
300 milionów studentów, 300 miliardów spostrzeżeń – zakochani w danych w edukacji
Opublikowany: 2016-04-07Ekskluzywne spojrzenie na laboratorium danych firmy Embibe
[To jest druga część serii Jak wykorzystujemy Deep Tech i Data Science do personalizacji edukacji]
Zbudowaliśmy Embibe z jedną wizją: maksymalizować efekty uczenia się na dużą skalę. Pozytywny wpływ na efekty uczenia się użytkownika jest trudnym, ale ważnym problemem do rozwiązania. W rzeczywistości istnieje wiele nietrywialnych, otwartych podproblemów, z których każdy musi zostać rozwiązany, aby zrealizować wzniosły cel, jakim jest celowe i pozytywne wpływanie na wyniki uczenia się.
Ale najpierw, jakie są efekty uczenia się? I dlaczego nam na nich zależy?
W dzisiejszym, wysoce konkurencyjnym świecie, uczennicę mierzy się w dużej mierze tym, ile może zdobyć w konkurencyjnym egzaminie, a nawet w klasie szkolnej. Jej wynik może mieć znaczący wpływ na jej opcje zawodowe. Na potrzeby tego artykułu ujęmy efekty uczenia się jako funkcję wrodzonego i możliwego do wyszkolenia potencjału ucznia do uczenia się, przyswajania i optymalnego stosowania treści, w ściśle określonych ramach czasowych; aby mogła zmaksymalizować swój wynik w każdym konkretnym, konkurencyjnym kontekście akademickim.
W krajach rozwijających się, takich jak Indie, stosunek liczby uczniów do nauczycieli jest bardzo zniekształcony, a nauczyciele nie są w stanie skutecznie zapewnić spersonalizowanej uwagi na poziomie indywidualnym. Prowadzi to do dylematu, biorąc pod uwagę, że każdy uczeń uczy się i przyswaja informacje w różnym tempie i ma różne poziomy uzdolnień. Znanym efektem ubocznym niezdolności nauczycieli do zapewnienia spersonalizowanej uwagi jest to, że w każdej klasie/kolekcji uczniów materiał do nauki jest zawsze prezentowany w celu zaspokojenia potrzeb „przeciętnego” ucznia. Dlatego bardzo bystrzy uczniowie nie wykorzystują w pełni swojego potencjału i nie będą w stanie naprawdę rozwinąć swoich akademickich mięśni, podczas gdy uczniowie słabsi w nauce będą mieli trudności z poradzeniem sobie z resztą klasy. Jednak istniejące platformy i systemy nauczania online nie są w stanie naprawdę ułatwić spersonalizowanej nauki na poziomie ucznia.
Większość obecnych systemów uwzględnia tylko to, jak dobrze uczeń może dopasować swoje rozwiązania do modułów testowych określonych przez administratora systemu. Spersonalizowane uczenie się na egzaminach konkurencyjnych powinno zmaksymalizować wynik ucznia dla dowolnego celu akademickiego w ograniczonym czasie, który ma do dyspozycji. Spersonalizowane uczenie się powinno również konstruktywnie zająć się lukami w umiejętnościach ucznia nie tylko na poziomie wiedzy lub uzdolnień, ale także na poziomie postaw i zachowań. Ten brak skutecznych narzędzi do spersonalizowanego uczenia się, dostosowanych specjalnie i precyzyjnie dla każdego ucznia, powoduje, że nie jest on w stanie zrealizować swojego potencjału w osiągnięciu maksymalnego możliwego wyniku na dowolnym egzaminie.
W tym artykule zespół zajmujący się analizą danych embibe położy podwaliny pod różne powiązane ze sobą problemy związane z danymi, które należy rozwiązać, aby zmaksymalizować efekty uczenia się, a zwłaszcza poprawę wyników. Problem ten ma dwa główne wymiary – pozyskiwanie treści i dostarczanie treści. Każdy wymiar stawia unikalne wyzwania w wielu obszarach, które z pewnością zafascynują każdego analityka danych.
Pozyskiwanie treści
Automatyczne pozyskiwanie treści
Dziesiątki plansz programowych, tysiące rozdziałów i koncepcji oraz dziesiątki tysięcy instytutów i szkół owocują setkami tysięcy pytań i odpowiedzi generowanych i wykorzystywanych przez instruktorów każdego roku. Wyobraź sobie, że każdy uczeń był w stanie sprawdzić swoją wiedzę przed egzaminami na dowolny podzbiór lub wszystkie z tych pytań, a także uzyskać szczegółowe wyjaśnienia dotyczące poprawnych odpowiedzi i typowych błędów. Aby to urzeczywistnić, wykorzystujemy optyczne rozpoznawanie znaków (OCR) i uczenie maszynowe, aby zbudować własną platformę automatycznego przetwarzania, która będzie wysoce skalowalna, prawdziwie wielojęzyczna i minimalnie zależna od danych wejściowych człowieka. Na tym zabawa się nie kończy. Ramy będą również w stanie przyswajać odręczne treści w sposób niezależny od pisarza, tym samym szybko dodając do naszego i tak już fantastycznego repozytorium pytań, odpowiedzi, koncepcji, wyjaśnień i wiedzy.
Znakowanie koncepcji
W porządku, więc teraz mamy pytania, odpowiedzi, koncepcje i rozdziały zebrane w ogromnej hurtowni danych. Ręczne oznaczanie każdego pytania lub rozdziału odpowiednimi pojęciami byłoby bolesne lub odwrotnie. Data Science na ratunek! Korzystając z nowatorskich pomysłów z klasyfikacji tekstu, modelowania tematów i głębokiego uczenia się, automatycznie oznaczamy koncepcje pytaniami, odpowiedziami i rozdziałami.

Wybór najpopularniejszych koncepcji przeglądanych przez użytkowników Embibe za pomocą funkcji Nauka w grudniu 2015 r., styczniu 2016 r. i lutym 2016 r.
Nasze wcześniejsze bazy danych zawierające zestawy inicjujące wysokiej jakości ręcznie oznaczonej treści są kluczowe, ponieważ wyodrębniamy funkcje językowe, leksykalne i kontekstowe, aby trenować najnowocześniejsze modele tagowania tekstowego dla wszystkich nowych danych, które są przyjmowane do naszego systemy.
Wzbogacanie metadanych
Obecnie w Internecie dostępnych jest mnóstwo informacji na każdy temat, o którym chciałbyś się dowiedzieć. Idee i koncepcje budują się nawzajem. Na przykład I Zasada Termodynamiki jest związana z pojęciem układu termodynamicznego, co z kolei wiąże się m.in. z pojęciami ciepła właściwego gazów, zachowania energii mechanicznej i pracy wykonywanej przez gaz. Nasza struktura pozyskiwania treści obejmuje komponenty wzbogacania danych, które automatycznie przemierzają sieć i oznaczają treści tak różnymi elementami multimedialnymi, jak wyjaśnienia tekstowe, łącza wideo, definicje, komentarze użytkowników i dyskusje na forum, a wszystko to z poszanowaniem praw autorskich i prawidłowego przypisywania własności do treści źródłowych . To bogactwo dostępnych informacji umożliwia również automatyczne łączenie powiązanych pojęć w strukturę drzewa. Wykorzystując pomysły z dziedziny teorii grafów, eksploracji tekstu i propagacji etykiet na strukturach rzadkich, tworzymy powiązania i połączenia między koncepcjami, które mają wspólną relację źródło-cel.
Automatyczne tworzenie drzewa pojęć dla podzbioru pomysłów z matematyki, z których każdy jest połączony z jedną lub wieloma powiązanymi koncepcjami
Grupowanie podobnych pytań
Gdybyś przygotowywał się do egzaminu, czy chciałbyś ćwiczyć to samo pytanie w kółko? To nie byłoby pomocne. I odwrotnie, wyobraź sobie, jak niezwykle przydatne byłoby przećwiczenie małego zestawu odpowiednich pytań, które pomogą ci całkowicie opanować nową koncepcję lub rozdział. Dzięki naszemu dostępowi do setek tysięcy pytań rozwinęliśmy możliwość grupowania pytań w oparciu o podobieństwo w wielu wymiarach – między innymi ukierunkowanych na treść, przetestowanych pod kątem koncepcji, poziomie trudności i celach egzaminacyjnych.
Grupowanie tekstu w oparciu o ukryte semantyczne przestrzenie informacyjne oraz ich połączenie z innymi kategoriami i wartościami liczbowymi pozwala nam precyzyjnie pogrupować nasz wszechświat pytań w obszary zainteresowania, które można dostosować dla każdej osoby za pomocą Embibe. Dodatkowo, ten bogaty zasób danych tekstowych, które przekształciliśmy w solidne przestrzenie cech numerycznych związanych z klastrami pojęć, pozwala nam nieco zakłócić istniejące dane, aby wygenerować potencjalnie nieskończone wyrażenia przestrzeni pytań. Więcej pytań w czasie wykonywania, nigdy wcześniej nie widzianych! Dzięki temu możemy zapewnić użytkownikom maksymalną wartość czasu spędzonego na naszej platformie.
Dostarczanie zawartości
Profilowanie użytkownika
Śledzimy każdy ruch użytkownika w Embibe. Miliony prób praktycznych i testowych wykonanych przez naszych użytkowników w ciągu ostatnich trzech lat są skalibrowane w przestrzeni danych o wielu tysiącach wymiarów. Przekłada się to na przestrzeń miliardów punktów danych, które możemy wydobyć, aby zagłębić się w dane behawioralne naszych użytkowników i wygenerować spostrzeżenia, które korelują z procesem uczenia się. Każda dodatkowa próba użytkownika poprawia jej zdolność do zdobywania wyższych punktów za pojęcia przypisane do tej próby, wraz z powiązanymi koncepcjami poprzedzającymi i następującymi. Ten bardzo złożony problem polega na wykorzystaniu pomysłów z przetwarzania macierzy rzadkich, algorytmów obliczeniowych w teorii grafów i teorii odpowiedzi na elementy w celu stworzenia solidnych i adaptacyjnych profili użytkowników, które skalują się wraz z rosnącą bazą użytkowników.
Polecany dla Ciebie:

Co oznacza przepis anty-profitowy dla indyjskich startupów?

W jaki sposób start-upy Edtech pomagają indyjskim pracownikom podnosić umiejętności i być gotowym na przyszłość...

Akcje New Age Tech w tym tygodniu: Kłopoty Zomato nadal, EaseMyTrip publikuje Stro...

Indyjskie startupy idą na skróty w pogoni za finansowaniem

Digital Marketing Platform Logicserve Bags Finansowanie INR 80 Cr, zmienia nazwę na LS Dig...

Raport ostrzega przed odnowioną kontrolą regulacyjną dotyczącą przestrzeni Lendingtech
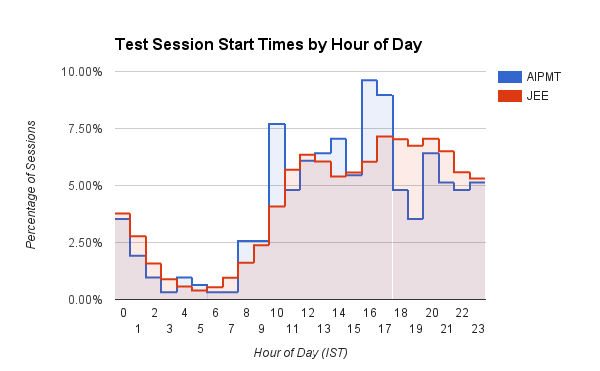
Ciekawy wykres słupkowy pokazujący godzinę (godzinę dnia w IST), o której użytkownicy rozpoczynają sesje testowe na Embibe. Użytkownicy medyczni (AIPMT) mają zdefiniowany wzrost około 10 rano i między 15:00 a 17:00. Z drugiej strony użytkownicy inżynierii (JEE) wykazują stopniowe wydłużanie czasu rozpoczęcia sesji w miarę upływu dnia, które osiąga szczyt około 16:00 do 20:00. Studenci JEE również konsekwentnie rozpoczynają więcej sesji treningowych między 17:00 a 3 nad ranem w porównaniu ze studentami AIPMT. Zgadujemy, że lekarze są bardziej zdyscyplinowani!

Nasze rozbudowane oprzyrządowanie i pomiar aktywności użytkowników na bardzo szczegółowym poziomie daje nam możliwość wywnioskowania ukrytych preferencji związanych ze stylami uczenia się powiązanymi z poszczególnymi użytkownikami. Na przykład niektórzy uczniowie mogą uczyć się, a następnie wykonywać testy, lepiej za pomocą objaśnień wideo, w porównaniu z innymi uczniami, którzy wolą obszerne opisy tekstowe, lub jeszcze inni, którzy uczą się, pracując krok po kroku przez rozwiązane przykładowe problemy. Możemy odwzorować użytkowników na dobrze przestudiowane teoretyczne modele stylów uczenia się, takie jak Model Dunn i Dunn (Dunn i Dunn 1989) lub Model Stylów Umysłu Gregorca (Gregorc 1982), aby automatycznie dostosować kursy korekcyjne i pomóc użytkownikowi w poprawie wyników.
Kohortowanie użytkowników
Kohortowanie to klasyczny problem grupowania. Użytkownicy są pogrupowani na podstawie ich wzorców użytkowania w odniesieniu do funkcji produktu, a także wzorców wydajności w odniesieniu do sesji testowych, praktycznych i rewizyjnych. Każdy użytkownik jest mapowany do wielowymiarowej przestrzeni cech składającej się z wielu tysięcy atrybutów, które obejmują zarówno miary statyczne, jak i czasowe. Koordynacja na podstawie miar czasowych daje nam możliwość zimnego startu niskiej aktywności i nowych użytkowników poprzez przypisanie prawdopodobnych trajektorii kohort tym użytkownikom na podstawie ich początkowej aktywności. Kohortowanie użytkowników jest podstawowym wymogiem naszych funkcji dogłębnej nauki wyższego poziomu, takich jak uczenie mikroadaptacyjne, automatyczne generowanie informacji zwrotnych i rekomendowanie treści.
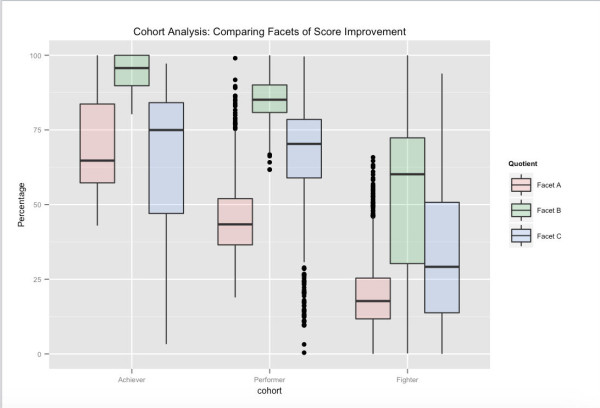
Jeden możliwy widok kohort użytkowników – związany z długoterminową wydajnością testów. W oparciu o ogólne wyniki testów, Achievers stanowią najwyższy percentyl użytkowników w Embibe, Performers w następnym przedziale, a Fighters w ostatnim przedziale. Pokazane różne aspekty odnoszą się do różnych aspektów poprawy wyników, w których skupiliśmy naszą przestrzeń funkcji. Na przykład widzimy, że chociaż Facet_A różni się znacznie w różnych kohortach, kierując informacje zwrotne do innych aspektów uczenia się i wpływając na nie, można przesunąć użytkowników do kolejnej wyższej kohorty.
Nauka mikroadaptacyjna
Dostarczanie treści i informacji zwrotnych o niewielkich rozmiarach jest kluczem do skutecznego uczenia się online. Ogólnie użytkownicy spędzają w Internecie od 30 minut do godziny, ćwicząc koncepcje i pytania. W tym krótkim czasie bardzo ważne jest zmaksymalizowanie wpływu każdej sesji ograniczonej czasowo. Każda sesja jest atutem dla użytkownika, aby zmaksymalizować naukę, a najlepiej to osiągnąć, stosując strategię wielkości kęsa. Nasz mikroadaptacyjny silnik do sesji treningowych pobiera profil użytkownika i atrybuty kohorty wraz z naszym drzewem wiedzy z 11 000 (i rosnącymi!) połączonymi metaatrybutami pojęć jako dane wejściowe i zapewnia, że sekwencja pytań, dostarczone wskazówki i tylko- inteligentna informacja zwrotna na czas dostosowuje się dokładnie do użytkownika, aby poprawić jej wyniki w nauce w przypadku każdego celu o wielkości kęsa. Każde małe zużycie treści lub informacji zwrotnej wpłynie na kalibrację biegłości użytkownika w porównaniu z naszym obszernym drzewem pojęć wiedzy. Rzadkie techniki przetwarzania macierzy, teoria odpowiedzi na elementy i algorytmy wykresów kierują mikroadaptacją uczenia się.
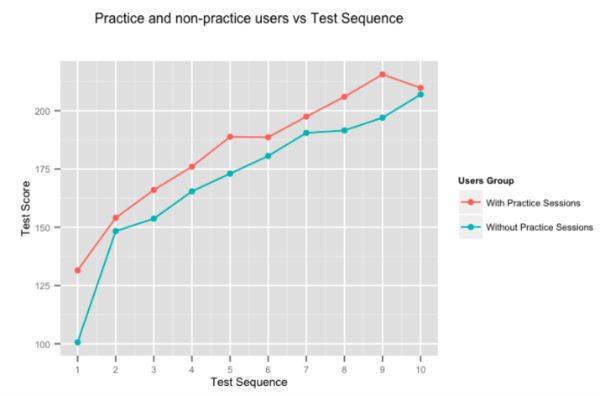
Dość oczywiste jest, że praktyka czyni ją doskonałym, ale i tak postanowiliśmy przeprowadzić obliczenia. Powyższy rysunek przedstawia średnią poprawę wyników użytkowników, dla kolejnych testów podawanych przez użytkowników, którzy spędzają czas na naszych sesjach ćwiczeń adaptacyjnych, oraz tych, którzy tego nie robią. Użytkownicy, którzy ćwiczą na Embibe, konsekwentnie przewyższają tych, którzy tego nie robią, o prawie 10% test-on-test.
System opinii i rekomendacji
System opinii i rekomendacji Embibe (na który już złożyliśmy wnioski patentowe) został zaprojektowany i zbudowany w jednym celu – aby zmaksymalizować poprawę wyniku użytkownika. Instrumentujemy i interpretujemy tysiące sygnałów dotyczących prób użytkownika podczas sesji treningowych i testowych oraz przekształcamy te sygnały w wielowymiarową przestrzeń tysięcy funkcji dla każdego użytkownika. Korzystając ze statystycznego wydobycia wzorców w naszej ogromnej przestrzeni funkcji związanych z próbami użytkowników, skupiliśmy się na uszeregowanych zestawach parametrów, które pozytywnie podnoszą wynik użytkownika. Parametry te są kodowane maszynowo jako wysoce ukierunkowane kapsułki just-in-time z informacją zwrotną o poprawie wyników i dostarczane użytkownikowi, gdy kontynuuje sesję treningową. Opinie i rekomendacje ujawniają słabości i strategie, które może zastosować, aby zmaksymalizować swój wynik.
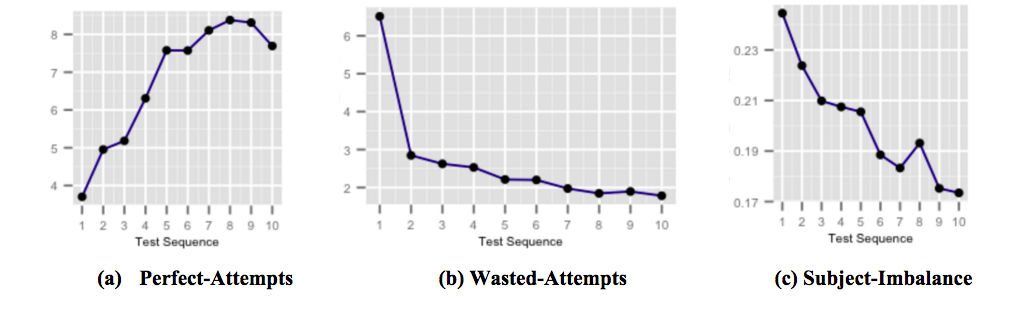
Powyższe liczby pokazują, w jaki sposób nasze wysoce ukierunkowane kapsułki z informacjami zwrotnymi „dokładnie na czas”, mające na celu poprawę wyników, wpływają na wyniki uczniów, gdy użytkownik jest narażony i zdaje sobie sprawę z typowych pułapek związanych z testowaniem. Rysunek (a) pokazuje średnią liczbę doskonałych prób wzrastającą w kolejnych testach. Próby doskonałe to próby, na które w określonym czasie udzielono prawidłowej odpowiedzi. Rysunek (b) pokazuje średnią liczbę zmarnowanych prób malejącą w kolejnych testach. Próby zmarnowane to próby, na które udzielono błędnej odpowiedzi, gdy uczeń miał więcej czasu niż mógł poświęcić na przemyślenie pytania. A rysunek (c) pokazuje średni spadek równowagi w dokładności względem przedmiotu w kolejnych testach. Nierównowaga między dokładnością względem przedmiotu jest definiowana jako różnica między najwyższą i najniższą dokładnością wśród wszystkich przedmiotów w dowolnym teście zdanym przez użytkownika. Wyższa nierównowaga między dokładnością przedmiotu oznacza, że użytkownik jest mniej przygotowany na niektóre przedmioty w porównaniu z innymi przedmiotami.
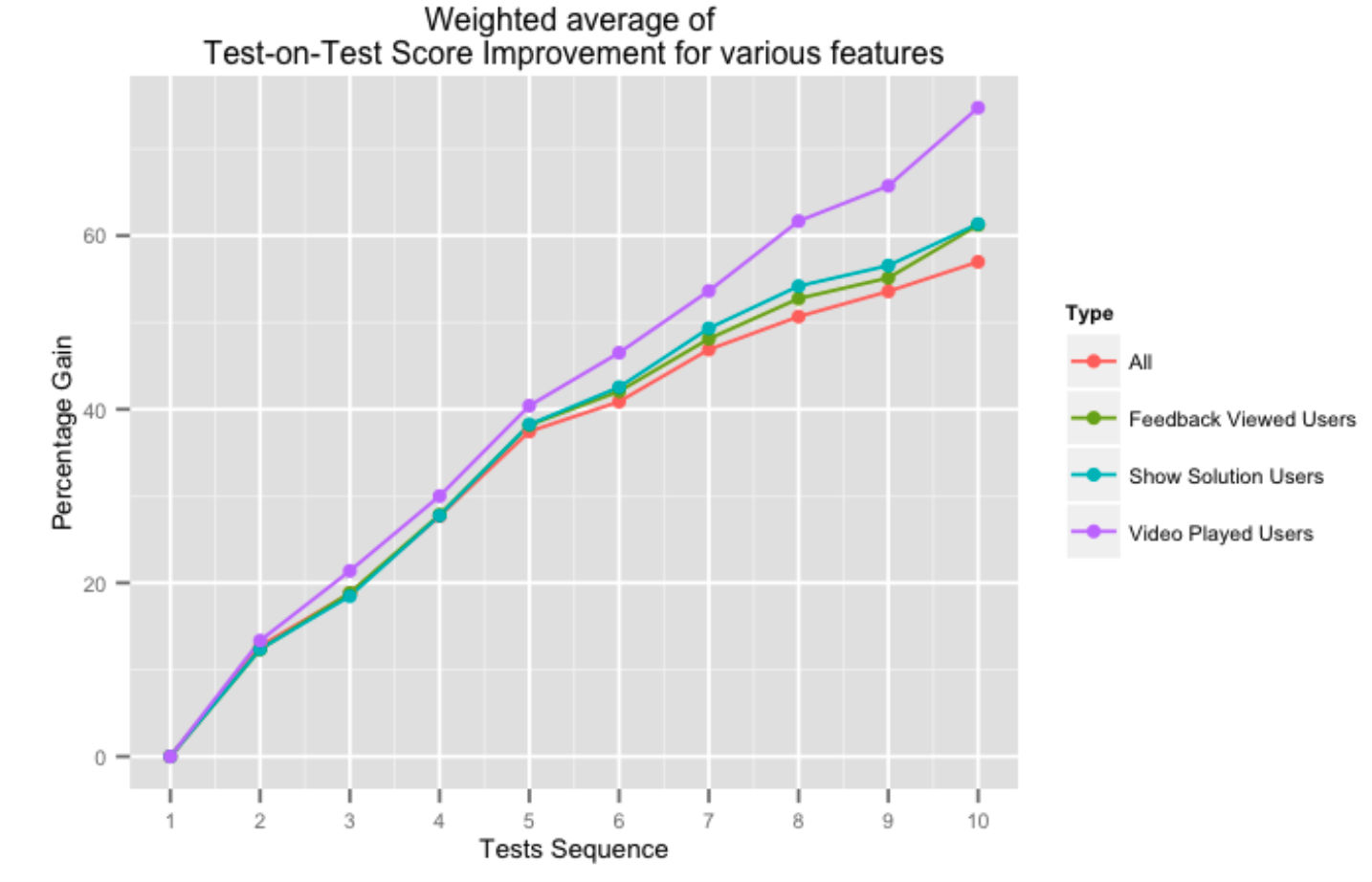
Powyższy rysunek pokazuje procentowy wzrost wyników kolejnych testów w teście dla użytkowników, którzy korzystają z różnych aspektów naszego systemu informacji zwrotnej. Korzystanie z pomocy naszej platformy w postaci rozwiązań wideo lub ogólnych informacji zwrotnych z testów pozytywnie wpływa na wyniki testów, zwłaszcza gdy użytkownik wykonuje więcej testów.
Szacowanie poprawy wyniku
Dla użytkowników, którzy przygotowują się do wszelkiego rodzaju egzaminów, poprawa wyników jest najważniejszym aspektem wpływającym na efekty uczenia się. Nasze bogactwo danych behawioralnych daje nam możliwość uczenia się na podstawie wcześniejszych działań użytkowników, mierząc, jak ich zachowanie podczas i po wykonaniu testów na Embibe wpływa na poprawę wyników. Eksploracja danych pod kątem wzorców statystycznych dotyczących użytkowania, aktywności i cech behawioralnych wśród różnych kohort użytkowników daje nam poparty naukowo dowód skuteczności naszej platformy.
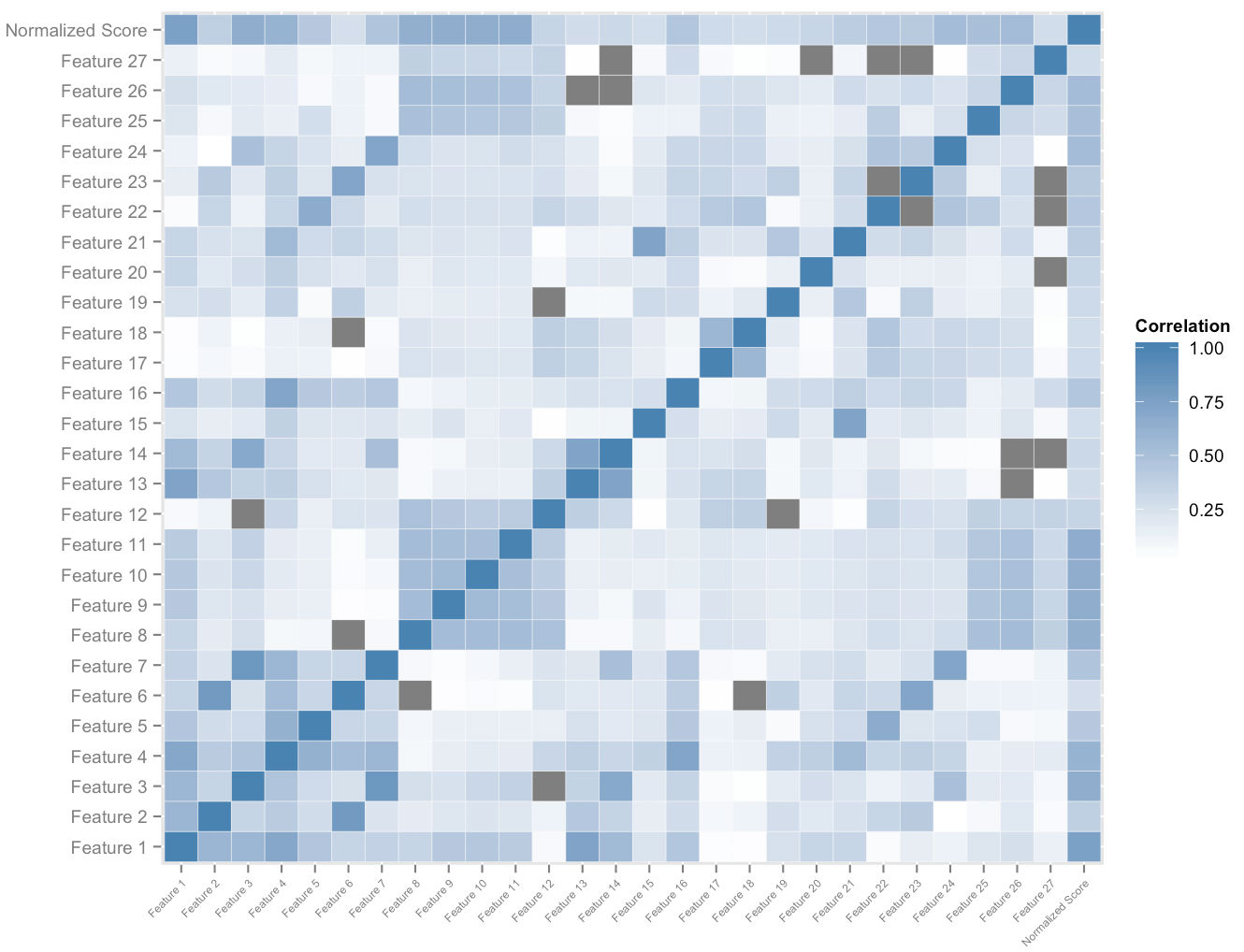
Powyższy rysunek pokazuje podzbiór przestrzeni funkcji, którą tworzymy na użytkownika. Analiza korelacji krzyżowych w przestrzeni cech i ogólnych znormalizowanych wyników daje nam uporządkowanie według względnego znaczenia cechy. To, wraz z empiryczną analizą dominacji, pozwala nam zmierzyć kwant wpływu każdej cechy na jej wkład w poprawę wyników. Odpowiednio wyważona kombinacja prędkości najważniejszych z tych cech pozwala nam ilościowo przypisać miarę potencjalnej poprawy wyniku każdemu uczniowi, który dostosowuje się do niej w miarę korzystania z platformy.
To ekscytujące czasy w dziedzinie edukacji, zwłaszcza w Indiach i innych krajach rozwijających się. Istnieje pilna potrzeba zastosowania głębokiej nauki, z silnym naciskiem na wykorzystanie danych i spostrzeżeń, jakie mogą one dostarczyć, aby przenieść edukację i uczenie się na wyższy poziom. Nasze platformy pozyskiwania i dostarczania treści są zbudowane na solidnych zasadach naukowych i pomagają użytkownikom uświadomić sobie ogromną wartość Embibe w postaci poprawy wyników w ograniczonym czasie przygotowania. Nasza mikroadaptacyjna platforma uczenia się, która wykorzystuje informacje zwrotne i zalecenia specyficzne dla użytkownika, precyzyjnie dostosowane do użytkowników, w oparciu o ich klasyfikacje kohortowe oraz cechy behawioralne, umożliwia użytkownikom satysfakcjonujące korzystanie z systemu Embibe. Są to pierwsze konkretne kroki w kierunku rozwiązania problemu pozytywnego wpływu na efekty uczenia się. To jest spersonalizowana nauka.
W tym poście poruszyliśmy różne podproblemy, które należy rozwiązać, aby poprowadzić nas na drodze do wpływania na wyniki uczenia się. W następnym poście opowiemy o tym, jak mierzymy i śledzimy różne wskaźniki w Embibe, które są związane z naszymi użytkownikami i ich aktywnością, abyśmy mogli trzymać rękę na pulsie naszego produktu, jego rozwoju i skuteczności jako miejsce nauki online.
Zawsze szukamy niegodziwych mądrych ludzi, którzy mogliby dołączyć do naszych szeregów w Data Science Lab. Jeśli lubisz testować hipotezy, przeprowadzać regresje, rozkładać na czynniki ogromne macierze, śmiać się w obliczu dużych zbiorów danych, zwalniać zadania związane z redukcją map, budować modele tematyczne na bałaganiarskim tekście nieustrukturyzowanym, wydobywać zaszumione dane w poszukiwaniu wzorców statystycznych, pozyskiwać góry danych z otwartych danych źródła, argumentowanie wartości p, trenowanie sieci neuronowych i głębokich sieci przekonań, przełączanie między Pythonem a R, wirowanie wizualizacji i powłoki skryptów, pokochasz to tutaj!
Napisz do nas ze swoim CV na adres oferty pracy.<id>@embibe.com, gdzie:
<id> to liczba utworzona z pierwszych 8 niezerowych cyfr wartości funkcji gęstości prawdopodobieństwa dla rozkładu normalnego, zaokrąglona do 19 cyfr dokładności oraz
mu jest 26. liczbą w sekwencji Padovan, a
sigma to 17. liczba w ciągu Fibonacciego zaczynająca się od 1, a
x to 1002. liczba pierwsza
Nasz zespół składa się z Keyur Faldu ( główny analityk danych), Achint Thomas ( główny badacz danych) i Chintan Donda (badacz danych ).
Bibliografia
- Inwentarz stylów uczenia się . Lawrence, KS: Systemy cenowe.
- Gregorc AF, (1982). Model stylów umysłu: teoria, zasady i zastosowania. Maynard, MA: Gabriel Systems.
Embibe niedawno ukończył 3 lata na rynku jako jedna z czołowych firm zajmujących się analizą danych edukacyjnych. Studenci spędzili ponad 100 000 godzin na produkcie w samym marcu 2016 r., bez inwestycji w płatny marketing.