
3億學生,3000億洞察——愛上教育數據
已發表: 2016-04-07Embibe 數據科學實驗室的獨家內幕
[這是我們如何使用深度技術和數據科學來個性化教育系列的第二部分]
我們以一個單一的願景構建了 Embibe:最大限度地提高學習成果。 對用戶的學習成果產生積極影響是一個難以解決但很重要的問題。 事實上,有許多不平凡的開放子問題,每一個都需要解決,以實現有意和積極影響學習成果的崇高目標。
但首先,什麼是學習成果? 我們為什麼要關心他們?
在當今競爭激烈的世界中,衡量一個學生在很大程度上取決於她在競爭性考試甚至學校課堂上的得分。 她的分數會對她的職業選擇產生重大影響。 出於本文的目的,讓我們將學習成果構建為學生先天和可訓練潛力的函數,以便在嚴格規定的時間限制內以最佳方式學習、吸收和應用內容; 這樣她就可以在任何特定的競爭性學術環境中最大化她的分數。
在像印度這樣的發展中國家,學生與教師的比例非常不平衡,教師無法在個人層面有效地提供個性化的關注。 鑑於每個學生以不同的速度學習和吸收信息並且具有不同的能力水平,這導致了一個兩難境地。 教師無法提供個性化關注的一個已知副作用是,對於任何給定的教室/學生集合,學習材料總是為迎合“普通”學生而呈現。 因此,非常聰明的學生不能充分發揮他們的潛力,也無法真正發揮他們的學術力量,而學業較弱的學生將很難應付課堂上的其他部分。 然而,現有的在線學習平台和系統並不能真正促進學生層面的個性化學習。
大多數當前系統僅考慮學生如何將他們的解決方案與系統管理員指定的測試模塊相匹配。 競爭性考試的個性化學習應該在有限的時間內最大限度地提高學生在任何學術目標上的分數。 個性化學習還應建設性地解決學生的能力差距,不僅在知識或能力水平上,而且在態度和行為水平上。 缺乏有效的個性化學習工具,專門為每個學生量身定制,導致她無法在任何給定的考試中發揮自己的潛力,從而獲得盡可能高的分數。
在本文中,embibe 的數據科學團隊將為需要解決的各種相互關聯的數據相關問題奠定基礎,以最大限度地提高學習成果,特別是提高分數。 這個問題有兩個主要方面——內容攝取和內容交付。 每個維度都在許多領域提出了獨特的挑戰,這些領域肯定會讓任何數據科學家著迷。
內容攝取
自動攝取內容
數十個教學大綱板、數千個章節和概念以及數以萬計的機構和學校導致教師每年生成和使用數十萬個問題和答案。 想像一下,如果每個學生都能夠在任何子集或所有這些問題的考試前測試他們的知識,並獲得有關正確答案和常見錯誤的詳細解釋。 為了實現這一目標,我們正在利用光學字符識別 (OCR) 和機器學習來構建我們自己的自動攝取框架,該框架將具有高度可擴展性、真正的多語言,並且對人工輸入的依賴程度最低。 樂趣並不止於此。 該框架還將能夠以與作者無關的方式攝取手寫內容,從而迅速添加到我們已經非常棒的問題、答案、概念、解釋和知識庫中。
概念標記
好的,所以現在我們將問題、答案、概念和章節都納入了一個龐大的數據倉庫。 用相關概念手動標記每個問題或章節會很痛苦,反之亦然。 數據科學來拯救! 我們使用來自文本分類、主題建模和深度學習的前沿思想,自動將概念標記為問題、答案和章節。

在 2015 年 12 月、2016 年 1 月和 2016 年 2 月,Embibe 用戶使用 Learn 功能瀏覽的最流行概念精選。
我們先前的數據庫包含高質量手動標記內容的種子集,這有助於我們提取語言、詞彙和上下文相關的特徵,為所有被攝入到我們的新數據中的新數據訓練最先進的文本標記模型。系統。
元數據豐富
今天,網上有大量關於人們希望了解的主題的信息。 想法和概念是相互建立的。 例如,熱力學第一定律與熱力學系統的概念有關,而熱力學系統又與氣體的比熱容、機械能守恆和氣體所做的功等概念有關。 我們的內容攝取框架包括數據豐富組件,可自動抓取網絡並使用文本解釋、視頻鏈接、定義、用戶評論和論壇討論等多種媒體標記內容,同時尊重版權,並正確歸屬來源內容的所有權. 這種豐富的可用信息也使得自動連接樹結構中的相關概念成為可能。 利用圖論、文本挖掘和稀疏結構上的標籤傳播領域的思想,我們在共享源→目標關係的概念之間創建鏈接和互連。
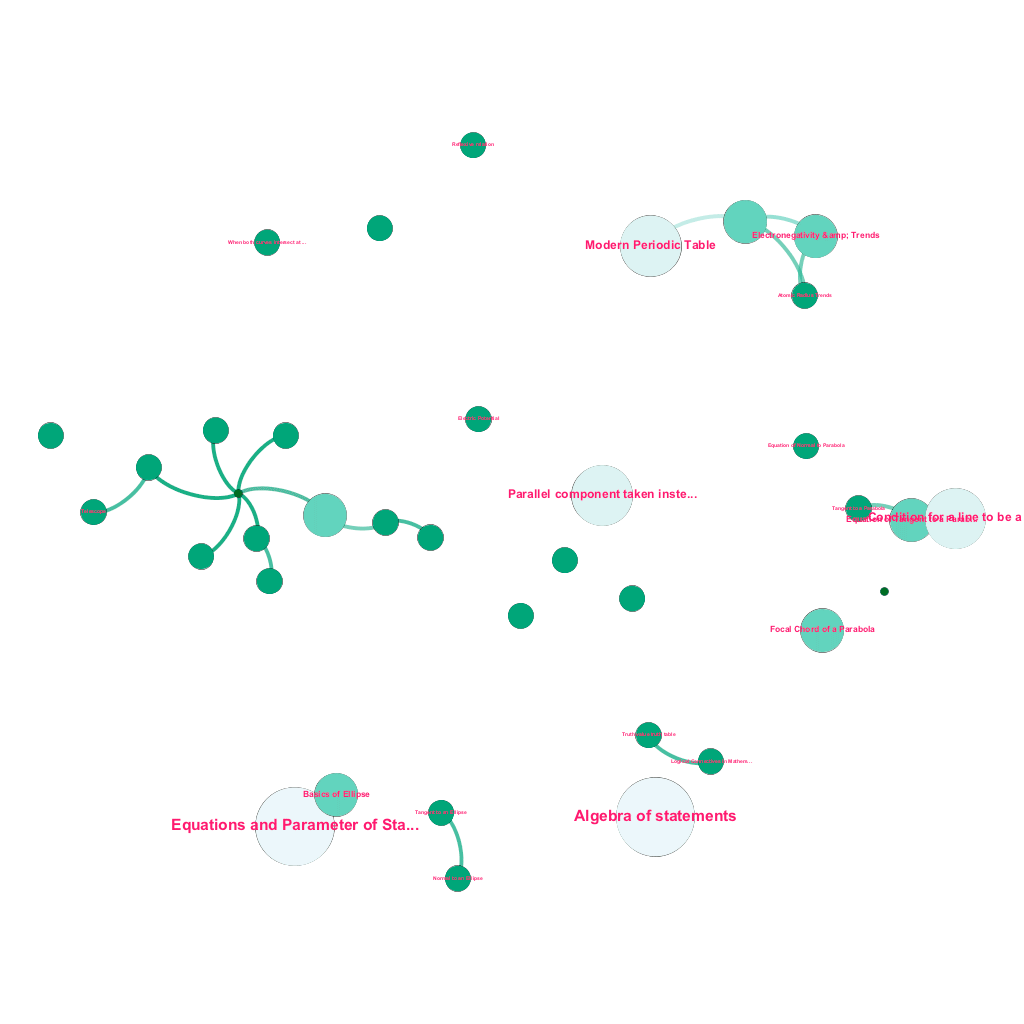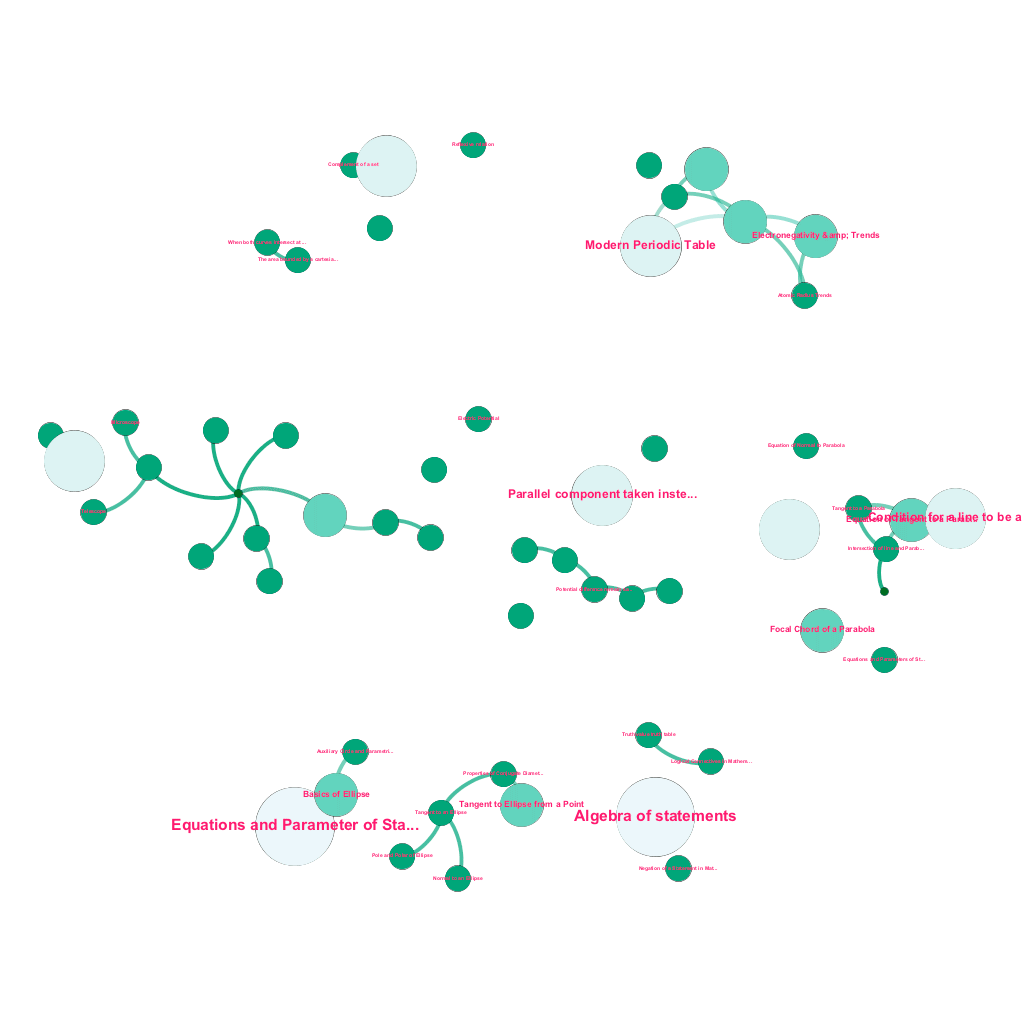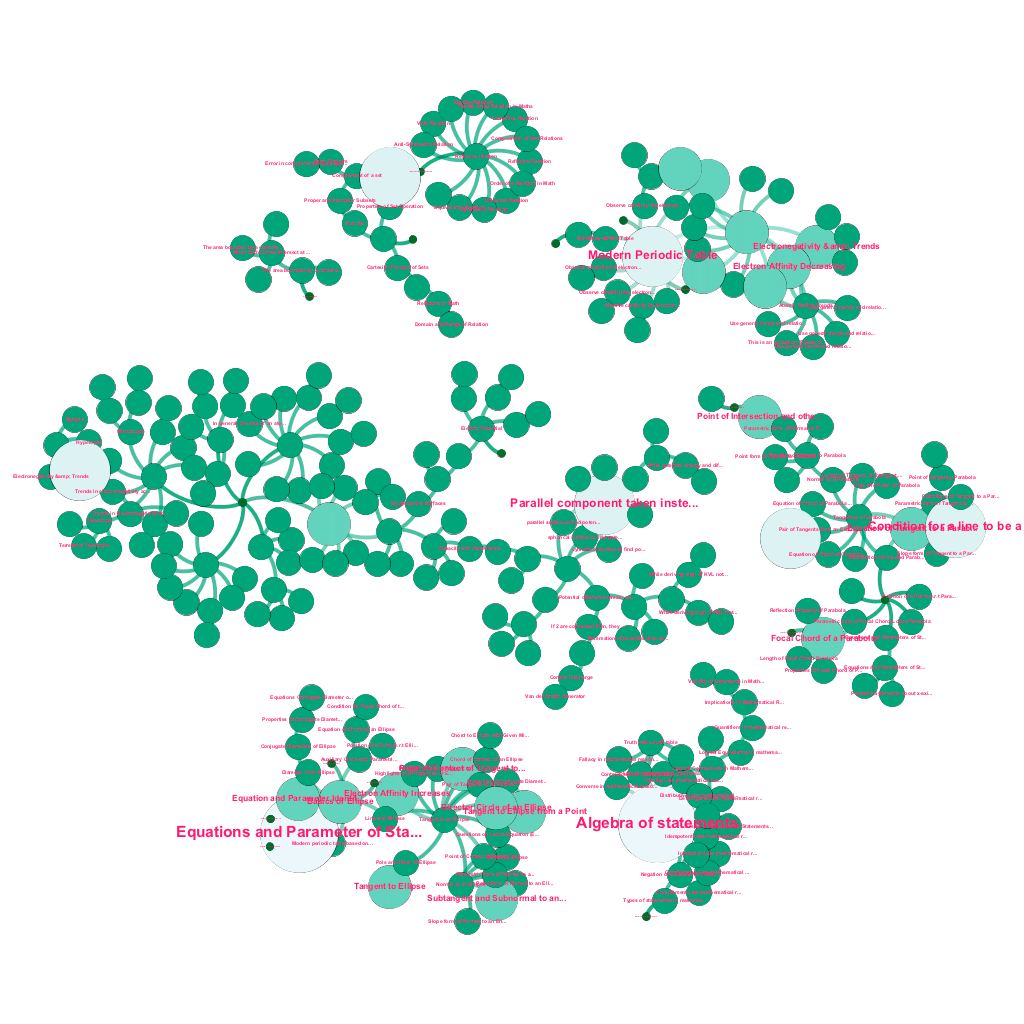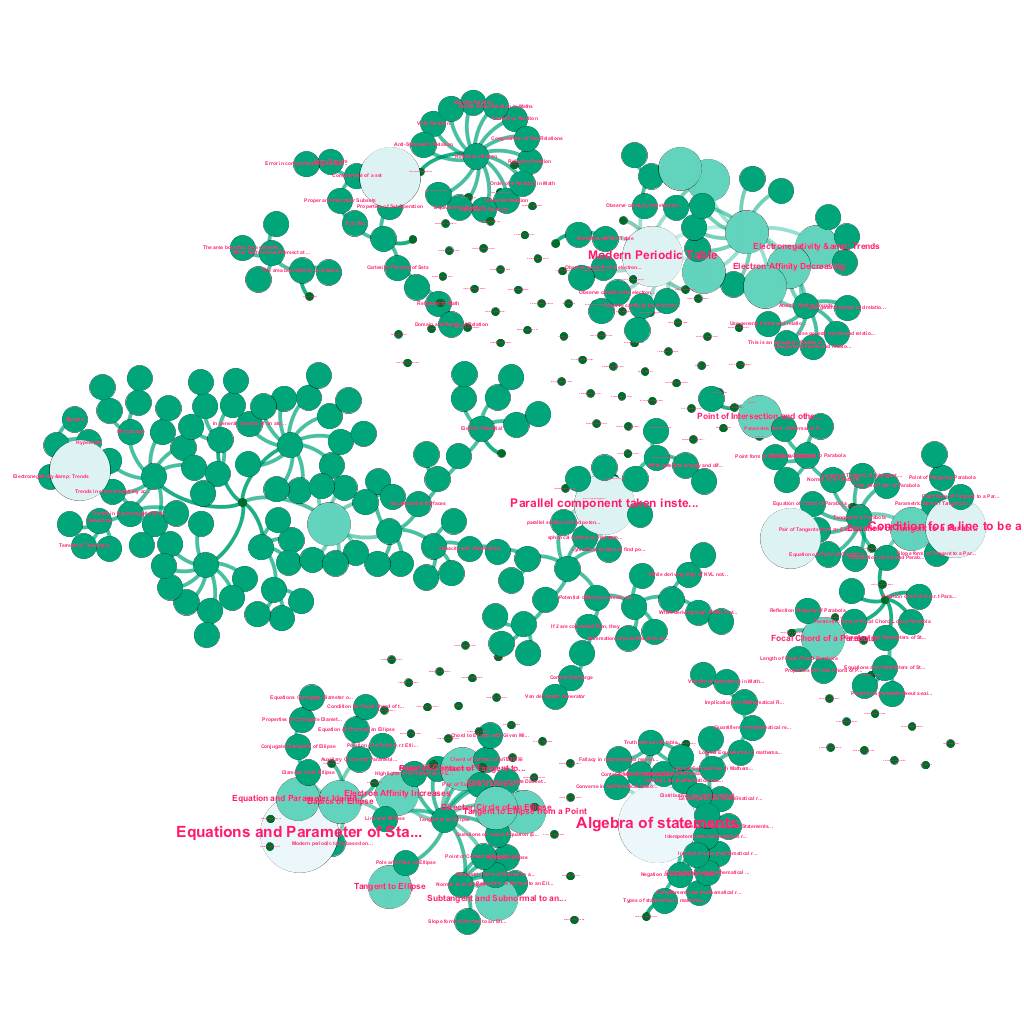
自動構建概念樹,用於數學中的一個子集,每個概念都連接到一個或多個相關概念
相似問題聚類
如果你正在準備考試,你會想一遍又一遍地練習同一個問題嗎? 那不會有幫助。 相反,想像一下練習一小部分相關問題會非常有用,這將幫助你完全掌握一些新概念或新章節。 通過訪問數十萬個問題,我們開發了基於多個維度的相似性對問題進行聚類的能力——內容定位、概念測試、難度級別和考試目標等。
基於潛在語義信息空間的文本聚類,以及它們與其他分類和數字特徵空間的結合,使我們能夠將我們的問題領域精確地分組到可以使用 Embibe 為每個人定制的感興趣的領域。 此外,我們已將這種豐富的文本數據資源轉化為與概念集群相關的穩健數字特徵空間,讓我們稍微擾亂現有數據以生成問題空間的潛在無限表達。 運行時更多問題,前所未見! 這使我們能夠為用戶在我們平台上花費的時間提供最大價值。
內容交付
用戶分析
我們跟踪用戶在 Embibe 上的一舉一動。 我們的用戶在過去三年中進行的數百萬次實踐和測試嘗試是在數千維的數據空間中進行校準的。 這意味著我們可以挖掘數十億數據點的空間,以深入挖掘用戶的行為數據並生成與學習發生方式相關的見解。 用戶的每一次額外嘗試,都會調整她在標記到該嘗試的概念以及相關的先前和後續概念上得分更高的能力。 這個超級複雜的問題涉及利用稀疏矩陣處理、圖論中的計算算法和項目響應理論中的思想來構建穩健且自適應的用戶配置文件,以適應我們不斷增長的用戶群。
為你推薦:

反暴利條款對印度初創企業意味著什麼?

教育科技初創公司如何幫助印度的勞動力提高技能並為未來做好準備……

本週新時代科技股:Zomato 的麻煩仍在繼續,EaseMyTrip 發布強...

印度初創公司走捷徑尋求資金

數字營銷平台 Logicserve 獲得 80 盧比的資金,更名為 LS Dig...

報告警告對 Lendingtech Space 重新進行監管審查
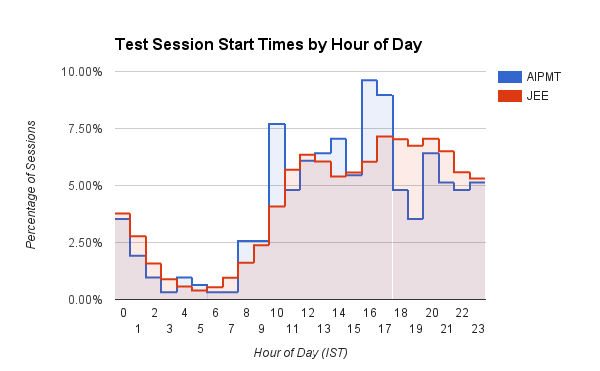
一個有趣的條形圖,顯示了用戶在 Embibe 上開始測試會話的時間(IST 中的小時數)。 醫療 (AIPMT) 用戶在上午 10 點左右和下午 3 點到 5 點之間有一個明確的高峰。 另一方面,工程 (JEE) 用戶顯示,隨著時間的推移,會話開始時間逐漸增加,在下午 4 點到 8 點左右達到峰值。 與 AIPMT 學生相比,JEE 學生在下午 5 點到凌晨 3 點之間開始的練習也更多。 我們猜測醫生更有紀律!

我們在非常精細的級別上對用戶活動進行廣泛的檢測和測量,使我們能夠推斷出與個人用戶相關的學習風格相關的潛在偏好。 例如,某些學生可能會在視頻解釋的幫助下學習,然後在測試中表現得更好,而其他學生則喜歡廣泛的文本描述,或者還有一些學生通過逐步解決示例問題來學習。 我們可以將用戶映射到經過深入研究的學習風格理論模型,如 Dunn 和 Dunn 模型 (Dunn & Dunn 1989) 或 Gregorc 的思維方式模型 (Gregorc 1982),以自動定制補習課程並幫助用戶提高分數。
用戶群組
隊列是一個經典的聚類問題。 用戶根據他們在產品特性方面的使用模式以及他們在測試、實踐和修訂會話方面的性能模式進行分組。 每個用戶都映射到包含數千個屬性的高維特徵空間,其中包括靜態和時間度量。 時間度量上的隊列使我們能夠通過根據初始活動為這些用戶分配可能的隊列軌跡來冷啟動低活動和新用戶。 用戶群組是我們更高層次的深度科學功能(如微自適應學習、自動反饋生成和內容推薦)的核心要求。
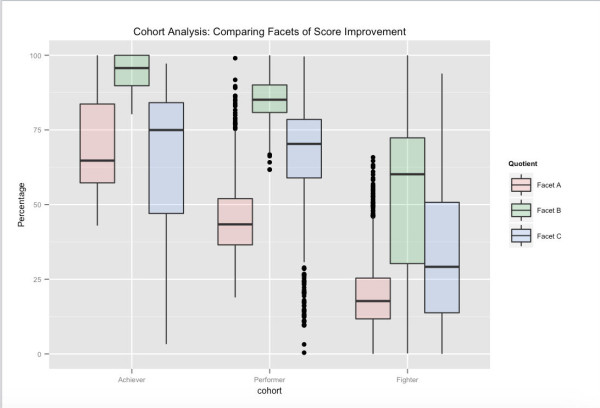
用戶群組的一種可能視圖——與長期測試性能相關。 根據他們的整體測試分數,成就者是 Embibe 用戶的最高百分位組,表演者是下一個組,戰士是最後一個組。 顯示的各個方面與我們將特徵空間聚類到的分數改進的不同方面有關。 例如,我們可以看到,儘管 Facet_A 在不同群組之間存在顯著差異,但通過針對其他學習方面的反饋並影響其他學習方面,有可能將用戶推入下一個更高的群組。
微適應學習
一口大小的內容和反饋交付是有效在線學習的關鍵。 通常,用戶在網上花費 30 分鐘到一個小時,練習概念和問題。 在這麼短的時間跨度內,最大化每個有時間限制的會話的影響是非常重要的。 每個會話都是用戶最大程度地學習的資產,而這最好通過一口大小的策略來完成。 我們用於練習會話的微自適應引擎,將用戶的個人資料和群組屬性以及我們的 11,000 個(並且還在增長!)相互關聯的概念的元屬性的知識樹作為輸入,並確保問題排序、提供的提示和公正 -及時的智能在線反饋可以精確地適應用戶,以提高她在任何小目標上的學習成果。 每一口內容或反饋的消費都會影響用戶對我們廣泛的概念知識樹的熟練度校準。 稀疏矩陣處理技術、項目響應理論和圖算法指導學習的微觀適應性。
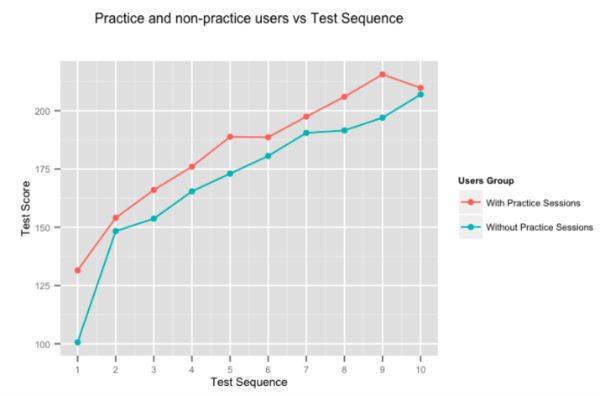
很明顯,熟能生巧,但我們還是決定算一算。 上圖顯示了用戶的平均分數提高,對於那些花時間在我們的自適應練習課程上的用戶進行的連續測試,以及那些不花時間的用戶。 在 Embibe 上練習的用戶在測試測試中的得分始終比不練習的用戶高出近 10%。
反饋和推薦系統
Embibe 的反饋和推薦系統(我們已經在其上申請了專利)是為一個目的而設計和構建的——最大限度地提高用戶的分數。 我們在練習和測試會話期間檢測和解釋有關用戶嘗試的數千個信號,並將這些信號轉換為每個用戶的數千個特徵的高維空間。 在我們龐大的用戶嘗試特徵空間上使用統計模式挖掘,我們已經將排名參數集歸零,這些參數集可以積極提高用戶的分數。 這些參數被機器編碼為分數改進反饋的高度針對性的即時膠囊,並在用戶繼續練習時傳遞給用戶。 反饋和建議揭示了她可以用來最大化她的分數的弱點和策略。
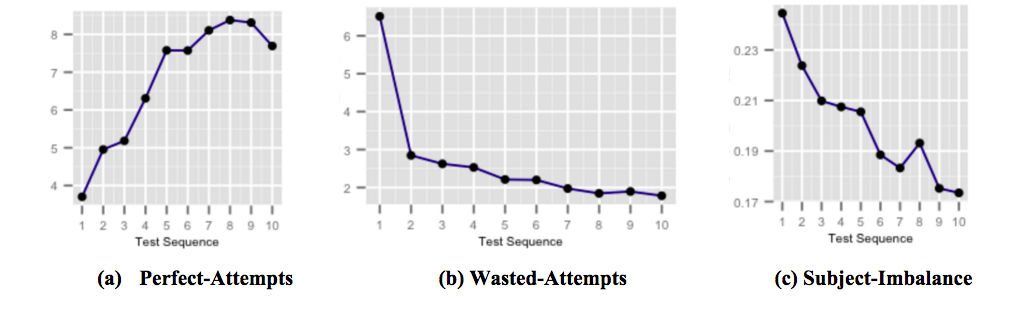
上圖顯示了當用戶接觸並意識到常見的考試陷阱時,我們針對分數提高的高度針對性的即時反饋膠囊如何影響學生的表現。 圖(a)顯示了完美嘗試的平均次數在連續測試中增加。 完美嘗試是在規定時間內正確回答的嘗試。 圖 (b) 顯示了在連續測試中浪費嘗試的平均次數減少。 浪費的嘗試是在學生有更多時間可以用來思考問題的情況下被錯誤回答的嘗試。 圖(c)顯示了平均主題準確度不平衡在連續測試中下降。 受試者準確度不平衡被定義為用戶參加的任何測試中所有受試者的最高準確度和最低準確度之間的差異。 較高的主題準確度不平衡意味著與其他主題相比,用戶對某些主題的準備不足。
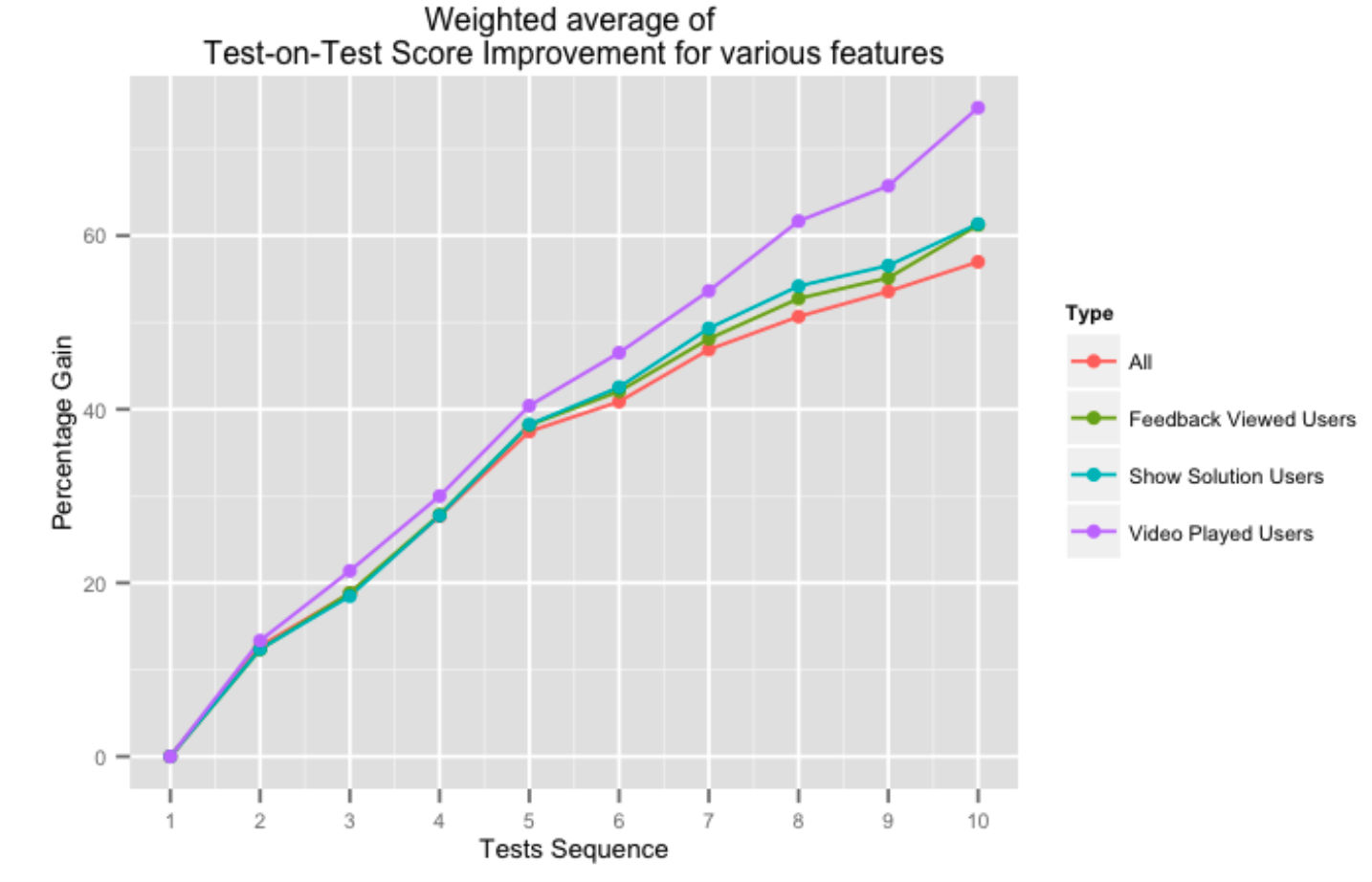
上圖顯示了使用我們反饋系統各個方面的用戶在連續測試分數中的百分比增益。 從我們的平台以視頻解決方案或整體測試反饋的形式獲得幫助,會對測試分數產生積極影響,尤其是當用戶完成更多測試時。
估計分數提高
對於準備任何形式的考試的用戶來說,分數提高是影響學習成果的最重要方面。 我們豐富的行為數據使我們能夠從用戶過去的行為中學習,通過衡量他們在 Embibe 測試期間和之後的行為如何影響分數提高。 在各種用戶群中對使用、活動和行為特徵的統計模式進行數據挖掘,為我們提供了有科學依據的平台有效性證明。
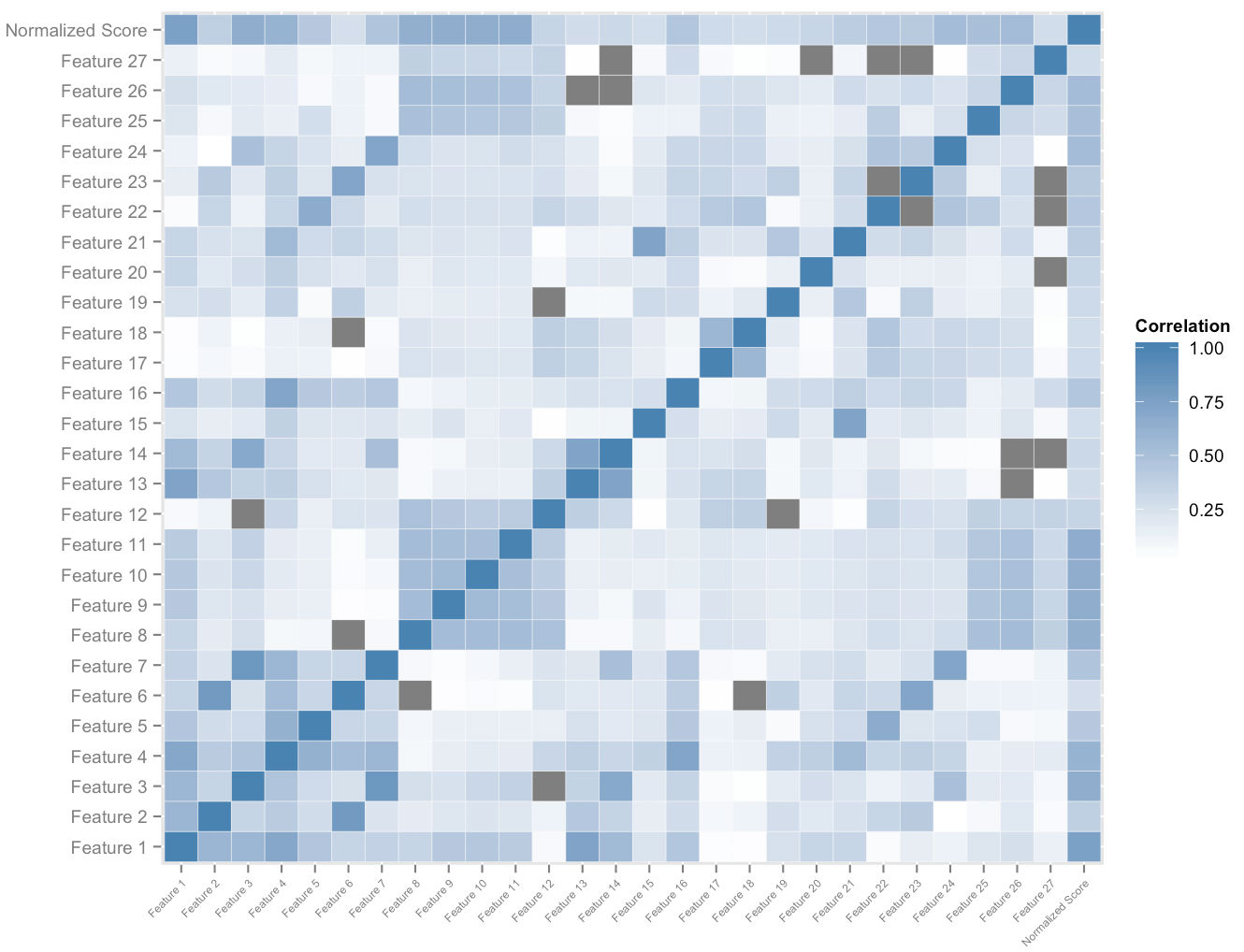
上圖顯示了我們為每個用戶構建的特徵空間的一個子集。 對特徵空間和整體歸一化分數的互相關分析為我們提供了相對特徵重要性的排序。 這與經驗優勢分析一起,使我們能夠衡量每個特徵對其對分數提高的貢獻的影響量。 這些特徵中最重要的特徵的速度的適當加權組合使我們能夠定量地為每個學生分配一個潛在分數提高的度量,這些學生在她使用平台時會適應她。
對於教育領域來說,這是激動人心的時刻,尤其是在印度和其他發展中國家。 迫切需要應用深度科學,重點關注使用數據及其可以提供的洞察力,以便將教育和學習提升到一個新的水平。 我們的內容攝取和交付平台是根據可靠的科學原理構建的,並正在幫助用戶在有限的準備時間範圍內以提高分數的形式實現 Embibe 的巨大價值。 我們的微自適應學習框架利用用戶特定的反饋和建議,根據用戶的群組分類和行為特徵,為用戶量身定制,讓用戶在 Embibe 上獲得充實的體驗。 這些是解決積極影響學習成果問題的第一個具體步驟。 這是個性化學習。
在這篇文章中,我們談到了需要解決的各種子問題,以推動我們沿著影響學習成果的道路前進。 在我們的下一篇文章中,我們將討論我們如何在 Embibe 測量和跟踪與我們的用戶及其活動相關的各種指標,以便我們了解我們產品的脈搏、它的增長和它的有效性一個在線學習目的地。
我們一直在尋找邪惡的聰明人加入我們在數據科學實驗室的行列。 如果你喜歡測試假設、運行回歸、分解龐大的矩陣、面對大數據發笑、啟動 map-reduce 工作、在凌亂的非結構化文本上構建主題模型、挖掘噪聲數據以獲得統計模式、從開放數據中攝取大量數據資源、爭論 p 值、訓練神經網絡和深度信念網絡、在 python 和 R 之間切換、旋轉可視化和腳本 shell,你會喜歡這裡的!
請將您的簡歷發送至 jobs.<id>@embibe.com,其中:
<id> 是由正態分佈的概率密度函數值的前 8 個非零數字組成的數字,四捨五入到 19 位精度,並且
mu 是 Padovan 序列中的第 26 個數字,並且
sigma 是斐波那契數列中從 1 開始的第 17 個數字,並且
x 是第 1002 個素數
我們的團隊由 Keyur Faldu(首席數據科學家)、 Achint Thomas(首席數據科學家)和Chintan Donda(數據科學家)組成。
參考
- 學習風格盤點。 堪薩斯州勞倫斯:價格系統。
- 格雷戈克 AF,(1982 年)。 思維風格模型:理論、原理和應用。 馬薩諸塞州梅納德:Gabriel Systems。
作為教育數據分析領域最重要的公司之一,Embibe 最近在市場上完成了 3 年。 僅在 2016 年 3 月,學生就在該產品上花費了超過 10 萬小時,而對付費營銷的投資為零。