și maximiza scorul.
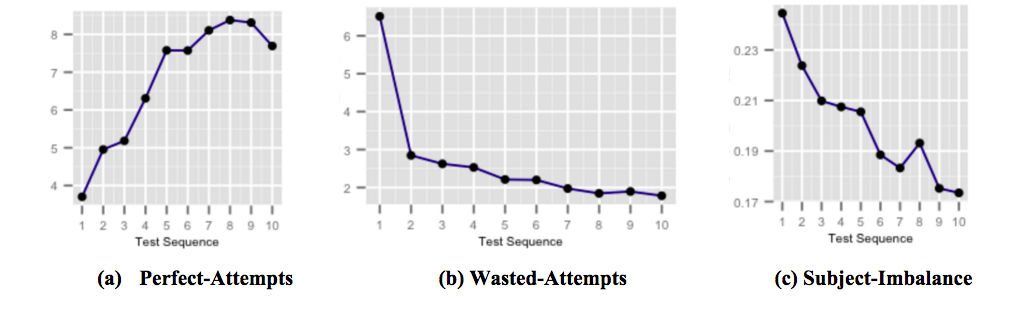
Cifrele de mai sus arată modul în care capsulele noastre de feedback direct la timp pentru îmbunătățirea punctajului afectează performanța elevilor, pe măsură ce utilizatorul este expus și devine conștient de capcanele comune ale testării. Figura (a) arată numărul mediu de încercări perfecte care crește pe parcursul testelor succesive. Încercările perfecte sunt încercări la care se răspunde corect într-un interval de timp stabilit. Figura (b) arată numărul mediu de încercări irosite în scădere în timpul testelor succesive. Încercările irosite sunt încercări la care se răspunde incorect în cazul în care studentul a avut mai mult timp care ar fi putut fi petrecut gândindu-se la întrebare. Iar figura (c) arată dezechilibrul mediu subiect-acuratețe în scădere în timpul testelor succesive. Subiect-acuratețe-dezechilibru este definit ca diferența dintre precizia cea mai mare și cea mai scăzută dintre toți subiecții la orice test luat de un utilizator. Un dezechilibru-acuratețe-subiect mai mare implică faptul că utilizatorul este mai puțin pregătit pentru anumite subiecte în comparație cu alte subiecte.
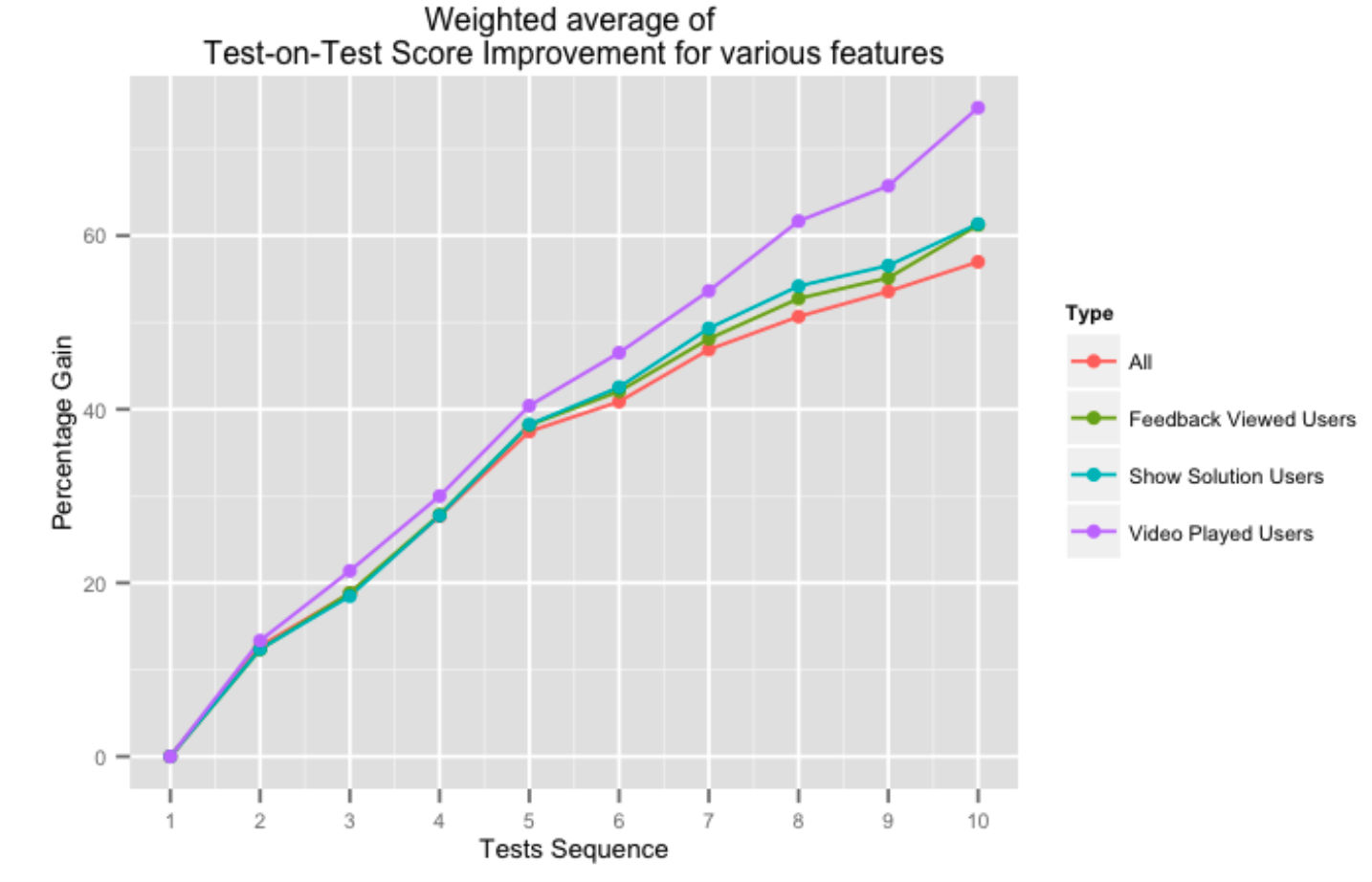
Figura de mai sus arată creșterea procentuală în scorurile succesive de la test la test pentru utilizatorii care utilizează diverse aspecte ale sistemului nostru de feedback. Asistența oferită de platforma noastră sub formă de soluții video sau feedback general asupra testelor are un impact pozitiv asupra scorurilor la test, mai ales pe măsură ce utilizatorul finalizează mai multe teste.
Estimarea îmbunătățirii scorului
Pentru utilizatorii care se pregătesc pentru examene de orice fel, îmbunătățirea punctajului este cel mai important aspect al afectării rezultatelor învățării. Bogăția noastră de date comportamentale ne oferă capacitatea de a învăța din acțiunile anterioare ale utilizatorilor, măsurând modul în care comportamentul lor în timpul și după efectuarea testelor pe Embibe afectează îmbunătățirea scorului. Exploatarea datelor pentru modele statistice de utilizare, activitate și caracteristici comportamentale, în rândul diferitelor cohorte de utilizatori, ne oferă dovezi susținute de știință a eficacității platformei noastre.
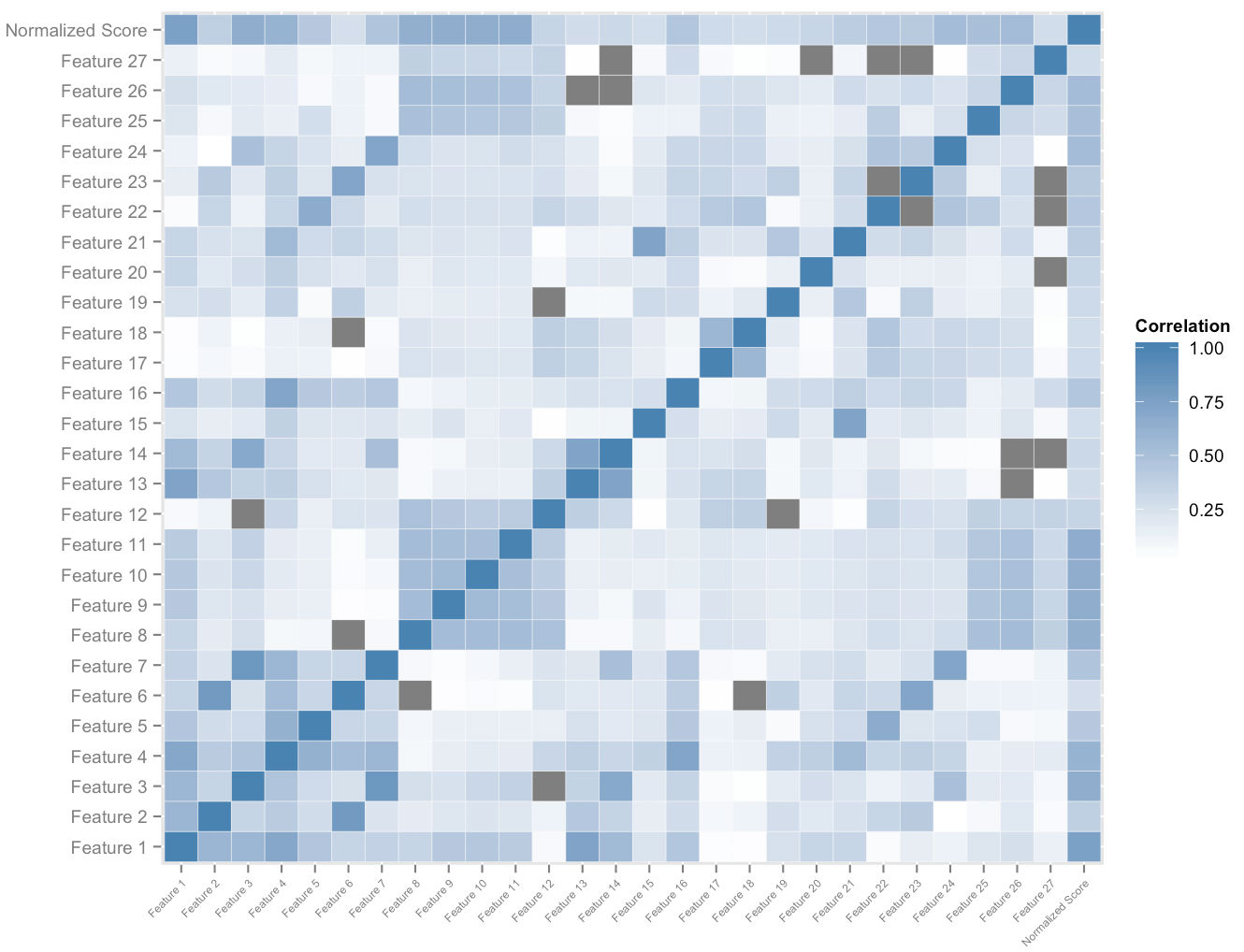
Figura de mai sus arată un subset al spațiului de caracteristici pe care îl construim per utilizator. Analiza corelației încrucișate pe spațiul caracteristicilor și scorurile generale normalizate ne oferă o ordonare în funcție de importanța relativă a caracteristicilor. Acest lucru, împreună cu analiza empirică a dominanței, ne permite să măsurăm cuantumul impactului fiecărei caracteristici asupra contribuției sale la îmbunătățirea scorului. O combinație ponderată corespunzător a vitezelor celor mai importante dintre aceste caracteristici ne permite să atribuim cantitativ o măsură de potențială îmbunătățire a scorului fiecărui elev, care se adaptează la ea pe măsură ce folosește platforma.
Acestea sunt vremuri interesante pentru domeniul educației, în special în India și alte țări în curs de dezvoltare. Există o nevoie urgentă de a aplica știința profundă, cu un accent puternic pe utilizarea datelor și a perspectivelor pe care le poate oferi, pentru a duce educația și învățarea la următorul nivel. Platformele noastre de asimilare și livrare de conținut sunt construite pe principii științifice solide și îi ajută pe utilizatori să realizeze o valoare imensă pentru Embibe sub formă de îmbunătățire a scorului în intervale de timp limitate de pregătire. Cadrul nostru de învățare micro-adaptabil, care utilizează feedback și recomandări specifice utilizatorului, adaptate exact utilizatorilor, pe baza clasificărilor lor de cohortă, precum și a caracteristicilor comportamentale, le permite utilizatorilor să aibă o experiență împlinită pe Embibe. Aceștia sunt primii pași concreti către rezolvarea problemei impactului pozitiv asupra rezultatelor învățării. Aceasta este o învățare personalizată.
În această postare, am atins diferite sub-probleme care trebuie rezolvate pentru a ne muta pe drumul spre afectarea rezultatelor învățării. În următoarea noastră postare, vom vorbi despre modul în care măsurăm și urmărim diferite valori la Embibe care sunt legate de utilizatorii noștri și de activitatea acestora, pentru ca noi să ținem un deget pe pulsul produsului nostru, creșterea acestuia și eficacitatea acestuia ca o destinație de învățare online.
Suntem mereu în căutarea unor oameni răi deștepți pe care să-i adăugăm în rândurile noastre la Data Science Lab. Dacă vă place să testați ipoteze, să rulați regresii, să factorați matrici uriașe, să râdeți în fața datelor mari, să trageți joburi de reducere a hărților, să construiți modele de subiecte peste text nestructurat dezordonat, să extrageți date zgomotoase pentru modele statistice, să ingerați munți de date din date deschise surse, argumentarea valorilor p, antrenarea rețelelor neuronale și a rețelelor de credință profundă, comutarea între python și R, învârtirea vizualizărilor și scripturile shell-urilor, vă va plăcea aici!
Trimite-ne un rând cu CV-ul tău la jobs.<id>@embibe.com, unde:
<id> este numărul format cu primele 8 cifre diferite de zero ale valorii funcției de densitate de probabilitate pentru distribuția normală, rotunjit la 19 cifre de precizie și
mu este al 26-lea număr din secvența Padovan și
sigma este al 17-lea număr din șirul Fibonacci, începând cu 1 și
x este al 1002-lea număr prim
Echipa noastră este formată din Keyur Faldu ( Scientist șef de date), Achint Thomas ( Scientist principal de date) și Chintan Donda ( Scientist de date).
Referințe
- Inventarul stilului de învățare . Lawrence, KS: Sisteme de preț.
- Gregorc AF, (1982). Modelul stilurilor minții: teorie, principii și aplicații. Maynard, MA: Gabriel Systems.
Embibe a împlinit recent 3 ani pe piață ca una dintre cele mai importante companii în analiza datelor educaționale. Studenții au petrecut peste 100.000 de ore pe produs numai în martie 2016, fără investiții zero în marketing plătit.